数据库设计基础知识
8.1 数据库基础概念
数据模型
数据模型三要素:数据结构、数据操作、数据的约束条件。其中数据的约束条件包括:实体完整性、参照完整性、用户自定义完整性。数据库三级模式两级映像
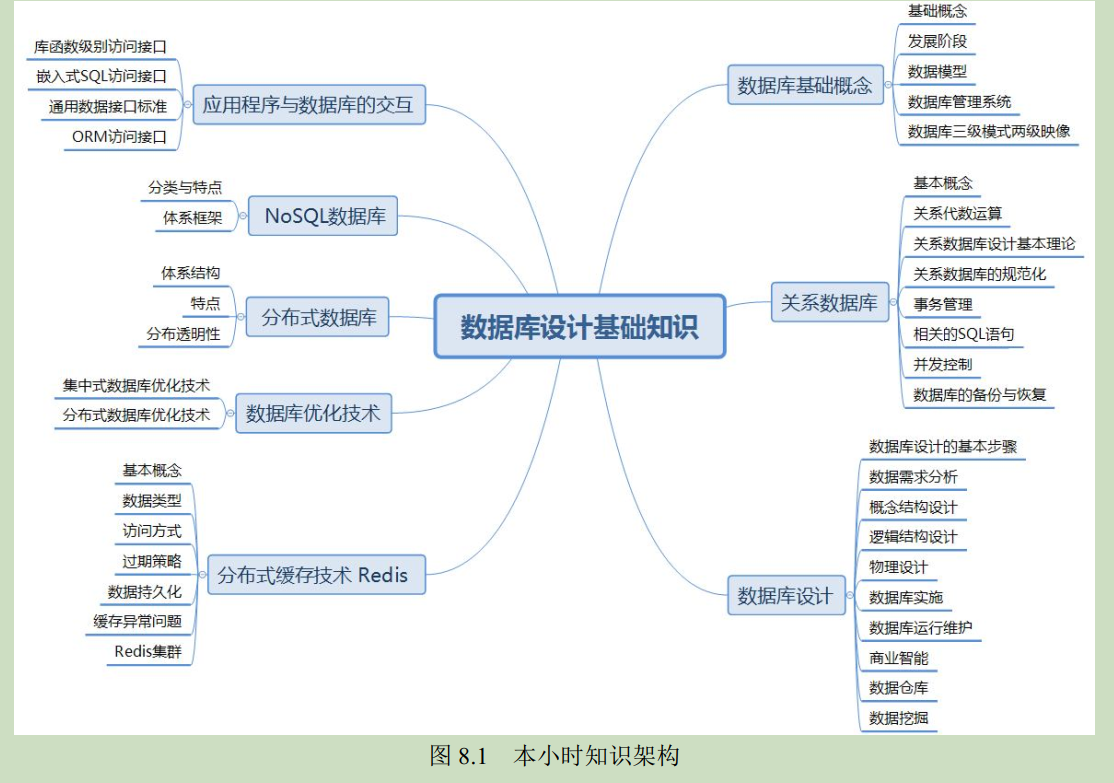
数据库一般采用三级模式,体系结构如下图,系统开发人员需要通过视图层、逻辑层和物理层上个层次上的抽象来降低用户屏蔽系统的复杂性,简化用户与
系统的交互。从数据库管理系统的角度,数据库也分为外模式、概念模式和内模式。
数据库系统子三级模式之间提供了两级映像:概念模式/内模式映像、外模式/概念模式映像。这两级映像保证了数据库中的数据具有较高的
逻辑独立性
和物理独立性。
数据库的三级模式:
| 概念模式 | 外模式 | 内模式 |
|---|---|---|
| 是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图 | 又叫子模式或用户模式,用户根据外模式用数据操作语句或应用程序去操作数据库中的数据 | 是数据物理结构和存储方式的描述, |
| 用以描述用户看到或正在使用的那部分数据的逻辑结构, | 是数据在数据库内部的表示方式,定义所有的内部记录类型、索引和文件的组织方式等 。 |
数据库的两级映像
| 逻辑独立性 | 物理独立性 |
|---|---|
| 对应外模式和概念模式之间的映像。指应用程序与数据库中的逻辑结构独立,当数据的逻辑结构改变时,应用程序不变 | 对应概念模式和内模式之间的映像, 指应用程序与磁盘中的数据互向独立,当数据的物理结构改变时,应用程序不变 |
8.2关系数据库
- 属性(Attribute)
- 域(Domain)
- 目或度(Degree)
- 候选码(Candidate Key)
- 主码(Primary Key)
- 主属性(Primary Attribute)
- 外码(Foreign Key)
- 全码(All-key)
关系代数
π 投影 选择对应的列表
σ 选择 获取符合条件的行
- 关系数据库设计的基本理论
-
- 函数依赖:
-
- 非平凡的函数依赖
-
- 平凡的函数依赖
-
- 完全函数依赖
-
- 部分函数依赖
-
- 传递依赖
- 关系数据库的规范化
-
- 第一范式:列不可再分
-
- 第二范式:不存在非主属性的完全依赖
-
- 第三范式:不存在非主属性的传递依赖
-
- BCNF:不存在主属性的传递依赖和完全依赖
- 事务管理
原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
8.3 数据库设计
