Abstract
扩散模型(Diffusion model)最近被证明可以生成高质量的合成图像,尤其是当它们与某种引导技术结合使用时,可以在生成结果的多样性与保真度之间进行权衡。本文探讨了在文本条件图像生成任务中使用扩散模型,并比较了两种不同的引导策略:CLIP 引导和无分类器引导。我们发现,人类评估者更倾向于使用无分类器引导方法,无论是在照片真实感还是与文本描述的匹配度方面,该方法通常都能生成具有高度真实感的图像样本。使用无分类器引导的一个 35 亿参数文本条件扩散模型生成的图像样本,在人类评估中优于 DALL-E 的输出,即使后者采用了代价较高的 CLIP 重新排序技术。此外,我们发现我们的模型可以通过微调来执行图像修复任务,从而实现强大的文本驱动图像编辑。我们还在一个过滤后的数据集上训练了一个较小的模型,并公开了代码和模型权重。
Introduction
这一部分主要是让qwen3阅读的,内容如下:
🧠 1. 图像生成与文本描述的关系
- 图像(如插图、绘画、照片)通常可以用自然语言轻松描述,但创作这些图像可能需要专业技能和大量时间。
- 因此,一个能够从自然语言生成逼真图像的工具可以极大地提升人类创造视觉内容的能力。
- 如果还能通过自然语言对图像进行编辑,则可以实现迭代优化和细粒度控制,这对于实际应用非常重要。
📚 2. 现有文本条件图像模型的进展与局限
- 当前的一些文本条件图像生成模型(如 DALL-E)可以从自由文本提示中生成图像,并能以语义合理的方式组合不相关的物体。
- 然而,它们还不能生成完全符合文本描述的高质量真实感图像(photorealistic images)。
🖼️ 3. 无条件图像生成模型的优势
- 无条件图像生成模型(如 GANs)已经可以生成高度真实的图像,甚至在某些情况下人类难以区分真假。
- 其中,扩散模型(diffusion models) 被认为是一类非常有前景的生成模型,在多个图像生成基准任务上达到了最先进的效果。
🔍 4. 引导技术(Guidance Techniques)的发展
- 在类别条件图像生成任务中,研究人员通过引入“分类器引导”(classifier guidance)来增强扩散模型,使其可以根据分类器标签进行图像生成。
- 另一种方法是“无分类器引导”(classifier-free guidance),它不需要单独训练分类器,而是通过插值有/无标签的预测结果来引导生成过程。
💡 5. 本文的研究动机与目标
- 基于引导扩散模型在生成真实感图像上的能力,以及文本到图像模型处理自由形式提示的能力,作者将引导扩散模型应用于文本条件图像合成任务。
- 主要研究内容包括:
- 训练一个35亿参数的文本条件扩散模型;
- 比较两种引导策略:CLIP 引导 和 无分类器引导;
- 使用人工评估和自动化评估方法比较生成图像的质量。
✅ 6. 主要发现与成果
- 使用无分类器引导的方法在图像质量和真实性方面优于 CLIP 引导;
- GLIDE 模型生成的图像不仅具有照片级真实感,还能体现广泛的世界知识;
- 在人类评估中,GLIDE 生成的图像在照片真实感方面有 87% 的偏好率优于 DALL-E,在与文本描述的匹配度方面也有 69% 的偏好率;
- 示例展示了模型在生成艺术风格图像、多概念组合、阴影反射等方面的能力。
🛠️ 7. 图像编辑能力(Inpainting)
- 尽管模型在很多任务上表现良好,但在复杂提示下生成高质量图像仍有挑战;
- 因此,作者进一步赋予模型图像修复(inpainting)能力,允许用户通过文本驱动的方式对已有图像进行编辑;
- 实验表明,模型能够根据上下文风格和光照信息,生成逼真的图像补全结果,包括合理的阴影和反射。
⚠️ 8. 伦理考量与模型发布
- 作者指出该模型也可能被滥用于生成虚假信息或深度伪造图像;
- 为了防止滥用并促进未来研究,他们发布了两个较小的模型:
- 一个是在过滤后的数据集上训练的小型扩散模型;
- 一个是加噪的 CLIP 模型(noised CLIP model)。
🏷️ 9. 系统命名
- 该系统被命名为 GLIDE,全称是:
Guided Language to Image Diffusion for Generation and Editing
- 发布的小型模型称为 GLIDE (filtered)。
Background
Diffusion模型的数学原理
先从最基本的概念开始吧,已经有一些印象不太深刻了,这篇笔记就补充起来:
正态分布(高斯分布)
首先重温一下正态分布:
如果一维随机变量 X X X 的密度函数为:
f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}} f(x)=2πσ1e−2σ2(x−μ)2其中 μ \mu μ 和 σ \sigma σ 为常数且 σ > 0 \sigma > 0 σ>0,则称随机变量 X X X 服从参数为 μ , σ 2 \mu, \sigma^2 μ,σ2 的正态分布,记作 X ∼ N ( μ , σ 2 ) X \sim N(\mu, \sigma^2) X∼N(μ,σ2) ,读作 X X X服从 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2)。 μ \mu μ 为总体均数, σ \sigma σ 为总体标准差。这里 N N N 为“Normal distribution(正态分布)”一词的首字母。
特别地,当 μ = 0 \mu = 0 μ=0, σ = 1 \sigma = 1 σ=1 时,正态分布 N ( 0 , 1 ) N(0, 1) N(0,1) 称为标准正态分布,其密度函数为:
φ ( x ) = 1 2 π e − x 2 2 , x ∈ ( − ∞ , + ∞ ) \varphi(x) = \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}}, \quad x \in (-\infty, +\infty) φ(x)=2π1e−2x2,x∈(−∞,+∞)
标准正态分布之所以重要,一个原因在于:任意的正态分布 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2) 的计算很容易转化为标准正态分布 N ( 0 , 1 ) N(0, 1) N(0,1)。容易证明:若 X ∼ N ( μ , σ 2 ) X \sim N(\mu, \sigma^2) X∼N(μ,σ2),则 Y = X − μ σ ∼ N ( 0 , 1 ) Y = \frac{X - \mu}{\sigma} \sim N(0, 1) Y=σX−μ∼N(0,1)。
马尔可夫过程和马尔可夫链
首先我们回忆一下随机过程:一个随机过程应该被描述为 { X t } t ∈ T \{X_t\}_{t \in T} {Xt}t∈T,其中每个 X t X_t Xt 是一个随机变量, t ∈ T t \in T t∈T 是时间索引集合。
马尔可夫性质(Markov Property)
[!note]
未来的状态只依赖于当前状态,而不依赖于过去的状态
公式可以表达为:
P ( X t + 1 = x t + 1 ∣ X t = x t , X t − 1 = x t − 1 , … , X 0 = x 0 ) = P ( X t + 1 = x t + 1 ∣ X t = x t ) P(X_{t+1}=x_{t+1}|X_t=x_t,X_{t-1}=x_{t-1},\dots,X_0=x_0)=P(X_{t+1}=x_{t+1}|X_t=x_t) P(Xt+1=xt+1∣Xt=xt,Xt−1=xt−1,…,X0=x0)=P(Xt+1=xt+1∣Xt=xt)
在信息论中又说为无记忆性。
马尔可夫链
定义
马尔可夫链是具有马尔可夫性质的离散时间、离散状态空间的随机过程。
设:
- 状态空间 S = { s 1 , s 2 , . . . , s n } S = \{s_1, s_2, ..., s_n\} S={s1,s2,...,sn} 是有限或可数无限集合;
- 时间索引 t ∈ N t \in \mathbb{N} t∈N。
那么我们称 { X t } t = 0 ∞ \{X_t\}_{t=0}^\infty {Xt}t=0∞ 为一个马尔可夫链,如果它满足:
P ( X t + 1 = j ∣ X t = i , X t − 1 = i t − 1 , . . . , X 0 = i 0 ) = P ( X t + 1 = j ∣ X t = i ) P(X_{t+1} = j \mid X_t = i, X_{t-1} = i_{t-1}, ..., X_0 = i_0) = P(X_{t+1} = j \mid X_t = i) P(Xt+1=j∣Xt=i,Xt−1=it−1,...,X0=i0)=P(Xt+1=j∣Xt=i)
2. 转移概率与转移矩阵
(1) 转移概率(Transition Probability)
定义从状态 i i i 到状态 j j j 在一步内的转移概率为:
P i j = P ( X t + 1 = j ∣ X t = i ) P_{ij} = P(X_{t+1} = j \mid X_t = i) Pij=P(Xt+1=j∣Xt=i)
这是一个条件概率,表示在当前处于状态 i i i 的条件下,下一步转移到状态 j j j 的概率。
(2) 转移矩阵(Transition Matrix)
所有可能的 P i j P_{ij} Pij 构成一个矩阵 P P P,称为转移矩阵:
P = [ P 11 P 12 ⋯ P 1 n P 21 P 22 ⋯ P 2 n ⋮ ⋮ ⋱ ⋮ P n 1 P n 2 ⋯ P n n ] P = \begin{bmatrix} P_{11} & P_{12} & \cdots & P_{1n} \\ P_{21} & P_{22} & \cdots & P_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ P_{n1} & P_{n2} & \cdots & P_{nn} \end{bmatrix} P= P11P21⋮Pn1P12P22⋮Pn2⋯⋯⋱⋯P1nP2n⋮Pnn
矩阵中的每一行都是一个概率分布,即:
∑ j = 1 n P i j = 1 , ∀ i ∈ S \sum_{j=1}^n P_{ij} = 1,\quad \forall i \in S j=1∑nPij=1,∀i∈S
3. 多步转移概率
我们可以计算任意时刻 t t t 到 t + k t+k t+k 的转移概率:
P i j ( k ) = P ( X t + k = j ∣ X t = i ) P^{(k)}_{ij} = P(X_{t+k} = j \mid X_t = i) Pij(k)=P(Xt+k=j∣Xt=i)
可以通过递归方式求得:
P ( k ) = P k P^{(k)} = P^k P(k)=Pk
即:多步转移矩阵是单步转移矩阵的幂。
Diffusion的前向过程和后向过程
