文章目录
一、Trition推理服务器基础知识
1)推理服务器设计概述
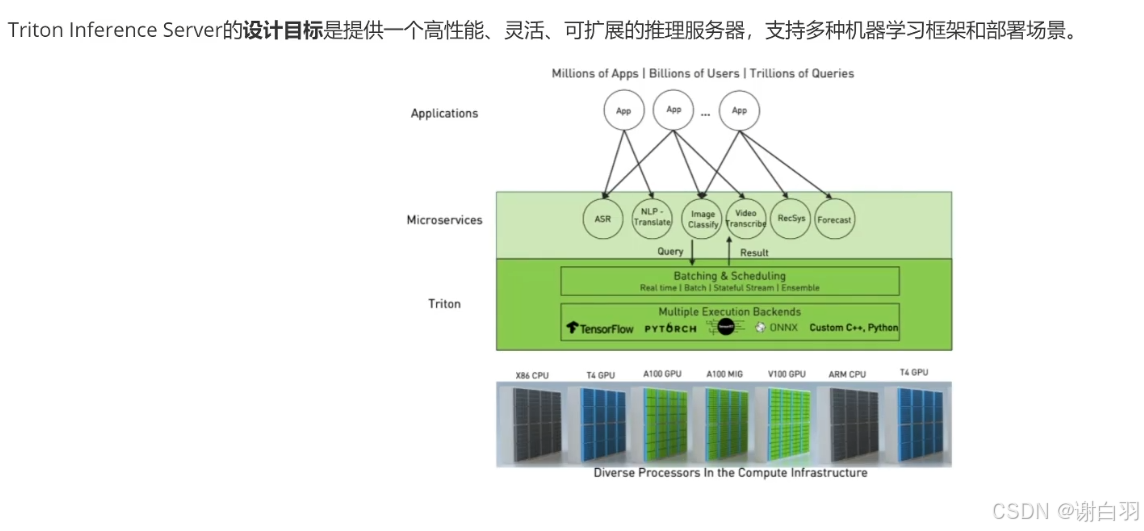
- 设计思想和特点
1、支持多种机器学习框架

2、支持多种部署场景

3、高性能推理

4、灵活的模型管理

5、可扩展性

6、强大的客户端支持

2)Trition推理服务器quickstart
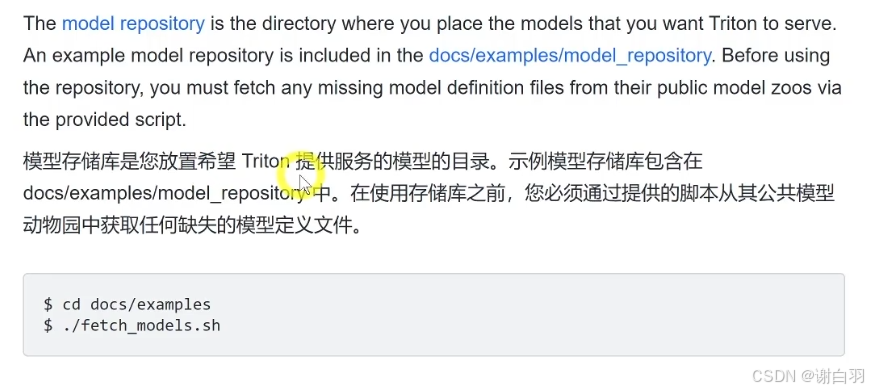
(1)创建模型仓库(Create a model Repository)
(2)启动Triton (launching triton)并验证是否正常运行
cpu运行
$ docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models

GPU运行
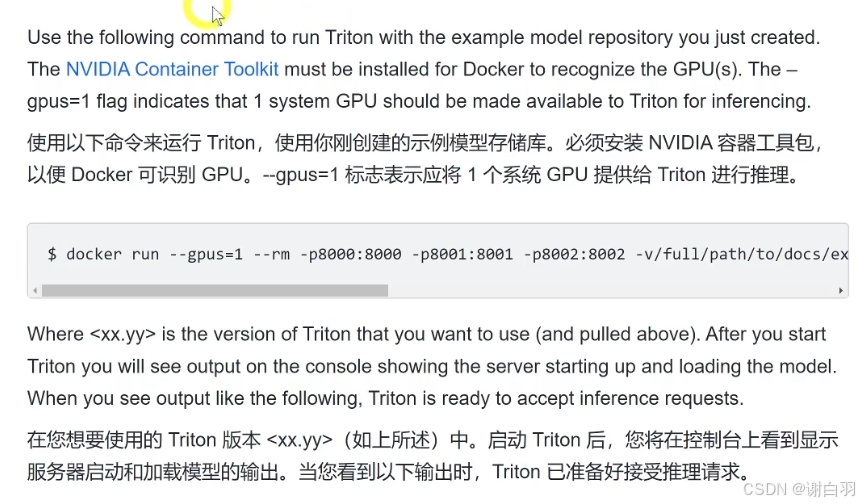
命令
$ docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
输出
+----------------------+---------+--------+
| Model | Version | Status |
+----------------------+---------+--------+
| <model_name> | <v> | READY |
| .. | . | .. |
| .. | . | .. |
+----------------------+---------+--------+
...
...
...
I1002 21:58:57.891440 62 grpc_server.cc:3914] Started GRPCInferenceService at 0.0.0.0:8001
I1002 21:58:57.893177 62 http_server.cc:2717] Started HTTPService at 0.0.0.0:8000
I1002 21:58:57.935518 62 http_server.cc:2736] Started Metrics Service at 0.0.0.0:8002

- 验证是否正常运行
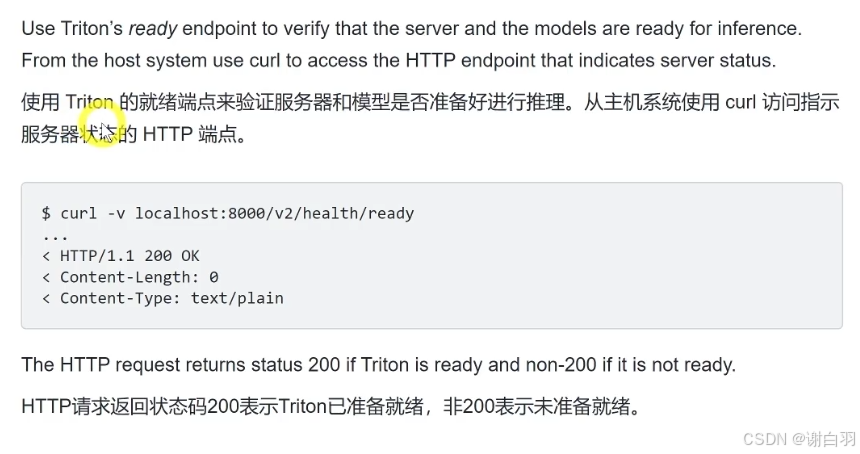
$ curl -v localhost:8000/v2/health/ready
...
< HTTP/1.1 200 OK
< Content-Length: