string的使用
string可以理解为:管理char字符数组的顺序表
使用string之前需要加头文件#include < string >
可以理解string的底层是这样的
class string
{
private:
char* _str;
size_t _size;
size_t _capacity;
};
Member functions(成员函数)
(constructor)构造
1. string();
2. string(const string& str);
3. string(const string& str, size_t pos, size_t len = npos);
4. string(const char* s);
5. string(const char* s, size_t n);
6. string(size_t n, char c);
7. template <class InputIterator>
string (InputIterator first, InputIterator last);
其中1、2、4是最常用的构造。
对npos的定义,npos属于string容器的成员常量
//size_t相当于unsigned int,npos给值-1,就是npos是一个非常大的数
static const size_t npos = -1;
构造的使用
#include <iostream>
#include <string>
using namespace std;
int main()
{
//1
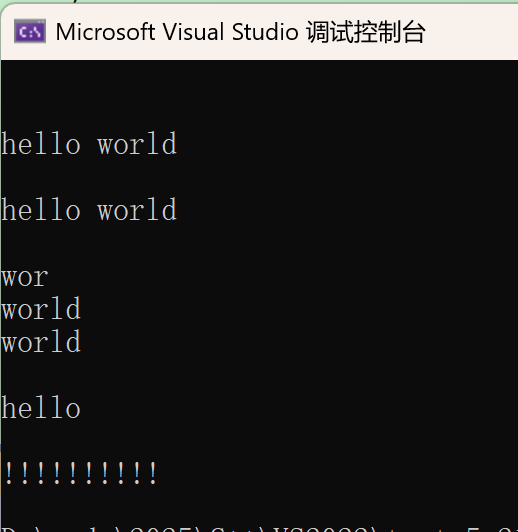
string s1;
cout << s1 << endl << endl;
//4
string s2("hello world");
cout << s2 << endl << endl;
//2 拷贝构造
string s3(s2);
cout << s3 << endl << endl;
//3 从下标pos位置开始拷贝len个字符,如果len的大小大于pos位置及其之后字符
//的个数或len是缺省值npos,那么就把pos位置及其之后的字符全部拷贝过来
string s4(s2, 6, 3);
cout << s4 << endl;
string s5(s2, 6, 50);
cout << s5 << endl;
string s6(s2, 6);
cout << s6 << endl << endl;
//5 从str指向的字符串中拷贝前n个字符
const char* str = "hello world";
string s7(str, 5);
cout << s7 << endl << endl;
//6 拷贝n个c字符
string s8(10, '!');
cout << s8 << endl;
//7 等后面了解迭代器之后再使用
return 0;
}
(destructor)析构
~string();
operator=
1. string& operator=(const string& str);
2. string& operator=(const char* s);
3. string& operator=(char c);
其中1、2是最常用的赋值。
operator=的使用
#include <iostream>
#include <string>
using namespace std;
int main()
{
//1
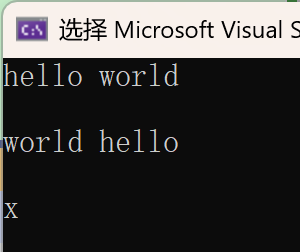
string s1;
string str("hello world");
const char* s = "world hello";
s1 = str;
cout << s1 << endl << endl;
//2
s1 = s;
cout << s1 << endl << endl;
//3
s1 = 'x';
cout << s1 << endl;
return 0;
}
遍历+修改
涉及:operator[]、operator<<、size、length、begin、end
string的遍历+修改有三种方式
#include <iostream>
#include <string>
#include <vector> //顺序表
#include <list> //链表
#include <algorithm> //算法
using namespace std;
int main()
{
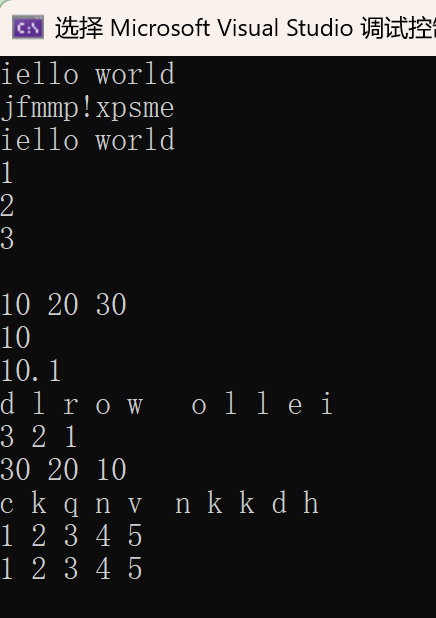
string s1("hello world");
const string s2("hello world");
//遍历+修改
//1. 下标+[] operator[] (小众)
s1[0]++; //s1.operator[](0)++;
//s2[0]++; //s2被const修饰,不能改变
cout << s1 << endl;
//对s1的每个字符都++
//s1.size()和s1.length()是一样的
//原本只有length但是为了让STL容器的风格保持一致又添加了个size
for(size_t i = 0; i < s1.size(); ++i)
{
s1[i]++;
}
cout << s1 << endl;
//2.迭代器iterator (所有容器的主流遍历+修改方式)
//迭代器具有迁移性,掌握了一个容器的迭代器使用,
//其他的容器的迭代器的使用就更容易上手
//迭代器可以理解为一个像指针一样的东西
//没s1的每个字符都--
string::iterator it1 = s1.begin();
//[begin(), end()) 左闭右开
//s1.begin()返回开始位置的迭代器
//s1.end()返回最后一个数据位置的下一个位置的迭代器
//等于说s1,end()是返回'\0'这个位置的迭代器
while(it1 != s1.end())
{
(*it1)--;
it1++;
}
cout << s1 << endl;
//这里是对迭代器去魅
//现阶段就把迭代器理解为一个像指针一样的东西就好
vector<int> v;
//尾部插入
v.push_back(1);
v.push_back(2);
v.push_back(3);
vector<int>::iterator it2 = v.begin();
while(it2 != v.end())
{
cout << *it2 << endl;
it2++;
}
cout << endl;
list<int> lt;
lt.push_back(10);
lt.push_back(20);
lt.push_back(30);
list<int>::iterator it3 = lt.begin();
while (it3 != lt.end())
{
cout << *it3 << " ";
it3++;
}
cout << endl;
//逆置string、vector、list
reverse(s1.begin(), s1.end());
reverse(v.begin(), v.end());
reverse(lt.begin(), lt.end());
//这就是迭代器的强大之处,算法通过迭代器去操作这些容器
//并脱离了具体的底层结构和底层结构解耦
//解耦:降低耦合,就是降低算法和容器的关联关系,让算法实用于所有的STL容器
