为什么要先讲SD原理 ?
- 逻辑理解: ComfyUI是节点式操作,需要自行搭建工作流,理解原理才能灵活定制工作流
- 学习效率: 基础原理不懂会导致后续学习吃力,原理是掌握ComfyUI的关键
- 核心价值: ComfyUI最有价值的功能就是自主搭建工作流,这需要深入理解SD原理
Stable Diffusion 扩散算法
- 基本概念: SD基于扩散算法(diffusion)生成图像,中文译为"稳定的扩散"
- 核心过程:
- 正向扩散: 生噪过程,增加噪点
- 反向扩散: 去噪过程,消除噪点
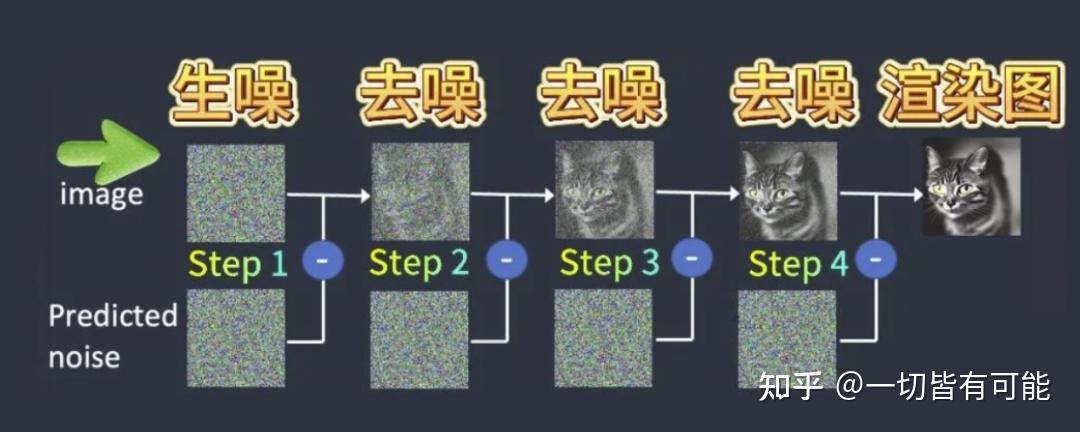
- 实现方式: 先将图片铺满噪点,然后根据步数逐步降噪,最终得到目标图像
- 关键结论: 图像生成是从噪点到清晰图片的渐进过程
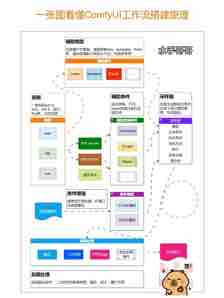
工作流示例
我们现在用一个实例来走一遍AI生图的流程。比如说我们要让AI生成一个美丽的女孩。
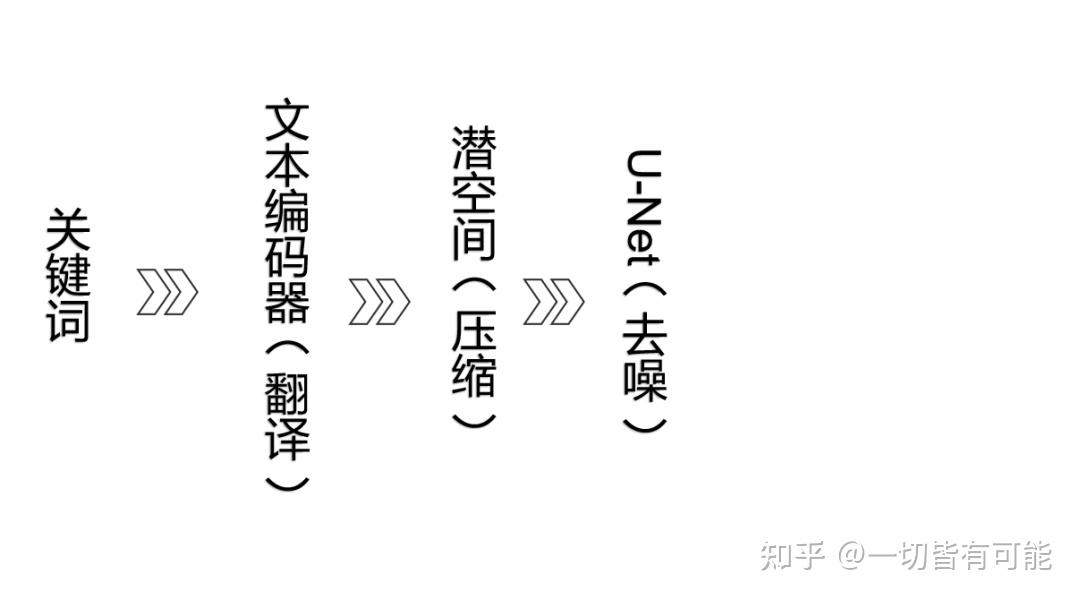
我们把关键词"beautiful girl"输入给计算机的时候,计算机无法理解"beautiful girl"。人类语言与计算机语言需要转换,就像中英文交流需要翻译。这就需要一个翻译:CLIP。
CLIP
CLIP是Text Encoder(文本编码器)的一种,其作用是将文本信息("beautiful girl")数字化,根据模型训练经验识别特征(大眼睛、好身材等)。将人类语言翻译为计算机能理解的数字化描述(函数/向量)。CLIP使AI能捕捉文本含义,是SD工作流的关键组件。
Latent Space(潜空间)
刚才被CLIP编译完的数字化信息会进入到 Latent Space(潜空间)。我们所使用的调度器,采样器,CFG Scale都是在潜空间里进行工作的。
在 ComfyUI 中,Latent Space 是连接文本、模型和生成图像的桥梁。它的核心价值在于:
高效性:压缩表示降低计算成本。
灵活性:支持多种潜在空间操作和扩展。
模块化:与 ComfyUI 的节点式工作流完美契合,便于可视化调试。
我们这里说一下其节省计算成本的作用,例如我要生成一张512x512的图片。

在Latent Space(潜空间)内,数据会被压缩:

Latent Space(潜空间)中有U-Net(作用是给图片去噪),其可以对随机种子生成噪声图进行引导。
到这一步,图片其实已经被生成出来了,只不过此时的图片是一张被压缩的,数字化的(一堆向量和参数)的图片,我们人类还无法看懂。
我们需要解码器对图片进行解压,解码器的作用是将计算机数据转变为人类可视图像
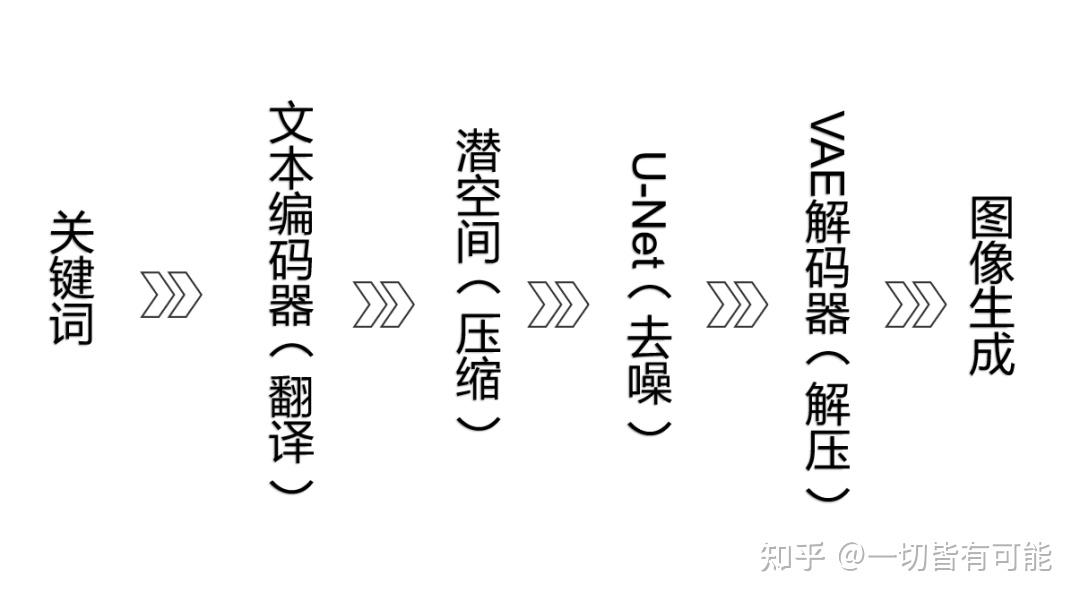
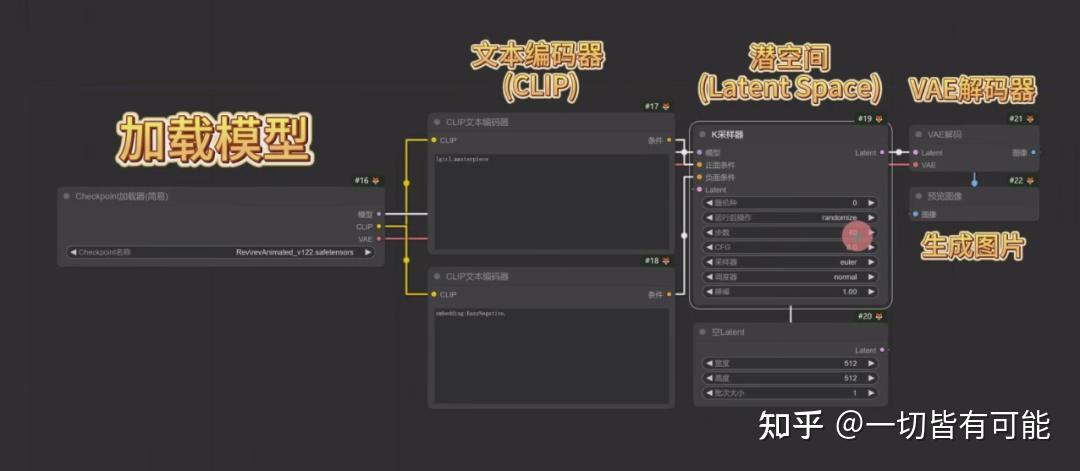
以上就是文生图的大致工作流程,下图为Comfy UI的工作流节点