一、《用于精确目标检测和语义分割的丰富特征层次结构》
1.1、基本信息
原文标题:Rich feature hierarchies for accurate object detection and semantic segmentation
中文译名:用于精确目标检测与语义分割的丰富特征层次结构
版本:第5版技术报告(Tech report v5)
作者:Ross Girshick等(UC Berkeley)
发表时间:2014年(CVPR会议扩展版)
核心贡献:提出R-CNN(Regions with CNN features)框架,首次将深度卷积网络(CNN)与区域提议方法结合,奠定两阶段目标检测范式基础。
作者主页:
论文地址:
[1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation
1.2、主要内容
方法创新:
区域提议+CNN特征提取:通过选择性搜索(Selective Search)生成候选区域,后经CNN提取高层次特征。
端到端训练改进:针对小样本数据,采用预训练(ImageNet)+微调(PASCAL VOC)策略。
边界框回归:引入后处理步骤优化检测框定位精度。
技术突破:
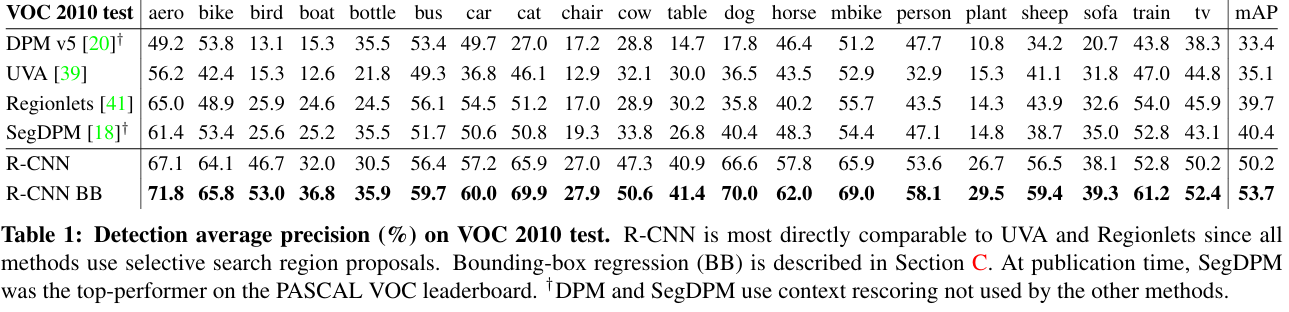
在PASCAL VOC 2012上将mAP从35.1%提升至53.7%,性能飞跃52%。
