掌握二叉搜索树:从基础知识到实际应用的全貌
二叉搜索树作为计算机科学的核心数据结构,凭借其动态有序性和高效操作,已成为数据库、编译器、NLP等领域的基石。随着自平衡技术、分布式计算和机器学习的融合,BST将在未来持续进化,为海量数据处理、实时系统优化等场景提供更强大的支持。无论是传统软件优化还是新兴技术落地,BST的潜力远未穷尽。
一. 二叉搜索树简介
1.1 基本概念
二叉搜索树(Binary Search Tree, BST)是一种特殊的二叉树,满足以下性质:
- 左子树所有节点的值均小于根节点值;
- 右子树所有节点的值均大于根节点值;
- 左右子树本身也是二叉搜索树。
- 其核心优势在于:
- 中序遍历可得到一个升序序列;
- 平均时间复杂度为 O(log n),支持高效查找、插入和删除操作。
1.2 意义与价值
- 动态数据管理
- 相比静态有序数组的二分查找(O(log n)),BST 支持动态插入和删除,且无需像链表一样线性遍历,兼顾了链表的灵活性和数组的快速访问特性。
- 自平衡扩展性
- 通过红黑树、AVL树等自平衡变体,解决了BST退化为链表(时间复杂度退化至O(n))的问题,确保在频繁操作下仍保持高效。
- 天然有序性
- 中序遍历直接生成有序序列,适用于需要范围查询或排序的场景。
1.3 典型应用场景
- 数据库索引
- 加速键值查询(如按主键查找记录),避免全表扫描。
示例:MySQL的InnoDB引擎使用B+树(BST的扩展)管理索引。
- 编译器符号表
- 存储变量名及其属性(类型、作用域),支持快速查找和更新。
- 自然语言处理(NLP)
- 构建词汇表,优化词汇统计和分析(如词频统计、拼写检查)。
- 动态集合管理
- 实时排行榜、任务队列等需要频繁插入/删除且保持有序的场景。
- 文件系统与共享软件
- 按文件名、时间戳等属性组织文件,支持快速检索和动态更新(如阿里云开发者社区案例)。
1.4 性能分析
如下图:通过该图分析一下,并总结得出结论。
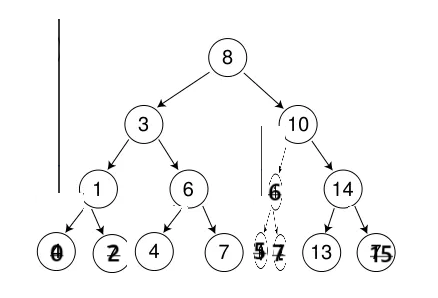
2 h 2^h 2h-1=N,注这里的h表示树的高度,N表示树中的节点个数。
即 h = log 2 ( N + 1 ) h = \log_2 (N + 1) h=log2(N+1),根据时间复杂度的规则,常数给省略,即 h = log 2 N h = \log_2 N h=log2N
- 最优情况下,二叉搜索树转化成完全二叉树,其高度为 h = log 2 N h = \log_2 N h=log2N
如下图:
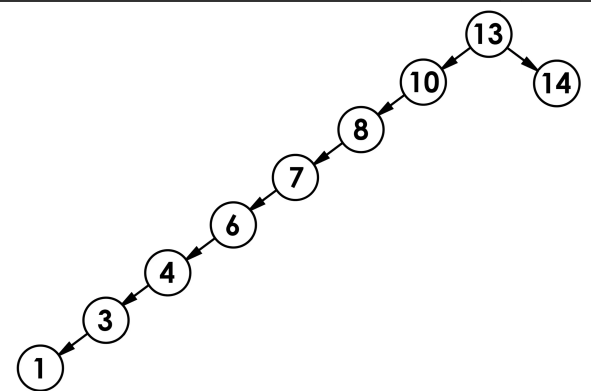
高度为: h = N-1,。 - 最差情况下,二叉搜索树退化为单支树。
综上而言,二叉搜索树增删查时间复杂度为O(N),以最差的情况算时间复杂度。
