1. HTTP常见状态码有哪些?
- 1xx 类状态码属于提示信息,是协议处理中的一种中间状态,实际用的比较少。
- 2xx 类状态码表示服务器成功处理了客户端的请求。
- 3xx 类状态码表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
- 4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
- 5xx 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
常见:
- 200:请求成功
- 301:永久重定向;302:临时重定向
- 404:无法找到此页面;405:请求的方法类型不支持
- 500:服务器内部出错
2. MySQL事务特性是什么?怎么实现的?
- 原子性(Atomicity):事务中的所有操作要么全部完成,要么全部回滚。
- 一致性(Consistency):事务前后,数据处于一致状态(满足约束条件)。
- 隔离性(Isolation):并发事务之间互不干扰,每个事务都想自己在独立执行。
- 持久性(Durability):一旦事务提交,修改就会永久保存,即使系统宕机也能恢复。
- 原子性通过 Undo Log(回滚日志)实现:每执行一条 DML (增删改)语句,InnoDB 会将数据变更前的状态写入 Undo Log,如果事务失败或调用了 ROLLBACK,InnoDB 就会根据 Undo Log 进行回滚。
- 一致性依靠原子性 + 隔离性 + 约束:回滚保证事务要么成功要么失败,隔离性避免脏读,外键、唯一约束等在事务开始前就要满足。
- 隔离性通过 MVCC(多版本并发控制)和锁机制实现:支持四种隔离级别,通过 MVCC(快照读)实现读操作并发不加锁,保证效率;加锁机制保证写操作不冲突,如行锁、间隙锁、意向锁等。
- 持久性通过 Redo Log(重做日志):当事务提交时,修改数据的操作会写入 Redo Log,如果数据库宕机,在重启时可以用过 Redo Log 恢复未同步的数据页,确保事务持久性。
3. Java线程池的核心参数有哪些?
线程池是为了减少频繁的创建线程和销毁线程带来的性能损耗,原理如下图:
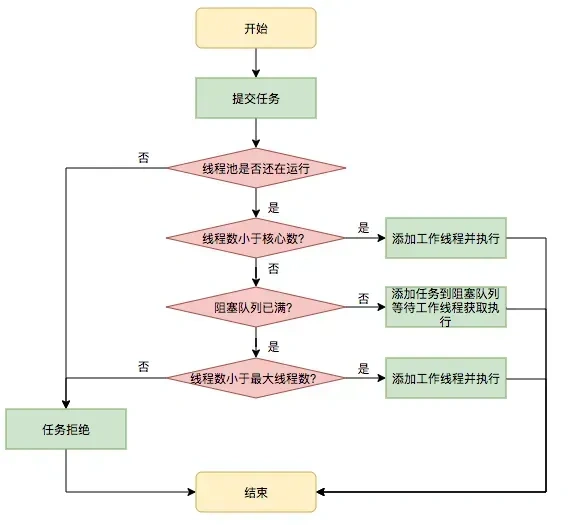
当我们提交任务时,线程池会优先使用核心线程处理任务;如果核心线程已满,则尝试将任务放入任务队列中;若队列也满了,则判断是否还能创建非核心线程(总线程数未达到最大值),若可以就创建新线程处理任务;如果线程数已达到最大,任务将根据设置的拒绝策略进行处理(如抛异常、丢弃、调用者执行等)。执行完的线程不会立即销毁,而是等待一定时间以复用,非核心线程若长时间空闲会被回收,从而实现高效的线程管理和资源利用。
new ThreadPoolExecutor()的七个参数:
| 组成 | 作用 |
|---|---|
corePoolSize |
核心线程数,线程池初始化后保持不被回收的线程数 |
maximumPoolSize |
最大线程数,队列满了后允许创建的最大线程数 |
workQueue |
任务阻塞队列(如 LinkedBlockingQueue) |
threadFactory |
线程创建工厂,决定线程命名、优先级等 |
handler |
拒绝策略,当线程池无法处理新任务时的处理方式 |
keepAliveTime |
非核心线程空闲多久会被回收 |
unit |
keepAliveTime 时间的单位 |
4. 数据库翻页(limit)查询时,发现越往后查询越来越慢,为什么?该如何修改SQL能解决?
例如SQL:
SELECT * FROM user ORDER BY id LIMIT 100000, 10;
MySQL 会先扫描前面 100000 条数据,然后丢弃这些数据,再返回第 100001 到 100010 条。这就导致随着 offset 增大,扫描的数据越来越多;性能逐渐下降,慢在“跳过”的那一部分数据上;特别是是数据量大时,响应时间可能成倍增长。
方案一:使用主键或唯一索引做“位置标记”分页,基于上一次的最大 ID 做分页,而不是 OFFSET 跳页。
- 优化后(假设上一页最后一条记录id是100000)
SELECT * FROM user WHERE id > 100000 ORDER BY id LIMIT 10;
扫描和返回的是精确的 10 条;性能稳定,不随着页数增大而下降;非常适合大数据量的“滚动加载”或“上一页/下一页”式分页。方案二:覆盖索引 + 子查询定位 ID。
- 用子查询先取 ID(走索引),再回表查数据
SELECT * FROM user WHERE id IN (SELECT id FROM user ORDER BY id LIMIT 100000, 10);
适用于无法用主键分页的情况。
5. Insert或Update,不用两个语句去分别判断,用一条语句实现存在就更新,否则就插入?
最常用方式:
INSERT ... ON DUPLICATE KEY UPDATE
适用于主键或唯一索引冲突时进行更新。
INSERT INTO 表名 (字段1, 字段2, ...)
VALUES (值1, 值2, ...)
