组复制
MySQL 官方提供的一种高可用性解决方案,属于 MySQL InnoDB 集群的一部分。它通过分布式一致性协议(基于 Paxos 的变体)实现多个节点之间的数据同步,确保数据的一致性和故障容错能力。
实验准备
linux系统安装docker (不要用win安装docker,win宿主机无法直接与容器通信)
docker虚拟网卡
docker network create --driver bridge --subnet=192.168.0.0/24 --gateway=192.168.0.1 mysql-group-replica
| 实例 | 端口 | server_id | ip | 用途 |
|---|---|---|---|---|
| mysql1 | 4406 | 101 | 192.168.0.16 | Primary 初始节点 |
| mysql2 | 4407 | 102 | 192.168.0.17 | Secondary 节点 |
| mysql3 | 4408 | 103 | 192.168.0.18 | Secondary 节点 |
docker run \
--name mysql1 \
--ip 192.168.0.16 \
--hostname mgr-node1 \
--add-host mgr-node2:192.168.0.17 \
--add-host mgr-node3:192.168.0.18 \
--network mysql-group-replica \
-p 4406:3306 \
-v /home/admin/Documents/mgr-node1/data:/var/lib/mysql \
-v /home/admin/Documents/mgr-node1/config:/etc/mysql/conf.d \
-v /home/admin/Documents/mgr-node1/logs:/logs \
-e MYSQL_ROOT_PASSWORD=123456 \
-d mysql:8.0.27\
docker run \
--name mysql2 \
--ip 192.168.0.17 \
--hostname mgr-node2 \
--add-host mgr-node1:192.168.0.16 \
--add-host mgr-node3:192.168.0.18 \
--network mysql-group-replica \
-p 4407:3306 \
-v /home/admin/Documents/mgr-node2/data:/var/lib/mysql \
-v /home/admin/Documents/mgr-node2/config:/etc/mysql/conf.d \
-v /home/admin/Documents/mgr-node2/logs:/logs \
-e MYSQL_ROOT_PASSWORD=123456 \
-d mysql:8.0.27\
docker run \
--name mysql3 \
--ip 192.168.0.18 \
--hostname mgr-node3 \
--add-host mgr-node1:192.168.0.16 \
--add-host mgr-node2:192.168.0.17 \
--network mysql-group-replica \
-p 4408:3306 \
-v /home/admin/Documents/mgr-node3/data:/var/lib/mysql \
-v /home/admin/Documents/mgr-node3/config:/etc/mysql/conf.d \
-v /home/admin/Documents/mgr-node3/logs:/logs \
-e MYSQL_ROOT_PASSWORD=123456 \
-d mysql:8.0.27\
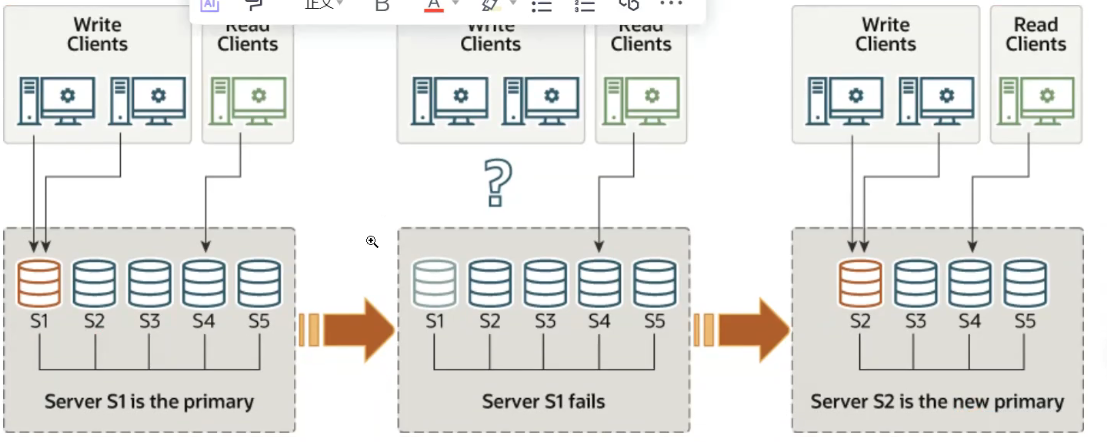
单主模式(默认)
group_replication_single_primary_mode = ON是默认参数
- 环境要求
- 所有节点必须使用 InnoDB 存储引擎。
- MySQL 5.7.17+ 或 8.0+。
- 所有节点时钟同步(NTP)。
- 基础配置(每个节点)
[mysqld]
skip-name-resolve = ON # 禁止 DNS 反向解析
server-id=1 # 每个节点唯一
gtid_mode=ON #组复制依赖GTID复制
enforce-gtid-consistency=ON #组复制依赖GTID复制
log_bin=binlog
#组复制插件
plugin_load_add ='group_replication.so'
# 组复制相关配置
group_replication_group_name = '0d3eeaf8-3599-11f0-8760-0242c0a80010' #所属组名
group_replication_start_on_boot = OFF #设置插件在服务器启动时不自启
group_replication_bootstrap_group = OFF
group_replication_local_address = 'mgr-node1:33061' #此库与其他库通信的本库地址,端口是指定一个新的端口
group_replication_group_seeds = 'mgr-node1:33061,mgr-node2:33061,mgr-node3:33061' #组成员的主机名和端口,端口是指定一个新的端口
report_host = mgr-node1
- 启动组复制
SET SQL_LOG_BIN=0;
-- 创建复制账号(所有实例一样,每个实例都有可能升为主库)
CREATE USER 'repl'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
FLUSH PRIVILEGES;
-- 配置复制通道
CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='123456' FOR CHANNEL 'group_replication_recovery';
SET SQL_LOG_BIN=1;
-- 启动组复制(第一个节点)
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
-- 其他节点
START GROUP_REPLICATION;
--查看组内节点状态
SELECT * FROM performance_schema.replication_group_members;
RESET MASTER; -- 如果此库为刚创建的库可以执行清除本地 binlog 和 GTID 记录
节点自动升级
主节点宕机,mysql会自动将其中一个从节点升级为主节点,由于我们group_replication_start_on_boot = OFF,所以主节点恢复以后需要手动重新加入组,也就是执行START GROUP_REPLICATION;
多主
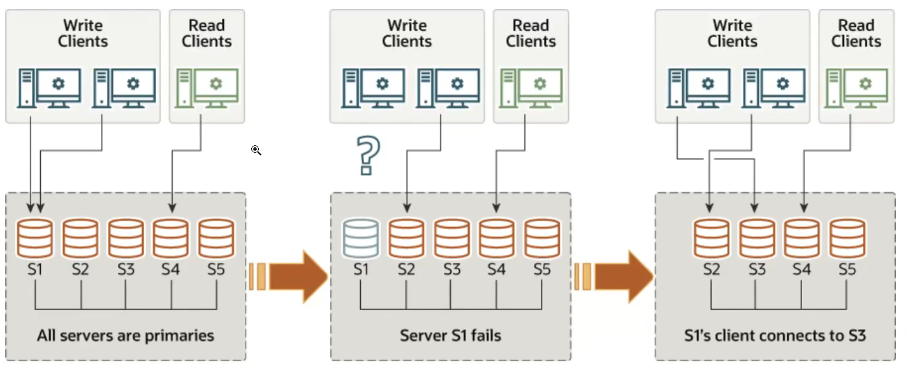
从单主切换到多主
停掉组复制(所有节点)
STOP GROUP_REPLICATION;修改配置参数
设置 group_replication_single_primary_mode=OFF:- 永久生效:
在每个节点的配置文件my.cnf中添加或修改:
group_replication_single_primary_mode = OFF- 临时生效:
在所有节点执行:
SET GLOBAL group_replication_single_primary_mode = OFF;- 永久生效:
开启多主一致性检查
SET GLOBAL group_replication_enforce_update_everywhere_checks = ON;启动组复制(所有节点)
-- 启动组复制(第一个节点) SET GLOBAL group_replication_bootstrap_group=ON; START GROUP_REPLICATION; SET GLOBAL group_replication_bootstrap_group=OFF;其他每个成员节点上重新启动组复制:
START GROUP_REPLICATION;
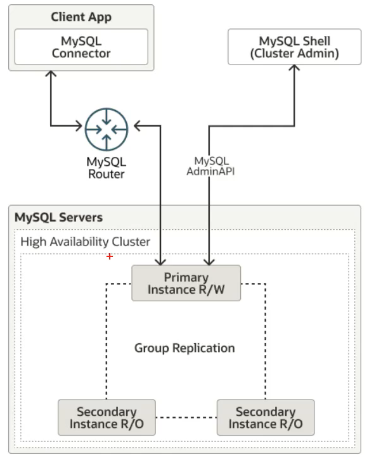
MySQL InnoDB Cluster
MySQL InnoDB Cluster 是 MySQL 官方提供的一套高可用、高一致性的原生集群解决方案,它基于:
- MySQL Server (InnoDB 引擎)
- Group Replication(实现数据同步和高可用)
- MySQL Shell(用于配置和管理集群)MySQL Shell (docker镜像自带了)