🧠 一、基本思想回顾:马尔可夫链与扩散模型的关系
在扩散模型中,我们构建了一个离散时间、连续状态空间的马尔可夫链。
- 前向过程(Forward Process):从原始数据 x 0 x_0 x0 开始,逐步加入高斯噪声,最终得到一个纯噪声样本 x T x_T xT。
- 后向过程(Reverse Process):从纯噪声 x T x_T xT 出发,逐步去噪,恢复出原始数据 x 0 x_0 x0。
这两个过程都满足马尔可夫性质:每一步只依赖于当前状态,不依赖过去的状态。
🔁 二、扩散模型的前向过程(Forward Process)
1. 定义
前向过程是一个逐步添加高斯噪声的过程,构成一个马尔可夫链:
x 0 → x 1 → x 2 → ⋯ → x T x_0 \rightarrow x_1 \rightarrow x_2 \rightarrow \cdots \rightarrow x_T x0→x1→x2→⋯→xT
其中:
- x 0 x_0 x0 是原始数据(如一张图片);
- x t x_t xt 是第 t t t 步加噪后的数据;
- x T x_T xT 是纯高斯噪声。
2. 转移分布
每一步的状态转移由如下高斯分布定义:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1},\ \beta_t I) q(xt∣xt−1)=N(xt;1−βtxt−1, βtI)
这里的 q ( x t ∣ x t − 1 ) q(x_t | x_{t-1}) q(xt∣xt−1)表示前向过程中的一步转移分布,是一个高斯分布,这表示,在给定上一时刻状态 x t − 1 x_{t-1} xt−1,当前状态 x t x_t xt是一个均值为 1 − β t x t − 1 \sqrt{1 - \beta_t} x_{t-1} 1−βtxt−1,协方差为 β t I \beta_t I βtI 的高斯分布
其中:
- β t ∈ ( 0 , 1 ) \beta_t \in (0,1) βt∈(0,1) 是预设的噪声强度参数;
- 随着 t t t 增大, β t \beta_t βt 逐渐增大,表示噪声逐步增强。
由于符合一个马尔可夫链,故每一项概率分布只与前一项有关,所以可以将这个过程写成:
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(x_{1:T} | x_0) = \prod_{t=1}^T q(x_t | x_{t-1}) q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
即从 x 0 x_0 x0开始,一步步转移到 x 1 , x 2 , … , x T x_1,x_2,\dots,x_T x1,x2,…,xT的完整路径的概率分布
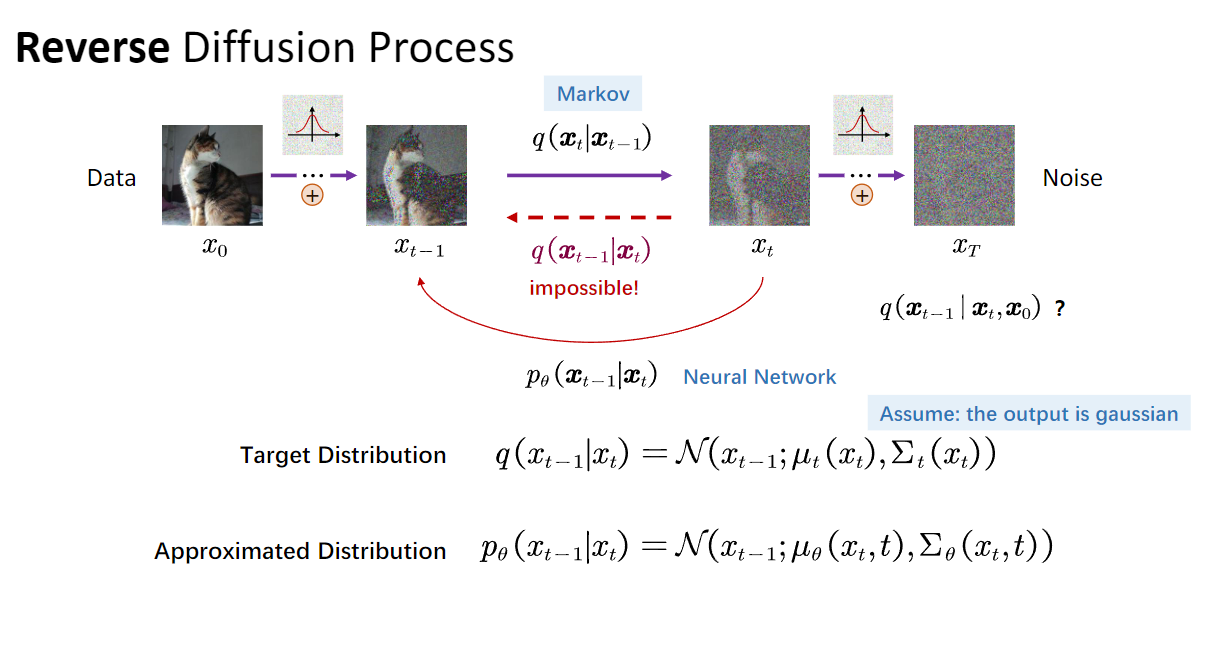
🔁 三、后向过程(Reverse Process)
目标:
从纯噪声 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I) 出发,逐步去噪,恢复出原始数据 x 0 x_0 x0。
这个过程也是一个马尔可夫链:
x T → x T − 1 → ⋯ → x 0 x_T \rightarrow x_{T-1} \rightarrow \cdots \rightarrow x_0 xT→xT−1→⋯→x0
只不过这一次我们不知道真实的后向分布 q ( x t − 1 ∣ x t ) q(x_{t-1} | x_t) q(xt−1∣xt),所以需要用神经网络来近似建模。
🧠 三、后向过程的数学表达
理想情况下,我们希望建模:
q ( x t − 1 ∣ x t ) q(x_{t-1} | x_t) q(xt−1∣xt)
但由于这涉及到复杂的贝叶斯推断,通常难以直接计算。因此,扩散模型使用一个参数化的神经网络分布来近似它:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(x_{t-1} | x_t) = \mathcal{N}\left( x_{t-1};\ \mu_\theta(x_t, t),\ \Sigma_\theta(x_t, t) \right) pθ(xt−1∣xt)=N(xt−1; μθ(xt,t), Σθ(xt,t))
其中:
- μ θ ( x t , t ) \mu_\theta(x_t, t) μθ(xt,t):神经网络预测的均值;
- Σ θ ( x t , t ) \Sigma_\theta(x_t, t) Σθ(xt,t):协方差矩阵,可以是固定的或学习的;
- θ \theta θ:神经网络的参数。
后面使用的图片是基于B站视频【大白话01】一文理清 Diffusion Model 扩散模型 | 原理图解+公式推导】
损失函数的设计
在 DDPM 中,我们的目标是让模型能够生成高质量的图像或数据。为此,我们希望模型的边缘分布 p ( x 0 ) p(x_0) p(x0) 能尽可能拟合真实数据分布 q ( x 0 ) q(x_0) q(x0)。
换句话说,我们想最大化数据点 x 0 x_0 x0 的对数似然:
log p ( x 0 ) \log p(x_0) logp(x0)
这个量衡量了模型对单个样本 x 0 x_0 x0 的“信任度”——越大说明模型越倾向于生成这样的样本。
但为什么不能直接最大化 log p ( x 0 ) \log p(x_0) logp(x0)?
