 一、引言
一、引言
在人工智能技术飞速发展的今天,客服机器人已成为企业提升服务效率的重要工具。然而,传统客服系统在多轮对话连贯性和精准回复能力上存在明显短板。检索增强生成(Retrieval-Augmented Generation, RAG)技术通过结合大语言模型(LLM)与外部知识库,为解决这一问题提供了创新路径。本文将深入探讨 RAG 在客服机器人中的应用,重点分析其如何实现多轮对话与精准回复,并结合实际案例与技术框架展开讨论。
二、RAG 技术原理与核心优势
2.1 技术架构解析
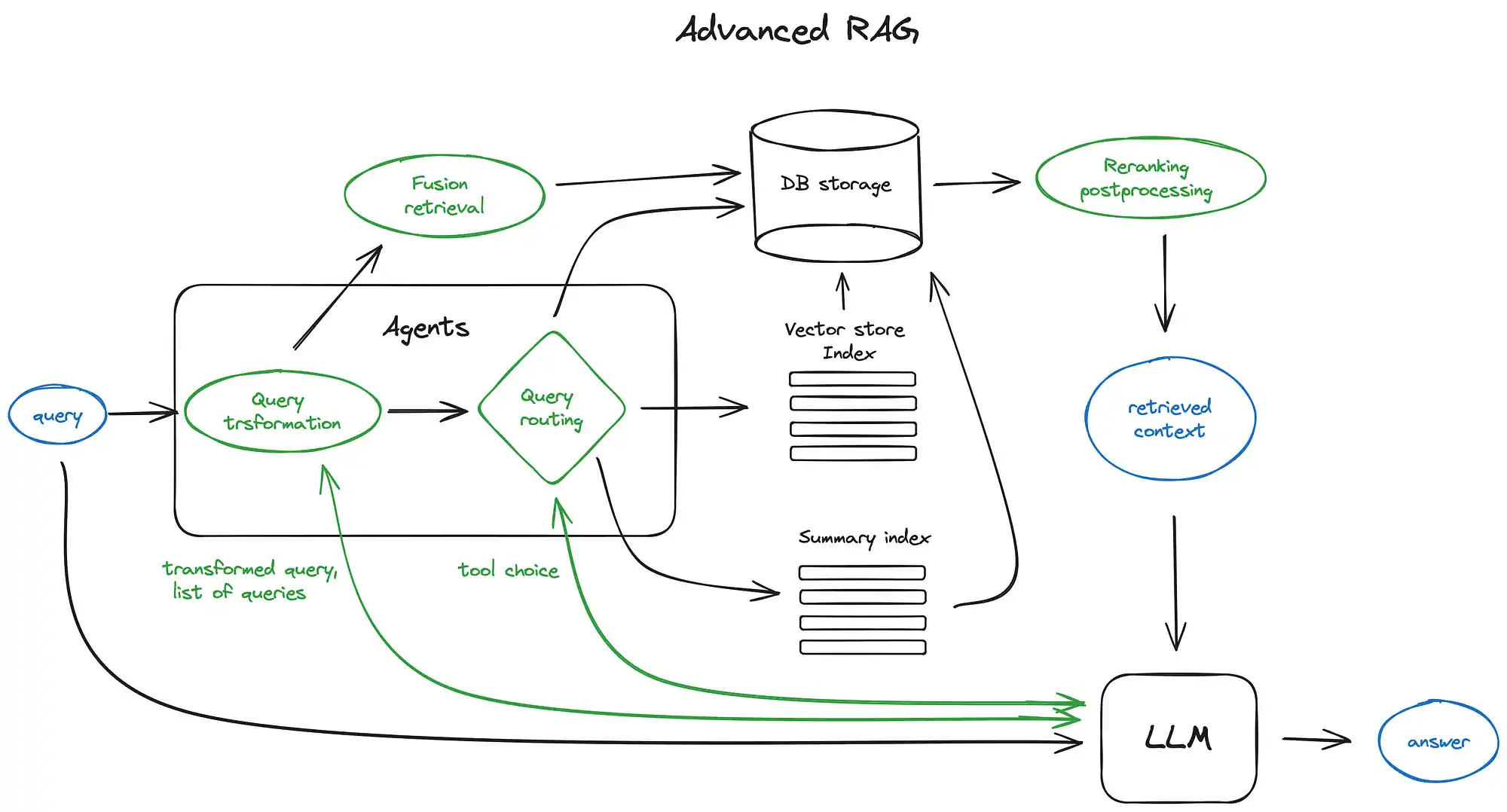
RAG 系统的核心流程可分为三个阶段:
- 检索阶段:通过向量数据库(如 Milvus、Faiss)对用户查询进行语义匹配,从知识库中提取相关文档片段。
- 生成阶段:将检索结果与用户查询结合,通过 LLM 生成自然流畅的回复。
- 反馈优化:通过用户反馈和评估指标(如 Groundedness、Completeness)迭代优化系统。
以火山引擎的 RAG 解决方案为例,其通过 “检索 - 生成 - 溯源” 机制,将用户问题与企业知识库动态关联,确保回复的准确性和可追溯性。
2.2 核心优势
- 降低幻觉风险:通过实时检索外部知识,避免 LLM 生成无依据的内容。
- 提升时效性:支持知识库动态更新,适用于政策变化、产品更新等场景。
- 多轮对话能力:通过上下文记忆模块,系统可理解多轮对话中的隐含需求,如东航客服机器人自动识别旅客未明示的特殊服务需求。
三、多轮对话的实现与优化
3.1 上下文管理技术
- 序列模型应用:LSTM、GRU 等模型可捕捉对话历史中的语义依赖,例如在技术支持场景中记住用户问题背景,确保回复一致性。
- 增量式更新机制:每次对话后动态更新上下文,避免信息过时。例如在电商场景中,根据用户最新选择调整推荐策略。
- 树形结构检索:RAPTOR 方法通过递归摘要和树形组织,从长文档中快速提取关键信息,提升复杂场景下的上下文处理效率。
3.2 多轮对话案例
东航的 RAG 客服系统通过 “多轮对话记忆与场景理解模块”,可处理航班异常、携带宠物等复杂问询。系统在对话中自动关联业务规则,效率提升数十倍。某保险客户通过 RAG 技术承接 30% 的咨询问题,显著改善了多轮对话体验。
四、精准回复的技术路径
4.1 检索优化策略
- 混合检索:结合关键词匹配(BM25)与语义检索(DPR),平衡精度与召回率。例如在医疗场景中,通过混合检索快速定位相关病例和治疗方案。
- 重新排序:使用 RankGPT 等模型对检索结果进行二次排序,确保最相关文档优先被 LLM 处理。
- 查询扩展:通过同义词和概念扩展丰富查询语义,例如将 “AI 在医疗中的应用” 扩展为 “健康科技”“机器学习” 等相关术语。
4.2 生成优化方法
- 提示工程:设计结构化提示引导模型输出,例如在法律咨询中明确要求引用具体法律条款。
- 多步推理:将复杂问题分解为子任务,逐步检索和生成答案。例如在电商客服中,先查询订单状态,再结合促销规则生成回复。
- 幻觉控制:通过检索内容约束生成,例如在金融场景中强制模型基于最新财报数据回答。
五、技术框架与工具链选择
5.1 主流框架对比
| 框架 | 核心优势 | 适用场景 |
|---|---|---|
