摘要
尽管大型语言模型(LLM)在各种任务中取得了巨大的成功,但它们经常与幻觉问题作斗争,特别是在需要深入和负责任的推理的场景中。这些问题可以通过在LLM推理中引入外部知识图(KG)来部分解决。在本文中,我们提出了一个新的LLM-KG集成范式“LLMKG”,它把LLM作为一个代理,以交互式地探索相关的实体和KGs上的关系,并进行推理的基础上检索到的知识。我们通过引入一种称为图上思维(ToG)的新方法进一步实现了这种范式,其中LLM代理迭代地在KG上执行波束搜索,发现最有希望的推理路径,并返回最可能的推理结果。我们通过一系列精心设计的实验来检验和说明ToG的以下优点:1)与LLM相比,ToG具有更好的深度推理能力; 2)ToG通过利用LLM推理和专家反馈,具有知识可追溯性和知识可纠正性; 3)ToG为不同的LLM、KG和提示策略提供了一个灵活的即插即用框架,而不需要任何额外的训练成本; 4)在某些场景下,具有小LLM模型的ToG的性能可以超过诸如GPT-4的大LLM,这降低了LLM部署和应用的成本。作为一种具有较低计算成本和较好通用性的免训练方法,ToG在9个数据集中的6个数据集中实现了整体SOTA,而大多数以前的SOTA依赖于额外的训练。我们的代码可在https://github.com/IDEA-FinAI/ToG上公开获取。
一、简介
大型语言模型(LLM)(Ouyang等人,2022年; OpenAI,2023年; Thoppilan等人,2022; Brown等人,2020年a;乔杜里等人,2022年; Touvron等人,2023)在各种自然语言处理任务中表现出了卓越的性能。这些模型利用应用于大量文本语料库的预训练技术来生成连贯且上下文适当的响应。尽管LLM具有令人印象深刻的性能,但它们在面对复杂的知识推理任务时具有实质性的局限性(Petroni等人,2021年; Talmor等人,2019年; Talmor & Berant,2018年; Zhang等人,2023),需要深入和负责任的推理。首先,LLM通常不能对需要超出预训练阶段所包括的专门知识(图1a中的过时知识)的问题或需要长逻辑链和多跳知识推理的问题提供准确的答案。第二,LLM缺乏责任感、可解释性、透明性,引起了人们对产生幻觉或有毒文字的担忧。第三,LLM的训练过程往往既昂贵又耗时,因此要使他们的知识保持最新很有挑战性。
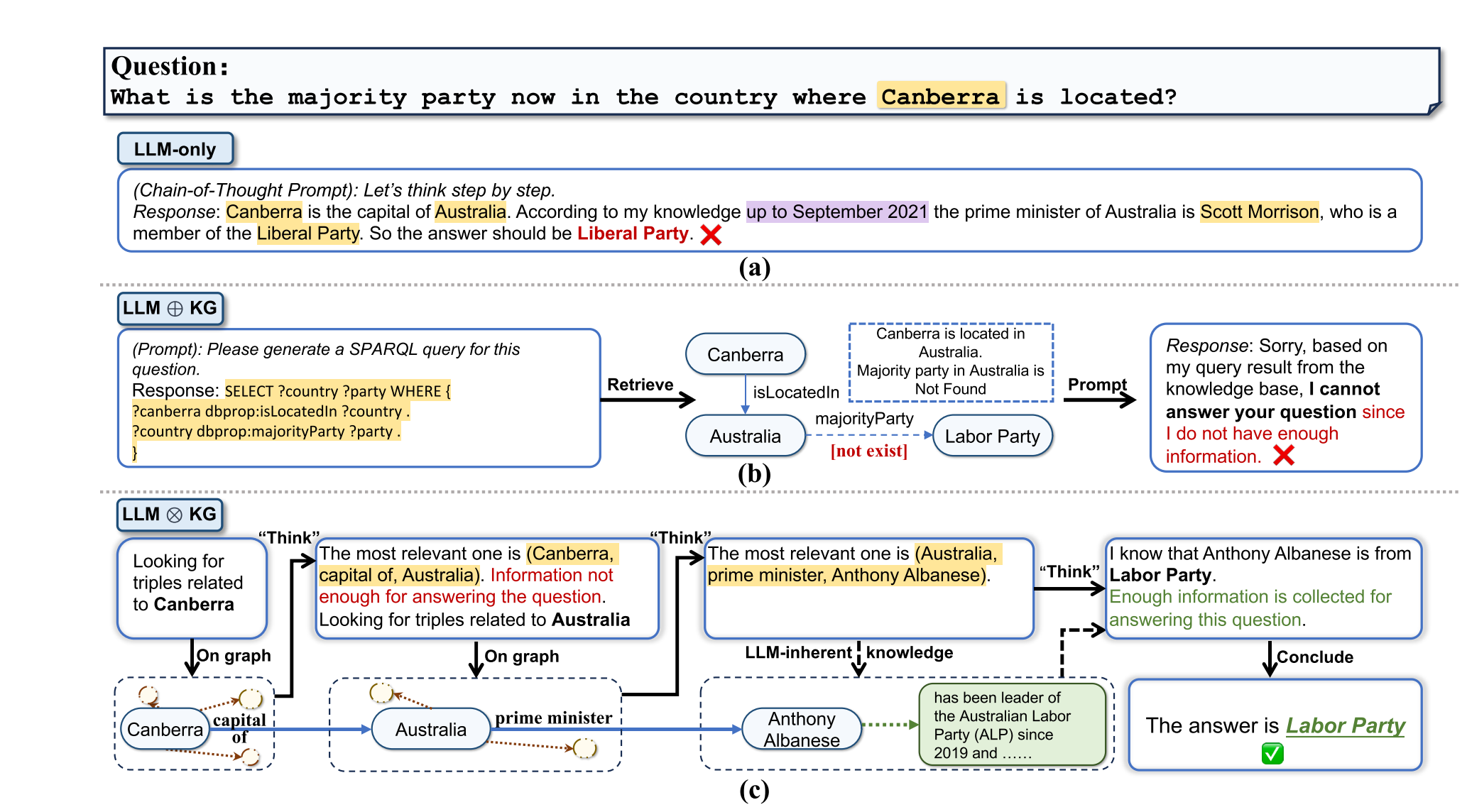
图1:三种LLM推理范式的代表性工作流程:(a)仅LLM(例如,思想链提示),(B)LLM KG(例如,通过LLM生成的SPARQL查询的KBQA),(c)LLM
KG(例如,通过LLM生成的SPARQL查询的KBQA),(c)LLM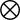 KG(例如,图上思考)
KG(例如,图上思考)
认识到这些挑战,一个自然的和有前途的解决方案是结合外部知识,如知识图(KG),以帮助改善LLM推理。KG提供了结构化的、明确的、可编辑的知识表示,提供了一种补充策略来减轻LLM的局限性(Pan等人,2023年)的报告。研究人员(Li等人,2023 c; Xie等人,2022年; Baek等人,2023 b; Yang等人,2023; Wang等人,2023 a; Jiang等,2023)已经探索了将知识组作为外部知识来源来减轻LLM中的幻觉。这些方法遵循一个例程:从KG中检索信息,相应地增加提示,并将增加的提示馈送到LLM中(如图1b所示)。在本文中,我们将这种范式称为“LLM KG”。虽然LLM的目标是整合LLM和KG的能力,但在该范式中,LLM扮演着翻译器的角色,将输入的问题转换成机器可理解的命令,以供KG搜索和推理,但它并不直接参与图推理过程。不幸的是,松耦合的LLM
KG范式有其自身的局限性,它的成功在很大程度上取决于KG的完整性和高质量。例如,在图1b中,尽管LLM成功地识别了回答问题所需的必要关系类型,但缺少关系“多数党”会导致检索正确答案失败。
基于这些考虑,我们提出了一个新的紧耦合的“LLMKG”范式,其中KG和LLM协同工作,在图推理的每一步中互补彼此的能力。图1c提供了一个示例,说明LLM
