七 模型选择与调优
1 交叉验证
(1) 保留交叉验证HoldOut
HoldOut Cross-validation(Train-Test Split)
在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集,其余30%被用作验证集。也就是我们最常使用的,直接划分数据集的方法。
优点:很简单很容易执行。
缺点1:不适用于不平衡的数据集。假设我们有一个不平衡的数据集,有0类和1类。假设80%的数据属于 “0 “类,其余20%的数据属于 “1 “类。这种情况下,训练集的大小为80%,测试数据的大小为数据集的20%。可能发生的情况是,所有80%的 “0 “类数据都在训练集中,而所有 “1 “类数据都在测试集中。因此,我们的模型将不能很好地概括我们的测试数据,因为它之前没有见过 “1 “类的数据。
缺点2:一大块数据被剥夺了训练模型的机会。
在小数据集的情况下,有一部分数据将被保留下来用于测试模型,这些数据可能具有重要的特征,而我们的模型可能会因为没有在这些数据上进行训练而错过。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
x = iris.data
y = iris.target
# Hold-Out保留交叉验证
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=1)
print(y_test)
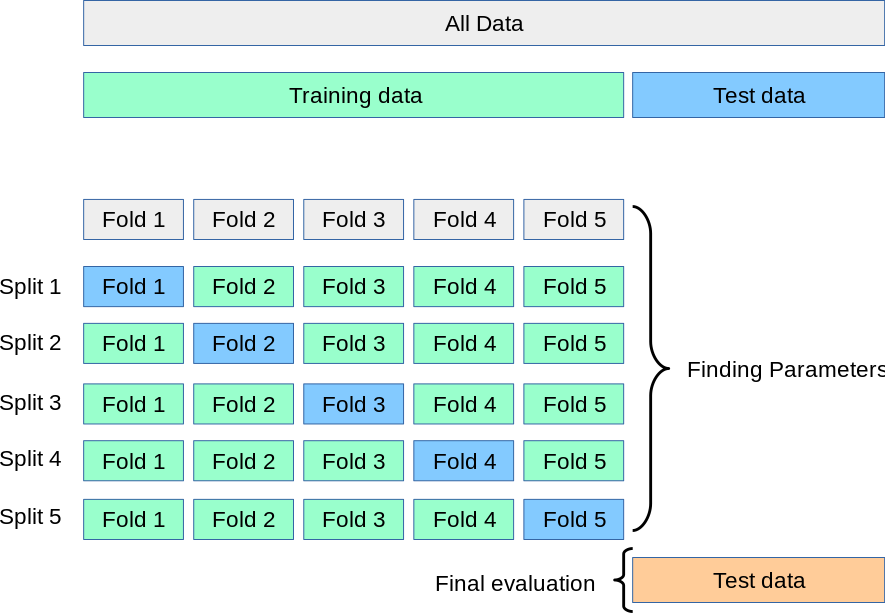
(2) K-折交叉验证(K-fold)
(K-fold Cross Validation,记为K-CV或K-fold)
K-Fold交叉验证技术中,整个数据集被划分为K个大小相同的部分。每个分区被称为 一个”Fold”。所以我们有K个部分,我们称之为K-Fold。一个Fold被用作验证集,其余的K-1个Fold被用作训练集。
该技术重复K次,直到每个Fold都被用作验证集,其余的作为训练集。
模型的最终准确度是通过取k个模型验证数据的平均准确度来计算的。
# 交叉验证
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
iris = load_iris()
x = iris.data
y = iris.target
# K-Fold 交叉验证
kf = KFold(n_splits=5,shuffle=True,random_state=1)
index = kf.split(x,y)
# print(next(index))
# print("---------------")
# print(next(index))
for train_index,test_index in index:
x_train,x_test = x[train_index],x[test_index]
y_train,y_test = y[train_index],y[test_index]
print(x_train,x_test,y_train,y_test)(3) 分层k-折交叉验证Stratified k-fold
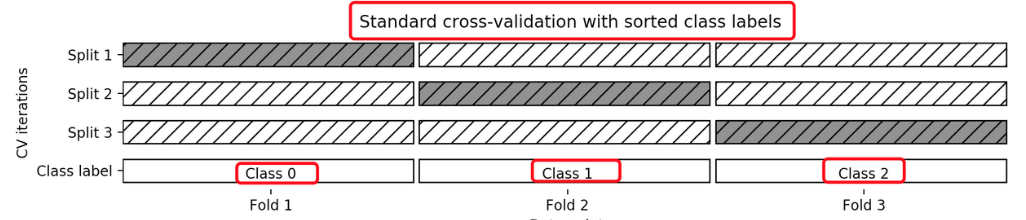
Stratified k-fold cross validation,
K-折交叉验证的变种, 分层的意思是说在每一折中都保持着原始数据中各个类别的比例关系,比如说:原始数据有3类,比例为1:2:1,采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别保持着1:2:1的比例,这样的验证结果更加可信。
# 交叉验证
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
iris = load_iris()
x = iris.data
y = iris.target
# SSK-Fold 分层k折交叉验证
kf = StratifiedKFold(n_splits=5)
index = kf.split(x,y)
# print(next(index))
# print("---------------")
# print(next(index))
for train_index,test_index in index:
x_train,x_test = x[train_index],x[test_index]
y_train,y_test = y[train_index],y[test_index]
print(x_train,x_test,y_train,y_test)
break(4) 其它验证
去除p交叉验证) 留一交叉验证) 蒙特卡罗交叉验证 时间序列交叉验证
(5)API
from sklearn.model_selection import StratifiedKFold
说明:普通K折交叉验证和分层K折交叉验证的使用是一样的 只是引入的类不同
from sklearn.model_selection import KFold
使用时只是KFold这个类名不一样其他代码完全一样
strat_k_fold=sklearn.model_selection.StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
n_splits划分为几个折叠 shuffle是否在拆分之前被打乱(随机化),False则按照顺序拆分 random_state随机因子