- 数据库设计的基本步骤。可以分为用户需求分析、概念结构设计、逻辑结构设计、物理结构设计、应用程序设计、运行维护。
- 数据需求分析
- 概念结构设计。概念数据模型又称为实体-联系模型,它按照用户的观点来对数据和信息建模,主要用于数据库设计,概念结构设计的工作步骤包括:选择局部应用、
逐一设计分ER图和ER图合并。 在进行ER图合并时,需要解决属性冲突、命名冲突和结构冲突。ER图三要素:实体、属性、实体之间的联系。 - 逻辑结构设计。主要步骤包括确定数据模型、将ER图转化为指定的数据模型、确定完整性约束和确定用户视图。
- 物理设计。主要步骤确定数据分布、存储结构和访问方式
- 数据库实施。根据逻辑和物理设计的结果,在计算机上建立实际的数据库结构,数据加载(装入),进行试运行和评价。
- 数据库运行维护。主要包括对数据库性能的监测和改善、故障恢复、数据库的重组和重构。在数据库运行阶段,对数据库的维护主要由DBA完成。
- 商业智能(Business Intelligence ,BI)是企业对商业数据的搜集、管理和分析的系统过程,目的是使企业的各级决策者获得知识或洞察力,帮助他们作出
对企业更有利的决策。一般认为数据仓库、联机分析处理(OLAP)和数据挖掘是商业智能的三大组成部分。 - 数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定且随时间变化的数据集合,用于支持管理决策。
数据仓库的关键特征是:面向主题、集成的、非易失的、时变的、
传统数据库和数据仓库的比较
| 比较项目 | 传统数据库 | 数据仓库 |
|---|---|---|
| 数据内容 | 当前值 | 历史的、归档的、归纳的、计算的数据(处理过的) |
| 数据目标 | 面向业务操作程序 、重复操作 | 面向主题域,分析应用 |
| 数据特性 | 动态变化、 更新 | 静态、不能直接更新,只能定时添加,更新 |
| 数据结构 | 高度结构化、复杂、适合操作计算 | 简单、适合分析 |
| 使用频率 | 高 | 低 |
| 数据访问量 | 每个事务只访问少量记录 | 每个事务访问大量记录 |
| 对相应时间要求 | 计时单位小 如秒 | 计时单位大 ,秒、分钟 、小时 |
OLTP和OLAP的区别
| 项目 | OLTP | OLAP |
|---|---|---|
| 用户 | 操作人员、低层管理人员 | 决策人员、高级管理人员 |
| 功能 | 日常操作处理 | 分析决策 |
| DB设计 | 面向应用 | 面向主题 |
| 数据 | 当前的、最新的、细节的、二维的、分立的 | 历史的、聚集的、多维的、集成的、 统一的 |
