
引言
架构思维:通用架构模式_从设计到代码构建稳如磐石的系统
架构思维:通用架构模式_稳如老狗的SDK设计最佳实践
我们以“防备上游、做好自己、怀疑下游”的准则,分别从系统设计、部署和代码层面,介绍了如何构建高可用后台系统。但再完善的防护也难保万无一失,真正的挑战在于在用户感知之前,第一时间发现问题。
接下来我们将从监控的角度出发,教你如何设计微服务监控,帮助快速、自动地暴露故障,保障系统稳定运行。
什么是监控
监控是指对系统运行状态数据持续审查,并设定阈值,对超出阈值的指标发出告警的机制。如下所示,监控数据通常以 时间(X 轴) 与 指标值(Y 轴) 的曲线图形式展示:
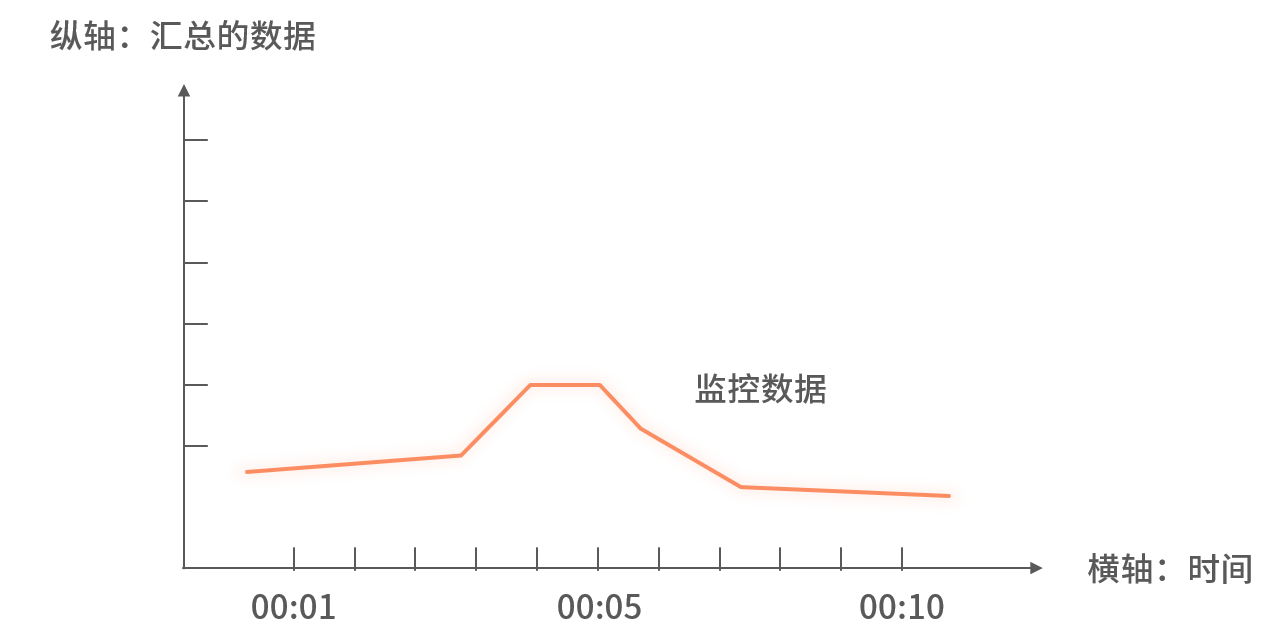
X 轴:时间间隔(秒或分钟)
Y 轴:该间隔内汇聚的指标(数量、平均值、最大值等)
三大常见监控类型
1. 次数监控
