前言
本文详细介绍了在Linux环境下安装和配置MongoDB副本集的完整流程。主要内容包括:下载MongoDB安装包并上传至服务器;创建必要的数据和日志目录;解压安装包并配置mongod.conf文件;分发MongoDB到集群节点;配置环境变量;启动副本集服务;以及初始化副本集并添加节点。通过图文并茂的方式展示了每个操作步骤的执行过程和验证方法,最终实现了包含hadoop1(主节点)、hadoop2和hadoop3(副本节点)的三节点MongoDB副本集环境。
一、下载MongoDB
1. 下载MongoDB
MongoDB安装包下载地址:https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-5.0.30.tgz
2. 上传安装包
通过拖移的方式将下载的MongoDB安装包mongodb-linux-x86_64-rhel70-5.0.30.tgz上传至虚拟机hadoop1的/export/software目录。
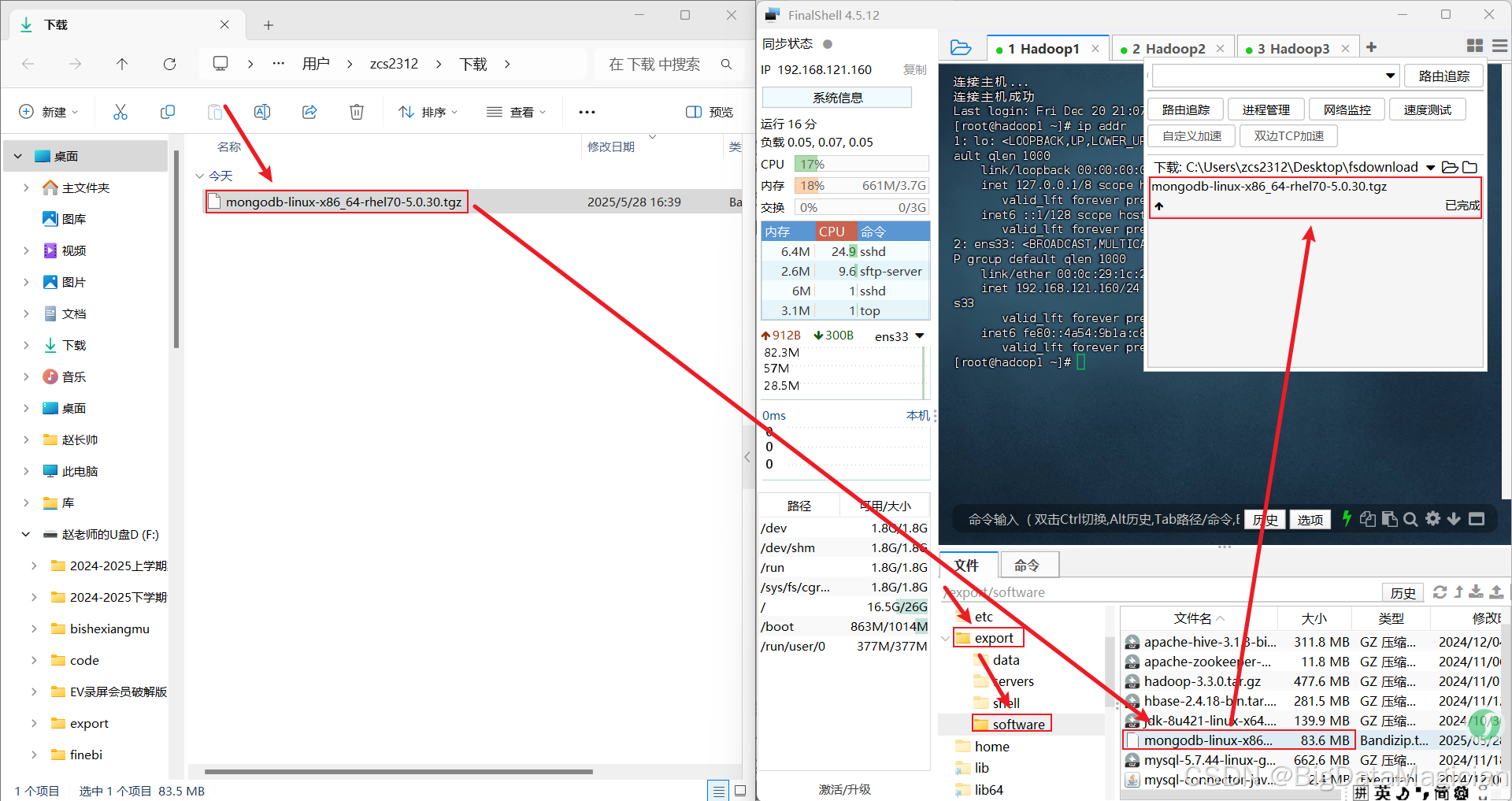
3. 创建相关目录
目录/export/data/mongodb/data用于存放副本数据,目录/export/data/mongodb/logs用于存放副本集日志,文件/export/data/mongodb/logs/mongodb.log用于保存日志,MongoDB的数据目录和日志目录不会自动创建,需要手动创建。分别在虚拟机hadoop1、hadoop2和hadoop3执行如下命令创建相关目录。
mkdir -p /export/data/mongodb/data
mkdir -p /export/data/mongodb/logs
touch /export/data/mongodb/logs/mongodb.log
二、安装配置MongoDB
1. 解压MongoDB安装包
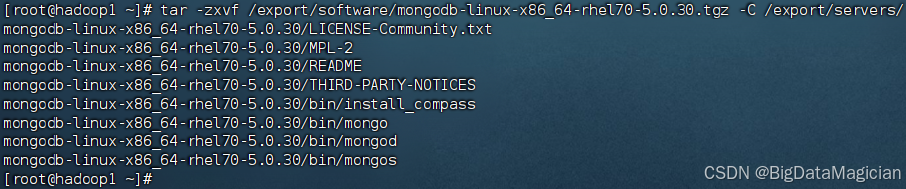
在虚拟机hadoop1上将MongoDB安装包解压至/export/servers目录。
tar -zxvf /export/software/mongodb-linux-x86_64-rhel70-5.0.30.tgz -C /export/servers/
解压完成如下图所示。
2. 重命名MongoDB文件夹名称
把MongoDB文件夹名称按标准命名方式(软件名-版本号)重命名。
mv /export/servers/mongodb-linux-x86_64-rhel70-5.0.30/ /export/servers/mongodb-5.0.30

3. 修改配置文件
参数映射说明
| 命令行参数 | 配置文件路径 | 说明 |
|---|---|---|
--port 27017 |
net.port |
MongoDB服务监听的端口 |
--bind_ip hadoop1 |
net.bindIp |
监听的网络接口(主机名或IP) |
--dbpath=/export/... |
storage.dbPath |
数据文件存储路径 |
--logpath=/export/... |
systemLog.path |
日志文件路径 |
--logappend |
systemLog.logAppend |
以追加模式写入日志(保留历史记录) |
--fork |
processManagement.fork |
以守护进程模式运行(后台运行) |
--replSet bigdata_mongodb |
replication.replSetName |
副本集名称 |
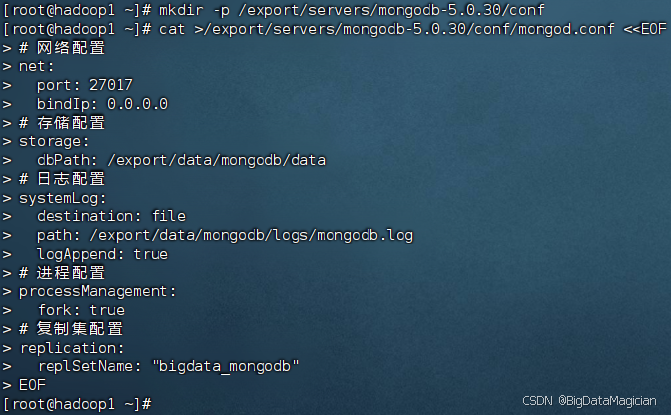
在虚拟机hadoop1执行如下命令创建配置文件目录,并向配置文件mongod.conf中添加配置内容。
mkdir -p /export/servers/mongodb-5.0.30/conf
cat >/export/servers/mongodb-5.0.30/conf/mongod.conf <<EOF
# 网络配置
net:
port: 27017
bindIp: 0.0.0.0
# 存储配置
storage:
dbPath: /export/data/mongodb/data
# 日志配置
systemLog:
destination: file
path: /export/data/mongodb/logs/mongodb.log
logAppend: true
# 进程配置
processManagement:
fork: true
# 复制集配置
replication:
replSetName: "bigdata_mongodb"
EOF
4. 分发MongoDB文件夹
把虚拟机hadoop1中的MongoDB文件夹复制到虚拟机hadoop2和hadoop3中。
scp -r /export/servers/mongodb-5.0.30/ root@hadoop2:/export/servers/
scp -r /export/servers/mongodb-5.0.30/ root@hadoop3:/export/servers/
5. 配置环境变量
