深入理解Docker和K8S
Docker 是大型架构的必备技能,也是云原生核心。Docker 容器化作为一种轻量级的虚拟化技术,其核心思想:将应用程序及其所有依赖项打包在一起,形成一个可移植的单元。
容器的本质是进程:
容器是在 Linux 宿主机上运行的一个进程,
- 容器的镜像中定义了容器启动时运行的程序。
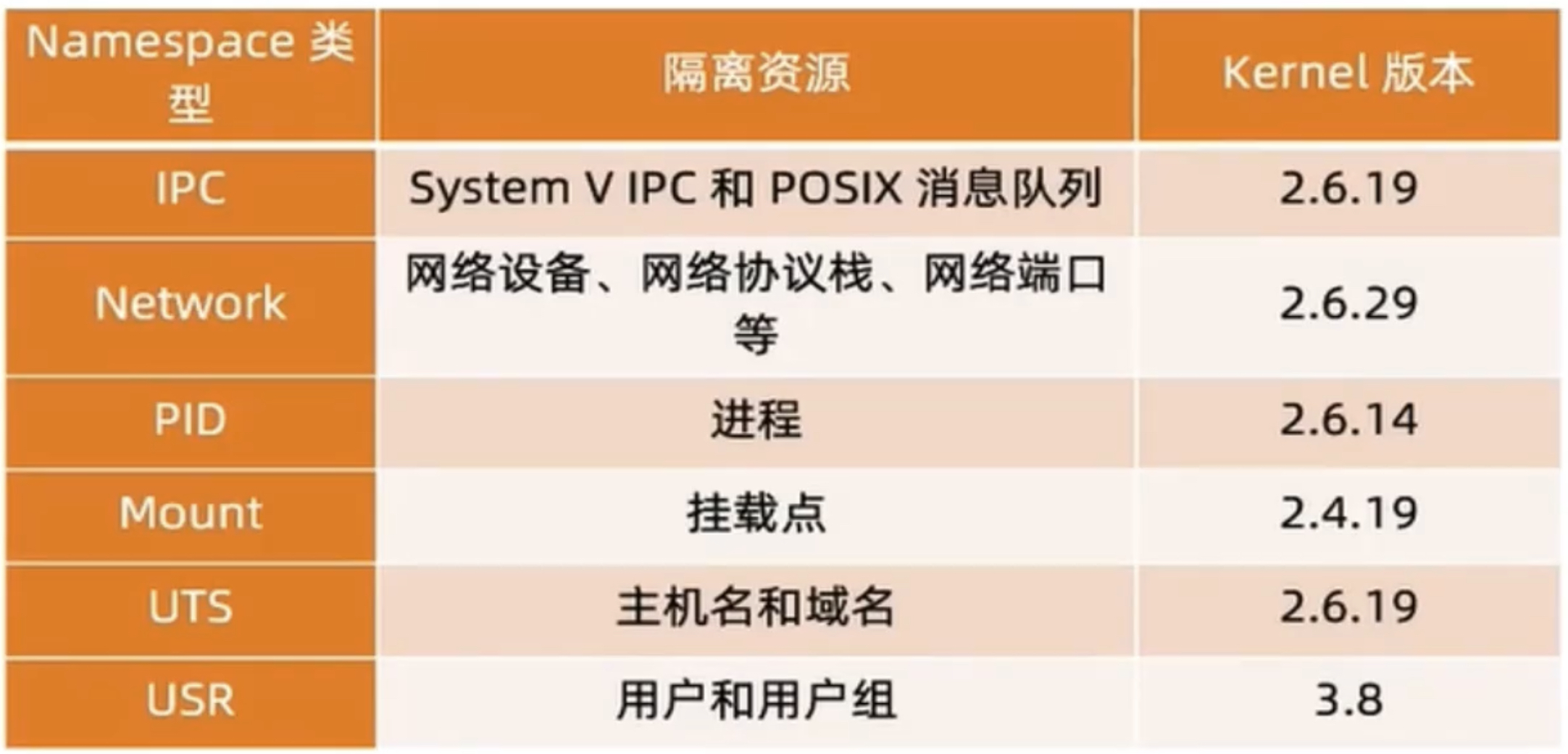
- 在启动时,被设置了新的 NameSpace、IPC、Network、PID、Mount、UTS,所以容器所能看到的进程,网络、磁盘挂载,都与宿主机不同。
通过 Linux 提供的三大核心机制实现:
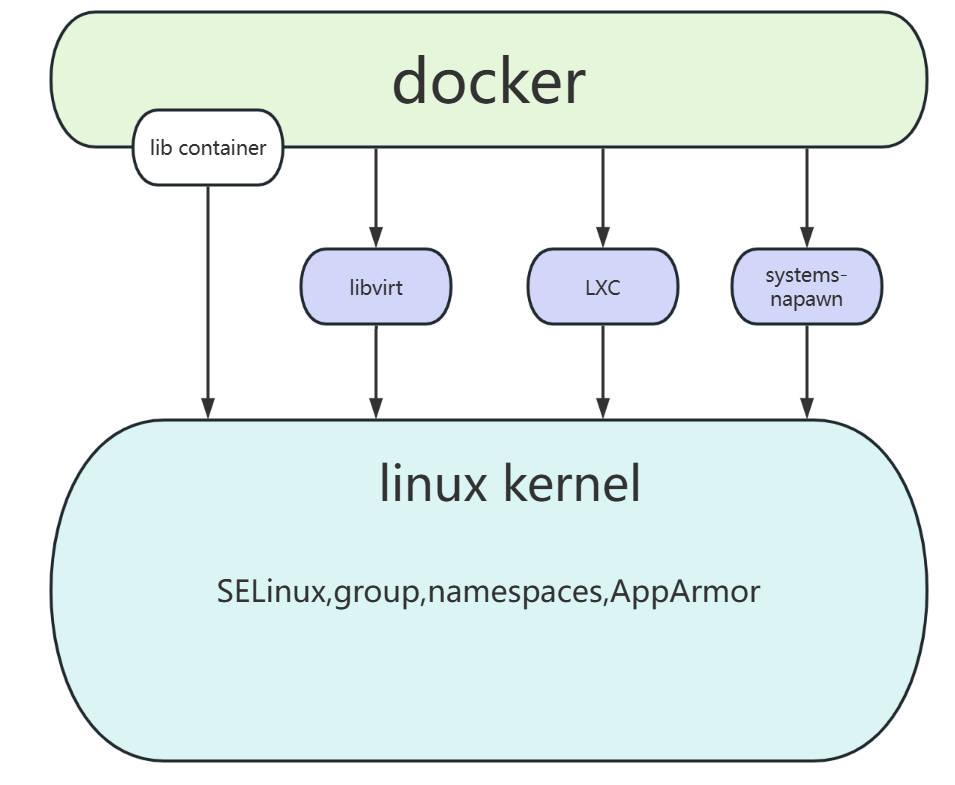
1.Namespace:实现资源隔离Namespace是Linux内核提供的资源隔离机制,为容器创建独立的系统资源视图,包括:PID Namespace:隔离进程ID,容器内进程只能看到本容器进程。Network Namespace:隔离网络栈,容器拥有独立的网络接口和IP。Mount Namespace:隔离文件系统挂载点,容器有独立文件系统视图。User Namespace:隔离用户和组ID,提升安全性。IPC、UTS等 Namespace:隔离进程间通信、主机名等资源。通过Namespace,Docker容器实现进程、网络、文件系统等多维度的隔离,保证容器间互不干扰。
2.Cgroups:资源限制与配额Cgroups是Linux内核的资源管理机制,用于限制和监控容器的资源使用,包括CPU、内存、磁盘I/O和网络带宽。它保证容器不会超出分配资源,防止资源争抢和系统过载。Cgroups支持资源优先级管理和统计监控,是Docker实现资源控制的基础。