因为模型定义的是一个复杂的生成过程:先从标准正态分布采样 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I),然后通过一系列去噪步骤逐步生成 x T − 1 , . . . , x 0 x_{T-1}, ..., x_0 xT−1,...,x0。也就是说:
p ( x 0 ) = ∫ p ( x 0 : T ) d x 1 : T = ∫ p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) d x 1 : T p(x_0) = \int p(x_{0:T}) dx_{1:T} = \int p(x_T) \prod_{t=1}^T p_\theta(x_{t-1}|x_t) dx_{1:T} p(x0)=∫p(x0:T)dx1:T=∫p(xT)t=1∏Tpθ(xt−1∣xt)dx1:T
这个积分无法直接计算,因此我们无法直接优化 log p ( x 0 ) \log p(x_0) logp(x0)。
如何解决这个问题呢?此处引入了变分下界法来间接优化 log p ( x 0 ) \log p(x_0) logp(x0)。
我们引入一个近似后验分布 q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0),构造变分下界(ELBO)来间接优化 log p ( x 0 ) \log p(x_0) logp(x0)。
✅ ELBO 定义如下:
log p ( x 0 ) ≥ E q ( x 1 : T ∣ x 0 ) [ log p ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] = : ELBO \log p(x_0) \geq \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_{0:T})}{q(x_{1:T}|x_0)} \right] =: \text{ELBO} logp(x0)≥Eq(x1:T∣x0)[logq(x1:T∣x0)p(x0:T)]=:ELBO
这个ELBO理解起来刚开始有些难度,我结合了信息论和概率论的基础知识,参考了部分博客(后面贴出):
[!info]
变分推断(Variational Inference, VI)是贝叶斯近似推断方法中的一大类方法,将后验推断问题巧妙地转化为优化问题进行求解。
下面我们简单推导一下变分下界:
KL散度
首先我们得知道KL散度的公式,KL散度(Kullback-Leibler Divergence ),也称为 相对熵(Relative Entropy)。其公式如下:
D KL ( p ∥ q ) = E x ∼ p [ log p ( x ) q ( x ) ] = ∫ p ( x ) log p ( x ) q ( x ) d x (连续变量) D_{\text{KL}}(p \| q) = \mathbb{E}_{x \sim p} \left[ \log \frac{p(x)}{q(x)} \right] = \int p(x) \log \frac{p(x)}{q(x)} dx \quad \text{(连续变量)} DKL(p∥q)=Ex∼p[logq(x)p(x)]=∫p(x)logq(x)p(x)dx(连续变量)
= ∑ x p ( x ) log p ( x ) q ( x ) (离散变量) = \sum_x p(x) \log \frac{p(x)}{q(x)} \quad \text{(离散变量)} =x∑p(x)logq(x)p(x)(离散变量)
ELBO与KL散度
假设我们有观测数据 x x x,以及一个潜在变量模型:
p ( x ) = ∫ p ( x , z ) d z p(x) = \int p(x, z) dz p(x)=∫p(x,z)dz
其中:
- x x x 是可观测变量(比如图像)
- z z z 是隐变量(比如类别、噪声、语义等)
我们的目标是最大化 log p ( x ) \log p(x) logp(x),但这个积分很难直接计算或优化。
为了解决这个问题,我们引入一个近似后验分布 q ( z ) q(z) q(z),它是对真实后验 p ( z ∣ x ) p(z|x) p(z∣x) 的估计。
根据 KL 散度的定义:
D KL ( q ( z ) ∥ p ( z ∣ x ) ) = E z ∼ q [ log q ( z ) p ( z ∣ x ) ] D_{\text{KL}}(q(z) \| p(z|x)) = \mathbb{E}_{z \sim q} \left[ \log \frac{q(z)}{p(z|x)} \right] DKL(q(z)∥p(z∣x))=Ez∼q[logp(z∣x)q(z)]
注意, p ( z ∣ x ) = p ( x , z ) p ( x ) p(z|x) = \frac{p(x, z)}{p(x)} p(z∣x)=p(x)p(x,z),代入得:
D KL ( q ( z ) ∥ p ( z ∣ x ) ) = E q [ log q ( z ) p ( x , z ) / p ( x ) ] = E q [ log q ( z ) p ( x , z ) + log p ( x ) ] D_{\text{KL}}(q(z) \| p(z|x)) = \mathbb{E}_q \left[ \log \frac{q(z)}{p(x,z)/p(x)} \right] = \mathbb{E}_q \left[ \log \frac{q(z)}{p(x,z)} + \log p(x) \right] DKL(q(z)∥p(z∣x))=Eq[logp(x,z)/p(x)q(z)]=Eq[logp(x,z)q(z)+logp(x)]
因为 log p ( x ) \log p(x) logp(x) 与 z z z 无关,可以提出期望:
= log p ( x ) + E q [ log q ( z ) − log p ( x , z ) ] = \log p(x) + \mathbb{E}_q [ \log q(z) - \log p(x,z) ] =logp(x)+Eq[logq(z)−logp(x,z)]
移项得:
log p ( x ) = D KL ( q ( z ) ∥ p ( z ∣ x ) ) − E q [ log q ( z ) − log p ( x , z ) ] \log p(x) = D_{\text{KL}}(q(z) \| p(z|x)) - \mathbb{E}_q [ \log q(z) - \log p(x,z) ] logp(x)=DKL(q(z)∥p(z∣x))−Eq[logq(z)−logp(x,z)]
即:
log p ( x ) = D KL ( q ( z ) ∥ p ( z ∣ x ) ) + E q [ log p ( x , z ) − log q ( z ) ] ⏟ ELBO \log p(x) = D_{\text{KL}}(q(z) \| p(z|x)) + \underbrace{\mathbb{E}_q [\log p(x,z) - \log q(z)]}_{\text{ELBO}} logp(x)=DKL(q(z)∥p(z∣x))+ELBO Eq[logp(x,z)−logq(z)]
上面我们得到了一个非常重要的恒等式:
log p ( x ) = D KL ( q ( z ) ∥ p ( z ∣ x ) ) + ELBO \log p(x) = D_{\text{KL}}(q(z) \| p(z|x)) + \text{ELBO} logp(x)=DKL(q(z)∥p(z∣x))+ELBO
由于 KL 散度总是非负的:
D KL ( q ( z ) ∥ p ( z ∣ x ) ) ≥ 0 ⇒ log p ( x ) ≥ ELBO D_{\text{KL}}(q(z) \| p(z|x)) \geq 0 \Rightarrow \log p(x) \geq \text{ELBO} DKL(q(z)∥p(z∣x))≥0⇒logp(x)≥ELBO
所以,**ELBO 是 log p ( x ) \log p(x) logp(x) 的一个下界(Evidence Lower Bound)
而且我们可以将 ELBO 写成更直观的形式:
p ( x , z ) = p ( x ∣ z ) p ( z ) p(x, z) = p(x|z) p(z) p(x,z)=p(x∣z)p(z)
代入 ELBO 表达式中:
ELBO = E q ( z ) [ log ( p ( x ∣ z ) p ( z ) ) − log q ( z ) ] \text{ELBO} = \mathbb{E}_{q(z)} \left[ \log (p(x|z) p(z)) - \log q(z) \right] ELBO=Eq(z)[log(p(x∣z)p(z))−logq(z)]
对乘积取对数变为加法:
= E q ( z ) [ log p ( x ∣ z ) + log p ( z ) − log q ( z ) ] = \mathbb{E}_{q(z)} \left[ \log p(x|z) + \log p(z) - \log q(z) \right] =Eq(z)[logp(x∣z)+logp(z)−logq(z)]
拆开期望:
= E q ( z ) [ log p ( x ∣ z ) ] + E q ( z ) [ log p ( z ) − log q ( z ) ] = \mathbb{E}_{q(z)} [ \log p(x|z) ] + \mathbb{E}_{q(z)} [ \log p(z) - \log q(z) ] =Eq(z)[logp(x∣z)]+Eq(z)[logp(z)−logq(z)]
注意到第二项:
E q ( z ) [ log p ( z ) − log q ( z ) ] = − E q ( z ) [ log q ( z ) p ( z ) ] = − D KL ( q ( z ) ∥ p ( z ) ) \mathbb{E}_{q(z)} [ \log p(z) - \log q(z) ] = - \mathbb{E}_{q(z)} \left[ \log \frac{q(z)}{p(z)} \right] = - D_{\text{KL}}(q(z) \| p(z)) Eq(z)[logp(z)−logq(z)]=−Eq(z)[logp(z)q(z)]=−DKL(q(z)∥p(z))于是我们得到:
ELBO = E q ( z ) [ log p ( x ∣ z ) ] − D KL ( q ( z ) ∥ p ( z ) ) \text{ELBO} = \mathbb{E}_{q(z)} [ \log p(x|z) ] - D_{\text{KL}}(q(z) \| p(z)) ELBO=Eq(z)[logp(x∣z)]−DKL(q(z)∥p(z))
所以我们就完成了整个推导过程,最终结论如下:
ELBO = E q ( z ) [ log p ( x , z ) − log q ( z ) ] = E q ( z ) [ log p ( x ∣ z ) ] − D KL ( q ( z ) ∥ p ( z ) ) \boxed{ \text{ELBO} = \mathbb{E}_{q(z)} [ \log p(x,z) - \log q(z) ] = \mathbb{E}_{q(z)} [ \log p(x|z) ] - D_{\text{KL}}(q(z) \| p(z)) } ELBO=Eq(z)[logp(x,z)−logq(z)]=Eq(z)[logp(x∣z)]−DKL(q(z)∥p(z))
ELBO运用到此处
在 DDPM 模型中,我们有:
- 观测数据: x 0 x_0 x0(原始图像)
- 隐变量: x 1 , x 2 , . . . , x T x_1, x_2, ..., x_T x1,x2,...,xT(逐步加噪的中间状态)
所以我们可以把联合分布写成:
p ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p(x_{0:T}) = p(x_T) \prod_{t=1}^T p_\theta(x_{t-1} | x_t) p(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)
这里包括先验 p ( x T ) = N ( x T ; 0 , I ) p(x_T) = \mathcal{N}(x_T; 0, I) p(xT)=N(xT;0,I),即最终的“起点”是一个标准正态分布。中间的转移分布为: p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(x_{t-1} | x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
其中:
- μ θ ( x t , t ) \mu_\theta(x_t, t) μθ(xt,t):神经网络预测的均值
- Σ θ ( x t , t ) \Sigma_\theta(x_t, t) Σθ(xt,t):可以固定或学习的方差(通常设为与时间有关的常数)
整个联合分布也可写为:
p ( x 0 : T ) = N ( x T ; 0 , I ) ⋅ ∏ t = 1 T N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p(x_{0:T}) = \mathcal{N}(x_T; 0, I) \cdot \prod_{t=1}^T \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)) p(x0:T)=N(xT;0,I)⋅t=1∏TN(xt−1;μθ(xt,t),Σθ(xt,t))
而前向过程是已知的马尔可夫链:
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(x_{1:T} | x_0) = \prod_{t=1}^T q(x_t | x_{t-1}) q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
于是我们定义 ELBO:
log p ( x 0 ) ≥ ELBO = E q [ log p ( x 0 : T ) − log q ( x 1 : T ∣ x 0 ) ] \log p(x_0) \geq \text{ELBO} = \mathbb{E}_q \left[ \log p(x_{0:T}) - \log q(x_{1:T}|x_0) \right] logp(x0)≥ELBO=Eq[logp(x0:T)−logq(x1:T∣x0)]
根据前面的公式:
ELBO = E q [ log p ( x 0 : T ) − log q ( x 1 : T ∣ x 0 ) ] \text{ELBO} = \mathbb{E}_q \left[ \log p(x_{0:T}) - \log q(x_{1:T}|x_0) \right] ELBO=Eq[logp(x0:T)−logq(x1:T∣x0)]
代入模型定义的联合分布和前向过程:
ELBO = E q [ log p ( x T ) + ∑ t = 1 T log p θ ( x t − 1 ∣ x t ) − ∑ t = 1 T log q ( x t ∣ x t − 1 ) ] \text{ELBO} = \mathbb{E}_q \left[ \log p(x_T) + \sum_{t=1}^T \log p_\theta(x_{t-1}|x_t) - \sum_{t=1}^T \log q(x_t|x_{t-1}) \right] ELBO=Eq[logp(xT)+t=1∑Tlogpθ(xt−1∣xt)−t=1∑Tlogq(xt∣xt−1)]
整理为:
ELBO = E q [ log p ( x T ) + ∑ t = 1 T log p θ ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) ] \text{ELBO} = \mathbb{E}_q \left[ \log p(x_T) + \sum_{t=1}^T \log \frac{p_\theta(x_{t-1}|x_t)}{q(x_t|x_{t-1})} \right] ELBO=Eq[logp(xT)+t=1∑Tlogq(xt∣xt−1)pθ(xt−1∣xt)]
我们再次使用 KL 散度恒等式:
D KL ( q ∣ ∣ p ) = E q [ log q − log p ] ⇒ log p q = − log q p = − ( log q − log p ) D_{\text{KL}}(q||p) = \mathbb{E}_q[\log q - \log p] \Rightarrow \log \frac{p}{q} = -\log \frac{q}{p} = -(\log q - \log p) DKL(q∣∣p)=Eq[logq−logp]⇒logqp=−logpq=−(logq−logp)
所以:
log p θ ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) = − log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) = − ( log q ( x t ∣ x t − 1 ) − log p θ ( x t − 1 ∣ x t ) ) \log \frac{p_\theta(x_{t-1}|x_t)}{q(x_t|x_{t-1})} = - \log \frac{q(x_t|x_{t-1})}{p_\theta(x_{t-1}|x_t)} = - \left( \log q(x_t|x_{t-1}) - \log p_\theta(x_{t-1}|x_t) \right) logq(xt∣xt−1)pθ(xt−1∣xt)=−logpθ(xt−1∣xt)q(xt∣xt−1)=−(logq(xt∣xt−1)−logpθ(xt−1∣xt))
于是 ELBO 可以写成:
ELBO = E q [ log p ( x T ) − ∑ t = 1 T ( log q ( x t ∣ x t − 1 ) − log p θ ( x t − 1 ∣ x t ) ) ] \text{ELBO} = \mathbb{E}_q \left[ \log p(x_T) - \sum_{t=1}^T \left( \log q(x_t|x_{t-1}) - \log p_\theta(x_{t-1}|x_t) \right) \right] ELBO=Eq[logp(xT)−t=1∑T(logq(xt∣xt−1)−logpθ(xt−1∣xt))]
进一步整理为:
ELBO = E q [ log p ( x T ) − ∑ t = 1 T log q ( x t ∣ x t − 1 ) ] + E q [ ∑ t = 1 T log p θ ( x t − 1 ∣ x t ) ] \text{ELBO} = \mathbb{E}_q \left[ \log p(x_T) - \sum_{t=1}^T \log q(x_t|x_{t-1}) \right] + \mathbb{E}_q \left[ \sum_{t=1}^T \log p_\theta(x_{t-1}|x_t) \right] ELBO=Eq[logp(xT)−t=1∑Tlogq(xt∣xt−1)]+Eq[t=1∑Tlogpθ(xt−1∣xt)]这可以看作两个部分:
- 第一部分:与模型无关,仅由前向扩散过程决定
- 第二部分:与反向过程有关,是我们可以通过训练优化的部分
因此,最大化 ELBO 等价于最大化第二部分:
E q [ ∑ t = 1 T log p θ ( x t − 1 ∣ x t ) ] \mathbb{E}_q \left[ \sum_{t=1}^T \log p_\theta(x_{t-1}|x_t) \right] Eq[t=1∑Tlogpθ(xt−1∣xt)]
假设:
- 前向过程是已知的高斯马尔可夫链:
x t = α t x t − 1 + 1 − α t ϵ t , ϵ t ∼ N ( 0 , I ) ⇒ q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) x_t = \sqrt{\alpha_t} x_{t-1} + \sqrt{1 - \alpha_t} \epsilon_t, \quad \epsilon_t \sim \mathcal{N}(0, I) \Rightarrow q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t} x_{t-1}, (1 - \alpha_t) I) xt=αtxt−1+1−αtϵt,ϵt∼N(0,I)⇒q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I)
