1.模型部署
LLM部署是将训练好的大型语言模型集成到生产环境中,使其能够接收用户输入并提供推理服务的整个过程。
针对边缘计算场景,推荐的推理框架有:
NVIDIA Triton Inference Server + TensorRT Backend:
- 简介:
TensorRT 是一个底层的模型优化和运行时库,专注于提升单个模型在NVIDIA GPU上的推理性能。
Triton Inference Server 是一个上层的推理服务平台,专注于模型的部署、管理和高效服务。
Triton + TensorRT 是将这两者结合,利用 TensorRT 优化模型,再通过 Triton 提供高性能、可扩展的推理服务。
优点:
- TensorRT对视觉模型的极致优化: 自动驾驶中的视觉感知模型(如目标检测、分割、深度估计、BEV感知等)是基础。TensorRT能将这些模型优化到极致,确保低延迟和高吞吐量。
模型编排: Triton非常适合将复杂的VLA流程串联起来。
成熟稳定: Triton是NVIDIA官方支持的,经过了大量生产环境的验证。
- 简介:
vLLM:
- 简介:
- 一个快速且易于使用的LLM推理和服务引擎,通过PagedAttention等技术显著提高吞吐量。
优点:
LLM推理优化: vLLM的PagedAttention技术,能显著提高KV Cache的利用效率,在LLM的推理吞吐量和延迟方面做了极致优化。
连续批处理: 进一步提升GPU利用率。
vLLM适用场景和问题:
架构适配问题:vLLM主要为Transformer架构的Decoder-only或Encoder-Decoder语言模型设计。如果是端到端的自研VLA架构,可能无法适配。
- 功能单一:相比Triton,vLLM在模型管理、多模型编排、多协议支持、监控等方面功能较少。
- 简介:
| 特性 | NVIDIA Triton Inference Server + TensorRT Backend | vLLM | 重要性 | 最优选项 |
| 端到端VLA流程支持 | 优秀:支持模型编排,可将视觉感知、特征融合、LLM推理、决策输出等串联管理。 | 有限:主要关注LLM部分。 | 极高 | Triton + TensorRT |
| LLM 推理性能 | 优秀:依赖TensorRT对Transformer的优化。 | 顶尖:通过PagedAttention、连续批处理等技术实现LLM极致吞吐量和低延迟。 | 高 | vLLM |
| LLM 显存效率 | 良好:TensorRT通过量化等减少显存。 | 极佳:PagedAttention显著提高KV Cache利用率,大幅降低LLM显存占用。 | 高 | vLLM |
| 实时流处理能力 | 良好:动态批处理。 | 一般:主要为请求-响应模式优化。 | 高 | Triton + TensorRT |
| 确定性与可预测性 | 较高:TensorRT编译引擎行为相对固定,Triton调度可配置。 | 一般:一些动态优化可能引入不确定性。 | 极高 | Triton + TensorRT |
| 工业级特性与成熟度 | 高:模型版本管理、监控、多协议、NVIDIA生态支持。 | 中等:专注于推理核心,企业级服务特性较少。 | 高 | Triton + TensorRT |
| 与自动驾驶硬件生态兼容性 | 优秀:与NVIDIA Drive/Orin平台紧密集成。 | 有限:主要针对GPU,对专用AI加速器的利用不如原生NVIDIA方案。 | 高 | Triton + TensorRT |
| 社区与前沿技术跟进 | 中等:NVIDIA会逐步集成,但可能滞后于专门的LLM研究社区。 | 高:快速采纳和实现LLM领域的最新优化成果。 | 中高 | vLLM |
官方文档中vLLM支持的部分多模态模型:
| 模型系列 | 模型参数 | 输入类型 | 具体模型 | LoRA | PP | V1 |
| LLaVA 系列 | 7B–34B | T + IE+ | llava-hf/llava-1.5-7b-hf, llava-hf/llava-v1.6-mistral-7b-hf |
✅︎ | ✅︎ | ✅︎ |
| Qwen-VL 系列 | 7B–72B | T + IE+ / VE+ | Qwen/Qwen-VL-Chat, Qwen/Qwen2-VL-7B-Instruct, Qwen/Qwen2.5-Omni-7B |
✅︎ | ✅︎ | ✅︎ |
| DeepSeek-VL 系列 | 3B–72B | T + I+ | deepseek-ai/deepseek-vl2-tiny, deepseek-ai/deepseek-vl2 |
✅︎ | ✅︎ | ✅︎ |
| InternVL 系列 | 2B–9B | T + IE+ | OpenGVLab/InternVL3-9B, OpenGVLab/InternVideo2_5_Chat_8B |
✅︎ | ✅︎ | ✅︎ |
| MiniCPM 系列 | 0.5B–8B | T + IE+ + VE+ | openbmb/MiniCPM-V-2, openbmb/MiniCPM-Llama3-V-2_5 |
✅︎ | ✅︎ | ✅︎ |
| Phi 多模态系列 | 3B–4B | T + IE+ / A+ | microsoft/Phi-3-vision-128k-instruct, microsoft/Phi-4-multimodal-instruct |
✅︎ | ✅︎ | ✅︎ |
| Gemma多模态系列 | 3B–27B | T + I+ | google/gemma-3-4b-it, google/gemma-3-27b-it |
✅︎ | ⚠️ | ✅︎ |
| Llama 多模态系列 | 17B–128E | T + I+ | meta-llama/Llama-4-Scout-17B-16E-Instruct, meta-llama/Llama-3.2-90B-Vision-Instruct |
✅︎ | ✅︎ | ✅︎ |
| 其他轻量级模型 | 0.8B–3B | T + I | h2oai/h2ovl-mississippi-800m, SmolVLM2-2.2B-Instruct |
✅︎ | ✅︎ | ✅︎ |
输入类型定义
- T:文本(Text)
- I:图像(Image)
- V:视频(Video)
- A:音频(Audio)
- E:扩展模态(如 OCR、图表、文档解析)
- +:增强输入能力(如多图/视频帧处理、跨模态融合)
功能支持
- LoRA:支持低秩适配微调;
- PP(流水线并行):支持多 GPU 分布式推理(⚠️ 表示需特定配置)
- V1:兼容 vLLM 1.x 版本框架。
2. 模型压缩
LLM压缩旨在减少模型的参数量、存储大小和计算量,同时尽可能保持模型的性能。
2.1 主要的压缩技术:
剪枝:
原理: 移除模型中不重要或冗余的权重、神经元、注意力头甚至整个层。
方法: 通常需要先训练一个大模型,然后根据重要性评分进行剪枝,之后可能需要进行微调以恢复性能。
挑战: 确定合适的剪枝粒度和比例,以及剪枝后的性能恢复。
量化:
原理: 将模型中通常用FP32表示的权重和/或激活值,用更低位数的数据类型表示,FP16, BF16、INT8、INT4甚至更低。
优势:
减少模型大小: FP32 -> INT8,模型大小约减小4倍。
加速计算: 很多硬件对INT8等低精度运算有专门优化,速度远超FP32。
降低功耗。
混合精度: 可以对模型不同部分采用不同精度,例如敏感部分用FP16,其他部分用INT8。
知识蒸馏:
原理:训练一个参数量较小、结构更简单的“学生模型”,使其学习模仿一个大的、性能优越的“教师模型”的行为。
优势: 学生模型可以显著小于教师模型,但能达到接近教师模型的性能。
挑战: 设计合适的蒸馏损失函数、选择合适的学生模型结构、训练过程可能较复杂。
低秩分解 :
低秩分解: 将模型中的大权重矩阵分解为两个或多个小矩阵的乘积。
优势: 显著减少模型参数量。
LoRA 及其变体虽然主要用于高效微调,但其核心思想也是利用低秩分解来表示参数更新,也可以看作一种参数高效的表示方式。

| 方法 | 简单性 | 高效性 | 开源库支持 |
| 量化 | 高 | 高 | 非常丰富 |
| 剪枝 | 中 | 中高 | 有,但应用需调优 |
| 知识蒸馏 | 中低 | 高 | 有,但需自行设计 |