补充:二分查找也可以时间O( l o g 2 N log_2 N log2N)级别效率,但存在两大缺陷: - 需要支持下表随机访问,并且有序
- 插入,删除效率低,涉及移动数据
1.5 总结与展望
随着大数据时代的到来,自然语言处理、图像识别等领域需要快速高效的数据存储和检索机制。尽管二叉搜索树在某些情况下存在平衡性问题,未来可能会结合自平衡的树结构(如AVL树、红黑树)来改进性能。此外,随着并行计算技术的发展,研究如何在分布式系统中应用二叉搜索树的思想,将是一个重要的研究方向。
在智能算法和机器学习领域,二叉搜索树的基本原则也可能被拓展和应用于更复杂的模型和数据结构中。总的来说,二叉搜索树作为一种基础的数据结构,具有广泛的应用前景和深远的研究意义。
二. 搜索二叉树实现
2.1 插入
插入过程思考步骤:
- 树如果为空,直接将该节点赋值给根指针_root
- 树不为空,插入的值比根节点大,往右走,因为左节点的值都比根节点的值小;插入的值比根节点小,往左走,因为右节点的值都比根节点的值大,最后将该节点与父节点进行连接。细节:需要注意判断当前节点的值与父节点的值大小进行比较,不可根据本能反应差左边还是右边。
- 如果⽀持插⼊相等的值,插⼊值跟当前结点相等的值可以往右⾛,也可以往左⾛,找到空位置,插⼊新结点。(要注意的是要保持逻辑⼀致性,插⼊相等的值不要⼀会往右⾛,⼀会往左⾛)
- 示例代码:
bool Insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;//不允许插入相同的值,插入失败
}
}
cur = new Node(key);
if (parent->_key > key)
parent->_left = cur;
if (parent->_key < key)
parent->_right = cur;
return true;//表示插入成功
}
2.2 查找
这个过程就简单了,当前要查的节点的值与根节点的值进行比较,比它大的往右走,反之往左走;走到空,就没找到,返回false即可,否则返回true,表示找到了。
- 示例代码:
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return true;//找到了
}
}
return false;//未找到
}
2.3 删除
2.3.1 单或无孩型
删除过程相对较复杂,别担心,小编一步一步带入大家学习并掌握它。
下面以几张图片来讲解过程,如下:
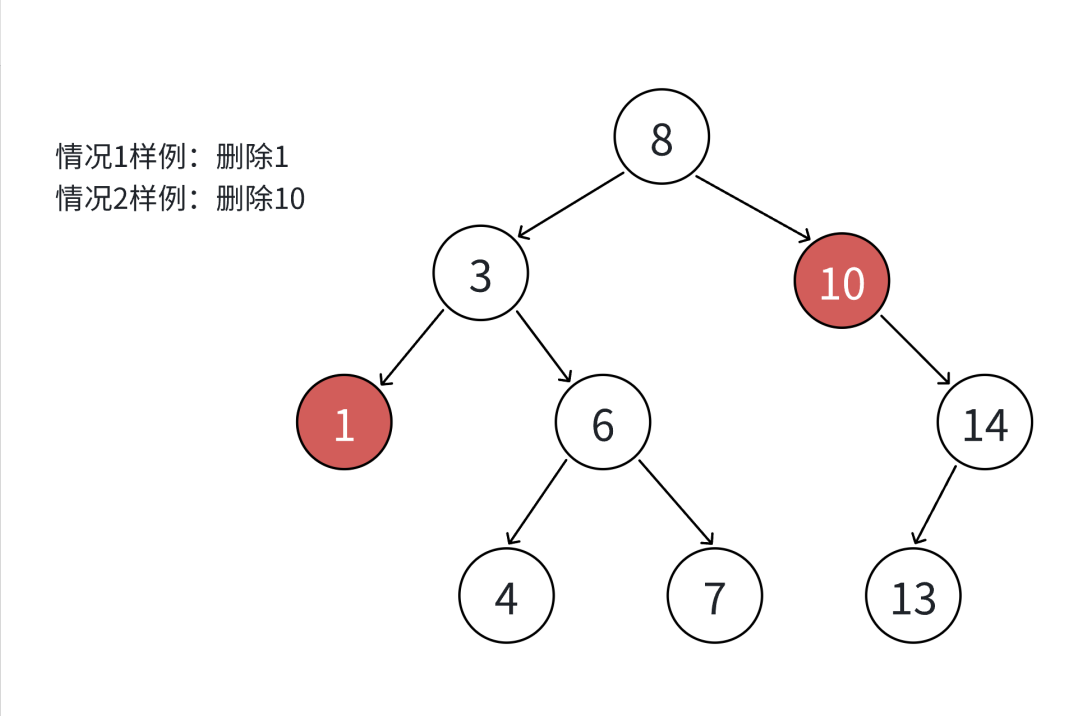
先查找该节点的值是否存在该搜索二叉树中,存在才进行删除,不存在什么也不做。
比如:
- 删除1,1的左右孩子结点都为空,将父节点(3)指向空即可
- 删除10,将父亲节点(8)指向10的右节点,因为10的左节点为空。
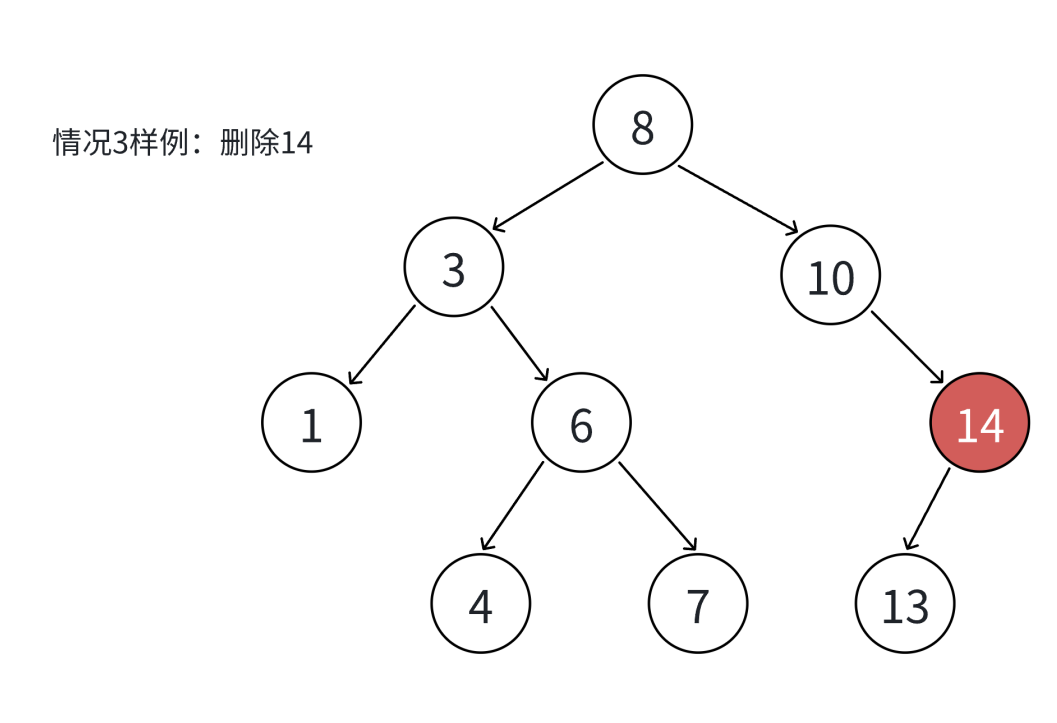
先查找该节点的值是否存在该搜索二叉树中,存在才进行删除,不存在什么也不做。
比如:
- 删除14,14的左孩子结点不为空,将14的父节点(10)指向14的左节点即可,因为14节点的右为空,所以在指向前需判断,不可盲目的连接。
通过上述分析无孩型可以规定至单孩型,处理过程一致: - 通过上述分析得出的伪代码如下(该代码有问题):
bool Erase(const K& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
if (cur->_left == nullptr)
{
//左为空,父亲指向我的右
if (cur == parent->_right)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
delete cur;
}
else if (cur->_right == nullptr)
{
//右为空,父亲指向我的左
if (cur == parent->_right)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
delete cur;
}
else
{
//...
}
return true;
}
}
return false;
}
上述代码有没有问题???
我们来看加入我们删除8这个节点,会有什么问题,parent为空,在else进行解引用,程序必崩溃。
如何解决???
如果当前根节点左为空,且正要删除根节点,重新将根节点的右节点当做根节点即可,在释放旧的根节点;当前根节点右为空,且正要删除根节点,重新将根节点的左节点当做根节点即可,在释放旧的根节点,否则再让父节点指向要删除节点的左或右节点。
- 示例代码如下:
bool Erase(const K& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
if (cur->_left == nullptr)
{
if (cur == _root)
{
_root = cur->_right;
}
else
{
//左为空,父亲指向我的右
if (cur == parent->_right)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
}
delete cur;
}
else if (cur->_right == nullptr)
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
//右为空,父亲指向我的左
if (cur == parent->_right)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
}
delete cur;
}
else
{
//...
