MYSQL 索引与数据结构笔记
文章目录
1. B-Tree 与 B+ Tree 基础对比
- B-Tree(平衡树)
- 每个节点既存储 键(Key),也存储 实际数据(Data)。
- 查找时从根节点(Root)开始,沿着指针遍历至叶节点(Leaf),每次节点访问都可能触发一次磁盘 I/O。
- 特点:小的键在左,大的键在右,定位单条记录的最坏深度与树高成正比。
- B+ Tree(平衡树加强版)
- 非叶子节点 只存储 键,不存储数据;所有数据集中存放于 叶子节点。
- 叶子节点之间通过双向链表相连,支持范围查询时从起始叶节点依次遍历,无需回到根节点重复搜索。
- 由于非叶子节点仅存键,可在同页面存储更多索引,树更“宽”、高度更浅,减少索引查找的磁盘 I/O 次数。
以上图示直观对比了两者的结构差异:
- B-Tree 左侧,内外节点均存数据;
- B+ Tree 右侧,内部节点只有键,叶子通过链表横向连接。
B 树相比其他数据结构为何更快?B 树又如何进一步提升性能?
一、B 树的优势
- 高扇出(Fan-out)、低高度
- B 树的每个节点(页面)可以包含 m 个子指针和 m–1 个关键字,通常 m 很大(几百到上千),因为页面大小(如 16 KB)可容纳大量记录指针。
- 相比二叉搜索树(每节点仅 2 个子指针),B 树树高明显更低:
高度 ≈ log m N ≪ log 2 N \text{高度} \approx \log_{m}N \ll \log_{2}N 高度≈logmN≪log2N - 结果:每次查询只需少量层次的磁盘 I/O。
- 磁盘友好:“页面+批量读写”
- 节点大小与磁盘块(页面)大小匹配,一次 I/O 就能读取或写入一个完整节点。
- 大量连续指针和键值在同一页面中,最大化单次 I/O 的有效数据利用率。
- 动态平衡
- B 树在插入/删除时始终保持平衡,无需昂贵的旋转操作(区别于 AVL、红黑树)。
- 分裂/合并操作较少,且都局限在少数相邻节点,引发的页面写回有限。
- 支持范围查询(部分)
- 虽非链表连接,B 树也能通过中序遍历叶子节点进行范围扫描,复杂度 O ( log m N + K ) O(\log_m N + K) O(logmN+K),其中 K 是返回行数。
二、B 树的进一步优化
在 B 树基础上,B+ 树对 I/O 和范围查询做了两点关键改进:
- 非叶子节点只存“路由键”
- B 树:每个节点都存键+数据指针。
- B+ 树:
- 内部节点:仅存 键 和子指针,页内可容纳更多分支,进一步提升扇出 m m m。
- 叶子节点:存所有 键 + 数据指针。
- 好处:更宽的树 → 更浅的树 → 更少层级 I/O。
- 叶子节点双向链表
- 所有叶子通过指针串联,形成线性链表。
- 范围查询:
- 定位首条记录( log m N \log_m N logmN 次 I/O)。
- 顺链遍历后续叶子页,每页一次 I/O,即可连续获取大量记录,无需再回到根节点。
- 预取优化:操作系统或 InnoDB 可预测地提前读取下几页,减少读取延迟。
三、综合对比
| 特性 | 二叉树 / AVL / 红黑树 | B 树 | B+ 树 |
|---|---|---|---|
| 树高 | Θ ( log 2 N ) \Theta(\log_2 N) Θ(log2N) | Θ ( log m N ) \Theta(\log_m N) Θ(logmN) | Θ ( log m N ) \Theta(\log_m N) Θ(logmN)(更小) |
| 每层 I/O | 1 个节点(小) | 1 个大页面 | 1 个更大分支数大页面 |
| 插入/删除 | 旋转、重染色开销大 | 分裂/合并局部节点 | 同 B 树,节点更少分裂 |
| 范围查询 | 需要中序多次回溯 | 叶子遍历可中序,但无链表需回根 | 首查后链表顺序遍历,高效顺序读取 |
| 磁盘利用率 | 无页面概念,非批量 I/O | 每页批量 | 同 B 树,更多指针→更高页面利用率 |
结论
- B 树 相比纯内存二叉结构,更贴合磁盘 I/O 模型:高扇出、低树高、少 I/O。
- B+ 树 在此基础上:
- 更高扇出(节点更“瘦”),进一步压低树高;
- 链表化叶子,极大优化范围扫描和预取,减少随即 I/O。
这种设计正好契合数据库对“大量数据+高并发读写+范围查询”场景的需求,因而被广泛采用,MySQL InnoDB 默认索引即基于 B+ 树。
2. MySQL 为何选择 B+ Tree
更少的磁盘 I/O
- 叶子节点更集中,树高度更低。
- 访问任意数据最多经过 ⌈ log m N ⌉ \lceil \log_{m}N\rceil ⌈logmN⌉层,且每层页面能存更多指针。
高效的范围查询
- 双向链表链通所有叶节点。
- 查询
[low, high]时,从根定位low,再顺链查到high,无需多次回根。
页面利用更高
- 非叶子节点仅存键,单页指针更多。