//3. 范围for 也叫语法糖(意思是范围for用着很爽) C++11添加的
//所有容器都支持范围for
//在使用范围for之前先说以下auto
//auto可以自动推导变量的类型
auto x = 10;
auto y = 10.1;
cout << x << endl;
cout << y << endl;
int& z = x;
auto m = z; //m不是z的引用,它的类型是int
m++; //m++不改变z和x
auto& n = z; //n是z的引用
//下面两个auto推导出来的类型都是int*
auto p1 = &x;
auto* p2 = &x; //这种写法只能是指针
//auto和auto*的区别
auto p3 = x; //auto推导出来的类型是int
//auto* p4 = x; //编译报错,不能这样写
//自动取容器数据
//自动判断结束
//自动迭代
for(auto e : s1)
{
cout << e << " ";
}
cout << endl;
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
for(auto e : lt)
{
cout << e << " ";
}
cout << endl;
//修改
//范围for的底层就是迭代器,auto e = *迭代器
//所以e是*迭代器的拷贝,要修改容器数据就要加引用
//这里的auto也可以写具体的类型,但习惯上都写的auto
//for(char& e : s1)
for(auto& e : s1)
{
e--;
cout << e << " ";
}
cout << endl;
//以前数组的遍历方式
int arr[] = { 1, 2 ,3, 4, 5 };
for(int i = 0; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
cout << arr[i] << " ";
}
cout << endl;
//但是现在数组可以用范围for遍历
//可以认为它在语法上特殊处理过
for(auto e : arr)
{
cout << e << " ";
}
cout << endl;
return 0;
}
迭代器
涉及:begin/end、rbegin/rend、cbegin/cend、crbegin/crend
迭代器分为:普通迭代器和const迭代器,普通迭代器修饰普通对象,const迭代器修饰const对象
常用:begin/end、rbegin/rend
int main()
{
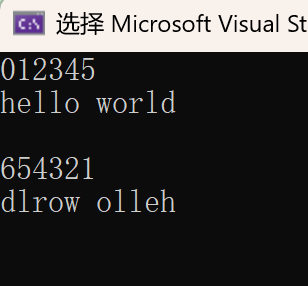
string s1("123456");
const string s2("hello world");
//begin/end 正向迭代器 正向遍历
string::iterator it1 = s1.begin();
while(it1 != s1.end())
{
(*it1)--;
it1++;
}
cout << s1 << endl;
string::const_iterator it2 = s2.begin();
while(it2 != s2.end())
{
//(*it2)--;//const_iterator迭代器指向的数据不能修改
it2++;
}
cout << s2 << endl << endl;
//rbegin/rend 反向迭代器 反向遍历
string::reverse_iterator it3 = s1.rbegin();
while(it3 != s1.rend())
{
(*it3)++;
cout << *it3;
it3++;
}
cout << endl;
string::const_reverse_iterator it4 = s2.rbegin();
while(it4 != s2.rend())
{
//(*it4)--; //不能修改
cout << *it4;
it4++;
}
cout << endl << endl;
//cbegin/cend、crbegin/crend是确定要返回const版本
//c就是const
}
//构造第7点
7. template <class InputIterator>
string (InputIterator first, InputIterator last);
//起始位置的迭代器,末尾数据位置的下一个位置的迭代器
int main()
{
string s1("hello world");
string s2(s1.begin(), s1.end());
cout << s2 << endl;
}
max_size、capacity、push_back、clear、empty、shrink_to_fit、pop_back
常用:push_back、clear、empty、pop_back
int main()
{
string s1("123456");
//max_size就是这个string字符串最长能有多长
//但是其实这个接口没有什么意义,实际到不了那么长
//X64和X86环境下max_size的值不同,不同平台也不同
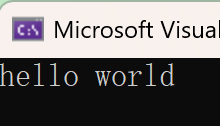
cout << s1.max_size() << endl;
cout << endl;
//capacity 返回当前string字符串的容量,不包含\0
//返回的值加1才是实际的容量
//size和capacity均不包含\0
cout << s1.size() << endl;
cout << s1.capacity() << endl;
string s2;
size_t old = s2.capacity();
cout << "capacity:" << old << endl;
for(size_t i = 0; i < 100; ++i)
{
//push_back 尾部插入
s2.push_back('x');
if(s2.capacity() != old)
{
old = s2.capacity();
cout << "capacity:" << old << endl;
}
}
//VS2022第一次扩容2倍,后面都是1.5倍扩容,不同平台底层实现不同
cout << endl;
//clear 清空数据
//empty 判空
cout << s1 << endl;
s1.clear();
if(s1.empty())
cout << "yes" << endl;
cout << endl;
//shrink_to_fit 缩容
cout << "size:" << s2.size() << endl;
cout << "capacity:" << s2.capacity() << endl;
//s2.clear(); //clear只会改变size不会改变容量
for(size_t i = 0; i < 50; ++i)
{
//pop_back 尾部删除
//尾删只会改变size不会改变容量
s2.pop_back();
}
s2.shrink_to_fit();
cout << "size:" << s2.size() << endl;
cout << "capacity:" << s2.capacity() << endl;
//为什么这些接口都不缩容,这不是浪费空间吗?