3.UnionFS:镜像的分层文件系统UnionFS(联合文件系统)允许将多个只读镜像层叠加,形成一个统一的文件系统视图。每个镜像层存储相对于上一层的增量变化,支持镜像层的共享和复用。容器启动时,在镜像层之上添加可写层,实现写时复制(Copy-on-Write),保证镜像层只读且容器的文件变更隔离。
NameSpace 限制了容器能看到的世界:
Linux NameSpace:默认情况下,子进程会复制父进程的 NameSpace。
Cgroup 限制容器能够使用的资源:
Cgroup 能够对进程使用系统资源进行限制,以 CPU 资源、Memory 资源为例。
CPU资源:
1、限制容器的 CPU 资源使用:cpu.cfs_period_us调度周期(默认为 10000 us)、cpu.cfs_quota_us=-1不限制CPU使用份额、cpu_sharesCPU分配比例(多个容器竞争CPU资源时使用)。

2、容器运行后,会创建对应的/sys/fs/cgroup/cpu/docker/<CONTAINER ID>目录,用于 CPU 资源的控制组(cgroups)管理。以下是各个文件和目录的作用解释:
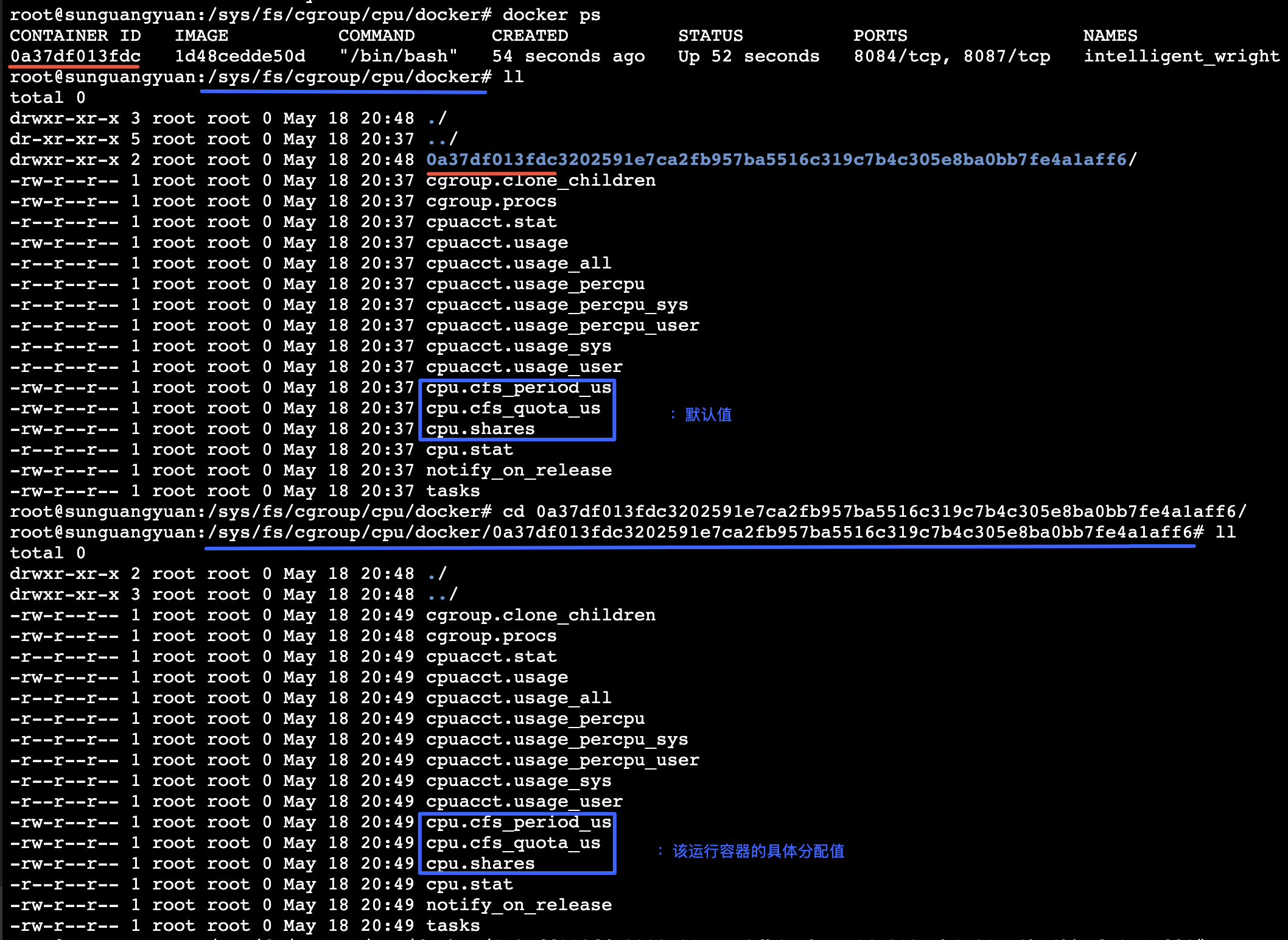
- cgroup.clone_children: 这个文件影响 clone() 系统调用,用于控制是否在创建新进程时复制父进程的 CPU 控制组设置。
- cgroup.procs: 包含当前 cgroup 中的所有进程 ID (PID)。这个文件可读可写,写入一个 PID 可以将该进程移动到这个 cgroup 中。
