李宏毅机器学习ML课程学习笔记
Some proper nouns(according to the function)
- Regression: outout a scalar. (eg. temperature)
- Classification: given options, and the function outputs the correct one. (eg. chess)
- Structured Learing: create something with structure. (eg. image)
Other nouns (field in ML)
- update: consider the loss process, we need to devide the parameters to many batches, we call the renew of one batch a update;
- epoch: see all the batches once.
- hyperparameter: like learning rate η \eta η, the parameters that ourselves defined.
- overfitting problem: the problems that good in trainning date but bad in predicte date
The process of predict unknow parameters (TRAIN)
We select the linear model to explain.
First step:
- Linear Model: y = b + w x 1 y = b + wx_1 y=b+wx1
- w: weight
- b: bias
- lable (the ture number): y ˆ \^{y} yˆ
Second step:
- define loss: L(b, w) = 1 N ∑ n = 1 N e n \frac{1}{N}\sum_{n=1}^N e_n N1∑n=1Nen,
- normally, e = ∣ y − y ˆ ∣ e = |y - \^{y}| e=∣y−yˆ∣, L is MAE, normal used;
- normally, e = ( y − y ˆ ) 2 e = (y - \^{y})^2 e=(y−yˆ)2, L is MSE
- we need to optimize loss.
- Error Surface: a contour map with w is x-axis, b is y-axis.
The third step: optimization
- w ∗ , b ∗ = a r g m i n w , b L w^*, b^* = arg min_{w,b}L w∗,b∗=argminw,bL
- 解释:在数学优化中,arg min 表示使函数达到最小值时的变量取值. eg. ( arg , min , F(x, y) ) 表示当 ( F(x, y) ) 取得最小值时,变量 ( x, y ) 的取值.
- we use Gradient Descent to optimize, now we only consider one prameter w w w to show the process.
pick a random initial value w 0 w_0 w0,
compute ∂ L ∂ w ∣ w = w 0 \frac{\partial L}{\partial w}|_{w = w_0} ∂w∂L∣w=w0, then w 1 w_1 w1 ← \leftarrow ← w 0 w_0 w0 - η ∂ L ∂ w ∣ w = w 0 \eta \frac{\partial L}{\partial w}|_{w = w_0} η∂w∂L∣w=w0.
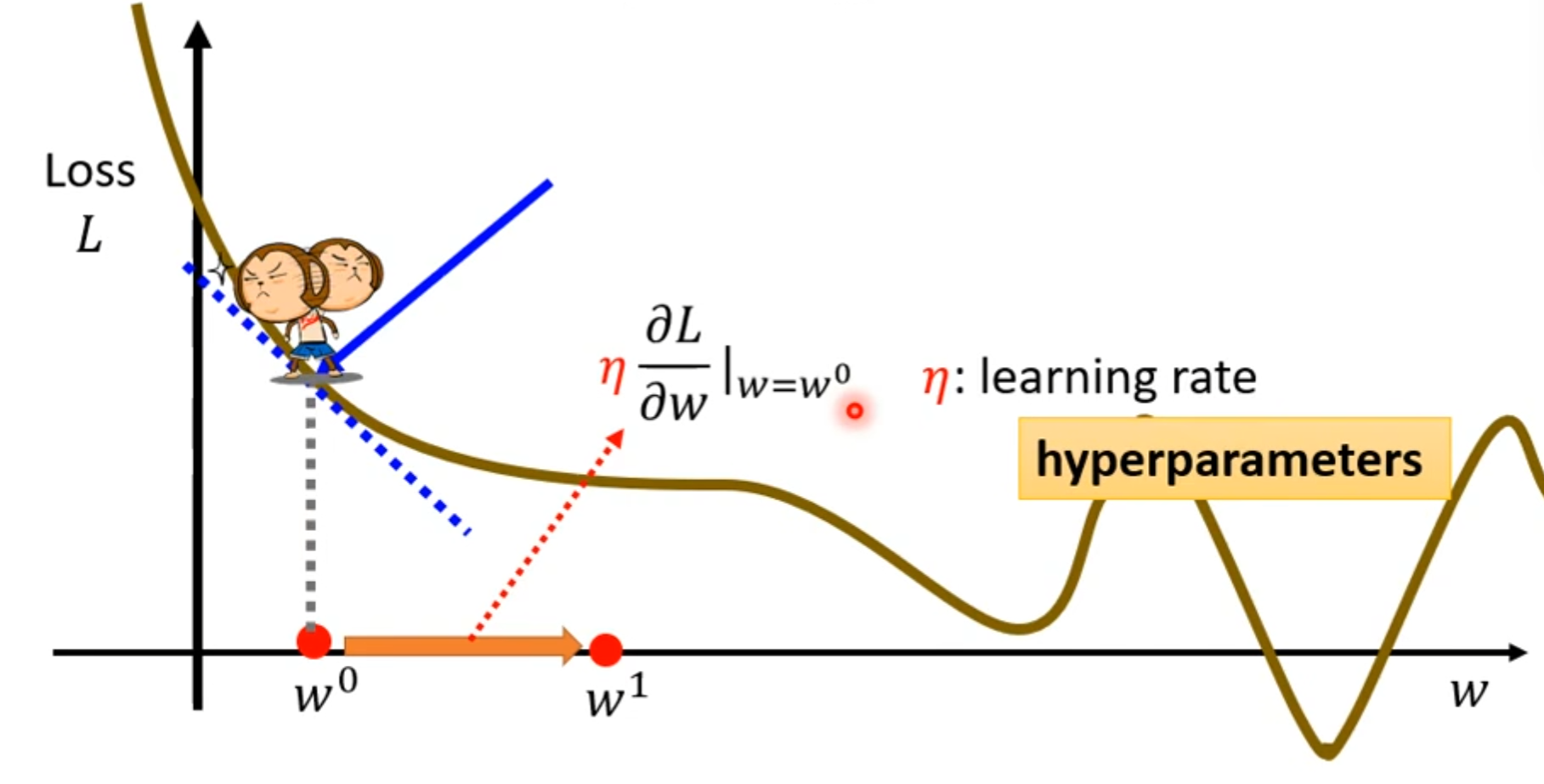
update w iteratively.