用于统计某个事件或方法的调用次数,比如接口被调用次数、某段逻辑执行次数。
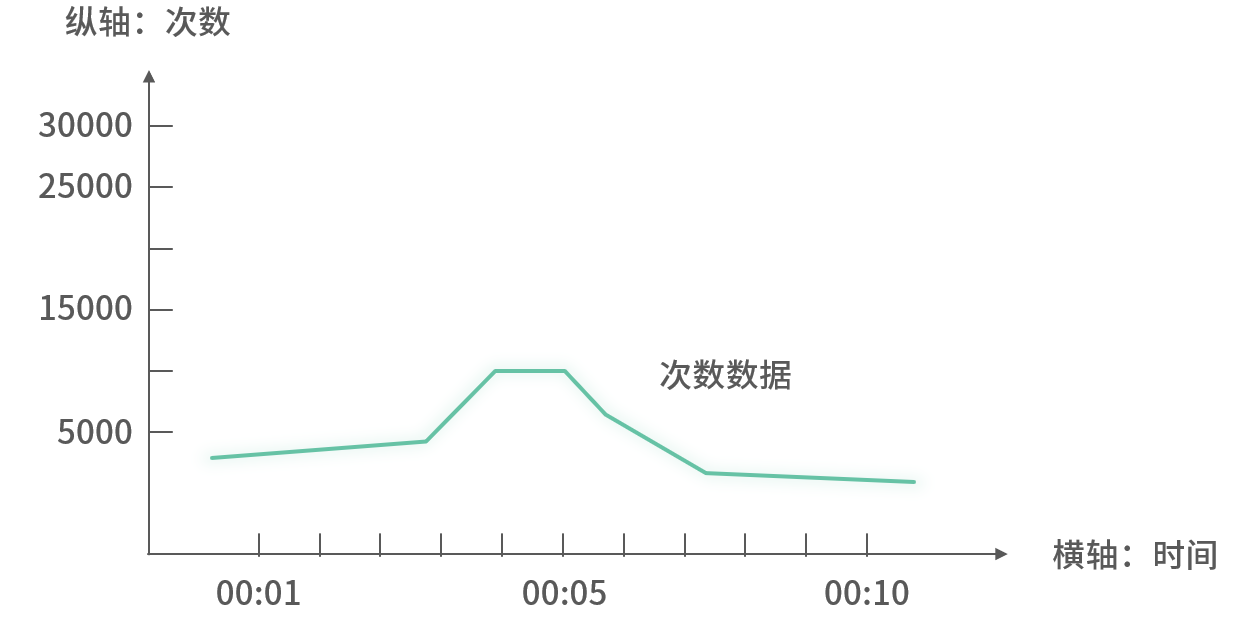
图 2:次数监控示例
Y 轴:指定间隔内总调用次数
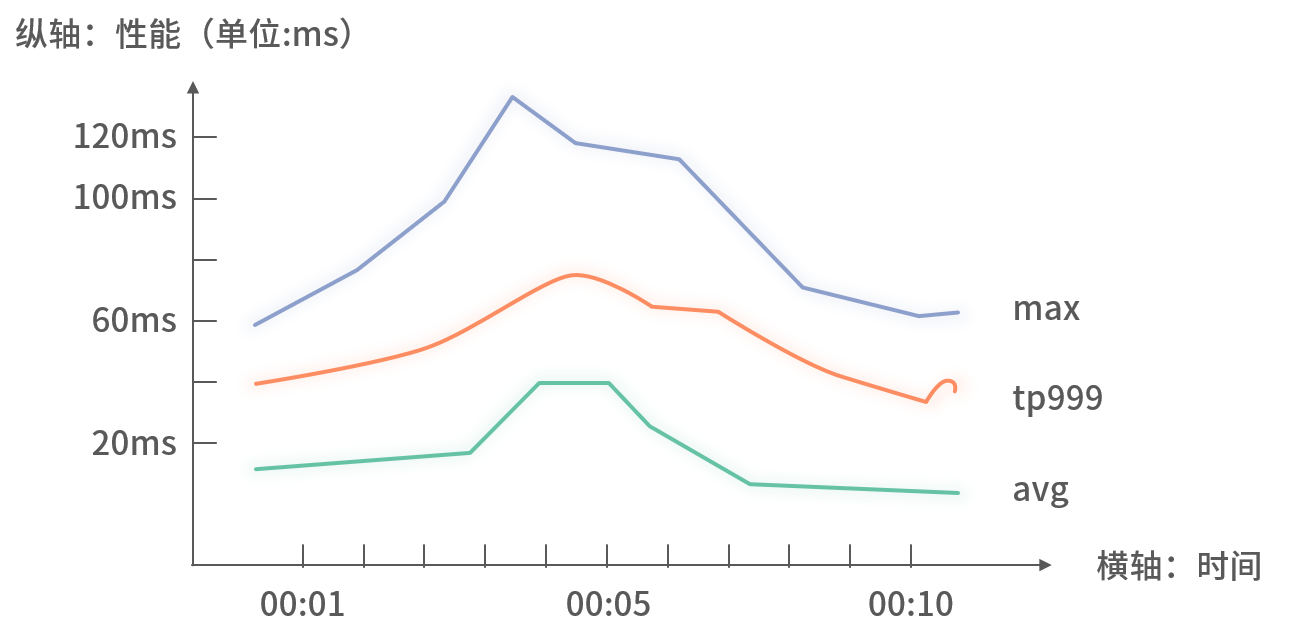
2. 性能监控
关注接口或依赖调用的延迟,常用指标有:
- 平均耗时(AVG) = 总耗时 / 调用次数
- 最大耗时(Max) = 区间内单次最长耗时
- TPn(如 TP999)= 排序后第 n‰ 位置的耗时值
通常将 Avg、Max、TP99X 三者合并展示:
3. 可用率监控
计算指定区间内业务执行成功的比例。
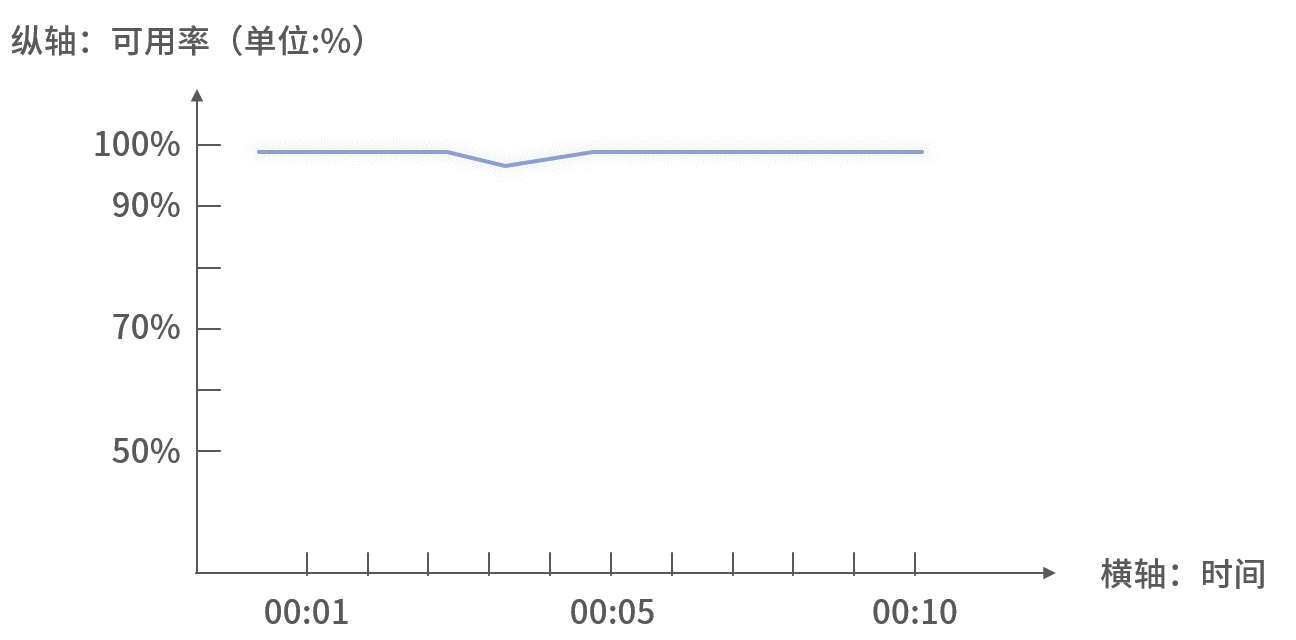
在可用率判断中,要区分:
- 业务异常(如参数校验失败):不算失败,不降可用率
