在LINUX中,文件分为打开的文件和未被打开的文件。研究打开的文件,本质上是研究进程与文件之间的关系;研究未打开的文件,我们要去研究这些未打开的文件是如何被管理的,所以我们就要去研究文件系统。
1. 磁盘
未被打开的文件一定是存储在硬盘上,通过文件系统进行管理的。现在,我们家用的电脑一般都是使用固态硬盘,而固态硬盘通过闪存进行存储;而在大企业里,服务器的搭建所用的存储器件,仍旧是机械硬盘,机械硬盘通过磁盘进行存储。
接下来,我们会以磁盘为例,逐步深入Linux的文件系统。
为什么在讲文件系统之前,我们要先讲磁盘呢?因为,未被打开的文件是被存储在磁盘上的,要去了解文件系统的特性,那么肯定需要去了解磁盘是如何存储文件的。
1.1 磁盘的物理结构

机械硬盘本质上是一个机电一体化的设别,当然机械硬盘中,机械的比重很大,上图便是一个机械硬盘的物理结构。
机械硬盘中的核心是磁盘,是存储数据的器件。
磁盘是两面的,每一面都可以用来存储数据。从上图中看,似乎磁头只有一个,实际上,每一个磁盘的面,都会对应有一个磁头,即磁头像夹子一样夹着一个磁盘。实际结构可以通过下图来理解:
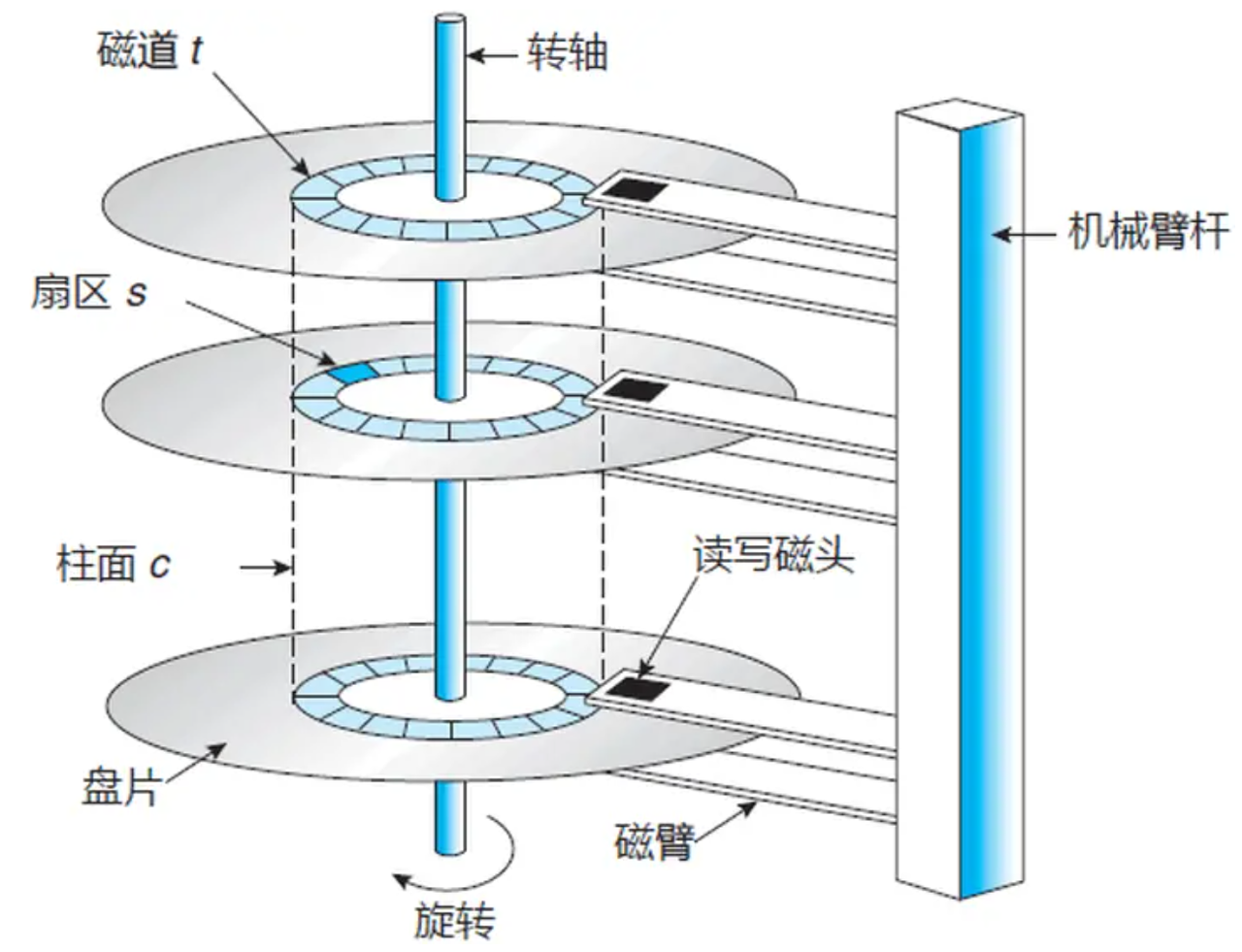
一块磁盘的一个磁面上,可用以存储数据,那么存储数据的单位如何划分呢?
扇区是磁盘上存储数据的基本单位,大小为512字节。
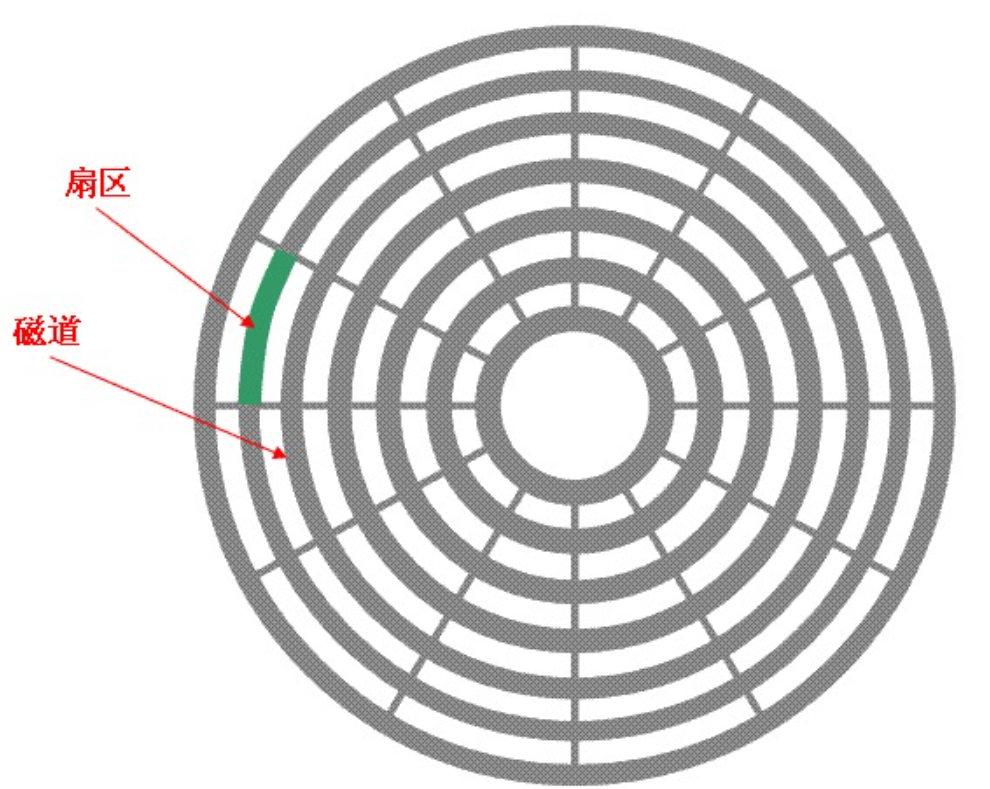
因此,整个磁盘的存储结构可以划分为如上图所示的一个个同心圆,每个同心圆上的扇区数是相等的(大部分磁盘),而内圆半径小,外圆半径大,因此必然有外圆上的扇区排列更疏,内圆上的扇区排列更紧密。
接下来,我们来了解一些描述磁盘的专有名词:
- 磁道:每一块磁盘上,一个盘面上的一个同心圆即构成一个磁道
- 扇区:磁盘存储数据的基本单位,大小为512字节
- 柱面:由于一个机械硬盘中会有多个磁盘,一个磁盘又有两个盘面,因此我们将所有磁盘的所有盘面中的半径相同的同心圆,称这些半径相同的同心圆为一个柱面。
1.2 磁盘的CHS定址法
在磁盘中,我们该如何定位一个扇区呢?
在机械硬盘中,有两个设备是频繁运动的:一个是高速旋转的磁盘,一个移动的磁头。
磁盘自身旋转的运动无需多说,但是磁头的移动,虽然一个盘面对应一个磁头,但这多个磁头是沿着盘面的半径方向共进退的。
因此,我们可以得出一个结论:盘面自身的旋转可以在一个同心圆上切换扇区,磁头的运动可以切换同心圆。
所以,我们定位一个扇区,本质上就是定位这个扇区在哪个同心圆上,在哪个盘面上,又是这个同心圆的哪个扇区。
通过对磁盘柱面,磁头和扇区进行编号,我们就有了CHS定址法。
CHS中,C是指cylinder,即柱面;H是指header,即磁头;S是指sector,即扇区。所以,通过三个编号,就可以定位任意一个扇区的位置。使用CHS定址法,操作系统看待磁盘可以用一个三维数组来看待,要与磁盘进行数据交互,给磁盘三个数字即可。
1.3 磁盘的LBA定址法
上述介绍了磁盘的CHS定址法,但实际上,从操作系统层面来看,每次都要提供三个编号给磁盘,才能访问特定位置的扇区,太低效了,因此在操作系统层面,不会以一个三维数组来看待磁盘。
那么操作系统究竟是如何看待磁盘的呢?
我们先来理解磁盘的一个柱面。磁盘的柱面,是由多个磁道上的同心圆构成的,一个圆形的磁道如果将其拉直展开,上面的扇区排布,正如一个一维数组的分布,而如果我们将这个柱面展开,是不是可以近似得到一个二维数组:

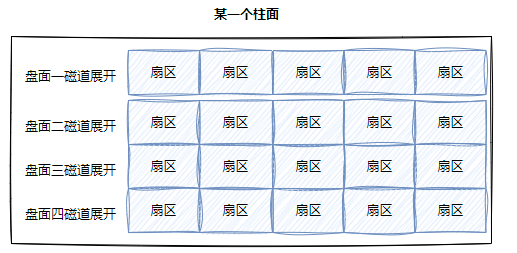
一个机械硬盘中有多个磁盘,这多个磁盘如果我们从柱面的角度,把每一个柱面都展开的话,一个柱面相当于一个二维数组,再对不同柱面加以编号,是不是就能得到一个三维数组:
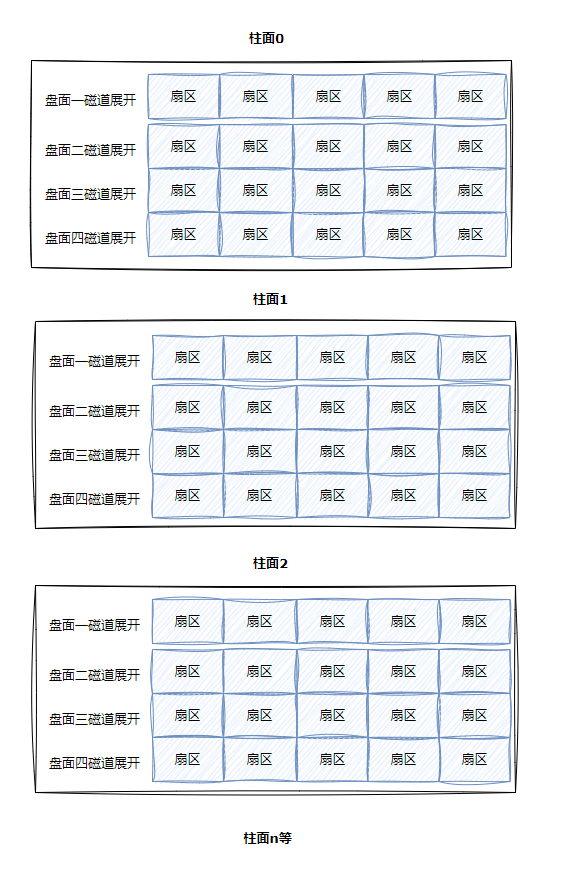
而本质上,三维数组也是可以一维看待的。这样我们就只需要一个数,就可以定位任意一个扇区了,而这就是LBA定址法。实际上,在磁盘内部仍旧是使用CHS定址法,只不过操作系统可以将磁盘看待成一个一维数组,使用一个数进行定位。
在实际访问时,操作系统将使用LBA定址法得到的数传递给磁盘,由于磁盘柱面数,一个柱面中的磁道数,一个磁道中的扇区数都是固定的,因此磁盘内部的电路就可以将这一个使用LBA定址法得到的一个数,转变为CHS定址法中的三个数,进而定位任意扇区。

2. 文件系统
2.1 磁盘是块设备
磁盘的最小存储单位是扇区,大小为512个字节。但是实际上,OS与磁盘进行交互的时候,不会以扇区为单位,这样读写的效率太低了。操作系统与磁盘进行交互,总是以八个扇区为单位,即4KB的形式进行访问。我们把这八个扇区构成的单位称作数据块,即操作系统以数据块的形式访问磁盘,磁盘也就是块设备.
所以,实际上,OS看待磁盘,是一个以块为单位的一维数组,即block array[N]。
操作系统使用LBA定址法,将磁盘抽象为一个以扇区为成员的一维数组sector array[N],而一个块中的扇区数为8,因此由块号我们可以得到具体块中八个扇区的编号,即扇区的LBA编号,而LBA编号又可以转化为CHS的三个编号,进而OS通过块号就可以实现对磁盘的八个扇区的访问。
2.2 磁盘分区
我们已经知道操作系统以数据块的形式,即4KB的形式,对磁盘进行数据访问。
但是,一个磁盘太大了,动辄512GB,1TB,2TB,如果只以块的形式来看待磁盘,那么磁盘上的块数就太多了,并不好管理。所以,操作系统看待磁盘会对磁盘进行分区。
通常情况下,一个柱面为分区的最小单位。因此,确定一个分区,实际上只要确定这个分区的起始柱面号和终止柱面号即可。
所以,如果我们的电脑只有一块机械硬盘的话,那么我们所看到的C盘,D盘,E盘,本质上是操作系统对这块机械硬盘中的磁盘所划分的不同分区罢了。
2.3 磁盘分组
操作系统将整块磁盘进行分区以便管理,但是分区相对来说还是很大,于是操作系统进一步划分分区,将一个分区划分为多个组,由于这些组实际上是由一个个数据块构成的,因此这些组又被称为块组,即BLOCK GROUP。