//1. 缩容的代价很大,因为在堆上申请的空间不支持先释放一部分
//2. 缩容是新开一块小空间,然后把旧数据拷贝过来
//3. 缩容就是一种以时间换空间的做法
//shrink_to_fit会让capacity减小到>=size,,为什么不直接减小到size?
//因为它这个容量底层也是有对齐规则的,不同平台底层对齐规则不同
}
reserve、resize
这两个都不常用
int main()
{
//reserve 扩容 跟shrink_to_fit类似
string s1("123456");
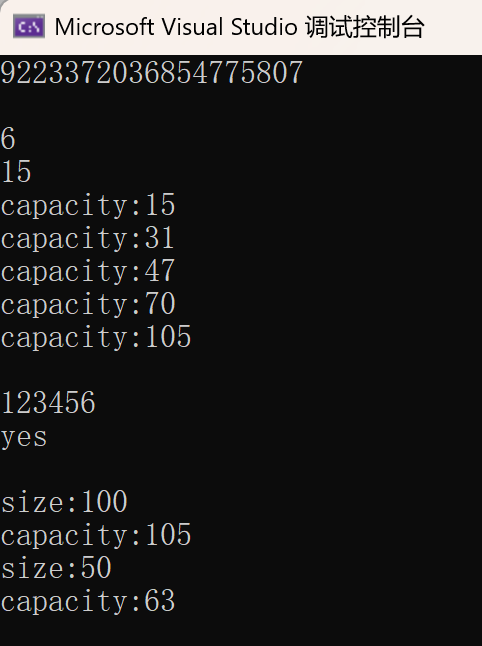
cout << "size:" << s1.size() << endl;
cout << "capacity:" << s1.capacity() << endl;
s1.reserve(100);
cout << "size:" << s1.size() << endl;
cout << "capacity:" << s1.capacity() << endl;
//reserve会不会缩容是不确定的,但如果缩容的话,肯定不会影响原始数据内容
s1.reserve(3);
cout << "size:" << s1.size() << endl;
cout << "capacity:" << s1.capacity() << endl;
cout << endl;
//reserve使用场景:知道容量要多少,直接开好,避免扩容,提高效率
string s2;
size_t old = s2.capacity();
cout << "capacity:" << old << endl;
s2.reserve(100);
for(size_t i = 0; i < 100; ++i)
{
s2.push_back('x');
if(s2.capacity() != old)
{
old = s2.capacity();
cout << "capacity:" << old << endl;
}
}
cout << endl;
//resize 改变size的值
//void resize(size_t n);
//void resize(size_t n, char c);
//如果n < size,保留前n个字符,删除之后的字符
//如果n >= size,传字符c就用c填满多出来的空间,不传就用\0填满
string s3("123456");
s3.resize(3);
cout << "size:" << s3.size() << endl;
cout << s3 << endl;
s3.resize(9);
cout << "size:" << s3.size() << endl;
cout << s3 << endl;
s3.resize(13, 'x');
//这里打印出来是123xxxx,直接忽略了\0,实际是123\0\0\0\0\0\0xxxx,监视窗口可以查看
//std::string的特性:std::string类内部维护了字符串的长度信息,通过size()成员函数获取。
//它并不依赖\0来标识字符串结束。当使用cout输出std::string对象时,cout会根据
//std::string内部记录的长度去输出字符序列,而不是像处理C风格字符串那样遇到\0就停止。
cout << "size:" << s3.size() << endl;
cout << s3 << endl;
return 0;
}
operator[]、at、back、front
常用:operator[]
void test_string()
{
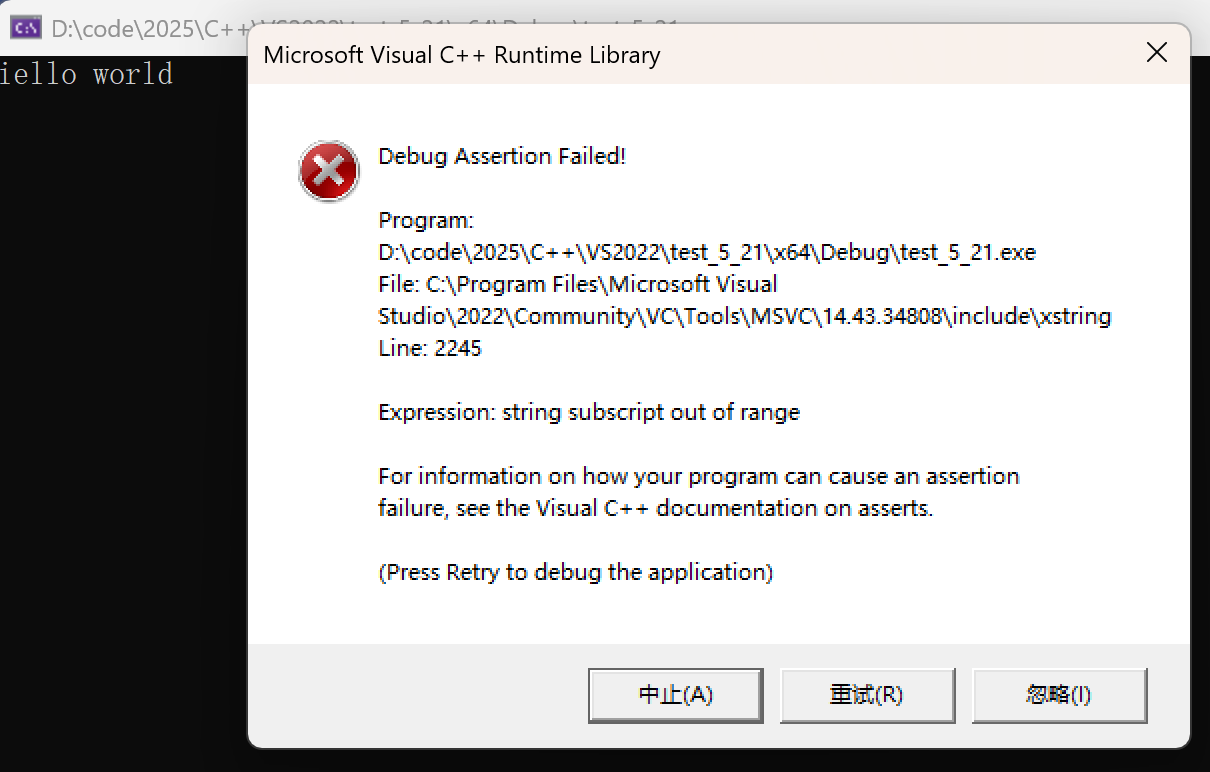
//operator[]对越界是断言报错
//但断言在Release版本下是不起作用的
string s1("hello world");
s1[0]++;
cout << s1 << endl;
//s1[15]; //越界直接断言报错
//它是在operator[]函数中,assert(pos < _size)断言检查的
//at的功能和operator[]是一样的
//只是at对越界是抛异常,它是可以捕获的
s1.at(0)--;
cout << s1 << endl;
//s1.at(15); //越界抛异常
//普通数组是没有越界检查的,它是抽查的
int a[10] = { 0 };
//a[16] = 1;//不同平台情况不同
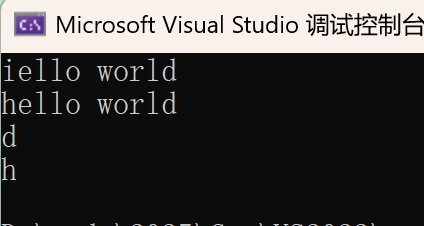
//back/front 返回结束/开始位置的字符
cout << s1.back() << endl;
cout << s1.front() << endl;
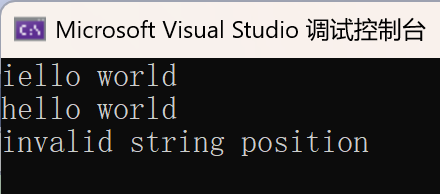
}
int main()
{
//捕获异常
try
{
test_string();
}
catch (const exception& e)
{
cout << e.what() << endl;
}
return 0;
}
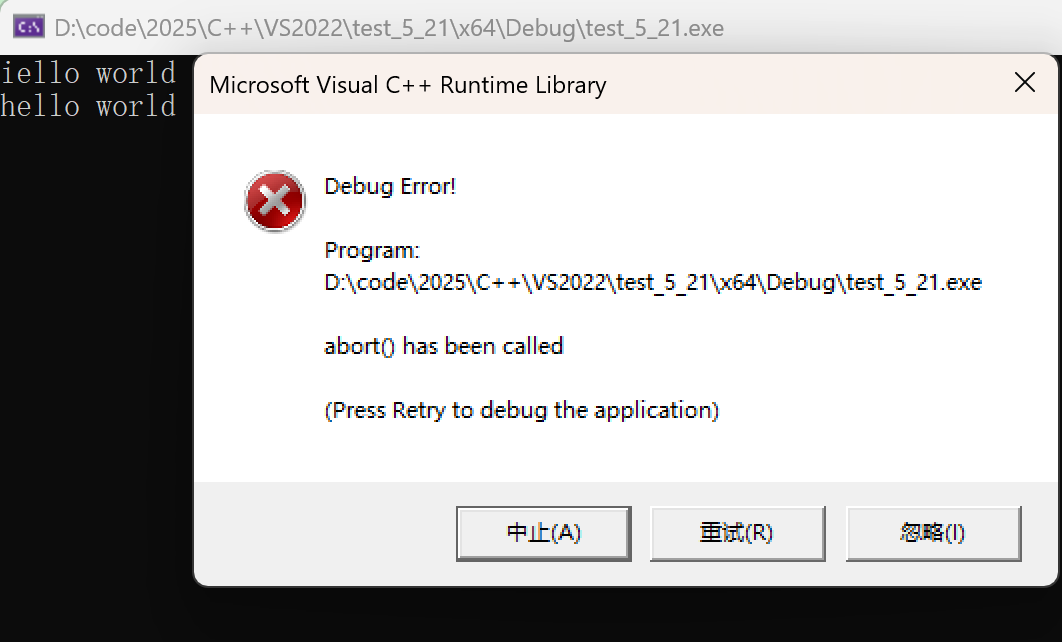
断言报错
抛异常,不捕获异常
抛异常,捕获异常
operator+=、append、assign、insert、erase、replace、find
常用:operator+=、find
int main()
{
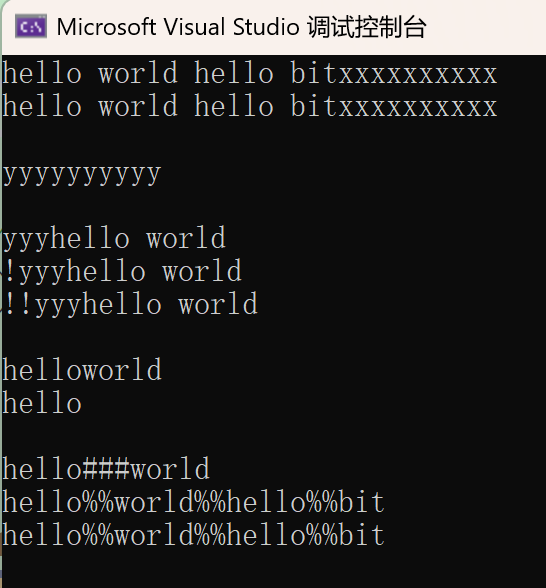
//append追加 就是尾部插入
string s1("hello world");
s1.push_back(' ');
s1.append("hello bit");
s1.append(10, 'x');
cout << s1 << endl;
//operator+= 完全可以替代append
string s2("hello world");
s2 += " ";
s2 += "hello world";
s2 += "xxxxxxxxxx";
cout << s2 << endl << endl;
//assign 赋值
//operator= 也可以替代assign
s1.assign(10, 'y');
cout << s1 << endl << endl;
//insert 在一个位置之前插入
//insert谨慎使用,底层涉及数据挪动,效率低下,O(N)
string s3("hello world");
s3.insert(0, "yyy");
cout << s3 << endl;
s3.insert(0, 1, '!');
cout << s3 << endl;
s3.insert(s3.begin(), '!');
cout << s3 << endl << endl;
//erase 删除
//erase谨慎使用,底层涉及数据挪动,效率低下,O(N)
string s4("hello world");
s4.erase(5, 1);
cout << s4 << endl;
s4.erase(5);
cout << s4 << endl << endl;
//replace 替换
//replace谨慎使用,底层涉及数据挪动,效率低下,O(N)
string s5("hello world");
s5.replace(5, 1, "###");