分别在虚拟机hadoop1、hadoop2和hadoop3执行如下命令,向环境变量配置文件/etc/profile追加环境变量内容。配置环境变量后,需要加载环境变量配置文件/etc/profile,使用hadoop的环境变量生效。
echo >> /etc/profile
echo 'export MONGODB_HOME=/export/servers/mongodb-5.0.30' >> /etc/profile
echo 'export PATH=$PATH:$MONGODB_HOME/bin:$MONGODB_HOME/bin' >> /etc/profile
source /etc/profile
配置好环境变量后,分别在虚拟机hadoop1、hadoop2和hadoop3执行如下命令验证环境变量是否配置成功。
mongo --version
成功如下图所示。

6. 启动副本集
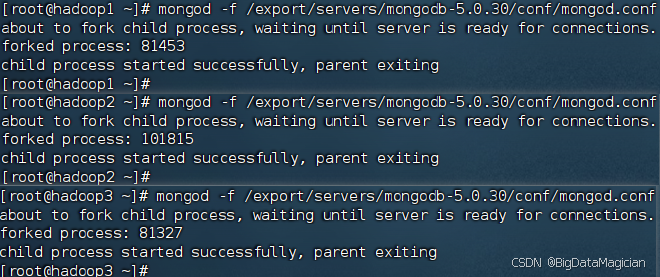
以副本集模式启动MongoDB,分别在虚拟机hadoop1、hadoop2和hadoop3执行如下命令启动MongoDB服务。
mongod -f /export/servers/mongodb-5.0.30/conf/mongod.conf
7. 进入MongoDB客户端
在虚拟机hadoop1执行如下命令进入hadoop1的MongoDB客户端。
mongo --host hadoop1 --port 27017
8. 初始化副本集
8.1 初始化副本集
在虚拟机hadoop1执行如下命令初始化副本集。
rs.initiate()
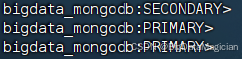
初始化成功如下图所示。

完成初始化后,节点默认处于SECONDARY(副本节点)状态,等待几秒后自动选举自己为PRLMARY(主节点),如下图所示。
8.2 添加副本节点
在虚拟机hadoop1执行如下命令将服务器hadoop2和hadoop3以副本节点的角色添加到副本集中。
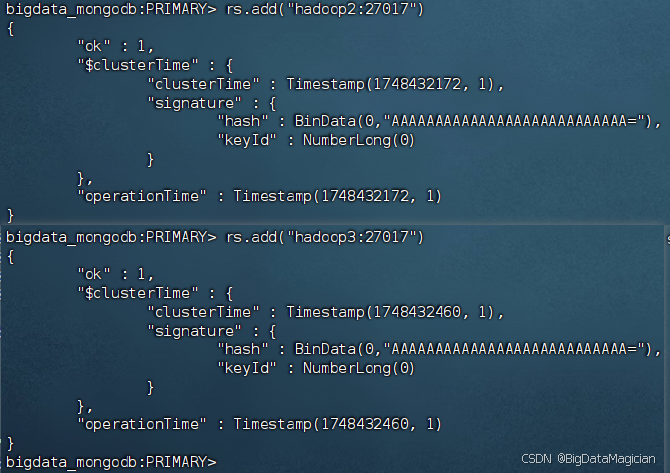
rs.add("hadoop2:27017")
rs.add("hadoop3:27017")
添加成功如下图所示。
在虚拟机hadoop2执行如下命令进入hadoop2的MongoDB客户端,查看副本集状态。
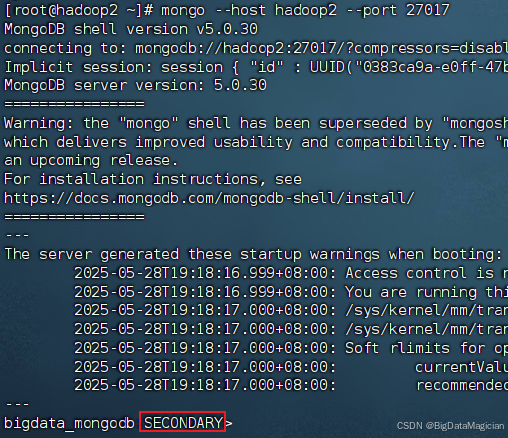
mongo --host hadoop2 --port 27017
如下图所示,服务器hadoop2是为SECONDARY状态。
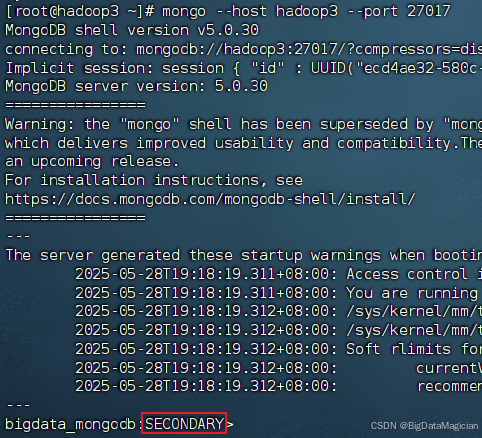
