在大数据时代,数据往往分散存储在各种不同类型的系统中。其中,传统的关系型数据库 (RDBMS) 如 MySQL, Oracle, PostgreSQL 等,仍然承载着大量的关键业务数据。而Hadoop生态系统 (包括 HDFS, Hive, HBase 等) 则以其强大的分布式存储和计算能力,成为处理和分析海量数据的首选平台。如何高效、便捷地在这两种体系之间迁移数据,成为了一个亟待解决的问题。正是在这样的需求背景下,Apache Sqoop 应运而生,它扮演了数据导入导出工具的重要角色。
一、Sqoop 是什么?—— 数据迁移的瑞士军刀
Sqoop (SQL-to-Hadoop and Hadoop-to-SQL) 是一个专门设计用来在 Apache Hadoop (及其相关项目如 Hive 和 HBase) 与结构化数据存储 (如关系型数据库) 之间传输批量数据的命令行工具。
简单来说,Sqoop 的核心功能是:
- 导入 (Import):将数据从关系型数据库 (如 MySQL 中的表) 抽取出来,并加载到 Hadoop 的分布式文件系统 HDFS 中,通常存储为文本文件 (如 CSV, TSV) 或更高效的序列化格式 (如 Avro, Parquet)。数据也可以直接导入到 Hive 表或 HBase 表中。
- 导出 (Export):将存储在 HDFS (或其他 Hadoop 系统) 中的数据抽取出来,并加载回到关系型数据库的表中。
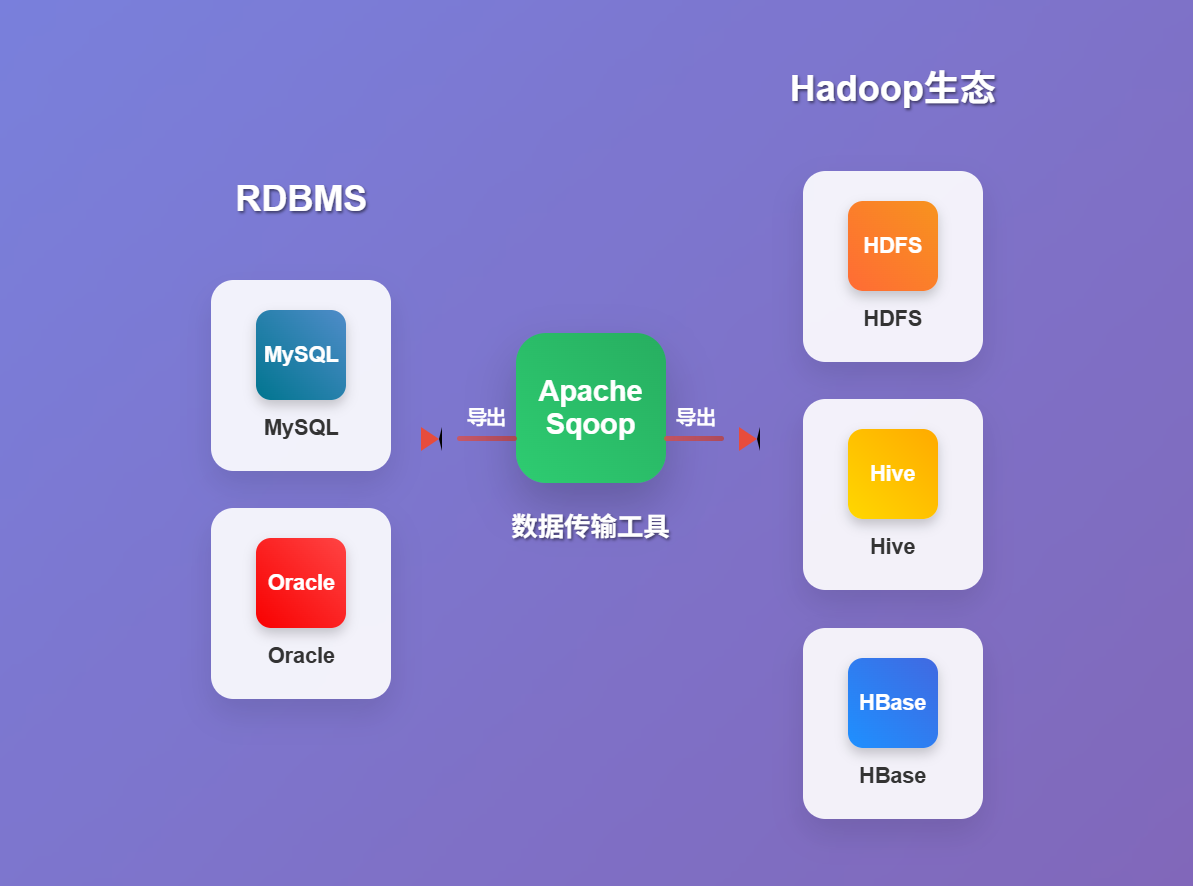
Sqoop 利用 MapReduce 来并行处理数据的导入和导出任务,从而实现高效的数据传输,尤其擅长处理 大规模数据集。它支持多种主流的关系型数据库,并提供了丰富的命令行选项来控制数据迁移的各个方面,如数据过滤、并行度调整、数据格式转换等。
二、Sqoop 的发展简史
Sqoop 的发展历程与其在大数据生态中的重要性紧密相关:
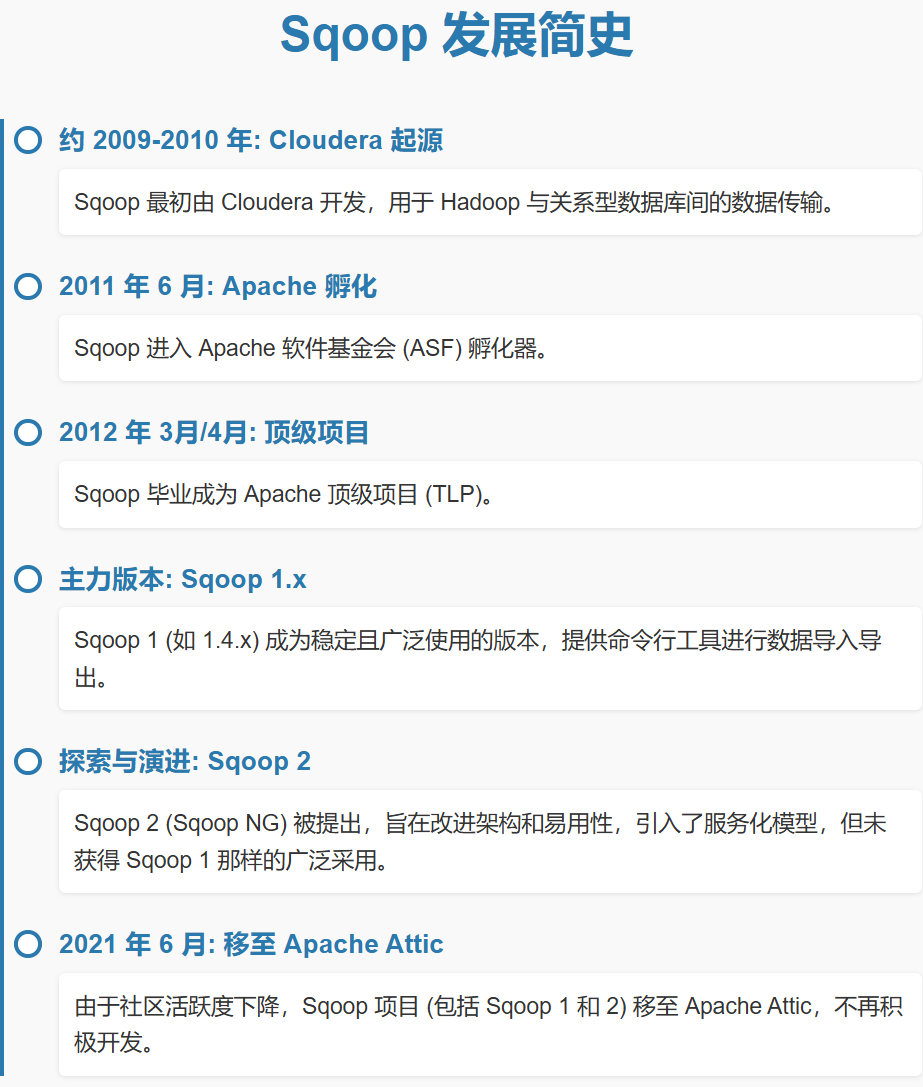
起源与早期发展 (约 2009 - 2011 年):
