论文来源:ICCV(2023)
项目地址:https://github.com/southnx/ACoLP
1.研究背景与问题
开放集场景下的泛化性:传统 HOI 检测假设训练集包含所有测试类别,但现实中存在大量未见过的 HOI 类别(如 “修理自行车” 在训练中未出现)。视频 HOI 需处理时间动态信息(如 “打开”“关闭” 等时序动作),静态图像方法无法直接迁移。
时序信息建模困难:视频中的交互依赖连续帧的时空关系,现有方法多聚焦物体和人体特征,忽略动作本身的语义核心作用。
现有方法局限:
缺乏动作中心建模:多数方法以物体 / 人体为中心,忽视动词(动作)的核心语义价值。
开放集能力不足:未显式设计泛化机制,难以识别训练未见的 HOI 类别。
2.核心创新点
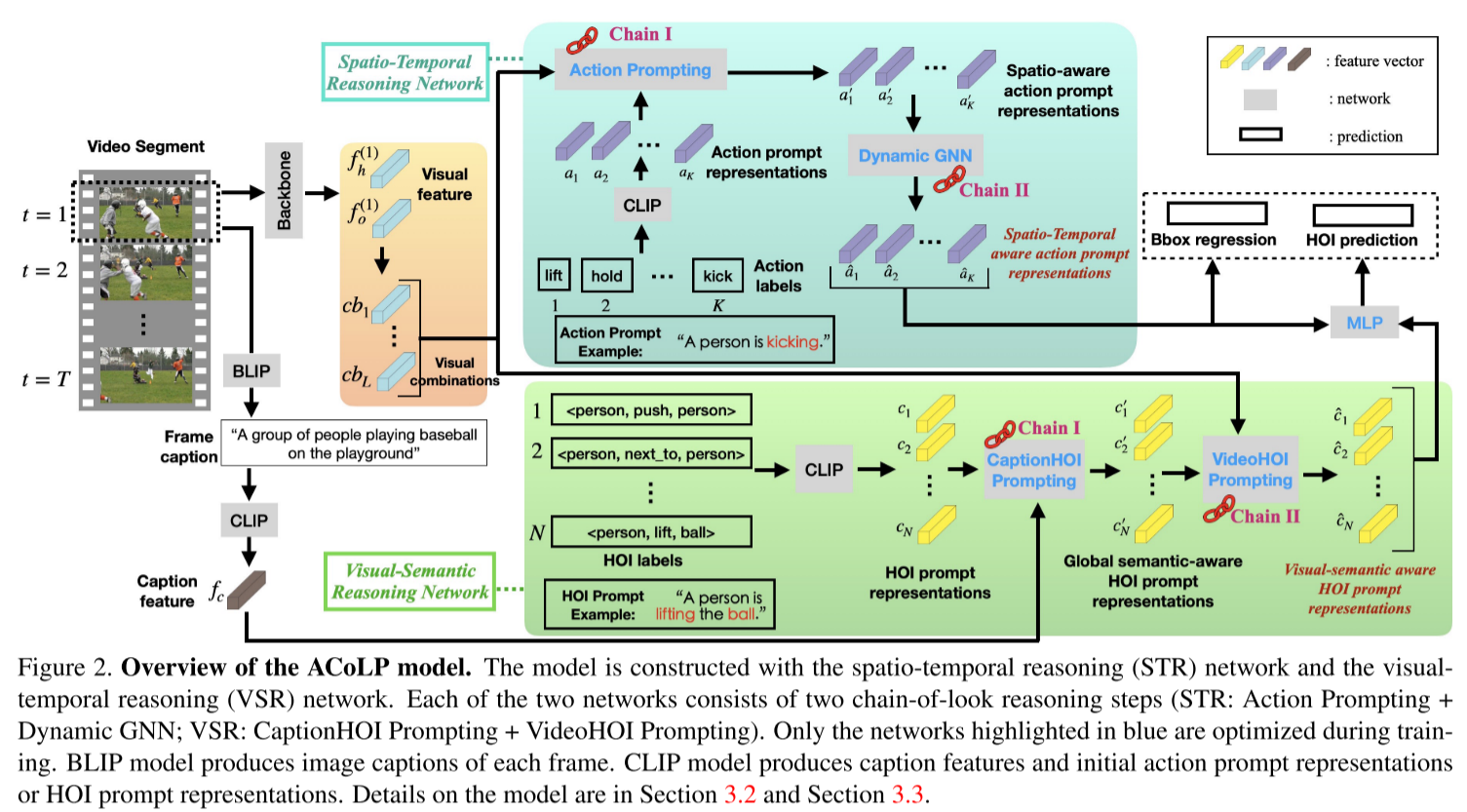
2.1 动作中心的链式视觉提示(Chain-of-Look Prompting)
灵感来源:自然语言处理中的 “思维链”(Chain-of-Thought)提示,将复杂推理分解为中间步骤。

视频 HOI 的视觉推理分解:
视觉语义推理网络(VSR):
