Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路!
我的博客:<但凡.
我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C++修炼之路》

1、引言
在计算机科学中,位图(Bitmap)和布隆过滤器(Bloom Filter)是两种高效的数据结构,广泛应用于海量数据处理、缓存系统、网络路由、垃圾邮件过滤等场景。它们能以极小的空间代价实现快速查询,但各自有不同的特点和适用场景。
本文将详细介绍:
位图(Bitmap)的原理及C++实现
布隆过滤器(Bloom Filter)的原理及C++实现
两者的对比及适用场景
2、位图
2.1、什么是位图
首先大家想这样一个问题,现在给你40亿个无符号整数,怎么快速地判断某一个数是否存在?
思路一:unordered_set存储。
在不考虑效率的情况下,我们首先想一个问题,unordered_set能否存储下40亿个数据?
我们开辟一个unordered_set对象,然后输出他的理论最大值:
#include<iostream>
#include<unordered_set>
using namespace std;
unordered_set<size_t> s;
int main()
{
cout << s.max_size() << endl;
return 0;
}这个理论最大值和系统有关:
(1) 32 位系统
指针大小:4 字节(32 bit)
最大地址空间:232=4,294,967,296232=4,294,967,296(约 4GB)
这是 CPU 能寻址的内存上限,即使物理内存更大,单个进程也无法直接使用超过此限制。
unordered_set::max_size():通常返回 232−1232−1(约 43 亿),因为 STL 容器的最大容量受限于地址空间。
(2) 64 位系统
指针大小:8字节(64 bit)
最大地址空间:264=18,446,744,073,709,551,616264=18,446,744,073,709,551,616(约 16EB,1EB = 10亿GB)
理论上是天文数字,实际受操作系统和硬件限制(如 x86-64 通常用 48 bit 地址,最大 256TB)
unordered_set::max_size():通常返回 264−1264−1(约 1.8×10191.8×1019),因为地址空间足够大。
看似能容下40亿个数据,但是现实情况中真的能存储这么多吗?
首先我们要知道,哈希表中存储的无符号整数类型大约占32到64字节,尽管元素本身只占4个字节,但是我们要存储在哈希表中,每个节点还得包含指向下一个节点的指针。再受内存对齐规则,缓存的哈希值,分配器额外开销的影响,这就导致每个无符号整数会占到32到64字节。再加上我们实际电脑内存首先,假设你的电脑有64g内存,那他最多也只能存储1到2亿个数。这可是远远不够的。
思路二:暴力枚举
这个思路就更不可能了,因为时间复杂度太高,肯定满足不了需求。
思路三:排序加二分
这个思路看似可以,但是也是受内存限制。我们想要存储40亿个数据,那么我们需要开辟的数组大小需要14.90G(大约),受内存限制,假设电脑为16G(当下主流的电脑内存大小),我们光开机系统就已经占用的我们的内存至少%20,那么怎么可能开出来这么大的数组呢?那我们拿个大点的电脑来,64G的,就算他能存下,那么我现在说他能存下400亿个数据吗?这肯定是不可能的。那么有没有一种办法,能够更高效的,不需要大内存空间解决这个问题呢?