- Sqoop 最初是由 Cloudera 公司开发的。随着 Hadoop 在企业中的应用逐渐增多,将现有关系型数据库中的历史数据导入 Hadoop 进行分析的需求日益迫切。
- 早期的数据迁移往往需要编写自定义的脚本或程序,效率低下且容易出错。Sqoop 的出现旨在简化这一过程。
- 2011 年,Sqoop 被贡献给 Apache 软件基金会 (ASF),进入孵化器项目。
成为 Apache 顶级项目与 Sqoop 1 的成熟 (约 2012 - 至今):
- 2012 年 3 月,Sqoop 成功毕业成为 Apache 顶级项目 (TLP),这标志着其技术成熟度和社区活跃度得到了广泛认可。
- Sqoop 1 (主要是 1.4.x 系列版本) 成为了最稳定、应用最广泛的版本。它提供了稳定的导入导出功能,支持众多数据库,并与Hadoop 生态中的其他组件 (如 Hive, Oozie) 良好集成。
Sqoop 2 的探索与演进 (Sqoop1 的后续版本):
- 为了解决 Sqoop 1 在易用性、安全性、可扩展性等方面的一些局限,社区启动了 Sqoop 2 (也称 Sqoop NG - Next Generation) 项目。
- Sqoop 2 的设计目标包括:提供REST API 和 Web UI 以方便管理,更强的安全性 (如基于角色的访问控制),以及更好的连接器模型以支持更多数据源。
- 然而,Sqoop 2 的发展和推广相对 Sqoop 1 较为缓慢,Sqoop 1.4.x 仍然是目前许多生产环境中的主力版本。
三、Sqoop 的工作原理
Sqoop 的核心工作原理是将数据传输任务转换为一系列的 MapReduce 作业 (或在较新版本中可能利用 Tez/Spark 等引擎,但经典原理基于 MapReduce)。
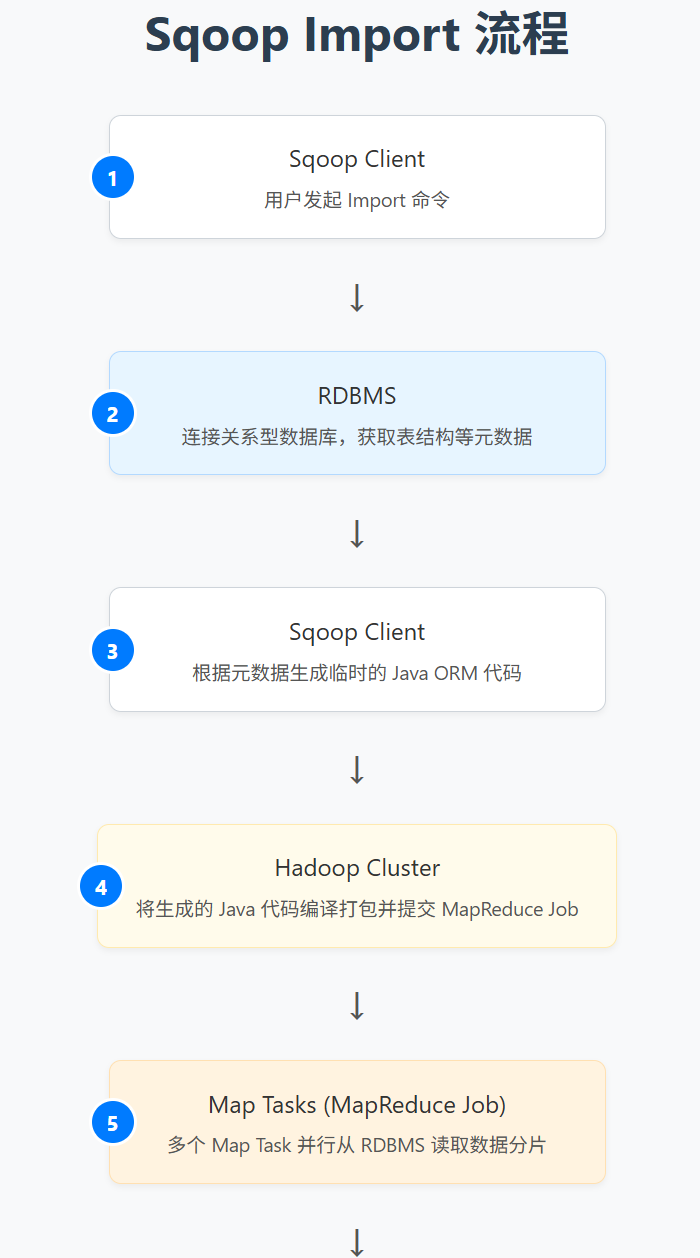
3.1 导入 (Import) 原理:
连接数据库与元数据获取:用户通过命令行指定数据库连接信息 (JDBC URL, 用户名, 密码) 和要导入的表 (或 SQL 查询)。Sqoop 首先连接到数据库,获取表的元数据信息 (如列名、数据类型)。