cout << s5 << endl;
//find 找到第一个匹配的字符或字符串
//找到返回该字符位置或该字符串首字符位置
//找不到返回string::npos
//把所有的空格替换成%%
string s6("hello world hello bit");
//效率低下
size_t pos = s6.find(' ');
while(pos != string::npos)
{
s6.replace(pos, 1, "%%");
pos = s6.find(' ', pos + 2);
}
cout << s6 << endl;
//空间换时间
string s7;
s7.reserve(s6.size());
for(auto e : s6)
{
if(e == ' ')
s7 += "%%";
else
s7 += e;
}
cout << s7 << endl;
return 0;
}
c_str、data、get_allocator
int main()
{
//c_str 返回指向字符数组的指针
//就是将string类型的字符串转换成const char*类型并返回
//c_str就是为了更好的兼容C语言
string filename("test.cpp");
//这里需要const char*类型
FILE* fout = fopen(filename.name.c_str(), "r");
if(fout == nullptr)
{
cout << "fopen error" << endl;
return 1;
}
char ch = fgetc(fout);
while(ch != EOF)
{
cout << ch;
ch = getc(fout);
}
//data跟c_str类似,可以将filename.name.c_str()
//改成filename.name.data()测试一下
//get_allocator用于获取容器当前使用的内存分配器
//get_allocator基本不会用到
return 0;
}
copy、rfind、substr
常用:rfind、substr
//找后缀
string findsubffix(string& filename)
{
//从前往后找,找到的可能不是后缀,比如filename4
//size_t i = filename.find('.');
//if (i != string::npos)
//{
// return filename.substr(i);
//}
string empty;
return empty;
return string();
//return "";
//rfind 从后往前找
size_t i = filename.rfind('.');
if (i != string::npos)
{
return filename.substr(i);
}
//string empty;
//return empty;
//return string();
return "";
}
//切分url
void split_url(string& url)
{
size_t i1 = url.find(':');
if(i1 != string::npos)
{
cout << url.substr(0, i1) << endl;
}
size_t i2 = i1 + 3;
size_t i3 = url.find('/');
if(i3 != string::npos)
{
cout << url.substr(i2, i3 - i2) << endl;
cout << url.substr(i3 + 1) << endl;
}
}
int main()
{
//copy将string类型的一个子串拷贝到一个C的字符数组中
//copy不常用,一般会用substr
//substr 拷贝当前字符数组的一个子串,并返回该子串
//string substr (size_t pos = 0, size_t len = npos) const;
//substr是从pos位置开始,拷贝len个字符
string filename("test.cpp");
string s1 = filename.substr(4);
cout << s1 << endl;
//找后缀
string filename1("test.cpp");
string filename2("test.c");
string filename3("test");
string filename4("test.cpp.tar.zip");
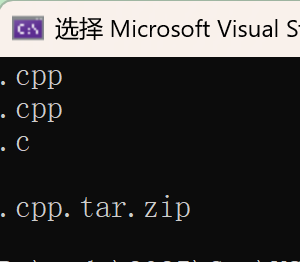
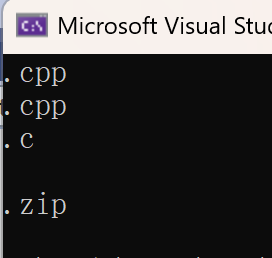
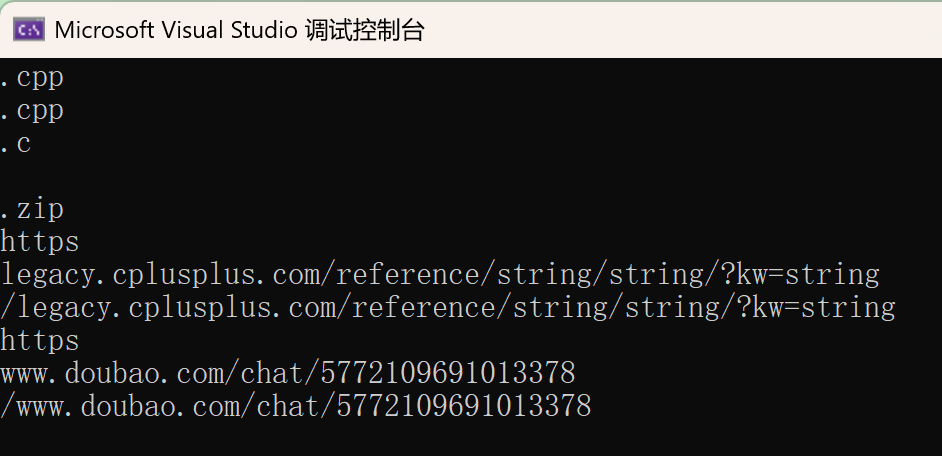
cout << findsubffix(filename1) << endl;
cout << findsubffix(filename2) << endl;
cout << findsubffix(filename3) << endl;
cout << findsubffix(filename4) << endl;
string url1 = "https://legacy.cplusplus.com/reference/string/string/?kw=string";
string url2 = "https://www.doubao.com/chat/5772109691013378";
split_url(url1);
split_url(url2);
return 0;
}
从前往后找
从后往前找
find_first_of、find_last_of、find_first_not_of、find_last_not_of
不常用
find_first_of 在当前字符串中找传参的字符串中任意一个字符并返回其位置
find_last_of 从后往前找
find_first_not_of 在当前字符串中找不是传参的字符串中任意一个字符并返回其位置
find_last_not_of 从后往前找
compare
comepare 字符串比较,不常用,因为string重载了字符串大小比较relational operators (string)
Non-member function overloads(非成员函数重载)
operator+、relational operators、getline
它们都常用
int main()
{
string s1("hshd");
string s2("hshderjfk");
const char* str = "ysdh";
//字符串大小比较relational operators (string)
s1 == s2;
s1 == str;
str == s1;
//operator+ (string)
s1 + s2;
s1 + str;
str + s1;
//getline 得到一行,跟cin相似,但是getline是遇到\n才结束
//getline也可以自己设置终止字符,但不会读入终止字符
getline(cin, s1);
cout << s1 << endl;
getline(cin, s1, '!');
cout << s1 << endl;
return 0;
}
operator>>、swap
都常用
int main()
