【分布式】分布式ID介绍和实现方案总结
【一】分布式ID介绍
【1】什么是ID
日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。我们现实生活中也有各种 ID,比如身份证 ID 对应且仅对应一个人、地址 ID 对应且仅对应一个地址。
简单来说,ID 就是数据的唯一标识。
【2】什么是分布式ID
分布式 ID 是分布式系统下的 ID。分布式 ID 不存在与现实生活中,属于计算机系统中的一个概念。
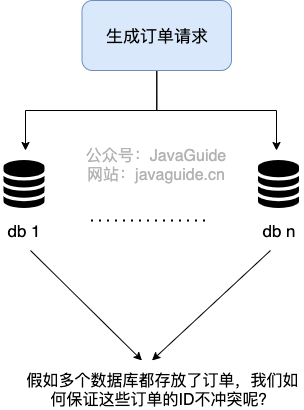
我简单举一个分库分表的例子。
例如一个项目,使用的是单机 MySQL 。但是,没想到的是,项目上线一个月之后,随着使用人数越来越多,整个系统的数据量将越来越大。单机 MySQL 已经没办法支撑了,需要进行分库分表(推荐 Sharding-JDBC)。在分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。
我们如何为不同的数据节点生成全局唯一主键呢?这个时候就需要生成分布式 ID了。
【3】分布式ID需要满足哪些要求
分布式 ID 作为分布式系统中必不可少的一环,很多地方都要用到分布式 ID。
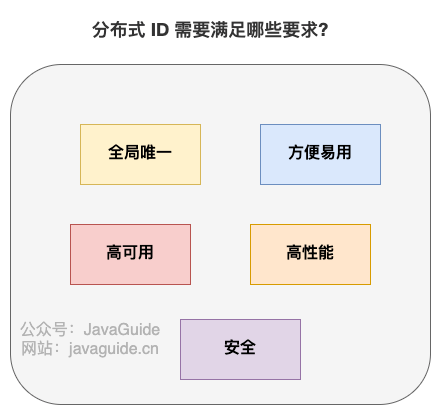
一个最基本的分布式 ID 需要满足下面这些要求:
(1)全局唯一:ID 的全局唯一性肯定是首先要满足的!
(2)高性能:分布式 ID 的生成速度要快,对本地资源消耗要小。
(3)高可用:生成分布式 ID 的服务要保证可用性无限接近于 100%。
(4)方便易用:拿来即用,使用方便,快速接入!
除了这些之外,一个比较好的分布式 ID 还应保证:
(1)安全:ID 中不包含敏感信息。
(2)有序递增:如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
(3)有具体的业务含义:生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
(4)独立部署:也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
【二】分布式ID常见解决方案
【1】UUID
UUID (Universally Unique Identifier) 是由数字和字母组成的 128 位标识符。Java 中可以使用 java.util.UUID 类生成:
String uuid = UUID.randomUUID().toString();
// 示例输出: 550e8400-e29b-41d4-a716-446655440000
(1)优点
本地生成,无需网络调用,性能高
全球唯一性,不依赖数据库等外部系统
实现简单,Java 内置支持
(2)缺点
字符串形式存储,占用空间大
无序性,作为数据库主键时在索引和存储方面有性能问题
可读性差,不适合作为业务标识
(3)适用场景
分布式系统中的日志记录
临时文件命名
无需排序和可读性要求的场景
【2】数据库自增id
使用数据库的自增字段(如 MySQL 的 AUTO_INCREMENT):
CREATE TABLE user (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
-- 其他字段
);
在 Spring Boot 中可以通过 JPA 或 MyBatis 实现:
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// 其他字段和方法
}
(1)优点
实现简单,数据库原生支持
有序递增,适合作为索引
数字类型,存储和查询效率高
(2)缺点
单点故障风险,依赖数据库
性能瓶颈,高并发下可能成为系统瓶颈
水平扩展困难,分库分表时需要额外处理
(3)适用场景
数据量不大、并发不高的系统
对 ID 有序性要求较高的场景
【3】数据库号段模式
每次从数据库获取一段 ID 范围,在应用内分配:
@Service
public class IdGenerator {
@Autowired
private IdSegmentRepository idSegmentRepository;
private AtomicLong currentId;
private long maxId;
private final Object lock = new Object();
public long nextId() {
if (currentId == null || currentId.get() >= maxId) {
synchronized (lock) {
if (currentId == null || currentId.get() >= maxId) {
IdSegment segment = idSegmentRepository.getNextSegment("user");
currentId = new AtomicLong(segment.getStartId());
maxId = segment.getEndId();
}
}
}
return currentId.incrementAndGet();
}
}
(1)优点
减少数据库访问频率,提高性能
有序递增,适合索引
实现相对简单
(2)缺点
仍然依赖数据库,存在单点故障风险
号段分配不均匀可能导致浪费
重启应用会丢失未使用的号段
(3)适用场景
并发中等的分布式系统
对 ID 有序性有要求的场景
【4】Redis 生成 ID
利用 Redis 的原子操作(如 INCR)生成 ID:
@Service
public class RedisIdGenerator {
@Autowired
private StringRedisTemplate redisTemplate;
public long nextId(String key) {
return redisTemplate.opsForValue().increment(key, 1);
}
// 批量获取提高性能
public List<Long> nextBatchId(String key, int batchSize) {
List<Long> ids = new ArrayList<>(batchSize);
long startId = redisTemplate.opsForValue().increment(key, batchSize);
for (int i = batchSize - 1; i >= 0; i--) {
ids.add(startId - i);
}
return ids;
}
}
(1)优点
高性能,支持高并发
有序递增,适合索引
可通过配置 Redis 集群提高可用性
(2)缺点
依赖 Redis,存在单点故障风险(需要集群)
ID 生成依赖网络,有一定延迟
重启 Redis 后可能导致 ID 不连续(如果使用持久化可能解决)
(3)适用场景
高并发系统
对 ID 有序性有要求的场景
需要高性能 ID 生成的场景
【5】⭐️Twitter Snowflake 算法
Snowflake 算法生成 64 位长整型 ID,结构如下:
(1)1 位符号位(始终为 0)
(2)41 位时间戳(毫秒级)
(3)10 位工作机器 ID(5 位数据中心 ID + 5 位机器 ID)
(4)12 位序列号(同一毫秒内的计数)
public class SnowflakeIdGenerator {
private final long startTimeStamp = 1609459200000L; // 2021-01-01
private final long workerIdBits = 5L;
private final long datacenterIdBits = 5L;
private final long sequenceBits = 12L;
private final long maxWorkerId = ~(-1L << workerIdBits);
private final long maxDatacenterId = ~(-1L << datacenterIdBits);
private final long workerIdShift = sequenceBits;
private final long datacenterIdShift = sequenceBits + workerIdBits;
private final long timestampShift = sequenceBits + workerIdBits + datacenterIdBits;
private final long sequenceMask = ~(-1L << sequenceBits);
private final long workerId;
private final long datacenterId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("Worker ID can't be greater than " + maxWorkerId + " or less than 0");
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException("Datacenter ID can't be greater than " + maxDatacenterId + " or less than 0");
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id for " + (lastTimestamp - timestamp) + " milliseconds");
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - startTimeStamp) << timestampShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
}
(1)优点
高性能,本地生成无需网络调用
有序递增,适合索引
分布式环境下不重复
可根据业务需求调整各部分位数
(2)缺点
依赖系统时钟,时钟回拨会导致生成重复 ID
机器 ID 需要预先分配和管理
起始时间固定,ID 生成时间有限制(约 69 年)
(3)适用场景
高并发分布式系统
对 ID 有序性和性能有较高要求的场景
数据量较大的系统
【6】美团 Leaf 方案
Leaf 是美团开源的分布式 ID 生成系统,结合了数据库号段模式和 Snowflake 算法的优点:
(1)Leaf-segment:基于数据库号段模式,优化了高并发场景
(2)Leaf-snowflake:基于 Snowflake 算法,解决了时钟回拨问题
// Leaf-segment 模式的简化实现示例
@Service
public class LeafSegmentIdGenerator {
@Autowired
private LeafAllocMapper leafAllocMapper;
private ConcurrentMap<String, SegmentBuffer> cache = new ConcurrentHashMap<>();
public Result get(String key) {
SegmentBuffer buffer = cache.get(key);
if (buffer == null) {
synchronized (this) {
buffer = cache.get(key);
if (buffer == null) {
buffer = initSegmentBuffer(key);
cache.put(key, buffer);
}
}
}
return getIdFromSegmentBuffer(buffer);
}
// 其他方法...
