这篇文章的主要研究内容是介绍了一种名为 Visual Reinforcement Fine-Tuning (Visual-RFT) 的方法,旨在通过强化学习技术提升大型视觉语言模型(LVLMs)在视觉任务中的表现,尤其是在微调数据有限的情况下。以下是文章的核心内容总结:
1. 研究背景
大型推理模型(LRMs):如 OpenAI 的 o1,通过强化微调(Reinforcement Fine-Tuning, RFT)能够利用少量数据(数十到数千个样本)在特定领域任务中表现出色。然而,RFT 在视觉任务中的应用尚未得到充分探索。
现有问题:传统的监督微调(Supervised Fine-Tuning, SFT)依赖大量标注数据,数据效率低;而强化学习(RL)在视觉任务中的应用还比较有限。
2. Visual-RFT 方法
核心思想:将强化学习中的可验证奖励(Verifiable Rewards)应用于视觉任务,通过设计针对不同视觉任务的可验证奖励函数,结合策略优化算法(如 Group Relative Policy Optimization, GRPO),提升模型的视觉感知和推理能力。
具体实现:
使用大型视觉语言模型(LVLMs)为每个输入生成多个包含推理过程和最终答案的响应。
设计任务特定的可验证奖励函数,例如:
检测任务:基于交并比(IoU)和置信度的奖励函数。
分类任务:基于准确率和格式的奖励函数。
使用策略优化算法(如 GRPO)更新模型,通过试错学习优化模型输出。
3. 实验验证
实验任务:包括细粒度图像分类、少样本目标检测、推理定位和开放词汇目标检测。
实验结果:
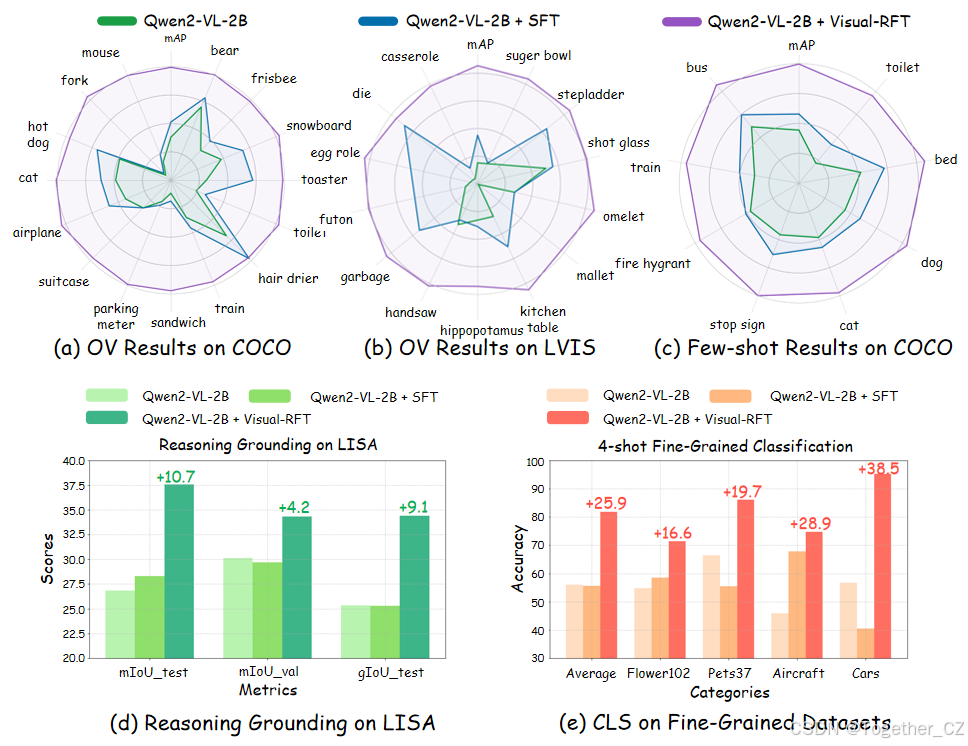
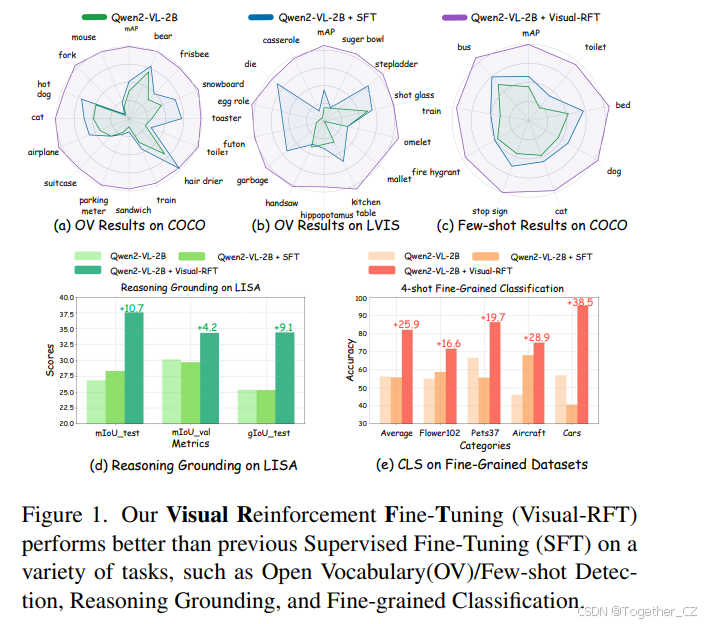
细粒度图像分类:在仅有一样本数据的情况下,Visual-RFT 的准确率比基线提高了 24.3%,而 SFT 则下降了 4.3%。
少样本目标检测:在 COCO 数据集的两样本设置中,Visual-RFT 超过了基线 21.9;在 LVIS 数据集上超过了 15.4。
推理定位:在 LISA 数据集上,Visual-RFT 在边界框 IoU 和分割掩膜 gIoU 上显著优于 SFT。
开放词汇目标检测:在 COCO 的 15 个新类别和 LVIS 的 13 个稀有类别上,Visual-RFT 的 mAP 提升显著,甚至在一些原本无法识别的类别上实现了从 0 到 1 的突破。
4. 关键结论
数据效率:Visual-RFT 在有限数据下表现出色,显著优于传统的监督微调(SFT)。
泛化能力:Visual-RFT 能够快速适应新任务和新类别,展现出强大的泛化能力。
推理能力:通过强化学习,模型能够生成详细的推理过程,提升视觉任务的性能。
开源贡献:作者开源了训练代码、数据和评估脚本,方便后续研究。
5. 创新点
首次将强化学习应用于视觉任务:将 DeepSeek R1 风格的强化学习扩展到视觉领域,填补了这一领域的研究空白。
设计多种可验证奖励函数:为不同视觉任务设计了高效的奖励函数,简化了奖励计算过程。