{
//>>流提取运算符
string s1("hello world");
cout << s1 << endl;
//遇到空格或换行结束
cin >> s1;
cout << s1 << endl;
//swap等string模拟实现的时候再讲
return 0;
}
string的模拟实现
准备string.h、string.cpp、test.cpp三个文件
只实现了一些常用的功能
string.h
#pragma once
#include <cstring>
#include <cassert>
#include <iostream>
using namespace std;
//避免模拟实现的string跟库里的string重复
namespace bs
{
class string
{
public:
//迭代器类型
typedef char* iterator;
//const迭代器类型
typedef const char* const_iterator;
//我们在底层实现string的迭代器时直接把它typedef为指针了,但编译器
//底层不是这样的,其他的很多容器的迭代器是不能typedef为指针的
//迭代器[begin(), end())
iterator begin();
iterator end();
//const迭代器[begin(), end())
const_iterator begin() const;
const_iterator end() const;
//无参构造,可以直接用有参加缺省值代替
//string();
//构造
string(const char* str = "");
//拷贝构造
string(const string& str);
//string内部实现的对string类型进行交换的swap
void swap(string& str);
//传统string赋值写法
//string& operator=(const string& str);
//现代string赋值写法
string& operator=(string tmp);
//析构
~string();
//返回当前字符个数,不包含\0
size_t size() const;
//const的operator[],值不可改变
const char& operator[](size_t i) const;
//普通的operator[],值可以改变
char& operator[](size_t i);
//C++风格的string类型字符串转C风格的const char*类型字符串
const char* c_str() const;
//扩容
void reserve(size_t n);
//尾部插入
void push_back(char ch);
//追加
void append(const char* str);
//operator+=
string& operator+=(char ch);
string& operator+=(const char* str);
//在pos位置之前插入
string& insert(size_t pos, char ch);
string& insert(size_t pos, const char* str);
//删除从pos位置开始,len长度的字符
string& erase(size_t pos = 0, size_t len = npos);
//尾部删除
void pop_back();
//从前往后查找第一个匹配的字符或字符串,返回其位置
size_t find(char ch, size_t pos = 0) const;
size_t find(const char* str, size_t pos = 0) const;
//从pos位置截取len长度的子串并返回
string substr(size_t pos = 0, size_t len = npos) const;
//清空字符串
void clear();
//关系运算符
bool operator<(const string& s) const;
bool operator<=(const string& s) const;
bool operator>(const string& s) const;
bool operator>=(const string& s) const;
bool operator==(const string& s) const;
bool operator!=(const string& s) const;
private:
//成员变量
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0;
//VS2022在底层实现string时用了个buff字符数组,避免空间浪费
//_size < 16 串存在buff数组上
//_size >= 16 串存在_str指向的空间上
//char buff[16];
public:
//成员常量
static const size_t npos;
};
//非成员函数重载
//流插入和流提取
ostream& operator<<(ostream& out, const string& s);
istream& operator>>(istream& in, string& s);
//getline
istream& getline(istream& in, string& s, char delim = '\n');
//交换
void swap(string& x, string& y);
}
string.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "string.h"
//命名空间名字相同,在不同文件,是同一个命名空间
namespace bs
{
//string::string()
// :_str(new char[1]{'\0'})
// ,_size(0)
// ,_capacity(0)
//{}
string::string(const char* str)
//strlen的时间复杂度O(N),所以才只在初始化列表中初始化_size
//再在函数体中用_size给_str和_capacity赋值
:_size(strlen(str))
{
//cout << "string::string(const char* str)" << endl;
//多申请一个空间给\0
_str = new char[_size + 1];
_capacity = _size;
//strcpy和memcpy的区别
//strcpy拷贝到\0就结束了,memcpy会把给定的长度拷贝完
//所以用memcpy更保险
//strcpy(_str, str);
memcpy(_str, str, _size + 1);
}
//传统写法和现代写法的区别
//传统写法是自己造轮子,现代写法是直接用别人写好的
//传统写法
//string::string(const string& str)
//{
// //cout << "string::string(const string& str)" << endl;
// _str = new char[str._capacity + 1];
// memcpy(_str, str._str, str._size + 1);
// _size = str._size;
// _capacity = str._capacity;
//}
//string内部实现的swap
void string::swap(string& str)
{
//内置类型交换,直接用库里swap的交换
std::swap(_str, str._str);
std::swap(_size, str._size);
std::swap(_capacity, str._capacity);
}
//现代写法
string::string(const string& str)
{
//cout << "string::string(const string& str)" << endl;
//利用直接构造实例化一个tmp,再让tmp跟*this交换
string tmp(str._str);
swap(tmp);
}
//传统写法
//string& string::operator=(const string& str)
//{
// if (this != &str)//防止自己赋值自己
// {
// char* tmp = new char[str._capacity + 1];
// memcpy(tmp, str._str, str._size + 1);
// delete[] _str;
// _str = tmp;
// _size = str._size;
// _capacity = str._capacity;
// }
//
// return *this;
//}
//现代写法
//string& string::operator=(const string& str)
//{
// if (this != &str)
// {
// string tmp(str);
// swap(tmp);
// }
//
// return *this;
//}
//现代写法-更简洁
string& string::operator=(string tmp)//传值传参调用构造
{
//cout << "string& string::operator=(string tmp)" << endl;
swap(tmp);
return *this;
}
string::~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
string::iterator string::begin()
{
return _str;
}
string::iterator string::end()
{
return _str + _size;
}
string::const_iterator string::begin() const
{
return _str;
}
string::const_iterator string::end() const
{
return _str + _size;
}
size_t string::size() const
{
return _size;
}
const char& string::operator[](size_t i) const
{
assert(i < _size);
return _str[i];
}
char& string::operator[](size_t i)
{
assert(i < _size);
return _str[i];
}
const char* string::c_str() const
{
return _str;
}
void string::reserve(size_t n)
{
//cout << "reserve" << n << endl;
if (n > _capacity)
{
char* tmp = new char[n + 1];
//strcpy(tmp, _str);
memcpy(tmp, _str, _size + 1);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void string::push_back(char ch)
{
if (_size >= _capacity)
{
//扩容
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
void string::append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
//扩容
size_t newcapacity = _size + len < 2 * _capacity ? 2 * _capacity : _size + len;
reserve(newcapacity);
}
//strcpy(_str + _size, str);
memcpy(_str + _size, str, len + 1);
_size += len;
}
string& string::operator+=(char ch)
{
push_back(ch);
return *this;
}
string& string::operator+=(const char* str)
{
append(str);
return *this;
}
string& string::insert(size_t pos, char ch)
{
assert(pos <= _size);
//实际_size 不会大于_capacity
if (_size >= _capacity)
{
//扩容
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
//挪动数据 两种方法
//int end = _size;
//while (end >= (int)pos)
//{
// _str[end + 1] = _str[end];
// --end;
//}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
string& string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
//扩容
size_t newcapacity = _size + len < 2 * _capacity ? 2 * _capacity : _size + len;
reserve(newcapacity);
}
//挪动数据 两种方法
//int end = _size;
//while (end >= (int)pos)
//{
// _str[end + len] = _str[end];
// --end;
//}
size_t end = _size + len;
while (end - len + 1 > pos)
{
_str[end] = _str[end - len];
--end;
}
//memcpy(_str + pos, str, len);
for (size_t i = 0; i < len; ++i)
{
_str[pos + i] = str[i];
}
_size += len;
return *this;
}
string& string::erase(size_t pos, size_t len)
{
//要删的数据长度大于pos位置及其后面的数据长度
if (len == npos || len >= _size - pos)
{