| 低秩分解 | 中 | 中 | 部分集成,或需手动 |
2.2 常用工具和库:
量化:
BitsAndBytes: Hugging Face生态常用,支持8-bit, NF4, FP4等量化,易于集成到Transformers库。
AutoGPTQ: 专门用于LLM的GPTQ量化实现。
AutoAWQ: AWQ量化方法的实现。
TensorRT-LLM: 支持FP8, INT8, INT4 (PTQ-INT4, SmoothQuant, AWQ) 等量化,用于NVIDIA GPU高性能推理。
ONNX Runtime: 支持多种量化方法,可以作为模型部署中间步骤。
剪枝:
PyTorch torch.nn.utils.prune: PyTorch官方的剪枝工具。
Hugging Face Transformers: 部分模型和示例可能包含剪枝脚本或集成。
TextPruner, NNI (Microsoft): 更通用的模型压缩工具,包含剪枝算法。
Sparsity (NVIDIA): 用于支持稀疏计算的库,配合非结构化剪枝。
DeepSpeed-Compression: 包含剪枝功能。
知识蒸馏:
Hugging Face Transformers Trainer: 可以自定义训练循环和损失函数来实现蒸馏。
TextBrewer, Distiller (Intel AI Lab, 已归档): 曾是流行的蒸馏工具库。
DeepSpeed: 也提供了一些蒸馏的辅助功能。
备注: KD更多的是一种训练范式,库主要提供框架和辅助工具,具体实现(尤其是损失函数设计)高度依赖研究者。
低秩分解:
PyTorch (手动实现): 可以使用torch.linalg.svd等函数手动分解权重矩阵并替换。
PEFT (Parameter-Efficient Fine-Tuning) library (Hugging Face): 包含LoRA等基于低秩思想的方法,主要用于微调,但可以启发压缩。
TensorLy: 一个用于张量分解的Python库。
备注: 直接用于LLM整模型压缩的专用低秩分解库较少,更多是作为一种技术思想被应用或手动实现。
2.3 模型部署压缩流程:
模型选择/训练: 选择一个合适的预训练模型或自行训练。
模型压缩:
根据目标部署环境和性能要求,选择压缩技术。
进行剪枝、量化、蒸馏等操作。
评估性能损失。
模型转换:
将压缩后的模型转换为目标推理引擎支持的格式(转ONNX,再转TensorRT)。
服务封装与部署:
使用推理服务框架(如Triton, TorchServe, vLLM)封装优化后的模型,提供API接口。
配置批处理、并发控制、监控等。
部署到云端、本地或边缘设备。
监控与迭代:
持续监控模型的性能、延迟、吞吐量、资源消耗等。
根据反馈进行模型更新、压缩策略调整或部署优化。
3. 模型量化
3.1 数值
①FP32:float32, 32位二进制,1位符号,8位指数,23位尾数 (实际精度23+1=24位)。
②FP16:float16, 16位二进制,1位符号,5位指数,10位尾数 (实际精度10+1=11位)。
③BF16:bfloat16,16位二进制,1位符号,8位指数, 7位尾数 (实际精度7+1=8位)。
④INT8:8位二进制,直接表示整数范围为 -128 到 +127
⑤INT4:4位二进制,直接表示整数范围为 -8 到 +7
显存占用关系:1*FP32=2*FP16=2*BF16=4*INT8=8*INT4
BF16与FP16的区别:BF16牺牲了尾数精度以保留与FP32相同的指数范围,因此动态范围更大,更不容易溢出,适合训练;FP16精度相对较高,但动态范围小,容易溢出或下溢。
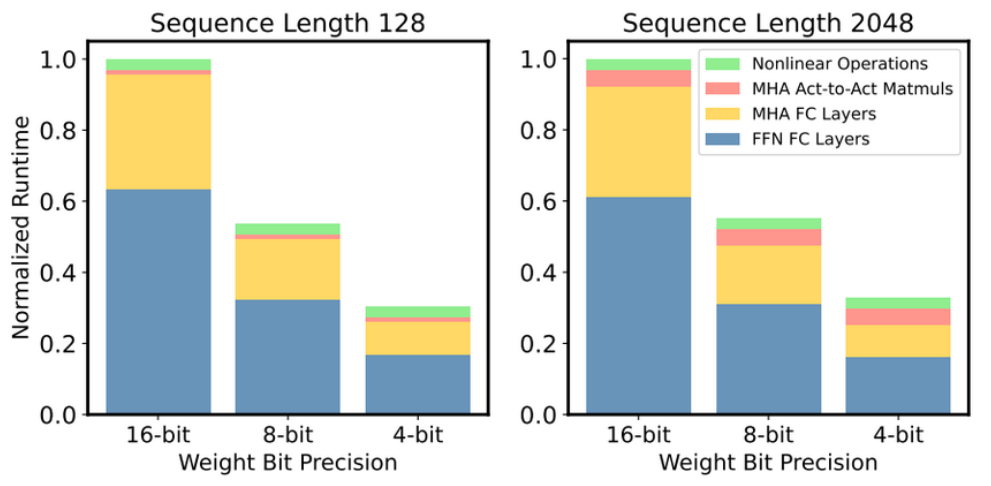
图表是 LLaMA-7B 模型在进行权重量化时的Normalized Runtime。
分析可知:
- 降低权重量化比特数显著减少运行时间
- FC层参数占比最大,且受益于量化,运行时间急剧缩减。
3.2 量化方法PTQ和QAT
训练后量化 ( PTQ):
过程:在已训练的模型上,使用少量或不使用额外数据,对模型量化过程进行校准.
