文章目录
前言
按照笔者之前的行业经验, 数据集的整理是非常重要的, 因此笔者这里增加原文中出现的几个数据集和环境的学习
1 BridgeData V2

1.1 概述

skill 例如:抓取(pick), 放置(place), 推动(pushing), 清扫(sweeping), 堆叠(stacking), 折叠(folding)
trajectories 就是action集合:

其中数据集合结构图如下:
图像分辨率:640×480
1.2 硬件环境
BridgeData的整体环境如图:
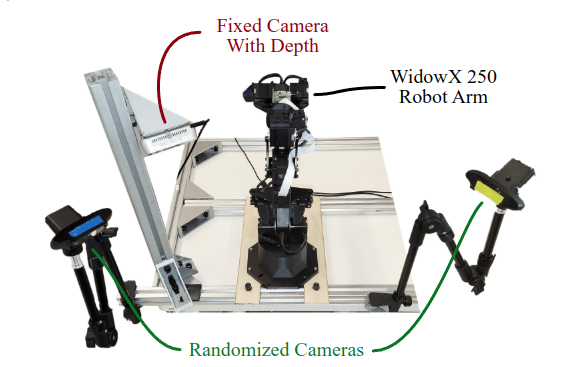
其中所有的硬件(包括支架, 导轨,工件 等等)描述链接如下:
https://docs.google.com/document/d/1si-6cTElTWTgflwcZRPfgHU7-UwfCUkEztkH3ge5CGc/edit?pli=1&tab=t.0

该平台主要的内容:
一个固定视角(over-the-shoulder) 的RGBD(Intel D435),
一个固连在机器人腕部的RGB(custom Raspberry Pi),
两个可变视角RGB(Logitech C920),在数据采集过程中会被更改。
我们关心的机械臂和摄像头参数如下:




但是要注意的是openVLA没有用腕部摄像头(原因是方便 PK 其他工作), 因此只用了第三人视角的摄像头

2 数据集
2.1 场景与结构
可以看到数据集合总共有两种

| 类型 | 说明 |
|---|---|
| Human demonstrations | 人类通过遥操作(如鼠标/VR 手柄)控制机器人执行任务,系统记录图像、指令和动作 |
| Scripted policies | 开发者用 Python/控制代码编写一套“规则程序”,在给定场景中自动执行任务,比如:“如果检测到杯子在桌面中心,则移动 gripper 到目标点并下降” |
数据结构如下图, 其中每个traj_group 都是相同场景,固定部分摆件,然后制造数据
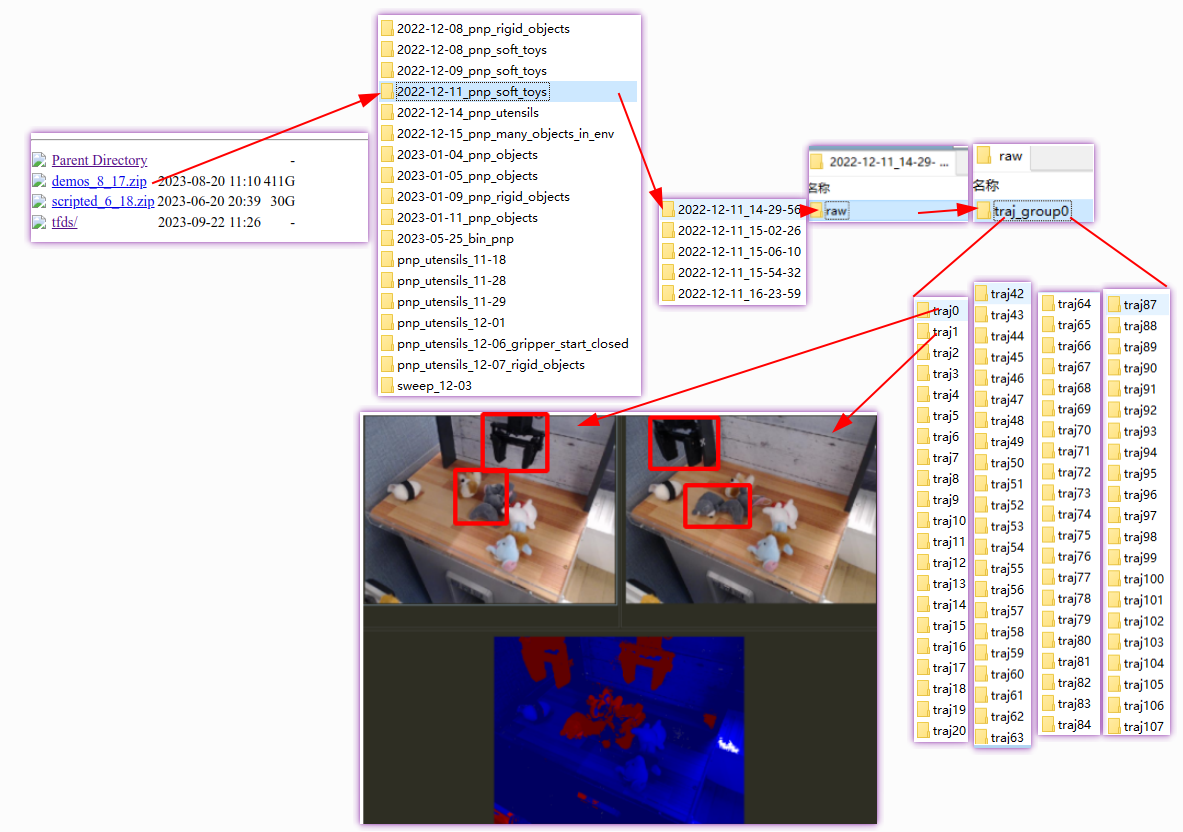
再升一级目录,我们可以看到 相同的场景,不同的拍摄时间对应不同的 摆件,而不是控制部分不同的摆件
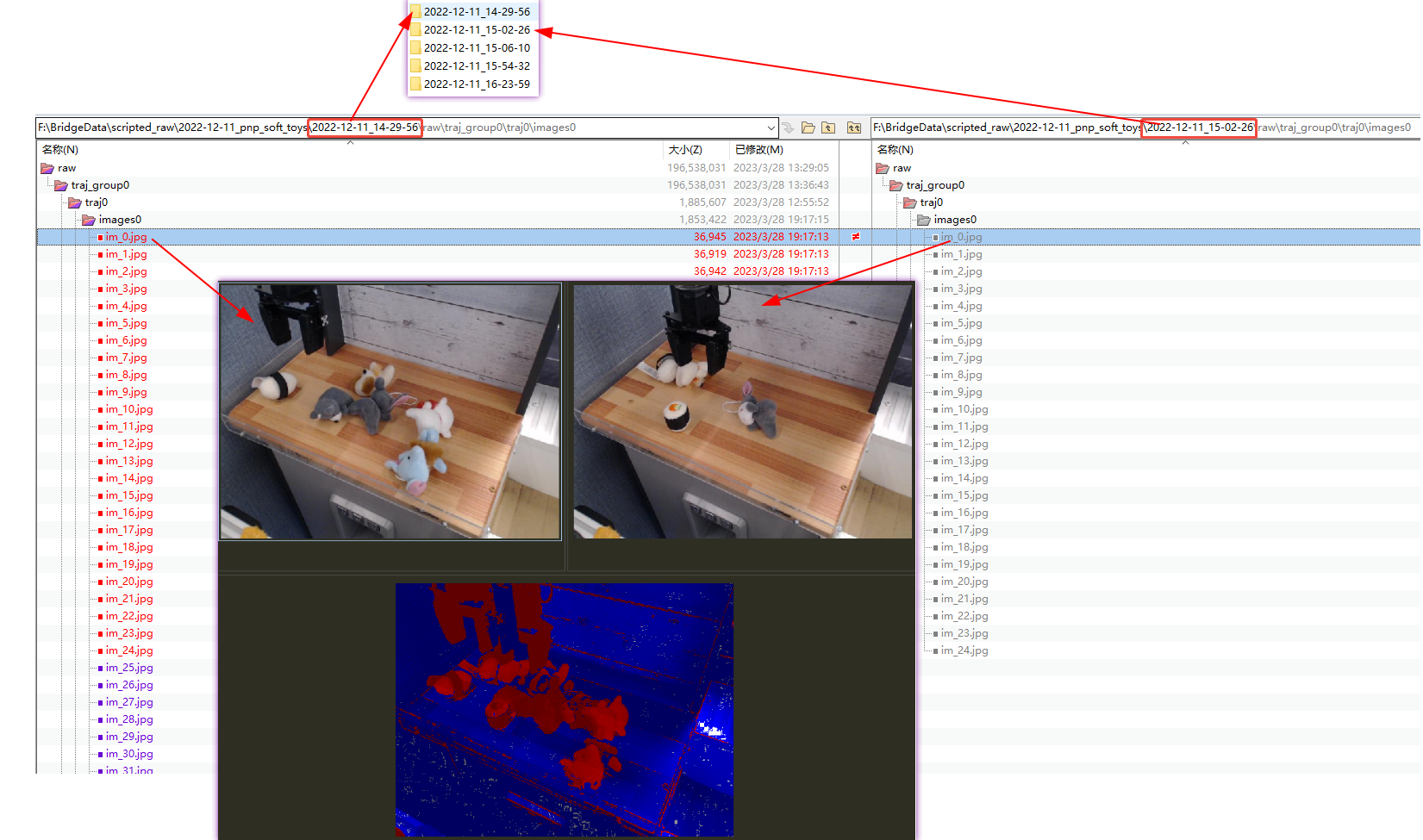
我们, 再进入raw 数据,可以看到bridge_data的场景结构
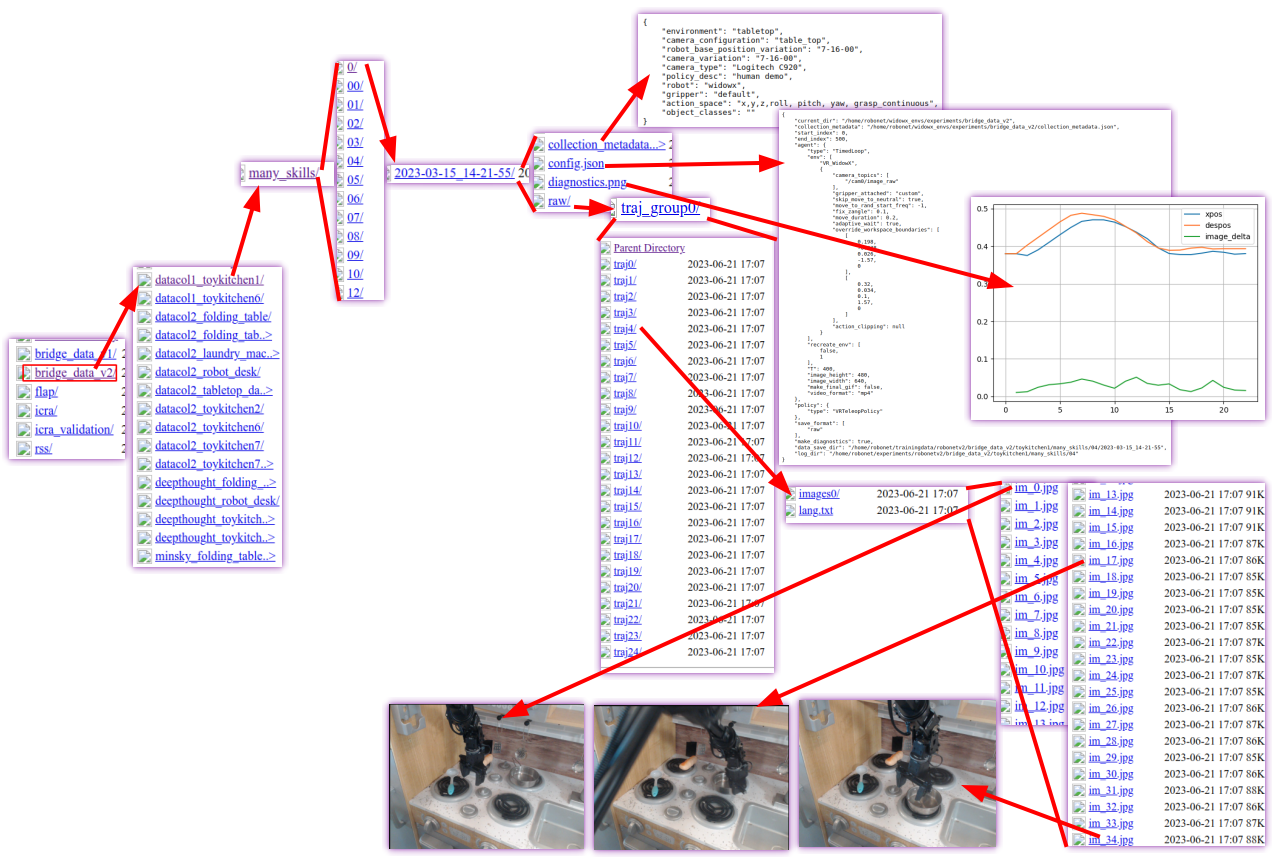
其中这里作者还为数据的正确性做了验证放了一张diagnostics.png 图片以显示当前 通过脚本给定数据的正确性.
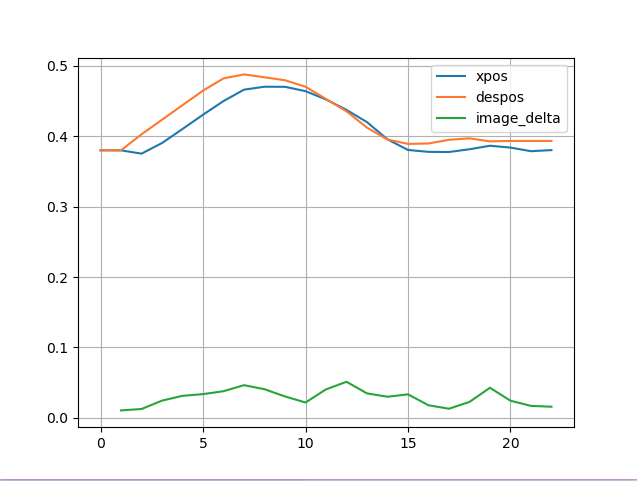
| 名称 | 意义 | 数据来源 |
|---|---|---|
| xpos | 实际执行到的位置 | 通过机器人反馈采集,每一帧记录 |
| despos | 计划中的目标位置 | 来自控制策略(如 scripted policy)或人类操作输入 |
2.2 数据结构
每一组数据里都包含三个文件:

2.2.1 images0
images0 是用于ViT的一组图片, obj_dict 是场景信息

可以看出就是完成一个 trajetory的过程.
2.2.2 obs_dict.pkl

| 键名 | 含义 |
|---|---|
| joint_effort | 每个关节的施加力矩(关节力) |
| qpos | 关节位置(Joint Position) |
| qvel | 关节速度(Joint Velocity) |
| full_state | 完整状态向量(包含位姿、关节等) |
| state | 简化状态(可能是观测空间状态) |
| desired_state | 控制器期望状态(即 despos 源) |
| time_stamp | 每帧时间戳 |
| eef_transform End-Effector | 的变换矩阵(即 gripper 位姿) |
| high_bound / low_bound | 状态空间上下界 |
| env_done | 当前帧是否终止(布尔) |
| t_get_obs | 获取观测时耗(调试用) |
其中
eef_transform代表的是 gripper 的六自由度位姿变换矩阵(通常是 4x4),可以从中提取出:
(1) 平移向量(x, y, z) 即我们要的 xpos
(2) 旋转矩阵 , 可进一步转为欧拉角(roll, pitch, yaw)
2.2.3 policy_out.pkl
| 索引 | 含义 | 示例值 | 说明 |
|---|---|---|---|
| [0:3] | Δx, Δy, Δz | -0.012, 0.037, 0.004 | 空间位置变化向量(平移动作) |
| [3:6] | Δroll, Δpitch, Δyaw | 0.0043, -0.0037, -0.8251 | 欧拉角空间的姿态微调(旋转动作) |
| [6] | gripper_open | 1 or 0 | 夹爪开闭指令(1 表示张开,0 表示闭合) |

