一、JVM 堆内存:对象的生存与消亡之地
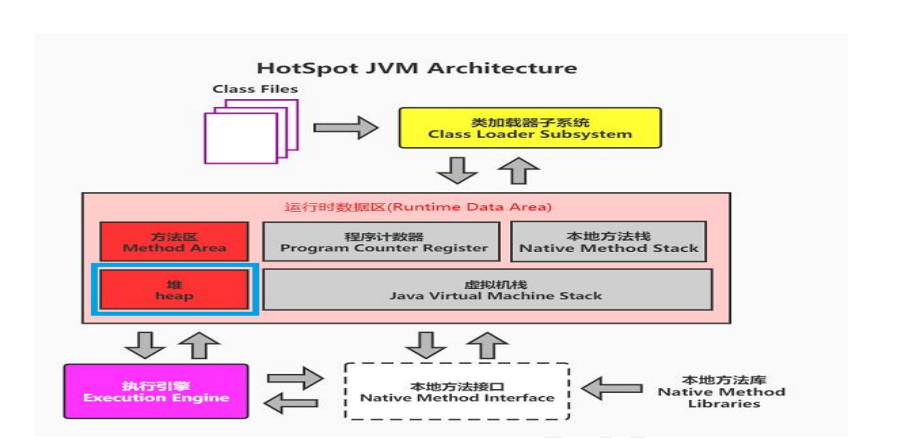
作为 Java 虚拟机中最大的内存区域,堆内存是所有对象实例的 “出生地” 与 “安息所”。从程序运行的角度看,所有通过new关键字创建的对象都在堆中分配内存,其生命周期完全由垃圾回收机制(GC)自动管理,开发者无需手动释放。
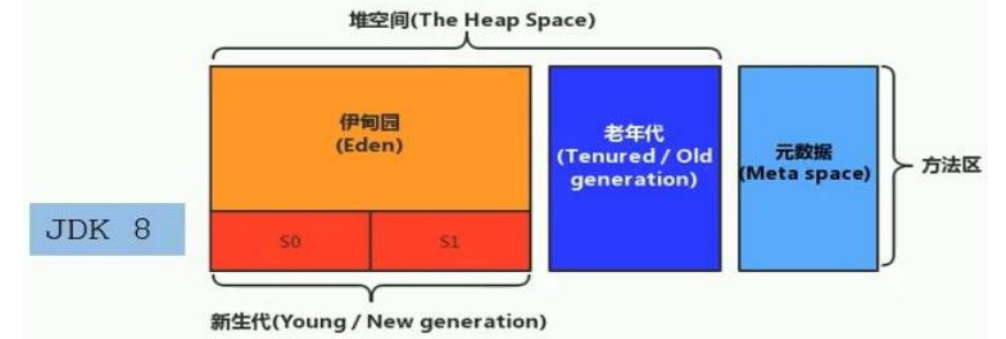
1.堆内存的区域划分(以 Java 8 为例)
堆内存被逻辑划分为新生代和老年代两大区域,这种分代设计是 JVM 性能优化的关键策略:
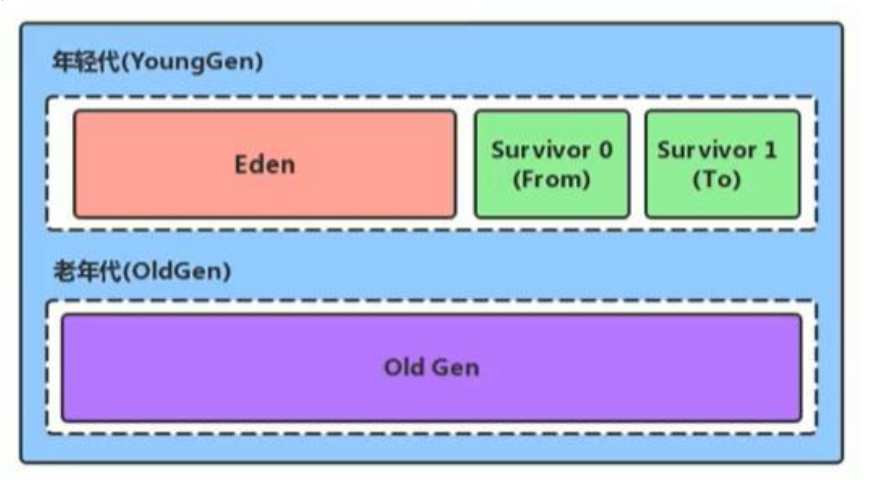
新生代(Young Generation)
- Eden 区:新对象的默认分配区域,占据新生代 80% 的空间。当 Eden 区填满时,会触发Minor GC(新生代垃圾回收),回收不再被引用的对象。
- Survivor 区(S0 和 S1):两个大小相等的区域(各占新生代 10%),用于存放 Minor GC 后存活的对象。每次 GC 后,存活对象会在 S0 和 S1 之间 “轮换”,确保总有一个 Survivor 区为空,这种设计避免了频繁的全量复制,提升了内存利用效率。
老年代(Old Generation)
- 存储生命周期较长的对象,如缓存数据、静态引用对象等。对象进入老年代的条件包括:
- 在新生代经历 15 次 GC 后仍存活(默认年龄阈值,可通过
-XX:MaxTenuringThreshold调整)。- 大对象直接分配(超过新生代可用空间时,通过
-XX:PretenureSizeThreshold配置)。- 老年代内存不足时触发Major GC,若回收后仍无法满足需求,将触发Full GC,若依然失败则抛出
OutOfMemoryError: Java heap space。
2.对象创建与内存流转过程
