实现顺序查找表
1.上机名称
实现顺序查找表
顺序查找表的基本概念
顺序查找表是一种线性数据结构,通常用于存储一组元素。这些元素在表中按顺序排列,查找操作通过逐个比较表中的元素来实现。顺序查找表适用于小规模数据或不需要频繁查找的场景。顺序查找表的特点
顺序查找表的主要特点是其简单性和直接性。由于元素是按顺序存储的,查找操作需要从表的一端开始,逐个比较元素,直到找到目标元素或遍历完整个表。这种查找方式的时间复杂度为 O(n),其中 n 是表中元素的数量。顺序查找表的实现
顺序查找表可以通过数组或链表来实现。数组实现的顺序查找表在内存中是连续存储的,而链表实现的顺序查找表则通过指针链接各个元素。
顺序查找表的优缺点
顺序查找表的优点是实现简单,插入操作的时间复杂度为 O(1)。缺点是查找操作的时间复杂度较高,为 O(n),尤其是在数据量较大的情况下,查找效率较低。顺序查找表的应用场景
顺序查找表适用于数据量较小、查找操作不频繁的场景。例如,在小型缓存系统或简单的任务队列中,顺序查找表可以提供足够的性能。顺序查找表的优化
为了提高顺序查找表的查找效率,可以采用一些优化策略,如将频繁访问的元素移动到表的前面,或者使用二分查找等更高效的查找算法。然而,这些优化通常需要额外的存储空间或更复杂的数据结构。
2.上机要求
(1)实现无序的顺序查找表,实现插入键值对、按照关键字查询、删除记录等操作
(2)实现有序的顺序查找表,实现插入键值对、按照关键字查询、删除记录等操作
3.上机环境
visual studio 2022
Windows11 家庭版 64位操作系统
4.程序清单(写明运行结果及结果分析)
4.1 程序清单
4.1.1 头文件
#pragma once
#include<iostream>
#include<string>
#define MAX_LEN 64
using namespace std;
//在此项目里,默认采用从大到小的排序顺序
typedef std::string Key; //键
typedef std::string Value; //值
enum Type {
_ORDER, DIS_ORDER
};
//Node结构体包含两个成员变量:key和val,分别用于存储键和值。
struct Node{
Key key;
Value val;
};
class Record {
public:
Record(int flag); //用于初始化Record对象,flag表示记录是有序还是无序。
~Record();
void push(Key key, Value val); //用于将键值对添加到记录中。
void search(Key key); //用于查找指定键的记录。
void search(); //用于交互式查找记录。
void erease(Key key); //用于删除指定键的记录。
void printinfo(int i); //用于打印指定索引的记录信息。
void searchkey(int low, int high, Key key);//用于在指定范围内查找键。
void view(); //用于查看所有记录。
int getsize(); //用于获取当前记录的数量。
private:
Node* base; //基址
int curlen; //现有长度
int maxlen; //空间尺度
int flag; //标记是无序还是有序
};
4.1.2 实现文件
#include "Sq_Search.h"
Record::Record(int flag){
this->curlen = 0;
this->maxlen = MAX_LEN;
this->base = new Node[maxlen];
memset(base, 0, sizeof(base));
this->flag = flag;
}
Record::~Record(){
delete[]base;
this->curlen = 0;
this->maxlen = 0;
}
void Record::push(Key key, Value val){
if (curlen + 1 > maxlen) {
Node* fresh = new Node[maxlen * 2];
maxlen *= 2;
memset(fresh, 0, sizeof(fresh));
for(int i =0;i<curlen;i++){
fresh[i].key = base[i].key;
fresh[i].val = base[i].val;
}
delete[]base;
base = fresh;
}
switch (flag){
case _ORDER: {
int i = 0;
while (base[i].key.compare(key) > 0&&i<curlen) i++;
int cord = i;
for (i = curlen; i > cord && i > 0; i--) {
base[i] = base[i - 1];
}
base[cord].key = key;
base[cord].val = val;
++curlen;
break;
}
case DIS_ORDER: {
base[curlen].key = key;
base[curlen].val = val;
++curlen;
break;
}
default: {
cout << "No Type!" << endl;
exit(1);
break;
}
}
}