接下来介绍我们的主角:位图。
位图(Bitmap),也称为位集合(Bitset),是一种利用二进制位(bit)来高效存储和操作数据的数据结构。它的核心思想是:
每个 bit 表示一个数字是否存在(0 = 不存在,1 = 存在)。
适用于海量无重复整数的存储和查询(如去重、排序、快速查找)。
在位图中,我们每一位就能代表一个数字,如果这一位为1,那么说明这个数字存在,如果为0,就说明这个数字不存在。但是需要注意的是,位图只能存储整数。
2.2、位图的模拟实现
相比于之前的红黑树,哈希表,位图就简单的多了。
template<size_t N>
class bitset
{
public:
bitset()
{
_bs.resize(N / 32 + 1);//开空间
//对于小数,我们要存在下一个int中,所以+1,至于整数,我们为了统一就都+1就可以了,这样最多只浪费了一个int
//也可以这样理解,这样开空间是第一个int下标为1,可以让他这样对应上。
//每一位标记一个数,我们插入N个数据,需要N位,一个int类型有32(4*8)位,所以说得N/32
}
//插入
void set(size_t x)
{
size_t i = x / 32;//确定存在那个int中
size_t j = x % 32;//确定存在哪一位
_bs[i] |= (1 << j);
//x映射改成1
}
//删除
void reset(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bs[i] &= (~(1 << j));
}
bool test(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
return _bs[i] & (1 << j);
}
private:
std::vector<int> _bs;
};核心操作只有三个,插入,删除,判断。
插入操作首先计算这个数应该存放在哪一个区块中,然后把这个数模32,确定他存在哪一位,接着通过二进制运算把他存下来。
删除操作也是先判断删除的数存在哪一位,在通过二进制操作把他改为0。
查找操作也是同理。
现在解决上面的问题就很简单了。开辟空间时我们直接传入-1,开辟出来42亿九千万(约等于)个数据,然后对于给定的四十亿个数据进行set就行了。
传-1是因为size_t类型的参数传-1实际上值就成了(1LL<<32-1),也就是三十二位全是1。这个值我们经常使用。
2.3、C++库中的位图
在C++库中也有一份位图,库中的位图实现的功能更多一些,但是总体来说主要的还是上面这三个。

但是库里面的位图有一个小bug。就是我们开辟空间时不能传-1,如果传-1程序会崩掉。
#include<iostream>
#include<bitset>
using namespace std;
const int INF = (1LL << 32) - 1;
bitset<INF> s;//如果传-1会在运行是崩掉
int main()
{
for (int i = 1;i <= 10000;i++)
{
s.set(i);
}
cout<<s.test(100)<<endl;
return 0;
}2.4、twobitset
现在看这样一个问题:⼀个文件有100亿个整数,1G内存,设计算法找到出现次数不超过2次的所有整数。
如果只有一个位图,我们只能判断他在不在。如果想要记录次数的话我们需要多个位图。
由于他这里次数不超过2,我们使用两个位图,来模拟二进制数就可以了。我们可以通过两个位图记录0,1,10,11这四个数。
template<size_t N>
class twobitset
{
//标记出现次数为0,1,2,3
public:
void set(size_t x)
{
//检测之前出现的次数并对他进行++
bool bit1 = _bs1.test(x);
bool bit2 = _bs2.test(x);
if (!bit1 && !bit2)
{
_bs2.set(x);
}
else if (!bit1 && bit2)
{
_bs1.set(x);
}
else if (bit1 && !bit2)
{
_bs1.set(x);//重新set一次也没事
_bs1.set(x);
}
}
//返回数字
int get_count(size_t x)
{
bool bit1 = _bs1.test(x);
bool bit2 = _bs2.test(x);
if (!bit1 && !bit2)
{
return 0;
}
else if (!bit1 && bit2)
{
return 1;
}
else if (bit1 && !bit2)
{
return 2;
}
else if (bit1 && bit2)
{
return 3;
}
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};测试代码:
void test_twobitset()
{
twobitset<100> tbs;//100为我们要存入的数字的最大值
int a[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6,6,6,6,7,9 };
for (auto e : a)
{
tbs.set(e);
}
for (size_t i = 0; i < 100; ++i)
{
//cout << i << "->" << tbs.get_count(i) << endl;
if (tbs.get_count(i) == 1 || tbs.get_count(i) == 2)
{
cout << i << " ";
}
}
}
void test_bitset1()
{
int a1[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };
int a2[] = { 5,3,5,99,6,99,33,66 };
bitset<100> bs1;
bitset<100> bs2;
for (auto e : a1)
{
bs1.set(e);
}
for (auto e : a2)
{
bs2.set(e);
}
for (size_t i = 0; i < 100; i++)
{
if (bs1.test(i) && bs2.test(i))
{
cout << i << " ";
}
}
}3、布隆过滤器
倘若我们想要判断是否存在的数据不是整形,那么位图就不适用了,我们有没有什么办法来快速判断在大量数据中某一个特定的数据是否存在呢?