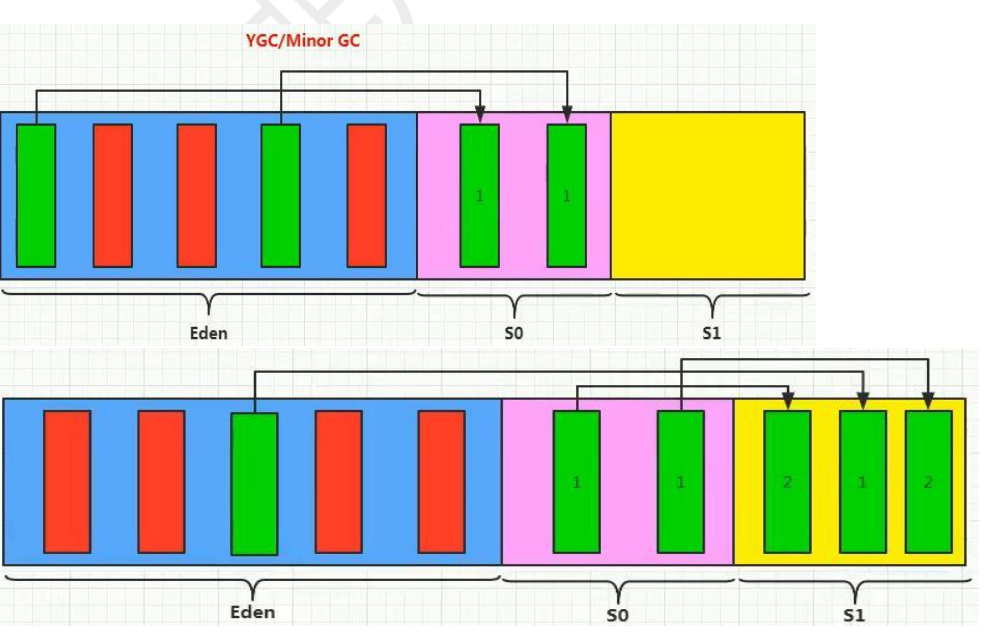
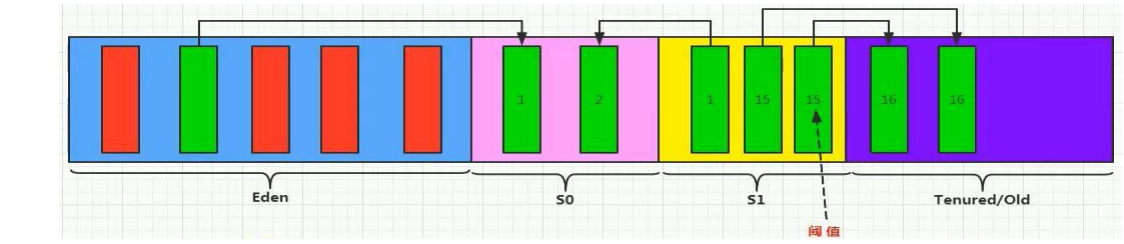
- Eden 区优先分配:新对象首先在 Eden 区创建,若空间不足则触发 Minor GC,回收无效对象。
- Survivor 区的 “年龄增长”:第一次 Minor GC 后,存活对象进入 S0 区,年龄标记为 1;下次 GC 时,S0 区存活对象(年龄 + 1)与新 Eden 区存活对象转移至 S1 区,依此类推。
- 老年代 “晋升”:当对象年龄达到阈值或超过 Survivor 区容量时,进入老年代。老年代采用标记 - 清除或标记 - 压缩算法回收,减少内存碎片。
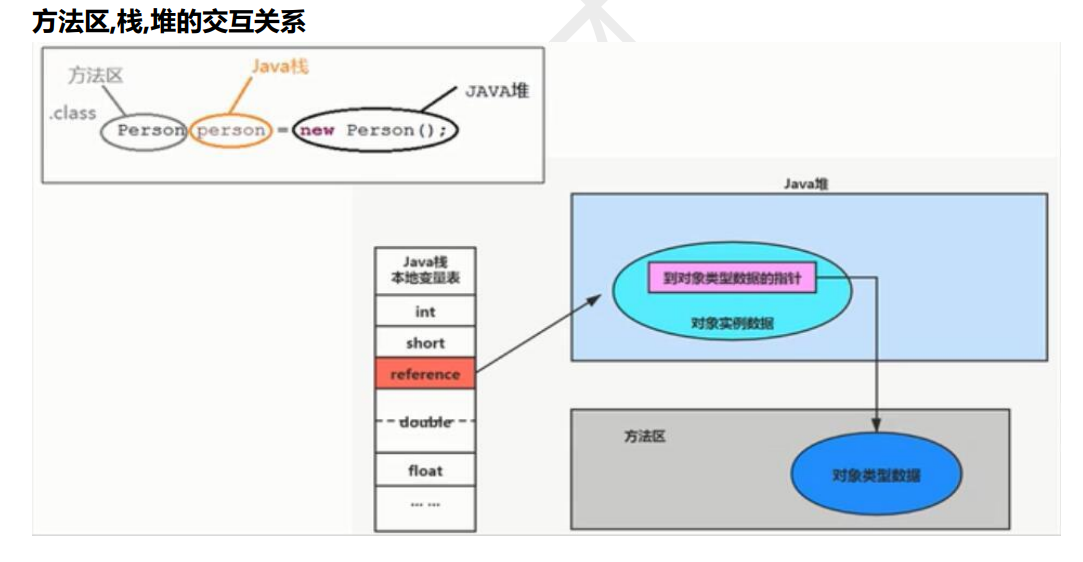
二、方法区:元数据与静态数据的 “知识库”
方法区是 JVM 中存储类元数据的核心区域,虽然逻辑上属于堆的一部分,但在 HotSpot 虚拟机中被独立称为非堆(Non-Heap)或元空间(Metaspace)(JDK8+)。
存储内容与功能特性
- 类元数据:包含类的字节码(
.class文件内容)、方法定义、字段信息等,例如public class User的结构会被解析为方法区中的元数据。- 常量池:存储字符串常量(如
"hello world")和static final修饰的常量,例如public static final int COUNT = 10中的COUNT值。- 静态变量:类级别的变量(如
public static int age),其内存分配在方法区的静态存储区域。- JIT 编译代码:热点代码(如高频调用的方法)经即时编译器优化后生成的本地机器指令,缓存于此以提升执行效率。
内存管理与回收机制
- 动态扩展:通过
-XX:MetaspaceSize参数设置元空间初始大小,默认随类加载动态扩展,但若加载类过多可能导致OutOfMemoryError: Metaspace。- 低效的垃圾回收:
- 常量回收:当字符串常量不再被引用时,可能被回收(如
String.intern()方法释放的常量)。- 类卸载:需满足严格条件(堆中无该类实例、类加载器已回收、无反射引用),实际应用中很少发生,因此方法区回收通常不是 GC 的重点。
三、执行引擎:字节码的 “翻译官” 与 “优化器”
执行引擎是 JVM 的 “执行核心”,负责将字节码转换为底层操作系统可识别的机器指令,其工作机制直接影响程序的运行效率。
解释执行与编译执行的双重模式
解释器(Interpreter)
- 工作原理:逐行将字节码转换为机器指令并执行,无需提前编译,适合程序启动阶段或低频执行的代码。
- 优缺点:启动速度快,但执行效率较低,例如首次调用的方法会直接通过解释器执行。
JIT 即时编译器(Just-In-Time Compiler)
- 工作原理:分析代码调用频率,对高频执行的 “热点代码”(如循环体、核心业务方法)进行深度优化,编译为本地机器指令并缓存至方法区。
- 优化手段:包括内联优化(将小方法直接嵌入调用处)、常量传播(将常量值直接替换到代码中)、循环展开(减少循环判断次数)等,大幅提升执行效率。
- 热点探测:通过计数器统计方法调用次数或循环执行次数,超过阈值(如 10000 次)即判定为热点代码,触发 JIT 编译。
混合模式的性能平衡
JVM 默认采用 “解释 + 编译” 的混合执行模式:
- 启动阶段:通过解释器快速执行代码,避免编译延迟。
- 运行阶段:JIT 编译器逐步优化热点代码,使程序在运行中逐渐 “升温”,平衡启动速度与长期性能。
这种设计使得 Java 兼具脚本语言的灵活性和编译语言的高效性,例如电商秒杀系统中,高频的库存扣减方法会被 JIT 编译优化,提升吞吐量。
四、本地方法接口:Java 与 Native 世界的 “连接器”
本地方法接口(Native Interface)是 Java 与非 Java 代码交互的桥梁,允许 Java 程序调用 C/C++ 等语言实现的底层功能。