在虚拟机hadoop3执行如下命令进入hadoop3的MongoDB客户端,查看副本集状态。
mongo --host hadoop3 --port 27017
如下图所示,服务器hadoop3是为SECONDARY状态。
三、副本集操作
1. 副本集状态介绍
以下是 MongoDB 副本集(Replica Set)状态的详细介绍。
| 分类 | 状态/概念 | 说明 |
|---|---|---|
| 基本架构 | 副本集(Replica Set) | 由多个 MongoDB 节点组成的集群,实现数据冗余、高可用和故障转移。 |
| 主节点(Primary) | 唯一可写入的节点,处理所有写操作,并将变更同步到从节点(Secondary)。 | |
| 从节点(Secondary) | 复制主节点数据,可用于读操作(默认禁止,需配置 readPreference)。 |
|
| 仲裁节点(Arbiter) | 不存储数据,仅参与选举投票,用于解决脑裂问题(奇数节点时非必需)。 | |
| 节点状态 | PRIMARY |
主节点状态,当前集群唯一写入节点。 |
SECONDARY |
从节点状态,同步主节点数据,支持只读(需配置)。 | |
RECOVERING |
节点正在同步数据(如初次加入副本集或数据同步中),不可读/写。 | |
STARTUP |
节点刚启动,正在初始化,尚未完成同步。 | |
STARTUP2 |
节点已完成初始化,正在尝试加入副本集。 | |
DOWN |
节点不可用(如进程停止或网络故障)。 | |
ARBITER |
仲裁节点状态,仅参与选举,不存储数据。 | |
REMOVED |
节点已从副本集中移除(但可能仍存在于配置中)。 | |
| 选举机制 | 主节点选举(Election) | 当主节点故障时,从节点通过心跳检测和投票机制重新选举新主节点。 |
| 心跳(Heartbeat) | 节点间通过定期心跳(默认2秒)检测存活状态。 | |
| 多数派原则(Majority) | 选举需获得副本集多数节点(含主节点)的投票才能生效。 | |
| 数据同步 | oplog(操作日志) | 主节点记录所有写操作的日志,从节点通过回放 oplog 实现数据同步。 |
| 同步延迟(Replication Lag) | 从节点与主节点的数据延迟时间(正常情况下应接近0)。 | |
| 读写策略 | 读偏好(Read Preference) | 控制读请求路由到主节点或从节点,支持 primary、primaryPreferred、secondary、secondaryPreferred、nearest 等模式。 |
| 管理命令 | rs.status() |