现在,我们管理好整块磁盘,实际上知道如何管理好一个块组即可——管理好一个块组,就能管理好一个分区;管理好一个分区,就能管理好一块磁盘。
所以,接下来,我们来研究一个块组的内部是如何进行划分和管理的。
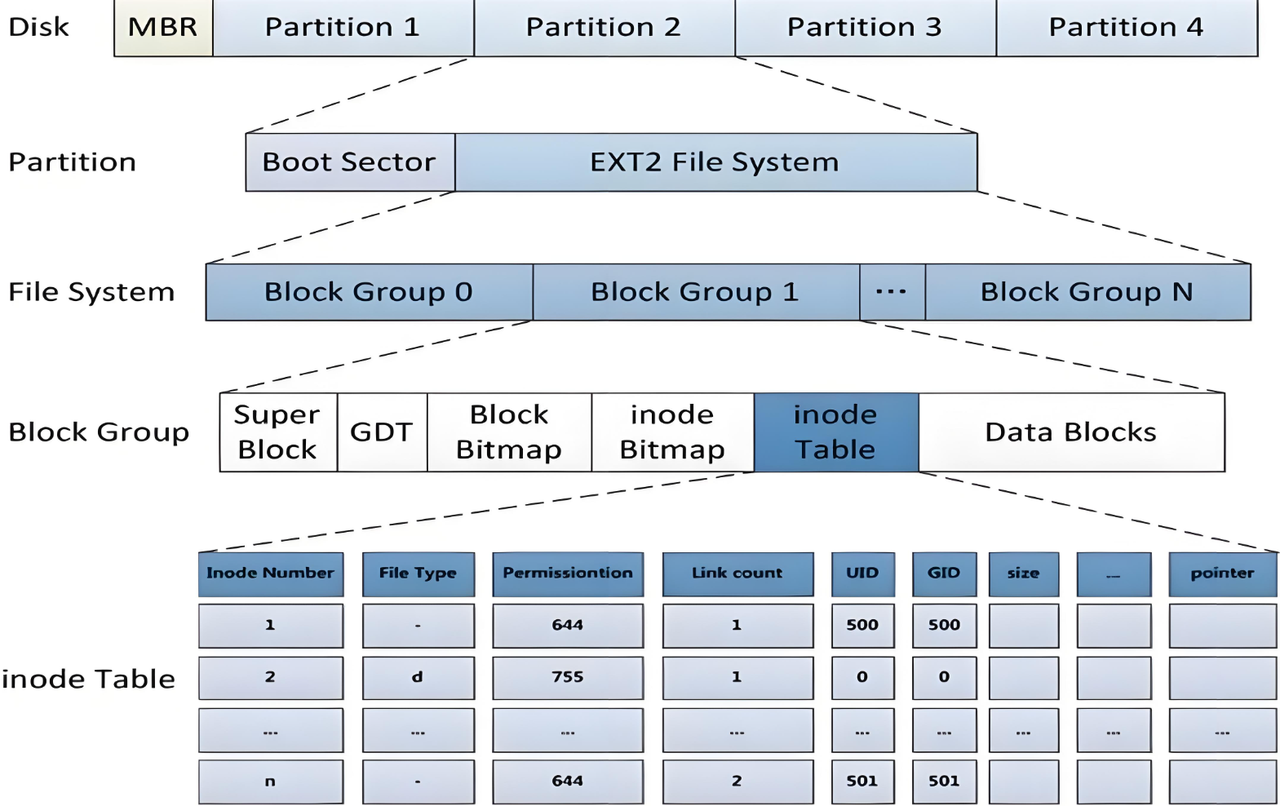
通过上图,我们可以了解到,一个块组有6个分区,下文将分别介绍这6个分区。
2.3.1 inode table 和 data block
文件=文件内容 + 文件属性,Linux的文件系统中,文件的内容和属性是分开存储的,文件的属性存放在一个struct inode的结构体中,文件的内容则存储在data blocks中。
先来说,data blocks。
在data blocks的内部,有一块块4KB大小的空间(操作系统访问磁盘的基本单位大小为4KB),这些空间就用于存储文件的内容。一个文件可能一个data block都不会使用,即无文件内容;一个文件也可能使用多个data block。
再来说,inode table
inode table本质上是一个inode的表结构,其中的空间全部用来存放struct inode。struct inode中保存的是相应文件的属性,当然一个文件肯定要能够找到它的文件内容,因此struct inode必定存储有该文件所对应的数据块号。
由于操作系统访问磁盘,以4KB为单位,而struct inode大小一般为128或256字节,因此操作系统访问磁盘读取inode,一次必然拿到多个inode,那么OS如何区分到底拿哪个inode呢?在struct inode中,会存在一个数字,这个数字用以唯一标识该inode和其所对应的文件,这个数字被称为inode号。
在命令行中,我们可以使用ls -li来查看当前目录下对应文件的inode号。

一个文件,有且仅有一个inode,但是data block 的数量可以为0或多个。
当然,inode会有inode号,这个inode号,是以分区为单位的,即在一个分区中进行编号;当data block 也有编号,不过data block 的编号是基于一个块组而言的,不过从一个分区来看,不同的块组会有编号,因此在一个分区中,只要确定块组号,再确定data block 的编号,也就能定位任意一个分区内的data block。
2.3.2 inode bitmap 和 block bitmap
现在,我们已经清楚文件的内容和属性在磁盘上如何存储,但是实际文件存储过程中,操作系统怎么知道存储到inode table中的哪个inode中,存储到data blocks的哪个data block中呢?
