前言
PostgreSQL(简称 pgsq1)作为功能强大的开源关系型数据库,以其稳定性扩展性和对 SQL 标准的严格遵循,广泛应用于企业级开发与数据分析场景。本课件将围绕 pgsq1 的日常使用展开,涵盖从基础登录到核心操作的完整流程。通过模块化学习,你将掌握数据库连接管理、库表创建与操作、模式(Schema)设计、远程访问权限配置以及账户安全维护等关键技能。无论你是数据库初学者还是运维人员,本内容均能帮助你系统化建立pgsql的基础操作能力,为高效管理和开发数据库应用奠定基础。
一. 基本使用
1. 登录数据库
Pgsql 登录时,必须使用 postgres 用户,登录后的命令提示符为“postgres=#postgres 表示你当前所在的库
2. 数据库操作
(1)列出库
常用的三种方法如下:
方法一:
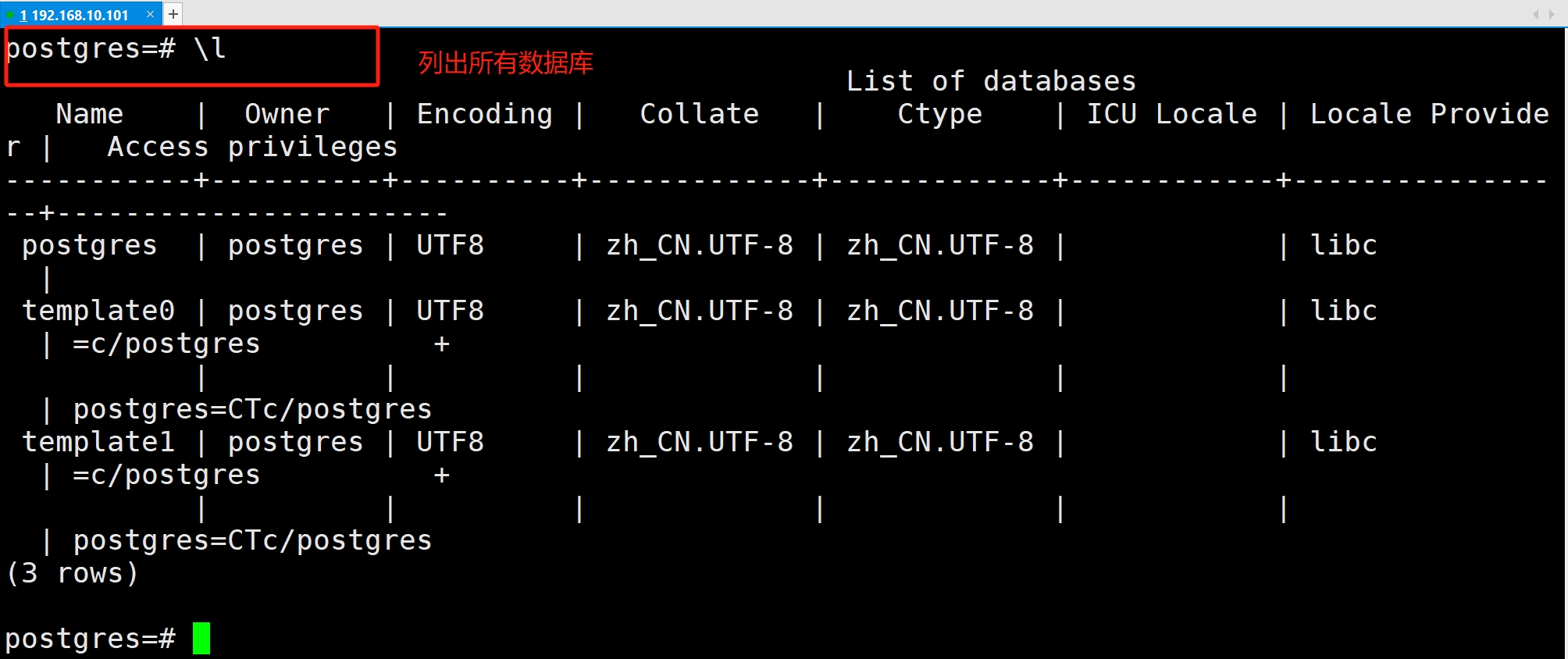
在PostgreSQL 的交互式终端 psql 中,““"开头的命令称为元命令(类似MySQL的SHOW语句),用于快速管理数据库
常用的元命令有:
| 元 | 含义 |
|---|---|
| \l | 列出所有数据库 |
| \c | [数据库名1或 \connect[数据库名] |
| \dn | 列出所有模式(Schema) |
| \db | 列出所有表空间 |
| \ ? | 显示 pgsq1 命令的说明(元命令査询帮助) |
| \q | 退出 psql |
| \dt | 列出当前数据库的所有表 |