- cpuacct.stat: 报告这个 cgroup 中所有进程的 CPU 使用情况,包括用户态和内核态的使用时间。
- cpuacct.usage: 报告这个 cgroup 中所有进程的总 CPU 使用时间,以纳秒为单位。
- cpuacct.usage_all: 显示每个 CPU 的使用情况,包括用户态和内核态的使用时间。
- cpuacct.usage_percpu: 显示每个 CPU 核心的使用时间。
- cpuacct.usage_percpu_sys: 显示每个 CPU 核心的内核态使用时间。
- cpuacct.usage_percpu_user: 显示每个 CPU 核心的用户态使用时间。
- cpuacct.usage_sys: 报告这个 cgroup 中所有进程在内核态下的 CPU 使用时间。
- cpuacct.usage_user: 报告这个 cgroup 中所有进程在用户态下的 CPU 使用时间。
- cpu.cfs_period_us: 配合 cpu.cfs_quota_us 使用,定义 CPU 带宽控制的时间周期,以微秒为单位。
- cpu.cfs_quota_us: 定义 cgroup 在 cpu.cfs_period_us 周期内可以使用的 CPU 时间总量,以微秒为单位。通过设置这个值,可以限制 cgroup 的 CPU 使用带宽。
- cpu.shares: 定义 cgroup 的 CPU 分享数。值越高,cgroup 在竞争 CPU 资源时获得的优先级越高。
- cpu.stat: 提供一些 CPU 限制的统计信息,比如用户态和系统态下的等待时间。
