01
背景
360集团现有多个自建GPU计算集群,GPU设备总量超过万张。这些集群完成了从基于 YARN 的资源管理模式向云原生架构的整体迁移。在迁移之初,AI平台即选定了Volcano作为GPU任务的唯一调度引擎。经过几年的持续优化与技术迭代,Volcano为360集团GPU集群带来了资源利用率的提升、资源碎片率的下降、训练任务性能提升等诸多积极变化。在过去一年中,360AI平台使用Volcano累计调度超过100万个Pod,资源碎片率<7%,资源分配率>85%,资源利用率>45%
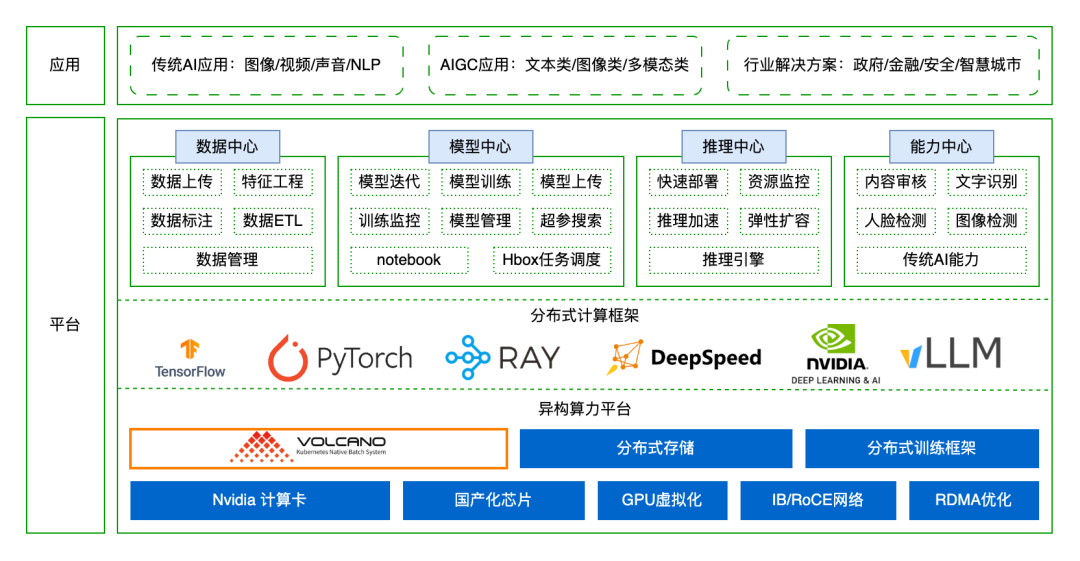
Volcano在长期使用中展现出两大突出优势:广泛的适用性和高度的灵活性。在适用性方面,得益于CNCF生态。Volcano作为CNCF孵化项目,几乎支持Kubernetes生态中所有类型的Workload,可完全替代原生kube-scheduler调度器。并且Volcano也支持多种资源类型,只要一种硬件资源遵循Kubernetes规范开发了device-plugin,Volcano就可以为workload分配这些资源,此外,借助其插件机制(如 DRF、Binpack 等),还能实现更精细化的资源分配策略。在灵活性方面,以360集团内部署的多个GPU集群为例,这些集群在资源池化、租户隔离等方面的配置各异,Volcano 均能出色适应并高效支持这些复杂且多样化的应用场景。
02
实践
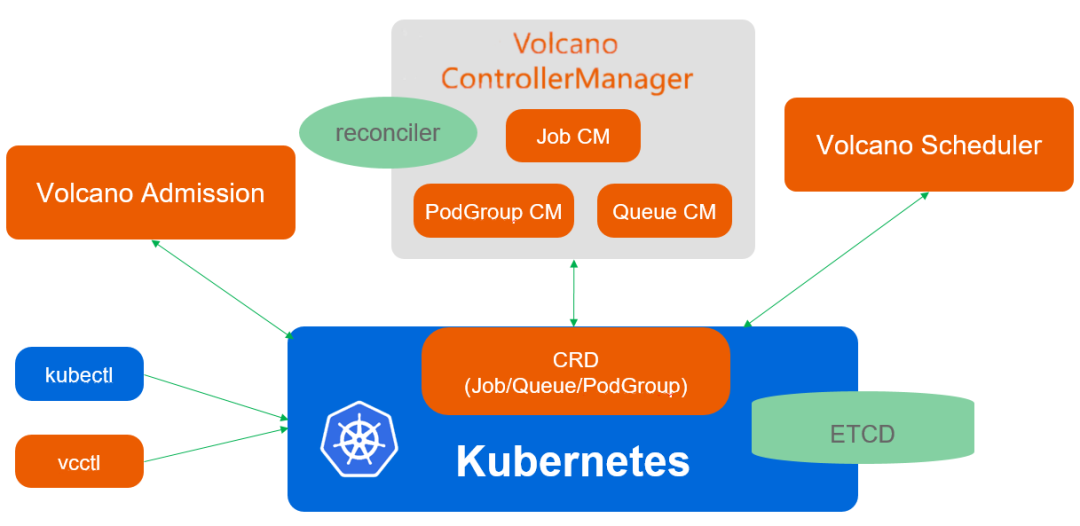
2.1 action和plugin机制
Volcano的核心机制之一是其Action和Plugin的设计模式。在调度周期内,系统会依次执行所有已注册的Actions。这些Actions定义了调度过程中的关键节点,并为Plugin提供了标准化的函数注册点。Plugins通过实现这些预定义的函数接口,可以灵活地嵌入不同的调度算法,例如DRF、Gang以及Binpack等。
