此章节书上内容既包括文件操作,又包括hash存储的实现,较复杂。
先讲解一下涉及的文件操作:
文件操作:
一.creat系统调用
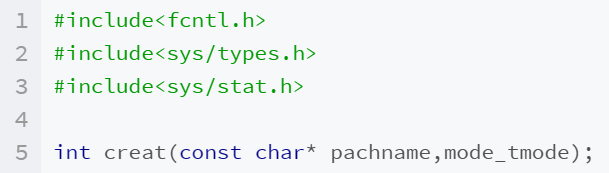
图一 create函数原型(图中pachname应为pathname)
- 当调用creat函数时,它会尝试创建一个名为pathname的文件。如果文件已经存在,那么除非提供了特殊的标志,否则creat函数会截断这个文件(即清空文件内容)。mode参数指定了新创建文件的权限位(文件模式),这与open函数的权限位相同。
- 如果creat函数成功创建文件,它会返回一个文件描述符,这个文件描述符是唯一的非负整数,用于在后续的文件操作中引用这个新创建的文件。如果创建文件失败,creat函数会返回-1,并且会设置全局变量errno来表示错误的原因。
- creat函数的缺点是它以只写的方式打开新创建的文件。这意味着如果使用creat函数创建文件后,你不能从这个文件描述符中读取数据。在open函数的新版本出现之前,如果你想创建一个临时文件并且需要先写入数据,你必须先调用creat函数来创建文件,然后调用close函数关闭文件描述符,最后再调用open函数以所需的方式(读、写或读写)重新打开文件。
二.open系统调用

图二 open函数原型
1.在Linux系统中,open是一个重要的系统调用,用于打开或创建一个文件,并返回一个文件描述符,该文件描述符可以用于后续的读写等操作。open函数非常灵活,可以通过不同的标志来控制文件的行为。
2.参数说明
pathname |
指向要打开或创建的文件的路径名。 |
|
flags |
O_RDONLY |
以只读方式打开文件。 |
O_WRONLY |
以只写方式打开文件。 |
|
O_RDWR |
以读写方式打开文件。 |
|
O_CREAT |
如果文件不存在,则创建它。 |
|
O_EXCL |
与O_CREAT一起使用,如果文件已存在则报错。 |
|
O_TRUNC |
如果文件已存在,则将其截断为0长度。 |
|
O_APPEND |
在每次写操作时,将数据追加到文件的末尾。 |
|
O_NONBLOCK |
以非阻塞方式打开文件。 |
|
mode |
当创建新文件时,指定文件的权限位。这个参数仅在设置了O_CREAT标志时才需要,用于设置新文件的权限。通常与S_IRUSR(用户读权限)、S_IWUSR(用户写权限)等宏结合使用。 |
|
表一 open函数的参数说明
3.open函数的返回值是一个文件描述符,这是一个非负整数,用于在后续的文件操作中引用打开的文件。如果打开文件失败,open函数返回-1,并设置全局变量errno来表示错误的原因。
4.灵活性:open函数可以通过组合不同的标志来满足不同的文件操作需求,如读写模式、创建文件、截断文件、追加写入等。
5.多功能性:open函数不仅可以打开已存在的文件,还可以创建新文件,并设置文件的权限。
6.高效性:open函数是系统调用,通常比标准库函数(如fopen)更加高效,因为它直接与操作系统交互。
7.文件描述符:open函数返回文件描述符,这是一个在操作系统层面上的资源标识符,可以用于后续的所有文件操作,如read、write、lseek等。
8.适用于底层操作:由于open函数提供的是底层接口,它非常适合用于需要精细控制文件操作的场合,如需要特定文件标志或文件权限的场景。
9.复杂性和易错性:由于open函数提供了许多标志和参数,这可能导致在使用时容易出错,尤其是在不熟悉这些标志的情况下。
10.错误处理:open函数在出错时返回-1,并设置全局变量errno来表示错误原因。这要求程序员必须检查返回值,并正确处理可能出现的错误。
11.跨平台问题:虽然open函数在大多数Unix-like系统中是通用的,但在Windows等其他操作系统上,可能需要使用不同的函数来打开文件。
12.权限和安全性:在使用open函数时,需要特别注意文件权限的设置,以避免安全漏洞,例如不当地设置文件权限可能导致未授权访问。
三.close系统调用

图三 close函数原型
- 在Linux和类Unix操作系统中,close系统调用用于关闭一个打开的文件描述符。当一个进程不再需要访问一个文件时,应该使用close来释放与该文件描述符相关的资源,并确保所有的数据都已经正确写入到磁盘。
- fd:需要关闭的文件描述符,这是一个非负整数,由之前的open、creat、dup、dup2、fcntl或其他文件操作函数返回。
- close函数的返回值是一个整数,如果关闭文件描述符成功,返回0;如果失败,返回-1,并设置全局变量errno来表示错误的原因。
- 在一个进程终止时,系统会自动关闭所有打开的文件描述符,但是依赖这一行为并不是一个好的编程实践。因为文件描述符是有限的资源,及时关闭不再使用的文件描述符可以避免资源泄漏,并且可以确保数据的完整性。
四.read系统调用

图四 read函数原型
- Read 系统调用在用户空间中的处理过程:Linux 系统调用(SCI,system call interface)的实现机制实际上是一个多路汇聚以及分解的过程,该汇聚点就是 0x80 中断这个入口点(X86 系统结构)。也就是说,所有系统调用都从用户空间中汇聚到 0x80 中断点,同时保存具体的系统调用号。当 0x80 中断处理程序运行时,将根据系统调用号对不同的系统调用分别处理(调用不同的内核函数处理)。Read 系统调用也不例外,当调用发生时,库函数在保存 read 系统调用号以及参数后,陷入 0x80 中断。这时库函数工作结束。Read 系统调用在用户空间中的处理也就完成了。