| LangChain | 灵活的工具链集成与动态组合能力 | 快速原型开发、复杂逻辑处理 |
| Haystack | 企业级部署优化与多模态支持 | 医疗、法律等专业领域 |
| DSPy | 声明式编程与自动化优化 | 数学推理、多模态检索 |
例如,LangChain 的ConversationalRetrievalChain可快速搭建多轮对话系统,而 Haystack 的 K8s 支持适合高并发场景。
5.2 向量数据库选型
- Milvus:高性能分布式架构,支持多语言语义检索,适用于跨国企业知识库。
- Elasticsearch:结合关键词与向量检索,适合混合搜索场景。
- RDS PostgreSQL:通过向量扩展插件实现低成本知识存储,适合中小规模应用。
六、实施挑战与解决方案
6.1 知识库管理
- 大规模数据处理:采用语义切块(Chunking)和增量更新策略,例如阿里云 PAI 支持分块大小和重叠量配置,优化检索效率。
- 实时性要求:通过消息队列(如 Kafka)实现知识库变更的实时同步,确保回复内容的时效性。
6.2 多语言支持
- 统一语义空间:使用 m3e 等多语言 Embedding 模型,将不同语言文本映射到同一向量空间,实现跨语言检索。例如,火山引擎的多语言 RAG 系统支持中英日三语问答,准确率提升显著。
- 动态语言切换:在提示词中明确要求统一输出语言,例如强制模型以中文回答所有问题,避免语言混乱。
6.3 性能优化
- 缓存机制:对高频查询结果进行缓存,减少 LLM 调用次数。例如 Haystack 的缓存模块可降低 30% 的响应时间。
- 模型压缩:通过量化和剪枝技术优化 Embedding 模型,例如 DSPy 使用 T5-base 实现与 GPT-3.5 相当的性能,成本降低 60%。
七、评估与持续优化
7.1 核心指标
- 准确性:通过 Precision@K、MAP 等指标评估检索结果质量。
- 响应时间:要求客服场景中平均延迟低于 2 秒。
- 用户满意度:通过 NPS(净推荐值)和对话流畅度评分衡量体验。
7.2 优化方法
- A/B 测试:对比不同检索策略(如混合检索 vs. 密集检索)的效果,选择最优方案。
- 反馈闭环:收集用户反馈并自动标注错误案例,定期微调检索器和生成器。
八、未来趋势与展望
8.1 技术创新
- 校正型 RAG:引入评估器实时检查检索结果,自动触发重新检索,提升准确性。
- 自我反思型 RAG:通过 “检索器 - 评审器 - 生成器” 协同,实现动态调整检索策略。
- Fast GraphRAG:基于知识图谱的检索技术,支持超大规模数据集的高效处理。
8.2 应用扩展
- 多模态客服:整合图像、语音等非结构化数据,例如通过图片识别自动解答产品问题。
- 个性化服务:结合用户画像和历史对话,提供定制化回复,例如金融客服根据用户风险偏好推荐产品。
九、结论
RAG 技术通过融合检索与生成能力,为客服机器人的多轮对话和精准回复提供了革命性解决方案。从东航的业务手册整合到火山引擎的多语言实践,RAG 已在多个领域验证了其价值。随着技术的不断演进,RAG 将进一步提升客服系统的智能化水平,成为企业数字化转型的核心驱动力。开发者可结合 LangChain、Haystack 等框架,灵活选择向量数据库和优化策略,构建高效可靠的 RAG 客服系统。