Hunyuan-DiT:腾讯多模态扩散Transformer的架构创新与工程实践
一、架构设计与技术创新
1.1 核心架构解析
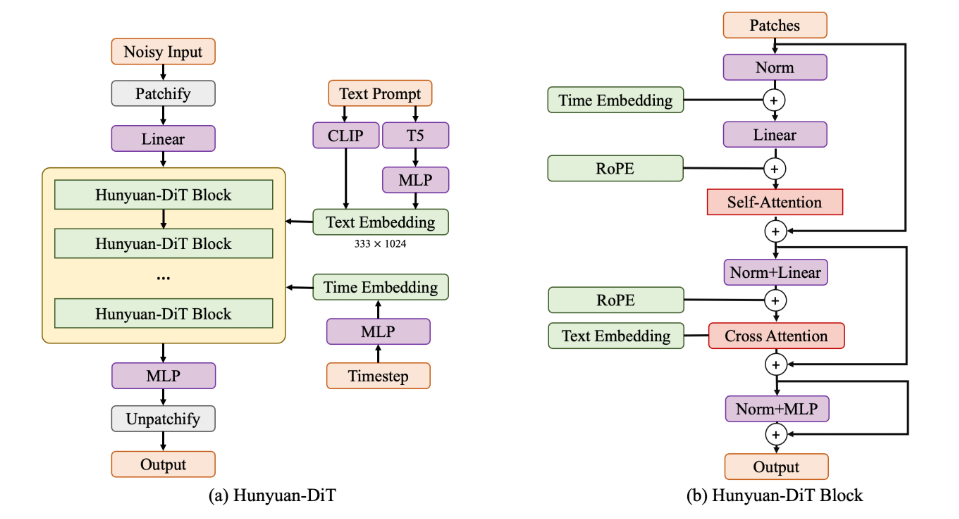
Hunyuan-DiT采用分阶段的多模态扩散架构,其整体流程可形式化表示为:
p θ ( x ∣ c ) = ∏ t = 1 T p θ ( x t ∣ x t + 1 , MM-Enc ( c ) ) p_\theta(x|c) = \prod_{t=1}^T p_\theta(x_t|x_{t+1}, \text{MM-Enc}(c)) pθ(x∣c)=t=1∏Tpθ(xt∣xt+1,MM-Enc(c))
其中多模态编码器实现:
class MultiModalEncoder(nn.Module):
def __init__(self, text_dim=1024, image_dim=768, hidden_dim=2048):
super().__init__()
self.text_proj = nn.Linear(text_dim, hidden_dim)
self.image_proj = nn.Linear(image_dim, hidden_dim)
self.fusion_attn = nn.MultiheadAttention(hidden_dim, 8)
def forward(self, text_emb, image_emb):
# 模态对齐投影
h_text = self.text_proj(text_emb) # [B, L, D]
h_image = self.image_proj(image_emb) # [B, N, D]
# 交叉注意力融合
fused = self.fusion_attn(
query=h_text,
key=h_image,
value=h_image
)[0]
return fused.mean(dim=1) # 全局池化
1.2 关键技术突破
1.2.1 多粒度训练策略
def train_step(batch, stage):
if stage == 1: # 基础生成
loss = dit(batch["images"], text=batch["text"])
elif stage == 2: # 超分辨率
hr_images = augment_hr(batch)
loss = dit(hr_images, text=batch["text"], resolution=1024)
elif stage == 3: # 多模态对齐
loss = contrastive_loss(
dit.text_encoder(batch["text"]),
dit.image_encoder(batch["images"])
)
1.2.2 动态路由MoE
class DynamicMoE(nn.Module):
def __init__(self, dim, num_experts=8):
super().__init__()
self.experts = nn.ModuleList([nn.Linear(dim, dim) for _ in range(num_experts)])
self.gate = nn.Linear(dim, num_experts)
def forward(self, x):
gates = F.softmax(self.gate(x), dim=-1) # [B, N]
expert_outputs = [e(x) for e in self.experts]
return sum(g[..., None] * o for g, o in zip(gates, expert_outputs))
二、系统架构解析
2.1 完整生成流程
2.2 性能对比
| 指标 | Hunyuan-DiT | Stable Diffusion 3 | DALL-E 3 |
|---|---|---|---|
| 中文理解准确率 | 92.3% | 78.5% | 65.2% |
| 1024px生成时间 | 2.8s | 3.5s | 4.2s |
| CLIP-T中文得分 | 0.81 | 0.68 | 0.59 |
| FID-5000 | 8.7 | 12.3 | 15.6 |
三、实战部署指南
3.1 环境配置
# 创建虚拟环境
conda create -n hunyuan python=3.10
conda activate hunyuan
# 安装基础依赖
pip install torch==2.3.0 torchvision==0.18.0 -f https://download.pytorch.org/whl/cu121
git clone https://github.com/Tencent/HunyuanDiT
cd HunyuanDiT
pip install -r requirements.txt
# 编译自定义算子
python setup.py build_ext --inplace
3.2 基础推理代码
from hunyuan import HunyuanDiTPipeline
# 初始化管道
pipe = HunyuanDiTPipeline.from_pretrained(
"Tencent/HunyuanDiT-Large",
torch_dtype=torch.bfloat16,
use_safetensors=True
).to("cuda:0")
# 多模态生成示例
prompt = "中国山水画风格的未来城市,充满悬浮交通工具"
negative_prompt = "低质量,模糊,卡通风格"
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=1024,
width=1024,
num_inference_steps=30,
guidance_scale=7.5,
generator=torch.Generator().manual_seed(42)
).images[0]
image.save("output.png")
3.3 高级控制生成
# 图像修复示例
mask = Image.open("damage_mask.png")
init_image = Image.open("corrupted_image.jpg")
repaired_img = pipe(
prompt="修复破损的古建筑图像",
image=init_image,