- Read 系统调用在核心空间中的处理过程:0x80 中断处理程序接管执行后,先检察其系统调用号,然后根据系统调用号查找系统调用表,并从系统调用表中得到处理 read 系统调用的内核函数 sys_read ,最后传递参数并运行 sys_read 函数。至此,内核真正开始处理 read 系统调用(sys_read 是 read 系统调用的内核入口)。在讲解 read 系统调用在核心空间中的处理部分中,首先介绍了内核处理磁盘请求的层次模型,然后再按该层次模型从上到下的顺序依次介绍磁盘读请求在各层的处理过程。
- Read 系统调用在核心空间中处理的层次模型:图五显示了 read 系统调用在核心空间中所要经历的层次模型。从图中看出:对于磁盘的一次读请求,首先经过虚拟文件系统层(vfs layer),其次是具体的文件系统层(例如 ext2),接下来是 cache 层(page cache 层)、通用块层(generic block layer)、IO 调度层(I/O scheduler layer)、块设备驱动层(block device driver layer),最后是物理块设备层(block device layer)。
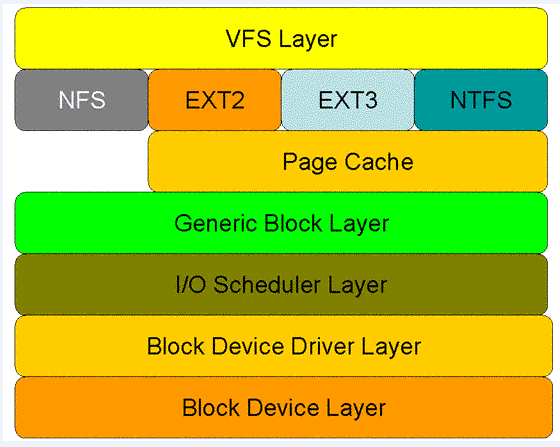
图五 read 系统调用在核心空间中的处理层次
五.write系统调用

图六 write系统调用
- 其中参数count表示最多写入的字节数,返回值表是真正写入的字节数。有些情况下返回值有可能会比指定的字节数要少,例如存储设备上没有空间了,或者写入的文件大小超过RLIMIT_FSIZE的限制了,或者写入过程被信号中断了等等。如果写入的是一个常规文件,写入会发生在当前偏移指针指向的位置,并会在写入完成后把偏移指针后移实际写入的字节数。内核中实现的写入和调整偏移指针的操作是原子的,应用程序不需要担心写入被打断时指针偏移与写入内容不匹配的问题。
- 如果遇到错误,write()会返回-1,与read()系统调用一样,并不是所有的情况下返回-1就表示文件坏了,写不了了,还需要继续检查errno来确定出错的原因。例如,如果当操作一个非阻塞模式的socket时,errno等于EAGAIN和EWOULDBLOCK通常意味着当前的socket还发不了数据,但是如果等一会再来尝试发一次,有可能又可以发了。所以对这两种错误,应用总是应该稍后再次尝试。还有EINTR错误,表示在成功写入任何数据之前就刚好被某个信号打断了,这时候也应该在信号处理完成后再次尝试写入。
EBADF |
指定的文件描述符无效,或不能写入 |
EINVAL |
指定的文件描述符不能写入。另外如果打开的文件指定了O_DIRECT标志,那么写入操作会直接刷新到存储设备,而不会为这个文件创建内核中的写入缓冲区,这时候,传入的写入数据地址和字节数都需要按照磁盘页的大小对齐,如果传入的参数是没有对齐的,也会返回这种错误。 |
EFAULT |
指定的buf无法访问 |
EIO |
当修改文件的iNode时遇到一个底层IO错误。 |
EFBIG |
文件内容在写入count个字节之后就会太大了,或者写入的位置超过了允许的偏移范围,返回这种错误的时候,不会有任何的数据真正写入到文件里面。 |
ENOSPC |
文件所在的设备没有足够的空间 |
表二 write调用的常见错误
- 简单性:write函数的接口简单,易于理解和使用。它接受文件描述符、数据缓冲区和要写入的字节数作为参数,直观且易于操作。
- 高效性:作为系统调用,write通常比标准库函数(如fprintf或fputs)更高效,因为它直接与操作系统交互,减少了上下文切换和内存拷贝的次数。
- 灵活性:write可以用于写入任何类型的文件,包括普通文件、管道、套接字和设备文件。这使得它在多种不同的编程场景中都非常有用。
- 同步写入:默认情况下,write是同步的,这意味着在write返回之前,数据已经被写入磁盘。这有助于确保数据的持久性和一致性。
- 错误处理:write在遇到错误时返回-1,并设置全局变量errno来表示错误原因。这要求程序员必须检查返回值,并正确处理可能出现的错误,如磁盘满、权限问题或其他系统错误。
- 写入大小的限制:write函数可能无法一次性写入超过一定大小的数据块。在写入大量数据时,可能需要多次调用write,并检查每次写入的字节数,以确保所有数据都被正确写入。
- 缓冲区问题:在某些情况下,写入的数据可能被缓冲在内核空间中,而不是立即写入磁盘。如果系统崩溃,这些缓冲的数据可能会丢失。为了确保数据的持久性,可能需要使用fsync或fdatasync系统调用来强制将缓冲区中的数据写入磁盘。
- 安全性:在使用write时,需要确保文件描述符是正确的,并且有适当的权限进行写入。不正确的使用可能导致数据被写入错误的文件,从而引起安全漏洞或数据损坏。
六.lseek系统调用
包含头文件
#include <sys/types.h>
#include <unistd.h>函数原型
off_t lseek(int fd, off_t offset, int whence);函数功能
reposition read/write file offset.
函数参数
fd:文件描述符
offset:偏移量
whence:位置
- SEEK_SET:The offset is set to offset bytes. offset为0时表示文件开始位置。
- SEEK_CUR:The offset is set to its current location plus offset bytes. offset为0时表示当前位置。
- SEEK_END:The offset is set to the size of the file plus offset bytes. offset为0时表示结尾位置
函数返回值
- 成功返回当前位置到开始的长度
- 失败返回-1并设置errno
TIPS:lseek(fd,0,SEEK_END)返回文件总字节数,可用于比较访问是否到达文件尾。
hash存储代码理解
下面给出本人理解代码时,增加的注释,便于理解。
Tips:建议跟着main函数的执行过程理解具体执行。
hash文件
hashfile.h
#ifndef HASHFILE_H
#define HASHFILE_H
#include<unistd.h>
#include<sys/stat.h>
#define COLLISIONFACTOR 0.5
struct HashFileHeader
{
int sig; //Hash文件印鉴
int reclen; //每条记录长度
int total_rec_num; //总记录数
int current_rec_num; //当前记录数
};
struct CFTag
{
char collision; //冲突计数
char free; //空闲标志
};
//创建一个哈希文件,返回文件描述符,若创建失败则返回-1
int hashfile_creat(const char *filename,mode_t mode,int reclen,int total_rec_num);
//int hashfile_open(const char *filename,int flags);
//打开一个哈希文件,返回文件描述符,若打开失败则返回-1
int hashfile_open(const char *filename,int flags,mode_t mode);
//关闭一个哈希文件,返回0,若关闭失败则返回-1
int hashfile_close(int fd);
//按key读取哈希文件中的一条记录,若失败则返回-1
int hashfile_read(int fd,int keyoffset,int keylen,void *buf);
//向哈希文件中写入一条记录(只是调用hashfile_saverec函数),若失败则返回-1
int hashfile_write(int fd,int keyoffset,int keylen,void *buf);
//删除哈希文件中buf对应的记录,若删除成功则返回0,若失败则返回-1
int hashfile_delrec(int fd,int keyoffset,int keylen,void *buf);
//查找哈希文件中buf对应的记录,若找到则返回记录的偏移量,若未找到则返回-1
int hashfile_findrec(int fd,int keyoffset,int keylen,void *buf);
//将一条记录保存到哈希文件中,返回写入的字节数,若失败则返回-1
int hashfile_saverec(int fd,int keyoffset,int keylen,void *buf);
//计算哈希值,返回哈希地址
int hash(int keyoffset,int keylen,void *buf,int total_rec_num);
//检查哈希文件是否已满,返回0表示未满,返回1表示已满
int checkHashFileFull(int fd);
//读取哈希文件头信息,返回读取的字节数,若失败则返回-1;hfh为指向HashFileHeader结构体的指针
int readHashFileHeader(int fd,struct HashFileHeader *hfh);
#endif
hashfile.c
//hashfile.c
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<stdio.h>
#include<stdlib.h>
#include<memory.h>
#include"hashfile.h"
int hashfile_creat(const char *filename,mode_t mode,int reclen,int total_rec_num)
{
struct HashFileHeader hfh;
int fd;
int rtn;
char *buf;
int i=0;
hfh.sig = 31415926;
hfh.reclen = reclen;
hfh.total_rec_num = total_rec_num;
hfh.current_rec_num = 0;
//fd = open(filename,mode);
fd = creat(filename,mode);
if(fd != -1)
{
//写入文件头信息
lseek(fd,0,SEEK_SET);
rtn = write(fd,&hfh,sizeof(struct HashFileHeader));
//lseek(fd,sizeof(struct HashFileHeader),SEEK_SET);
if(rtn != -1)
{
//写入空闲标志
buf = (char*)malloc((reclen+sizeof(struct CFTag))*total_rec_num);
memset(buf,0,(reclen+sizeof(struct CFTag))*total_rec_num);
rtn = write(fd,buf,(reclen+sizeof(struct CFTag))*total_rec_num);
free(buf);
}
close(fd);
return fd;
}
else{
close(fd);
return -1;
}
}
int hashfile_open(const char *filename,int flags,mode_t mode)
{
int fd = open(filename,flags,mode);
struct HashFileHeader hfh;
if(read(fd,&hfh,sizeof(struct HashFileHeader))!= -1)
{
lseek(fd,0,SEEK_SET);//将文件指针移到开头
if(hfh.sig == 31415926)
return fd;
else
return -1;
}
else return -1;
}
int hashfile_close(int fd)
{
return close(fd);
}
int hashfile_read(int fd,int keyoffset,int keylen,void *buf)
{
struct HashFileHeader hfh;
readHashFileHeader(fd,&hfh);