KG的优势。在这个例子中,在图1b中导致失败的缺失关系“多数党,”可以由具有动态推理能力的LLM代理发现的参考三元组(Australia,prime minister,Anthony Albanese)来补充(Yao等人,2022年),以及来自LLM固有知识的安东尼·艾博年的政党成员资格。以这种方式,LLM利用从KG检索到的可靠知识成功地生成正确答案。作为这一范式的一个实现,我们提出了一个算法框架“图上思考”(意思是:LLM“思考”沿着”知识“图”上的推理路径一步一步地进行,以下简称为ToG),用于深度、可靠和高效的LLM推理。在KG/LLM推理中使用波束搜索算法(Jurafsky & Martin,2009年)(Atif等人,2023年; Sun等人,2023 a; Xie等人,2023; Liu等人,2024),ToG允许LLM动态地探索KG中的多个推理路径,并相应地做出决策。给定一个输入问题,ToG首先识别初始实体,然后迭代地调用LLM,以通过探索(通过“在图上”步骤在KG中寻找相关三元组)和推理(通过“思考”步骤决定最相关的三元组)从KG中检索相关三元组,直到通过波束搜索中收集的前N个推理路径的信息以回答问题(由LLM在“思考”步骤中判断)或者达到预定义的最大搜索深度。
ToG的优点可以概括为:(1)深度推理:ToG从知识库中提取出多样的多跳推理路径,作为LLM推理的基础,增强了LLM对知识密集型任务的深度推理能力。(2)负责任的推理:显式的、可编辑的推理路径提高了LLM推理过程的可解释性,并允许对模型输出的出处进行跟踪和校正。(3)灵活性和效率:a)ToG是一种即插即用的框架,可以无缝地应用于各种LLM和KG。(b)在ToG框架下,知识更新可以通过KG来实现,而LLM的知识更新成本高、速度慢。c)ToG增强了小型LLM的推理能力(例如,LLAMA 2 - 70 B)与大型LLM(例如,GPT-4)的水平。
二、方法
ToG通过要求LLM在知识图上执行波束搜索来实现“LLMKG”范例。具体地,它提示LLM迭代地探索KG上的多个可能的推理路径,直到LLM确定可以基于当前推理路径来回答问题。ToG不断地更新和维护前N个推理路径P = {p1,p2,...,pN},其中N表示波束搜索的宽度。ToG的整个推理过程包括初始化、探索和推理3个阶段。
2.1图上思考
2.1.1图的初始化
给定一个问题,ToG利用底层LLM在知识图上定位推理路径的初始实体。该阶段可以被视为前N个推理路径P的初始化。ToG首先提示LLM自动提取所讨论的主题实体,并获得前N个主题实体的问题。注意,主题实体的数量可能小于N。
2.1.2探索
在第D次迭代开始时,每条路径由D-1个三元组组成,即,
,其中
示主体和客体实体,
是它们之间的特定关系,
和
彼此连接。
中的尾实体和关系的集合表示为
和
。
第D次迭代中的探索阶段旨在利用LLM基于问题从当前N个实体集的相邻实体中识别最相关的前N个实体
,并使用
扩展前N个推理路径P。为了解决使用LLM处理众多相邻实体的复杂性,我们实现了两步探索策略:首先,探索重要关系,然后使用所选择的关系来指导实体探索。
关系探索
关系探索是一个深度为1、宽度为N的波束搜索过程,从到
。整个过程可以分解为两个步骤:搜索和修剪。LLM作为代理自动完成此过程。
图2:ToG的示例工作流。发光的实体是每次迭代(深度)时搜索开始的中心实体,粗体的实体是修剪后下一次迭代的选定中心实体。在每个修剪步骤中,边缘的暗度表示由LLM给出的排序分数,并且虚线指示由于低评估分数而被修剪的关系。
搜索
在第D次迭代开始时,关系探索阶段首先为每个推理路径搜索链接到尾实体
的关系
。这些关系被聚合成
。在图2的情况下,
,
表示向内或向外链接到
的所有关系的集合。值得注意的是,搜索过程可以通过执行附录E.1和E.2中所示的两个简单的预定义公式查询来轻松完成,这使得ToG能够很好地适应不同的KG,而无需任何训练成本。
修剪
一旦我们已经从关系搜索中获得候选关系集和扩展的候选推理路径
,我们就可以利用LLM基于问题