显著提升性能:在多个视觉任务上取得了显著的性能提升,尤其是在少样本和开放词汇任务中。
6. 研究意义
推动多模态模型的发展:为 LVLMs 在视觉任务中的应用提供了新的思路和方法。
提高模型的适应性和泛化能力:使模型能够在数据稀缺的情况下快速适应新任务,具有重要的实际应用价值。
这篇文章通过引入 Visual-RFT 方法,展示了强化学习在提升视觉语言模型性能方面的巨大潜力,为未来的研究和应用提供了新的方向。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:
官方项目地址在这里,如下所示:
官方使用到的数据集如下:
| Datasets | Task | Setting | Description |
|---|---|---|---|
| laolao77/ViRFT_COCO | Detection | - | It includes all categories from COCO, with a total of 6k entries. |
| laolao77/ViRFT_COCO_base65 | Detection | Open Vocabulary | It includes 65 basic categories from COCO, with a total of 6k entries. |
| laolao77/ViRFT_COCO_8_cate_4_shot | Detection | Few-shot | It includes 8 selected categories from COCO. |
| laolao77/ViRFT_LVIS_few_shot | Detection | Few-shot | It includes 6 selected categories from COCO. |
| laolao77/ViRFT_CLS_flower_4_shot | Classification | Few-shot | It includes the 102 categories from the Flower102 dataset, with 4 images per category. |
| laolao77/ViRFT_CLS_fgvc_aircraft_4_shot | Classification | Few-shot | It includes the 100 categories from the FGVC-Aircraft dataset, with 4 images per category. |
| laolao77/ViRFT_CLS_car196_4shot | Classification | Few-shot | It includes the 196 categories from the Stanford Cars dataset, with 4 images per category. |
