今天学习python的web.py,返回的内容为列表样式的字符串,如下
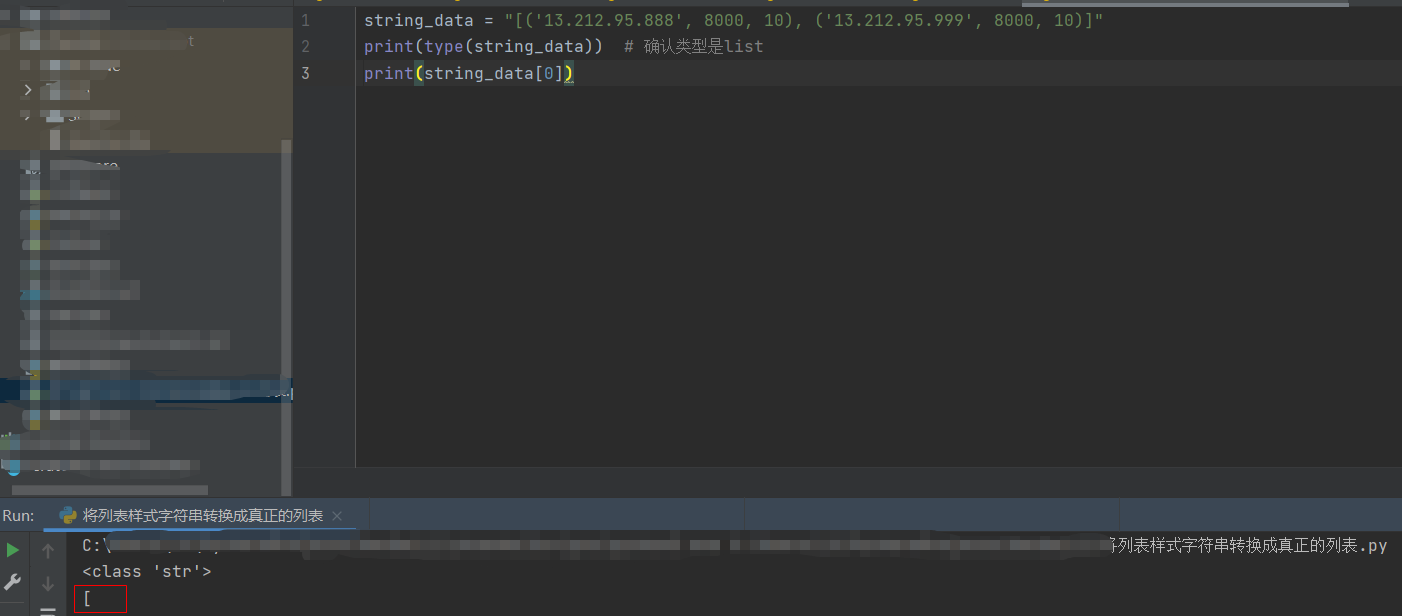
string_data = "[('13.212.95.888', 8000, 10), ('13.212.95.999', 8000, 10)]"
此时,如果想提取第一个元素,也就是('13.212.95.888', 8000, 10),不能使用string_data[0],因为string_data是一个字符串。
看一下运行情况,结果仅仅是一个[:
那么如何操作呢?
