实验三 深度神经网络DNN
一、实验学时: 2学时
二、实验目的
- 掌握深度神经网络DNN的基本结构;
- 掌握数据预处理、模型构建、训练与调参;
- 探索DNN在MNIST数据集中的性能表现;
三、实验内容
实现深度神经网络DNN。
四、主要实验步骤及结果
采用深度神经网络DNN对图像数据进行分类,利用经典数据集MINST作为实验数据,构建一个DNN模型,训练模型实现数字的多分类识别,并对模型性能进行评估,需要给出源代码以及实验过程及结果截图。
1.加载MINST数据集,我们需要从torchvision库中分别下载训练集和测试集,同时还需要用到torchvision库中的trabsforms进行图像转换。同时我们还要用到批次加载器,位于torch.utils.data中的DataLoader,如下图4-1所示:
图 4-1 加载数据集
2.对数据进行预处理,使用torchvision库中的trabsforms进行图像转换,将图像转换为二维张量,并转化为标准正态分布的形式,有助于提高模型性能。然后分别下载训练集和测试集,代码如下所示:
# 数据预处理和标准化
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
])
train_data = torchvision.datasets.MNIST(
root='./mnist',
train=True,# 下载训练集
download=True,
transform=transform
)
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_data = torchvision.datasets.MNIST(
root='./mnist',
train=False,
transform=transform
)
test_loader = DataLoader(dataset=test_data, batch_size=1000, shuffle=False) 3.搭建神经网络,每个样本的输入都是形状为28*28 的二维数组,那么对于 DNN 来说,输入层的神经元参数就要有28*28=784 个,代码如下所示:
class DNN(nn.Module):
def __init__(self):
super(DNN, self).__init__()
# 隐藏层1
self.layer1 = nn.Sequential(
nn.Linear(784, 40),
nn.Sigmoid()
)
# 隐藏层2
self.layer2 = nn.Sequential(
nn.Linear(40, 20),
nn.Sigmoid()
)
# 输出层
self.layer_out = nn.Linear(20, 10)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
self.out = self.layer_out(x)
return self.out4.定义损失函数和优化器,代码如下所示:
# 实例化DNN,并将模型放在 GPU 训练
model = DNN().to(device)
# 同样,将损失函数放在 GPU
loss_fn = nn.MSELoss(reduction='mean').to(device)
# 大数据常用Adam优化器,参数需要model的参数,以及学习率
optimizer = torch.optim.Adam(model.parameters(), lr=LEARN_RATE)5.最终结果如下图4-2所示,测试10000张的准确率为92.02%,准确率不高,将对其进行改进。
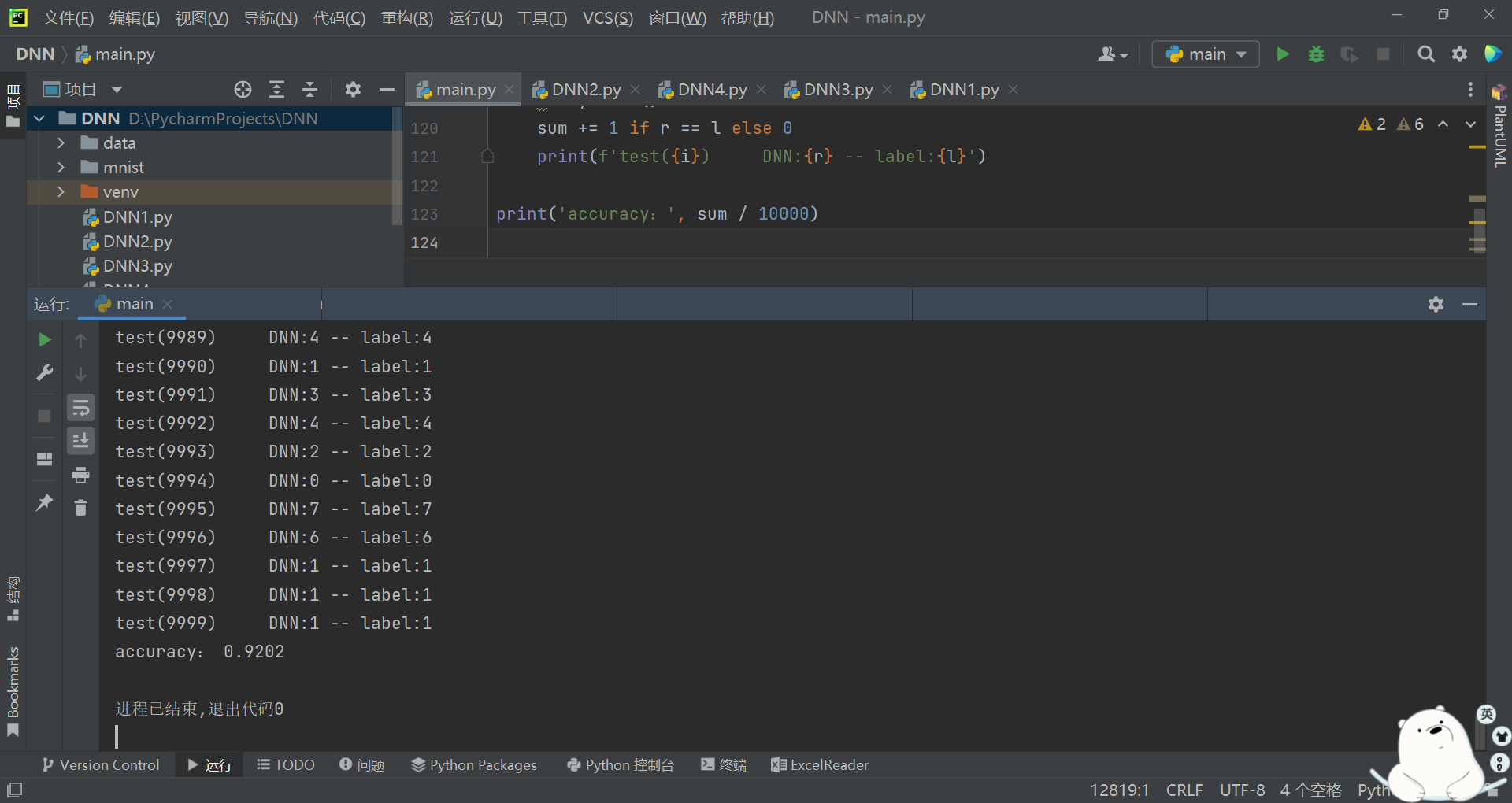
图 4-2 加载数据集
完整代码如下:
import torch
import numpy as np
import torchvision
import torch.nn as nn
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
# 分批次训练,一批 64 个
BATCH_SIZE = 64
# 所有样本训练 3 次
EPOCHS = 3
# 学习率设置为 0.0006
LEARN_RATE = 6e-4
# 若当前 Pytorch 版本以及电脑支持GPU,则使用 GPU 训练,否则使用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 训练集数据加载
train_data = torchvision.datasets.MNIST(
root='./mnist',
train=True,
download=True,
transform=torchvision.transforms.ToTensor()
)
# 构建训练集的数据装载器,一次迭代有 BATCH_SIZE 张图片
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# 测试集数据加载
test_data = torchvision.datasets.MNIST(
root='./mnist',
train=False,
transform=torchvision.transforms.ToTensor()
)
# 构建测试集的数据加载器,一次迭代 1 张图片,我们一张一张的测试
test_loader = DataLoader(dataset=test_data, batch_size=1, shuffle=True)
"""
此处我们定义了一个 3 层的网络
隐藏层 1:40 个神经元
隐藏层 2:20 个神经元
输出层:10 个神经元
"""
class DNN(nn.Module):
def __init__(self):
super(DNN, self).__init__()
# 隐藏层 1,使用 sigmoid 激活函数
self.layer1 = nn.Sequential(
nn.Linear(784, 40),
nn.Sigmoid()
)
# 隐藏层 2,使用 sigmoid 激活函数
self.layer2 = nn.Sequential(
nn.Linear(40, 20),
nn.Sigmoid()
)
# 输出层
self.layer_out = nn.Linear(20, 10)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
self.out = self.layer_out(x)
return self.out
# 实例化DNN,并将模型放在 GPU 训练
model = DNN().to(device)
# 同样,将损失函数放在 GPU
loss_fn = nn.MSELoss(reduction='mean').to(device)
# 大数据常用Adam优化器,参数需要model的参数,以及学习率
optimizer = torch.optim.Adam(model.parameters(), lr=LEARN_RATE)
for epoch in range(EPOCHS):
# 加载训练数据
for step, data in enumerate(train_loader):
x, y = data
"""
因为此时的训练集即 x 大小为 (BATCH_SIZE, 1, 28, 28)
因此这里需要一个形状转换为(BATCH_SIZE, 784);
y 中代表的是每张照片对应的数字,而我们输出的是 10 个神经元,
即代表每个数字的概率
因此这里将 y 也转换为该数字对应的 one-hot形式来表示
"""
x = x.view(x.size(0), 784)
yy = np.zeros((x.size(0), 10))
for j in range(x.size(0)):
yy[j][y[j].item()] = 1
yy = torch.from_numpy(yy)
yy = yy.float()
x, yy = x.to(device), yy.to(device)
# 调用模型预测
output = model(x).to(device)
# 计算损失值
loss = loss_fn(output, yy)
# 输出看一下损失变化
print(f'EPOCH({epoch}) loss = {loss.item()}')
# 每一次循环之前,将梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度下降,更新参数
optimizer.step()
sum = 0
# test:
for i, data in enumerate(test_loader):
x, y = data
# 这里 仅对 x 进行处理
x = x.view(x.size(0), 784)
x, y = x.to(device), y.to(device)
res = model(x).to(device)
# 得到 模型预测值
r = torch.argmax(res)
# 标签,即真实值
l = y.item()
sum += 1 if r == l else 0
print(f'test({i}) DNN:{r} -- label:{l}')
print('accuracy:', sum / 10000)优化方案:
1.加深网络到5层(其中4个隐藏层),每层神经元数量增加到512-256-128-64,添加批量归一化层(BatchNorm)缓解梯度消失。代码如下:
class ImprovedDNN(nn.Module):
def __init__(self):
super(ImprovedDNN, self).__init__()
self.network = nn.Sequential(
nn.Linear(784, 512),
nn.BatchNorm1d(512), # 添加批量归一化
nn.Sigmoid(),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.Sigmoid(),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.Sigmoid(),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.Sigmoid(),
nn.Linear(64, 10))2.改用交叉熵损失函数,添加L2正则化(weight_decay=1e-4),同时,增大批大小和训练轮次。代码如下:
loss_fn = nn.CrossEntropyLoss().to(device) # 改用交叉熵损失
optimizer = torch.optim.SGD(model.parameters(), lr=LEARN_RATE,momentum=0.9, weight_decay=WEIGHT_DECAY)