的文字信息和候选关系
从
中选出以尾部关系
结尾的新的前N个推理路径P。此处使用的提示可参见附录E.3.1。如图2所示,LLM在第一次迭代中从链接到实体
的所有关系中选择前3个关系{capital of,country,territory}。由于堪培拉是唯一的主题实体,所以前3个候选推理路径被更新为{(堪培拉,首都),(堪培拉,国家),(堪培拉,领土)}。
实体探索
实体探索与关系探索类似,实体探索也是由LLM从到
执行的波束搜索过程,并且包括两个步骤,搜索和修剪。
搜索
一旦我们已经从关系探索获得了新的前N个推理路径P和新的尾关系的集合,对于每个关系路径
,我们可以通过查询
或
来探索候选实体集
,其中
表示
的尾实体和关系。我们可以聚合
扩展为
,并利用尾部实体
扩展前N条推理路径
到
。对于所示的情况,
可以表示为{Australia,Australia,澳大利亚首都直辖区}。
修剪
由于每个候选集合中的实体是用自然语言表达的,因此我们可以利用LLM来从
中选择以尾部实体
结束的新的前N个推理路径P。此处使用的提示可参见附录E.3.2。如图2所示,澳大利亚和澳大利亚首都直辖区被评分为1,因为关系capital of、country和territory仅分别链接到一个尾实体,并且当前推理路径p被更新为{(堪培拉,capital of,Australia),(Canberra,country,Australia),(堪培拉,territory,澳大利亚首都直辖区)}。
在执行上述两个探索之后,我们重新构建新的前N个推理路径P,其中每条路径的长度增加1。每个修剪步骤最多需要N个LLM调用。
2.1.3推理
在通过探索过程获得当前推理路径P后,我们提示LLM评估当前推理路径是否足以生成答案。如果评估产生了肯定的结果,我们将提示LLM使用推理路径生成答案,并将查询作为输入,如图2所示。用于评价和生成的提示可参见附录E.3.3和E.3.4。相反,如果评估产生负结果,我们会重复探索和推理步骤,直到评估为正或达到最大搜索深度Dmax。如果算法还没有结束,这意味着即使在达到Dmax时,ToG仍然不能探索推理路径来解决问题。在这种情况下,ToG仅基于LLM中的固有知识来生成答案。ToG的整个推理过程包含D个探索阶段、D个评价步骤和一个生成步骤,最多需要2ND +D + 1次对LLM的调用。
2.2基于关系的图上思考
先前的KBQA方法,特别是基于语义分析的方法,主要依赖于问题中的关系信息来生成正式查询(Lan等人,2022年)的报告。受此启发,我们提出了基于关系的ToG(ToG-R),它探索由主题实体开始的前N个关系链
,而不是基于三元组的推理路径。ToG-R在每次迭代中依次执行关系搜索、关系剪枝和实体搜索,这与ToG相同。然后,ToG-R根据实体搜索得到的所有以
结尾的候选推理路径进行推理。如果LLM确定所检索的候选推理路径不包含LLM回答问题的足够信息,则我们从候选实体
中随机采样N个实体,并继续下一次迭代。假设每个实体集合
中的实体可能属于相同的实体类并且具有相似的相邻关系,则修剪实体集合
的结果可能对随后的关系探索几乎没有影响。因此,我们使用随机波束搜索代替ToG中的LLM约束波束搜索来进行实体剪枝,称为随机剪枝。算法1和2显示了ToG和ToG-R的实现细节。ToG-R最多需要ND +D + 1个对LLM的调用。
与ToG相比,ToG-R提供了两个关键的好处:1)它消除了使用LLM修剪实体的过程的需要,从而减少了总体成本和推理时间。2)ToG-R主要强调关系的字面信息,当中间实体的字面信息缺失或不熟悉时,减轻了误导推理的风险。
三、实验
3.1实验设计
3.1.1数据集和评估指标