| 存取 | 读/写数十条记录 | 读上百万条记录 |
| 工作单位 | 简单的事务 | 复杂的查询 |
| 用户数 | 上千个 | 上百个 |
| DB大小 | 100MB甚至GB级别 | 100GB甚至TB级别 |
- 数据挖掘。数据挖掘是在没有明确的假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先知、有效和实用三个特征。
8.4 应用程序与数据库交互
NoSQL数据库
- 分类和特点
NoSQL数据库按照所使用的数据结构的类型,可以分为列式存储数据库、键值对存储数据库、文档型数据库、图数据库。
NoSQL特征:易扩展、大数据量、高性能、灵活的数据模型、高可用。 - 体系结构
NoSQL整体框架由下至上分为数据持久层(Data Persistence)、数据分布层(Data Distribution Model)、数据逻辑层(Data Logic
Model) 和接口层(Interface)。
NoSQL数据库适用情况:数据模型比较简单、需要灵活性更强的IT系统、对数据库性能要求较高、不需要高度的数据一致性。
8.6 分布式数据库
- 体系结构
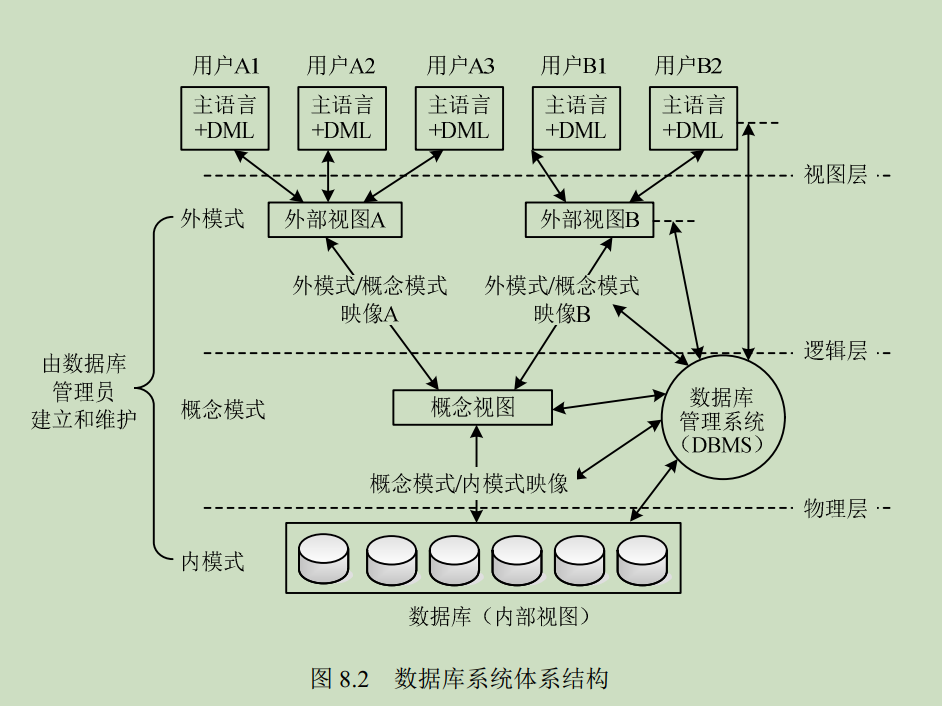
-
- 全局视图:(全局外模式)是全局应用的用户视图,是全局概念模式的子集,该层直接与用户(或应用程序)交互。
-
- 全局概念模式:全局概念模式定义分布式数据库中数据的整体逻辑结构,数据就如同没有分布意义,可用传统的集中式数据库中所采用的方法进行定义。
-
- 分片模式:将一个关系模式分解为几个数据片
-
- 分配模式:分布式数据库的本质特性就是数据分布在不同的物理位置。分配模式的主要职责是定义数据片段(即分片模式的处理结果)的存放节点。
-
- 局部概念模式:局部概念模式是局部数据库的概念模式。
-
- 局部内模式:就是局部数据库的内模式
- 特点
-
- 共享性:不同节点的数据共享
-
- 自治性:每个节点对本地数据都能独立管理
-
- 可用性:某一场地故障时,可以使用其他场地上的副本而不至于使整个系统瘫痪
-
- 分布性: 数据分布在不同场地上存储
8.7 数据库优化技术
- 集中式数据库优化技术
-
- 集中式数据库优化技术
集中式数据库性能优化最常见的事反规范化设计,主要包括增加冗余列、增加派生列、重新组表、水平分割、垂直分割表。
反规范化设计的主要优点是避免了进行行表之间的连接操作, 从而提高数据操作的性能;缺点还是会造成数据的重复存储,浪费了磁盘空间,会产生数据不一致的问题。
若要避免数据不一致的问题,可以通过设置触发器、采用事务机制(适用于单体数据库中)、应用保证(适用于异构数据库之间)以及批处理脚本方式。
