文章概述
本文介绍了如何在 华为开发者空间 中快速部署并使用 Ollama 模型运行框架,并结合 deepseek-r1 模型进行本地或远程交互推理。内容涵盖环境准备、模型配置、网卡绑定、内网穿透、API调用等多个环节,适合希望在华为云上快速搭建本地类大模型推理环境的开发者参考使用。
华为开发者空间介绍
华为开发者空间,是为全球开发者打造的专属开发环境,致力于为每位开发者提供一台云主机、一套开发工具和云上存储空间。该平台汇聚了昇腾、鸿蒙、鲲鹏、GaussDB、欧拉等华为核心技术生态的开发资源,并配套提供案例指导,支持开发者从开发编码到调测部署的完整流程。
依托这一平台,开发者可快速构建和部署 AI 模型应用,尤其适合进行类 ChatGPT 等本地部署实验,也非常适用于 LLM(大语言模型)的微调、推理和集成测试。
安装 Ollama
curl -fsSL https://dtse-mirrors.obs.cn-north4.myhuaweicloud.com/case/0035/install.sh | sudo bash
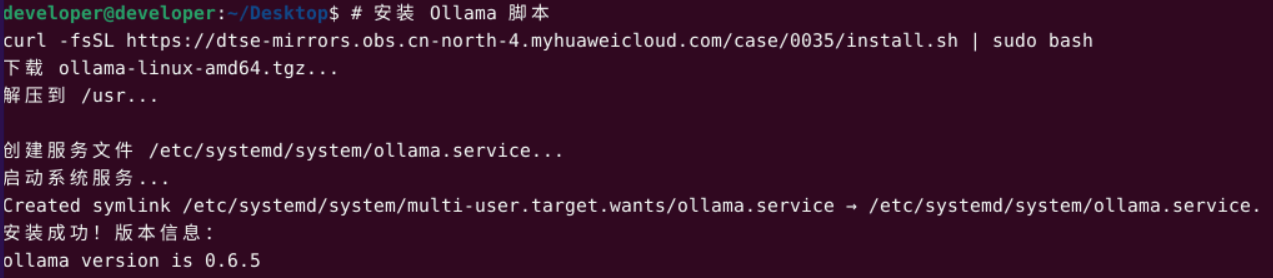
安装完成后建议立即验证 Ollama 是否部署成功:
ollama --version

如果返回版本信息,说明安装成功。
配置 deepseek 模型
我们以 deepseek-r1:1.5b 模型为例进行演示:
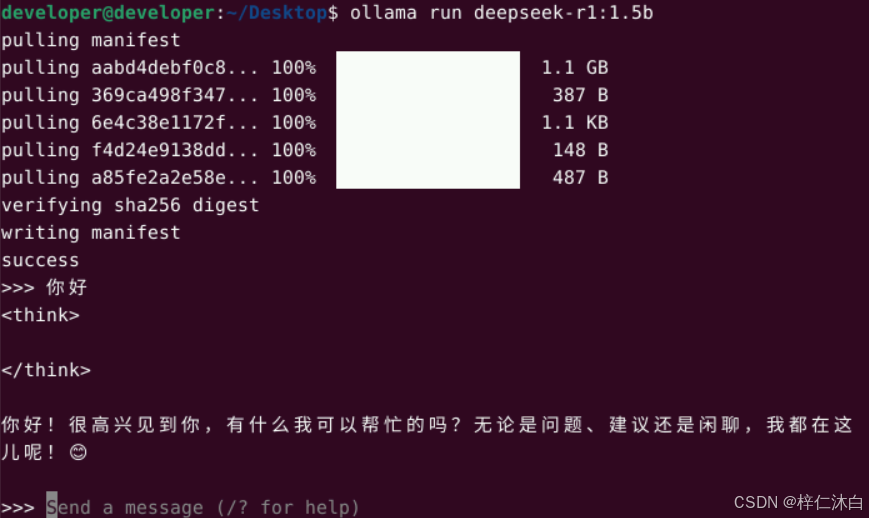
ollama run deepseek-r1:1.5b
第一次运行会自动从网络下载对应模型到本地缓存。此模型具备基础的语言理解能力,适合用于轻量级推理或嵌入测试。
模型版本与参数规格对比表
| 模型名称 | 模型大小 | 上下文长度 | 输入类型 |