}
return true;
}
}
return false;
}
2.3.2 双孩型
当删除的节点既有左孩子又有右孩子,使用替代法。
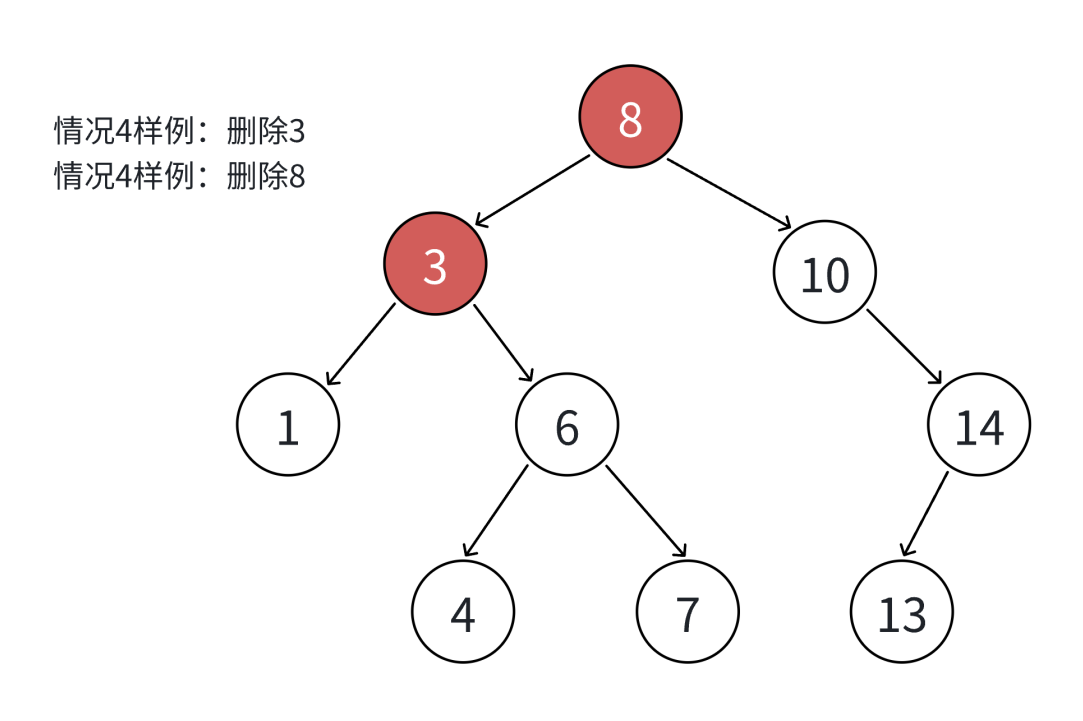
找个符合二叉搜索树规则的节点来替代,
- 找当前节点左子树最大节点的值来替代
- 找当前节点右子树最小节点的值来替代
为什么行???
因为左子树节点最大的值,比左子树所有节点的值都大,比右子树所有节点的值都小,可能站稳脚跟。本篇以第二种为例:
假如删除3,从右子树找最小的值4,从右子树的当前根节点,一直去左子树找,因为最小值在左子树,找到4,再将最小节点的值与当前正要删除节点的值(3)进行替换,从而转化成间接删除3这个节点。注意旧节点的右子树不一定为空。
- 示例代码:
else
{
//找右子树最小的最小节点,进行交换,间接删除要删除的节点。
Node* minright = cur->_right;
Node* minrightparent = cur;
while (minright->_left)
{
minrightparent = minright;
minright = minright->_left;
}
cur->_key = minright->_key;//交换值,达到删除的目的
if (minright == minrightparent->_right)
{
minrightparent->_right = minright->_right;
}
else
{
minrightparent->_left = minright->_right;
}
delete minright;
}
2.3.4 整合代码
下面的代码是上面分析的整合版。
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
//删除
if (cur->_left == nullptr)
{
//if (parent == nullptr)
if (cur == _root)
{
_root = cur->_right;
}
else
{
// 父亲指向我的右
if (cur == parent->_right)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
}
delete cur;
}
else if (cur->_right == nullptr)
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
// 父亲指向我的左
if (cur == parent->_right)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
}
delete cur;
}
else
{
// 找右子树最小节点(最左)替代我的位置
Node* minRightParent = cur;
Node* minRight = cur->_right;
while (minRight->_left)
{
minRightParent = minRight;
minRight = minRight->_left;
}
cur->_key = minRight->_key;
if (minRightParent->_left == minRight)
{
minRightParent->_left = minRight->_right;
}
else
{
minRightParent->_right = minRight->_right;
}
delete minRight;
}
return true;
}
}
return false;
}
三. ⼆叉搜索树key和key/value使⽤场景
3.1 仅使用键(Key)的场景
当数据仅需通过键进行快速查找、排序或范围查询,且无需存储额外数据时,纯键结构更合适。典型场景包括:
- 数据库索引
- 例如:按用户ID快速查找记录,BST可加速主键查询(如MySQL的B+树索引是BST的变种)。
- 优势:支持范围查询(如 WHERE id BETWEEN 10 AND 20)。
- 有序集合维护
- 例如:实现一个动态排序的排行榜(如游戏高分榜),或自动补全功能(如输入时按字母顺序过滤候选词)。
- 优势:插入、删除和查找时间复杂度为平均 O(logn)。
- 符号表(Symbol Table)的键管理
- 仅需管理键的存在性(如检查变量名是否已定义),不关心具体值。
3.2 使用键值对(Key/Value)的场景
当需要通过键快速访问关联的额外数据时,键值对结构更适用。典型场景包括:
- 缓存系统
- 例如:Redis、Memcached 使用键值对存储临时数据,通过键快速检索值(如用户会话信息)。
- 优势:支持高效读写,适合热点数据加速。
- 符号表实现
- 例如:编译器中的符号表,存储变量名(键)及其类型、作用域(值)。
- 优势:键唯一性保证,值可存储复杂属性。
- 配置管理
- 例如:通过配置键(如 database.url)快速获取配置值,支持动态更新。
- 路由表或映射表
- 例如:网络路由中通过目标IP(键)查找下一跳地址(值)。