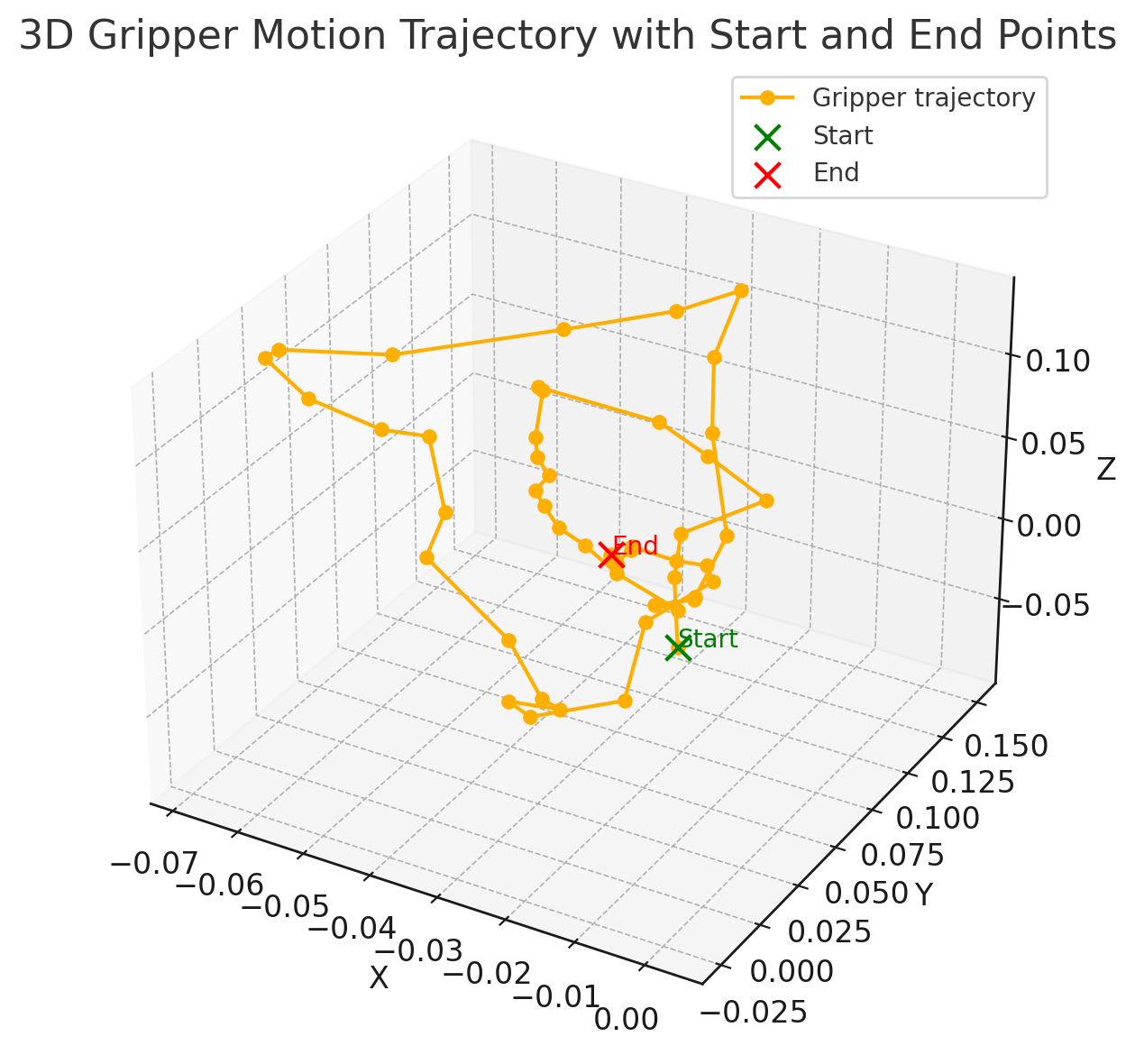
我这条case 共计49组,这张图是记录了 xyz的运动轨迹
这张图分析了 爪子夹取东西的时间分布图.