代码生成 (Code Generation):Sqoop 根据表的元数据自动生成一个特定于该表的 Java 类。这个类知道如何从数据库读取记录并将其序列化 (或反序列化)。
MapReduce 作业提交:Sqoop 将导入任务作为一个 MapReduce 作业提交到 Hadoop 集群。
- 分片 (Splitting):Sqoop 尝试将要导入的表数据进行逻辑分片 (splitting)。默认通常基于主键或其他数值型列的范围进行分片。每个分片会分配给一个 Map Task 处理。分片的目的是实现并行导入。
- Map Tasks 执行:每个 Map Task 使用生成的 Java 类和 JDBC 连接到数据库,读取其负责分片的数据。然后,Map Task 将读取到的数据 写入到 HDFS 上的目标位置,可以指定输出文件的格式 (如文本、Avro、Parquet)。
- Reduce Tasks (通常不需要):对于大多数导入操作,不需要 Reduce 阶段,因为 Map 任务可以直接将数据写入 HDFS。

3.2 导出 (Export) 原理:
连接数据库与元数据获取:用户指定 HDFS 上的数据源路径、目标数据库连接信息和目标表名。Sqoop 连接数据库获取目标表的元数据。
代码生成:与导入类似,Sqoop 生成一个Java 类,该类知道如何将 HDFS 中的数据解析并转换为适合插入到目标数据库表的格式。
MapReduce 作业提交:
- Map Tasks 执行:每个 Map Task 读取 HDFS 上分配给它的部分数据文件。它使用生成的 Java 类解析数据,并将每条记录转换为数据库记录。
- 写入数据库:Map Task 通过 JDBC 将转换后的记录 批量插入到目标数据库表中。为了提高性能和保证事务性 (一定程度上),Sqoop 通常会分批次执行
INSERT语句,并可能使用临时表或分阶段提交的策略。 - Reduce Tasks (通常不需要):导出操作通常也主要由 Map 任务完成。