int offset = hashfile_findrec(fd,keyoffset,keylen,buf);
if(offset != -1)
{
//定位到记录的起始位置
lseek(fd,offset+sizeof(struct CFTag),SEEK_SET);
return read(fd,buf,hfh.reclen);
}
else
{
return -1;
}
}
int hashfile_write(int fd,int keyoffset,int keylen,void *buf)
{
return hashfile_saverec(fd,keyoffset,keylen,buf);
//return -1;
}
int hashfile_delrec(int fd,int keyoffset,int keylen,void *buf)
{
//定位到记录的起始位置
int offset;
offset = hashfile_findrec(fd,keyoffset,keylen,buf);
if(offset != -1)
{
//将存储实际位置的tag空闲标志置为0
struct CFTag tag;
read(fd,&tag,sizeof(struct CFTag));
tag.free =0; //置空闲标志
lseek(fd,offset,SEEK_SET);
write(fd,&tag,sizeof(struct CFTag));
//将hash索引位置的冲突计数减1
struct HashFileHeader hfh;
readHashFileHeader(fd,&hfh);
int addr = hash(keyoffset,keylen,buf,hfh.total_rec_num);
offset = sizeof(struct HashFileHeader)+addr*(hfh.reclen+sizeof(struct CFTag));
if(lseek(fd,offset,SEEK_SET)==-1)
return -1;
read(fd,&tag,sizeof(struct CFTag));
tag.collision--; //冲突计数减1
lseek(fd,offset,SEEK_SET);
write(fd,&tag,sizeof(struct CFTag));
//更新文件头中的当前记录数
hfh.current_rec_num--; //当前记录数减1
lseek(fd,0,SEEK_SET);
write(fd,&hfh,sizeof(struct HashFileHeader));
return 0; //删除成功
}
else{
return -1;
}
}
int hashfile_findrec(int fd,int keyoffset,int keylen,void *buf)
{
//读取文件头信息
struct HashFileHeader hfh;
readHashFileHeader(fd,&hfh);
//计算哈希地址
int addr = hash(keyoffset,keylen,buf,hfh.total_rec_num);
int offset = sizeof(struct HashFileHeader)+addr*(hfh.reclen+sizeof(struct CFTag));
//定位到哈希地址处
if(lseek(fd,offset,SEEK_SET)==-1)
return -1;
struct CFTag tag;
read(fd,&tag,sizeof(struct CFTag));
//如果冲突计数为0,说明不存在该记录
char count = tag.collision;
if(count==0)
return -1; //不存在
recfree:
if(tag.free == 0)
{
offset += hfh.reclen+sizeof(struct CFTag);
if(lseek(fd,offset,SEEK_SET)==-1)
return -1;
read(fd,&tag,sizeof(struct CFTag));
goto recfree;
}
else{
char *p =(char*)malloc(hfh.reclen*sizeof(char));
read(fd,p,hfh.reclen);
//printf("Record is {%d , %s}\n",((struct jtRecord *)p)->key,((struct jtRecord *p)->other);
char *p1,*p2;
p1 = (char *)buf+keyoffset;
p2 = p + keyoffset;
int j=0;
while((*p1 == *p2)&&(j<keylen))
{
p1++;
p2++;
j++;
}
//如果j等于keylen,说明找到了匹配的记录
if(j==keylen)
{
free(p);
p = NULL;
return(offset);
}
else{ //如果 key 不匹配,判断该记录是否属于同一个哈希槽(防止跨槽误判),
//如果是,则计数--,然后继续查找下一个槽位,直到冲突计数用完或找到为止。
if(addr == hash(keyoffset,keylen,p,hfh.total_rec_num))
{
count--;
if(count == 0)
{
free(p);
p = NULL;
return -1;//不存在
}
}
free(p);
p = NULL;
offset += hfh.reclen+sizeof(struct CFTag);
if(lseek(fd,offset,SEEK_SET) == -1)
return -1;
read(fd,&tag,sizeof(struct CFTag));
goto recfree;
}
}
}
int hashfile_saverec(int fd,int keyoffset,int keylen,void *buf)
{
//检查哈希文件是否已满
if(checkHashFileFull(fd)){
return -1;
}
//读取文件头信息
struct HashFileHeader hfh;
readHashFileHeader(fd,&hfh);
//计算哈希地址
int addr = hash(keyoffset,keylen,buf,hfh.total_rec_num);
int offset = sizeof(struct HashFileHeader)+addr*(hfh.reclen+sizeof(struct CFTag));
//定位到哈希地址处
if(lseek(fd,offset,SEEK_SET)==-1)
return -1;
struct CFTag tag;
read(fd,&tag,sizeof(struct CFTag));
//增加冲突计数
tag.collision++;
lseek(fd,sizeof(struct CFTag)*(-1),SEEK_CUR);
write(fd,&tag,sizeof(struct CFTag));
while(tag.free!=0) //冲突,顺序探查
{