查看副本集状态的核心命令,返回各节点状态、同步信息及选举相关参数。 |
rs.initiate() |
初始化副本集配置。 | |
rs.add() |
向副本集添加节点。 | |
rs.remove() |
从副本集移除节点。 | |
| 典型场景 | 故障转移(Failover) | 主节点故障后,从节点自动选举新主节点,业务自动切换(需驱动支持)。 |
| 负载均衡(Read Scaling) | 将读请求分发到从节点,减轻主节点压力(需配置读偏好)。 | |
| 注意事项 | 节点数量建议 | 推荐奇数个节点(如3/5/7个),避免脑裂(偶数节点需搭配仲裁节点)。 |
| 版本兼容性 | 副本集内节点版本必须一致,否则可能导致同步失败或功能异常。 |
2. 查看副本集成员状态
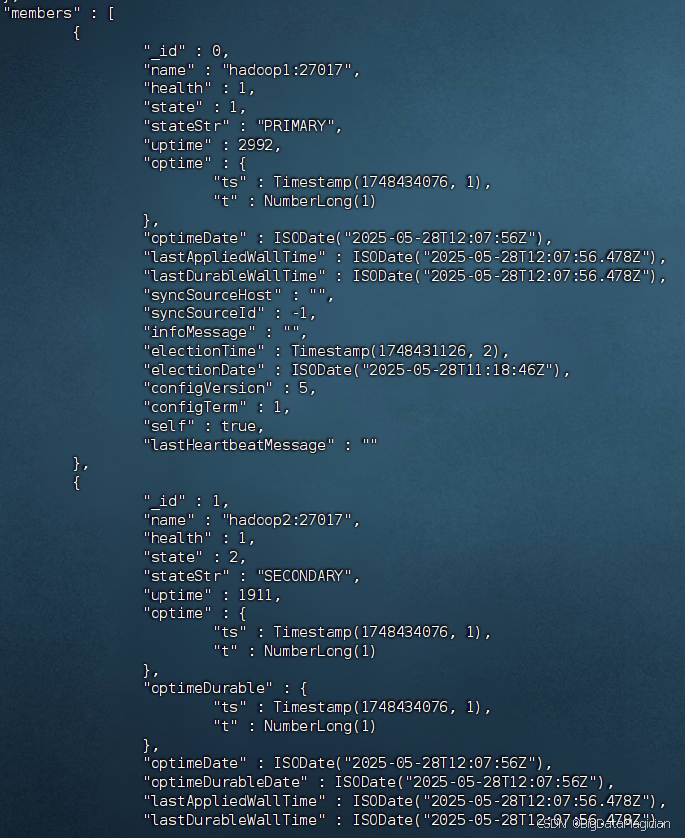
在虚拟机hadoop1执行如下命令查看副本集成员状态。
rs.status()
返回的部分结果如下图所示。
状态码对应关系
| 状态码 | 状态字符串 | 说明 |
|---|---|---|
1 |
PRIMARY |
主节点 |
2 |
SECONDARY |
从节点 |
3 |
RECOVERING |
数据同步中(不可用) |
5 |
STARTUP |
节点启动中 |
6 |
ARBITER |
仲裁节点 |
8 |
DOWN |
节点不可用 |
9 |
UNKNOWN |
节点状态未知(如网络隔离) |
3. 数据同步
3.1 启用数据同步
分别在虚拟机hadoop2和hadoop3的MongoDB客服端执行如下命令开启数据同步。
rs.secondaryOk()
3.2 测试数据同步
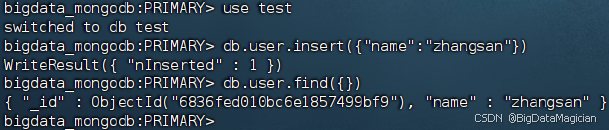
在虚拟机hadoop1的MongoDB客服端执行如下命令,切换到test数据库,并向集合user插入一个文档。
use test
db.user.insert({"name":"zhangsan"})
db.user.find({})
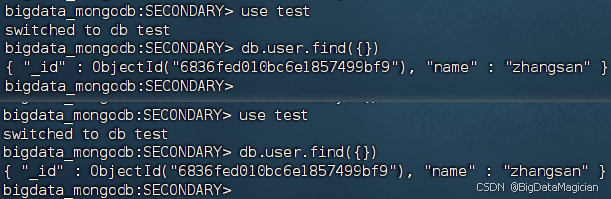
在虚拟机hadoop2和hadoop3的MongoDB客服端执行如下命令,测试数据是否已经同步,可用查询到数据说明数据已经同步到hadoop2和hadoop3。
use test
db.user.find({})
如下图所示。
4. 故障转移
测试方法:终止hadoop1的MongoDB的主节点进程,查看hadoop2和hadoop3这两个从节点是否会有一个自动转为主节点。
4.1 终止hadoop1的MongoDB的主节点进程