- 更少分裂、重平衡次数,维护成本更低。
3. 索引使用示例与性能分析
假设有如下测试表:
CREATE TABLE t_demo (
id_int INT NOT NULL PRIMARY KEY,
id_char CHAR(10),
INDEX idx_char (id_char)
);
INDEX / KEY
- 在 SQL 标准中,
INDEX用于指示“给某列建立额外的索引结构”;MySQL 中INDEX和KEY同义。 - 作用:加速基于该列的查找(
=、IN)、排序(ORDER BY)、范围扫描(BETWEEN、>、<)等操作。 - 类型:
- 普通索引(Secondary Index):如上例
idx_char,只存列值 + 聚簇主键,用于辅助查找。 - 唯一索引(UNIQUE INDEX):加上
UNIQUE关键字,保证列值不重复。 - 全文索引(FULLTEXT):用于自然语言全文检索。
- 空间索引(SPATIAL):针对 GIS 数据。
- 普通索引(Secondary Index):如上例
idx_char
这是索引的名字,必须在同表内唯一。
建议命名习惯:
idx_<列名>或idx_<表名>_<列名>,便于维护和阅读。用途示例:
SHOW INDEX FROM t_demo; -- 你会看到一个名为 idx_char 的索引,Column_name: id_char DROP INDEX idx_char ON t_demo;
聚簇索引 vs 辅助索引
- 聚簇索引(Clustered Index)
- 由 InnoDB 强制由主键构建。
- 叶子节点直接存放整行数据(行记录)。
- 辅助索引(Secondary Index)
- 叶子节点只存「索引列值 + 主键列值」。
- 查到主键后,再回聚簇索引查整行。
3.1 整数字段索引查询
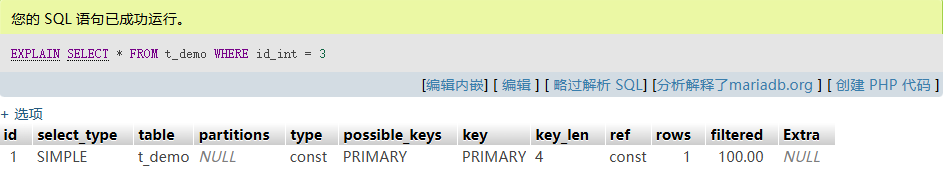
EXPLAIN SELECT * FROM t_demo WHERE id_int = 3;
- Output:
key: PRIMARY, rows: 1 - 利用聚簇索引,直接定位叶节点,一个 I/O 即可返回数据。
EXPLAIN用于让 MySQL 优化器输出该查询的“执行计划”,常见字段:
| 列名 | 含义 |
|---|---|
id |
查询标识,表示第几条子查询或联合查询 |
select_type |
查询类型,如 SIMPLE(简单查询)、PRIMARY、SUBQUERY 等 |
table |
本行描述的是哪张表 |
type |
访问类型,从好到差:system / const / eq_ref / ref / range / ALL |
possible_keys |
优化器认为可用的索引列表 |
key |
实际使用的索引 |
key_len |
使用索引的字节长度 |
ref |
哪个列或常量与索引列比较 |
rows |
估算需要扫描的行数 |
filtered |
估算有多少百分比的行会被 WHERE 过滤 |
Extra |
额外信息,如 Using index(覆盖索引)、Using filesort、Using temporary 等 |
3.2 字符字段索引查询
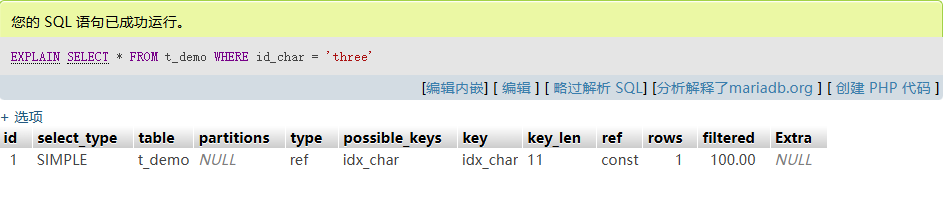
EXPLAIN SELECT * FROM t_demo WHERE id_char = 'three';
- Output:
key: idx_char, rows: 1 - 较整型略慢,但依然通过二分定位叶节点和链表读取。
4. 索引失效与类型转换陷阱
当对 索引字段 应用函数或运算时,会导致 MySQL 无法利用索引,转而全表扫描,示例如下:
EXPLAIN SELECT * FROM t_demo WHERE id_int + 0 = 1;
-- key: NULL, rows: 全表扫描

原因:
- 聚簇索引的页内顺序被打乱,MySQL 无法在叶节点上直接比较。
- 索引失效后,每行先转换再比较,磁盘 I/O 和 CPU 转换开销剧增。
最佳实践
避免在 WHERE 条件中对索引列进行任何运算或类型转换。
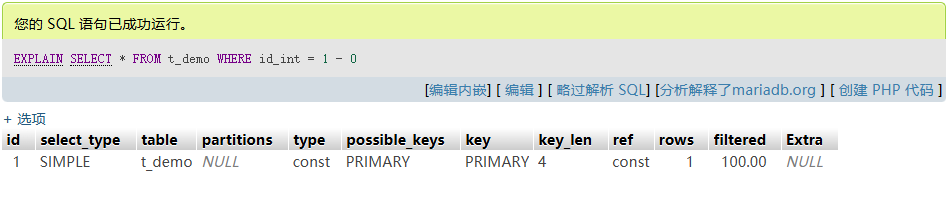
如需偏移量查询,可将常量移至列右侧:
-- 建议 SELECT * FROM t_demo WHERE id_int = 1 - 0; -- 避免 SELECT * FROM t_demo WHERE id_int + 0 = 1;对于范围查询(如
BETWEEN、>、<),只要不对字段本身改动,即可走范围索引。
5. 小结
- B+ Tree:MySQL 默认索引结构,专为大规模数据检索优化。
- 范围查询:链表加速,极大提升大数据下的连续扫描性能。
- 索引失效:对索引列的任何计算或类型转换都会导致全表扫描,严重影响性能。