| \d [TABLE] | 查看表结构 |
| \du | 列出所有用户 |
方法二:
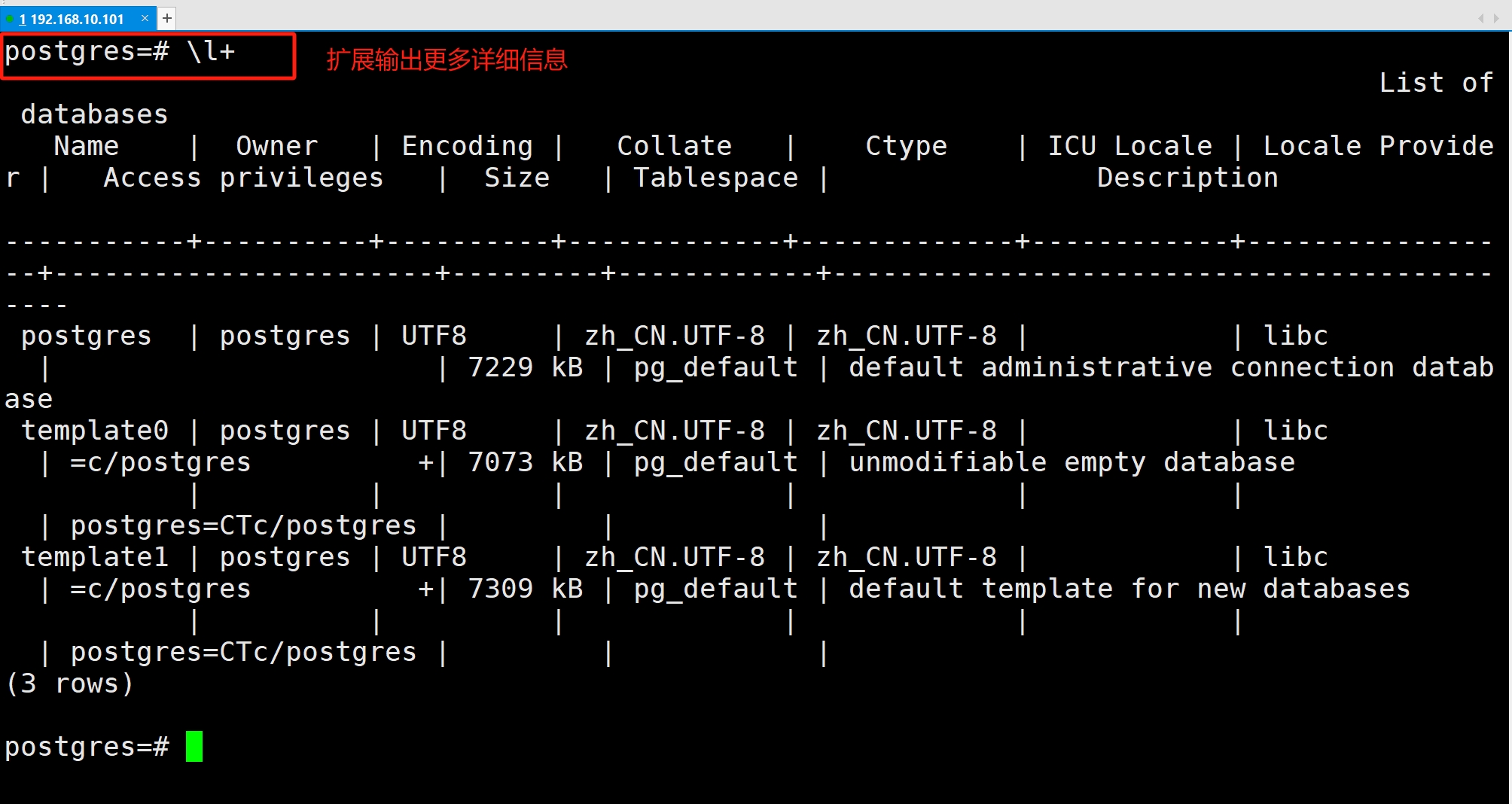
\l+的输出比\l多了Size,Tablespace 和 Description 列
| 含义 | |
|---|---|
| + | 扩展输出,显示更多字段或详细信息 |
方法三:
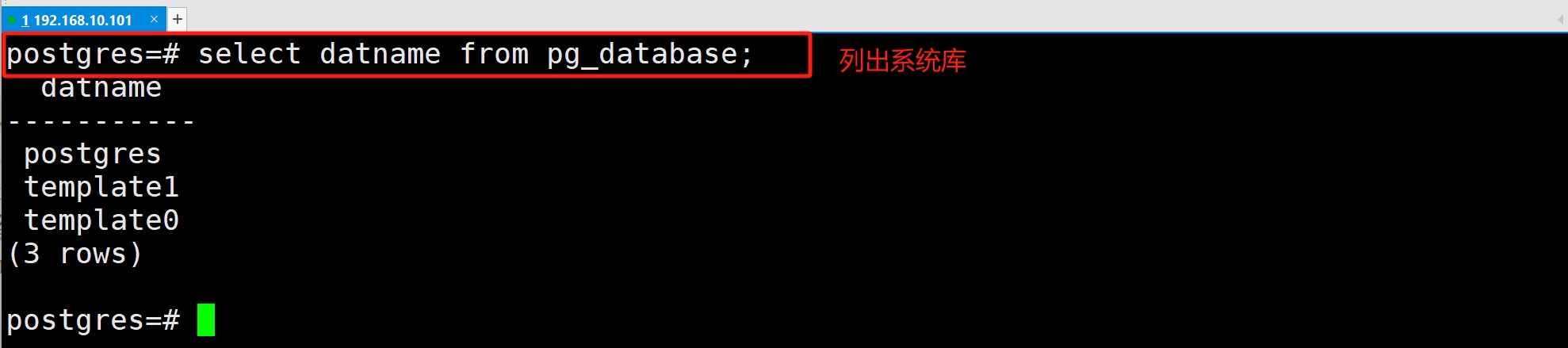
使用SQL 命令
| 含义 | |
|---|---|
| pg_database | 是系统表:它存储了 PostgreSQL 实例中所有数据库的元信息(如数据库名称、所有者、编码等)。