- notify_on_release: 控制当 cgroup 的最后一个进程结束时,是否自动删除该 cgroup。设置为 1 表示启用通知,设置为 0 表示禁用。
- tasks: 包含当前 cgroup 中的所有线程 ID (TID)。与 cgroup.procs 类似,但包含线程而不是进程。
Memory资源:
1、限制容器的 Memory 资源使用:memory.limit_in_bytes限制容器可以使用的物理内存的上限、memory.oom_control容器超过内存上限的策略(默认为kill)

2、容器运行后,会创建对应的/sys/fs/cgroup/memory/docker/<CONTAINER ID>目录,用于 Memory 资源的控制组(cgroups)管理。以下是各个文件和目录的作用解释:
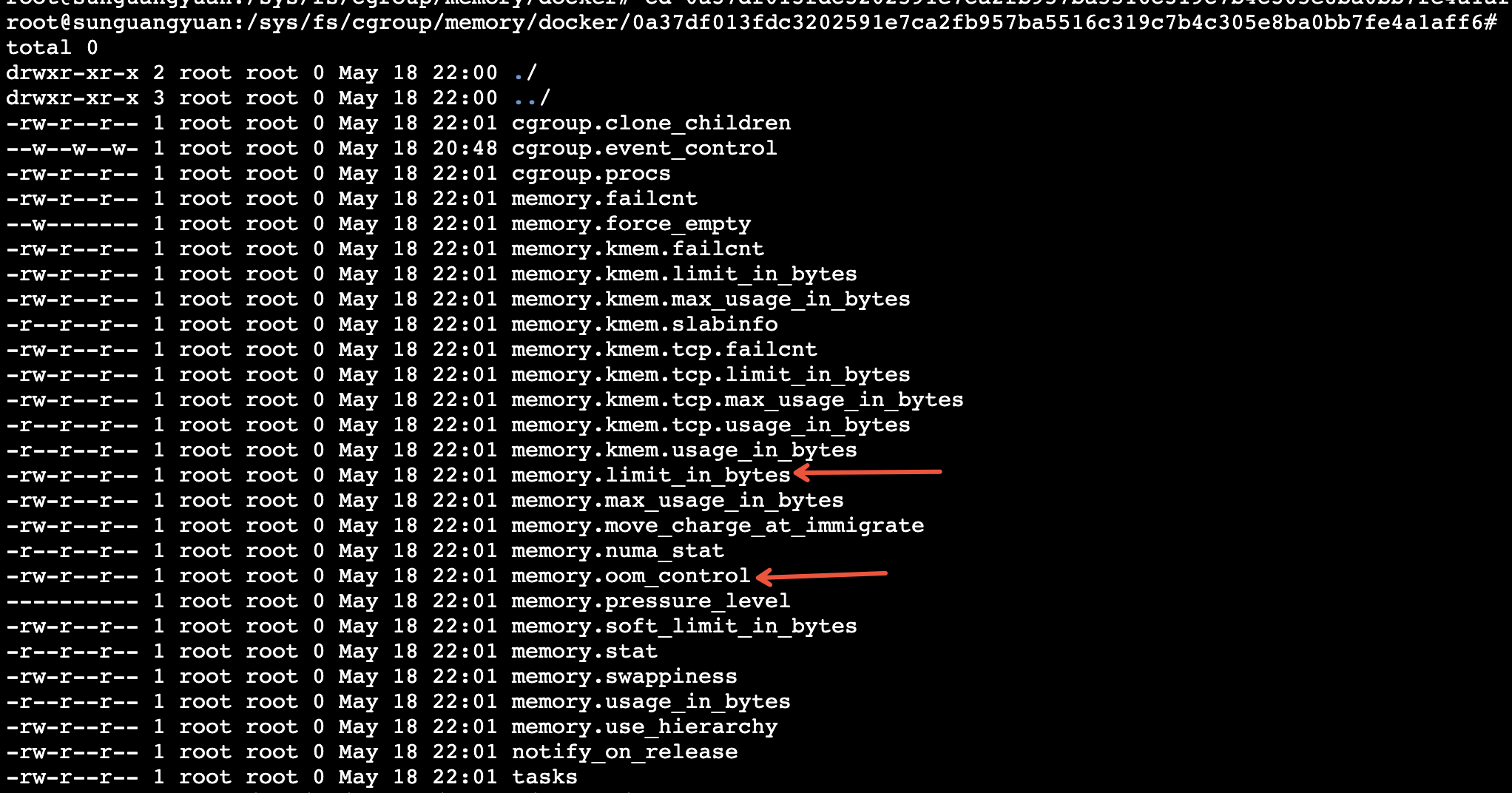
- cgroup.clone_children: 影响 clone() 系统调用,用于控制是否在创建新进程时复制父进程的内存控制组设置。
- cgroup.event_control: 用于事件控制,当某些条件满足时,可以触发用户空间的事件通知。
- cgroup.procs: 包含当前 cgroup 中的所有进程 ID (PID)。这个文件可读可写,写入一个 PID 可以将该进程移动到这个 cgroup 中。
- memory.failcnt: 记录内存资源分配失败的次数。
- memory.force_empty: 触发内存 cgroup 的强制清空。
- memory.kmem.failcnt: 记录内核内存分配失败的次数。
