多分类与多标签分类算法
在机器学习领域,分类任务是核心问题之一。根据预测目标的性质,主要分为单标签分类(包括二分类和多分类)和多标签分类。本文将基于核心课件内容,系统阐述这些算法的原理、策略及实现。
一、单标签分类问题
1. 单标签二分类
- 定义:每个样本仅属于两种互斥类别之一(如 A/B),需预测单个二值标签。
- 核心思想:在特征空间中构建决策边界(如线、面、超平面)分离两类样本。
- 经典算法:
- Logistic 回归(概率化线性分类)
- SVM(最大化分类间隔)
- KNN(基于邻近样本投票)
- 决策树(基于特征规则划分)
2. 单标签多分类
- 定义:每个样本属于 K 种互斥类别之一(K ≥ 3),需预测单个多值标签。
- 经典算法:Softmax 回归(逻辑回归的多类推广)、KNN、决策树。
- 核心策略:将多分类问题转化为多个二分类子问题求解:
- One-Versus-One (OvO)
- 原理:对 K 个类别进行两两组合,为每对类别 (A, B) 训练一个二分类器。共需训练
K(K-1)/2个分类器。 - 预测:对测试样本运行所有分类器,采用多数投票决定最终类别。
- 优点:每个分类器仅使用涉及的两个类别的数据,训练数据规模较小。
- 缺点:分类器数量随 K 急剧增长,预测开销大。
- 原理:对 K 个类别进行两两组合,为每对类别 (A, B) 训练一个二分类器。共需训练
- One-Versus-Rest (OvR / One-Vs-All)
- 原理:为每个类别 i 训练一个二分类器。将类别 i 作为正例,其余所有类别作为反例。共需训练
K个分类器。 - 预测:对测试样本运行所有 K 个分类器:
- 若仅有一个分类器输出“正例”,则预测为该类。
- 若多个分类器输出“正例”,选择置信度最高(如预测概率最大)的类别。
- 优点:分类器数量少(仅 K 个)。
- 缺点:训练每个分类器时正反例样本量极不均衡(1类 vs K-1类),可能影响性能。
- 原理:为每个类别 i 训练一个二分类器。将类别 i 作为正例,其余所有类别作为反例。共需训练
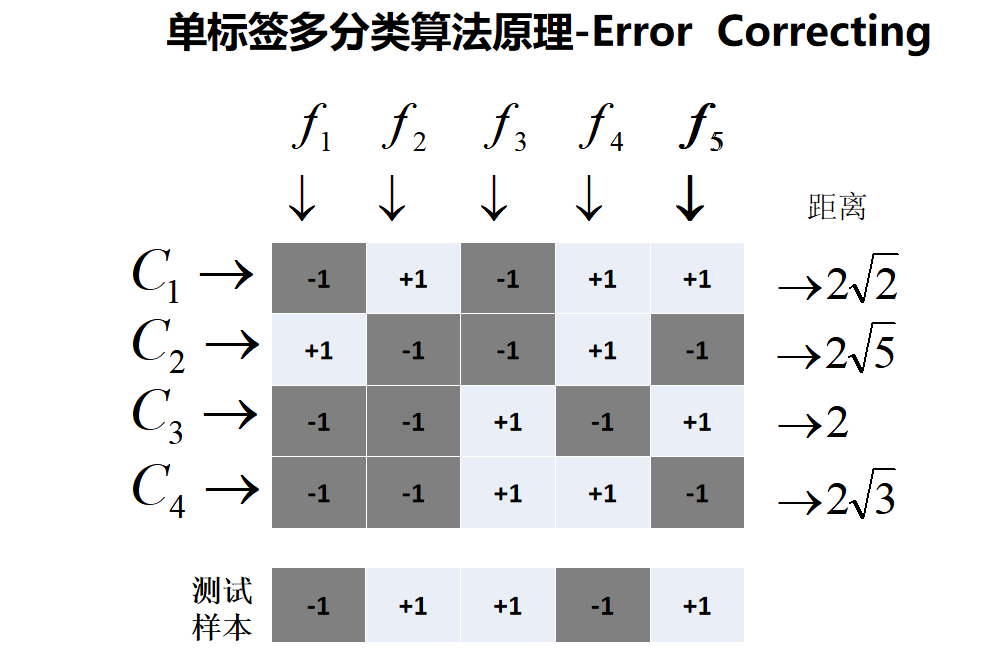
- 纠错输出码 (Error Correcting Output Codes, ECOC)
- 原理:包含两个阶段:
- 编码阶段:对 K 个类别进行 M 次二元划分(每次划分指定部分类为正,部分为反),每次划分训练一个二分类器。每个类别被编码为一个 M 位二进制码字。
- 解码阶段:用 M 个分类器预测测试样本,得到一个 M 位输出码字。计算该码字与每个类别标准码字(如海明距离),预测为距离最近的类别。
- 优点:对分类器错误具有一定容错能力。
- 缺点:设计有效的编码矩阵是关键挑战。
- 原理:包含两个阶段:
- One-Versus-One (OvO)
二、多标签分类问题 (Multi-Label Learning - MLL)
1. 定义与特点
- 每个样本可能同时关联多个标签(如一篇文档可同时属于“科技”、“金融”)。
- 存在两种情况:
- 需要预测多个独立的
y值。 - 一个样本可属于多个不固定类别的组合。
- 需要预测多个独立的
- 关键挑战:标签之间可能存在依赖关系。
2. 解决策略
策略一:问题转换 (Problem Transformation Methods)
- 核心思想:将多标签问题转化为一个或多个单标签(通常是二分类)问题。
- 主要方法:
- 二元关联 (Binary Relevance - BR)
- 原理:为
q个待预测标签中的每一个单独训练一个二分类器。第 i 个分类器判断样本是否属于标签 i。 - 优点:实现简单直观,易于并行化。当标签间独立时效果良好。
- 缺点:完全忽略标签间依赖关系;需训练
q个分类器(当q大时开销大)。
- 原理:为
- 分类器链 (Classifier Chains - CC)
- 原理:将标签按随机顺序排列 (
L1, L2, ..., Lq)。训练时:- 第一个分类器仅用特征