_size = pos;
_str[_size] = '\0';
}
else
{
size_t i = pos + len;
memmove(_str + pos, _str + i, _size - i + 1);
_size -= len;
}
return *this;
}
void string::pop_back()
{
assert(_size > 0);
--_size;
_str[_size] = '\0';
}
size_t string::find(char ch, size_t pos) const
{
for (size_t i = pos; i < _size; ++i)
{
if (_str[i] == ch) return i;
}
return npos;
}
size_t string::find(const char* str, size_t pos) const
{
//strstr时间复杂度O(N^2)
const char* p = strstr(_str + pos, str);
if (p != nullptr) return p - _str;
return npos;
}
string string::substr(size_t pos, size_t len) const
{
assert(pos < _size);
if (len == npos || len >= _size - pos)
len = _size - pos;
string ret;
ret.reserve(len);
for (size_t i = 0; i < len; ++i)
{
ret += _str[pos + i];
}
//cout << &ret << endl;
return ret;
}
void string::clear()
{
_str[0] = '\0';
_size = 0;
}
//"hello" "hello" false
//"hellowww" "hello" false
//"hello" "hellowww" true
bool string::operator<(const string& s) const
{
size_t i1 = 0, i2 = 0;
while (i1 < _size && i2 < s._size)
{
if (_str[i1] < s._str[i2])
{
return true;
}
else if (_str[i1] > s._str[i2])
{
return false;
}
else
{
i1++;
i2++;
}
}
return i2 < s._size;
}
bool string::operator<=(const string& s) const
{
return (*this < s || *this == s);
}
bool string::operator>(const string& s) const
{
return !(*this <= s);
}
bool string::operator>=(const string& s) const
{
return !(*this < s);
}
bool string::operator==(const string& s) const
{
size_t i1 = 0, i2 = 0;
while (i1 < _size && i2 < s._size)
{
if (_str[i1] != s._str[i2])
{
return false;
}
else
{
i1++;
i2++;
}
}
return i1 == _size && i2 == s._size;
}
bool string::operator!=(const string& s) const
{
return !(*this == s);
}
ostream& operator<<(ostream& out, const string& s)
{
for (size_t i = 0; i < s.size(); i++)
{
out << s[i];
}
return out;
}
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch = in.get();//一个字符一个字符地读取
char buff[128];//空间换时间
int i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
buff[i] = '\0';
s += buff;//避免多次扩容,浪费时间
i = 0;
}
ch = in.get();
}
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}
istream& getline(istream& in, string& s, char delim)
{
s.clear();
char ch = in.get();
char buff[128];
int i = 0;
while (ch != delim)
{
buff[i++] = ch;
if (i == 127)
{
buff[i] = '\0';
s += buff;
i = 0;
}
ch = in.get();
}
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}
void swap(string& x, string& y)
{
x.swap(y);//直接调用string内部实现地swap
}
const size_t string::npos = -1;
//定义静态变量时,static仅在声明处需要,用于指定内部链接;定义处无需重复,避免重复声明内部链接属性。
}
test.cpp
#include "string.h"
namespace bs
{
void test_string1()
{
string s1;
cout << s1.c_str() << endl;
string s2("hello world");
cout << s2.c_str() << endl;
for (size_t i = 0; i < s2.size(); ++i)
{
s2[i]++;
}
cout << s2.c_str() << endl;
string::iterator it2 = s2.begin();
while (it2 != s2.end())
{
cout << *it2 << " ";
it2++;
}
cout << endl;
for (auto e : s2)
{
cout << e << " ";
}
cout << endl;
const string s3("hello world");
string::const_iterator it3 = s3.begin();
while (it3 != s3.end())
{
cout << *it3 << " ";
it3++;
}
cout << endl;
}
void test_string2()
{
string s1("hello world");
s1.push_back('x');
cout << s1.c_str() << endl;
s1.append("hello bit");
cout << s1.c_str() << endl;
s1 += 'y';
s1 += "zzz";