值得注意的是,Volcano的架构采用了高度模块化的设计。除了少数核心的Actions和Plugins作为基础组件外,大多数Actions和Plugins都是可配置的。这种可插拔的架构设计使得用户能够根据实际需求灵活选择和组合不同的调度算法,从而满足多样化的调度场景需求。同时,这种设计也为开发者扩展自定义调度逻辑提供了标准化的接入点。
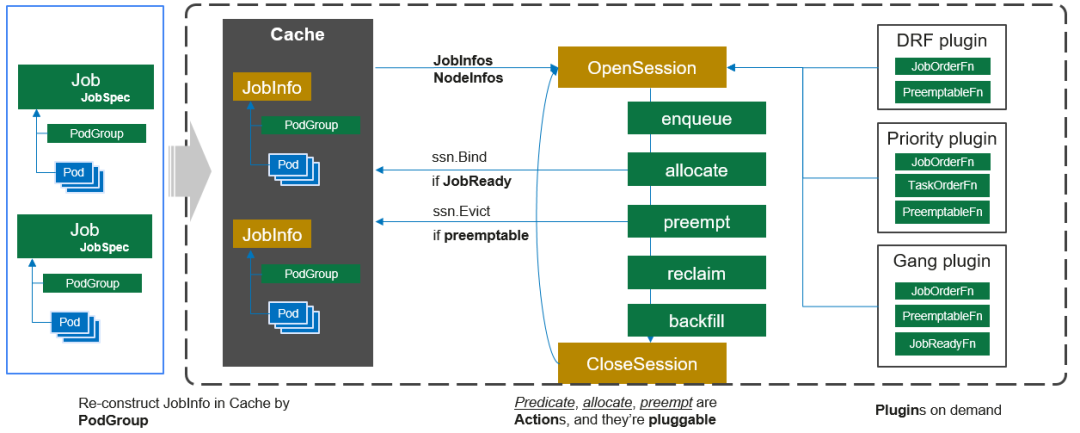
在360的多个集群中,主要采用了这些Plugins:
capacity:Volcano通过Capacity插件提供了Capability、Deserved、Guarantee三种资源管理策略,满足多租户环境下的资源分配需求,支持闲时资源共享,显著提升集群的资源利用率。
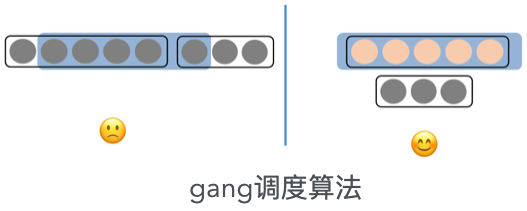
gang: 实现任务的原子性调度,避免紧耦合分布式训练任务出现部分Pod资源等待或死锁的情况,确保整个任务整体成功调度。
drf : 基于DRF算法进行公平资源分配,有效平衡多租户混合负载场景下CPU/GPU等资源的使用,防止资源饥饿问题。
priority插件 & Preempt Action: 为任务定义优先级并抢占,保障生产、高价值任务优先执行,满足SLA,必要时抢占低优先级任务资源。
task-topology: 感知硬件拓扑调度:优化大规模训练任务的Pod布局,合理使用Nvlink加速。降低通信延迟、提升通信带宽以提升性能。
conformance: 保证关键命名空间下的系统组件不被干扰,例如kube-system,volcano-system等