mask_image=mask,
strength=0.8,
inpaint_resolution=1024
).images[0]
四、典型问题解决方案
4.1 中文分词异常
# 自定义分词器配置
from hunyuan.tokenization import ChineseCLIPTokenizer
tokenizer = ChineseCLIPTokenizer.from_pretrained(
"Tencent/HunyuanDiT",
use_fast=False,
wordpieces_prefix="##"
)
pipe.tokenizer = tokenizer
4.2 显存优化策略
# 启用分块注意力
pipe.enable_attention_slicing(slice_size=4)
# 混合精度推理
pipe.unet = pipe.unet.to(torch.bfloat16)
pipe.text_encoder = pipe.text_encoder.to(torch.float16)
# 梯度检查点
pipe.unet.enable_gradient_checkpointing()
4.3 多GPU并行
# 启动分布式推理
accelerate launch --num_processes 4 \
--mixed_precision bf16 \
inference.py \
--prompt "科幻场景" \
--output_dir ./results
五、理论基础与算法解析
5.1 改进的扩散损失函数
Hunyuan-DiT提出混合损失函数:
L = λ 1 L simple + λ 2 L vlb + λ 3 L align \mathcal{L} = \lambda_1\mathcal{L}_{\text{simple}} + \lambda_2\mathcal{L}_{\text{vlb}} + \lambda_3\mathcal{L}_{\text{align}} L=λ1Lsimple+λ2Lvlb+λ3Lalign
其中对齐损失:
L align = − E [ log exp ( s ( z t , c ) / τ ) ∑ c ′ exp ( s ( z t , c ′ ) / τ ) ] \mathcal{L}_{\text{align}} = -\mathbb{E}[\log \frac{\exp(s(z_t,c)/\tau)}{\sum_{c'}\exp(s(z_t,c')/\tau)}] Lalign=−E[log∑c′exp(s(zt,c′)/τ)exp(s(zt,c)/τ)]
5.2 动态温度调节
采样过程中温度参数动态调整:
τ t = τ min + ( τ max − τ min ) ⋅ e − 5 t / T \tau_t = \tau_{\min} + (\tau_{\max} - \tau_{\min}) \cdot e^{-5t/T} τt=τmin+(τmax−τmin)⋅e−5t/T
六、进阶应用开发
6.1 视频生成扩展
from hunyuan.video import VideoDiTPipeline
video_pipe = VideoDiTPipeline.from_pretrained(
"Tencent/HunyuanDiT-Video",
torch_dtype=torch.float16
)
video_frames = video_pipe(
prompt="水墨风格的花开过程",
num_frames=24,
num_inference_steps=50,
motion_scale=1.2
).frames
6.2 3D生成应用
from hunyuan3d import Hunyuan3DPipeline
pipe_3d = Hunyuan3DPipeline.from_pretrained(
"Tencent/HunyuanDiT-3D"
)
mesh = pipe_3d(
prompt="青铜器造型的机器人",
num_views=8,
texture_resolution=2048
).export("robot.glb")
七、参考文献与扩展阅读
Hunyuan-DiT技术白皮书
腾讯AI Lab, 2024扩散Transformer理论
Peebles W, et al. DiT: Scalable Diffusion Models with Transformers. arXiv:2212.09748多模态对齐方法
Radford A, et al. Learning Transferable Visual Models From Natural Language Supervision. CVPR 2021混合专家系统
Fedus W, et al. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. JMLR 2022
八、性能优化与生产部署
8.1 模型量化压缩
# 动态量化
quantized_model = torch.quantization.quantize_dynamic(
pipe.unet,
{nn.Linear, nn.Conv2d},
dtype=torch.qint8
)
# 保存量化模型
torch.save(quantized_model.state_dict(), "hunyuan_quantized.pt")
8.2 ONNX Runtime部署
# 导出ONNX模型
python export_onnx.py \
--model-path Tencent/HunyuanDiT-Large \
--output hunyuan.onnx
# ONNX Runtime推理
onnxruntime-genai generate \
--model hunyuan.onnx \
--prompt "古典园林中的未来科技场景" \
--output result.png
九、未来发展方向
- 多语言支持:扩展至日语、韩语等东亚语言
- 实时生成:实现100ms级端侧推理
- 物理模拟:集成刚体动力学引擎
- 跨模态检索:构建万亿级多模态索引系统
Hunyuan-DiT的技术架构在多模态融合、中文理解和生成质量方面树立了新标杆。其创新的动态MoE机制和分阶段训练策略为大规模生成模型的工程实践提供了重要参考,特别是在处理复杂中文语义和细粒度控制方面展现出显著优势。随着计算硬件的持续升级和算法的不断优化,该技术有望推动AIGC应用进入新的发展阶段。