- 非业务异常(如网络超时、空指针):算失败,需降可用率并报警
阈值设置需结合接口级别和 SLA,核心接口可设 100%,其他接口可适当放宽。
落地监控
业务
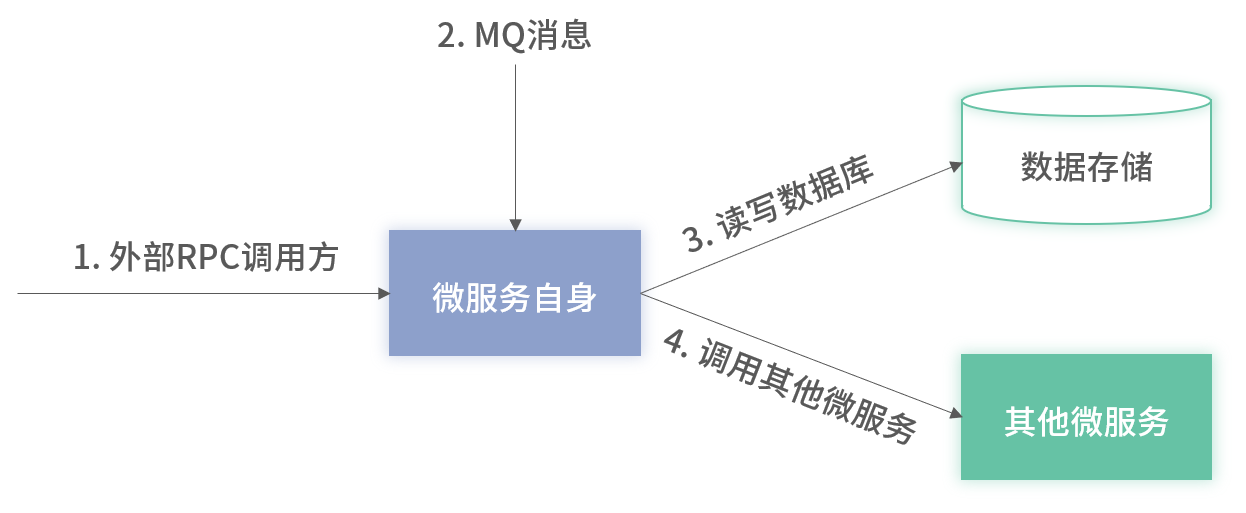
1. 服务入口
次数监控
- 基于压测瓶颈设阈值告警,并配合限流
- 按调用方维度统计,快速定位流量异常来源
- 同环比监控,自动识别突增
性能监控
- 必要时只告警 Avg、Max、TP999(或 TP9999)
- 按调用方分层监控,排查使用差异
- 基于入参(如批量大小)分段监控,辅助优化策略
可用率监控
- 接口级与调用方级双重告警
- 按业务/非业务异常判定成功与否
- 阈值分级:重要接口近乎 100%,普通接口可降至 95%
2. 服务内部
- 聚焦核心与可疑方法,避免监控点过多导致告警疲劳
- 监控 JVM(Young/Full GC、堆内存使用)、RPC 线程池剩余数、进程存活状态