与文件描述符表中用于表示该文件描述符是否被占用一样,我们同样引入位图结构。
inode bitmap中,每一个二进制数位对应一个inode,二进制数位的1/0表示该inode是否被占用;
block bitmap中,每一个二进制数位对应一个data block,二进制数位的1/0表示该data block是否被占用。
所以,OS系统在向磁盘中存储文件时,会首先从低位开始查找inode bitmap,找到未被占用的inode,将相关文件的属性存储进去;对于block bitmap也是同样的道理。
2.3.3 GDT
GDT,英文全称group descriptor table,即块组描述符表。
在这个结构体中,记录整个块组的相关信息,例如整个块组的空间划分情况,以及未被占用的inode数和data block数等等。
2.3.4 super block
super block,即超级块。
前面我们说,操作系统将磁盘进行分区划分,分区内部又进行块组划分,那么文件系统是对什么做管理呢?
文件系统是对分区做管理的,也就是说,一个分区对应一个独立的文件系统,或者说一个分区本身就是一个独立的文件系统。
而超级块,就是记录整个分区相关文件信息的一个结构体。比如说,超级块内部会有如下信息:整个分区有多少个块组,每个块组多大,总共有多少个inode和data block,总共有多少个未被占用的inode 和 data block等等。
不过让人疑惑的是,super block既然是描述整个分区,为什么要放在一个块组内部呢?
实际上,不是所有块组内部都有super block,但一定存在多个块组,其内部含有super block。这本质上是一种容灾备份,因为super block管理的是整个分区,即一个文件系统的信息,如果其中的信息丢失了,整个文件系统,整个分区,就没有办法正常工作了,因此必须要容灾备份,这样即便一个块组中的super block损坏了,还可以使用别的块组中的super block,同时恢复这个被损坏的super block。
2.3.5 磁盘分区的格式化
LINUX中,将磁盘进行分区划分,一个分区对应一个文件系统,所以一个在Linux中,一个磁盘要想能够被OS使用,必须分区且格式化。
那什么是格式化呢?磁盘的分区肯定要通过文件系统进行管理,格式化本质上就是向磁盘中写入文件系统的相关信息,具体来说,就是写入super block 和 gdt 等的相关管理信息,这就是对磁盘分区的格式化。
所以,将一块磁盘分区格式化,就是重新写入信息,而这些重新写入的信息,会将整个分区当作未存储任何文件属性和文件内容来看待。
2.4 重新理解不同的文件操作
现在,基于上述知识,我们来重新理解一下不同的文件操作。
新建文件:即建立对应的文件inode 和 data block,并将inode bitmap 和 block bitmap 中相关比特位置为1,表示有效占用即可。
删除文件:不需要真正删除文件inode 和 data block 中的存储信息,只需要将两个位图结构中的相应比特位置为0即可,即覆盖式删除。这也说明了为什么,删除一个文件总是远远快于新建一个 文件。
修改文件:OS通过文件inode编号找到对应文件,然后向相应文件的inode和data block 中做写入。
查文件:OS通过文件编号inode找到对应文件,然后从相应文件的inode和data block中,获取相关的信息。
不过,实质上,文件系统的部分信息是会被加载到内存中的,对文件的增删查改的操作,都不是直接进行磁盘级I/O,而是先在内存中,对相关结构,如struct file/struct inode(内存中的,注意与磁盘级的inode 做区分)做修改,或是向文件内核缓冲区中写入,最后再刷新到磁盘上的,即先内存级的修改,再覆盖到磁盘上。
2.5 目录文件和普通文件
在Linux操作系统中,系统会区分普通文件和目录文件,但是在磁盘上,在文件系统中,这两者是不做区分的,都是文件,都是一样的存储方式,分区的inode中存储文件属性,分区的data block中存储文件内容。
目录文件存储中,文件属性的存储可以理解,但文件内容存什么呢?
目录文件中,其内容为该目录下文件名与inode号的映射关系。
在Linux中,文件属性struct inode中,是不包含文件名的。那么我们是如何通过文件名去访问相关文件的呢?正是因为目录文件中,存放了文件名与inode号的映射关系,在访问一个文件前,OS会先打开该文件所在的目录,拿到其中对应的映射关系,即拿到相应文件的inode号,由于inode号是唯一标识文件的,因此也就可以访问到相应文件。
所以,现在我们就可以理解,一个目录下,为什么不能有同名文件。因为目录文件,其内容存放的是映射关系,而文件名是映射关系的键值,当然不能重复。
同时,我们也可以明白,在指定目录下新建文件的本质了——除了要写入新建文件的inode和data block,还要向其所对应的目录文件内容中,写入文件名和inode号的映射关系。
3. Linux 路径
3.1 路径解析
Linux中,通过路径来定位文件。
这该怎么理解呢?
比如说,我们现在有这么一个路径:/home/wnf/code.c
这个路径标识了code.c这个文件的存储位置,那该路径能否唯一标识且定位code.c这个文件呢?
我们在访问code.c这个文件的时候,OS是会对code.c所在的路径做解析的。对于根目录,OS会特殊处理,根目录有其固定的inode号和磁盘存储位置,我们只需要关注根目录后的路径即可。
整个路径解析的过程是这样的。OS首先到根目录的文件内容中,获取home所对应的inode号,然后再到home这个目录文件内容中,获取wnf所对应的inode号,最后再到wnf这个目录文件内容中,获取code.c所对应的inode号,拿到code.c的inode号后,才可以访问到code.c这个文件。
通过这样的路径解析过程,最终访问到的文件一定是唯一且确定的,即Linux中,通过路径来定位文件。
3.2 路径缓存
前面提到,在磁盘中,文件被统一看待,不区分目录文件和普通文件。
但是,我们在Linux中,使用tree命令,确实能看到整个文件系统的树形结构,看到这个树形结构中,目录文件和普通文件被区分开——非空目录文件为路上结点,空目录文件和普通文件为叶子结点,这是为什么呢?
而且,Linux中,对文件的任何操作,首先都需要定位到该文件,而定位到该文件必须要对该文件的绝对路径进行解析,但是每次路径解析,理论上都需要从根目录开始解析,这是不是太低效了,有没有解决方法呢?
所以,针对上述两个问题,我们要引入Linux中,路径缓存和目录树的概念。
Linux中,在做路径解析时,会对第一次解析到的路径做路径缓存,创建一个struct denftry的结构。什么意思呢,我们继续使用3.1中的示例:/home/wnf/code.c
在第一次对这个路径做解析的时候,解析的顺序是根目录、home目录、wnf目录和code.c文件,那么在这整个第一次的解析过程中,OS会分别为这四个文件创建struct dentry结构,即目录树结构,如下图所示:
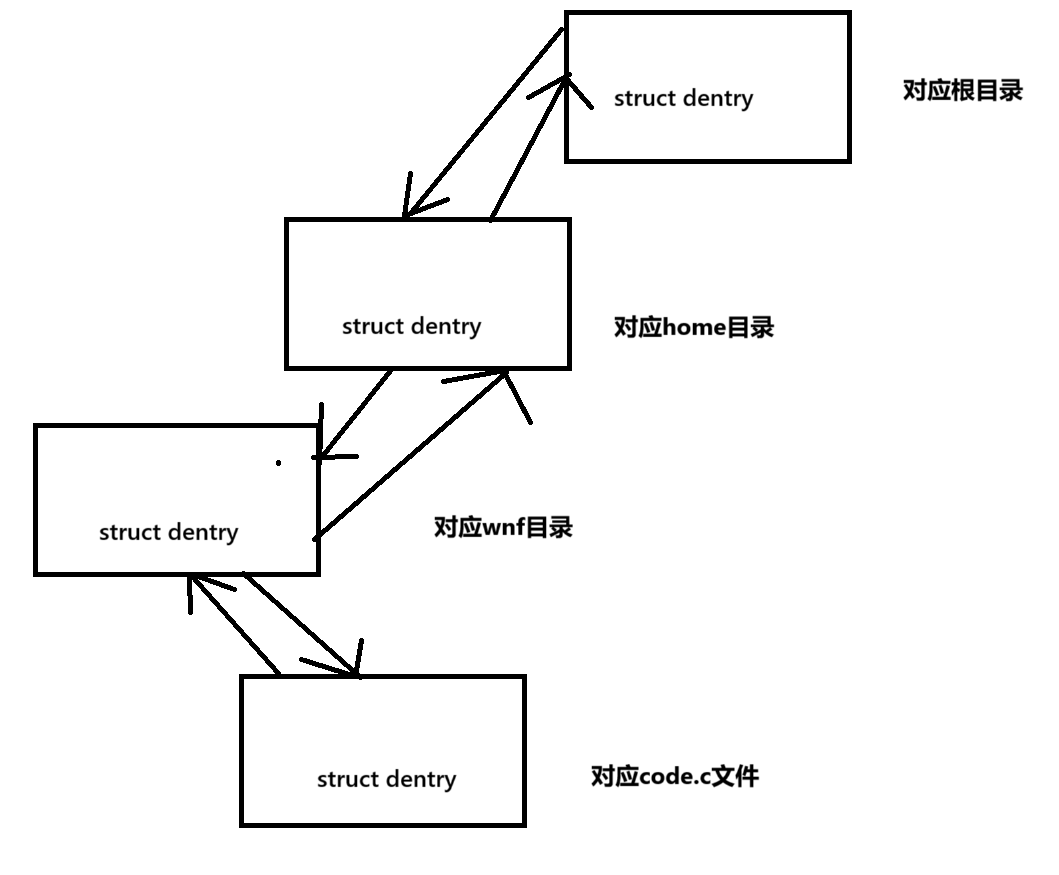
OS在第一次对上述路径做解析时,会在内核中,形成并维护这样一棵多叉树结构。当然,我们还得了解struct dentry中的内容,才能对这棵目录树有更深刻的理解。
struct dentry与某条路径上的文件是对应的,因此struct dentry中,会存储对应文件的文件名和一个指向该文件struct inode的指针;同时,struct dentry本质上维护一棵树形结构,因此其内部一定存在记录该struct dentry父结点(不存在或唯一)和子结点(不一定唯一)的变量。
现在,我们可以来理解,OS内核中,维护这样的一棵多叉目录树,即进行路径缓存有什么用了。
进行路径缓存后,OS在做路径解析时,只有第一次会是最慢的,之后做路径解析时,OS会首先从整棵目录树的根结点开始,向下遍历,不断去匹配struct dentry中所存储的路径文件名,如果能够匹配成功,就继续向下到子结点,继续匹配;如果无法匹配成功,就为这个新的文件创建新的struct dentry,然后链入到目录树中,进行路径缓存。
所以,有了路径缓存后,进行路径解析时,对于已缓存的路径,就不要频繁查看目录文件内容去找到对应映射,也就是减少了磁盘级I/O,可以直接通过dfs整棵目录树,找到目标文件所对应的dentry结构,而dentry结构中,恰好就有指向struct inode的指针,即可以拿到目标文件的inode号,也就可以访问磁盘上的目标文件了——这样,多次磁盘级I/O,变为了一次磁盘级I/O,效率显然大大提升了。
3.3 路径缓存:一个结论和一个问题
所以,一个结论:在文件系统中,统一看待目录文件和普通文件,因此文件系统并没有树形结构的概念;而我们平时所讲的Linux文件系统的多叉树结构,本质上是OS内核自身重新维护的,是内存级别的。
当然,还有一个问题,文件系统中可能会存储很多文件,不同的文件有不同的路径,因此要进行缓存的路径可能会非常多,而路径缓存是内存级别的,内存相比于磁盘小得多,那会不会出现内存短缺的情况呢?