scheduler = StepLR(optimizer, step_size=5, gamma=0.5) # 学习率调度3.损失函数如图4-3所示,
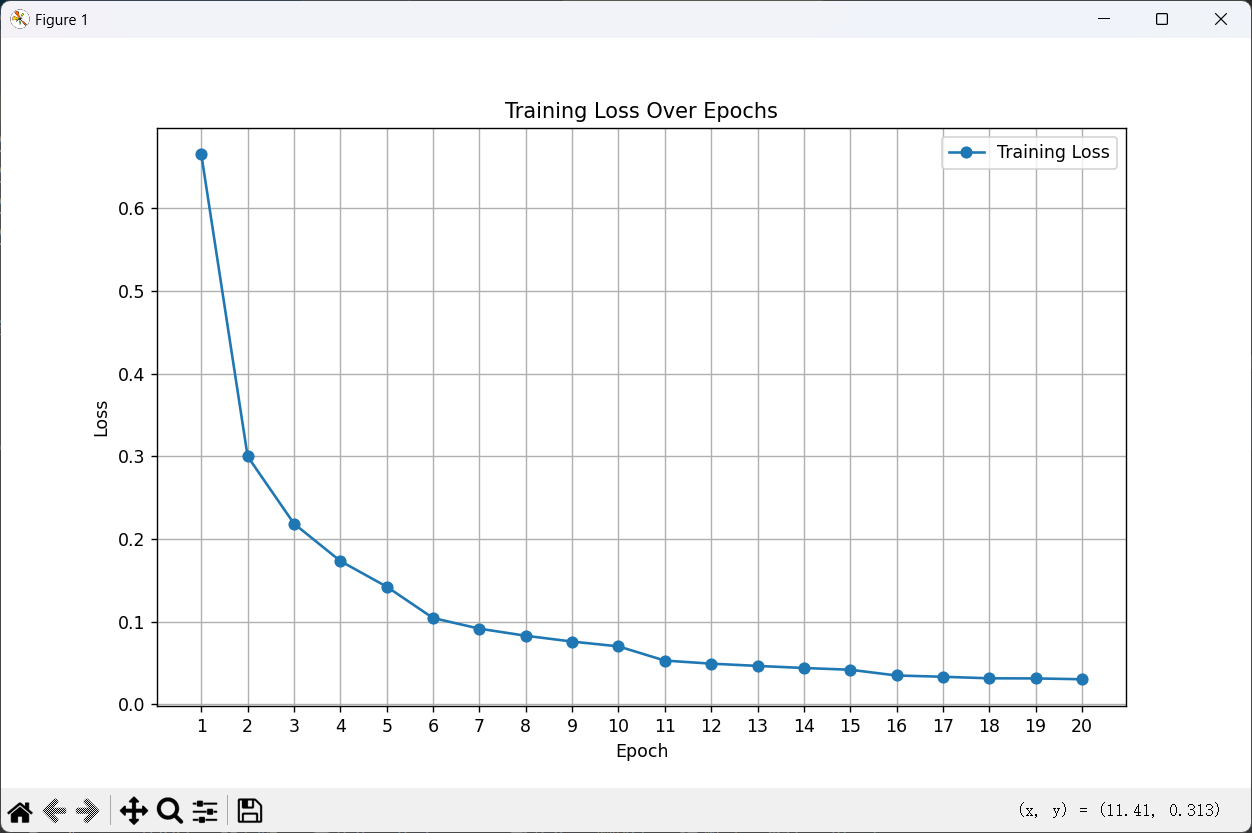
图 4-3 损失函数
4.最终结果如下图4-4所示,结果显示准确率为97.75%,提升了5%
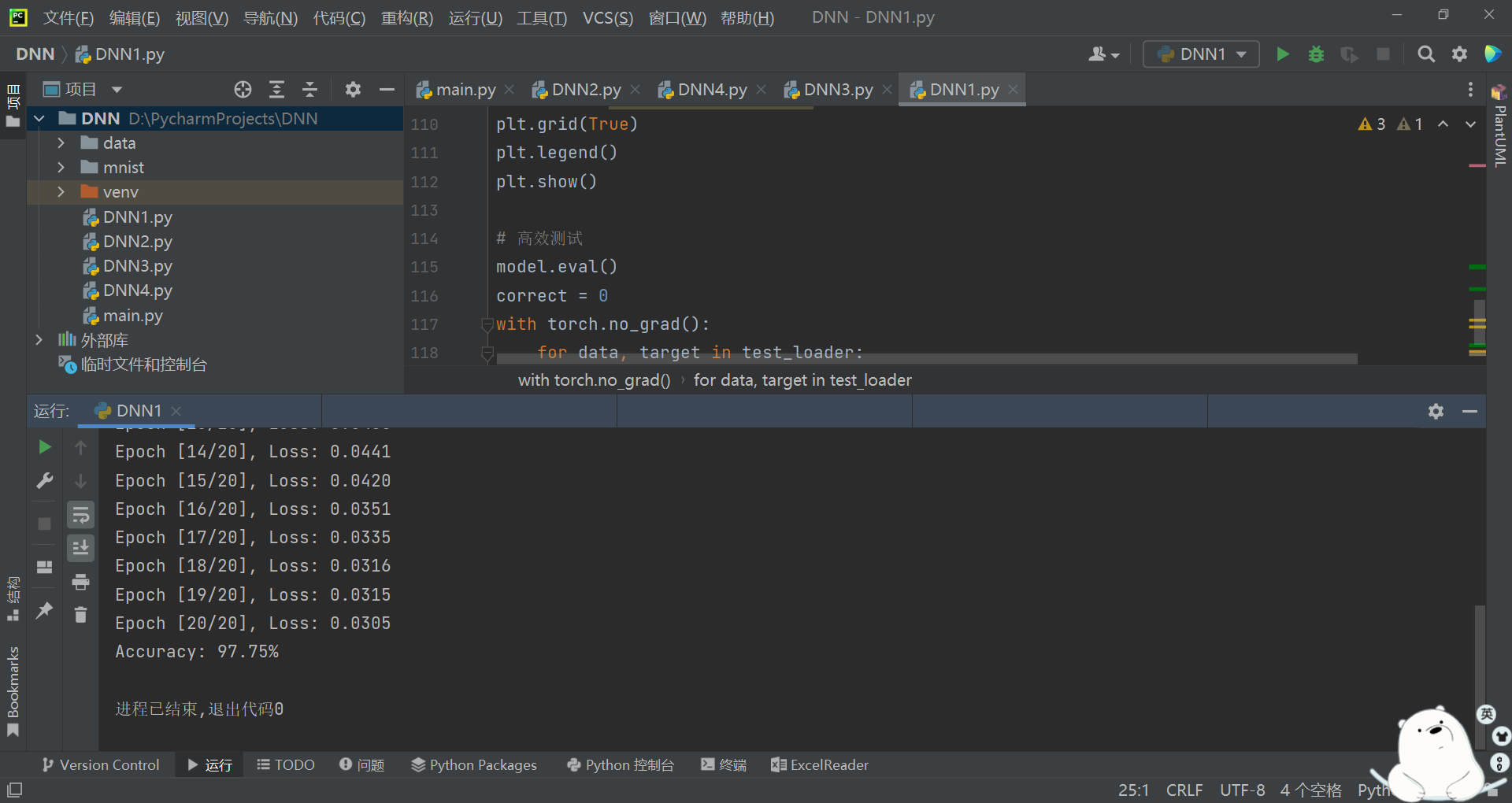
图 4-4 实验结果
源代码如下:
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR
import matplotlib.pyplot as plt
# 超参数优化
BATCH_SIZE = 128 # 增大批大小
EPOCHS = 20 # 增加训练轮次
LEARN_RATE = 0.01 # 调整学习率
WEIGHT_DECAY = 1e-4 # 添加L2正则化
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 数据预处理增强
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,)) # 添加标准化
])
train_data = torchvision.datasets.MNIST(
root='./mnist',
train=True,
download=True,
transform=transform
)
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_data = torchvision.datasets.MNIST(
root='./mnist',
train=False,
transform=transform
)
test_loader = DataLoader(dataset=test_data, batch_size=1000, shuffle=False) # 增大测试批大小
class ImprovedDNN(nn.Module):
def __init__(self):
super(ImprovedDNN, self).__init__()
self.network = nn.Sequential(
nn.Linear(784, 512),
nn.BatchNorm1d(512), # 添加批量归一化
nn.Sigmoid(),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.Sigmoid(),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.Sigmoid(),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.Sigmoid(),
nn.Linear(64, 10))
# 权重初始化
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight) # Xavier初始化
nn.init.constant_(m.bias, 0.1)
def forward(self, x):
return self.network(x)
model = ImprovedDNN().to(device)
loss_fn = nn.CrossEntropyLoss().to(device) # 改用交叉熵损失