属于系统目录(System Catalog):类似 MySQL的 information schema,但 PostgreSQl 的系统目录更底层且直接存储在pg catalog 模式中 |
| pg_database | 是系统目录表,所以无论当前连接到哪个数据库,该表始终可见系统表默认属于pg_catalog 模式,而pg_catalog 始终位于搜索路径(searchpath)的首位。因此,查询时无需显式指定模式(如pg catalog.pg database) |
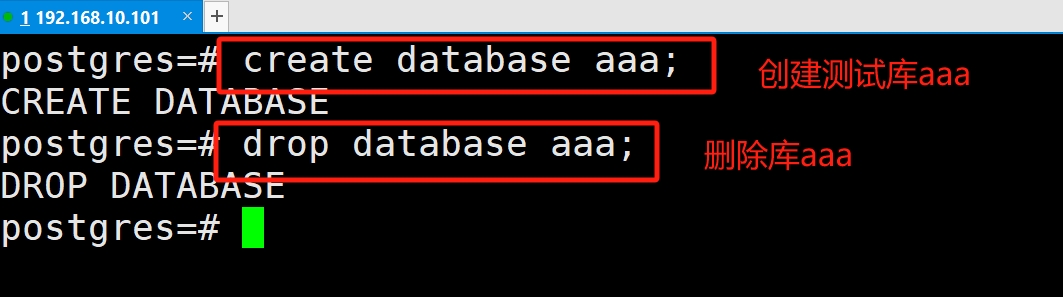
(2)创建库

(3)删除库
(4)切换库

(5)查看库大小
函数以字节为单位返回数据库的大小