证明深层CNN特征对复杂视觉任务(检测/分割)的强表征能力。
局限性:
计算成本高(每张图需独立处理约2000个区域提议)。
训练流程非完全端到端(需分阶段优化)。
1.3、影响和作用
学术影响:开创基于深度学习的目标检测新范式,直接启发Fast R-CNN、Faster R-CNN、Mask R-CNN等后续工作。推动CNN在计算机视觉中的核心地位确立(CVPR 2014最佳论文提名)。
工业应用:成为自动驾驶(物体识别)、医学影像分析、卫星图像解译等领域的基础技术。相关思想延伸至自然语言处理(如区域提议+特征提取的类比应用)。
历史意义:被引用超2万次(截至2023年),誉为"目标检测领域的里程碑式研究"。
二、实现过程
1. 候选区域生成:使用选择性搜索或其他方法生成约2000个候选区域 (使用Selective Search方法)。
2. 特征提取:对每个候选区域使用卷积神经网络(通常是在ImageNet上 预训练的网络)提取固定长度的特征向量。
3. 分类:使用支持向量机(SVM)对每个候选区域进行分类,判断其是否 包含特定类别的物体。
4. 回归:使用回归器对每个候选区域的边界框进行微调,以更准确地定位 物体。
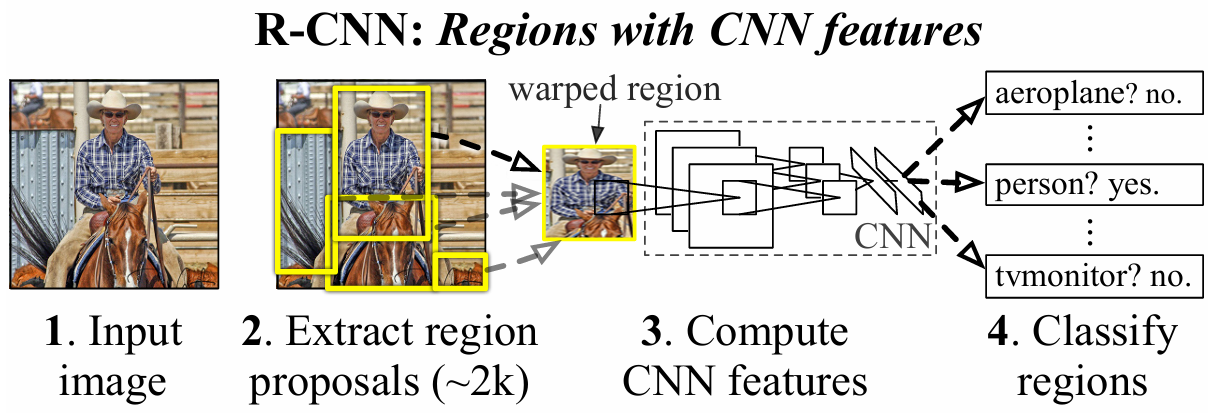
2.1、 候选区域生成
利用Selective Search算法通过分割生成候选区域(region proposals), 这些区域作为后续目标检测和分类的输入。Selective Search算法的主要目 标是通过合并和分割超像素(superpixels)来形成具有潜在目标的区域。
具体来说,Selective Search算法的实现步骤如下:
1. 超像素分割: 首先,图像被分割成许多紧密相连的区域,这些区域称为超像素 (superpixels)。 超像素分割可以使用各种算法,如基于图的分割(例如图割算法) 或基于像素相似性的分割(例如SLIC算法)或者每个不同颜色的区 域代表一个超像素 。
2. 相似性合并: 算法使用不同的合并策略来将这些超像素合并成更大的区域。这些 合并策略通常考虑颜色、纹理、大小和形状等特征的相似性。 合并策略包括贪婪合并、聚类合并、多尺度合并等,以便在不同尺 度上捕获不同类型和大小的目标。
3. 生成候选区域:最终,Selective Search算法生成2000个左右的候选区域,每个区 域都有不同的形状、大小和位置。 这些候选区域被认为是图像中可能包含目标的位置,它们接下来会 被送入CNN进行特征提取和分类,以确定它们是否包含真正的目 标,并且进一步被用来进行目标检测。
Selective Search算法的核心思想是通过多尺度和多种合并策略,快速生成 丰富的候选区域,覆盖图像中各种潜在目标的可能位置。
2.2、特征提取
将2000个候选区域缩放到227*227的像素中,接着将缩放后的候选区域被 送入一个预训练的卷积神经网络(AlexNet)。