- 机器层面:CPU、内存使用率与负载(Load)监控
3. 服务依赖
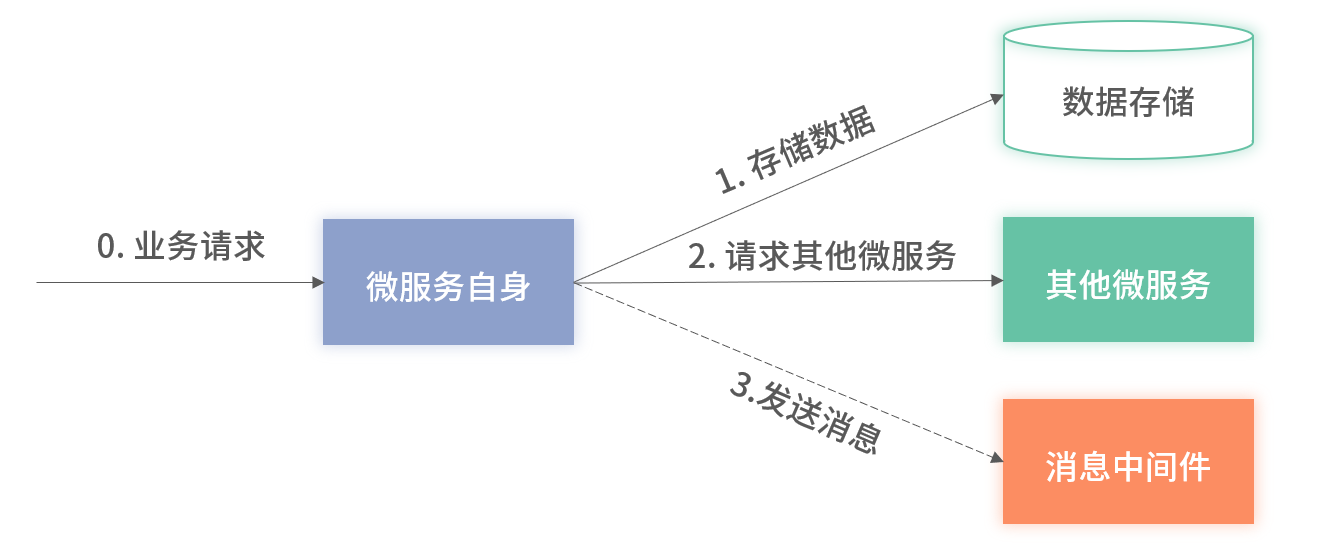
- 对每个下游依赖统一埋点监控(可用率、性能、次数)
- 注意解析 RPCResult 等包装返回,防止“隐性”失败漏报
- Java 应用可通过 AOP 或框架拦截(如 MyBatis Interceptor)统一实现
监控时间间隔的取舍
- 秒级监控最优,能最快暴露故障
- 但存储成本高(1s 数据量是 1min 的 60 倍)
- 若系统同时支持秒级和分钟级,生产环境推荐秒级,测试或存储受限时可降至分钟级
小结
- 三大基础指标:次数、性能、可用率
- 三层架构落地:入口、内部、依赖
- 补充监控:JVM、线程池、进程、机器资源
- 阈值与时序:结合 SLA、接口重要度,优先秒级