offset += hfh.reclen+sizeof(struct CFTag);
if(offset >= lseek(fd,0,SEEK_END))//
offset = sizeof(struct HashFileHeader); //reach at and,then rewind
if(lseek(fd,offset,SEEK_SET)==-1)
return -1;
read(fd,&tag,sizeof(struct CFTag));
}
//写入新记录
tag.free =-1;
lseek(fd,sizeof(struct CFTag)*(-1),SEEK_CUR);
write(fd,&tag,sizeof(struct CFTag));
write(fd,buf,hfh.reclen);
//更新文件头中的当前记录数
hfh.current_rec_num++;
lseek(fd,0,SEEK_SET);
return write(fd,&hfh,sizeof(struct HashFileHeader)); //存入记录
}
int hash(int keyoffset,int keylen,void *buf,int total_rec_num)
{
//先将 buf 指针偏移到 key 的起始位置:char *p = (char*)buf + keyoffset;
//用一个循环,把 key 的每个字节的 ASCII 值累加到 addr 变量上。
//最后用 addr 对哈希表总槽数(total_rec_num * COLLISIONFACTOR)取模,得到哈希地址。
int i=0;
char *p =(char*)buf+keyoffset;
int addr =0;
for(i=0;i<keylen;i++)
{
addr += (int)(*p);
p++;
}
return addr%(int)(total_rec_num*COLLISIONFACTOR);
}
int checkHashFileFull(int fd)
{//检查Hash文件是否已满
struct HashFileHeader hfh;
readHashFileHeader(fd,&hfh);
if(hfh.current_rec_num<hfh.total_rec_num)
return 0;
else
return 1;
}
int readHashFileHeader(int fd,struct HashFileHeader *hfh)
{
lseek(fd,0,SEEK_SET);
return read(fd,hfh,sizeof(struct HashFileHeader));
}
测试文件
jtRecord.h
//jtRecord.h
//每条记录的长度
#define RECORDLEN 32
struct jtRecord
{
int key;//记录的键值
char other[RECORDLEN-sizeof(int)];//记录的其他内容
};
#ifdef HAVE_CONFIG_H
#include<config.h>
#endif
jtRecord.c
//jtRecord.c
#ifdef HAVE_CONFIG_H
#include<config.h>
#endif
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<string.h>
#include"hashfile.h"
#include"jtRecord.h"
//key相对于本条记录首地址的偏移量和长度
#define KEYOFFSET 0
#define KEYLEN sizeof(int)
//文件名
#define FileNAME "jing.hash"
void showHashFile();
int main(int argc,char *argv[])
{
struct jtRecord rec[6] = {
{1,"jing"},{2,"wang"},{3,"li"},
{4,"zhang"},{5,"qing"},{6,"yuan"}
};
int j=0;
for(j=0;j<6;j++)
{
//计算哈希地址
printf("<%d,%d>\t",rec[j].key,hash(KEYOFFSET,KEYLEN,&rec[j],6));
}
//创建哈希文件
int fd = hashfile_creat(FileNAME,O_RDWR|O_CREAT,RECORDLEN,6);
int i=0;
printf("\nOpen and Save Record...\n");
fd = hashfile_open(FileNAME,O_RDWR,0);
for(i=0;i<6;i++)
{
//保存记录
hashfile_saverec(fd,KEYOFFSET,KEYLEN,&rec[i]);
}
hashfile_close(fd);
showHashFile();
//Demo find Rec
printf("\nFind Record...");
fd = hashfile_open(FileNAME,O_RDWR,0);
int offset = hashfile_findrec(fd,KEYOFFSET,KEYLEN,&rec[4]);
printf("\noffset is %d\n",offset);
hashfile_close(fd);
struct jtRecord jt;
struct CFTag tag;
fd = open(FileNAME,O_RDWR);
lseek(fd,offset,SEEK_SET);
read(fd,&tag,sizeof(struct CFTag));
printf("Tag is <%d,%d>\t",tag.collision,tag.free);
read(fd,&jt,sizeof(struct jtRecord));
printf("Record is {%d,%s}\n",jt.key,jt.other);
//Demo Delete Rec
printf("\nDelete Record...");
fd = hashfile_open(FileNAME,O_RDWR,0);
hashfile_delrec(fd,KEYOFFSET,KEYLEN,&rec[2]);
hashfile_close(fd);
showHashFile();
//Demo Read
fd = hashfile_open(FileNAME,O_RDWR,0);
char buf[32];
memcpy(buf,&rec[1],KEYLEN);
hashfile_read(fd,KEYOFFSET,KEYLEN,buf);
printf("\nRead Record is {%d,%s}\n",((struct jtRecord *)buf)->key,((struct jtRecord *)buf)->other);
hashfile_close(fd);
//Demo Write
printf("\nWrite Record...");
fd = hashfile_open(FileNAME,O_RDWR,0);
hashfile_write(fd,KEYOFFSET,KEYLEN,&rec[3]);