ON DUPLICATE KEY UPDATE 字段1=新值1, 字段2=新值2;
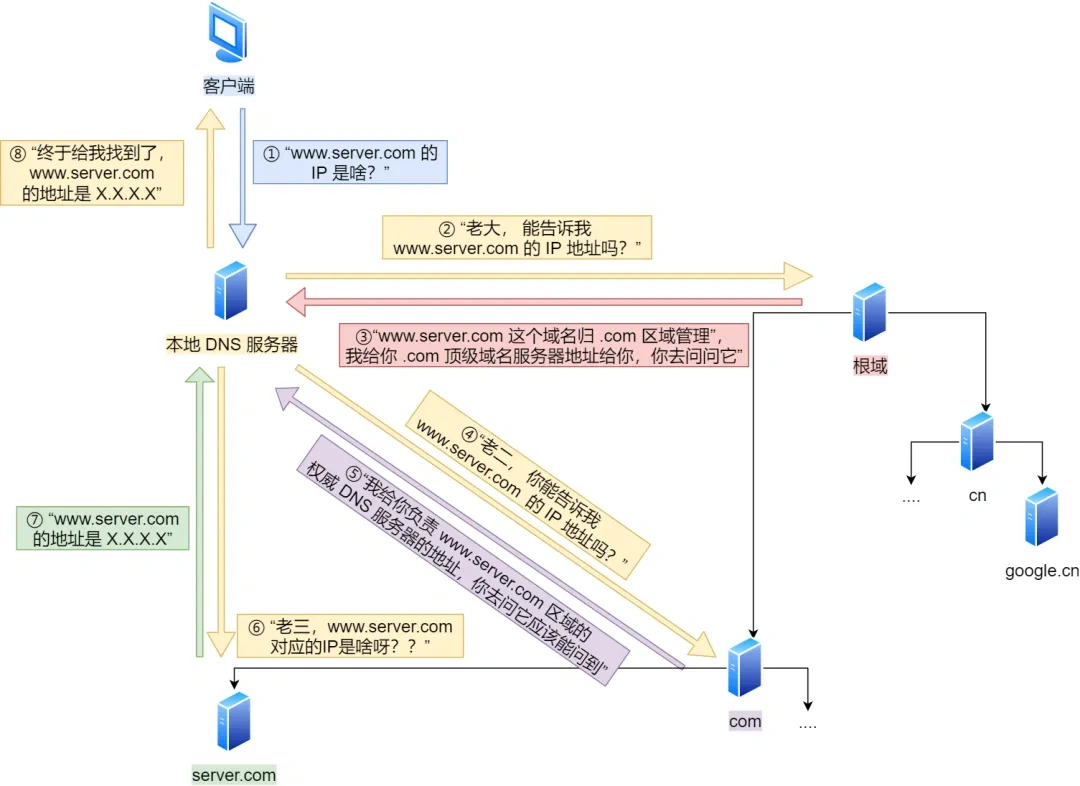
6. DNS基于什么协议实现的?
基于 UDP 协议
- 客户端发起 DNS 请求:客户端向本地 DNS 服务器请求解析
www.server.com,使用 UDP,端口 53。- 本地 DNS 服务器向根域名服务器查询:本地 DNS 发现自己没有
www.server.com的记录,于是向根域名服务器请求(UDP 查询)。- 根服务器响应(返回
.com顶级域服务器地址):根服务器并不直接返回 IP,而是告诉你:“这是 .com 的事,你去问 .com 的 DNS。”- 继续迭代查询:本地 DNS 接着去问
com顶级域服务器:www.server.com是谁?.com顶级域返回一个 权威DNS 服务器地址(比如ns1.server.com)。- 向权威 DNS 服务器询问具体 IP:本地 DNS 向
server.com域的权威服务器发起请求:www.server.com到底啥 IP?权威服务器终于返回了最终的 IP 地址,比如:X.X.X.X。- 本地 DNS 将 IP 返回客户端,客户端就可以访问了。
| 名称 | 英文 | 作用 | 举例 |
|---|---|---|---|
| 1. 本地 DNS 服务器 | Local DNS Resolver | 最先被问,查缓存 | 运营商 DNS,如 114.114.114.114 |
| 2. 根 DNS 服务器 | Root DNS Server | 告诉你“顶级域(TLD)”服务器位置 | 管理 .com、.cn 等 |
| 3. 顶级域名服务器 | TLD DNS Server | 告诉你权威服务器位置 | 比如负责 .com 的服务器 |
| 4. 权威 DNS 服务器 | Authoritative DNS Server | 最终返回目标 IP 地址 | 比如负责 server.com 的服务器 |
7. 为什么是UDP?
因为基于 UDP 实现 DNS 能够提供低延迟、简单快速、轻量级的特性,更适合 DNS 这种需要快速响应的域名解析服务。
- 低延迟:UDP 是一种无连接的协议,不需要在数据传输前建立连接,因此可以减少传输时延,适合 DNS 这种需要快速响应的应用场景。
- 简单快速:UDP 相比于 TCP 更简单,没有 TCP 的连接管理和流量控制机制,传输效率更高,适合 DNS 这种快速传输数据的场景。
- 轻量级:UDP 头部较小,占用较少的网络资源,对于小型请求和响应来说更加轻量级,适合 DNS 这种频繁且短小的数据交换。
8. http的特点是什么?
HTTP 是一种基于文本的应用层协议,通信内容都是人类可读的文本格式,便于开发和调试;它具有良好的可扩展性,支持自定义头部和方法,使得协议可以不断适应新的需求;HTTP 还非常灵活,能够传输各种类型的数据(如 HTML、JSON、图片等),适用于 Web、API 等多种场景;不过它是无状态的,也就是说每次请求之间没有记忆,服务器不会自动记住客户端的信息,因此需要依靠 Cookie 或 Session 等机制来维持用户会话状态。