X预测L1。 - 第二个分类器用特征
X加上L1的预测结果作为输入,预测L2。 - 后续分类器依次加入前面所有标签的预测结果作为输入特征。
- 第一个分类器仅用特征
- 预测:按链顺序依次预测每个标签,并将前序预测值输入后续分类器。
- 优点:显式建模了标签间的依赖关系(高阶),通常性能优于 BR。
- 缺点:标签顺序影响结果;依赖关系难以最优确定;预测需按链顺序进行(无法完全并行)。
- 原理:将标签按随机顺序排列 (
- 校准标签排序 (Calibrated Label Ranking - CLR)
- 原理:为每一对标签
(Li, Lj)训练一个分类器,该分类器学习区分样本属于Li而不属于Lj的情况。引入一个额外的“虚拟”标签(Calibrator)作为排序基准。 - 预测:对每个标签
Li,计算它相对于校准标签和所有其他标签的“得分”。根据最终得分对所有标签排序,选择排名靠前的标签作为预测结果(通常设置阈值)。 - 优点:考虑了标签间的两两关系(二阶依赖)。
- 缺点:计算复杂度高(需
O(q²)个分类器);未建模更高阶依赖。
- 原理:为每一对标签
- 二元关联 (Binary Relevance - BR)
策略二:算法适应 (Algorithm Adaptation Methods)
- 核心思想:直接修改或扩展现有的单标签学习算法,使其能原生处理多标签数据。
- 代表算法:
- ML-kNN (Multi-Label k-Nearest Neighbors)
- 原理:基于 kNN 思想。对于一个测试样本:
- 找到其在特征空间中的
k个最近邻样本。 - 统计这些邻居样本的标签集合。
- 对于每个标签
Li,计算其在该邻居集中出现的频率。 - 应用最大后验概率 (MAP) 准则:结合标签的先验概率和邻居条件概率,决定是否将
Li分配给测试样本(通常与阈值比较)。
- 找到其在特征空间中的
- 优点:直观,利用了 kNN 的局部性思想。
- 原理:基于 kNN 思想。对于一个测试样本:
- ML-DT (Multi-Label Decision Trees)
- 原理:扩展决策树算法。关键改进在于分裂准则:
- 不再使用基尼系数或信息增益(针对单标签)。
- 采用多标签专用的度量,如:
- 标签熵的加权和
- 多标签信息增益 (Multi-label Information Gain)
- 基于差异度的度量 (Label-based Division)
- 优点:保持了决策树的可解释性,能处理标签依赖。
- 原理:扩展决策树算法。关键改进在于分裂准则:
- ML-kNN (Multi-Label k-Nearest Neighbors)
三、实现与应用
- scikit-learn 实践:
- 多分类:
OneVsRestClassifier,OneVsOneClassifier包装器可将二分类器(如SVC,LogisticRegression)用于多分类。 - 多标签:
OneVsRestClassifier本身即可用于多标签(每个标签视为独立的二分类任务,即 BR 策略)。ClassifierChain实现分类器链策略。MultiOutputClassifier是另一种实现 BR 策略的包装器。
- 多分类:
- 选择依据:
- 单标签多分类:样本量充足选 OvR;类别数少且追求精度选 OvO;需容错考虑 ECOC。
- 多标签分类:标签独立或
q小用 BR;存在强依赖且q适中用 CC 或 CLR;追求模型原生支持用 ML-kNN 或 ML-DT。
总结
理解和掌握多分类与多标签分类算法是解决现实世界复杂分类问题的关键。单标签多分类策略(OvO/OvR/ECOC)通过问题分解巧妙利用二分类器,而多标签算法则需专门策略(问题转换 BR/CC/CLR 或算法适应 ML-kNN/ML-DT)处理标签间的关联性。在实际应用中,应根据问题特点(类别数、标签独立性、数据规模、性能需求)和数据特性,选择最合适的算法或策略组合。