hashfile_close(fd);
showHashFile();
return 0;
}
void showHashFile()
{
int fd;
printf("\n");
fd = open(FileNAME,O_RDWR);
lseek(fd,sizeof(struct HashFileHeader),SEEK_SET);
struct jtRecord jt;
struct CFTag tag;
while(1)
{
if(read(fd,&tag,sizeof(struct CFTag))<=0)
break;
printf("Tag is <%d,%d>\t",tag.collision,tag.free);
if(read(fd,&jt,sizeof(struct jtRecord))<=0)
break;
printf("Record is {%d,%s}\n",jt.key,jt.other);
}
close(fd);
}
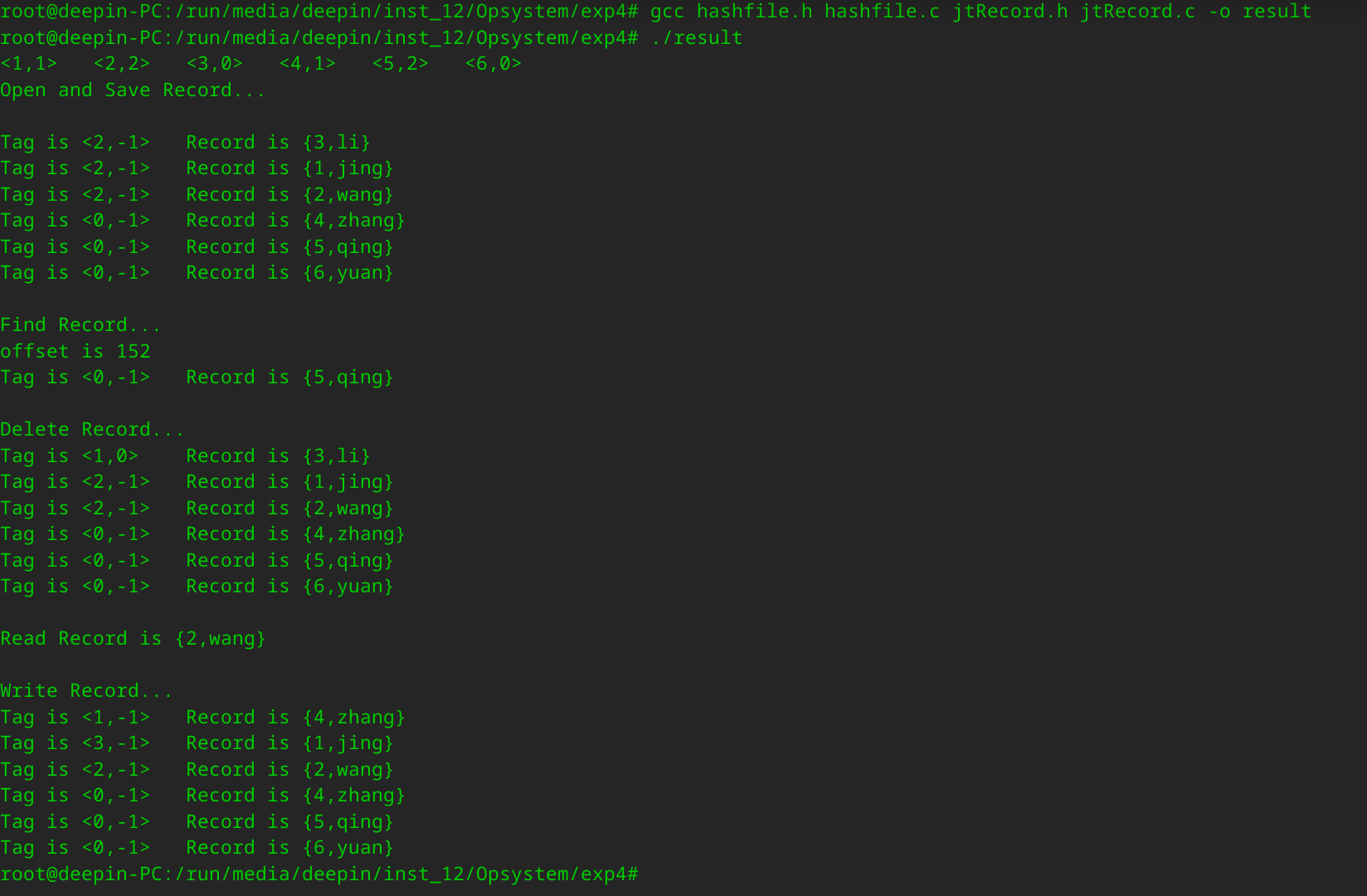
运行结果:
由于程序会创建文件,需要管理员权限,使用su指令转移到root下运行代码。
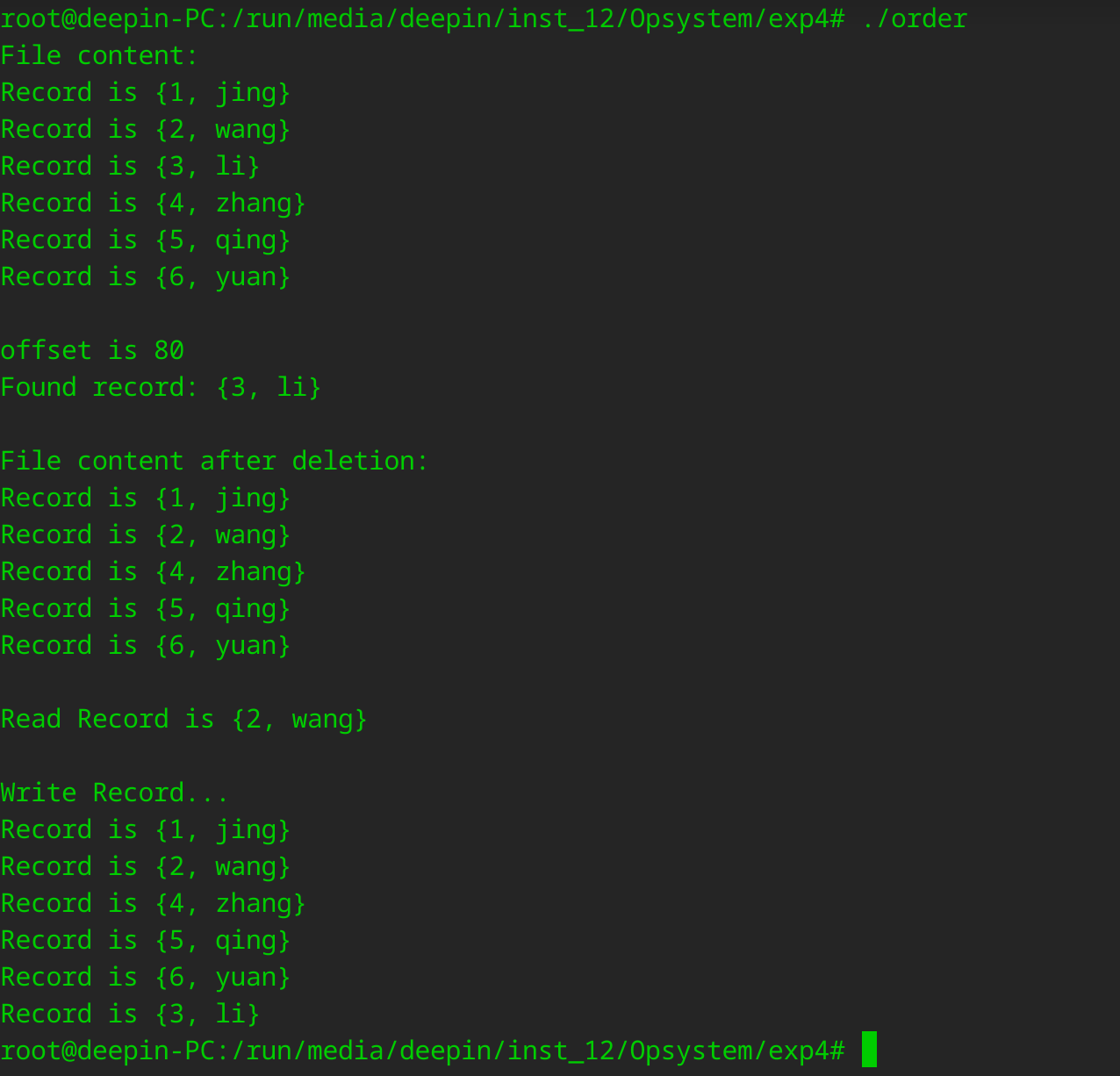
顺序存储实现
先给出代码(能使用hash类似的尽量不改)
代码:
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<stdio.h>
#include<stdlib.h>
#include<memory.h>
#include"jtRecord.h"
#define KEYOFFSET 0
#define KEYLEN sizeof(int)
struct SequenceFileHeader
{
int sig; //Hash文件印鉴
int reclen; //每条记录长度
int total_rec_num; //总记录数
int current_rec_num; //当前记录数
};
// 定义一个函数来比较两个记录
int compare_records(const void *a, const void *b) {
struct jtRecord *rec1 = (struct jtRecord *)a;
struct jtRecord *rec2 = (struct jtRecord *)b;
return rec1->key - rec2->key;
}
// 创建一个顺序文件
int create_sequence_file(const char *filename, mode_t mode, int reclen, int total_rec_num) {
int fd = creat(filename, mode);
if (fd == -1) {
return -1;
}
struct SequenceFileHeader sfh;
sfh.sig = 31415926;
sfh.reclen = reclen;
sfh.total_rec_num = total_rec_num;
//printf("total_num is %d, sfh.total_rec_num is %d\n", total_rec_num, sfh.total_rec_num);
sfh.current_rec_num = 0;
lseek(fd, 0, SEEK_SET);
write(fd, &sfh, sizeof(struct SequenceFileHeader));
close(fd);
return 0;
}
// 打开一个顺序文件
int open_sequence_file(const char *filename, int flags) {
int fd = open(filename, flags);
if (fd == -1) {
return -1;
}
struct SequenceFileHeader sfh;
read(fd, &sfh, sizeof(struct SequenceFileHeader));
if (sfh.sig != 31415926) {
close(fd);
return -1;
}
return fd;
}
// 关闭顺序文件
int close_sequence_file(int fd) {
return close(fd);
}
// 向顺序文件中添加记录
int add_record_to_sequence_file(int fd, void *record) {
struct SequenceFileHeader sfh;
lseek(fd, 0, SEEK_SET);
read(fd, &sfh, sizeof(struct SequenceFileHeader));
if (sfh.current_rec_num >= sfh.total_rec_num) {
//输出文件头所有信息
//printf("sig is %d, reclen is %d, total_rec_num is %d, current_rec_num is %d\n", sfh.sig, sfh.reclen, sfh.total_rec_num, sfh.current_rec_num);
//printf("current_rec_num is %d, total_rec_num is %d\n", sfh.current_rec_num, sfh.total_rec_num);
printf("File is full, cannot add more records.\n");
return -1; // 文件已满
}
lseek(fd, sizeof(struct SequenceFileHeader) + sfh.current_rec_num * (sfh.reclen), SEEK_SET);
write(fd, record, sfh.reclen);
sfh.current_rec_num++;
lseek(fd, 0, SEEK_SET);
write(fd, &sfh, sizeof(struct SequenceFileHeader));
return 0;
}
// 从顺序文件中查找记录
int find_record_in_sequence_file(int fd, int keyoffset, int keylen, void *record) {
struct SequenceFileHeader sfh;
lseek(fd, 0, SEEK_SET);
read(fd, &sfh, sizeof(struct SequenceFileHeader));
struct jtRecord current_record;
for (int i = 0; i < sfh.current_rec_num; i++) {
int key_position = sizeof(struct SequenceFileHeader) + i * (sfh.reclen);
lseek(fd, key_position, SEEK_SET);
read(fd, ¤t_record, sfh.reclen);
if (memcmp((char *)¤t_record + keyoffset, (char *)record + keyoffset, keylen) == 0) {