void Record::search(Key key){
switch (flag){
case _ORDER: {
searchkey(0,curlen-1,key);
break;
}
case DIS_ORDER: {
int i = 0;
while (i < curlen && base[i].key.compare(key))i++;
if (i == curlen)cout << "Can't find key!" << endl;
else printinfo(i);
break;
}
default:exit(3);
break;
}
}
void Record::search(){
cout << "please enter a key to search>>" << endl;
string str;
cin >> str;
search(str);
}
void Record::erease(Key key){
int i = 0;
while (i < curlen && base[i].key.compare(key))i++;
if (i == curlen)cout << "Can't find key!" << endl;
else {
for (int j = i; j < curlen; j++) {
base[j].key = base[j + 1].key;
base[j].val = base[j + 1].val;
}
--curlen;
cout << "Erease " << key << ">>" << endl;
}
}
void Record::printinfo(int i){
cout << base[i].val << endl;
}
void Record::searchkey(int low, int high,Key key){
int mid = (low + high) / 2;
if (mid >= high && base[mid].key.compare(key)) { cout << "Can't find key!" << endl; return; }
if ( base[mid].key.compare(key) == 0) { printinfo(mid); return; }
if ( base[mid].key.compare(key) < 0) { searchkey(low, mid - 1, key); }
if ( base[mid].key.compare(key) > 0) { searchkey(mid + 1, high, key); }
}
void Record::view(){
for (int i = 0; i < curlen; i++) {
cout <<base[i].key<<"\t--\t";
printinfo(i);
}
}
int Record::getsize(){
return curlen;
}
4.1.3 源文件
#include"Sq_Search.h"
int main() {
Record order = Record(_ORDER);
Record disorder = Record(DIS_ORDER);
order.push("hello", "你好");
order.push("world", "世界");
order.push("push", "插入");
order.push("int", "整型");
order.push("max", "最大");
order.push("min", "最小");
order.push("float", "浮点型");
disorder.push("hello", "你好");
disorder.push("world", "世界");
disorder.push("push", "插入");
disorder.push("int", "整型");
disorder.push("max", "最大");
disorder.push("min", "最小");
disorder.push("float", "浮点型");
cout << "view order:\n";
order.view();
cout << "view disorder:\n";
disorder.view();
order.search("hello");
disorder.search("world");
order.erease("hello");
order.view();
order.search();
}
4.2 实现展效果示
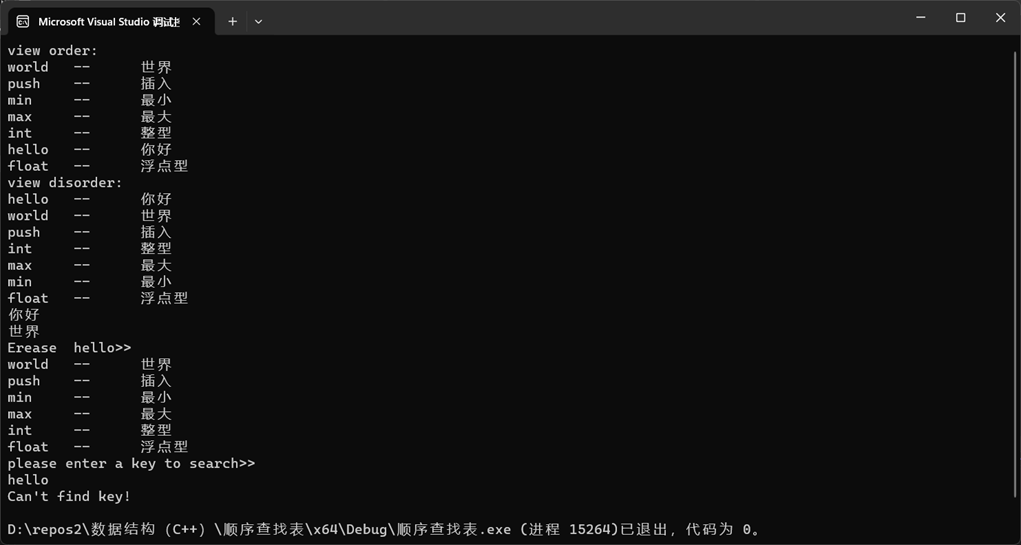
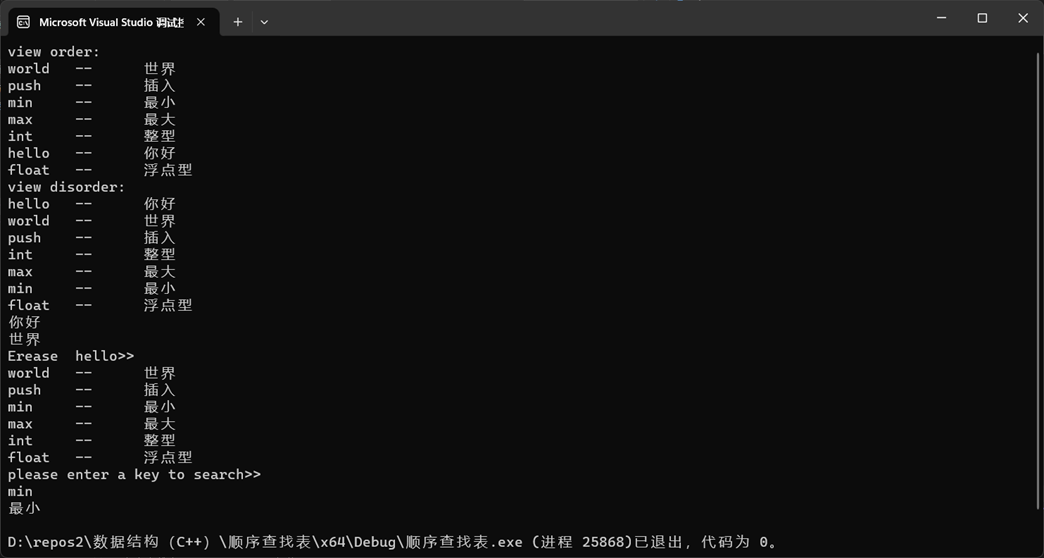
上机体会
通过这次实验,我深刻认识到理论知识和实践经验的重要性。在实现顺序查找表的过程中,我不仅掌握了基本的算法知识,还学会了如何优化代码以提高性能。此外,通过对比不同查找方法,我了解了各种方法的优缺点,为未来的应用开发提供了参考。
尽管顺序查找表在某些场景下仍有应用价值,但在大规模数据集上,其性能表现并不理想。因此,在实际应用中,我们需要根据具体需求选择合适的查找方法。对于需要频繁查找的数据,可以考虑使用哈希查找等高效算法。而对于只需在小规模数据上完成简单查找的任务,顺序查找表仍是一种简单、可靠的选择。
在无序查找表中,查找时间复杂度为O(n),在有序查找表中,查找时间复杂度为O(log n)对于数据量大的情况,显然有序表更占优势。