}
(1)优点
高性能,支持高并发
有序递增,适合索引
解决了 Snowflake 的时钟回拨问题
支持多种生成策略,可根据需求选择
(2)缺点
实现复杂,需要维护专门的服务
依赖数据库或 Zookeeper 等组件
学习成本较高
(3)适用场景
大规模分布式系统
对 ID 生成有严格要求的场景
需要统一 ID 管理的场景
【7】百度 UidGenerator
UidGenerator 是百度开源的分布式 ID 生成器,基于 Snowflake 算法并进行了优化:
(1)采用环形数组缓存已生成的 ID
(2)优化了时钟回拨问题
(3)支持批量生成
// 使用 UidGenerator 的示例
@Service
public class UidGeneratorService {
@Autowired
private DefaultUidGenerator uidGenerator;
public long getUid() {
return uidGenerator.getUID();
}
public String parseUid(long uid) {
return uidGenerator.parseUID(uid);
}
}
自 18 年后,UidGenerator 就基本没有再维护了
(1)优点
高性能,本地生成无需网络调用
解决了 Snowflake 的时钟回拨问题
支持批量生成,提高效率
可解析 ID 结构,便于调试
(2)缺点
实现复杂,需要引入第三方库
机器 ID 需要预先分配和管理
依赖系统时钟
(3)适用场景
高并发分布式系统
对 ID 生成性能有较高要求的场景
需要解析 ID 结构的场景
【三】Hutool 中生成分布式 ID 的方法和案例
【1】Snowflake 算法实现
Hutool 提供了 Snowflake 类实现 Twitter 的 Snowflake 算法,生成 64 位长整型 ID:
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.net.NetUtil;
import cn.hutool.core.util.IdUtil;
public class SnowflakeIdDemo {
public static void main(String[] args) {
// 方法一:使用默认配置创建 Snowflake
Snowflake snowflake = IdUtil.createSnowflake(1, 1);
long id1 = snowflake.nextId();
System.out.println("Snowflake ID: " + id1);
// 方法二:使用工具类直接生成 ID(自动分配 workerId 和 datacenterId)
long id2 = IdUtil.getSnowflakeNextId();
System.out.println("Auto Snowflake ID: " + id2);
// ⭐️方法三:使用 NetUtil 自动获取机器 ID
long workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());
workerId = workerId >> 16 & 31; // 取低 5 位作为 workerId
Snowflake customSnowflake = IdUtil.createSnowflake(workerId, 1);
long id3 = customSnowflake.nextId();
System.out.println("Custom Snowflake ID: " + id3);
}
}
高性能,本地生成无需网络调用
有序递增,适合作为数据库索引
分布式环境下不重复
支持自定义 workerId 和 datacenterId
【2】UUID 生成
Hutool 提供了更便捷的 UUID 生成方法:
import cn.hutool.core.util.IdUtil;
public class UuidDemo {
public static void main(String[] args) {
// 生成带分隔符的 UUID
String uuid1 = IdUtil.randomUUID();
System.out.println("Random UUID: " + uuid1);
// 生成不带分隔符的 UUID
String uuid2 = IdUtil.simpleUUID();
System.out.println("Simple UUID: " + uuid2);
// 基于指定字符串生成 UUID(相同输入生成相同输出)
String uuid3 = IdUtil.fastUUID();
System.out.println("Fast UUID: " + uuid3);
// 基于 MD5 生成 UUID
String uuid4 = IdUtil.md5UUID("your-input-string");
System.out.println("MD5 UUID: " + uuid4);
// 生成随机数字 ID
String randomNumberId = IdUtil.randomUUID().replaceAll("-", "").substring(0, 16);
System.out.println("Random Number ID: " + randomNumberId);
// 生成随机字母数字 ID
String randomStrId = IdUtil.fastSimpleUUID();
System.out.println("Random String ID: " + randomStrId);
// 生成时间戳 ID
String timestampId = String.valueOf(System.currentTimeMillis());