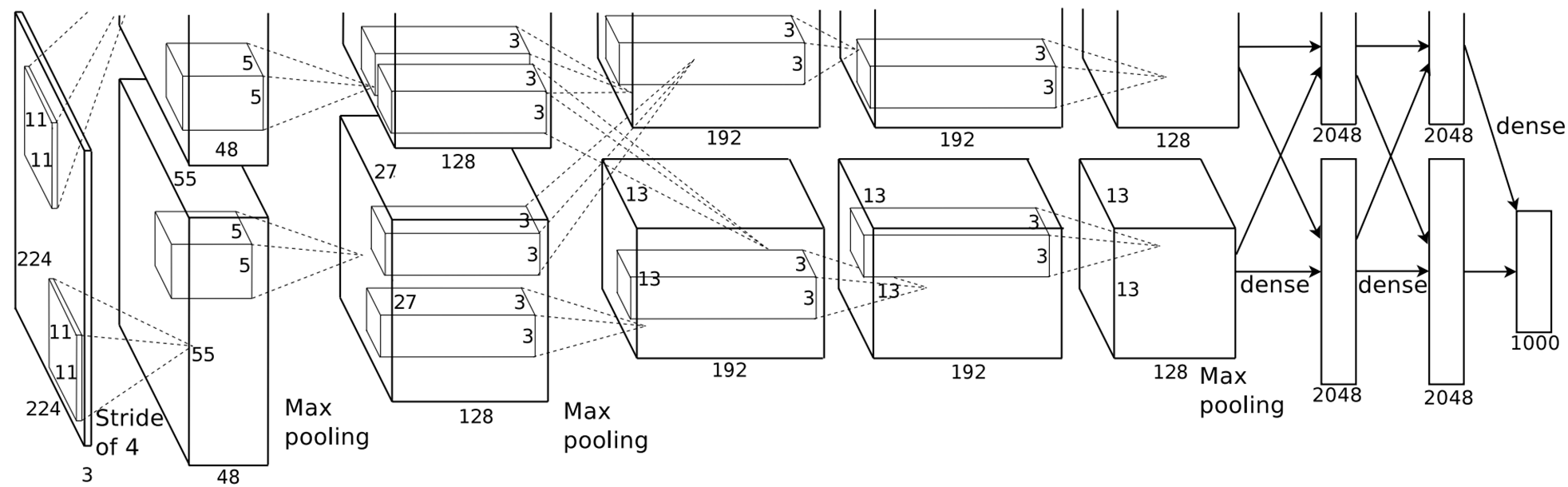
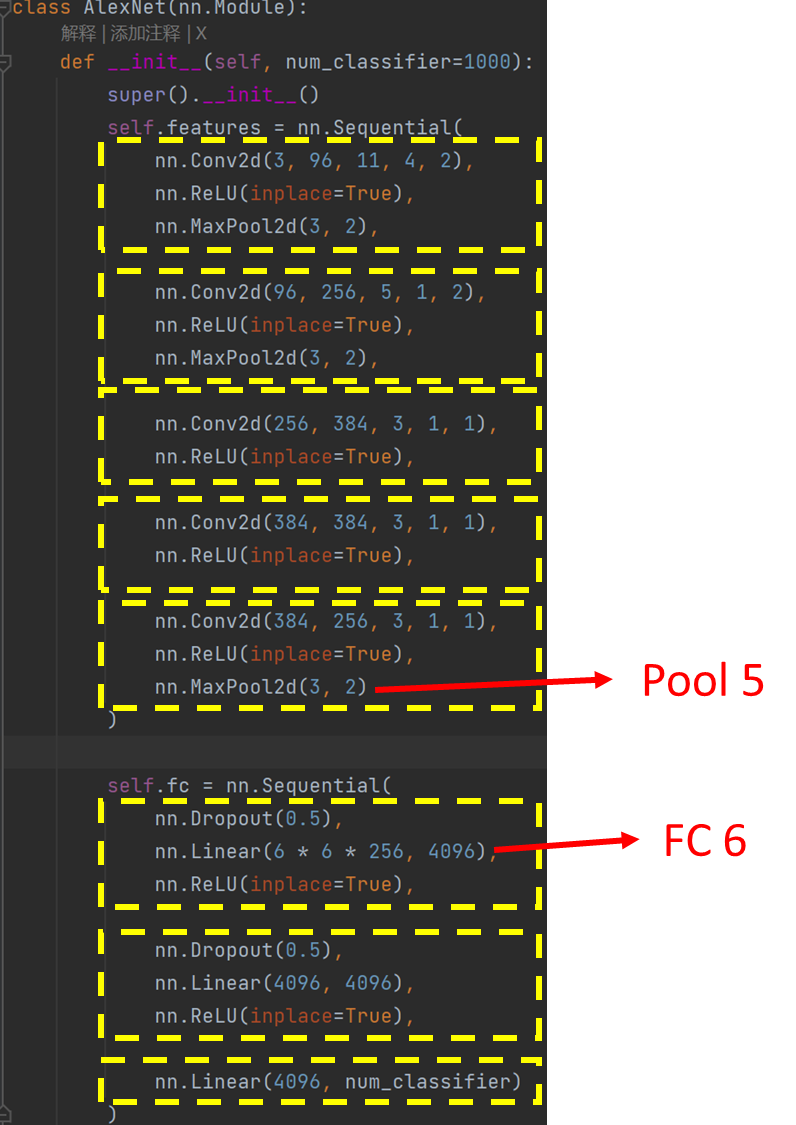
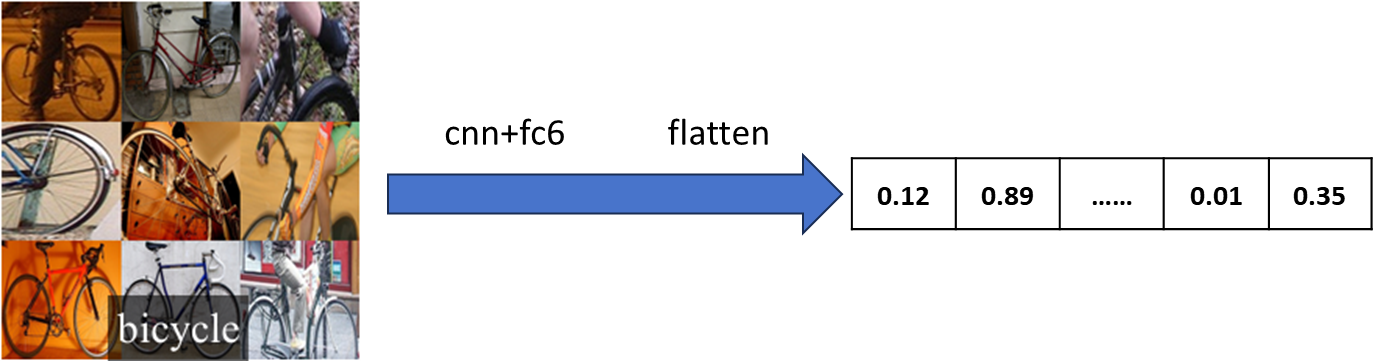
最终得到一个2000*4096的大矩阵
2.3、分类
使用支持向量机(SVM)对每个候选区域进行分类,具体过程为:
1. 将2000*4096特征与20个SVM组成的权重矩阵(4096*20)相乘,得 到2000*20的矩阵;
2. 获取2000*20维矩阵表示每个建议框是某个目标类别的得分;
3. 对上述2000*20维矩阵中每一列,即每一类进行非极大值抑制剔除重叠 建议框,得到该列即该类中得分最高的一些建议框。
每个目标类别通常对应一个独立的支持向量机(SVM)分类器。 这意味着如果有N个不同的目标类别,就会训练和使用N个单独的SVM 分类器来对候选区域进行分类。Pascal VOC有20类,所以是20。
但是在例如Pascal VOC中微调时,实际上有21类,因为还有一类是背景, 即负样本。
负样本是根据IoU选择的,如果预选框和GT BOX的IOU小于一定的阈 值,那么就会被认为是负样本。
负样本的作用
1、负样本在训练分类器时起到了重要作用,帮助模型学习如何区分目 标物体与非目标物体。分类器需要通过负样本学习背景的特征,以便 在推理阶段准确地将目标区域与背景区分开来。
2、训练过程中,平衡的正负样本比例有助于避免模型过度偏向负样本 而导致的分类器不平衡问题,从而提高模型的泛化能力和准确性。
2.4、回归
使用回归器对每个候选区域的边界框进行微调,以更准确地定位物体,即 实际上SS的候选框(2000个)的位置也就是NMS处理后剩余的建议框(并 没有2000个了)的位置并不是那么准确,所以需要进行调整。
具体步骤
1. 将所有的建议框和GT BOX进行IoU计算,小于某个阈值的直接删掉。
2. 使用20个回归器对4096维的数据进行计算(Pascal VOC是21个)。
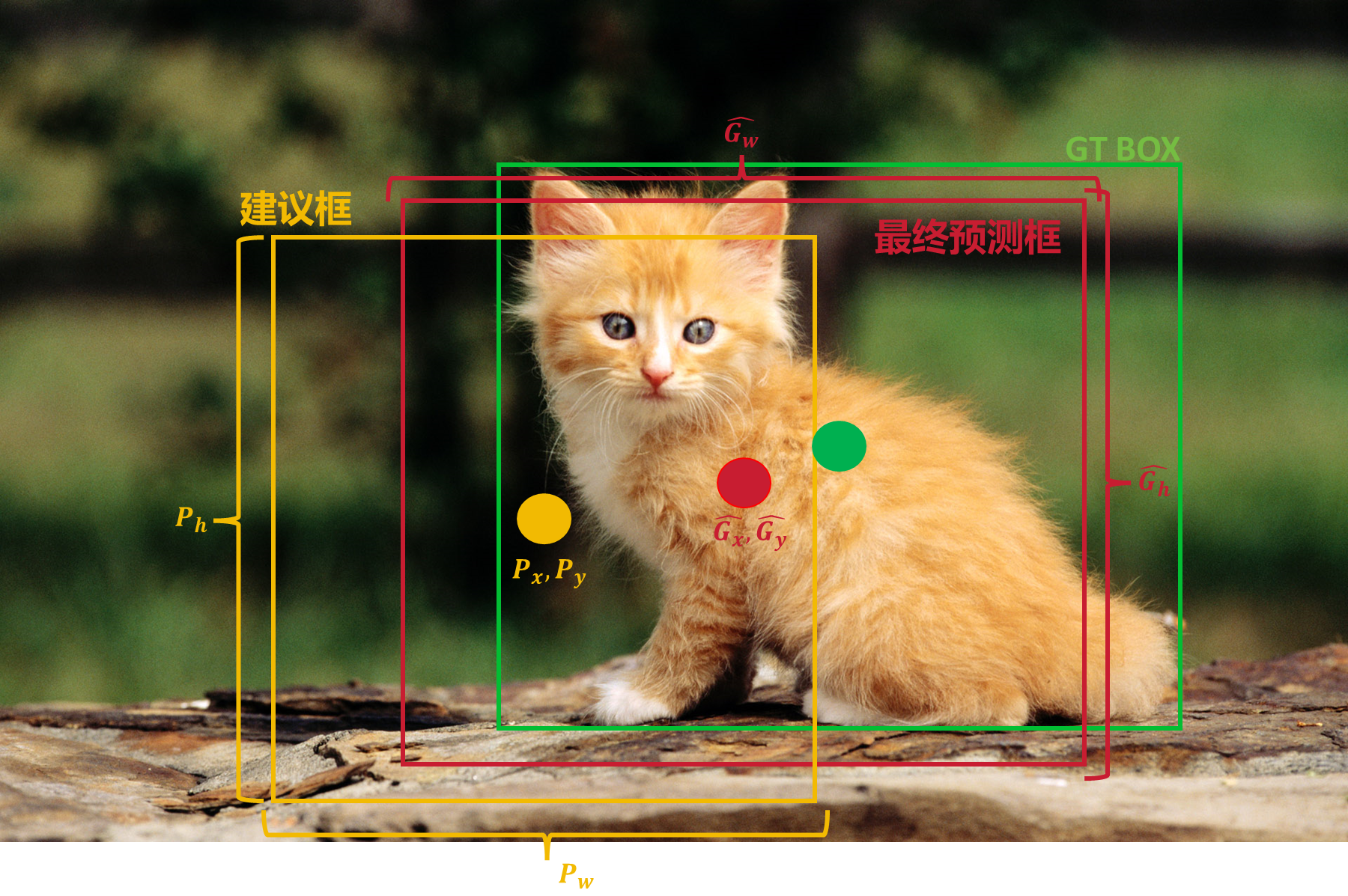

这些公式用于将网络预测的相对变化(偏移量)转换为绝对的边界框坐标 和尺寸。

三、R-CNN缺点
1. 预测速度比较慢:CPU上53秒/张,GPU上13秒/张。
2. 需要的内存较大:一个候选框4096维,一张图2000个候选框,如果有 1000张图,如果每个数是float32浮点型, 即每个数占用4字节(32 位) ,每个候选框占用内存为2096*4=16384个字节,换算成MB就是 16384/(1024^2)=0.015625MB, 那1张图所占的内存为0.015625*2000=31.25MB, 1000张图所占的内存为31.25*1000=31.25GB。
四、R-CNN过程总结