- 集中式数据库优化技术
- 分布式数据库优化技术
分布式数据库的性能优化可以采用主从复制、读写分离、分表、分库等技术。
-
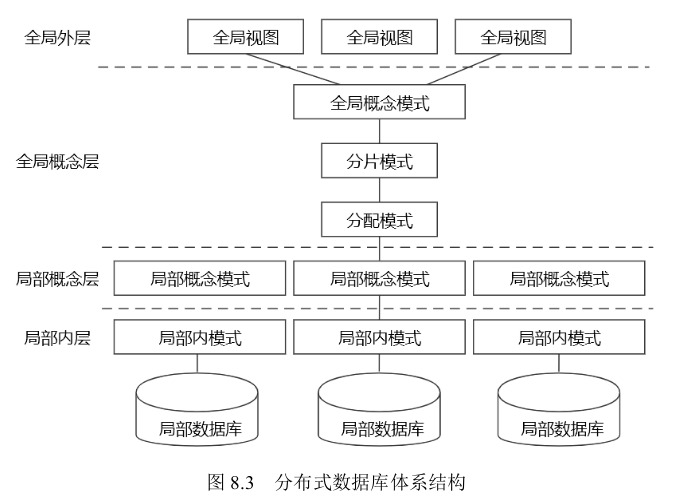
主从复制: 好处做数据的热备。架构的扩展。读写分离。在Mysql数据库中,主从数据库同步的模式有全同步、半同步、异步三种。主从数据库通过binlog进行数据的同步。具体如下图
基于binlog日志有三种模式:
- 基于SQL语句的复制:每一条更新语句(insert、update、delete)都会在binlog中,进而同步到从库的relaylog中,被从库的SQL线程取出来,回放执行。
该模式的优点是binlog的日志量可能会比较少,比如涉及行数一千条数据,同步这一句sql就同步了1000条数据。缺点是同步的SQL里面如果含有绑定本地变量的函数、
关键,可能造成主从不一致的情况。 - 基于行的复制:不记录SQL语句,只记录哪个记录更新前和更新后的数据,可以保证主从数据的绝对相同。缺点是:1条SQL更新100条数据,就需要同步100条数据行。
- 混合复制:以上两种模式的混合,选取两者的优点。对于绑定本地特性、评估可能造成主从不一致的SQL语句,则自动选用基于行的复制,其他的选择基于SQL语句复制。
-
- 读写分离:设置不同的主从数据库分别负责不同的操作。让主数据库负责数据的写操作,从数据库负责数据的读操作。通过角色分担的策略,分别提升读写性能,
有效减少数据并发操作的延迟。
- 读写分离:设置不同的主从数据库分别负责不同的操作。让主数据库负责数据的写操作,从数据库负责数据的读操作。通过角色分担的策略,分别提升读写性能,
-
- 分表:可以提升数据库并发以及I/O的性能。分表重在单个实例内部,将一个大表分为若干小表,业务内访问多个表。分表有两种方式。垂直切分、水平切分。
-
- 分库:分库是将原本存放在一个实例上的众多分类的数据表,分开存放到不同的实例上。有利于差异化管理。
8.8 分布式缓存技术Redis
过期策略:
定期删除、惰性删除
淘汰策略:
数据持久化 AOF| RDB
| 项目 | RDB内存快照(Redis Data Base) | AOF日志(Append Only File) |
|---|---|---|
| 说明 | 把当前内存中的数据集快照写入到磁盘(数据库中的所有的数据)。恢复时是将快照文件直接读到内存中。 | |
| 通过持续不断的保存Redis服务器所执行的更新命令来记录数据库的状态。恢复的时候需要从头开始回放更新命令 | ||
| 磁盘刷新频率 | 低 | 高 |