CaptionHOI 提示(CHP):利用 CLIP 和 BLIP 生成全局语义提示,融合图像字幕的高层语义(如 “人正在骑自行车”)。
VisualHOI 提示(VHP):通过目标检测提取人机对视觉特征,增强局部视觉信息(如人体姿势、物体位置)。
时空推理网络(STR):
动作提示(AP):将帧级视觉特征抽象为动作提示(如 “推”“拉”),对齐视觉与语义空间。
动态 GNN(D-GNN):建模跨帧动作的时间依赖,传播语义信息以捕捉时序动态(如 “开门” 的连续动作)。
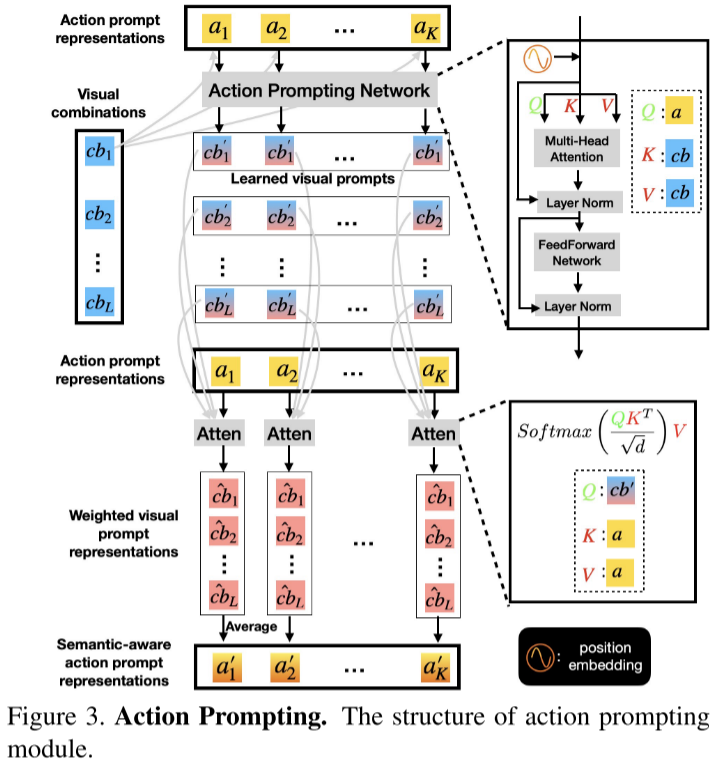
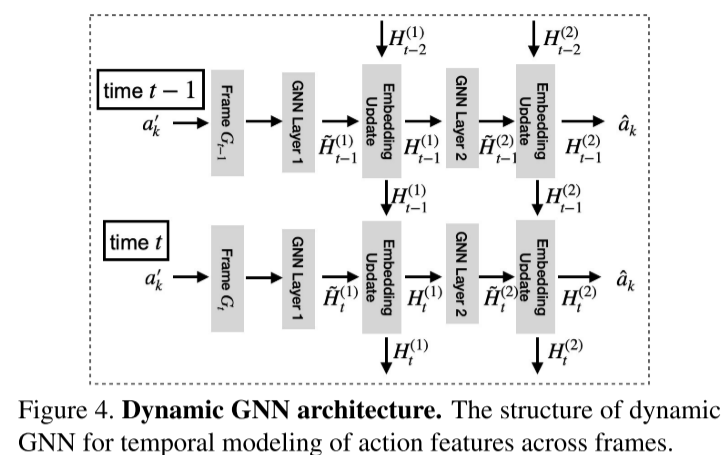
2.2 开放集泛化机制
预训练视觉 - 语言模型(CLIP)的零样本能力:
通过 CLIP 文本编码器生成动作和 HOI 类别的语义嵌入,利用其视觉 - 语言对齐能力识别未见类别。
分层推理链:
通过 CHP→VHP→AP→D-GNN 的链式结构,逐步从全局语义、局部视觉、动作抽象到时空动态,增强泛化性。
2.3 端到端的视频 HOI 检测框架
两阶段流程:
目标检测:使用 Faster R-CNN 提取人机边界框和实例特征。