noticed that the gradient descent will cause the problem of local minima, but it's not the main problem.
The condition of other models (Activation function/ Neuron/ Hidden Layer)
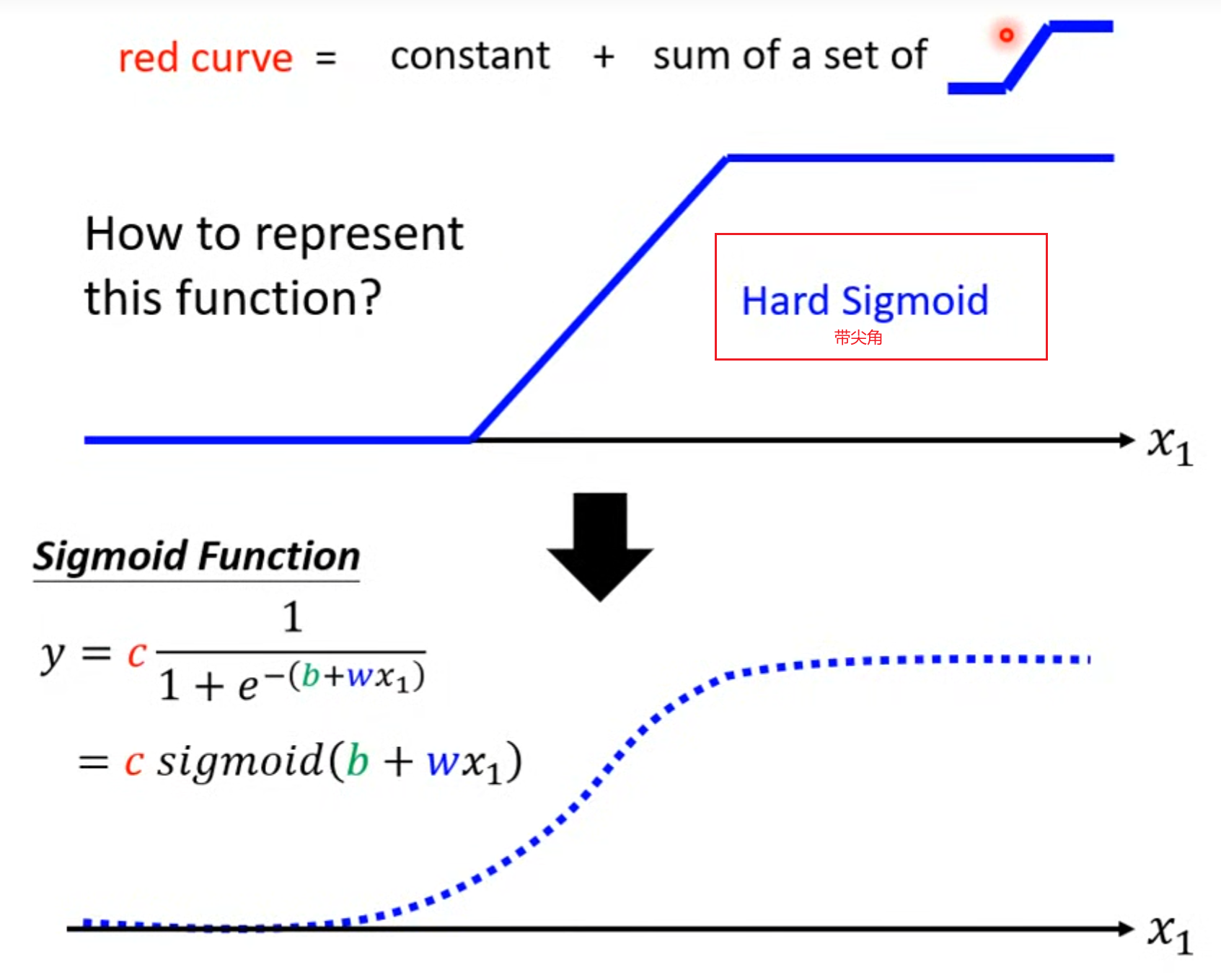
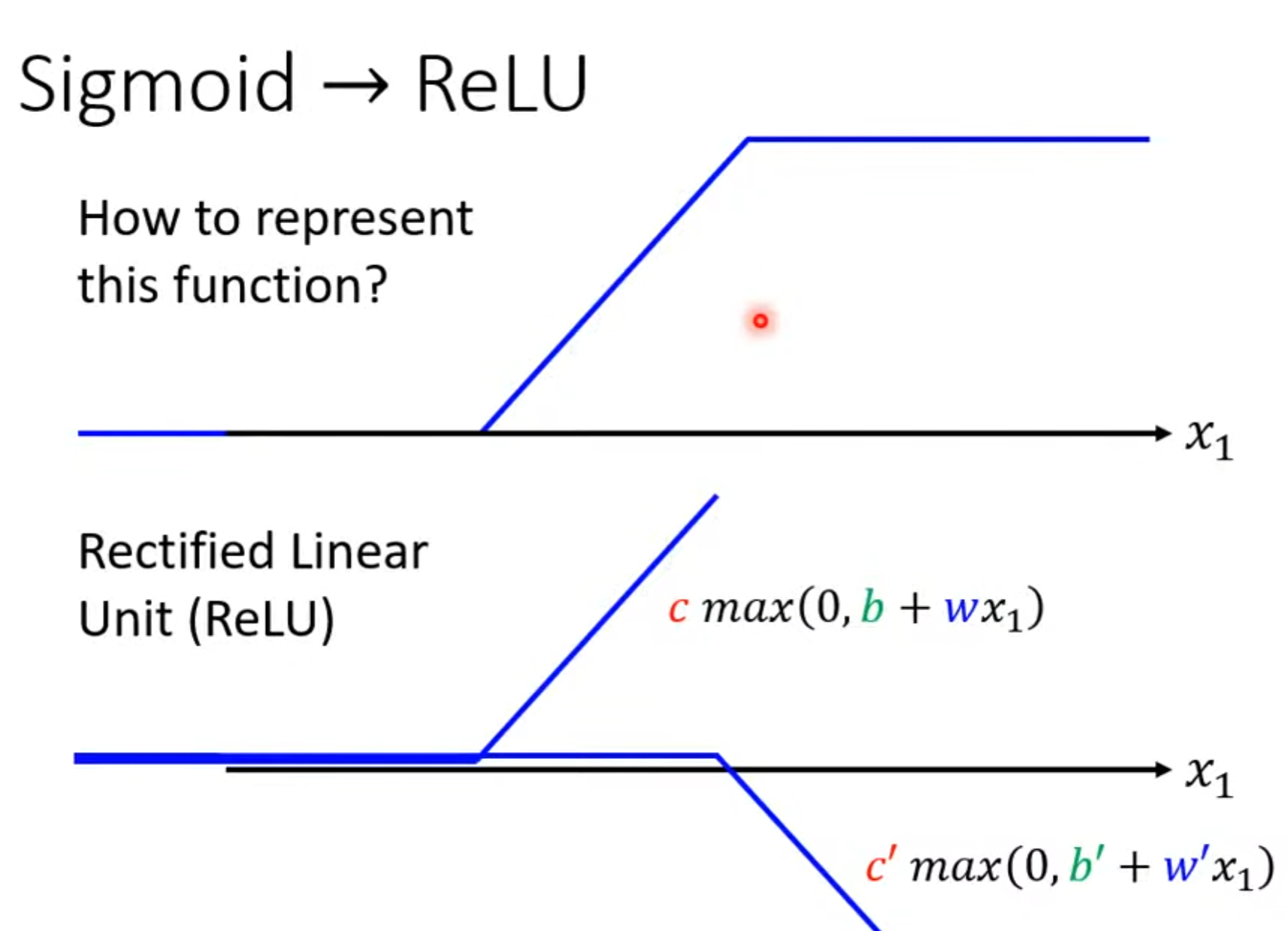
- piecewise linear model = constant + sum of a set of linear model
- y =
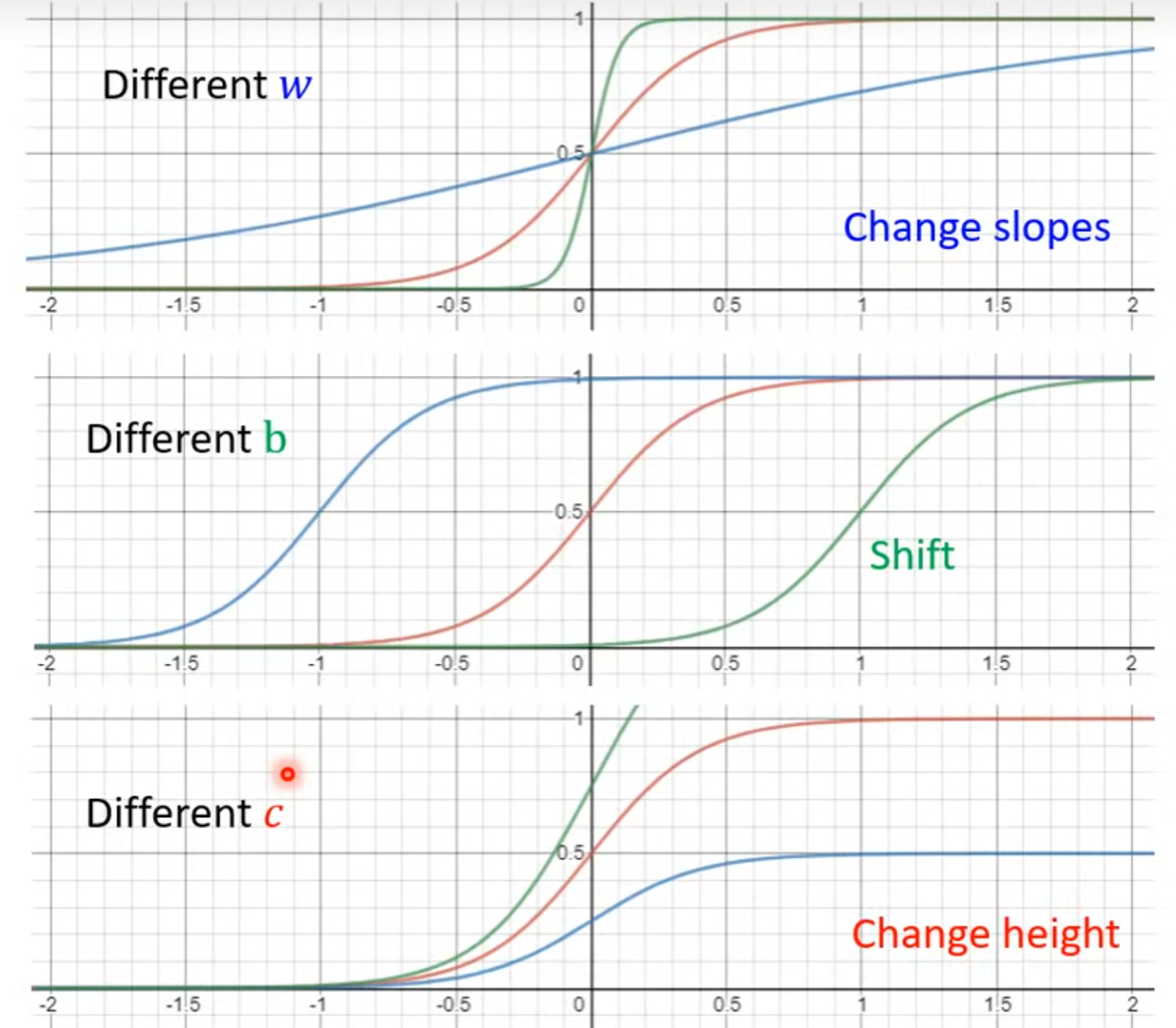
cs i g m o i d ( b + w x 1 ) sigmoid(b + w x_1) sigmoid(b+wx1) =c1 1 + e − ( b + w x 1 ) \frac{1}{1 + e^{-(b + wx_1)}} 1+e−(b+wx1)1the featueres of the sigmoid function:
- ReLu: rectified linear unit
ATTENTION 1
- About the parameters:
- model parameters
- hyperparameters: such as learning rate η \eta η (in the loss process)
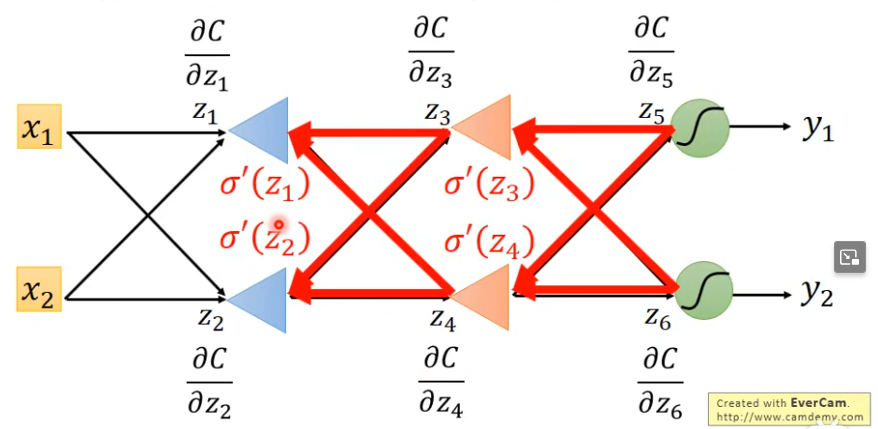
Backpropagation
- an efficient way to compute ∂ L ∂ θ \frac{\partial L}{\partial \theta} ∂θ∂L. (actually is ∇ \nabla ∇)
- Chain rule
