主成分分析—PCA
一、主成分分析简介
1. PCA概述
主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维方法。它通过线性变换将原始数据变换到一个新的坐标系中,使得第一个坐标(第一主成分)具有最大的方差,第二个坐标(第二主成分)具有次大的方差,以此类推。PCA的目的 是从高维数据中提取出最重要的特征,通过保留最重要的主成分来实现数据的降维,同时尽可能保留原始数据的结构。
数据的方差被最大化,这意味着我们将保留尽可能多的原始数据信息
2. 降维 & PCA
提问:为什么需要降维?作用是什么?
解释:
实际应用中的数据一般是高维的,对于高维的数据很难有直观的认识,如果把数据的维度降低到二维或者三维,并且保证数据点的关系与原高维空间里的关系保持不变或近似,就可以进行可视化,用肉眼来观察数据。数据经过降维以后,如果保留了原有数据的主要信息,那么就可以用降维的数据进行机器学习模型的训练与预测,时间效率也大大增加。
进行降维操作,第一个作用是压缩数据,减少数据量(可能会丢失一定的信息量),使用较少的计算机内存或者磁盘空间;第二个作用是加快学习算法的效率;第三个作用是数据的可视化, 以便对数据进行观察和探索。
3. PCA的优缺点
优点:
- 降低数据维度:PCA算法通过将数据投影到特征子空间中,可以有效地降低原始图像数据的维度,从而减少存储和计算的开销。
- 去除冗余信息:PCA算法通过分析数据的协方差矩阵,可以找到最具代表性的主成分,从而去除了数据中的冗余信息,保留了最重要的特征。
- 提取最显著特征:PCA算法能够将原始数据映射到一个新的低维空间,新空间的特征向量是按照重要性递减的顺序排列的,因此可以提取出最显著的特征,有助于更好地表示和区分人脸特征。
缺点:
- 信息损失:由于PCA算法是通过降维来实现的,这可能会导致一定程度的信息损失。降维过程中舍弃了部分方差较小的特征,可能损失了一些细节信息,从而影响了人脸识别的准确性。
- 敏感性问题:PCA算法对输入数据的质量比较敏感。当输入数据质量较差(如图像的光照、噪声等问题)时,PCA算法可能产生不准确的结果,从而影响识别的效果。
- 计算复杂度:PCA算法需要计算协方差矩阵和特征值分解,涉及到较复杂的数学运算,因此在大规模数据集上的计算会比较耗时。
二、PCA的数学基础
1. 方差
我们知道数值的分散程度,可以用数学上的方差来表述。一个变量的方差可以看做是每个元素与变量均值的差的平方和的均值,即:
V a r ( a ) = 1 m ∑ i = 1 m ( a i − μ ) 2 Var(a)=\frac{1}{m}\sum_{i=1}^{m}\left ( a_{i}-\mu \right )^{2} Var(a)=m1i=1∑m(ai−μ)2
为了方便处理,我们将每个变量的 均值都化为 0 ,因此方差可以直接用每个元素的平方和除以元素个数表示:
V a r ( a ) = 1 m ∑ i = 1 m a i 2 Var(a)=\frac{1}{m}\sum_{i=1}^{m}a_{i}^{2} Var(a)=m1i=1∑mai2
于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
2. 协方差矩阵
在PCA中,协方差矩阵是一个关键的数学工具。协方差矩阵用来描述两个或多个随机变量之间的关系。对于一个包含n个特征的数据集,其协方差矩阵记作Σ(希腊字母sigma)。
协方差矩阵的元素(i,j)表示第i个和第j个特征之间的协方差。协方差描述了两个变量一起变化的趋势:如果两个变量一起增加或一起减少,它们之间的协方差为正;如果一个增加而另一个减少,协方差为负;如果它们之间没有关系,协方差为零。
对于标准化后的数据矩阵X,协方差矩阵Σ的计算公式如下:
Σ = 1 n − 1 ⋅ X T ⋅ X \Sigma =\frac{1}{n-1}\cdot X^{T}\cdot X Σ=n−11⋅XT⋅X
其中,n 是样本数量, X T X^{T} XT 是矩阵 X 的转置。
3. 特征值和特征向量
协方差矩阵的特征值(eigenvalues)和特征向量(eigenvectors)是PCA的核心。它们提供了一个新的基础,其中数据的方差最大。
特征值: 协方差矩阵的特征值是一个数,表示在对应特征向量方向上的方差。特征值的大小决定了在该方向上数据的变化程度,越大表示方差越大。
特征向量: 协方差矩阵的特征向量是一个向量,描述了变换后的坐标系中的方向。每个特征向量都对应一个特征值,而且特征向量的长度为1。
协方差矩阵的特征值和特征向量满足以下方程:
Σ ⋅ ν = λ ⋅ ν \Sigma \cdot \nu = \lambda \cdot \nu Σ⋅ν=λ⋅ν
其中, ν \nu ν 是特征向量, λ λ λ 是特征值。这个方程表示协方差矩阵乘以特征向量等于特征值乘以特征向量。