交互预测:通过 VSR 和 STR 生成动作与 HOI 提示,结合多层感知机(MLP)预测交互类别和边界框。
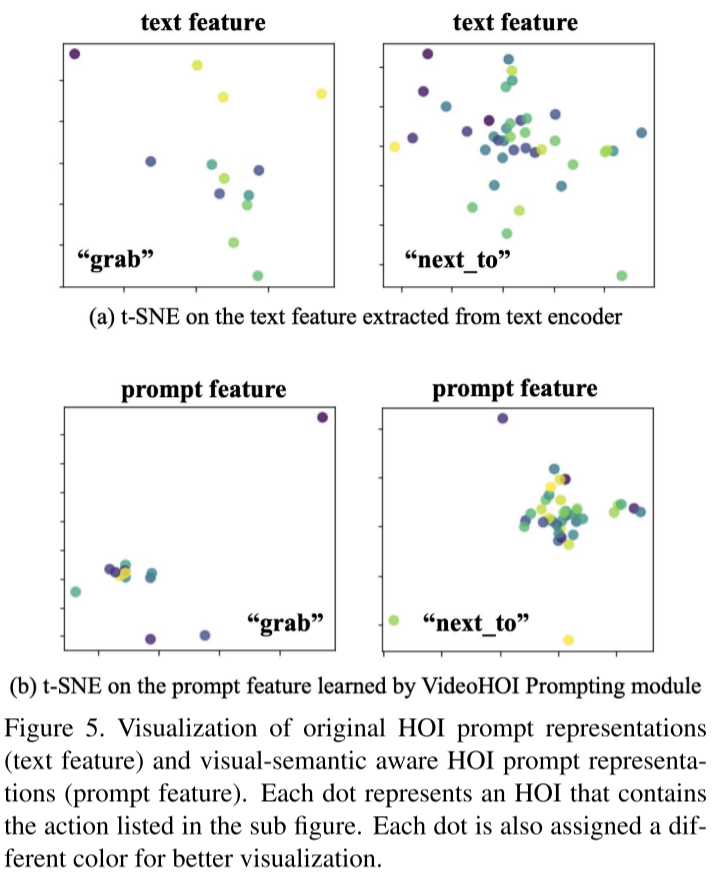
3.实验
3.1 计算要求
100 epochs on 4 GPUs with a batch size of 128(未提及具体显卡类型)
3.2 实验结果
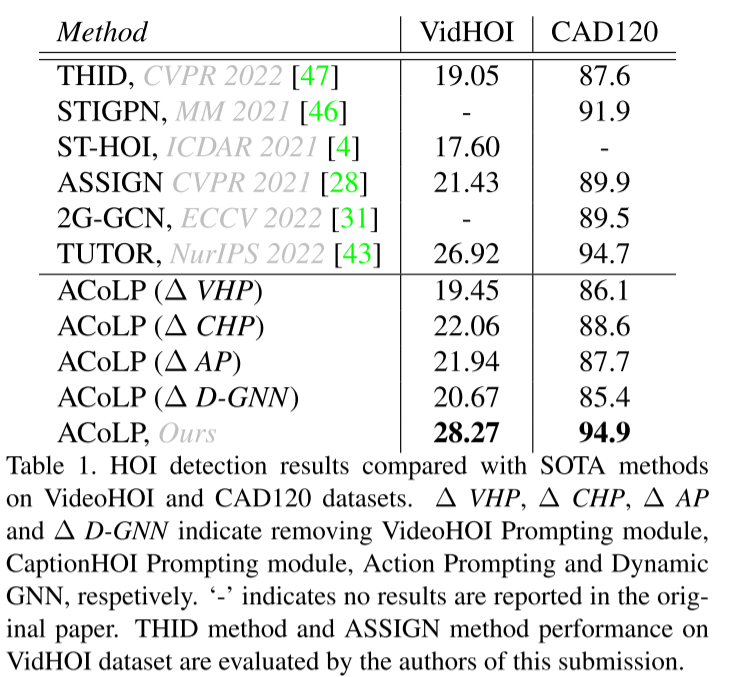

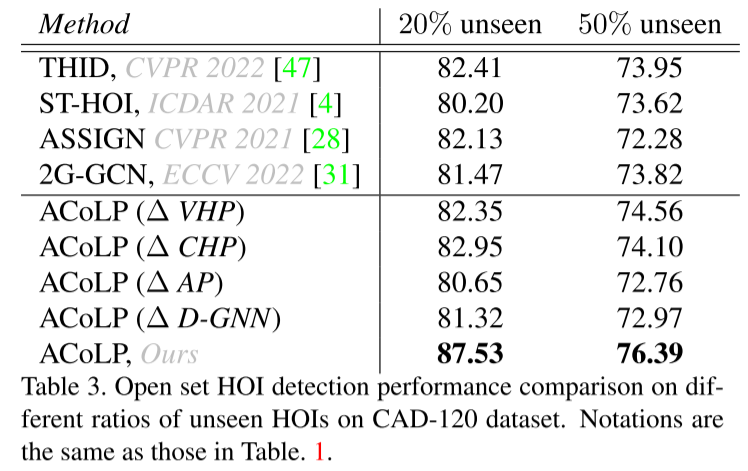

4.结论与展望
4.1 贡献总结
首个开放集视频 HOI 检测模型:通过动作中心的链式提示机制,显式建模动作语义和时序动态。
高效泛化能力:利用 CLIP 的零样本能力和动态 GNN 的时序建模,显著提升未见类别的检测性能。
双模态推理框架:融合全局语义、局部视觉和时空动态,在开放集和封闭集场景均达 SOTA。
4.2 局限与未来方向
局限:对极低频交互(如单样本)泛化能力有限;计算成本较高(依赖预训练模型)。
未来方向:引入动态提示调整机制;探索无锚框的端到端检测;扩展至更长时序的视频片段。