- MySQL Router(应用端连接路由)MySQL Router
修改host文件
vim /etc/hosts;
192.168.0.16 mgr-node1
192.168.0.17 mgr-node2
192.168.0.18 mgr-node3
ping mgr-node1;
添加mysqlsh path
echo "PATH=$PATH:/usr/local/mysqlsh/bin" >/etc/profile.d/mysqlsh.sh
chmod +x /etc/profile.d/mysqlsh.sh
source /etc/profile.d/mysqlsh.sh
重启宿主机
在第一个节点进入mysqlsh
mysqlsh root@mgr-node1:3306 --js
#检查实例配置,宿主机配置不高可能虚拟机反应慢容易超时
dba.checkInstanceConfiguration('root:123456@mgr-node1:3306');
dba.checkInstanceConfiguration('root:123456@mgr-node2:3306');
dba.checkInstanceConfiguration('root:123456@mgr-node3:3306');
#自动配置集群实例
dba.configureInstance('root:123456@mgr-node1:3306');
dba.configureInstance('root:123456@mgr-node2:3306');
dba.configureInstance('root:123456@mgr-node3:3306');
#创建集群
var cluster = dba.createCluster('my-cluster');
#添加其他实例
cluster.addInstance('root:123456@mgr-node2:3306');
cluster.addInstance('root:123456@mgr-node3:3306');
#Please select a recovery method [C]lone/[I]ncremental recovery/[A]bort (default Clone): 第一次添加的节点可以选择克隆c
#docker中的实例可能不会自动重启,需要手动启动,记得及时启动
注意事项
- 创建表必须有主键否则报错ERROR 3098
- 只有主节点可以写入,从节点写入会报错ERROR 1290
节点自动升级
主节点宕机,mysql会自动将其中一个从节点升级为主节点,与普通的组复制不同的是,宕机的节点上线会自动回到集群。
其他常见操作
一切操作都需要先获取到对应的cluster对象
- 集群选项
var cluster = dba.getCluster();
// 设置所有节点权重为50
cluster.setOption("memberWeight",50)
// 重新加入集群的重试次数五次
cluster.setOption("autoRejoinTries",5)
// 设置一个节点的权重
cluster.setInstanceOption("mgr-node2:3306","memberWeight",70)
cluster.setInstanceOption("mgr-node2:3306","autoRejoinTries",5)
//查看集群选项
cluster.options()
- 创建时携带参数
//在集群创建时候配置
dba.createCluster('myCluster',{memberWeight:75})//配置第一个节点
var cluster = dba.getCluster();
cluster.addInstance('mgr-node2:3306',{memberWeight:50})
- 将节点重新加入集群
// 从集群对象调用 rejoinInstance
cluster.rejoinInstance('mgr-node2:3306');
//参数修改如server_uuid变更等情况导致rejoin失败,则需要先移出节点,再加入
// 将指定节点移出集群
cluster.removeInstance('root@mgr-node2:3306',{force:true})
cluster.scan();
cluster.addInstance('root@mgr-node2:3306')