//输出记录索引
//printf("key = %d, find_key = %d\n", ((struct jtRecord *)record)->key, current_record.key);
return key_position; // 记录找到
}
}
return -1; // 记录未找到
}
// 从顺序文件中删除记录
int delete_record_from_sequence_file(int fd, int keyoffset, int keylen, void *buf) {
struct SequenceFileHeader sfh;
lseek(fd, 0, SEEK_SET);
read(fd, &sfh, sizeof(struct SequenceFileHeader));
struct jtRecord record;
int found = 0;
int del_index = -1;
int offset = sizeof(struct SequenceFileHeader);
// 找到要删除的记录下标
for (int i = 0; i < sfh.current_rec_num; i++) {
lseek(fd, offset + i * (sfh.reclen), SEEK_SET);
read(fd, &record, sfh.reclen);
if (memcmp((char *)&record + keyoffset, (char *)buf + keyoffset, keylen) == 0) {
found = 1;
del_index = i;
break;
}
}
if (!found) {
return -1; // 记录未找到
}
// 将后续记录前移
for (int i = del_index; i < sfh.current_rec_num - 1; i++) {
lseek(fd, offset + (i + 1) * (sfh.reclen), SEEK_SET);
read(fd, &record, sfh.reclen);
lseek(fd, offset + i * (sfh.reclen), SEEK_SET);
write(fd, &record, sfh.reclen);
}
sfh.current_rec_num--;
lseek(fd, 0, SEEK_SET);
write(fd, &sfh, sizeof(struct SequenceFileHeader));
return 0;
}
int read_record_in_sequence_file(int fd, int keyoffset, int keylen, void *buf)
{
struct SequenceFileHeader sfh;
lseek(fd, 0, SEEK_SET);
read(fd, &sfh, sizeof(struct SequenceFileHeader));
int offset = find_record_in_sequence_file(fd, keyoffset, keylen, buf);
if (offset != -1)
{
lseek(fd, offset, SEEK_SET);
return read(fd, buf, sfh.reclen);
}
else
{
return -1;
}
}
// 显示顺序文件内容
void show_sequence_file_content(const char *filename) {
int fd = open(filename, O_RDONLY);
struct SequenceFileHeader sfh;
lseek(fd, 0, SEEK_SET);
read(fd, &sfh, sizeof(struct SequenceFileHeader));
struct jtRecord record;
for (int i = 0; i < sfh.current_rec_num; i++) {
lseek(fd, sizeof(struct SequenceFileHeader) + i * (sfh.reclen), SEEK_SET);
read(fd, &record, sfh.reclen);
printf("Record is {%d, %s}\n", record.key, record.other);
}
close(fd);
}
// 主函数
int main() {
const char *filename = "sequencefile.dat";
struct jtRecord records[] = {
{1, "jing"},
{2, "wang"},
{3, "li"},
{4, "zhang"},
{5, "qing"},
{6, "yuan"}
};
int num_records = sizeof(records) / sizeof(struct jtRecord);
//printf("Records number: %d\n", num_records);
// 创建顺序文件
create_sequence_file(filename, O_RDWR | O_CREAT, sizeof(struct jtRecord), num_records);
// 添加记录
for (int i = 0; i < num_records; i++) {
int fd = open_sequence_file(filename, O_RDWR);
add_record_to_sequence_file(fd, &records[i]);
close_sequence_file(fd);
}
// 显示文件内容
printf("File content:\n");
show_sequence_file_content(filename);
// 查找记录在文件中位置
int fd = open_sequence_file(filename, O_RDWR);
int offset = find_record_in_sequence_file(fd, KEYOFFSET, KEYLEN, &records[2]);
if (offset != -1) {
printf("\noffset is %d\n",offset);
printf("Found record: {%d, %s}\n", records[2].key, records[2].other);
} else {
printf("Record not found.\n");
}
close_sequence_file(fd);
// 删除记录
fd = open_sequence_file(filename, O_RDWR);
delete_record_from_sequence_file(fd, KEYOFFSET, KEYLEN, &records[2]);
close_sequence_file(fd);
// 显示文件内容
printf("\nFile content after deletion:\n");
show_sequence_file_content(filename);