本地方法的应用场景
- 跨平台功能调用:访问操作系统底层资源,如文件系统(
FileInputStream的底层实现)、网络通信(Socket 接口)。- 性能敏感场景:对执行效率要求极高的代码(如加密算法、图形渲染),使用 C/C++ 实现以提升性能。
- 兼容遗留系统:集成现有非 Java 代码库,避免重复开发。
执行流程与实现细节
- 声明与注册:
在 Java 代码中使用native关键字声明本地方法(如public native int readFile(String path);),JVM 通过 ** 本地方法栈(Native Method Stack)** 记录方法调用信息。- 本地库加载:
执行引擎调用本地方法时,通过本地方法接口加载对应的本地库(Linux 下为.so文件,Windows 下为.dll文件),例如java.lang.System.currentTimeMillis()底层调用 C 语言的系统时间接口。- 结果返回:
本地代码执行完毕后,结果通过接口返回给 Java 层,继续后续逻辑处理。
本地方法栈的特点
- 线程私有:每个线程独立拥有本地方法栈,用于管理本地方法的调用栈帧,避免线程间数据干扰。
- 内存溢出风险:若本地方法递归调用过深或分配内存过大,可能抛出
StackOverflowError,需注意递归深度控制。
五、核心组件协同:从代码到机器指令的完整旅程
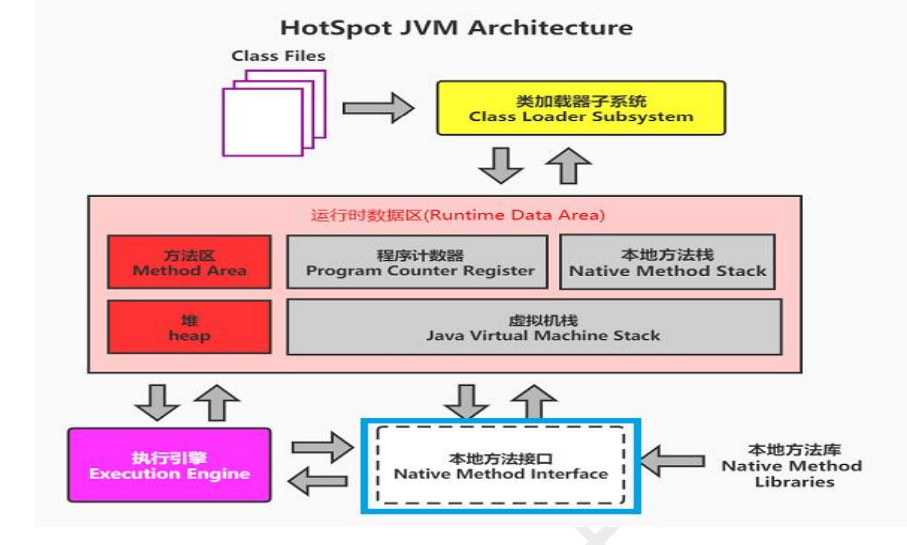
以new HashMap()为例,各组件协作流程如下:
- 类加载(方法区与类加载器):
类加载器将HashMap类的字节码加载至方法区,解析其构造方法、put方法等元数据。- 对象创建(堆内存):
在堆中为HashMap实例分配内存,初始化负载因子、容量等成员变量,对象引用指向方法区的HashMap元数据。- 方法执行(执行引擎):
执行引擎将new HashMap()的字节码解释或编译为机器指令,调用构造方法完成初始化。若put方法被高频调用,触发 JIT 编译优化。- 本地方法调用(如有):
若涉及哈希算法的底层实现(如native int hash(Object key)),通过本地方法接口调用 C 语言实现的哈希函数计算键值。- 垃圾回收(堆与 GC):
当HashMap实例不再被引用时,GC 标记其为垃圾对象,在 Minor GC 或 Major GC 中回收堆内存,方法区的HashMap元数据在满足卸载条件时被释放。
六、性能优化与实践建议
- 堆内存调优:
- 通过
-Xms和-Xmx设置合理的堆大小,避免频繁 GC。- 新生代占比可通过
-Xmn调整,通常建议新生代占堆内存的 1/3-1/2,适合大多数应用场景。- 方法区管理:
- 避免加载过多无用类,可通过
-XX:MetaspaceSize限制元空间大小,预防内存溢出。- 执行引擎优化:
- 分析 JIT 编译日志(
-XX:+PrintCompilation),定位未被优化的热点代码,针对性调整算法或结构。- 本地方法使用建议:
- 尽量减少本地方法调用频率,避免跨语言交互的性能损耗。
- 对必须使用的本地代码,做好内存管理,防止内存泄漏。
总结
JVM 的堆、方法区、执行引擎和本地方法接口共同构成了 Java 程序的运行基础:
- 堆内存通过分代回收机制高效管理对象生命周期;
- 方法区为类元数据提供全局存储,确保类型信息的唯一性;
- 执行引擎通过解释与编译的混合模式平衡启动速度与执行性能;
- 本地方法接口打破语言边界,赋予 Java 调用底层系统的能力。
理解这些组件的原理与协作,不仅能深入掌握 Java 的运行机制,更能在性能调优、内存故障排查中精准定位问题。无论是优化 GC 频率、分析热点代码,还是合理使用本地方法,JVM 的底层设计思想都为开发者提供了清晰的指引。在实际开发中,结合业务场景合理配置 JVM 参数,充分利用各组件特性,才能最大化发挥 Java 的性能优势。