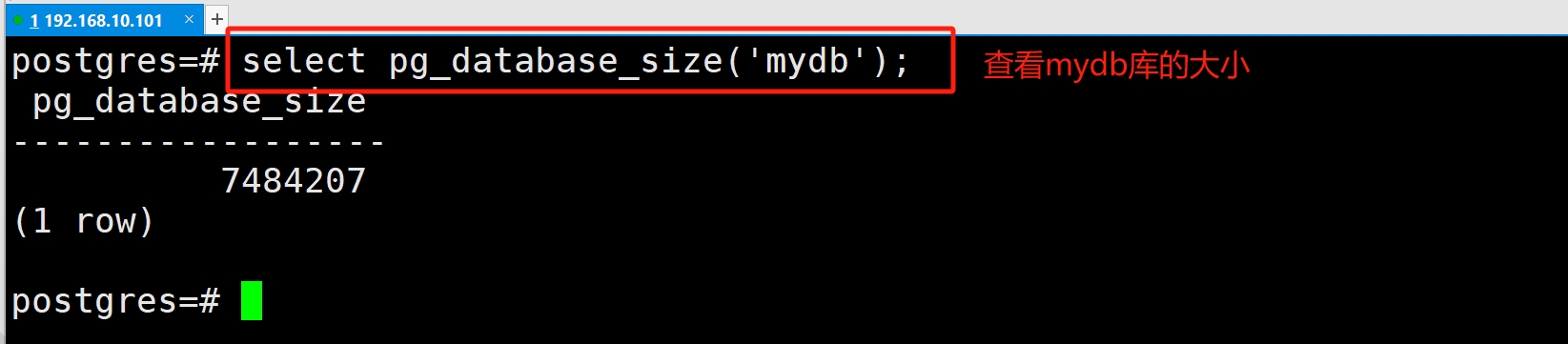
pg_size_pretty()函数将字节转为更易于阅读值

3. 数据表操作
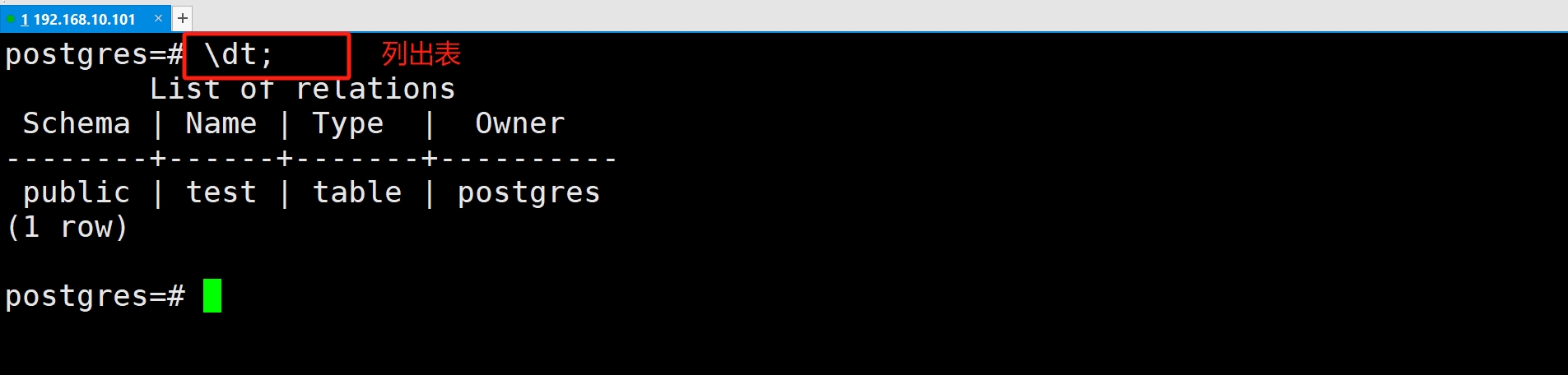
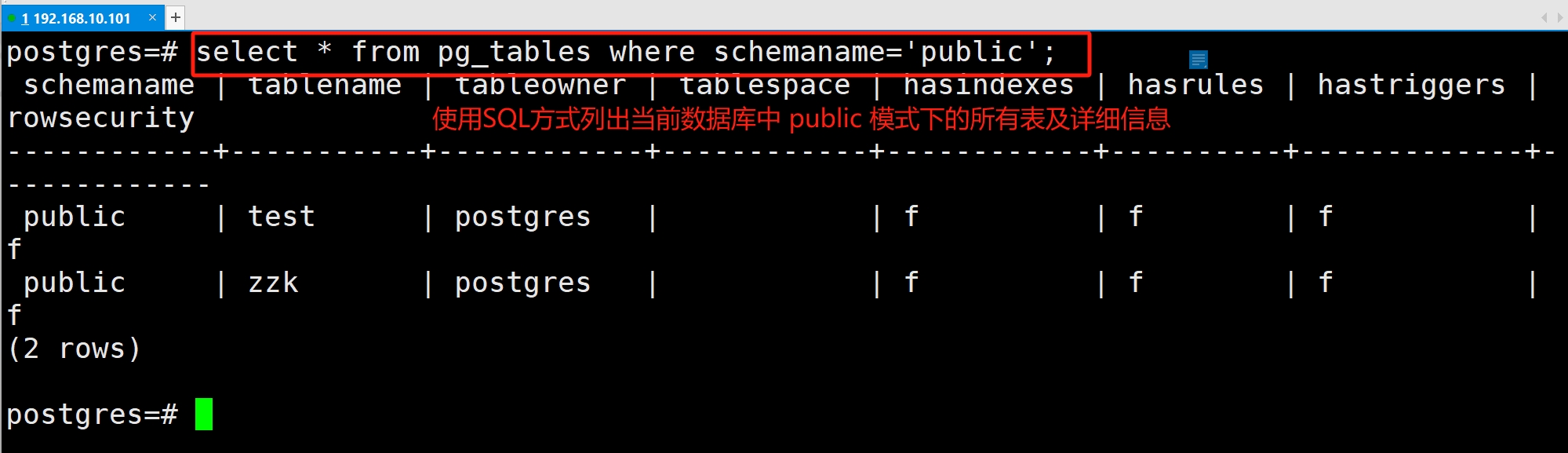
(1)列出表
列出表的常用方法:

(2)创建表
PostgreSQL 支持标准的 SQL类型 int、smallint、real、double precision、char(N)、varchar(N)、date、time、timestamp 和 interval,还支持其他的通用功能的类型和丰富的几何类型。