System.out.println("Timestamp ID: " + timestampId);
}
}
简单易用,无需配置
全球唯一,不依赖外部系统
提供多种生成方式,满足不同需求
【3】ObjectId (MongoDB ID)
Hutool 提供了生成 MongoDB ObjectId 的方法:
import cn.hutool.core.util.IdUtil;
public class ObjectIdDemo {
public static void main(String[] args) {
// 生成 ObjectId
String objectId = IdUtil.objectId();
System.out.println("ObjectId: " + objectId);
// 判断是否为有效的 ObjectId
boolean isValid = IdUtil.isValidObjectId(objectId);
System.out.println("Is valid ObjectId: " + isValid);
}
}
12 字节的 BSON 类型,包含时间戳、机器标识、进程 ID 和计数器
适合分布式系统中的文档标识
有序性不如 Snowflake,但比 UUID 更有序
【4】注意事项
(1)Snowflake 的 workerId 和 datacenterId:
在分布式环境中,每个节点的 workerId 和 datacenterId 必须唯一
可以通过配置文件、数据库或 ZooKeeper 等方式分配
(2)时钟回拨问题:
Snowflake 算法依赖系统时钟,时钟回拨会导致生成重复 ID
Hutool 的 Snowflake 实现了简单的时钟回拨处理,但极端情况下可能需要更复杂的解决方案
(3)性能考虑:
UUID 生成性能较高,但无序且占用空间大
Snowflake 性能也很高,且生成有序 ID,适合作为数据库索引
(4)ID 长度:
Snowflake 生成的 ID 为 64 位长整型,适合数据库存储
UUID 为 128 位,通常以字符串形式存储,占用空间较大
【5】总结
Hutool 提供了多种分布式 ID 生成方式,适用于不同场景:
(1)Snowflake:高性能、有序递增,适合分布式系统中的唯一标识
(2)UUID:简单易用、全球唯一,适合临时文件命名、日志追踪等
(3)ObjectId:MongoDB 风格的 ID,适合文档标识
【四】实际使用案例
通过工厂模式和策略模式设计一个灵活的分布式 ID 生成器,支持多种 ID 生成策略。
【1】策略接口设计
首先定义 ID 生成策略的接口:
/**
* ID生成策略接口
*/
public interface IdGenerator {
/**
* 生成ID
* @return 生成的ID
*/
String nextId();
}
【2】具体策略实现
(1)随机算法UUID
@Component
public class RandomNumeric implements IIdGenerator {
@Override
public long nextId() {
return RandomStringUtils.randomNumeric(11);
}
}
(2)日期算法
用于生成活动编号类,特性是生成数字串较短,但指定时间内不能生成太多
@Component
public class ShortCode implements IIdGenerator {
@Override
public synchronized long nextId() {
Calendar calendar = Calendar.getInstance();
int year = calendar.get(Calendar.YEAR);
int week = calendar.get(Calendar.WEEK_OF_YEAR);
int day = calendar.get(Calendar.DAY_OF_WEEK);
int hour = calendar.get(Calendar.HOUR_OF_DAY);
// 打乱排序:2020年为准 + 小时 + 周期 + 日 + 三位随机数
StringBuilder idStr = new StringBuilder();
idStr.append(year - 2020);
idStr.append(hour);
idStr.append(String.format("%02d", week));
idStr.append(day);
idStr.append(String.format("%03d", new Random().nextInt(1000)));
return idStr.toString();
}
}
(3)雪花算法
生成订单号
@Component
public class SnowFlake implements IIdGenerator {
private Snowflake snowflake;
@PostConstruct
public void init() {
// 0 ~ 31 位,可以采用配置的方式使用
long workerId;
try {
workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());
} catch (Exception e) {
workerId = NetUtil.getLocalhostStr().hashCode();
}
workerId = workerId >> 16 & 31;
long dataCenterId = 1L;
snowflake = IdUtil.createSnowflake(workerId, dataCenterId);
}
@Override