| laolao77/ViRFT_CLS_pets37_4shot | Classification | Few-shot | It includes the 37 categories from the Pets37 dataset, with 4 images per category. |
| LISA dataset | Grounding | - | Reasoning Grounding |
摘要
强化微调(Reinforcement Fine-Tuning, RFT)在大型推理模型(如 OpenAI 的 o1)中通过对其回答的反馈进行学习,这在微调数据稀缺的应用中尤其有用。最近的开源工作(如 DeepSeekR1)表明,带有可验证奖励的强化学习是复现 o1 的关键方向之一。尽管 R1 风格的模型在语言模型中取得了成功,但其在多模态领域的应用仍待探索。本工作引入了视觉强化微调(Visual Reinforcement Fine-Tuning, Visual-RFT),进一步将 RFT 的应用范围扩展到视觉任务。具体而言,Visual-RFT 首先使用大型视觉语言模型(Large Vision-Language Models, LVLMs)为每个输入生成包含推理标记和最终答案的多个响应,然后通过我们提出的视觉感知可验证奖励函数,结合策略优化算法(如 Group Relative Policy Optimization, GRPO)更新模型。我们为不同的感知任务设计了不同的可验证奖励函数,例如为对象检测任务设计了交并比(Intersection over Union, IoU)奖励。在细粒度图像分类、少样本目标检测、推理定位以及开放词汇目标检测基准测试中的实验结果表明,与监督微调(Supervised Fine-tuning, SFT)相比,Visual-RFT 具有竞争力的表现和卓越的泛化能力。例如,在仅包含约 100 个样本的单样本细粒度图像分类中,Visual-RFT 的准确率比基线提高了 24.3%。在少样本目标检测中,Visual-RFT 在 COCO 的两样本设置中超过了基线 21.9,在 LVIS 中超过了 15.4。我们的 Visual-RFT 代表了微调 LVLMs 的范式转变,提供了一种数据高效、奖励驱动的方法,增强了推理能力和对特定领域任务的适应性。
关键词:视觉强化微调、多模态任务、可验证奖励、策略优化、泛化能力
1. 引言
大型推理模型(LRMs)如 OpenAI 的 o1 [7] 是一种前沿的人工智能模型,旨在回答问题之前花费更多时间“思考”,并展现出卓越的推理能力。OpenAI o1 的一项令人印象深刻的能力是强化微调(RFT),它能够仅使用数十到数千个样本来高效地微调模型,使其在特定领域任务中表现出色。尽管 o1 的实现细节并未公开,但最近的开源研究(如 DeepSeek R1 [4])揭示了复现 o1 的一个有前景的方向是可验证奖励 [4, 12, 37]:强化学习中的奖励分数由预定义的规则直接确定,而不是由单独的奖励模型 [17, 26, 45] 在偏好数据上训练得出。RFT 与之前的监督微调(SFT)的主要区别在于数据效率。之前的 SFT 范式(见图 2(a))直接模仿高质量、精心策划的数据中提供的“真实”答案,因此依赖于大量的训练数据。相比之下,RFT 通过评估模型的回答并根据其正确性进行调整,帮助模型通过试错学习。因此,RFT 特别适用于数据稀缺的领域 [7, 24]。