答案是不会的。因为OS会通过LRU算法(least recently used,即最近最少使用),优化路径缓存,即把一些最近一段时间最少访问的路径所对应的struct dentry进行释放,即这些路径不再缓存,以保证维护的目录树不过多使用内存。
4. 磁盘挂载
一个磁盘分区如果想被使用,仅仅格式化还不够,还必须要进行磁盘挂载,即将磁盘分区与指定的目录相关联,这个磁盘分区才能够正常使用。
什么叫将磁盘分区与指定的目录相关联呢? 简单来说,将一个磁盘分区与指定目录关联后,之后在该目录所延伸出的路径中的文件,都会存储在与该目录相关联,即挂载的磁盘分区中。从这个角度上理解,磁盘分区挂载到指定目录后,有点指定该目录为其代理人的意思。
在Linux中,我们可以使用df命令,来查看文件系统,即磁盘分区的使用情况,还可以显示该磁盘分区的挂载情况。
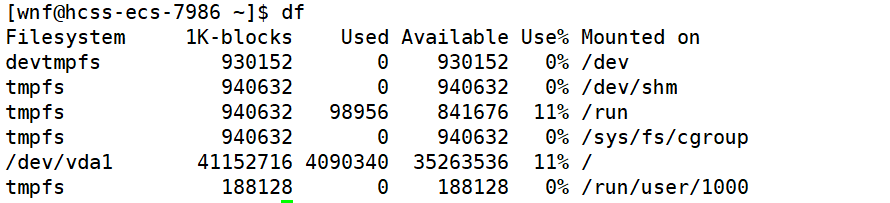
上图中,mounted on一栏下的内容,即为对应磁盘分区的挂载目录。我们可以清楚看到,/dev/vda1这个磁盘分区被挂载在根目录下。
理解了磁盘挂载之后,我们现在就可以解决之前并没有谈及的一个问题:inode以分区为单位进行编号,即一个分区中,inode号不可能相同,但不同分区中,一定会存在相同的inode号。
而我们之前讲过,OS只要拿到对应文件的inode号,就可以找到对应文件,可是OS系统又是怎么知道这个inode号是位于哪个分区呢?
通过磁盘分区挂载,我们可以知道,一个确定的路径,它所对应的磁盘分区是确定的,因为一个路径下,只能挂载一个磁盘分区。所以,在Linux中,通过路径定位一个文件,而OS在对目标文件路径做解析时,会将目标文件路径与所有磁盘分区的挂载路径进行比较(前导匹配),找到最符合的一条路径后,OS就会断定目标文件在挂载在该路径所对应目录上的磁盘分区中,最终拿到目标文件的inode号后,就到相应磁盘分区上拿到该文件了。
所以,通过磁盘挂载路径的前导匹配,可以确定磁盘分区,同时又可以拿到文件的inode号,这样OS就可以定位任意一个磁盘分区中的任意一个文件,即可以对磁盘上的任意文件进行操作。
5. 软硬链接
5.1 软硬链接是什么
在理解软硬链接是什么之前,我们先来看看Linux中,给一个文件建立软硬链接的操作。
建立软链接:ln -s target link,target表示被链接的目标文件,link表示创建的软链接。
建立硬链接:ln target link,target表示被链接的目标文件,link表示创建的硬链接。
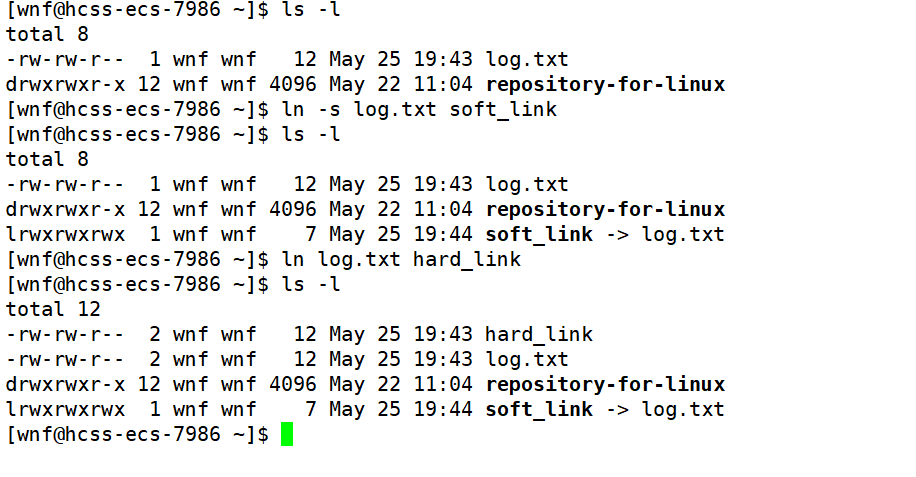
那么,软硬链接究竟是什么呢?它们又有什么区别呢?