优点:简单快速,数据需求少。
缺点:精度损失风险,校准依赖性。
子类别:
静态PTQ:权重和激活值的量化参数都在校准阶段确定并固定。
动态PTQ:权重通常静态量化,激活值的量化参数在推理时根据每个输入实例动态计算。精度稍好,但引入额外推理开销
量化感知训练 (QAT):
过程:利用额外的训练数据,在量化的同时结合反向传播对模型权重进行调整,确保量化模型的精度不掉点。
-
- 优点:精度更高,鲁棒性更好。
- 缺点:需要重新训练/微调,实现复杂度稍高。
3.3 权重量化与全量化
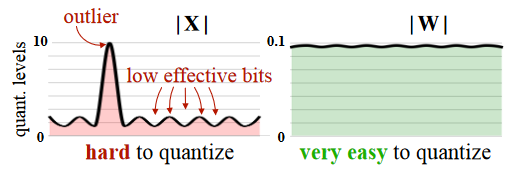
可以对模型参数、激活值或者梯度做量化。但模型的激活值往往存在异常值,直接对其做量化,会导致精度损失严重。
权重量化:
定义:仅对模型的权重参数进行量化。
- 优点:简单。
- 缺点:只能量化模型权重参数。
全量化 :
定义:对模型的权重和激活值都进行量化。
- 优点:针对模型所有参数进行量化。
- 缺点:量化难度大,需要引入更复杂的量化方法。
3.4 量化粒度
量化粒度 (Granularity):决定了缩放因子S和零点Z参数共享的范围。
逐张量 (Per-tensor/Per-layer):整个权重张量或激活张量共享同一套S和Z。最简单,但对分布变化大的张量可能不够灵活。
逐通道 (Per-channel/Per-axis):对于卷积层的权重,通常沿着输出通道维度为每个通道计算独立的S和Z。能更好地适应不同通道的数值分布,精度通常更高。对于激活值,有时也采用。
逐组 (Per-group):将一个通道或张量再细分为小组,每组有独立的S和Z。是逐通道和更细粒度之间的一种折衷,常见于LLM的权重量化。
3.5 线性量化和非线性量化
根据量化公式是否为线性,量化可以分为线性量化和非线性量化。
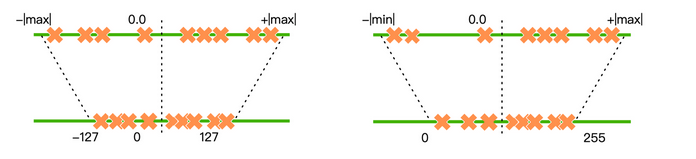
3.5.1 线性量化 (Linear/Affine/Uniform Quantization):根据量化前的浮点数r和量化后的整数q之间的线性关系进行量化。
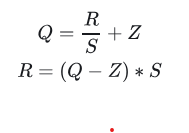
R 表示量化前的浮点数,Q 表示量化后的定点数,S(Scale)表示缩放因子的数值,Z(Zero)表示零点的数值。
- 对称 (Symmetric):量化前后的 0 点是对齐的,因此不需要记录零点。它适合对分布良好且均值为 0 的参数进行量化。因此对称量化常用于权重量化。
- 非对称 (Asymmetric):量化前后 0 点不对齐,需要额外记录一个 offset,也就是零点。非对称量化常用于激活值量化。
3.5.2 非线性量化 (Non-linear Quantization):非线性量化可以根据数据分布的特性进行更精细的量化,但计算复杂度较高,一般在线性量化无法满足要求,且必须进行量化解决问题才使用。
3.6 量化方式分析
- 追求效率(快速实现,允许精度损失,不追求极限压缩):PTQ+权重量化+逐张量量化+线性量化