|---|---|---|---|
| deepseek-r1:latest | 4.7GB | 128K | Text |
| deepseek-r1:1.5b | 1.1GB | 128K | Text |
| deepseek-r1:7b latest | 4.7GB | 128K | Text |
| deepseek-r1:8b | 4.9GB | 128K | Text |
| deepseek-r1:14b | 9.0GB | 128K | Text |
| deepseek-r1:32b | 20GB | 128K | Text |
| deepseek-r1:70b | 43GB | 128K | Text |
| deepseek-r1:671b | 404GB | 160K | Text |
这些模型适配不同规模的服务器资源,你可以参考下表选择合适的模型部署:
| 模型磁盘大小 | 模型参数量(估计) | 推荐显存(GPU) | 推荐内存(CPU-only) |
|---|---|---|---|
| 1.1GB | 1.5B | ≥ 4GB | ≥ 6GB |
| 4.7GB | 7B | ≥ 8GB | ≥ 12GB |
| 9GB | 14B | ≥ 16GB | ≥ 20GB |
| 20GB | 32B | ≥ 24GB | ≥ 32GB |
| 43GB | 70B | ≥ 48GB | ≥ 64GB |
| 404GB | 671B | 多卡分布式 GPU | 不推荐 CPU 运行 |
建议开发者根据云主机所分配的 CPU 内存或是否拥有 GPU 资源来判断模型选择,不要轻易加载超过自己硬件承载能力的模型,避免系统卡顿或崩溃。
运行模型后即可进入 CLI 交互界面:
ollama 绑定网卡
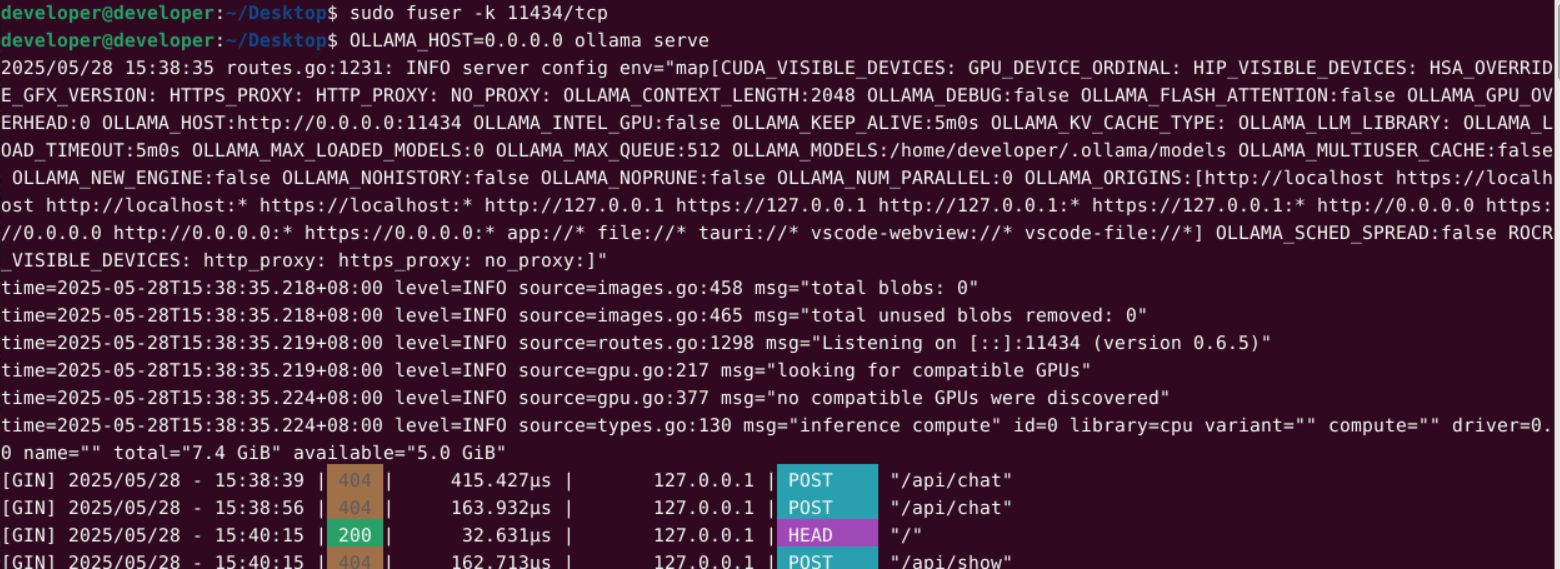
为了使本地网络可以访问部署在华为开发者空间的 Ollama 服务,需要绑定监听全部网卡(0.0.0.0):
killall ollama
OLLAMA_HOST=0.0.0.0 ollama serve
若报错:Error: listen tcp 0.0.0.0:11434: bind: address already in use,说明端口未释放。
解决步骤:
- 查询占用端口的进程:
sudo netstat -tulpn | grep 11434

- 强制终止对应进程:
sudo kill -9 <PID>
- 若仍然异常,确认是否存在僵尸进程:
ps aux | grep ollama
- 再次尝试启动服务:
OLLAMA_HOST=0.0.0.0 ollama serve
内网穿透
由于华为开发者空间提供的是 Cloud IDE 环境,默认不提供公网 IP,因此需要借助内网穿透工具将云环境映射到公网,本文选用 ngrok。
当然如果你的是正常的服务器,就可以用公网ip地址来访问,不用这么麻烦了。
工具官网:
https://ngrok.com/
步骤一:注册 ngrok 并获取 token
- 打开官网注册账号
- 登录后台进入 Dashboard,复制 Authtoken
步骤二:下载与配置
wget https://bin.equinox.io/c/bNyj1mQVY4c/ngrok-v3-stable-linux-amd64.tgz
tar -xzf ngrok-v3-stable-linux-amd64.tgz
./ngrok version # 确认版本
添加身份令牌:
./ngrok config add-authtoken <YOUR_AUTHTOKEN>
启动代理:
./ngrok http 11434
运行结果如下所示:
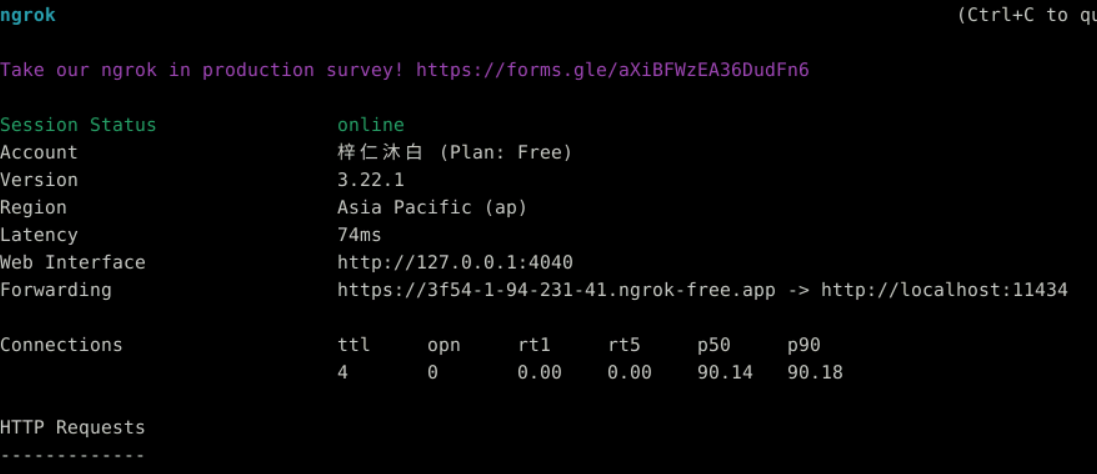
页面中给出的 https://xxxx.ngrok-free.app 即为你临时生成的公网访问地址,可用于访问 Ollama 接口。
在本地使用
Ollama 模型服务默认兼容 OpenAI API 协议,因此可以通过 OpenAI SDK 调用部署在远端(内网穿透后)的模型,便于开发集成。
下面是一个使用 OpenAI Python SDK 的示例:
from openai import OpenAI
client = OpenAI(
base_url="https://<你自己的临时域名>.ngrok-free.app/v1",
api_key="ollama" # Ollama不需要真实API Key,填写任意内容
)
response = client.chat.completions.create(
model="deepseek-r1:1.5b",
messages=[
{"role": "system", "content": "你是一个有帮助的AI助手"},
{"role": "user", "content": "讲一下华为云主机"}
],
temperature=0.7
)
print(response.choices[0].message.content)
注意:由于使用了内网穿透服务,通信质量较差时可能出现响应缓慢的情况,建议将其作为临时测试或调试用途使用。
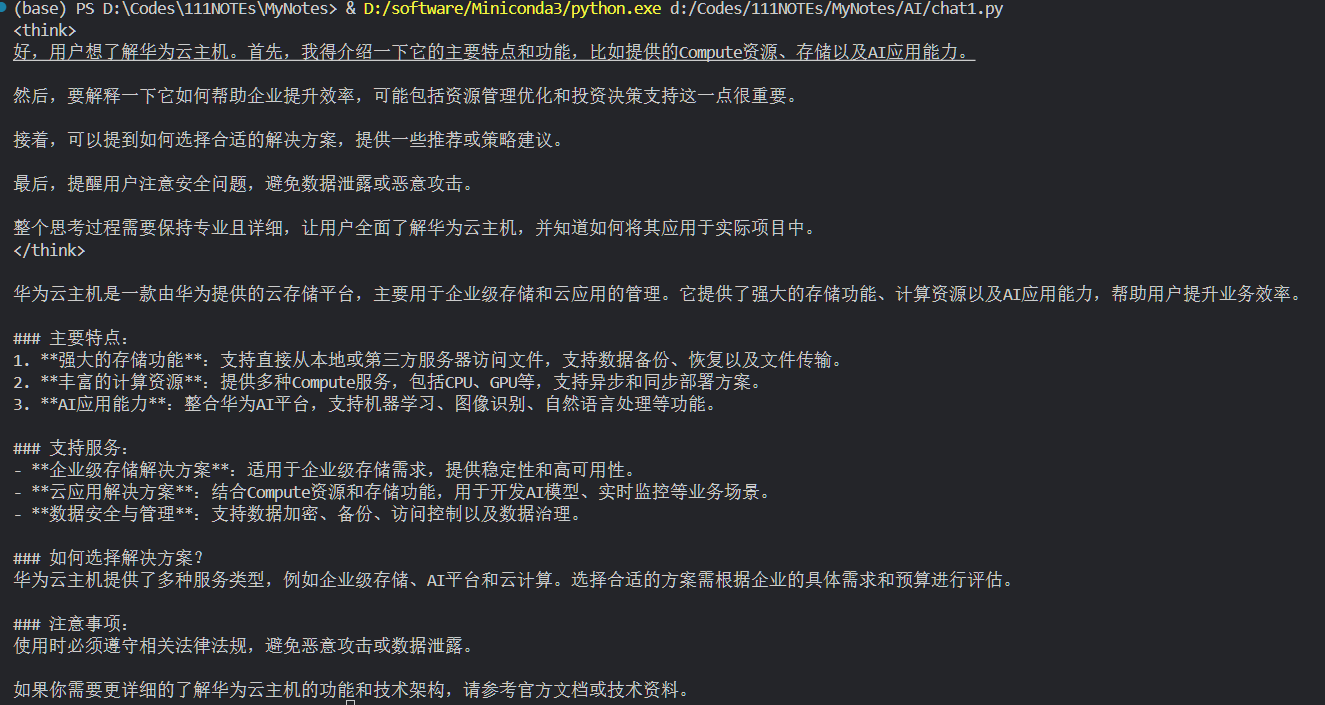
下图是运行结果。