然而,一个常见的误解是 RFT 仅应用于科学(例如数学)和代码生成任务。这是因为数学和编程具有清晰且客观的最终答案或测试用例,使得其奖励相对容易验证。在本文中,我们证明了 RFT 可以应用于视觉感知任务,而不仅仅是数学和代码领域。具体而言,我们引入了视觉强化微调(Visual Reinforcement Fine-Tuning, Visual-RFT),成功地将 RFT 扩展到为大型视觉语言模型(LVLMs)在各种多模态任务(见图 1)中赋能,例如少样本分类和开放词汇目标检测。
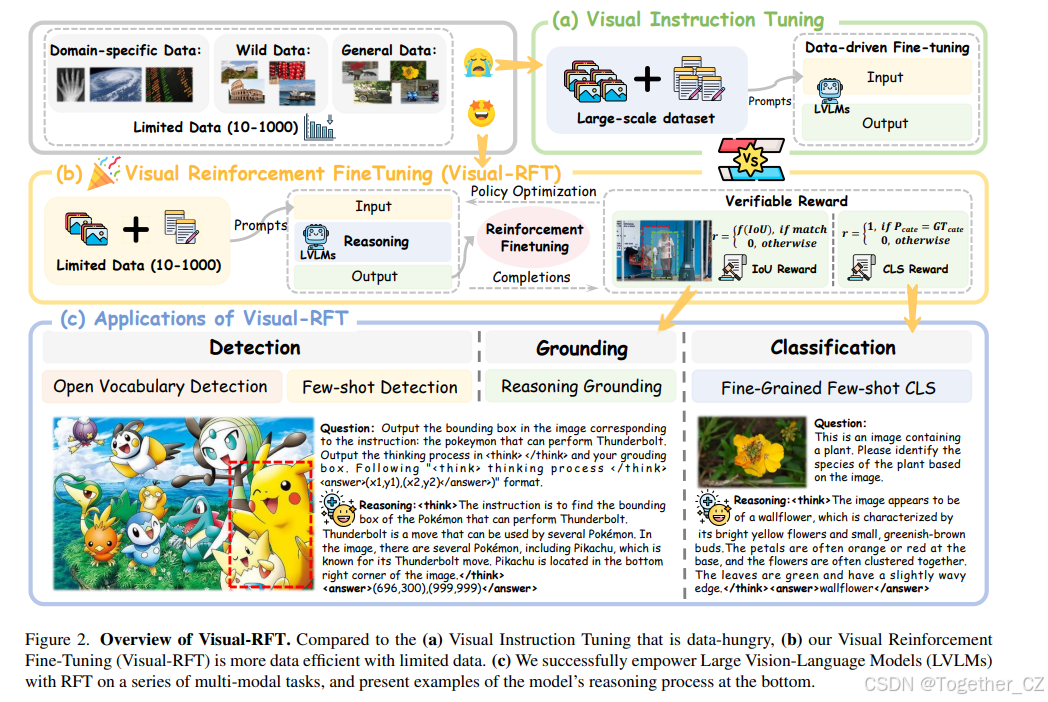
为了在视觉任务上扩展 RFT,我们在图 2(b)中展示了 Visual-RFT 的实现细节。对于每个输入,Visual-RFT 使用大型视觉语言模型(LVLMs)生成多个响应(轨迹),其中包含推理标记和最终答案。至关重要的是,我们定义了针对特定任务的基于规则的可验证奖励函数,以指导策略优化,例如 GRPO [31],用于更新模型。例如,我们为对象检测任务提出了交并比(IoU)奖励。与依赖于记忆正确答案的 SFT 相比,我们的方法探索不同的可能解决方案,并学习优化由我们的验证奖励函数定义的期望结果。这不是仅仅模仿预定义答案,而是发现什么是最有效的。我们的方法将训练范式从 SFT 的数据扩展转变为针对特定多模态任务设计可变奖励函数的战略。如图 2(c)所示,可验证奖励与视觉感知能力(例如检测、定位、分类)的协同组合,使我们的模型能够通过详细的推理过程快速且高效地掌握新概念。
我们在以下任务中验证了 Visual-RFT 的有效性。在细粒度图像分类中,模型利用其先进的推理能力高精度地分析细粒度类别。在仅包含极有限数据(例如约 100 个样本)的单样本设置中,Visual-RFT 将准确率提高了 24.3%,而 SFT 则下降了 4.3%。在少样本实验中,Visual-RFT 展示了卓越的少样本学习能力,与 SFT 相比具有显著优势。在推理定位中,Visual-RFT 在 LISA [11] 数据集上表现出色,该数据集严重依赖推理,超过了专门的模型(如 GroundedSAM [18])。此外,在开放词汇目标检测中,Visual-RFT 快速将识别能力转移到新类别,包括 LVIS [5] 中的稀有类别,显示出强大的泛化能力。具体而言,2B 模型在 COCO [15] 的新类别上从 9.8 提高到 31.3,在 LVIS [5] 的选定稀有类别上从 2.7 提高到 20.7。这些多样化的视觉感知任务不仅突出了 Visual-RFT 在视觉识别中的强大泛化能力,还强调了强化学习在增强视觉感知和推理中的关键作用。总之,我们的主要贡献如下:(1)我们引入了视觉强化微调(Visual-RFT),它将带有可验证奖励的强化学习扩展到视觉感知任务,这些任务在微调数据有限的情况下非常有效。