| 文件大小 | 小 | 大 |
| 数据恢复效率 | 高 | 低 |
| 数据安全 | 低 | 高 |
- 缓存穿透: 大量请求访问了没有缓存的key,即大量key不在redis,从而导致请求直接访问数据库,数据库压力增大。可能原因:
-
- 恶意攻击, 造成大量访问不存在的key。解决方案,1.针对比较少的请求来源IP,主动限制其访问次数,或者拉入黑名单。2.应用程序来检查key的合法性,提前
拒绝不合法请求。3.使用布隆过滤器
- 恶意攻击, 造成大量访问不存在的key。解决方案,1.针对比较少的请求来源IP,主动限制其访问次数,或者拉入黑名单。2.应用程序来检查key的合法性,提前
-
- 大量请求访问数据库里有但是Redis里面没有的key。解决方案:1. 预热Redis,运行一个批处理脚本,将可能会大量访问的数据预先加载到Redis。2.在最前端
进行流量控制,逐步把请求释放进来。给出一段时间,让Redis逐步加载数据。3.如果是Redis里面也没有的key,也要在Redis设置key,使其值为null或空。
- 大量请求访问数据库里有但是Redis里面没有的key。解决方案:1. 预热Redis,运行一个批处理脚本,将可能会大量访问的数据预先加载到Redis。2.在最前端
- 缓存雪崩。大量请求访问到缓存中的key,这些key是存在的,但同时到了过期时间,从而导致请求直接访问数据库,数据库压力增大。缓存雪崩可能进而影响一系
列的雪崩,影响上下游所有的应用服务。可能的原因如下:
-
- Redis故障。比如Redis宕机,网络出现抖动等。
解决方案:1.使用主从复制提高可用性,使用cluster集群方案降低故障的影响范围;2.如果出现故障,则可以采用服务降级、熔断、限流等措施。
- Redis故障。比如Redis宕机,网络出现抖动等。
-
- 大量的key采用了相同的过期时间,例如在同一时刻设置了大量的key,但过期时间都是5分钟。
解决方案:过期时间加上一个随机值,使众多key均匀过期。
- 大量的key采用了相同的过期时间,例如在同一时刻设置了大量的key,但过期时间都是5分钟。
缓存击穿。少量热点的key缓存失效了,使得请求直接访问数据库。
可能原因:热点key设置了太短的过期时间。例如秒杀业务的库存数量。解决方案:1.将key设置较长的过去时间。对于非常重要的key则设置永久有效。但需要解决好与数据中key的一致性问题,2.使用分布式锁。如果热点key失效了控制好后段数据库的流量。只允许一个请求去访问数据库,取出最新的key存放到Redis,其他请求则必须等待。Redis 集群
主从复制集群、哨兵集群、Cluster集群。