- 集群多数节点异常,恢复
集群多数节点异常,就失去了仲裁机制不能正常工作。
通过此命令可手动指定一组节点为 “活跃分区”,忽略其他节点,恢复服务。
//将集群剥离为单节点运行
cluster.forceQuorumUsingPartitionOf('root@mgr-node1:3306')
//再重新加入恢复的节点
cluster.rejoinInstance('mgr-node2:3306');
cluster.rejoinInstance('mgr-node3:3306');
- 集群节点角色切换-单主多主切换
cluster.switchToMultiPrimaryMode(); // 切换多主
cluster.switchToSinglePrimaryMode(); // 切换单主
//在多主切换单主时指定主节点
cluster.switchToSinglePrimaryMode("mgr-node1:3306");
- 创建集群用户
在集群的任一节点(通常是主节点)上,使用 root 账号登录并执行:
cluster.setupAdminAccount('cluster_admin')
- 销毁集群
var cluster = dba.getCluster()
cluster.dissolve()
- 查看帮助
dba.help()
灾后恢复
如何重新连接并管理现有集群
当你下次打开 MySQL Shell 时,可以通过以下步骤重新连接到已存在的集群:
- 连接到集群中的任意节点
mysqlsh root:123456@mgr-node1:3306 --js # 连接到任一节点
- 访问现有集群
//用于在 InnoDB 集群遇到完全中断 (例如,当组复制在所有成员实例上停止时)后重新配置和恢复集群。这个命令允许你连接到集群中的一个 MySQL 实例,并使用该实例的元数据来恢复整个集群。
dba.rebootClusterFromCompleteOutage();
//以上指令执行失败可以删除元数据重新创建集群
dba.dropMetadataSchema();
// 获取已存在的集群实例
var cluster = dba.getCluster();
// 验证集群状态
cluster.status();
- 添加新实例到集群
dba.addInstance('root:123456@mgr-noden:3306');
用MySQL Router实现读写分离
- 添加path
echo "PATH=$PATH:/usr/local/mysqlrouter/bin" >/etc/profile.d/mysqlrouter.sh
chmod +x /etc/profile.d/mysqlrouter.sh
source /etc/profile.d/mysqlrouter.sh
- 自动根据集群配置路由
mysqlrouter --bootstrap root:123456@mgr-node1:3306 --force --user=root
#或指定host
mysqlrouter --bootstrap root:123456@mgr-node1:3306 --force --user=root --report-host mgr
- 启动路由
mysqlrouter &
- 测试路由
读写端口
mysqlsh root@localhost:6446 --sql
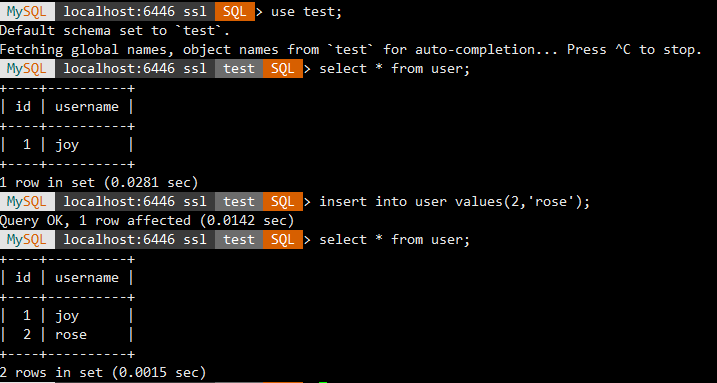
只读端口
mysqlsh root@localhost:6447 --sql

MySQL InnoDB ReplicaSet(复制集)
InnoDB ReplicaSet 是 MySQL InnoDB 提供的一种高可用架构,基于 Group Replication(组复制) 技术实现,旨在通过多个节点之间的数据复制和故障转移,提升数据库的可靠性、扩展性和容错能力。它主要用于解决传统主从复制(Master-Slave Replication)在高可用性和数据一致性方面的局限性。
MySQL InnoDB ClusterSet
InnoDB ClusterSet 是在多个 InnoDB Cluster 之上,构建的跨区域、跨数据中心灾备高可用方案。
它通过管理 多个 InnoDB Cluster,实现:
跨数据中心主备部署(例如主机在北京,备机在广州)
自动主集群切换(Primary Cluster → Secondary Cluster)
单点写入、全局数据同步