- 同时我们定义一个封闭式表达:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ t x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon_t xt=αˉtx0+1−αˉtϵt
- 反向过程建模为高斯分布:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
真实后验 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q(xt−1∣xt,x0) 也是高斯分布(因为它是联合高斯分布的一部分),下面推导它的均值:
首先我们从联合概率分布出发:
q ( x t − 1 , x t ∣ x 0 ) = q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 ) q(x_{t-1}, x_t | x_0) = q(x_{t-1} | x_0) q(x_t | x_{t-1}) q(xt−1,xt∣x0)=q(xt−1∣x0)q(xt∣xt−1)
根据贝叶斯公式:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t − 1 , x t ∣ x 0 ) q ( x t ∣ x 0 ) = q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 ) q ( x t ∣ x 0 ) q(x_{t-1} | x_t, x_0) = \frac{q(x_{t-1}, x_t | x_0)}{q(x_t | x_0)} = \frac{q(x_{t-1} | x_0) q(x_t | x_{t-1})}{q(x_t | x_0)} q(xt−1∣xt,x0)=q(xt∣x0)q(xt−1,xt∣x0)=q(xt∣x0)q(xt−1∣x0)q(xt∣xt−1)
由于所有分布都是高斯分布,所以我们可以直接写出这些分布的形式。
1. q ( x t − 1 ∣ x 0 ) q(x_{t-1} | x_0) q(xt−1∣x0)
这一步是从 x 0 x_0 x0 到 x t − 1 x_{t-1} xt−1 的加噪过程:
x t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 ϵ t − 1 ⇒ q ( x t − 1 ∣ x 0 ) = N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) x_{t-1} = \sqrt{\bar{\alpha}_{t-1}} x_0 + \sqrt{1 - \bar{\alpha}_{t-1}} \epsilon_{t-1} \Rightarrow q(x_{t-1} | x_0) = \mathcal{N}\left(x_{t-1}; \sqrt{\bar{\alpha}_{t-1}} x_0,\ (1 - \bar{\alpha}_{t-1}) I \right) xt−1=αˉt−1x0+1−αˉt−1ϵt−1⇒q(xt−1∣x0)=N(xt−1;αˉt−1x0, (1−αˉt−1)I)
2. q ( x t ∣ x t − 1 ) q(x_t | x_{t-1}) q(xt∣xt−1)
这是单步加噪:
x t = α t x t − 1 + 1 − α t ϵ t ⇒ q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) x_t = \sqrt{\alpha_t} x_{t-1} + \sqrt{1 - \alpha_t} \epsilon_t \Rightarrow q(x_t | x_{t-1}) = \mathcal{N}\left(x_t; \sqrt{\alpha_t} x_{t-1},\ (1 - \alpha_t) I \right) xt=αtxt−1+1−αtϵt⇒q(xt∣xt−1)=N(xt;αtxt−1, (1−αt)I)
3. q ( x t ∣ x 0 ) q(x_t | x_0) q(xt∣x0)
这是封闭式表达:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ t ⇒ q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon_t \Rightarrow q(x_t | x_0) = \mathcal{N}\left(x_t; \sqrt{\bar{\alpha}_t} x_0,\ (1 - \bar{\alpha}_t) I \right) xt=αˉtx0+1−αˉtϵt⇒q(xt∣x0)=N(xt;αˉtx0, (1−αˉt)I)
我们知道两个高斯分布的乘积仍然是一个高斯分布(归一化后):
设:
- p ( x ) = N ( x ; μ 1 , σ 1 2 ) p(x) = \mathcal{N}(x; \mu_1, \sigma_1^2) p(x)=N(x;μ1,σ12)
- q ( x ) = N ( x ; μ 2 , σ 2 2 ) q(x) = \mathcal{N}(x; \mu_2, \sigma_2^2) q(x)=N(x;μ2,σ22)
则:
p ( x ) q ( x ) ∝ N ( x ; μ 1 / σ 1 2 + μ 2 / σ 2 2 1 / σ 1 2 + 1 / σ 2 2 , 1 1 / σ 1 2 + 1 / σ 2 2 ) p(x) q(x) \propto \mathcal{N}\left( x;\ \frac{\mu_1/\sigma_1^2 + \mu_2/\sigma_2^2}{1/\sigma_1^2 + 1/\sigma_2^2},\ \frac{1}{1/\sigma_1^2 + 1/\sigma_2^2} \right) p(x)q(x)∝N(x; 1/σ12+1/σ22μ1/σ12+μ2/σ22, 1/σ12+1/σ221)
代入计算 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1} | x_t, x_0) q(xt−1∣xt,x0)
我们现在有:
q ( x t − 1 ∣ x 0 ) = N ( x t − 1 ; μ 1 , Σ 1 ) q(x_{t-1} | x_0) = \mathcal{N}(x_{t-1}; \mu_1, \Sigma_1) q(xt−1∣x0)=N(xt−1;μ1,Σ1),