为了测试ToG在多跳知识密集型推理任务上的能力,我们在5个KBQA数据集(4个多跳和1个单跳)上评估了ToG:CWQ(Talmor & Berant,2018),WebQSP(Yih et al.,2016),GrailQA(顾等人,2021)、QALD 10-en(Perevalov等人,2022)、简单问题(Bordes等人,2015年)的报告。此外,为了在更一般的任务上检查ToG,我们还准备了一个开放域QA数据集:WebQuestions(Berant等人,2013);两个槽填充数据集:T-REx(ElSahar等人,2018年)和零击RE(Petroni等人,2021);以及一个事实核查数据集:Creak(Onoe等人,2021年)的报告。请注意,对于两个大型数据集GrailQA和Simple Questions,我们仅随机选择了1,000个样本进行测试,以节省计算成本。对于所有数据集,精确匹配准确度(Hitts@1)被用作我们的评估度量,遵循先前的工作(Li等人,2023 c; Baek等人,2023 b; Jiang等人,2023年; Li等人,第2023条a款)。
3.1.2选择用于比较的方法
我们与标准提示(IO提示)(Brown等人,2020 b)、思维链提示(CoT提示)(Wei等人,2022)和自我一致性(Wang等人,2023 c),具有6个上下文内的范例和“逐步”推理链。此外,对于每个数据集,我们挑选了以前的最新(SOTA)工作进行比较。我们注意到,专门针对评估的数据集微调后的方法通常在本质上比基于提示而不训练的方法具有优势,但牺牲了对其他数据的灵活性和概括性。为了公平起见,因此,我们比较了以前的SOTA中的所有基于排序的方法和以前的SOTA中的所有方法。请注意,Tan等人的论文。(2023)不参与比较,因为其结果不是基于标准精确匹配,因此不可比。
3.1.3实验细节
考虑到ToG的即插即用便利性,我们在实验中尝试了三个LLM:ChatGPT,GPT-4和Llama-2。我们使用OpenAI API调用ChatGPT(GPT-3.5-turbo)和GPT-41。Llama 2 - 70 B-Chat(Touvron等人,2023)以8 A100- 40 G运行,没有量化,其中温度参数设置为0.4用于探索过程(增加多样性),并设置为0用于推理过程(保证再现性)。生成的最大令牌长度设置为256。在所有实验中,我们将宽度N和深度Dmax都设置为3以进行波束搜索。游离碱(Bollacker等人,2008)被用作CWQ、WebQSP、GrailQA、Simple Questions和Webquestions的KG,而Wikidata(Vrande Kazci 'c & Krötzsch,2014)被用作QALD 10-en、T-REx、Zero-Shot RE和Creak的KG。我们在所有数据集的ToG推理提示中使用5个镜头。
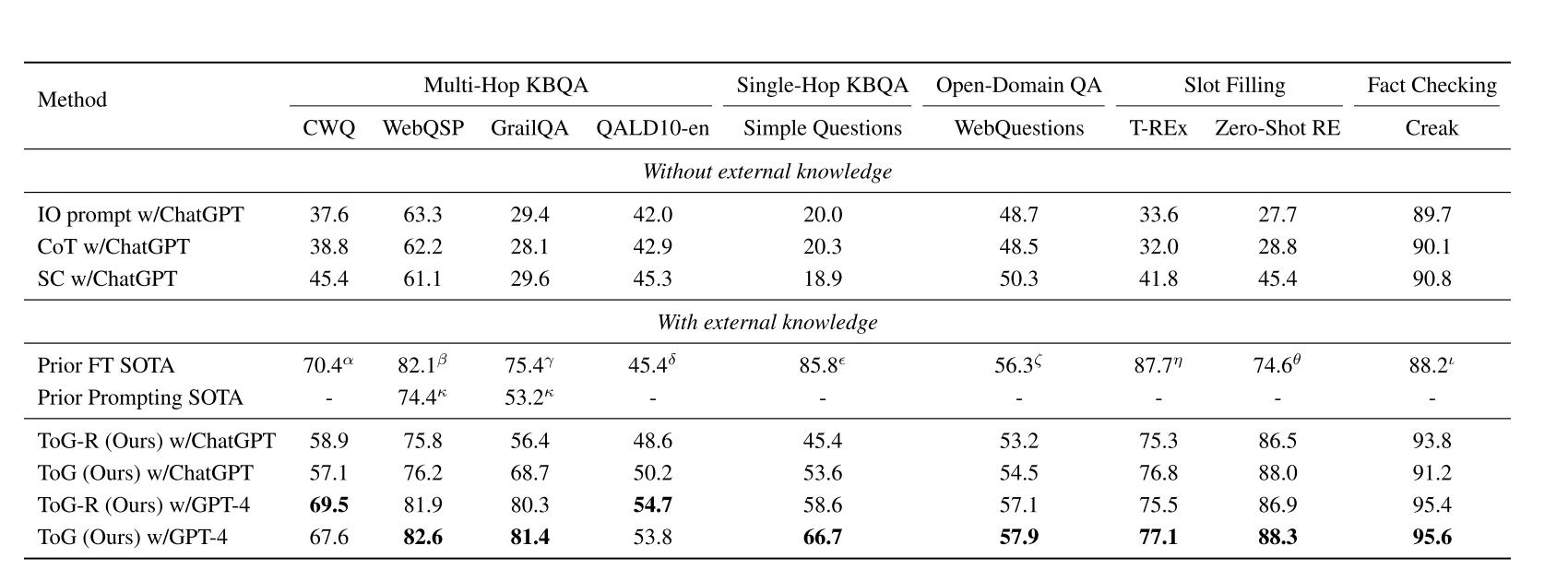
表1:不同数据集的ToG结果。前FT(微调)和提示SOTA包括最著名的结果:α:Das等人(2021); β:Yu等人(2023); γ:Gu等人(2023); δ:桑塔纳等人(2022); δ:Baek等人(2023 a); δ:Kedia等人(2022); η:Glass等人(2022); θ:Petroni等人(2021); i:Yu等人(2022); κ:Li等人(2023 a)。
3.2主要结果
3.2.1与其他方法的比较
由于CoT使用外部KG来增强LLM,我们首先将其与利用外部知识的方法进行比较。正如我们在图1中所看到的,即使ToG是一种无需训练的基于优化的方法,并且与那些使用数据进行训练以进行评估的微调方法相比具有天然的劣势,但使用GPT-4的ToG仍然在9个数据集中的6个中实现了新的SOTA性能,包括WebQSP,GrailQA,QALD 10-en,WebQuestions,Zero-Shot RE和Creak。甚至对于一些没有SOTA的数据集,例如,在CWQ,CoT的绩效已经接近SOTA(69.5%对百分之七十点四)。如果与所有基于提升的方法相比,使用GPT-4的ToG和使用ChatGPT的ToG的弱版本都能在所有数据集中赢得竞争。特别地,在开放域QA数据集WebQuestions上的1.6%的改进表明了ToG在开放域QA任务上的通用性。我们还注意到ToG在单跳KBQA数据集上的性能不如在其他数据集上的性能。这些结果表明,ToG算法在多跳数据集上具有更好的性能,支持了ToG算法增强了LLM深度推理能力的观点.
从图1中我们还可以看出,与那些没有利用外部知识的方法(如IO、CoT和SC提示方法)相比,ToG的优势更为显著。例如,在GrailQA和Zero-Shot RE上的性能分别提高了51.8%和42.9%。事实证明,在推理中,外部KG的好处是不可忽视的。
在大多数数据集上,ToG优于ToG-R,因为与ToG-R检索的关系链相比,基于三元组的推理路径提供了额外的中间实体信息。ToG生成的答案的更详细分析可在附录B.2中查看。为了更好地进行比较,在附录C中报告了每个数据集的先前方法的结果。
3.2.2不同骨干模型的性能
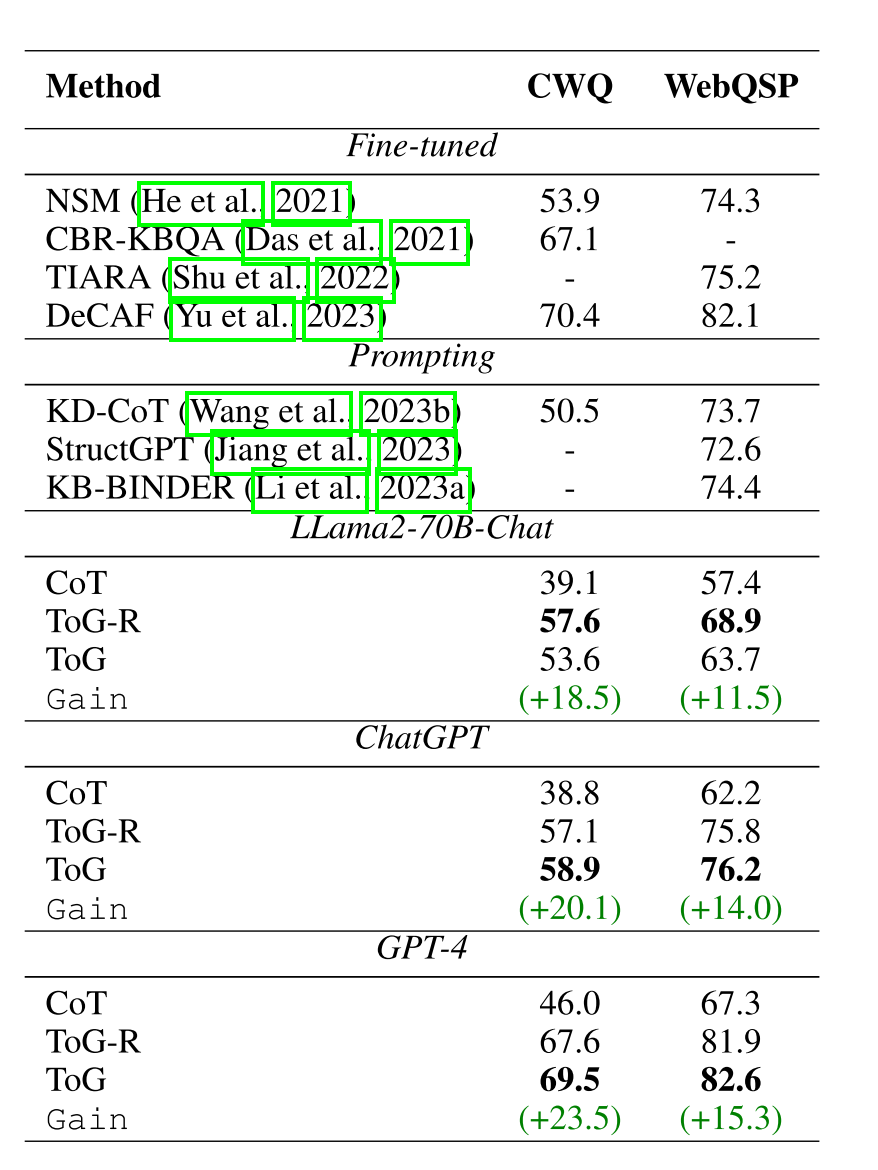
表2:在CWQ和WebQSP上使用不同骨干模型的ToG性能
考虑到ToG的即插即用的灵活性,我们在两个数据集CWQ和WebQSP上评估了不同骨干模型对其性能的影响。表2显示,正如我们预期的那样,CoT的性能随着主干模型的大小(也部分反映了推理能力)而提高(GPT-4 > ChatGPT > Llama-2)。此外,我们看到,主干模型越大,CoT和ToG之间的差距就越大(CWQ上的增益从Llama-2的18.5%增加到GPT-4的23.5%,WebQSP上的增益从Llama-2的11.5%增加到GPT-4的15.3%),这表明可以使用更强大的LLM挖掘KG的更多潜力。
此外,即使使用最小的模型Llama-2(70 B参数),ToG也优于使用GPT-4的CoT。这意味着LLM部署和应用的技术路线要便宜得多,即,具有廉价小型LLM的TOG可能是替代昂贵大型LLM的候选者,特别是在外部KG可以覆盖的垂直场景中。
3.2.3消融研究
我们进行各种消融研究,以了解不同因素在ToG中的重要性。我们对CWQ和WebQSP测试集的两个子集进行了消融研究,每个子集包含1,000个随机抽样的问题。
搜索深度和宽度对ToG重要吗?