3.1、什么是布隆过滤器
布隆过滤器(Bloom Filter)是由 Burton Howard Bloom 在 1970 年提出的一种概率型数据结构,用于高效判断某个元素是否存在于集合中。它的特点是:
空间效率极高(比哈希表更省内存)。
查询速度极快(时间复杂度
O(k),k为哈希函数数量)。存在一定的误判率(可能误判“存在”,但不会误判“不存在”)。
也就是说,布隆过滤器如果判断一个元素存在,那么这个判断可能不准确,但是如果判断某个元素不存在,这个元素是一定不存在的,也就是判断是准确的。那么为什么布隆过滤器会有这样的缺点呢?
布隆过滤器的工作原理是把一个数据,通过多个不同的哈希函数,映射到位图中。
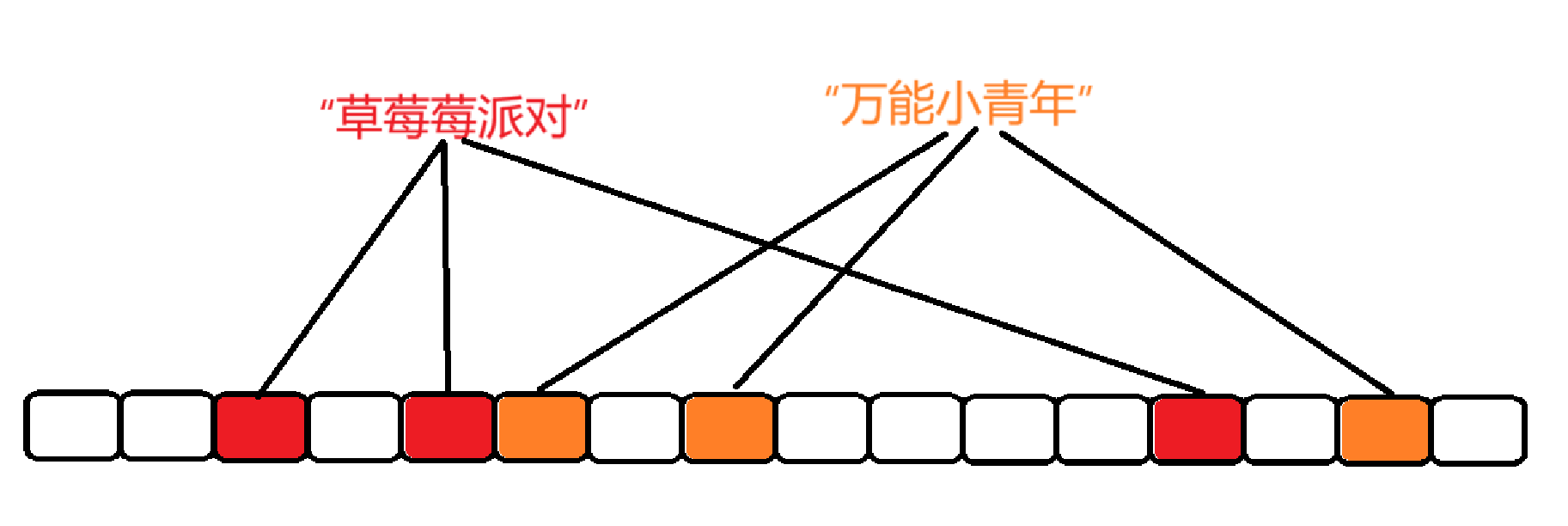
那么假设我们存储了图中两个值,假如现在来了第三个元素,我们想要检测第三个元素在不在,这第三个元素映射的三个值恰好和已经存在的两个值有重合,那么此时的判断就成了存在,固然是不准确的。
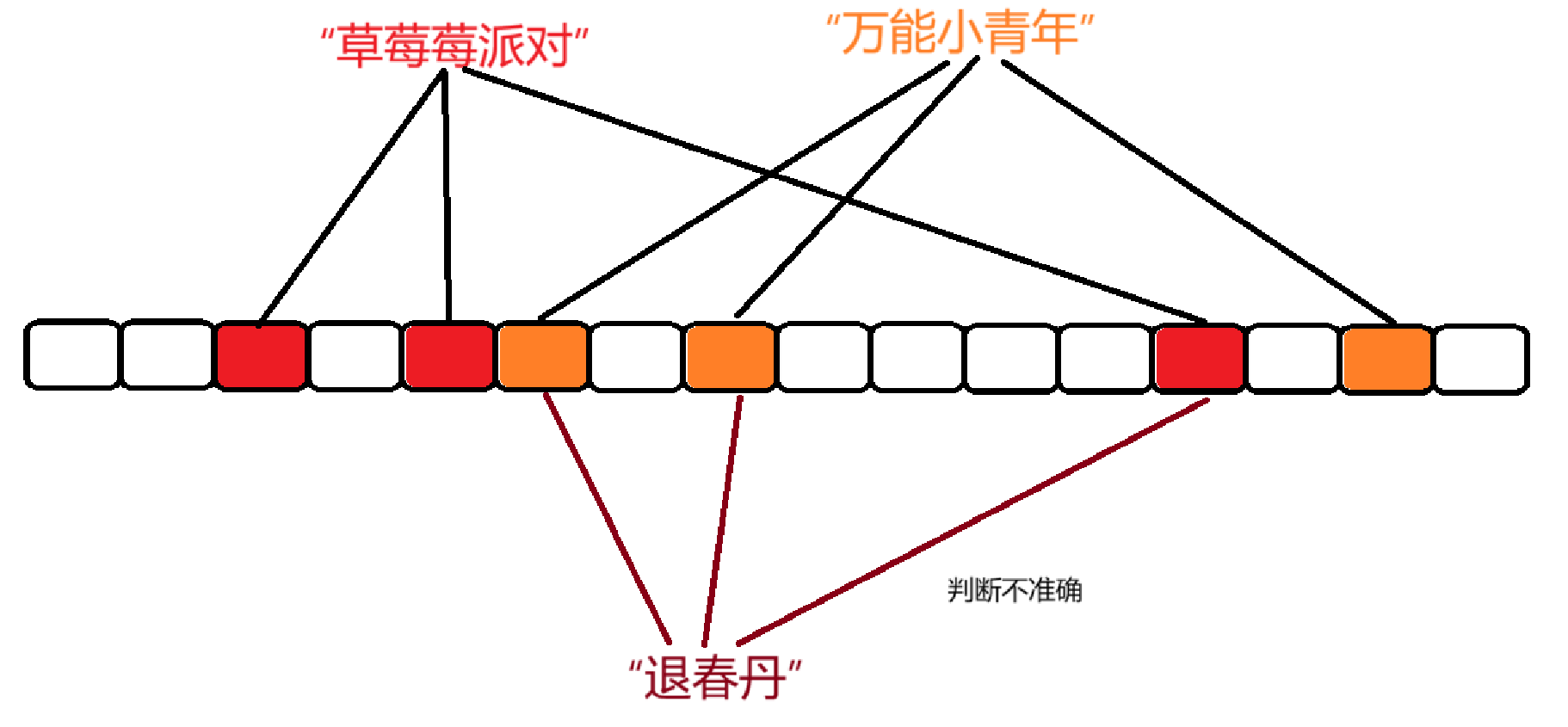
并且这种哈希冲突是无法解决的,我们只能通过合理使用哈希函数,尽可能降低哈希冲突。
3.2、布隆过滤器的误导率
这部分内容有几个公式,至于这些公式怎么推出来的大家如果感兴趣的话可以自己搜索一下,公式的推导对数学功底有一定要求。
布隆过滤器的误判率:
在k一定的情况下,当n增加时,误判率增加,m增加时,误判率减少。
当 时,误判率最低。
期望的误判率p和插入数据个数n确定的情况下,再把上面的公式带入误判率公式可以得到,通过期望的误判率和插入数据个数n得到bit长度:
3.3、布隆过滤器的代码实现
我们选取三个比较权威的哈希函数来实现布隆过滤器。需要注意的是我们实现布隆过滤器用的是上面我们自己实现的位图,不是库里的。
#pragma once
#include"BitSet.h"
#include<string>
struct HashFuncBKDR
{
// @detail 本 算法由于在Brian Kernighan与Dennis Ritchie的《The CProgramming Language》
// 一书被展示而得 名,是一种简单快捷的hash算法,也是Java目前采用的字符串的Hash算法累乘因子为31。
size_t operator()(const std::string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash *= 31;
hash += ch;
}
return hash;
}
};
struct HashFuncAP
{
// 由Arash Partow发明的一种hash算法。
size_t operator()(const std::string& s)
{
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0) // 偶数位字符
{
hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));
}
else // 奇数位字符
{
hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));
}
}
return hash;
}
};
struct HashFuncDJB
{
// 由Daniel J. Bernstein教授发明的一种hash算法。
size_t operator()(const std::string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash = hash * 33 ^ ch;
}
return hash;
}
};
template<size_t N,size_t X=6,class K=std::string,class Hash1=HashFuncBKDR,class Hash2=HashFuncAP,class Hash3=HashFuncDJB>
class BloomFilter
{
public:
//插入
void Set(const K& key)
{
//调用临时对象的()
size_t hash1 = Hash1()(key) % M;
size_t hash2 = Hash2()(key) % M;
size_t hash3 = Hash3()(key) % M;
//通过三种映射方式映射出三个值,然后set到图里面
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
bool Test(const K& key)
{
size_t hash1 = Hash1()(key) % M;
if (!_bs.test(hash1))
{
return false;
}
size_t hash2 = Hash2()(key) % M;
if (!_bs.test(hash2))
{
return false;
}
size_t hash3 = Hash3()(key) % M;
if (!_bs.test(hash3))
{
return false;
}
return true;
}
double getFalseProbability()
{
//套公式计算冲突率
double p = pow((1.0 - pow(2.71, -3.0 / X)), 3.0);
return p;
}
private:
static const size_t M = N * X;
bitset<M> _bs;
};
void TestBloomFilter2()
{
//如果插入长的字符,在检测这个字符的子串,可能会误判
srand(time(0));
const size_t N = 1000000;
BloomFilter<N> bf;
//BloomFilter<N, 3> bf;
//BloomFilter<N, 10> bf;
std::vector<std::string> v1;