public synchronized String nextId() {
return String.valueOf(snowflake.nextId());
}
}
(4)redis策略
例如生成业务编码
/**
* Redis生成ID策略
*/
public class RedisIdGenerator implements IdGenerator {
private final StringRedisTemplate redisTemplate;
private final String keyPrefix;
public RedisIdGenerator(StringRedisTemplate redisTemplate, String keyPrefix) {
this.redisTemplate = redisTemplate;
this.keyPrefix = keyPrefix;
}
@Override
public String nextId() {
String key = keyPrefix + ":" + LocalDate.now().format(DateTimeFormatter.BASIC_ISO_DATE);
Long increment = redisTemplate.opsForValue().increment(key, 1);
if (increment == 1) {
// 设置过期时间,防止key堆积
redisTemplate.expire(key, 24, TimeUnit.HOURS);
}
return key + ":" + increment;
}
}
【3】策略工厂
/**
* ID生成器工厂
*/
public class IdGeneratorFactory {
private final Map<String, IdGenerator> generators = new HashMap<>();
/**
* 注册ID生成器
* @param type 生成器类型
* @param generator 生成器实例
*/
public void registerGenerator(String type, IdGenerator generator) {
generators.put(type, generator);
}
/**
* 获取ID生成器
* @param type 生成器类型
* @return 生成器实例
*/
public IdGenerator getGenerator(String type) {
IdGenerator generator = generators.get(type);
if (generator == null) {
throw new IllegalArgumentException("不支持的ID生成类型: " + type);
}
return generator;
}
/**
* 支持的生成器类型
* @return 支持的类型列表
*/
public Set<String> getSupportedTypes() {
return generators.keySet();
}
}
【4】配置和初始化
/**
* ID生成器配置类
*/
@Configuration
public class IdGeneratorConfig {
@Autowired
private StringRedisTemplate redisTemplate;
@Bean
public IdGeneratorFactory idGeneratorFactory() {
IdGeneratorFactory factory = new IdGeneratorFactory();
// 注册UUID生成器
factory.registerGenerator("uuid", new UuidGenerator());
// 注册Redis生成器
factory.registerGenerator("redis", new RedisIdGenerator(redisTemplate, "id:seq"));
// 注册雪花算法生成器 (workerId和datacenterId可以从配置中获取)
factory.registerGenerator("snowflake", new SnowflakeIdGenerator(1L, 1L));
return factory;
}
}
【5】使用示例
@Service
public class OrderService {
private final IdGeneratorFactory idGeneratorFactory;
@Autowired
public OrderService(IdGeneratorFactory idGeneratorFactory) {
this.idGeneratorFactory = idGeneratorFactory;
}
public String createOrder(OrderDTO orderDTO) {
// 根据配置选择ID生成策略
String idType = "snowflake"; // 可以从配置中获取
IdGenerator generator = idGeneratorFactory.getGenerator(idType);
String orderId = generator.nextId();
// 创建订单逻辑
Order order = new Order();
order.setId(orderId);
order.setUserId(orderDTO.getUserId());
order.setAmount(orderDTO.getAmount());
// 其他设置...
orderRepository.save(order);
return orderId;
}
}