- 追求极限(低精度损失,极限压缩):
主流极限优化:QAT + 全量化 + 逐通道/逐组量化 + 线性量化
- 特定难题极限探索:QAT + 全量化 + 逐通道/逐组量化 + 非线性量化
3.7 量化具体实现方法
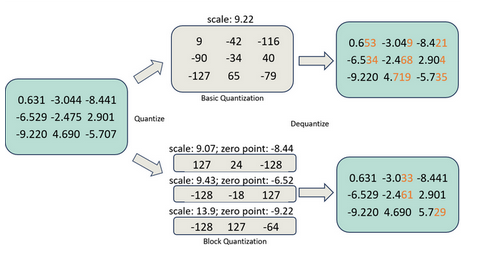
FP16->INT8的线性对称量化:
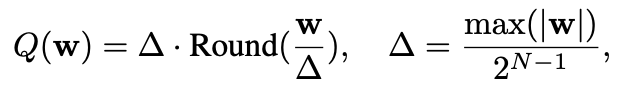
①计算参数:缩放因子 (Δ) (Z取0)
- 找到原始浮点数值中的绝对值最大值 ,max(|w|)=9.22。
- 确定目标整数类型的表示范围。量化到INT8那么N=8。
- 计算缩放因子 Δ:
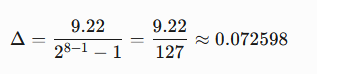
②根据参数量化参数:

如:q=-6.529/0.072598+0≈-90
③反量化:
![]()
Q(w)=-90*0.072598=-6.53382
④结合输入值计算精度损失:
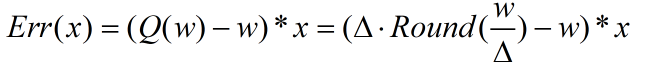
Err(x)=0.000738*x
可以认为INT8量化后引入了0.0738%的误差。
误差来源于两部分:
- 量化方式(INT8/INT4)
- 取整函数Round()
4. AWQ量化
PTQ权重量化,仅对模型权重进行低比特量化,激活值仍保留较高精度,W4A16模式。
4.1 主要创新思路
①权重并不同等重要,仅有小部分显著权重对推理结果影响较大
②量化时对显著权重进行放大可以降低量化误差
4.2 实现方法
①基于激活值分布挑选:激活值越大,对应通道的权重对推理结果影响越大。
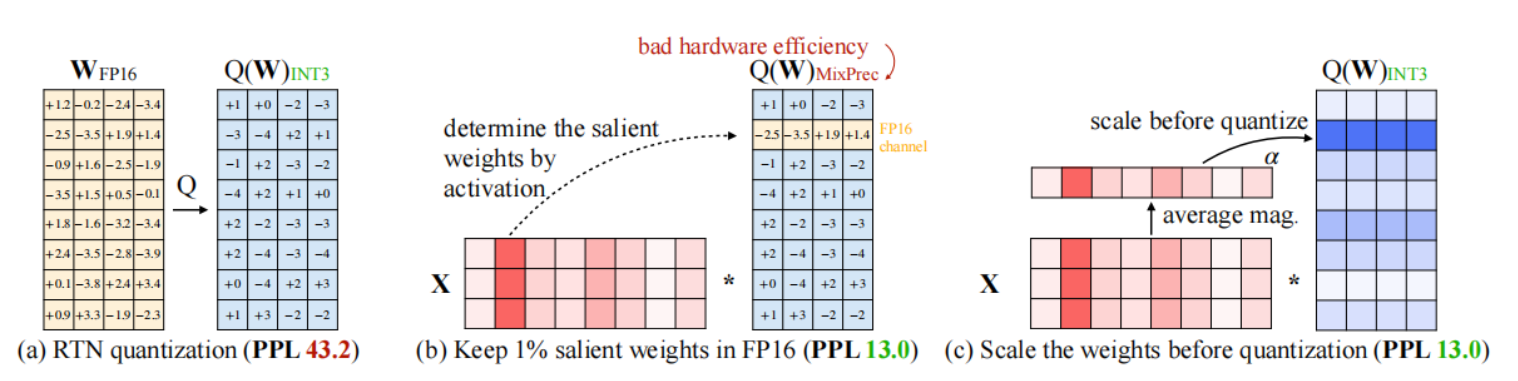
图(a)为朴素量化方法直接四舍五入。
图(b)为保留1%显著通道为FP16,将其他权重参数进行四舍五入。
图(c)为按列取绝对值平均值,把平均值较大的一列对应的通道视作显著通道,保留FP16精度。对其他通道进行低比特量化。

首先分析了三种显著权重挑选方法的结果:
- 随机挑选:随机挑选0.1%~1%的权重作为显著权重。
- 基于权重分布挑选:对权重矩阵中的元素按绝对值大小由大到小排序,绝对值越大越显著,选择前0.1%~1%的元素作为显著权重。
- 基于激活值分布挑选:根据输入和权重计算激活值,按激活值的大小排序进行挑选。
发现随机挑选的结果与RTN的结果差不多,基于权重W的量化与随机挑选的结果差不多。而基于激活值分布挑选weight的结果与fp16的精度差不多。
②为避免权重矩阵精度混用(显著权重FP16,其他权重INT4),采取对所有权重矩阵进行量化;但引入缩放因子权重进行放大,保护显著通道,降低量化误差。
原始量化公式如下:
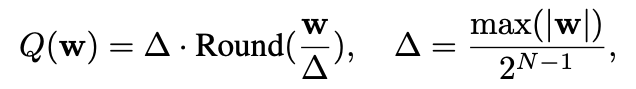
Δ为量化因子,Round()为取整函数。
引入缩放因子s的量化公式如下:
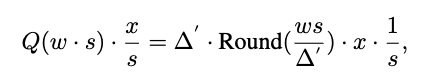
Δ‘为量化因子,Round()为取整函数,x为输入。