std::string url = "猪八戒";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.Set(str);
}
// v2跟v1是相似字符串集(前缀一样),但是后缀不一样
v1.clear();
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to_string(9999999 + i);
v1.push_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v1)
{
if (bf.Test(str)) // 误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集 前缀后缀都不一样
v1.clear();
for (size_t i = 0; i < N; ++i)
{
//string url = "zhihu.com";
string url = "孙悟空";
url += std::to_string(i + rand());
v1.push_back(url);
}
size_t n3 = 0;
for (auto& str : v1)
{
if (bf.Test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
cout << "公式计算出的误判率:" << bf.getFalseProbability() << endl;
}通过测试代码可以打得出我们的理论误判率和实际误判率是非常接近的。
默认的布隆过滤器不支持删除。因为在两个元素映射的值有冲突的情况下,删除一个元素就会影响另一个元素。
3.4、布隆过滤器的应用场景
布隆过滤器有很多应用场景,我们简单说两个。首先是数据库查询优化。我们可以通过数据库,优化磁盘查询时间。在查询前先用布隆过滤器判断数据是否可能存在于磁盘,若过滤器返回“不存在”,则直接跳过磁盘访问。
另外布隆过滤器可以做缓存穿透防护。当有人恶意请求大量不存在的 key时,会导致缓存失效,直接冲击数据库。我们可以用布隆过滤器把所有合法的key存储起来,请求key时,现在布隆过滤器中判断此key是否存在。
布隆过滤器还有很多使用场景,不一一列举了,感兴趣的可以自己搜索一下:
| 场景 | 核心需求 | 为什么用布隆过滤器? |
|---|---|---|
| 数据库查询优化 | 减少磁盘 IO | 快速过滤不可能存在的 key |
| 缓存穿透防护 | 防止恶意请求击穿数据库 | 内存高效,查询速度快 |
| 爬虫 URL 去重 | 避免重复抓取 | 节省内存,比哈希表更省空间 |
| 垃圾邮件过滤 | 快速拦截已知垃圾邮件 | 比传统黑名单更高效 |
| 大数据去重 | 流式数据去重 | 低内存占用,适合高吞吐场景 |
| CDN 边缘缓存 | 减少回源查询 | 快速判断内容是否在中心服务器 |
好了,今天的内容就分享到这,我们下期再见!