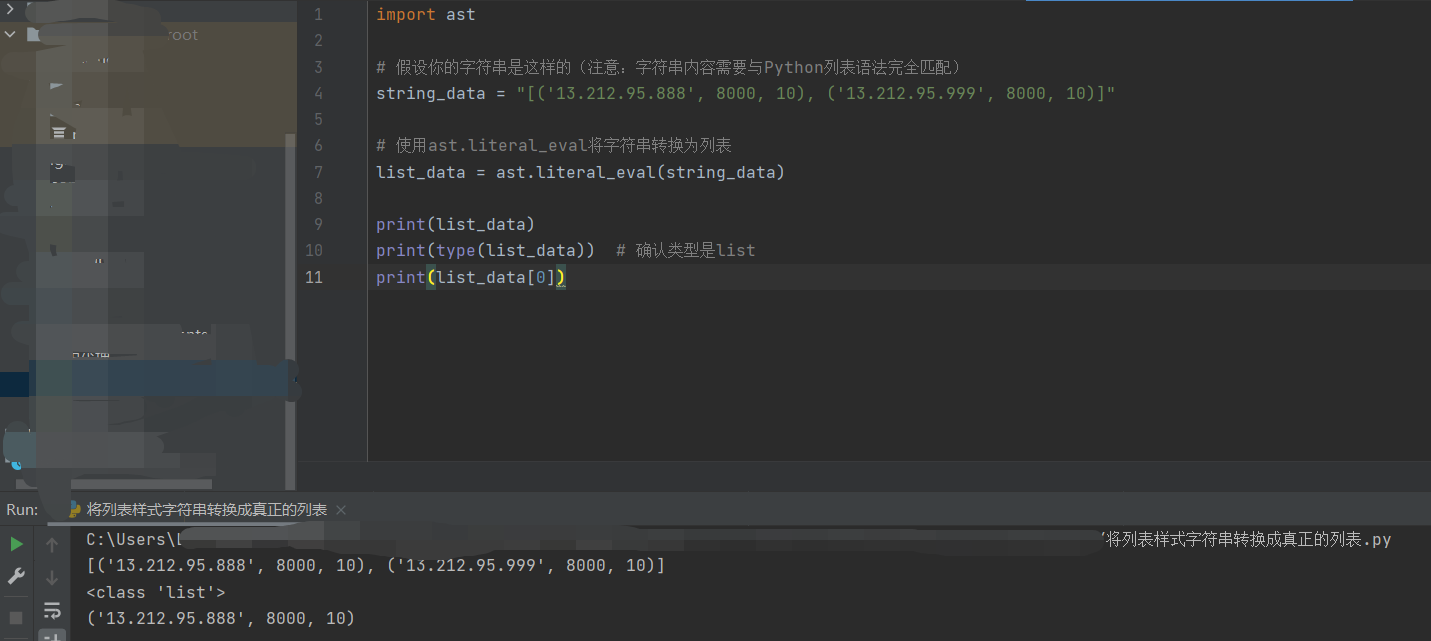
import ast
# 假设你的字符串是这样的(注意:字符串内容需要与Python列表语法完全匹配)
string_data = "[('13.212.95.888', 8000, 10), ('13.212.95.999', 8000, 10)]"
# 使用ast.literal_eval将字符串转换为列表
list_data = ast.literal_eval(string_data)
print(list_data)
print(type(list_data)) # 确认类型是list结果就和预期的一样了。
顺便说一下,对于json数据也存在如此的问题,所以,出现了json.dumps()和 json.loads()。
json.dumps()函数是将字典转化为json字符串,一般用在web.py的服务器的响应函数的return之前,因为return 字符串是最好的;
class Index(object):
def GET(self):
json_result = json.dumps(字典数据)
return json_result又如:
import json
dict1 = {'age': '12'}#也可以是dict1 = {"age": "12"}
json_info = json.dumps(dict1)
print(json_info)
print(type(json_info))注:字典里的内容可以是单引号,也可以是双引号。但json字符串数据必定是双引号。
结果:
json.loads()函数是将json字符串转化为字典,一般用在客户端请求处理中,请求完成后,得到的响应是服务器返回的字符串,想要进行下一步的数据提取和操作,转换成字典会更方便。
import requests
import json
r = requests.get('http://127.0.0.1:1234/')
ip_ports = json.loads(r.text)
print ip_ports又如:
json_info = '{"age": "12"}'#必须是字符串,而且json数据必须是双引号
dict1=json.loads(json_info)
print(dict1)
print(type(dict1))结果: