要想LLM大模型性能更佳,我们需要喂给模型看得懂的高质量数据。那有没有一种方法,能让我们把各种文档“读懂”,再喂给大模型使用呢?
如果你用传统OCR工具直接从PDF中提取文本,结果往往是乱序、缺失、格式错乱。因为实际文档中常包含公式、表格、手写批注、文字段落等各种难以提取的元素。

图1. 覆盖全面,支持公式、手写体、图表内容的解析
我们调研并实测了一批当前主流的开源模型,包括更适用于论文解析的Nougat,专精于表格数据提取的MinerU,针对手写体优化的GOT-OCR,适用于技术文档的Marker,擅长处理复杂多语言混排文档的Surya,专门处理政府招标文档表格的Camelot,以及擅长金融类表格分析的TATR。
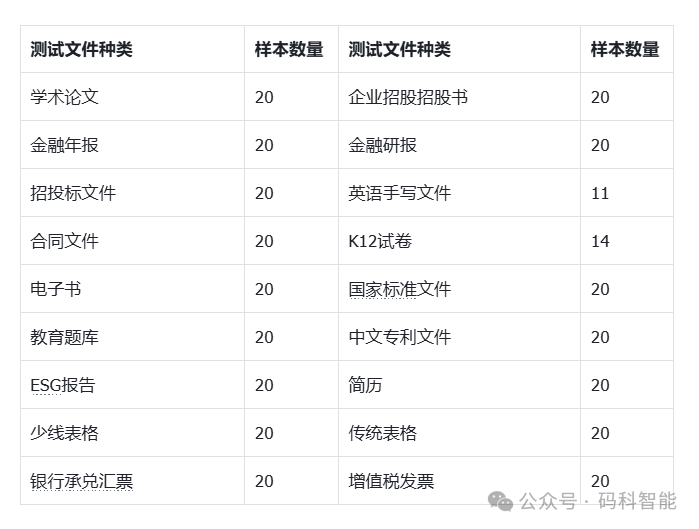
图2. 测试文件种类二十余种
上述模型各有优势,对于标准化文档已经够用了。但面对真实业务场景下的复杂文档,比如学术论文、财报、合同、工程图纸、试卷等,尤其涉及到文档中的复杂表格内容,模型往往就错误百出了。

一、什么样的文档解析工具才真正好用?
结合实际业务中的需求:能够识别文档中的所有信息,将文档解析为Markdown格式,并按常见的阅读顺序进行还原,从而赋能下游各类大语言模型任务。我们总结出理想中的文档解析引擎应具备以下几个核心能力:
✅ 识别能力覆盖全面:具有各类常见文档的识别解析能力,对有线无线表格、章节、标题、列表、公式、手写体、扫描件全部精准识别并结构化输出;

图3. 试卷的手写体识别,上半图是凌乱的手写字
✅ 表格识别强大:支持跨行合并、嵌套表格、带注释的复杂表格,100页文档1.5秒搞定;

✅ 输入输出灵活:输入:在线可用、API调用实时响应、本地部署也支持,一次性可处理万页以上的数据;输出:Markdown / JSON 格式输出,便于下游模型使用;
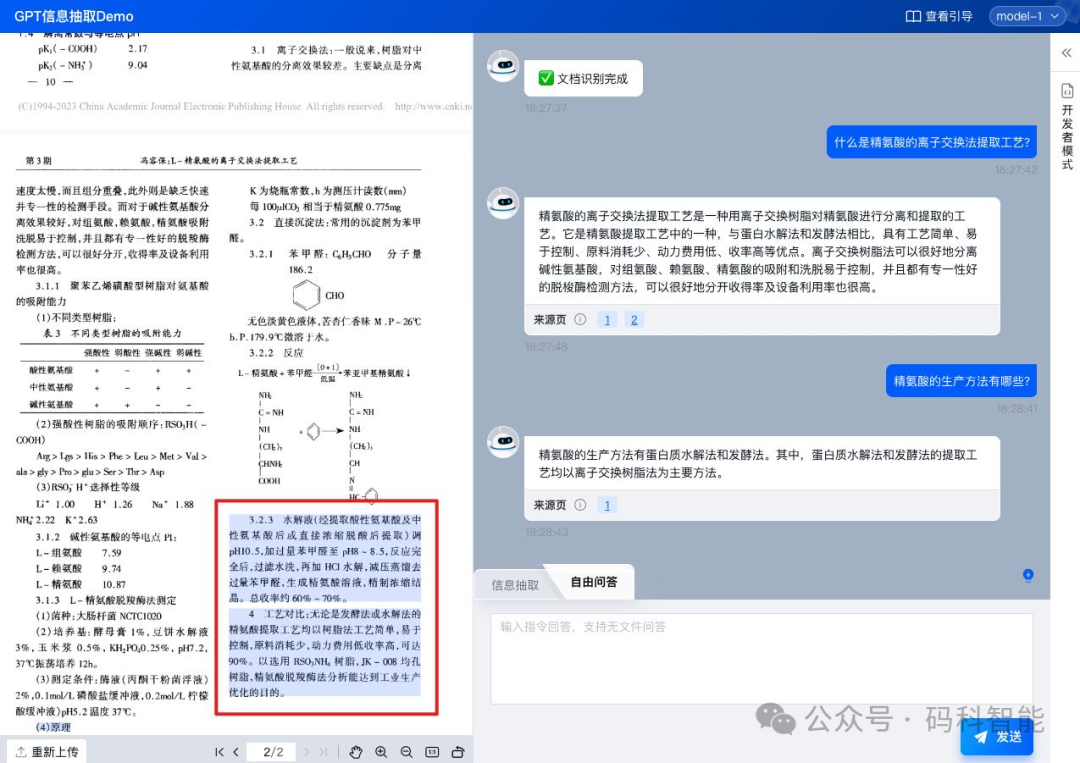
✅ 可溯源:抽取出来的内容可以溯源到原文位置,对长文档校验非常关键。同时能直接与文档问答,针对特定内容交互理解。
✅ 一次搞定多种格式:支持 PDF / Word / DOCX / HTML / JPG / PNG 等格式;