- generally, we have ∂ L ( θ ) ∂ w \frac{\partial L(\theta)}{\partial w} ∂w∂L(θ) = ∑ n = 1 N \sum_{n = 1}^N ∑n=1N ∂ C n ( θ ) ∂ w \frac{\partial C^{n}(\theta)}{\partial w} ∂w∂Cn(θ), where C means one batch of all θ s \theta s θs, so next we should only consider one ∂ C n ( θ ) ∂ w \frac{\partial C^{n}(\theta)}{\partial w} ∂w∂Cn(θ).
- for one neuron, we have z = x 1 w 1 + x 2 w 2 + b z = x_1w_1 + x_2w_2 + b z=x1w1+x2w2+b
- we have ∂ C ∂ w \frac{\partial C}{\partial w} ∂w∂C = ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z × \times × ∂ C ∂ z \frac{\partial C}{\partial z} ∂z∂C=
forward pass× \times ×backword pass forward pass: ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z = dummy inputs (intuitively obtained )backword pass: ∂ C ∂ z \frac{\partial C}{\partial z} ∂z∂C = ∂ a ∂ z \frac{\partial a}{\partial z} ∂z∂a × \times × ∂ C ∂ a \frac{\partial C}{\partial a} ∂a∂C= σ ′ ( z ) [ w 3 ∂ C ∂ z ′ + w 4 ∂ C ∂ z ′ ′ ] \sigma'(z)[w_3\frac{\partial C}{\partial z'} + w_4\frac{\partial C}{\partial z''}] σ′(z)[w3∂z′∂C+w4∂z′′∂C]- ∂ a ∂ z \frac{\partial a}{\partial z} ∂z∂a can be intuitively obtained from the above analysis.
- ∂ C ∂ a \frac{\partial C}{\partial a} ∂a∂C = ∂ C ∂ z ′ \frac{\partial C}{\partial z'} ∂z′∂C × \times × ∂ z ′ ∂ a \frac{\partial z'}{\partial a} ∂a∂z′ + ∂ C ∂ z ′ ′ \frac{\partial C}{\partial z''} ∂z′′∂C × \times × ∂ z ′ ′ ∂ a \frac{\partial z''}{\partial a} ∂a∂z′′ (the number of z’/z’/… depend on the number of the neurons) = ∂ y 1 ∂ z ′ \frac{\partial y_1}{\partial z'} ∂z′∂y1 × \times × ∂ C ∂ y 1 \frac{\partial C}{\partial y_1} ∂y1∂C × \times × ∂ z ′ ∂ a \frac{\partial z'}{\partial a} ∂a∂z′ + ∂ y 2 ∂ z ′ ′ \frac{\partial y_{2}}{\partial z''} ∂z′′∂y2 × \times × ∂ C ∂ y 2 \frac{\partial C}{\partial y_2} ∂y2∂C × \times × ∂ z ′ ′ ∂ a \frac{\partial z''}{\partial a} ∂a∂z′′ (if the layers is end)