特征值和特征向量的计算通过解特征方程得到,即:
d e t ( Σ − λ ⋅ I ) = 0 det(\Sigma -\lambda \cdot I)=0 det(Σ−λ⋅I)=0
其中, d e t det det 表示矩阵的行列式, I I I 是单位矩阵。解这个方程得到的特征值和对应的特征向量即为协方差矩阵的特征值和特征向量。
通过计算协方差矩阵的特征值和特征向量,我们得到一组特征值(降序排列)和对应的特征向量。这组特征值和特征向量表示了数据变换后的主成分。
三、PCA的算法流程
1. 标准化数据
PCA的第一步是对原始数据进行标准化处理,确保每个特征的均值为零,标准差为一。标准化消除了不同特征之间的量纲差异,使得每个特征对PCA的贡献相对均等。标准化后的数据矩阵记为 X X X。
2. 计算协方差矩阵
通过标准化后的数据矩阵 X X X,计算协方差矩阵 Σ Σ Σ。协方差矩阵描述了数据中每对特征之间的关系,是PCA的数学基础。协方差矩阵的元素 Σ i , j \Sigma _{i,j} Σi,j 表示第 i i i 个和第 j j j 个特征之间的协方差。
Σ = 1 n − 1 ⋅ X T ⋅ X \Sigma =\frac{1}{n-1}\cdot X^{T}\cdot X Σ=n−11⋅XT⋅X
3.计算特征值和特征向量
对协方差矩阵 Σ Σ Σ 进行特征值分解,得到特征值(λ) 和对应的特征向量(v)。特征值和特征向量满足以下方程:
Σ ⋅ ν = λ ⋅ ν \Sigma \cdot \nu = \lambda \cdot \nu Σ⋅ν=λ⋅ν
这一步的目的是找到数据中的主成分,即在哪些方向上数据变化最为显著。
4. 选择主成分
按照特征值的大小降序排列,选择前k个特征值对应的特征向量作为主成分。这一步决定了我们希望保留的维度数,即降维后的数据将包含的主要信息。
5. 数据投影
构建变换矩阵 W W W,其列是选择的前 k k k 个特征向量。将原始数据矩阵 X X X 与变换矩阵 W W W 相乘,即 X ⋅ W X⋅W X⋅W,得到降维后的数据矩阵 X n e w X_{new} Xnew。在新的坐标系中,每一行表示一个样本在主成分方向上的投影,实现了数据的降维。
X n e w = X ⋅ W X_{new}=X\cdot W Xnew=X⋅W
四、代码分析(人脸识别)
1. 加载图像数据
功能:
读取 ORL_Faces/s1/1.pgm 至 s40/10.pgm 的 400 张灰度人脸图像
每个人 10 张图,共 40 人
images 是形状为 (400, 高, 宽) 的图像数组
labels 是形状为 (400,) 的标签数组(1~40)
def load_faces(path='ORL_Faces'):
images = []
labels = []
for i in range(1, 41): # 类别 s1 ~ s40
for j in range(1, 11): # 每类10张图
img_path = os.path.join(path, f"s{i}", f"{j}.pgm")
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
if img is not None:
images.append(img)
labels.append(i)
else:
print(f"⚠️ 无法读取图像:{img_path}")
if not images:
raise RuntimeError("❌ 未读取到任何图像,请检查路径或格式。")
print(f"✅ 成功读取 {len(images)} 张图像。")
return np.array(images), np.array(labels)
2. 画图函数
功能:
绘制图像矩阵(用于展示“特征脸”或其他图像)
每张图像附有标题
h, w 为图像高宽,必须与输入匹配
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(min(n_row * n_col, len(images))):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
3. 主程序
核心流程如下:
① 读取数据
faces, labels = load_faces(path='ORL_Faces')
X = faces.reshape((n_samples, -1))
将图像拉平成一维向量(用于机器学习模型输入)
X.shape = (400, 10304)(假设每张图像为 112×92)
② 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(...)