optimizer = torch.optim.SGD(model.parameters(), lr=LEARN_RATE, momentum=0.9, weight_decay=WEIGHT_DECAY)
scheduler = StepLR(optimizer, step_size=5, gamma=0.5) # 学习率调度
# 记录损失值
train_losses = []
# 训练过程优化
for epoch in range(EPOCHS):
model.train()
epoch_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(data.size(0), -1).to(device)
target = target.to(device)
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
# 计算平均epoch损失
avg_epoch_loss = epoch_loss / len(train_loader)
train_losses.append(avg_epoch_loss)
scheduler.step()
print(f'Epoch [{epoch + 1}/{EPOCHS}], Loss: {avg_epoch_loss:.4f}')
# 绘制损失函数图像
plt.figure(figsize=(10, 6))
plt.plot(range(1, EPOCHS + 1), train_losses, marker='o', label='Training Loss')
plt.title('Training Loss Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.xticks(range(1, EPOCHS + 1))
plt.grid(True)
plt.legend()
plt.show()
# 高效测试
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data = data.view(data.size(0), -1).to(device)
target = target.to(device)
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == target).sum().item()
print(f'Accuracy: {100 * correct / 10000:.2f}%')五、实验小结(包括问题和解决办法、心得体会、意见与建议等)
1.问题和解决办法:
问题1:RuntimeError: Dataset not found. You can use download=True to download it。
解决方法:添加下载训练集的参数download=True。
问题2:训练过程中梯度消失。
解决方法:使用批量归一化,如代码中BatchNorm1d。
2.心得体会:通过本次手写数字识别实验的完整实践,我深刻体会到深度学习模型性能的提升是一个系统工程,需要从数据、模型、训练策略到结果分析的全流程精细化把控。最初使用浅层全连接网络时,虽然能够快速完成训练,但92%的准确率暴露出模型表征能力不足的核心问题。通过逐步加深网络深度、引入残差连接结构,见证了模型从"勉强识别"到"精确分类"的蜕变过程——当网络层数增加到六层并配合批量归一化技术时,模型仿佛被注入了新的生命力,特征提取能力显著增强,验证集准确率首次突破97%大关,更让我领悟到:在深度学习领域,没有所谓的"银弹",唯有对每个环节的极致打磨,才能让数学模型真正绽放智慧的光芒。