- memory.kmem.limit_in_bytes: 设置内核内存的使用限制,以字节为单位。
- memory.kmem.max_usage_in_bytes: 记录内核内存的最大使用量,以字节为单位。
- memory.kmem.slabinfo: 显示内核 slab 分配器的内存使用信息。
- memory.kmem.tcp.failcnt: 记录 TCP 缓冲相关的内核内存分配失败的次数。
- memory.kmem.tcp.limit_in_bytes: 设置 TCP 缓冲相关的内核内存的使用限制,以字节为单位。
- memory.kmem.tcp.max_usage_in_bytes: 记录 TCP 缓冲相关的内核内存的最大使用量,以字节为单位。
- memory.kmem.tcp.usage_in_bytes: 显示当前 TCP 缓冲相关的内核内存使用量,以字节为单位。
- memory.kmem.usage_in_bytes: 显示当前内核内存使用量,以字节为单位。
- memory.limit_in_bytes: 设置 cgroup 的内存使用限制,以字节为单位。
- memory.max_usage_in_bytes: 记录 cgroup 的最大内存使用量,以字节为单位。
- memory.move_charge_at_immigrate: 控制当进程移动到其他 cgroup 时,是否移动其内存使用量。
- memory.numa_stat: 显示 NUMA 节点相关的内存使用统计信息。
- memory.oom_control: 控制内存不足时的行为。