四、Sqoop 的价值与意义
Sqoop 的出现和广泛应用,对于大数据生态的发展具有重要的价值和意义:
打通数据孤岛:Sqoop 最直接的价值在于打破了传统关系型数据库与Hadoop 大数据平台之间的数据壁垒。它使得企业能够方便地将存量业务数据迁移到 Hadoop 中进行更深入、更复杂的分析,挖掘数据价值。
降低数据迁移门槛:在 Sqoop 出现之前,进行大规模数据迁移往往需要编写复杂的ETL脚本或Java程序。Sqoop 通过简单的命令行接口和自动代码生成,极大地简化了这一过程,降低了技术门槛,使得数据工程师和分析师可以更专注于数据本身。
提升数据迁移效率:Sqoop 利用 MapReduce 的并行处理能力,可以同时启动多个任务并发地进行数据读写,显著提高了大规模数据迁移的效率,缩短了数据准备时间。
支持多种数据格式与目标:Sqoop 不仅支持将数据导入为简单的文本文件,还支持导入为更高效、更适合分析的列式存储格式 (如 Avro, Parquet)。同时,它可以直接将数据导入 Hive 表 (自动创建表结构) 或 HBase,方便后续的数据分析和应用。
促进数据仓库和数据湖建设:Sqoop 是构建企业级数据仓库和数据湖的关键组件之一。它负责从各种业务系统 (通常是RDBMS) 定期抽取数据到中央数据平台,为后续的数据整合、清洗、分析和挖掘提供原始数据源。
与调度系统集成,实现自动化:Sqoop 可以方便地与 Oozie, Azkaban, Airflow 等工作流调度系统集成,实现数据迁移任务的自动化调度和监控,构建稳定可靠的数据管道。
结语:不可或缺的数据搬运工
尽管随着技术发展,新的数据集成工具 (如 Spark SQL 的 JDBC 数据源、Flink CDC 等) 不断涌现,但 Sqoop 凭借其成熟稳定、简单易用、专注于批量数据迁移的特性,在许多大数据场景下,尤其是在将传统关系型数据库数据接入 Hadoop 生态的初始加载和周期性批量同步方面,仍然扮演着 不可或缺的角色。它是连接结构化数据世界与大数据分析平台的重要桥梁和勤恳的数据搬运工。