cout << s1.c_str() << endl << endl;
string s2("hello world");
cout << s2 << endl;
s2 += '\0';
s2 += '\0';
s2 += '!';
cout << s2 << endl;
cout << s2.c_str() << endl;
s2 += "yyyyyyyyyyyyyyyyyyyy";
cout << s2 << endl;
cout << s2.c_str() << endl;
}
void test_string3()
{
string s1("hello world");
s1.insert(6, 'x');
cout << s1 << endl;
//s1.insert(60, 'x');
s1.insert(0, 'x');
cout << s1 << endl << endl;
string s2("hello world");
s2.insert(6, "xxx");
cout << s2 << endl;
s2.insert(0, "xxx");
cout << s2 << endl << endl;
string s3("hello world");
s3.erase(7, 3);
cout << s3 << endl;
string s4("hello world");
s4.erase(7, 40);
cout << s4 << endl;
string s5("hello world");
s5.erase(7);
cout << s5 << endl << endl;
string s6("hello world");
while (s6.size())
{
s6.pop_back();
cout << s6 << endl;
}
//s6.pop_back();
cout << endl;
}
void split_url(string& url)
{
size_t i1 = url.find(':');
if (i1 != string::npos)
{
//string s = url.substr(0, i1);
//cout << &s << endl;
//cout << s << endl;
cout << url.substr(0, i1) << endl;
}
size_t i2 = i1 + 3;
size_t i3 = url.find('/', i2);
if (i3 != string::npos)
{
cout << url.substr(i2, i3 - i2) << endl;
cout << url.substr(i3 + 1) << endl;
}
cout << endl;
}
void test_string4()
{
string url1 = "https://legacy.cplusplus.com/reference/string/string/?kw=string";
string url2 = "https://www.doubao.com/chat/5772109691013378";
split_url(url1);
split_url(url2);
}
void test_string5()
{
string s1("hello"), s2("hello");
string s3("helloxxx"), s4("hello");
string s5("hello"), s6("helloxxx");
cout << (s1 < s2) << endl;
cout << (s3 < s4) << endl;
cout << (s5 < s6) << endl << endl;
cout << (s1 <= s2) << endl;
cout << (s3 <= s4) << endl;
cout << (s5 <= s6) << endl << endl;
cout << (s1 > s2) << endl;
cout << (s3 > s4) << endl;
cout << (s5 > s6) << endl << endl;
cout << (s1 >= s2) << endl;
cout << (s3 >= s4) << endl;
cout << (s5 >= s6) << endl << endl;
cout << (s1 == s2) << endl;
cout << (s3 == s4) << endl;
cout << (s5 == s6) << endl << endl;
cout << (s1 != s2) << endl;
cout << (s3 != s4) << endl;
cout << (s5 != s6) << endl << endl;
}
void test_string6()
{
//string s1("hello"), s2("hello");
//cout << s1 << " " << s2 << endl;
//cin >> s1 >> s2;
//cout << s1 << " " << s2 << endl;
//string line;
//getline(cin, line);
//cout << line << endl;
//getline(cin, line, '!');
//cout << line << endl;
string s3;
cin >> s3;
cout << s3.size() << endl;
cout << s3 << endl;
}
void test_string7()
{
string s1("hello");
cout << s1 << endl;
string s2(s1);
cout << s2 << endl;
s2[0] = 'x';
cout << s1 << endl;
cout << s2 << endl;
string s3;
s3 = s1;
cout << s3 << endl;
}
void test_string8()
{
//为什么string要设计一个成员函数swap和一个全局函数swap?
string s1("hello"), s2("world");
swap(s1, s2); //如果我们不实现全局的swap,这里会调用算法库
//的模板的swap,那样将会有3次深拷贝,效率低下
s1.swap(s2);//调用成员函数swap效率高,不会有拷贝问题,
//string的设计者怕使用者不知道string中有成员函数swap,
//而去调用算法库的,所以又写了一个全局的,这样它会优先调全局的
}
}
int main()
{
bs::test_string8();
//typeid返回类型或对象的真实信息
//cout << typeid(bs::string::iterator).name() << endl;
//cout << typeid(std::string::iterator).name() << endl;
}
//int main()
//{
// string s1("11111111");
// string s2("111111111111111111111111111111111111111");
// cout << sizeof(s1) << endl;//28
// cout << sizeof(s2) << endl;//28
// //库里底层实现多了个buff字符数组,以空间换时间
//}