(2)我们为不同的视觉任务设计了不同的可验证奖励,使得能够在极低的成本下高效、高质量地计算奖励。这使得 DeepSeek R1 风格的强化学习能够无缝转移到 LVLMs。(3)我们在各种视觉感知任务上进行了广泛的实验,包括细粒度图像分类、少样本目标检测、推理定位和开放词汇目标检测。在所有设置中,Visual-RFT 都取得了显著的性能提升,显著超过了监督微调基线。(4)我们在 Github 上完全开源了训练代码、训练数据和评估脚本,以促进进一步的研究。
2. 相关工作
大型视觉语言模型(LVLMs)如 GPT4o [23] 通过整合视觉和文本数据实现了卓越的视觉理解能力。这种整合增强了模型处理复杂多模态输入的能力,并使得更先进的 AI 系统 [13, 16, 38, 47] 能够处理和响应图像和文本。一般来说,LVLMs 的训练涉及两个步骤:(a)预训练和(b)后训练,其中包含监督微调和强化学习。后训练对于提高模型的响应质量、指令遵循和推理能力至关重要。尽管在使用强化学习增强 LLMs 的后训练阶段已经进行了大量研究 [1, 3, 25, 28, 32, 33, 36, 40, 44, 52, 53],但对于 LVLMs 的进展却较为缓慢。在本文中,我们提出了 Visual-RFT,它在后训练阶段使用基于 GRPO 的强化算法和可验证奖励来增强模型的视觉感知和推理能力。最近,随着像 OpenAI 的 o1 [7] 这样的推理模型的出现,大型语言模型(LLMs)的研究重点越来越多地转向通过强化学习(RL)技术增强模型的推理能力。研究已经探索了在推理任务中提高 LLMs 性能的方法,例如解决数学问题 [2, 20, 31, 39, 41] 和编程 [6, 8, 46, 48]。这一领域的显著突破是 Deepseek-R1-Zero [4],它引入了一种仅使用 RL 实现强大推理能力的新方法,消除了监督微调(SFT)阶段。然而,目前基于 RL 的推理研究大多局限于语言领域,对其在多模态设置中的应用探索有限。对于 LVLMs,RL 主要用于诸如减少幻觉和使模型与人类偏好对齐等任务 [19, 34, 35, 42, 43, 49–51],但在专注于增强大型视觉语言模型的推理和视觉感知的研究方面仍存在显著差距。为了弥合这一差距,我们的工作引入了一种新颖的强化微调策略 Visual-RFT,将带有可验证奖励的基于 GRPO [31] 的 RL 应用于广泛的视觉感知任务。我们的方法旨在提高 LVLMs 在处理各种视觉任务时的性能,尤其是在微调数据有限的情况下。
3. 方法论
3.1. 前提
带有可验证奖励的强化学习。带有可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)[4, 12, 37] 是一种新颖的训练方法,旨在增强语言模型在具有客观可验证结果的任务中的表现,例如数学和编程。与依赖于训练有素的奖励模型的强化学习人类反馈(Reinforcement Learning from Human Feedback, RLHF)[17, 26, 45] 不同,RLVR 使用直接验证函数来评估正确性。这种方法简化了奖励机制,同时保持了与任务固有正确性标准的强烈一致性。给定输入问题 q,策略模型 πθ 生成响应 o 并获得可验证奖励。更具体地说,RLVR 优化以下目标:

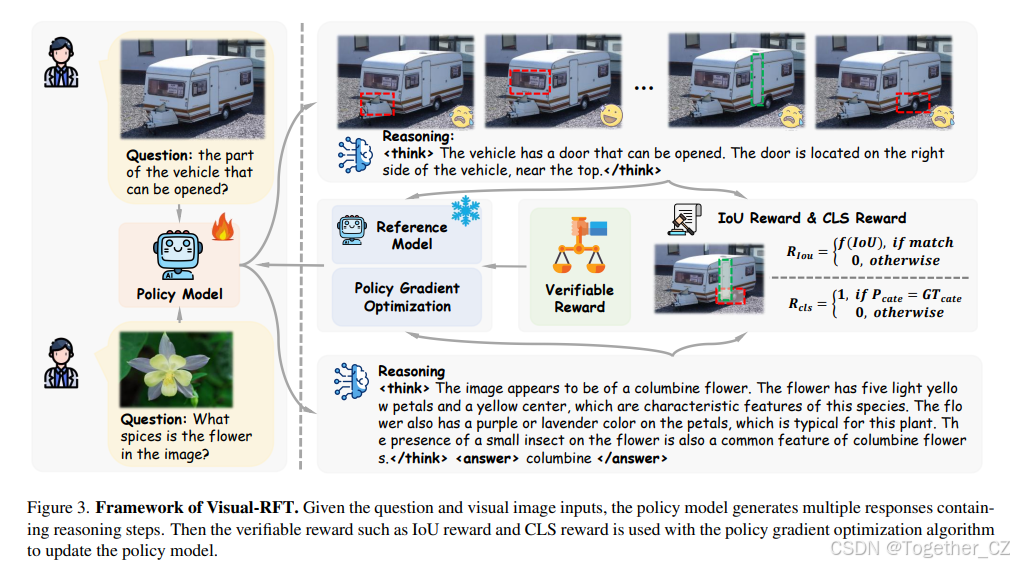
3.2. Visual-RFT
Visual-RFT 的框架如图 3 所示。用户提供的多模态输入数据包括图像和问题。策略模型 πθ 根据输入输出推理过程并生成一组响应。每个响应都通过可验证奖励函数计算奖励。在对每个输出进行组奖励计算后,评估每个响应的质量,并用于更新策略模型。为了确保策略模型训练的稳定性,Visual-RFT 使用 KL 散度限制策略模型与参考模型之间的差异。我们将在第 3.2.1 节中进一步讨论如何为视觉任务设计可验证奖励,并在第 3.2.2 节中讨论数据准备步骤。

3.2.1. 视觉感知中的可验证奖励
奖励模型是强化学习(RL)中的关键步骤,它与偏好对齐算法对齐,可以简单到检查预测与真实答案之间是否完全匹配的验证函数。最近 DeepSeek-R1 [4] 模型的 RL 训练过程通过可验证奖励设计显著提高了模型的推理能力。为了将这一策略转移到视觉领域,我们为各种视觉感知任务设计了不同的基于规则的可验证奖励函数。



3.2.2. 数据准备
为了在各种视觉感知任务上训练 Visual-RFT,我们需要构建多模态训练数据集。与 DeepSeek-R1 类似,为了增强模型的推理能力并将其应用于提高视觉感知,Visual-RFT 设计了一种提示格式,以指导模型在提供最终答案之前输出其推理过程。用于检测和分类任务的提示如表 1 所示。在训练过程中,我们使用格式奖励引导模型以结构化的格式输出其推理过程和最终答案。推理过程是模型在强化微调过程中自我学习和改进的关键,而由答案决定的奖励则指导模型的优化。
4. 实验
4.1. 实验设置
实现细节:我们的方法适用于各种视觉感知任务。我们采用少样本学习方法,为模型提供最少数量的样本进行训练。对于图像分类和目标检测任务,我们采用少样本设置来评估模型的细粒度辨别和识别能力,并在有限的数据上应用强化学习。然后,对于专注于推理定位的 LISA [11] 数据集,该任务需要强大的推理能力,我们使用 Visual-RFT 训练模型并评估其推理和感知性能。最后,对于开放词汇目标检测,我们通过在 COCO 数据集的 65 个基础类别上训练 Qwen2-VL-2/7B [38] 来评估模型的泛化能力,并在 COCO 的 15 个新类别和 LVIS [5] 的 13 个稀有类别上进行测试。模型的视觉感知和推理能力在开放词汇检测设置中进行评估。在我们的检测实验中,我们首先提示模型检查图像中是否存在该类别,然后为图像中存在的类别预测边界框。
4.2. 少样本分类
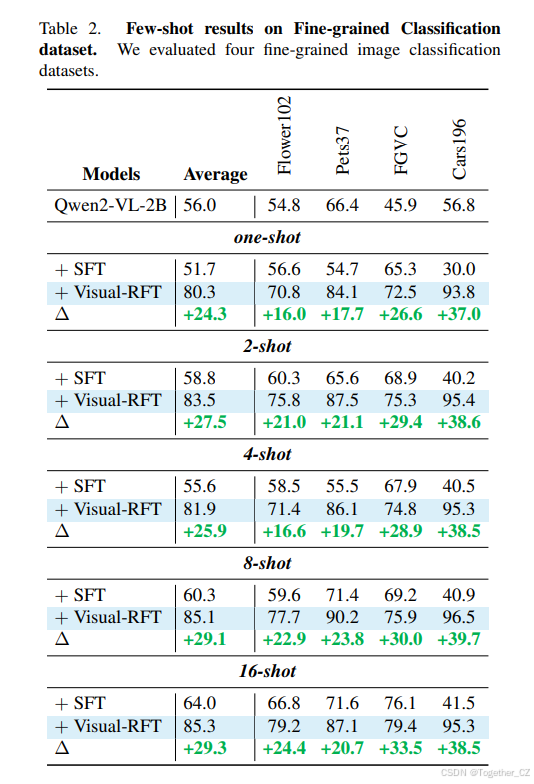
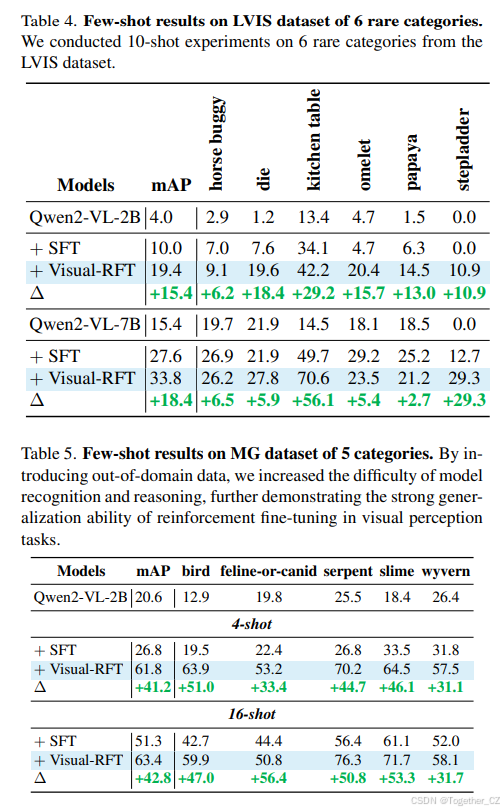
