1. 问题现象
在python代码中,用open函数打开文本文件并显示文本内容,中文显示乱码,代码如下。
from tkinter import *
import tkinter.filedialog
root = Tk()
# 给窗口的可视化起名字
root.title('Open File Test')
# 设定窗口的大小(长 * 宽)
root.geometry('640x360') # 这里的乘是小x
def open_file():
filename = tkinter.filedialog.askopenfilename()
if filename != '':
lb.config(text = "您选择的文件是:"+filename)
txt.delete("1.0","end") #清空文本框
with open(filename,'r') as rf:
for line in rf:
txt.insert("end",line)
else:
lb.config(text = "您没有选择任何文件")
lb = Label(root,text = '',bg="LightGray") #width=30, height=1
lb.place(x=100, y=10)
btn = Button(root,text="打开",command=open_file)
btn.place(x=10, y=10)
txt = Text(root, height=10)
txt.place(x=10, y=50)
root.mainloop()
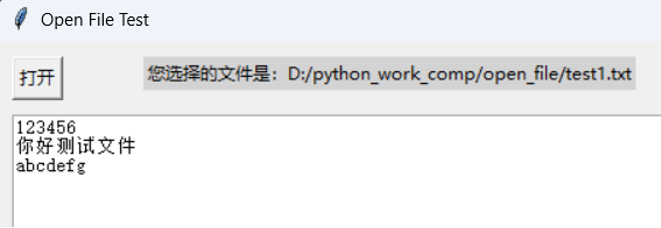
文本文件内容如下。
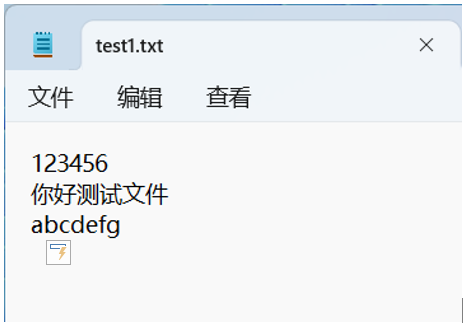
但是显示的时候,中文字符出现乱码。
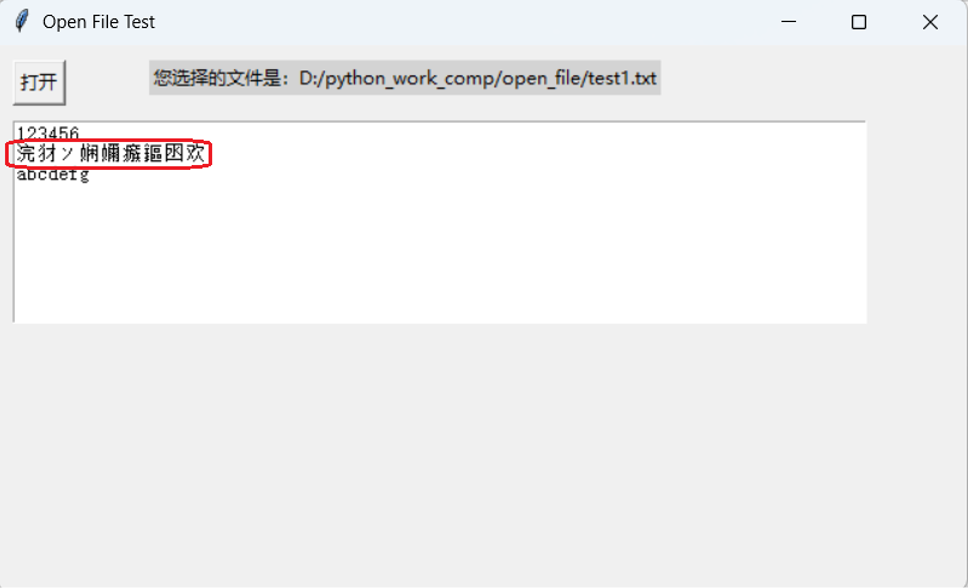
2. 原因分析