nodeorder: 提供了与 Kubernetes 默认调度器兼容的调度算法,确保节点亲和性(Node Affinity)、污点与容忍(Taint and Toleration)等核心调度策略的正常运作。此外,它还支持镜像缓存状态感知,以提升容器启动效率。
360内部对这些插件还做了功能上的增强,例如针对priority plugin和preempt action,360实现了指定队列内的作业可以抢占,指定的优先级可抢占低优先级任务,指定的优先级可以被高优先级的任务抢占。
360AI平台还自研了一些调度插件,满足内部的一些特殊需求。
网络拓扑感知插件
360智算中心借鉴NVIDIA DGX-SuperPod-A100架构,如上图所示为SuperPod的一组基本单元SuperPod SU(Scalable Unit),每个SU包含200台A800以及4台Leaf交换机,这20台节点间的同号网卡之间通过单台Leaf即可直接通信。
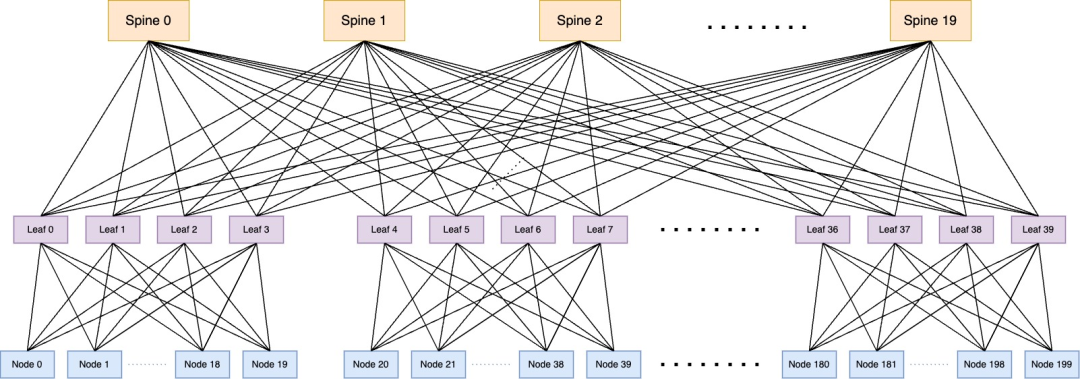
在分布式训练场景中,当多个Pod需要跨Spine交换机通信时,网络延迟和带宽竞争会显著降低训练性能。因此,最佳实践是将同一分布式训练作业的Pod调度至同一组Leaf交换机下的节点(如上图所示,Node0-Node19或Node20-Node39,每组20个节点)。在Volcano 1.11版本前,缺乏原生支持此类网络拓扑感知调度的调度插件。为此,360AI平台开发了网络拓扑感知调度插件。该优化通过智能匹配计算节点与网络拓扑结构,将多机分布式训练任务的性能提升了15%-20%。
在最新的Volcano 1.11版本中,Volcano官方实现了网络拓扑感知调度,可根据节点拓扑信息,自动将通信密集的Pod调度到同一个交换机下的节点,显著减少了AllReduce等集合操作的通信开销。