//按索引值查找记录
fd = open_sequence_file(filename, O_RDWR);
char buf[32];
memcpy(buf, &records[1], KEYLEN);
//printf("find record with key %d...\n", ((struct jtRecord *)buf)->key);
if (read_record_in_sequence_file(fd, KEYOFFSET, KEYLEN, &buf) != -1) {
printf("\nRead Record is {%d, %s}\n", ((struct jtRecord *)buf)->key, ((struct jtRecord *)buf)->other);
} else {
printf("Record not found.\n");
}
close_sequence_file(fd);
// 写入记录
printf("\nWrite Record...\n");
fd = open_sequence_file(filename, O_RDWR);
add_record_to_sequence_file(fd, &records[2]);
close_sequence_file(fd);
show_sequence_file_content(filename);
return 0;
}与hash存储区别:
函数功能基本与hash存储相同,只是将存储方式改为顺序存储。比如:
添加记录直接添加在末尾即已保存内容后面。
// 向顺序文件中添加记录
int add_record_to_sequence_file(int fd, void *record) {
struct SequenceFileHeader sfh;
lseek(fd, 0, SEEK_SET);
read(fd, &sfh, sizeof(struct SequenceFileHeader));
if (sfh.current_rec_num >= sfh.total_rec_num) {
//输出文件头所有信息
//printf("sig is %d, reclen is %d, total_rec_num is %d, current_rec_num is %d\n", sfh.sig, sfh.reclen, sfh.total_rec_num, sfh.current_rec_num);
//printf("current_rec_num is %d, total_rec_num is %d\n", sfh.current_rec_num, sfh.total_rec_num);
printf("File is full, cannot add more records.\n");
return -1; // 文件已满
}
lseek(fd, sizeof(struct SequenceFileHeader) + sfh.current_rec_num * (sfh.reclen), SEEK_SET);
write(fd, record, sfh.reclen);
sfh.current_rec_num++;
lseek(fd, 0, SEEK_SET);
write(fd, &sfh, sizeof(struct SequenceFileHeader));
return 0;
}查找记录时,从头开始一条条比对。
// 从顺序文件中查找记录
int find_record_in_sequence_file(int fd, int keyoffset, int keylen, void *record) {
struct SequenceFileHeader sfh;
lseek(fd, 0, SEEK_SET);
read(fd, &sfh, sizeof(struct SequenceFileHeader));
struct jtRecord current_record;
for (int i = 0; i < sfh.current_rec_num; i++) {
int key_position = sizeof(struct SequenceFileHeader) + i * (sfh.reclen);
lseek(fd, key_position, SEEK_SET);
read(fd, ¤t_record, sfh.reclen);
if (memcmp((char *)¤t_record + keyoffset, (char *)record + keyoffset, keylen) == 0) {
//输出记录索引
//printf("key = %d, find_key = %d\n", ((struct jtRecord *)record)->key, current_record.key);
return key_position; // 记录找到
}
}
return -1; // 记录未找到
}删除记录后,将该记录后面的记录逐条向前移动。
// 从顺序文件中删除记录
int delete_record_from_sequence_file(int fd, int keyoffset, int keylen, void *buf) {
struct SequenceFileHeader sfh;
lseek(fd, 0, SEEK_SET);
read(fd, &sfh, sizeof(struct SequenceFileHeader));
struct jtRecord record;
int found = 0;
int del_index = -1;
int offset = sizeof(struct SequenceFileHeader);
// 找到要删除的记录下标
for (int i = 0; i < sfh.current_rec_num; i++) {
lseek(fd, offset + i * (sfh.reclen), SEEK_SET);
read(fd, &record, sfh.reclen);
if (memcmp((char *)&record + keyoffset, (char *)buf + keyoffset, keylen) == 0) {
found = 1;
del_index = i;
break;
}
}
if (!found) {
return -1; // 记录未找到
}
// 将后续记录前移
for (int i = del_index; i < sfh.current_rec_num - 1; i++) {
lseek(fd, offset + (i + 1) * (sfh.reclen), SEEK_SET);
read(fd, &record, sfh.reclen);
lseek(fd, offset + i * (sfh.reclen), SEEK_SET);
write(fd, &record, sfh.reclen);
}
sfh.current_rec_num--;
lseek(fd, 0, SEEK_SET);
write(fd, &sfh, sizeof(struct SequenceFileHeader));
return 0;
}运行结果:
同样在root权限下运行。