查看hadoop1的MongoDB服务进程的PID。
ps -ef | grep mongodb
MongoDB服务进程的PID如下图红框部分所示。

关闭hadoop1的MongoDB服务进程。
kill -9 <PID>
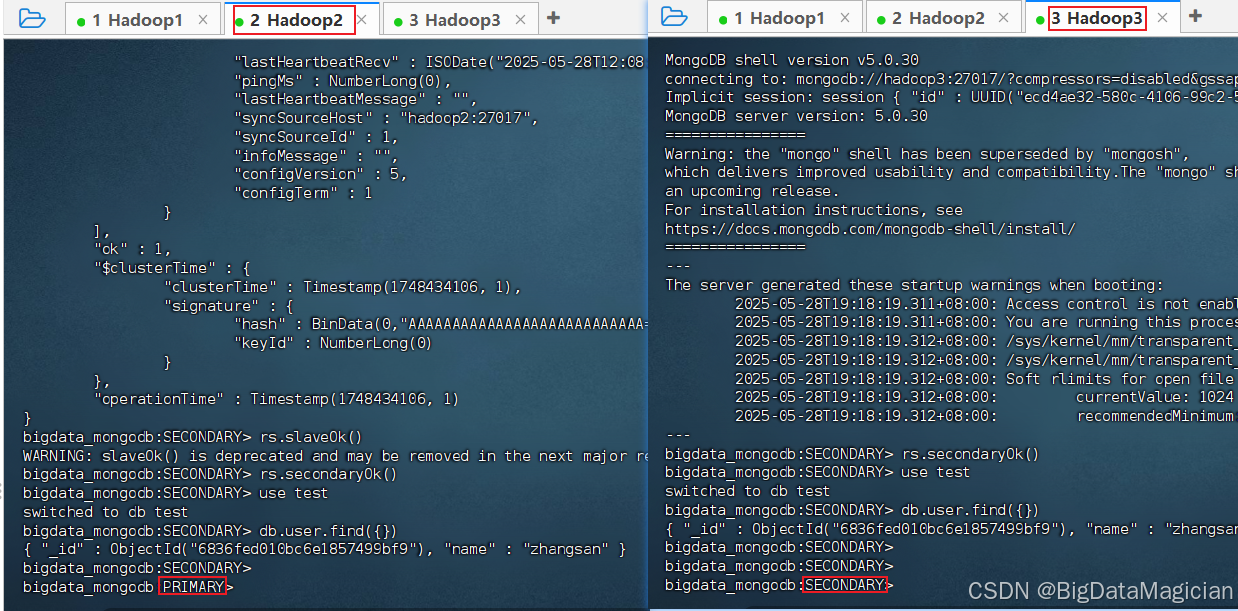
4.2 查看从节点是否有一个自动转为主节点
如下图所示,在hadoop2和hadoop3这两个从节点中,hadoop2转为了主节点。
5. 配置副本集成员
5.1 调整副本集成员的优先级
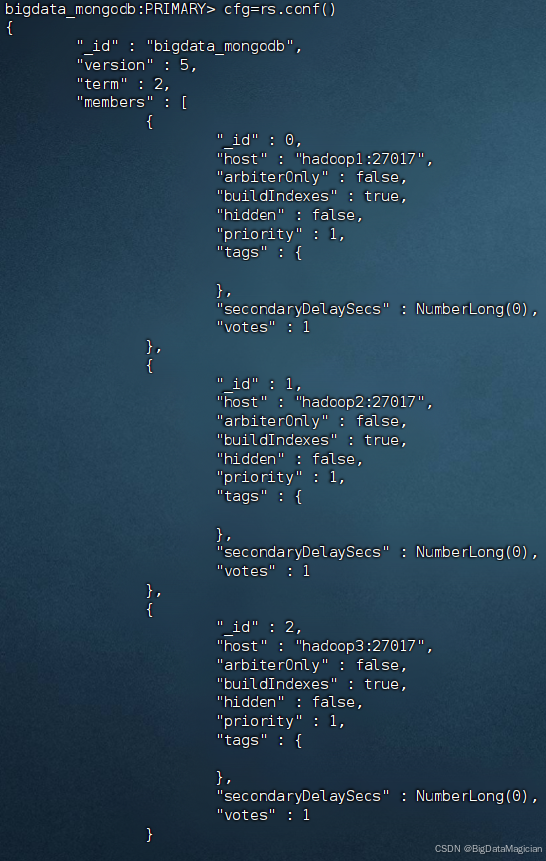
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
优先级越高越容易被选举为主节点,优先级的范围是0-100(值越大优先级越高),所有节点的优先级默认为1,优先级为0不能成为主节点。
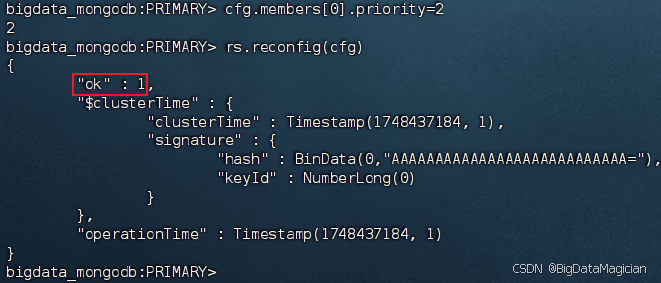
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop1的优先级改为2,并将修改后的配置应用到副本集。
cfg.members[0].priority=2
rs.reconfig(cfg)
配置成功如下图所示。
重新启动hadoop1的MongoDB服务
在虚拟机hadoop1执行如下命令启动MongoDB服务。
mongod -f /export/servers/mongodb-5.0.30/conf/mongod.conf
启动完成后等待10秒,可以发现hadoop1被重新选举成为主节点(因为hadoop1的优先级比较高),如下图所示。
5.2 配置隐藏节点
隐藏节点是副本集中持有数据副本、对客户端不可见、但可以参与主节点选举和数据同步的特殊节点,可用于数据备份或离线分析等场景。
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2的优先级改为0,使其不能被选举为主节点。
cfg.members[1].priority=0

在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2设置为隐藏节点。
cfg.members[1].hidden=true

在虚拟机主节点的MongoDB客服端执行如下命令将修改后的配置应用到副本集。
rs.reconfig(cfg)
5.3 配置延迟节点
延迟节点(Delayed Node)是副本集中数据落后于主节点指定时间(如1小时)的从节点,用于数据误操作恢复、版本验证等场景。