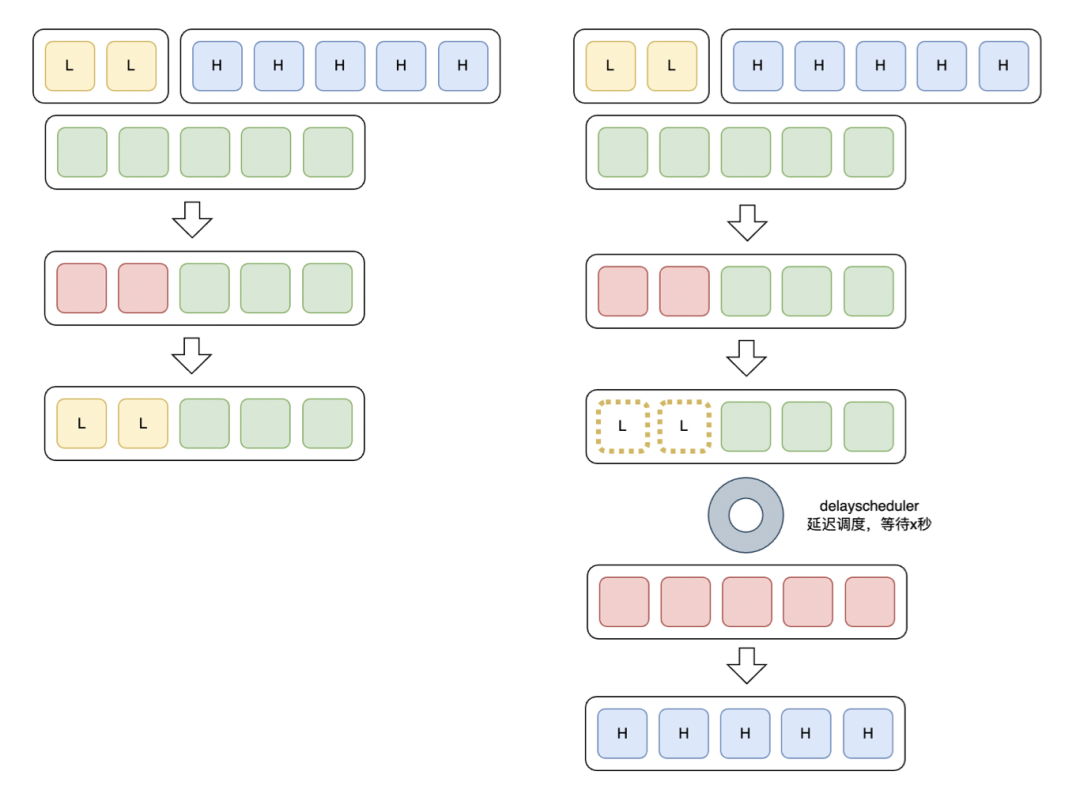
高优先级大任务防饥饿插件
大模型训练场景中,占用大块资源的任务结束时由于资源释放的顺序不确定,导致资源需求小的任务总是被优先调度,此时优先级规则是不生效的。基于这种场景我们提出了延迟调度的方法,当低优先级的任务资源满足时,采取延迟调度的方式,解决了资源需求大的训练任务长期饥饿的问题。
除调度器插件外,Volcano通过原生Job Controller插件机制为批处理作业提供增强功能,提升用户体验。关键插件包括:
env:自动注入分布式任务所需的公共环境变量(如任务索引、副本数),消除用户手动配置的冗余操作,方便进程感知自己的角色。
ssh:为Pod间建立免密SSH通信通道,保障MPI/PyTorch等框架的跨节点认证需求,提升分布式训练集群的部署效率。
svc:动态生成Headless Service,确保任务Pod通过DNS名称实现稳定的网络标识,实现更便捷的pod间通信方式。
pytorch:自动为Pod设置Pytorch的master和worker需要的环境变量,角色Index等信息,并且为Pod设置分布式通信所需端口。
2.2 租户隔离的历程
随着Volcano队列能力的增强和360使用方式上的进化,360 GPU集群租户隔离机制从单队列向多队列最终发展为层级队列架构,逐步实现更精细化的资源管控,为接下来的资源池化和闲时共享功能做好了坚实基础。
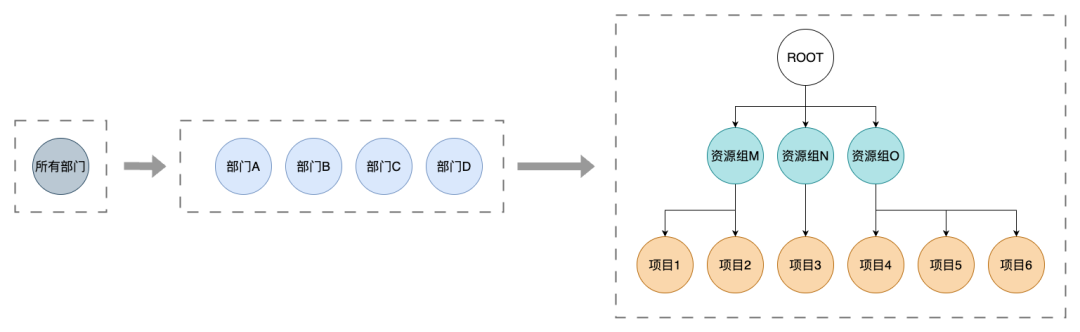
在初始采用Volcano时,360AI平台未实施队列划分策略,所有部门的作业均提交至同一队列。尽管这种"无门槛"的设计降低了初期使用复杂度,但也带来了资源缺乏隔离、管理难度增加以及跨部门任务相互干扰等问题。随着集群数量增多、单集群规模增大、使用平台的部门和人数增多,单队列在资源分配和管理层面逐渐显现出局限性。在意识到这点后,360AI平台及时推动了队列拆分,通过建立部门与队列的映射关系,实现了资源的细粒度管控。同时,平台启用了基于优先级的任务抢占机制,这不仅优化了资源利用率,而且使用户可以进一步体验调度器的其他能力,而非仅基础的资源分配功能。
随着Volcano 1.11版本的推出,Volcano实现了层级队列功能,该特性支持多级队列,可以用来对资源进行更细粒度的管理和分配,360也积极回馈开源社区,参与了此功能的设计和代码审核。基于层级队列的能力,360AI平台进一步优化了资源管理策略,将队列划分三层,分别是ROOT队列,表示集群所有资源,资源组级别队列,是一组项目的集合,项目级别队列,每个队列对应一个具体的项目。借助Volcano的capacity插件机制,实现了跨项目、跨资源组的空闲资源共享。充分发挥云原生架构的弹性优势,使平台整体资源利用率得到显著提升。
2.3 资源池化和闲时共享
在360AI平台中,存在三种类型的资源,分别是项目托管到AI平台的节点,360AI平台自有节点,在自有节点中,分为公共节点和独占节点。
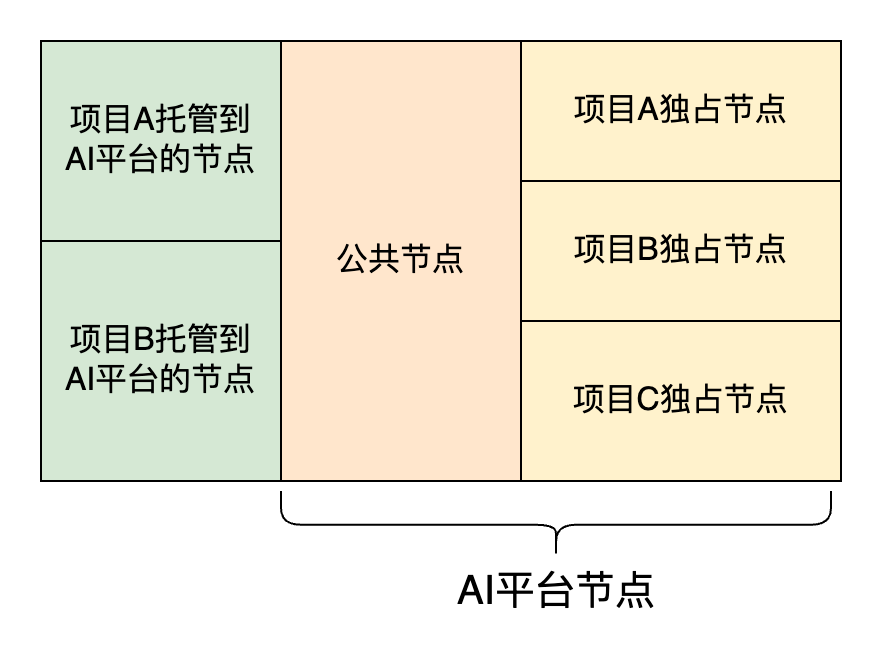
不同类型的节点上有不同的标签。在早期阶段,作业通过节点亲和性调度到它所属的节点上,这样的优点是不用考虑复杂的队列配额,使用上也比较方便,而且资源隔离性很强,不同项目间完全不会互相影响。缺点就是可能会造成A项目的资源空闲时,B项目却资源不足,在平台层面看造成了资源的浪费,导致硬件成本上升。并且在上述方案中,资源粒度是节点级别,相对来说这个资源隔离粒度较粗,如果能将资源粒度限制到计算卡级别,将会进一步提升资源利用率,降低资源碎片率。
基于以上需求,360AI平台在过去一段时间进行了自底向上的大范围重构,在不影响托管资源的前提下,进行资源池化+闲时共享的双重改造。首先是资源池化,将device-plugin上报的资源,修改为具体的型号。项目的资源配额从多少个节点,修改为xx型号的卡n张,yy型号的卡m张,对用户屏蔽节点这一概念,用户只能看到卡。其次是闲时共享,通过适配Capacity插件提供的deserved、capability能力,可以将项目独占节点在空闲时交由其他项目使用,当有需要时,通过reclaim动作,回收借出的资源。实现将空闲资源共享的同时,不影响独占资源所属的项目正常使用。从平台层面提高资源利用率。
03
未来规划
360AI平台将持续在调度侧进行投入,深入优化调度能力和调度性能,并且通过调度优化提升作业执行效率。从多个维度,提升硬件资源利用率,降低硬件使用成本。此外在大数据计算场景,为了实现Spark的云原生化改造,Volcano还将通过与Spark Operator的协同集成,支撑大数据批计算任务由Spark on Yarn向Spark on K8s迁移。逐步实现了普通计算任务、传统 AI 训练任务、大模型任务以及大数据分析任务的统一调度,构建了更为一致和高效的计算资源管理平台。360AI平台还将持续与开源社区合作,推进开源社区共建。
参考链接:
https://volcano.sh/zh/
https://github.com/volcano-sh/volcano
https://github.com/yeahdongcn/topology
更多技术干货,
请关注“360智汇云开发者”👇
360智汇云官网:https://zyun.360.cn(复制在浏览器中打开)
更多好用又便宜的云产品,欢迎试用体验~
添加工作人员企业微信👇,get更快审核通道+试用包哦~