他们的误差对比为:

可见s越大误差越小。对所有权重均进行低比特量化,对于显著权重乘以较大的 𝑠 降低误差;对于非显著权重乘以较小的 𝑠 。
③自动计算缩放因子:
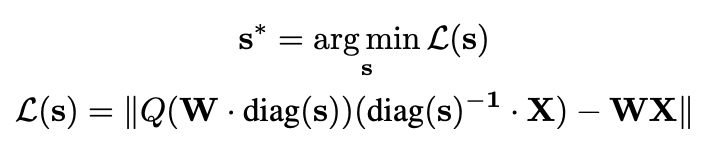
5. GPTQ量化
5.1 主要创新思路
①基于二阶梯度误差补偿:GPTQ通过引入Hessian矩阵(二阶导数)评估量化误差对模型输出的影响,实现更精确的误差补偿与AWQ的激活感知不同,GPTQ直接优化权重量化后的输出误差。
②逐层分块优化策略:将权重矩阵划分为连续列块(如128列/块),对每个块依次进行量化,并通过Cholesky分解计算Hessian逆矩阵,确保数值稳定性。
③动态误差累积补偿:在量化当前块后,更新剩余未量化权重的误差,避免误差累积导致的全局精度损失。
5.2 OBD
OBD是90年网络剪枝的文章,假设网络已经训练好,分析如何利用二阶信息对网络进行剪枝使得删除掉的参数对结果影响最小。
①训练好后对参数施加微小扰动,损失函数的变化为:
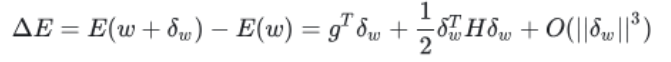
②泰勒展开得到

其中gi为损失函数的梯度;w为权重矩阵按列展开的矩阵;δw为参数wi的扰动;hij为hessian矩阵的元素。
③OBD 的一个关键简化是假设Hessian矩阵是对角的(即 i ≠ j 时 hij = 0 )。那么计算简化为:
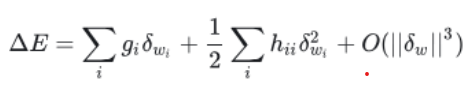
④训练好的网络意味着参数位于局部最小值附近,梯度接近0,所以公式进一步简化为:
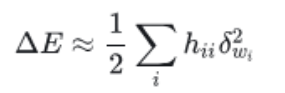
也就是说:我们可以通过施加微小扰动(删除一些小的参数),使用④中公式近似计算损失函数的变化。
⑤OBD算法剪枝实习方法:
- 构建神经网络;
- 训练网络直到收敛;
- 计算每个参数的二阶导数;
- 计算每个参数会带来的损失函数增加值;
- 删除ΔE最小的参数;
- 重复2-5直到删除的数量达到预设要求。
5.3 OBS
OBD的关键假设忽略了Hessian矩阵非对角线参数,而OBS考虑了这一部分。不对Hessian矩阵进行简化,OBS从头推导ΔE的公式为:
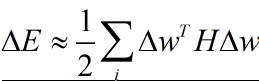
①将“删除一个参数”变成一个线性约束表达式:
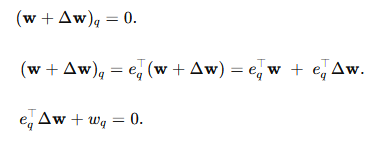
即:
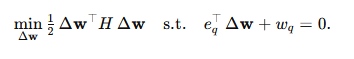
②引入拉格朗日算子把约束问题转为无约束优化问题:
![]()
③求出驻点方程解线性方程组:
对Δw和λ求导令其等于零:
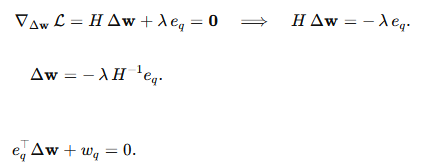
代入第二个等式得到:
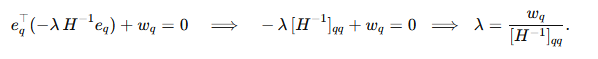
得到 最优更新方向为:
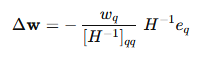