PostgreSqL中可以定制任意数量的用户定义数据类型。因而类型名并不是语法关键字,除了SQL 标准要求支持的特例外

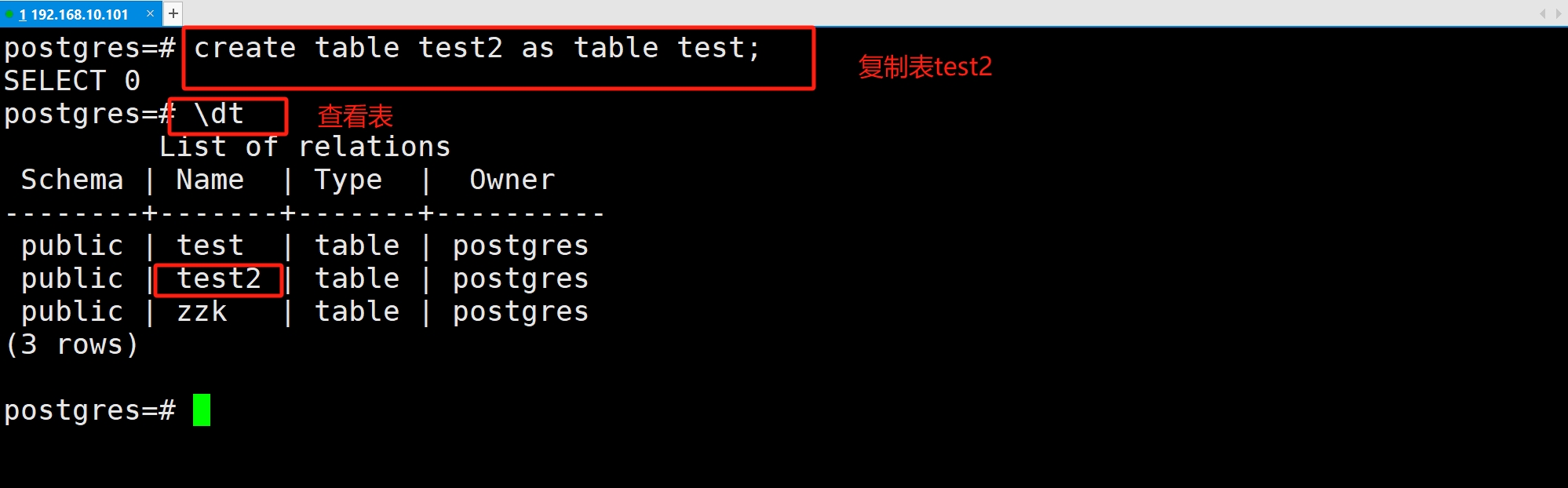
(3)复制表
要将已有的 table_name 表复制为新表 new_table,包括表结构和数据,请使用以下语句
| CREATE TABLE new table AS TABLE table name |
|---|
例如:
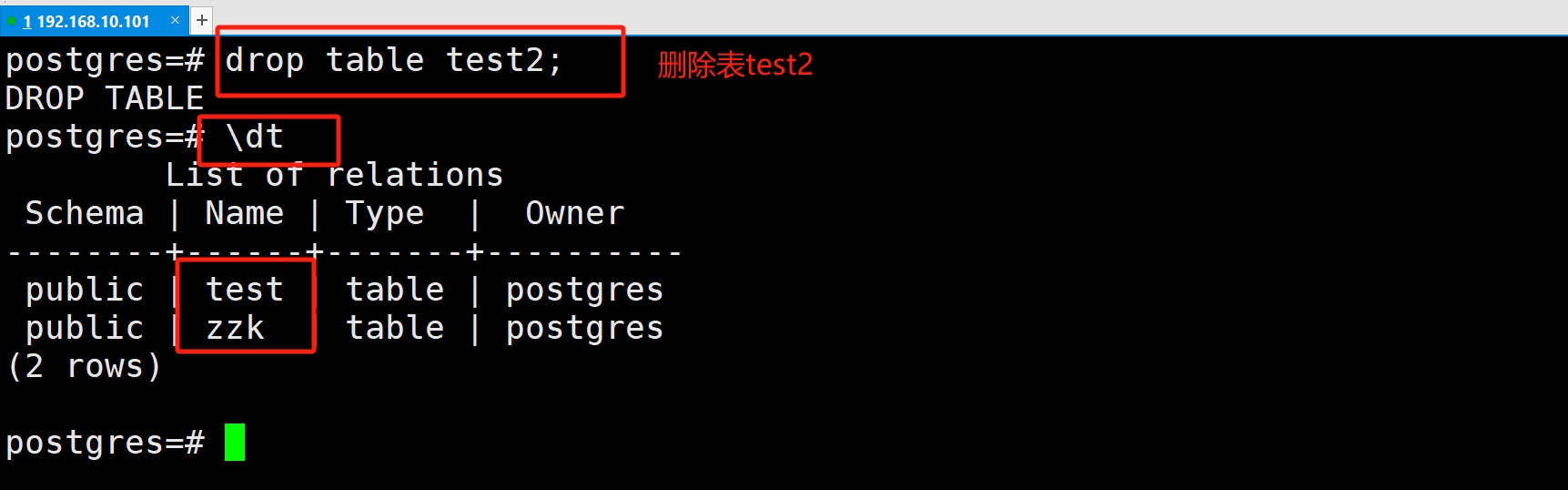
(4)删除表
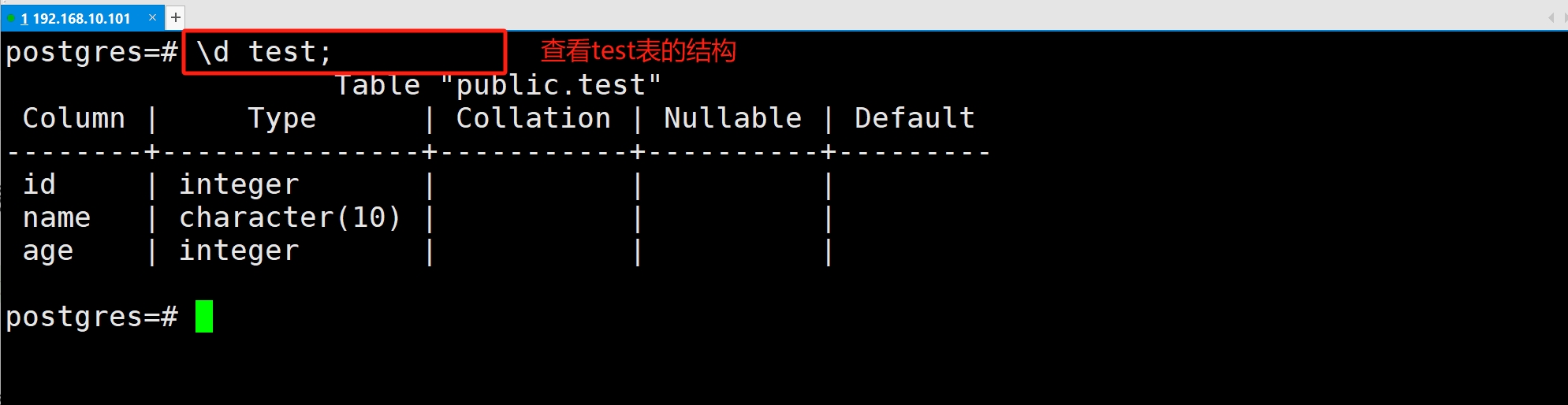
(5)查看表结构
4. 模式操作命令