为了展示 Visual-RFT 在视觉领域的广泛泛化能力,我们在细粒度图像分类上进行了少样本实验。我们选择了四个数据集:Flower102 [22]、Pets37 [27]、FGVCAircraft [21] 和 Car196 [10],这些数据集包含数十到数百个相似类别,为分类任务增加了显著的难度。如表 2 所示,在仅有一样本数据的情况下,Visual-RFT 已经实现了显著的性能提升(+24.3%)。相比之下,SFT 在相同数量的有限数据下表现出了明显的下降(-4.3%)。在 4-shot 设置下,SFT 的性能仍然略低于基线,而经过 Visual-RFT 强化微调的模型平均性能提升了 25.9。随着数据量的增加,在 8-shot 和 16-shot 设置下,SFT 的性能略微超过了基线,但仍然显著落后于 Visual-RFT 的性能。在图 4 中,我们展示了一些经过强化微调的模型在处理细粒度分类任务时的推理案例。这些结果不仅展示了 Visual-RFT 的强大泛化能力以及其从有限数据中学习的能力,还证实了与 SFT 相比,强化微调导致了对任务更深入的理解和更深入的学习。
4.3. 少样本目标检测
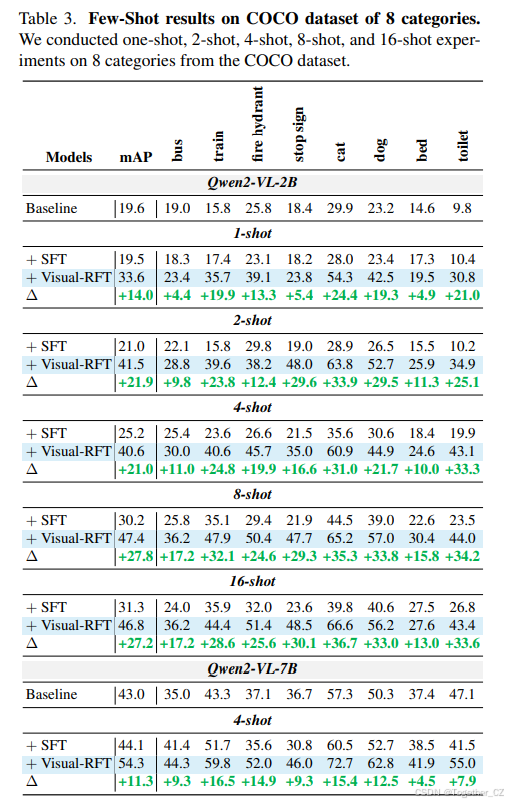
少样本学习一直是传统视觉模型和大型视觉语言模型(LVLMs)面临的挑战之一。强化微调为这一问题提供了新的解决方案,使模型能够通过少量数据快速学习和理解。我们从 COCO 数据集中选择了八个类别,每个类别分别有 1、2、4、8 和 16 张图像,构建了有限数据的训练集。对于 LVIS 数据集,我们选择了 6 个稀有类别。由于这些稀有类别的训练图像非常稀疏,每个类别有 1 到 10 张图像,我们将此近似为 10-shot 设置。然后我们使用强化微调和 SFT 训练 Qwen2-VL-2/7B 模型 200 步,以评估模型在有限数据下的学习能力。如表 3 和表 4 所示,尽管 SFT 和强化微调都可以在少样本设置下提高模型的识别准确率,但经过强化微调的模型始终显著优于 SFT 模型,并保持显著领先。在 COCO [15] 类别上,随着训练数据的增加,SFT 模型的平均 mAP 接近 31,而经过强化微调的模型接近 47。在表 4 所示的 LVIS [5] 少样本实验结果中,对于 LVIS 中更具挑战性的 6 个稀有类别,强化微调仍然优于 SFT。表 3 和表 4 中的结果清楚地表明了强化微调在少样本设置中的卓越表现,模型通过强化学习仅使用少量数据就实现了视觉感知能力的显著提升。
4.4. 推理定位
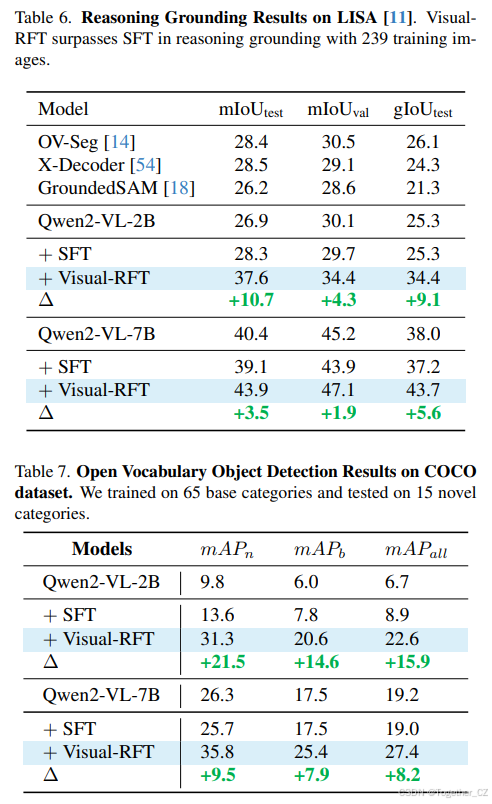