④代入损失增量公式:
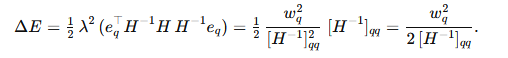
这就是论文里对第q个权重的Saliency度量:
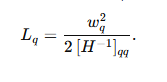
wq为第q个权重,H为Hessian矩阵,Lq为损失近似增量。Lq越小说明该层权重越不重要,
⑤OBS算法流程:
- 计算每个权重 wq 的 Lq,移除 Lq 最小的那个权重。
- 根据最优更新方向更新他权重。
- 重新计算H矩阵,然后迭代这个过程。
相比于OBD的创新点:
- 不对Hessian矩阵做简化,提高了精度。
- 将删除参数变为约束条件,继而设计拉格朗日函数,得到ΔE的(即Lq)计算公式。
5.4 OBQ
OBQ基于OBS,将全精度权重 wq 替换为量化后的值 quant(wq),同时调整其他未量化的权重来补偿这个量化操作引入的误差。
①将限制条件修改为:
![]()
引入量化的wq代替原始wq。
②得到拉格朗日函数:
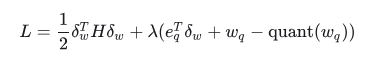
③参照OBS的方式解方程,得到最终的损失函数增量表达式:
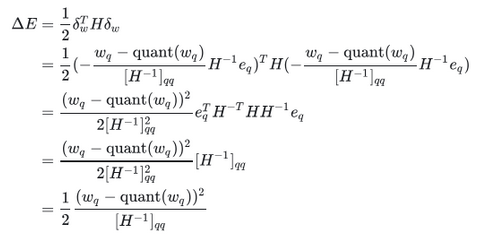
相比于OBS多了quant(wq)这一项。
④OBQ算法流程:
- 确定量化方案,收集量化数据。
- 计算H逆矩阵。
- 针对权重的每一个wq,计算ΔE,量化ΔE最小的那个权重。
- 根据最优更新方向更新他权重,计算H逆矩阵。
- 迭代量化过程直到结束。
5.5 GPTQ
GPTQ的创新点:
①取消贪心算法:OBQ使用贪心算法,逐个找影响最小的来量化,作者发现,其实随机的顺序效果也一样好(甚至在大模型上更好)。在GPTQ中直接全部都采用固定顺序,使得计算复杂度大大降低。
②批处理:OBQ 对权重一个个进行单独更新,作者发现瓶颈实际在于GPU的内存带宽,而且同一个特征矩阵W不同列间的权重更新是不会互相影响的。因此作者提出了批处理的方法,一次处理多个(如128)列,大幅提升了计算速度。
③数值稳定性: 作者观察到一些操作会引入数值误差。为了解决这个误差提出了两种方法,一是往H里加入一个小的常数项。另一个是用数值稳定的 Cholesky 分解提前计算好所有需要的信息,避免在更新的过程中再计算。
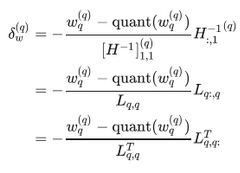
6. AWQ和GPTQ对比
| 特性 | GPTQ | AWQ |
| 核心思想 | 基于二阶信息的逐层权重误差补偿 | 激活感知,保护与显著激活通道相关的权重,通过缩放因子优化 |
| 量化策略 | 迭代量化,更新未量化权重以补偿误差 | 分析激活,确定每通道缩放因子,然后对缩放后的权重进行RTN量化 |
| 数学复杂度 | 较高 (Hessian 近似, Cholesky) | 较低 (主要依赖激活统计和缩放) |
| 量化速度 | 相对较慢 | 非常快 |
| 校准数据依赖 | 需要用于Hessian计算和迭代优化 | 主要用于收集激活统计数据以确定缩放因子 |
| 侧重点 | 精确量化权重本身 | 保护那些影响大的权重(通过激活幅度判断) |
| 参数修改 | 直接修改权重值进行补偿 | 主要通过优化每通道的缩放因子,权重本身是缩放后再RTN |
| 硬件友好性 | 推理时可能需要更复杂的核 (如果动态解量化) 或依赖特定硬件支持 | 通常更容易实现高效的整数推理 (INT4 权重 * FP16 激活,结合缩放) |
| 常见精度 | 3-4 bit 接近 FP16 | 4 bit 接近 FP16,有时在W4A16下表现优异 |
7. 量化工具
Transformers (Hugging Face)
简介: Transformers 库集成了多种量化方法和工具,特别是针对其生态系统内的 Transformer 模型。
支持的量化方法/集成:
BitsAndBytes: Transformers 深度集成,可实现 LLM 的 8-bit 和 4-bit 量化。
GPTQ: 通过与 AutoGPTQ等库的集成,支持 GPTQ 量化模型的加载和推理。
AWQ: 同样,通过集成支持 AWQ 量化模型的加载和推理。
ONNX Runtime Quantization: 支持将模型导出到 ONNX 并使用 ONNX Runtime 进行量化。
优点: 拥有庞大的模型库和活跃的社区,易于上手,与 Hugging Face 生态系统无缝集成。
BitsAndBytes
简介: 实现 LLM 的高效 8-bit 和 4-bit量化。通过自定义 CUDA 核函数实现了在保持较高精度的同时大幅降低显存占用。
支持的量化方法:
8-bit Quantization (LLM.int8())
4-bit Quantization (NF4, FP4)
优点: 对于大型语言模型的显存优化效果非常显著,是 QLoRA 等参数高效微调方法的基石,与 Transformers 集成良好。
AutoGPTQ
简介:GPTQ 量化实现库。提供了量化脚本和加载量化后模型的接口。
支持的量化方法: GPTQ
优点: 专注于 GPTQ,提供了简单的 API,与 Transformers 兼容性好,支持多种模型架构。
AutoAWQ
简介: 提供了 AWQ量化方法的实现。
支持的量化方法: AWQ
优点: AWQ 方法本身在 4-bit 量化上表现优异,实现相对简单,对硬件友好。
ONNX Runtime
简介: ONNX Runtime 是一个跨平台的高性能推理引擎,它也提供了对 ONNX 模型的量化工具。通常模型先从 PyTorch/TensorFlow 等框架导出为 ONNX 格式,然后使用 ONNX Runtime进行量化。
支持的量化方法:
Post-training static quantization
Post-training dynamic quantization
Quantization-aware training (通常在原始框架中完成,然后导出)
优点: 跨平台,支持多种硬件加速器,量化后的模型易于部署。