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2的优先级改为0,使其不能被选举为主节点。
cfg.members[1].priority=0
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2设置为延迟节点,设置延迟时间为3600秒。
cfg.members[1].secondaryDelaySecs=3600

在虚拟机主节点的MongoDB客服端执行如下命令将修改后的配置应用到副本集。
rs.reconfig(cfg)
5.4 配置副本集成员投票权
副本集成员的投票权是指成员在主节点选举中是否具备投票资格,允许有七个拥有投票权的成员,由votes参数控制(默认值为1表示有投票权,0表示无投票权),通常用于控制选举过程或排除特殊节点(如延迟节点、隐藏节点)参与投票。
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2的投票权设置为0,使其不能参与投票。
cfg.members[1].votes=0

在虚拟机主节点的MongoDB客服端执行如下命令将修改后的配置应用到副本集。
rs.reconfig(cfg)
5.5 将副本节点转为仲裁节点
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
在虚拟机主节点的MongoDB客服端执行如下命令把服务器hadoop2从副本集中移除。
rs.remove("hadoop2:27017")
在虚拟机hadoop2上按Ctrl+C关闭MongoDB客服端,并执行如下操作关闭MongoDB服务进程。
查看hadoop2的MongoDB服务进程的PID。
ps -ef | grep mongodb
MongoDB服务进程的PID如下图红框部分所示。

关闭hadoop2的MongoDB服务进程。
kill -9 <PID>
在虚拟机hadoop2上执行如下命令备份MongoDB数据存放目录。
mv /export/data/mongodb/data /export/data/mongodb/data-old
在虚拟机hadoop2上执行如下命令创建新的数据存放目录,并重新启动MongoDB服务。
mkdir -p /export/data/mongodb/data
mongod -f /export/servers/mongodb-5.0.30/conf/mongod.conf

在虚拟机主节点的MongoDB客服端执行如下命令以仲裁节点角色将hadoop2添加到副本集中。
rs.addArb("hadoop2:27017")