一旦容器内的进程占用内存超过限制,则可通过设置该字段让进程kill。 - memory.pressure_level: 用于监控内存压力水平,可以设置触发事件通知的阈值。
- memory.soft_limit_in_bytes: 设置内存的软限制,以字节为单位。超过软限制不会直接导致 OOM,但系统会尝试回收内存。
- memory.stat: 包含各种内存使用统计信息,如当前使用量、RSS、缓存等。
- memory.swappiness: 控制 cgroup 的交换倾向程度,值范围为 0-100。
- memory.usage_in_bytes: 显示当前内存使用量,以字节为单位。
- memory.use_hierarchy: 控制是否在计算内存使用时考虑子 cgroup。
- notify_on_release: 控制当 cgroup 的最后一个进程结束时,是否自动删除该 cgroup。设置为 1 表示启用通知,设置为 0 表示禁用。
- tasks: 包含当前 cgroup 中的所有线程 ID (TID)。与 cgroup.procs 类似,但包含线程而不是进程。
Overlay2文件系统:
overlay2 是一种堆叠文件系统,基于 Linux 内核的 OverlayFS 技术,依赖并建立在其他文件系统上,并不参与磁盘空间结构的划分,仅是将底层文件系统中的不同目录结构进行“合并”,然后向用户呈现。
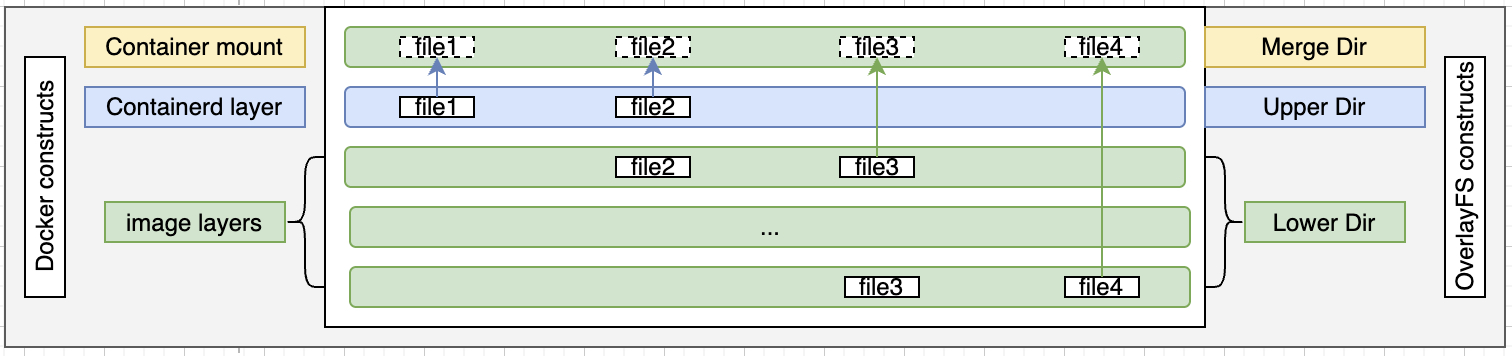
- 上层会覆盖下层相同的内容,故用户只能看到和操作 Merge 层,操作的变化会记录在 Upper 层,Lower 层是只读的。
- 用户创建新文件,则upper层会直接创建;删除文件,则在upper层创建一个“屏蔽”文件,屏蔽(whiteout)掉lower层的同名文件;修改文件内容,执行copy-on-write将lower层文件拷贝到upper层,保留原文件名只在upper层修改文件内容,并屏蔽(whiteout)掉lower层;修改文件名,执行copy-on-write将lower层文件拷贝到upper层,使用新文件名,并在upper层创建一个与原名相同的“屏蔽”文件用来屏蔽(whiteout)掉lower层。
Overlay2 是 Docker 默认使用的联合文件系统 UFS(Union Filesystem),用于管理容器镜像的分层存储和容器运行时文件系统的合并。
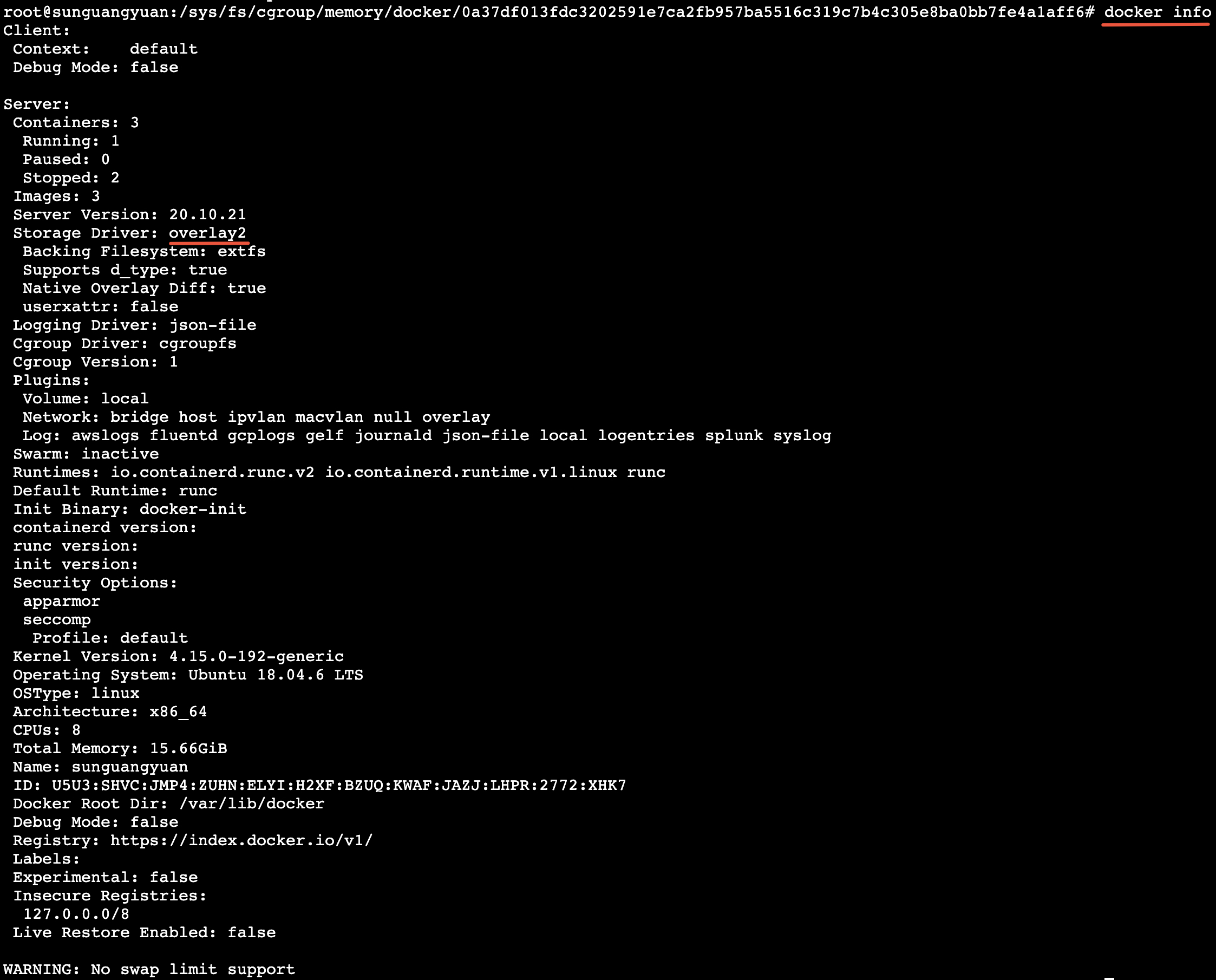
Overlay2 是 Docker 的分层存储引擎,通过联合挂载实现高效的文件管理。Docker 的 Overlay2 数据默认存储在 /var/lib/docker/overlay2/。当启动容器时,
- 镜像层(Lower Dir):所有镜像层按顺序堆叠(如 base-image → apt-get install → copy files)。
- 容器层(Upper Dir):镜像层之上创建的一个可写层,存储容器运行时的修改。
- 合并视图(Merged):将只读层和可写层合并,形成容器的完整文件系统。
Overlay2 的优点:
- 高效分层存储:多个容器共享相同的基础镜像层,节省空间。
- 写时复制(CoW):只有修改文件时才复制,减少磁盘 I/O。
- 性能较好:相比 aufs 和 devicemapper,Overlay2 是 Docker 推荐的存储驱动。