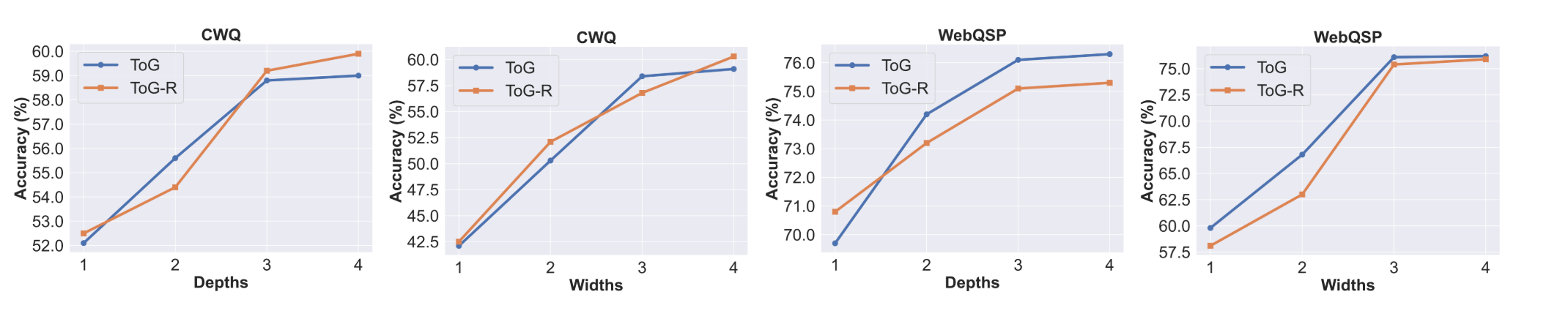
图3:不同搜索深度和宽度的ToG性能
为了探索搜索深度和波束宽度
对ToG性能的影响,我们在深度范围从1到4和宽度范围从1到4的设置下进行实验。如图3所示,ToG的性能随着搜索深度和宽度的增加而提高。这也意味着,随着勘探深度和广度的增加,ToG的性能可能会得到改善。然而,考虑到计算成本(随着深度线性增加),我们将深度和宽度都设置为3作为默认的实验设置。另一方面,当深度超过3时,性能增长减小,这主要是因为只有一小部分问题的推理深度(基于SPARQL中的关系数量,如附录中的图12所示)大于3。
不同的幼儿园是否会影响ToG的表现?
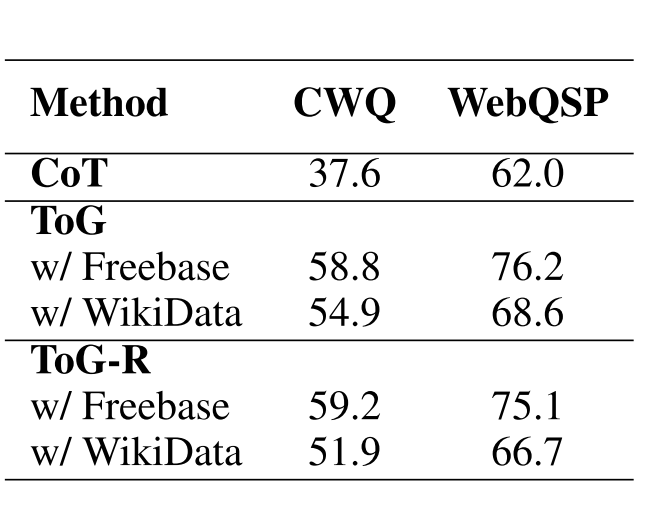
表3:在CWQ和WebQSP上使用不同源KG的ToG性能
ToG的主要优势之一是其即插即用功能。如表3所示,与CoT相比,ToG在CWQ和WebQSP上使用不同来源的KG实现了显著改进。另一方面,不同来源的KG可能对有ToG性能的不同影响。值得注意的是,Freebase对CWQ和WebQSP的改进比维基数据更显著,因为这两个数据集都是在Freebase上构建的。此外,在像Wikidata这样的大型KG中,搜索和修剪过程相对具有挑战性。
不同的提示设计如何影响ToG?