indexs=strat_k_fold.split(X,y)
返回一个可迭代对象,一共有5个折叠,每个折叠对应的是训练集和测试集的下标
然后可以用for循环取出每一个折叠对应的X和y下标来访问到对应的测试数据集和训练数据集 以及测试目标集和训练目标集
for train_index, test_index in indexs:
X[train_index] y[train_index] X[test_index ] y[test_index ]
2 超参数搜索
超参数搜索也叫网格搜索(Grid Search)
比如在KNN算法中,k是一个可以人为设置的参数,所以就是一个超参数。网格搜索能自动的帮助我们找到最好的超参数值。

3 sklearn API
class sklearn.model_selection.GridSearchCV(estimator, param_grid)
说明:
同时进行交叉验证(CV)、和网格搜索(GridSearch),GridSearchCV实际上也是一个估计器(estimator),同时它有几个重要属性:
best_params_ 最佳参数
best_score_ 在训练集中的准确率
best_estimator_ 最佳估计器
cv_results_ 交叉验证过程描述
best_index_最佳k在列表中的下标
参数:
estimator: scikit-learn估计器实例
param_grid:以参数名称(str)作为键,将参数设置列表尝试作为值的字典
示例: {"n_neighbors": [1, 3, 5, 7, 9, 11]}
cv: 确定交叉验证切分策略,值为:
(1)None 默认5折
(2)integer 设置多少折
如果估计器是分类器,使用"分层k-折交叉验证(StratifiedKFold)"。在所有其他情况下,使用KFold。
4 示例-鸢尾花分类
用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
# 用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
def knn_iris_gscv():
# 1)获取数据
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)KNN算法预估器, 这里就不传参数n_neighbors了,交给GridSearchCV来传递
estimator = KNeighborsClassifier()
# 加入网格搜索与交叉验证, GridSearchCV会让k分别等于1,2,5,7,9,11进行网格搜索偿试。cv=10表示进行10次交叉验证
estimator = GridSearchCV(estimator, param_grid={"n_neighbors": [1, 3, 5, 7, 9, 11]}, cv=10)
estimator.fit(x_train, y_train)
# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("在测试集中的准确率为:\n", score) #0.9736842105263158
# 最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_) #{'n_neighbors': 3}, 说明k=3时最好
# 最佳结果:best_score_
print("在训练集中的准确率:\n", estimator.best_score_) #0.9553030303030303
# 最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_) # KNeighborsClassifier(n_neighbors=3)
# 交叉验证结果:cv_results_
print("交叉验证过程描述:\n", estimator.cv_results_)
#最佳参数组合的索引:最佳k在列表中的下标
print("最佳参数组合的索引:\n",estimator.best_index_)
#通常情况下,直接使用best_params_更为方便
return None
knn_iris_gscv()
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
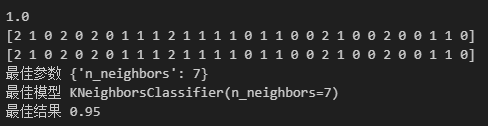
# 超参数搜索
x,y = load_iris(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=0)
# 创建knn模型
knn_model = KNeighborsClassifier(n_neighbors=7)
model = GridSearchCV(knn_model,param_grid={'n_neighbors':[3,4,5,6,7]},cv=5)
model.fit(x_train,y_train)
score = model.score(x_test,y_test)
print(score)
y_pred = model.predict(x_test)
print(y_pred)
print(y_test)
print("最佳参数",model.best_params_)
print("最佳模型",model.best_estimator_)
print("最佳结果",model.best_score_)