- 默认 75% 训练、25% 测试
③ 标准化处理
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
将所有数据特征转换为均值为 0,标准差为 1
PCA 对标准化数据效果更佳
④ PCA 降维
pca = PCA(n_components=150, whiten=True, random_state=42)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
- 提取前 150 个主成分(或不超过训练样本数)
- whiten=True 表示输出为单位方差,有助于后续分类
- PCA 降低维度以提高 KNN 的分类效率
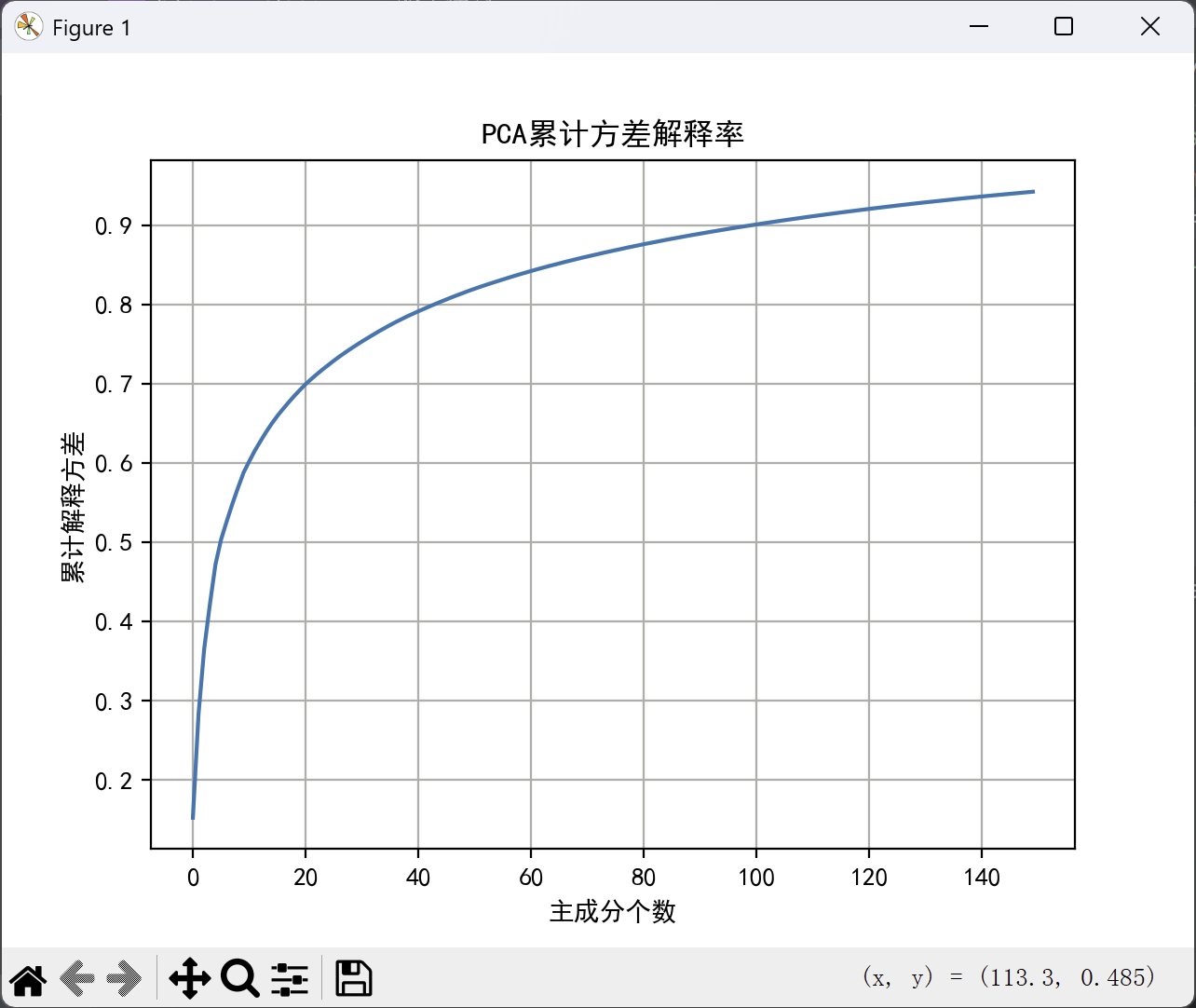
⑤ 累计解释方差图
plt.plot(np.cumsum(pca.explained_variance_ratio_))
可视化前几个主成分累积贡献的方差比
帮助判断是否选的主成分足够
⑥ KNN 分类
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train_pca, y_train)
y_pred = knn.predict(X_test_pca)
- 使用 KNN 对降维后的特征进行训练和预测
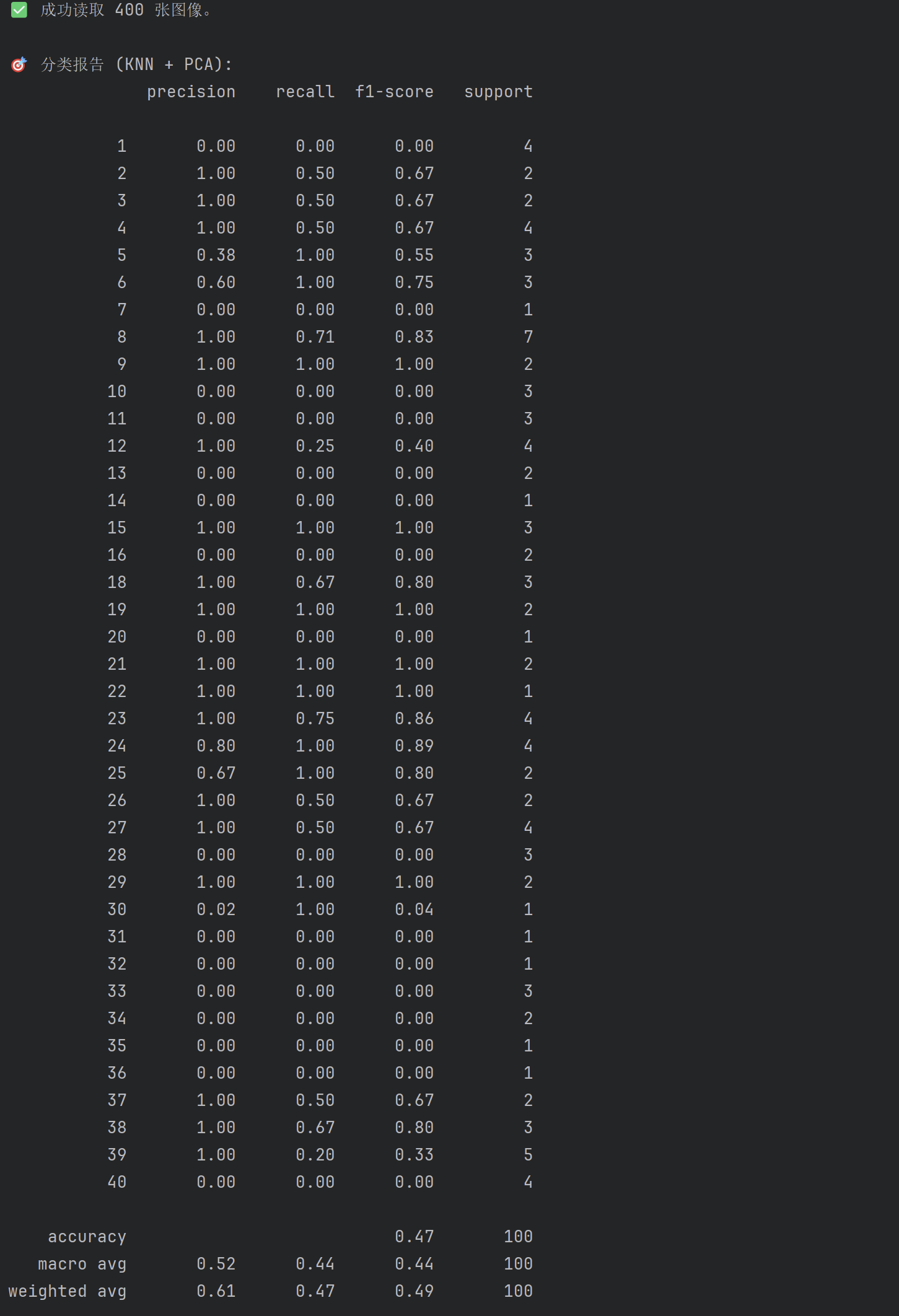
⑦ 分类结果评估
print(classification_report(y_test, y_pred))
- 打印分类精度、召回率、F1 分数
- 每个类都有对应指标
⑧ 可视化特征脸(Eigenfaces)
eigenfaces = pca.components_.reshape((n_components, h, w))
plot_gallery(eigenfaces, ..., h, w)
PCA 的主成分被还原成图像
每个主成分形状为原图大小,是“特征脸”
4. 完整代码
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
# === 字体设置(支持中文显示)===
font_path = "C:/Windows/Fonts/simhei.ttf"
font_prop = FontProperties(fname=font_path)
plt.rcParams['font.family'] = font_prop.get_name()