二、实战测评:基于真实样本的全方位评估
测评指标中分了6个维度,针对标题、段落、文本、阅读顺序、公式、表格进行定量测评。基于前文提到的大量真实样本,从多个维度评估了解析效果:
文件类型:PDF 扫描件、图像文件、电子文档;
内容种类:印刷体 + 手写字体,涵盖中英文;
场景分布:学术论文、商业报告、教育试卷、政府公文、工程图纸等。
最终我们找到了一个相对综合表现较好的文档解析工具 TextIn ParseX 。
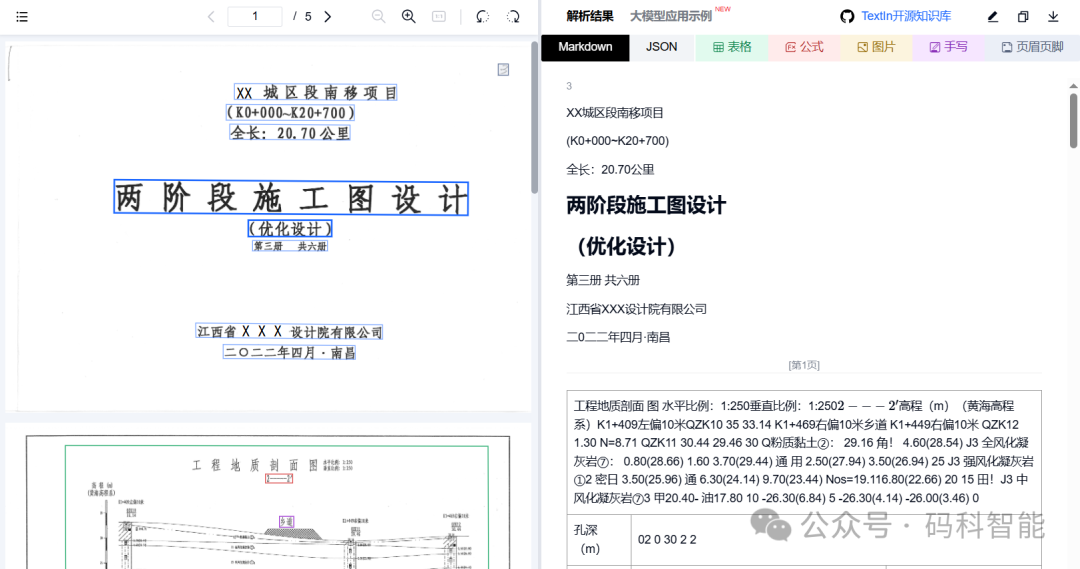
它不是简单的OCR,也不是普通的PDF转Markdown工具,而是一个专为LLM定制的通用文档解析服务。在多项测试中,TextIn ParseX 表现稳定,尤其在表格识别方面尤为突出,但公式识别相对一般。
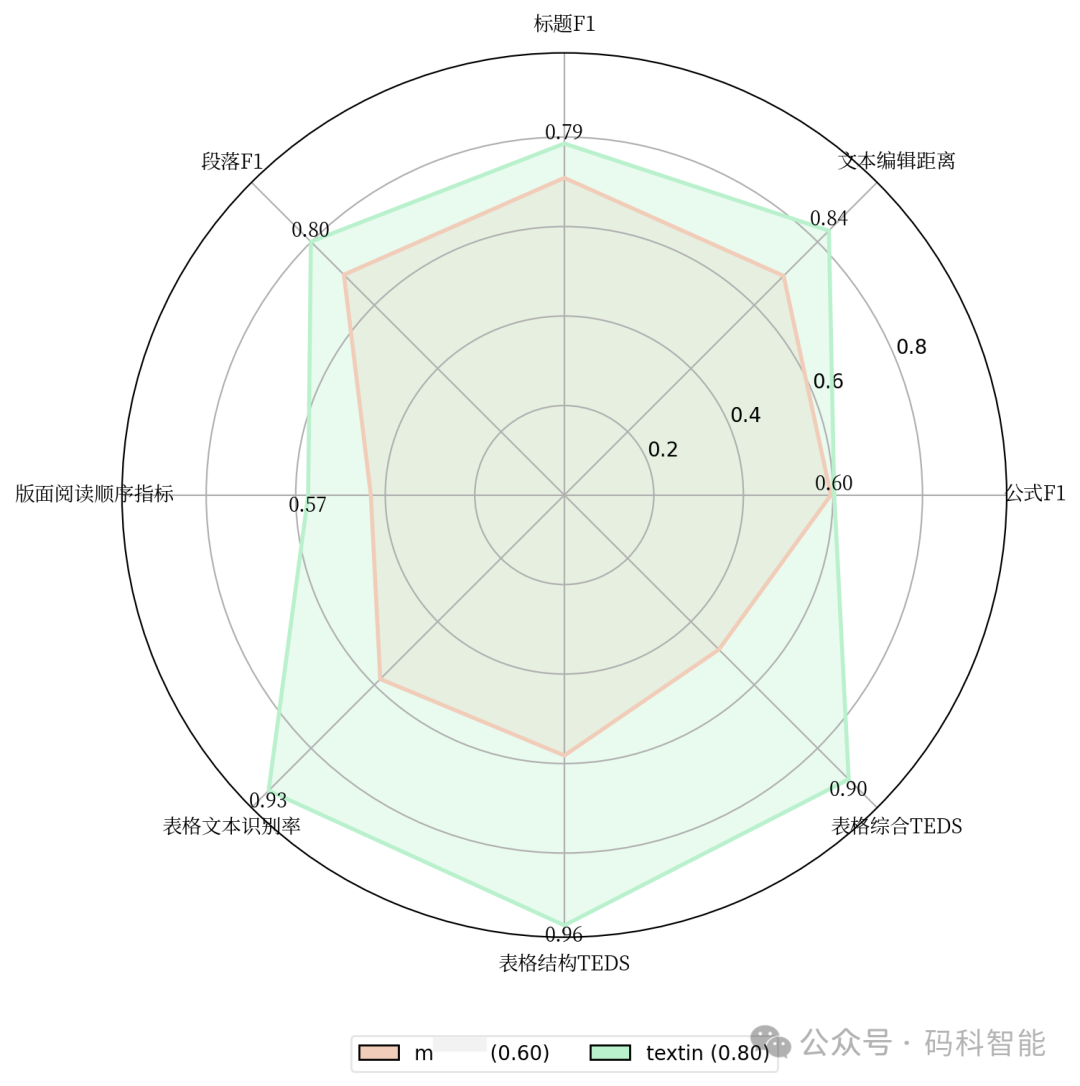
三、别让文档成为LLM落地的瓶颈很多人低估了文档解析的重要性。但实际上,文档质量决定了AI理解的上限。如果你正在构建 RAG、Agent 或知识库系统,可以考虑将TextIn ParseX作为你的文档预处理引擎。
因为你需要的不只是一个“能跑”的工具,而是一个稳定、准确、快速、可持续迭代的文档理解工具。你可以点击链接快速体验,直接上传文档进行测试。如需深度测试或大批量处理,也支持本地部署。
文章转载自TextIn合作博主——码科智能,未经允许,请勿转发