3.3 key/value改装代码
仅需在节点中增加value值,Find找到时返回节点的指针,以便对当前key对应的value值进行修改。
- 示例代码:
namespace key_value
{
template<class K, class V>
struct BSTNode
{
K _key;
V _value;
BSTNode<K, V>* _left;
BSTNode<K, V>* _right;
BSTNode(const K& key, const V& value)
:_key(key)
, _value(value)
, _left(nullptr)
, _right(nullptr)
{}
};
template<class K, class V>
class BSTree
{
typedef BSTNode<K, V> Node;
public:
bool Insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key, value);
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return nullptr;
}
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
//删除
if (cur->_left == nullptr)
{
//if (parent == nullptr)
if (cur == _root)
{
_root = cur->_right;
}
else
{
// 父亲指向我的右
if (cur == parent->_right)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
}
delete cur;
}
else if (cur->_right == nullptr)
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
// 父亲指向我的左
if (cur == parent->_right)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
}
delete cur;
}
else
{
// 找右子树最小节点(最左)替代我的位置
Node* minRightParent = cur;
Node* minRight = cur->_right;
while (minRight->_left)
{
minRightParent = minRight;
minRight = minRight->_left;
}
cur->_key = minRight->_key;
if (minRightParent->_left == minRight)
{
minRightParent->_left = minRight->_right;
}
else
{
minRightParent->_right = minRight->_right;
}
delete minRight;
}
return true;
}
}
return false;
}
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
cout << root->_key << " " << root->_value << endl;
_InOrder(root->_right);
}
Node* _root = nullptr;
};
}
3.3.1 统计次数测试
Test.cpp
#include"BStree.h"
int main()
{
string arr[] = { "苹果","香蕉","香蕉","西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉","香蕉","香蕉" };
key_value::BSTree<string, int> countTree;
for (auto& e : arr)
{
//key_value::BSTNode<string, int>* ret = countTree.Find(e);
auto ret = countTree.Find(e);
if (ret == nullptr)
{
countTree.Insert(e, 1);
}
else
{
ret->_value++;
}
}
countTree.InOrder();
return 0;
}
输出结果:

四. 最后
本文介绍二叉搜索树(BST)是动态有序数据结构,通过左小右大性质实现高效增删查改(平均O(log n)),但最差退化为O(n)。其核心价值体现在:1)数据库索引、编译器符号表等需快速范围查询场景;2)自平衡变体(如红黑树)解决退化问题,保障高频操作性能;3)键值对扩展支持缓存系统、配置管理等关联数据场景。本文详述了BST的插入、查找、删除实现(含单/双子节点处理),并通过词频统计案例演示键值对应用。随着技术发展,BST与自平衡、分布式计算的融合将持续赋能实时系统与大数据处理。