查了一下,还是跟编码方式有关。在 Python 中,open函数打开文件时如果不指定编码方式,open函数会以默认的编码方式打开文件。open函数默认的编码方式与操作系统有关:
• Windows:默认通常是 ANSI 编码(如 cp1252,取决于系统区域设置)。
• Linux/macOS:默认通常是 UTF-8。
因此文件的编码方式如果与默认编码方式不同,则可能导致文件读写时出现乱码。
在 Python 中,可以通过以下代码查看当前环境的默认编码:
import locale
print(locale.getpreferredencoding(False))
查询本机默认编码方式如下。
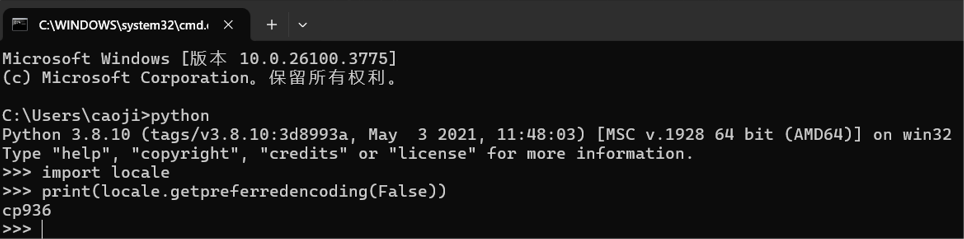
CP936 是一种代码页编码方式,也被称为 “Windows 936” 或 “GBK” 编码。CP936 编码向下兼容 GB2312 字符集。
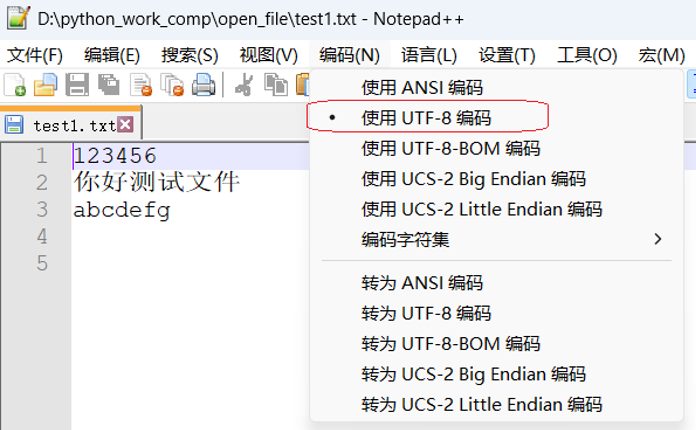
再看一下test1.txt文件的编码方式,是utf-8编码方式。编码方式与默认的不同,所以就会出现中文乱码现象。
3. 解决方法
解决此问题也有两种方法:
(1)为避免兼容性问题,建议在打开文件时明确指定编码,这种方法最常用,也是被推荐使用。 如下,在调用open函数时,指定encoding=‘utf-8’,这时打开文件显示就正常了。

(2)这种方法不改代码,而是将文本文件的编码方式改为GBK编码方式,也就是ANSI编码方式。用Notepad++软件打开文件,点击菜单栏编码,再点击转为UTF-8编码,然后保存即可。
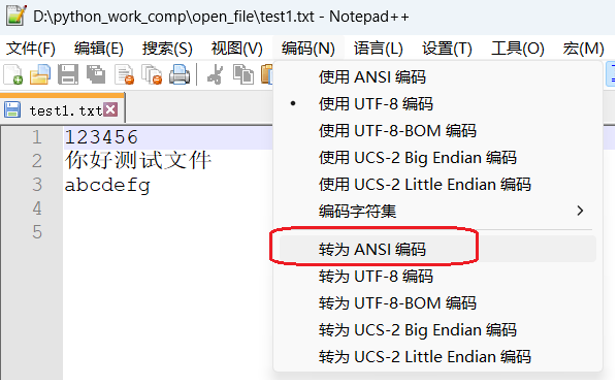
这时执行最初的程序,中文也能正常显示。但是因为UTF-8可变长度编码,支持全球所有语言,兼容性强,在处理多语言文本或需要跨平台兼容性的场景中,大多数文本都是采用UTF-8编码,所以推荐采用第1种方式处理。