我们进行额外的实验,以确定哪些类型的提示表示可以很好地为我们的方法。结果如表4所示。“三元组”表示使用三元组格式作为提示来表示多个路径,例如“(堪培拉,首都,澳大利亚),(澳大利亚,总理,Anthony Albanese)"。“序列”是指使用序列格式,如图2所示。“句子”涉及将三元组转换为自然语言句子。例如,“(堪培拉,capital of,Australia)”可以转换为“The capital of堪培拉is Australia.“结果表明,利用三元组表示的推理路径产生了最高程度的效率和上级性能。相反,当考虑ToG-R时,每个推理路径是从主题实体开始的关系链,使其与基于三元组的提示表示不兼容。因此,将ToG-R转换为自然语言形式会导致过长的提示,从而导致性能显著下降。
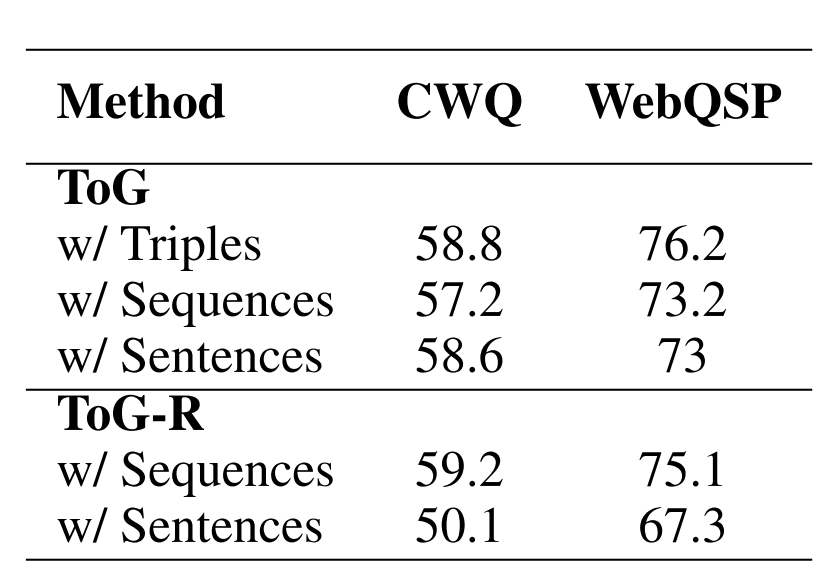
表4:使用不同提示设计的ToG性能
比较不同修剪工具的效果
除了LLM之外,可以测量文本相似性的轻量级模型(如BM25和SentenceBERT)可以在探索阶段用作修剪工具。我们可以根据与问题的字面相似性选择前N个实体和关系。我们研究了不同修剪工具对ToG性能的影响,如表5所示。用BM25或SentenceBERT替换LLM导致了我们的方法的显著性能下降。具体而言,CWQ上的结果平均下降了8.4%,而WebQSP上的结果平均下降了15.1%。实验结果表明,LLM作为剪枝工具的有效性最佳。另一方面,在使用BM25或SentenceBERT之后,我们只需要D + 1个到LLM的调用,而不是如我们在2.1.3节中讨论的2ND +D + 1个,这提高了ToG的效率。
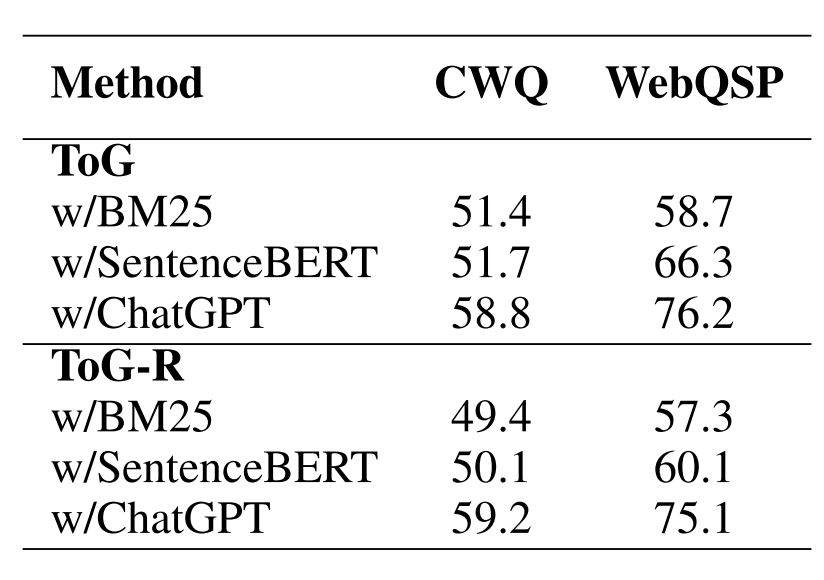
表5:使用不同修剪工具的ToG性能
我们对种子样本数量的影响以及ToG和初始射束搜索对KG的差异进行了额外的消融研究,如附录B.1所示。
3.3知识图谱中知识的可追溯性和正确性
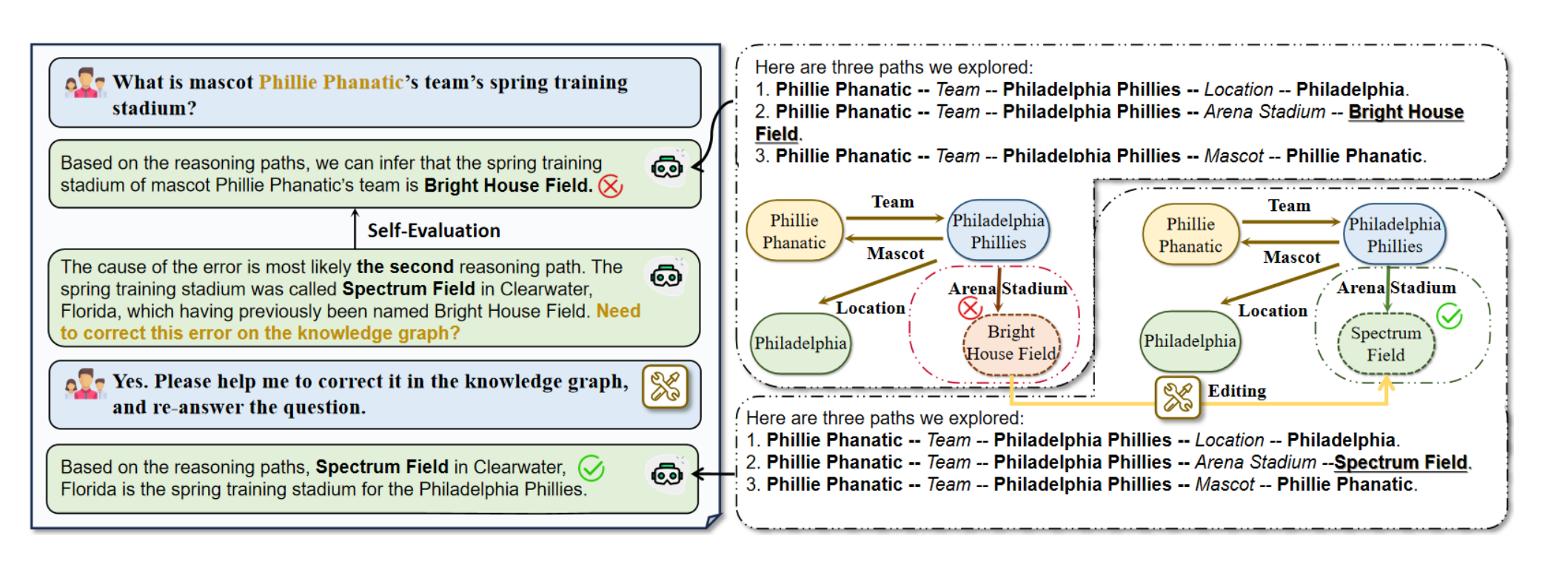
图4:ToG的知识可追溯性和可纠正性的说明
知识图谱中的质量对思维导图的正确推理至关重要。ToG的一个有趣的特性是LLM推理过程中的知识可追溯性和知识可纠正性,它提供了一种使用ToG本身来提高KG质量并降低KG构建和纠正成本的方法。如图4所示,可以向用户显示ToG的显式推理路径。如果潜在在ToG答案中的错误或不确定性被人类用户/专家或其他LLM发现时,ToG具有追溯和检查推理路径、发现具有错误的可疑三元组并纠正它们的能力。以图4中的情况为例。给定输入问题“吉祥物Phillie Phanatic的球队的春训体育场是什么?",ToG在第一轮中输出错误答案“Bright House Field”。