其中 μ 1 = α ˉ t − 1 x 0 \mu_1 = \sqrt{\bar{\alpha}_{t-1}} x_0 μ1=αˉt−1x0, Σ 1 = ( 1 − α ˉ t − 1 ) I \Sigma_1 = (1 - \bar{\alpha}_{t-1}) I Σ1=(1−αˉt−1)Iq ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t} x_{t-1},\ (1 - \alpha_t) I ) q(xt∣xt−1)=N(xt;αtxt−1, (1−αt)I)
我们将 x t x_t xt 视为观测变量,于是可以将 q ( x t ∣ x t − 1 ) q(x_t | x_{t-1}) q(xt∣xt−1) 看作似然函数,结合先验 q ( x t − 1 ∣ x 0 ) q(x_{t-1} | x_0) q(xt−1∣x0),用贝叶斯更新得到后验 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1} | x_t, x_0) q(xt−1∣xt,x0)
这是一个典型的线性高斯模型下的贝叶斯更新问题。根据卡尔曼滤波或高斯条件分布的结果,最终得到:
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ q ( x t , x 0 ) , Σ q ) q(x_{t-1} | x_t, x_0) = \mathcal{N}(x_{t-1}; \mu_q(x_t, x_0), \Sigma_q) q(xt−1∣xt,x0)=N(xt−1;μq(xt,x0),Σq)
其中:
μ q ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 ( 1 − α t ) 1 − α ˉ t x 0 \mu_q(x_t, x_0) = \frac{ \sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1}) }{1 - \bar{\alpha}_t} x_t + \frac{ \sqrt{\bar{\alpha}_{t-1}} (1 - \alpha_t) }{1 - \bar{\alpha}_t} x_0 μq(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1(1−αt)x0
Σ q = ( 1 − α t ) ( 1 − α ˉ t − 1 ) 1 − α ˉ t I \Sigma_q = \frac{(1 - \alpha_t)(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} I Σq=1−αˉt(1−αt)(1−αˉt−1)I
如果我们用噪声参数化 x 0 x_0 x0,即:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ ⇒ x 0 = x t − 1 − α ˉ t ϵ α ˉ t x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon \Rightarrow x_0 = \frac{x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon}{\sqrt{\bar{\alpha}_t}} xt=αˉtx0+1−αˉtϵ⇒x0=αˉtxt−1−αˉtϵ
将此处的 x 0 x_0 x0带入前面均值 μ q ( x t , x 0 ) \mu_q(x_t, x_0) μq(xt,x0)的公式,我们可以得到: μ q ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 ( 1 − α t ) x 0 1 − α ˉ t ⇔ 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) \mu_q(x_t, x_0) = \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})x_t + \sqrt{\bar{\alpha}_{t-1}}(1 - \alpha_t)x_0}{1 - \bar{\alpha}_t} \quad \Leftrightarrow \quad \frac{1}{\sqrt{\alpha_t}}\left(x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}}\epsilon_t\right) μq(xt,x0)=1−αˉtαt(1−αˉt−1)xt+αˉt−1(1−αt)x0⇔αt1(xt−1−αˉt1−αtϵt)
我们可以直接让神经网络预测噪声 ϵ t \epsilon_t ϵt,而不是直接预测 x t − 1 x_{t-1} xt−1。这样,最终的训练目标变为:
L = E x 0 , ϵ , t [ ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 ] \mathcal{L} = \mathbb{E}_{x_0, \epsilon, t} \left[ \|\epsilon - \epsilon_\theta(x_t, t)\|^2 \right] L=Ex0,ϵ,t[∥ϵ−ϵθ(xt,t)∥2]
其中:
- x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1 - \bar{\alpha}_t}\epsilon xt=αˉtx0+1−αˉtϵ
- ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t) 是神经网络预测的噪声
采样过程
在完成上述分析后,最终得到的反向过程需要从 x t x_t xt去得到 x t − 1 x_{t-1} xt−1,理解为采样过程,加入一个随机噪声项,公式如下:
x t − 1 = μ θ ( x t , t ) + σ t z , z ∼ N ( 0 , I ) x_{t-1} = \mu_\theta(x_t, t) + \sigma_t z,\quad z \sim \mathcal{N}(0, I) xt−1=μθ(xt,t)+σtz,z∼N(0,I)
带入均值得到:
x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z x_{t-1} = \frac{1}{\sqrt{\alpha_t}}\left(x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}}\epsilon_\theta(x_t, t)\right) + \sigma_t z xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))+σtz恭喜,到这里,我终于推导完成了DDPM的大致原理,其实很多细节部分我肯定仍存在疏忽,但是在基本概念和大致过程上终于形成了一个框架。