是一个逻辑容器,用于组织和管理数在 PostgreSQL 中,模式(Schema)它类似于文件系统中的文件夹,帮助据库对象(如表、视图、函数、索引等)。你在同一个数据库中分类存储不同的对象,避免命名冲突,并实现权限隔离
(1)创建模式
在当前库 postgres 中创建名为 hr 的模式

(2)默认模式
PostgreSQl 每个数据库都有一个默认模式 public
如果创建对象(表、视图等)时不指定模式,默认会放在 public 模式中

(3)删除模式

强制删除模式及其所有对象
postgres=# DROP SCHEMA hr CASCADE;
DROP SCHEMA
(4)查看所有模式
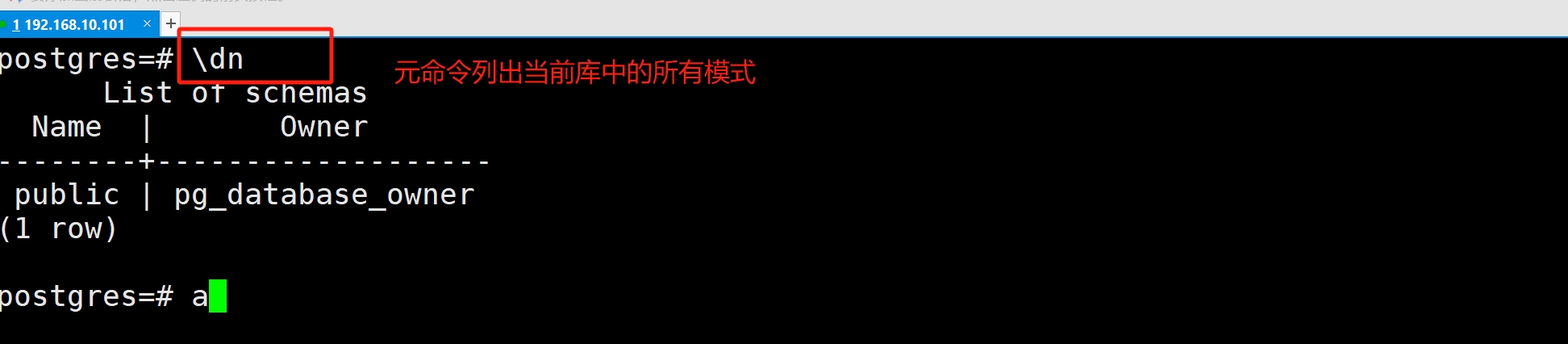