plt.rcParams['axes.unicode_minus'] = False
# 加载人脸图像数据
def load_faces(path='ORL_Faces'):
images = []
labels = []
for i in range(1, 41): # 类别 s1 ~ s40
for j in range(1, 11): # 每类10张图
img_path = os.path.join(path, f"s{i}", f"{j}.pgm")
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
if img is not None:
images.append(img)
labels.append(i)
else:
print(f"⚠️ 无法读取图像:{img_path}")
if not images:
raise RuntimeError("❌ 未读取到任何图像,请检查路径或格式。")
print(f"✅ 成功读取 {len(images)} 张图像。")
return np.array(images), np.array(labels)
# 绘制图像(支持原始图或特征脸)
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(min(n_row * n_col, len(images))):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
# 主程序入口
def main():
# 加载图像和标签
faces, labels = load_faces(path='ORL_Faces') # <-- 确保路径正确
n_samples, h, w = faces.shape
X = faces.reshape((n_samples, -1)) # 图像展平成向量
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, labels, test_size=0.25, random_state=42
)
# 标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# PCA降维
n_components = min(150, X_train.shape[0]) # 不超过样本数
pca = PCA(n_components=n_components, whiten=True, random_state=42)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# 解释方差比可视化
plt.figure()
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel("主成分个数")
plt.ylabel("累计解释方差")
plt.title("PCA累计方差解释率")
plt.grid()
plt.show()
# KNN分类器训练
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train_pca, y_train)
y_pred = knn.predict(X_test_pca)
# 分类评估
print("\n🎯 分类报告 (KNN + PCA):")
print(classification_report(y_test, y_pred))
# 可视化部分特征脸
eigenfaces = pca.components_.reshape((n_components, h, w))
eigenface_titles = [f"eigenface {i + 1}" for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w, n_row=3, n_col=4)
plt.show()
# 执行主函数
if __name__ == "__main__":
main()
5. 运行结果

五、实验感受
通过本次主成分分析(PCA)实验,我不仅加深了对线性代数中“特征值”“协方差矩阵”等概念的理解,也切实体会到了数据降维在实际问题中的重要性。以前在课堂上学习PCA时,总觉得它只是一个数学过程,而通过亲手实现算法的每一步,我对PCA“保留最大信息、减少维度冗余”的原理有了更加直观的认识。
在处理人脸图像数据的过程中,我第一次真正体会到“高维数据”的挑战:图像维度大、计算量高、存储开销大。而通过PCA降维,不仅大大减少了数据的维度,同时还能在不明显损失图像主要信息的前提下实现有效还原,这让我感受到数据压缩和特征提取的强大作用。
此外,我也意识到写代码和调试过程是理解理论最好的方式。比如在处理协方差矩阵和进行特征值分解的过程中,我遇到了一些维度不匹配或计算不稳定的问题,在查阅资料、调试改错的过程中,锻炼了自己的动手能力和分析问题的思维能力。
总体来说,这次实验既提升了我对PCA算法原理的理解,也增强了我将理论知识应用于实际问题的能力,对我今后进一步学习机器学习和图像识别相关课程有非常大的帮助。