视觉语言智能的另一个关键方面是根据用户需求精确定位对象。以前的专用检测系统缺乏推理能力,无法完全理解用户的意图。以 LISA [11] 为先驱,已经有工作致力于使大型语言模型(LLMs)输出控制标记以供其他模型(如 SAM [9])使用,或者直接通过监督微调预测边界框坐标 [29, 38]。在我们的工作中,我们探索了在这一任务中使用 Visual-RFT,并发现强化学习(RL)比监督微调有显著提升。我们在 LISA 训练集上对 Qwen2-VL 2B/7B 模型 [38] 进行了强化微调和监督微调(SFT),该训练集包含 239 张具有推理定位对象的图像。我们遵循 LISA 的相同测试设置,并比较了 SFT 和我们方法的结果,两者都进行了 500 步微调。如表 6 所示,Visual-RFT 在边界框 IoU 方面显著提高了最终结果,与 SFT 相比。此外,我们使用 Qwen2-VL 预测的边界框提示 SAM [9] 以生成分割掩膜(使用 gIoU 进行评估)。Visual-RFT 显著增强了定位能力,并优于以前的专用检测系统。定性结果如图 5 所示,推理过程显著提高了推理和定位精度。通过 Visual-RFT,Qwen2-VL 学会了批判性思考,并仔细检查图像以产生准确的定位结果。
4.5. 开放词汇目标检测
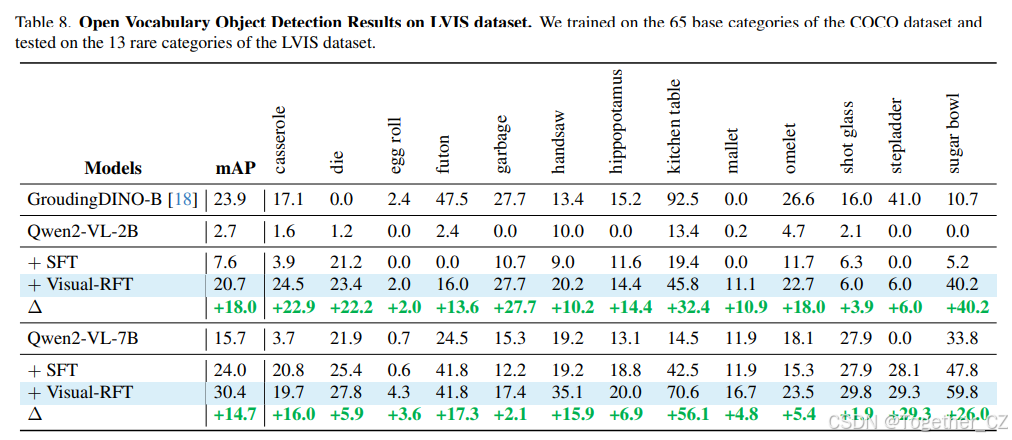
Visual-RFT 优于 SFT 的优势在于前者对任务的真正深入理解,而不仅仅是记忆数据。为了进一步展示强化微调的强大泛化能力,我们进行了开放词汇目标检测实验。我们首先从 COCO 数据集中随机抽取了 6K 个注释,其中包括 65 个基础类别。我们使用这些数据对 Qwen2-VL-2/7B 模型 [38] 进行了 Visual-RFT 和 SFT 训练,并在模型从未见过的 15 个新类别上进行了测试。为了增加难度,我们进一步测试了 LVIS [5] 数据集中的 13 个稀有类别。如表 7 和表 8 所示,经过强化微调后,Qwen2-VL-2/7B 模型在 COCO 数据集的 15 个新类别上平均 mAP 提高了 21.5,在更具挑战性的 LVIS [5] 稀有类别上 mAP 提高了 18.0。Visual-RFT 不仅将检测能力从 COCO 基础类别转移到新的 COCO 类别,还在更具挑战性的 LVIS 稀有类别上实现了显著提升。值得注意的是,在表 8 中的一些稀有 LVIS 类别中,原始或经过 SFT 训练的模型无法识别这些类别,导致 AP 为 0。然而,经过强化微调后,模型在识别这些以前无法识别的类别上实现了从 0 到 1 的质的飞跃(例如蛋卷和 futon)。这表明 Visual-RFT 对于提高 LVLMs 在视觉识别中的性能和泛化能力具有显著影响。
5. 结论
在本文中,我们介绍了视觉强化微调(Visual Reinforcement Fine-Tuning, Visual-RFT),这是首次将基于 GRPO 的强化学习策略应用于增强大型视觉语言模型(LVLMs)的视觉感知和定位能力。通过使用基于规则的可验证奖励系统,Visual-RFT 减少了对人工标注的需求,简化了奖励计算,并在各种视觉感知任务中实现了显著的改进。广泛的实验表明,Visual-RFT 在细粒度分类、开放词汇检测、推理定位和少样本学习任务中表现出色。它在有限的数据下优于监督微调(SFT),并显示出强大的泛化能力。这项工作展示了强化学习增强 LVLMs 能力的潜力,使其在视觉感知任务中更加高效和有效。