然后ToG回溯所有的推理路径,定位错误的原因可能来自第二条推理路径(Phillie Phanatic Team − → Philadelphia Phillies竞技场Stadium −−→ Bright House Field),并分析错误来自过时的三元组(Philadelphia Phillies,竞技场Stadium,Bright House Field)中“Bright House Field”的旧名“Specturm Field”。根据ToG的提示,用户可以要求LLM更正此错误,并使用正确的信息回答相同的问题。这个例子揭示了ToG不仅用KG增强了LLM,而且用LLM改进了KG的质量,这被称为知识注入(Moiseev等人,2022年)的报告。
四、相关工作
使用LLM提示的的推理
(思维链(CoT)Wei等人,2022)已被证明在增强LLM推理方面是有效的。该方法在少次学习范式下,根据推理逻辑生成一系列的提示实例,以提高LLM在复杂任务上的表现。CoT的思想已经沿着不同的维度得到了改进,包括Auto-CoT(Zhang et al.,2022),复合物-CoT(Fu等人,2023),自我一致性(Wang等人,2023 c)、零发射CoT(Kojima等人,2022)、Iter-CoT(Sun等人,2023 b)、ToT(Yao等人,2023)、GoT(Besta等人,2023)等。鉴于所有这些工作都仅使用训练数据中的知识的局限性,最近的工作如ReAct(Yao等人,2022)试图利用来自诸如Wiki文档的外部源的信息来进一步提高推理性能。
KG-增强的LLM
KG在动态、显式和结构化知识表示方面具有优势(Pan等人,2023)并且将LLM与KG相结合的技术已经被研究了。早期的研究(Peters等人,2019年; Huang等人,2024年; Luo等人,2024; Zhang等人,2021年; Li等人,2023 b; Liu等人,2020)在预训练或微调过程中将来自知识库的结构化知识嵌入到底层神经网络中。然而,嵌入到LLM中的KG牺牲了其自身在知识推理中的可解释性和在知识更新中的效率的性质(Hu等人,2023年)的报告。
最近的工作通过将相关的结构化知识从知识库翻译成用于LLMs的文本提示来将LLMs与知识库结合起来。所有的方法都遵循一条固定的管道,从KG中检索额外的信息来扩充LLM提示符,它们属于我们在引言部分定义的LLM KG范例。另一方面,Jiang et al.(2023)要求LLM探索KG,因此它可以被视为ToG的一个特例,属于LLM
KG范式。
五、结论
我们引入了LLMKG范式,用于以紧耦合的方式集成LLM和KG,并提出了图上思维(ToG)算法框架,该框架利用LLM作为代理参与KG推理以实现更好的决策。实验结果表明,ToG优于现有的基于微调的方法和基于迭代的方法,而无需额外的训练成本,并减轻了LLM的幻觉问题。
六、鸣谢
我们衷心感谢尊敬的审稿人提供的宝贵反馈和建设性意见,这些意见对改进和完善本文做出了重大贡献。他们提出的真知灼见和对细节的细致关注,在提高我们研究工作的质量和清晰度方面发挥了关键作用。