通过上图我们可以发现,由于文件的inode号唯一标识文件,实质上,我们为log.txt创建的硬链接和log.txt文件名本身指向相同的文件,也就是说,硬链接并不是一个独立的文件,正如C++中的引用是取别名,本质并没有新建变量一样,为一个文件创建硬链接,就是为这个文件取别名,本质上讲,就是在向该文件所对应的目录文件的内容中,写入一组新的映射关系。
就上图而言,硬链接hard_link和文件名log.txt没有区别,本质都是映射到相应磁盘分区inode号为658871的文件。
而软链接soft_link,我们可以发现其inode号与log.txt不同,说明软链接是一个独立的文件。那么软链接与被链接文件有什么关联呢?在LINUX中,我们对软链接文件的所有操作,都会被转化解释为对软链接所链接文件的操作。
软链接soft_link之所以能够实现上述转化,是因为在软链接文件的内容中,存储了其所链接文件的绝对路径,对软链接文件的操作,会在OS识别到该文件为软链接文件后,拿到其文件内容中的绝对路径,进而转化为对其所链接文件的操作。
5.2 软硬链接的应用
硬链接本质上是已有文件的别名,它可以起到给文件备份的作用。
实质上,在文件的struct inode结构体中,有一个引用计数的变量,表明映射到该文件的硬链接数,如果指向该文件的硬链接数为0,操作系统便会删除该文件。所以,为文件创建硬链接,可以起到容灾备份的作用。
而软链接是一个独立的文件,它的文件内容中存储其所连接文件的绝对路径,进而可以链接到该文件。
试想,如果一个文件在一个很长的路径下,那么我们要对这个文件进行操作是很麻烦的,要么直接列出该文件的路径,要么就要进到该文件所在的目录后,再对该文件进行操作,这样实在是太麻烦了。
而我们通过在一个比较方便简短的路径下创建软链接文件,链接到这个文件上,就可以实现对这个文件的便捷操作了。在windows中,我们所常用的快捷方式,本质上可以说就是一个软连接文件,其文件内容中,一定包含了其所链接对应的可执行文件的绝对路径。
其实,通过硬链接也可以实现上述软链接的功能,那为什么一般不用硬链接实现呢?
因为硬链接是与inode号绑定在一起的,这就决定了,硬链接只能在分区内链接;而软连接作为独立文件,其文件内容中直接存储了被链接文件的路径,因此可以跨分区链接,适用范围更广,更灵活。
因此,我们往往使用硬链接进行文件的容灾备份,而使用软链接来达到类似快捷方式的作用。
5.3 软硬链接和目录文件
在Linux中,我们可以给普通文件和目标文件设置软链接。
给目标文件设置软链接的时候,需要小心谨慎,因为可能会造成路径环路问题。
而对于硬链接,我们可以给普通文件创建硬链接,但是OS不允许我们在用户层面给目录文件创建硬链接。
不允许的原因很简单,为了防止出现路径环路问题。但实际上,OS自身已经给目录文件创建了硬链接。
我们在LINUX中,使用ls -al命令可以查看到两个隐藏文件:

这两个隐藏文件,分别代表当前目录和当前目录的上一级目录,实质上,这两个文件就是当前目录和上一级目录的硬链接文件。
通过下图我们可以进行验证:
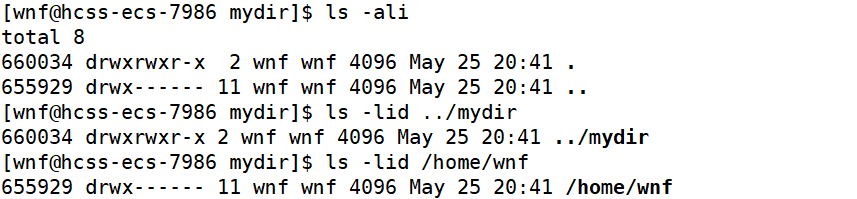
我们可以看到,inode号是两两对应的。并且,对于在/home/wnf目录中所创建的空目录文件mydir而言,我们可以看到上图中有一个数字2,这就代表了该空目录文件的引用计数为2,刚好分别对应了两个硬链接:一个mydir和另一个.。
虽然OS自己默认给目录文件设置了硬链接,但是OS内部做路径解析时,会对其自身设置的这两个硬链接做特殊判断——如果在路径开头,则正常解析;如果在路径中或路径末尾,则自动跳过不解析。这样,也就避免了路径环路问题。