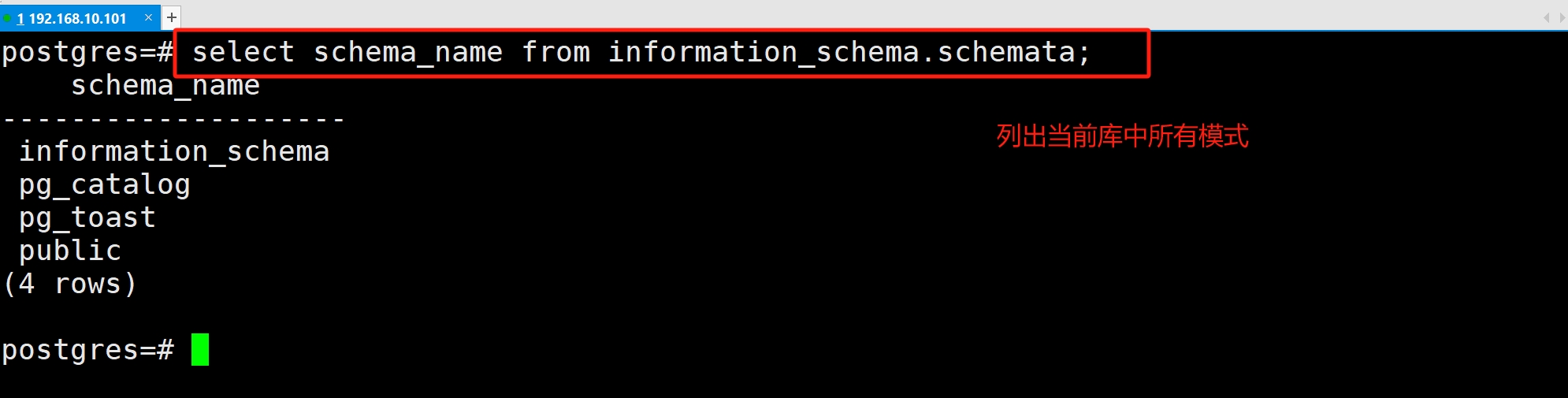
(5)在指定模式中创建表
未指定模式时,创建的对象(表,视图等)会按search path 顺序创建到第一个可用的模式中
在 postgres 库中的 hr 模式下创建一个名为 employees 的库

(6)切换当前模式
切换模式也就是调整 search_path 的搜索范围
切换到单个 schema

切换到多个 schema(按优先级顺序)

表示优先搜索 hr 模式,其次 public
(7)查看当前所在 schema
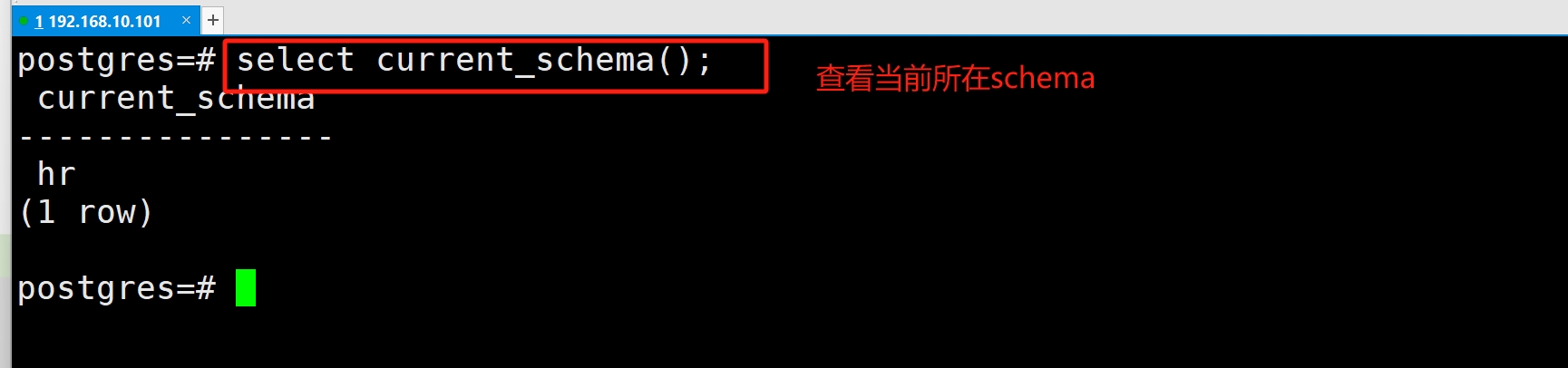
(8)查看搜索路径(Search Path)
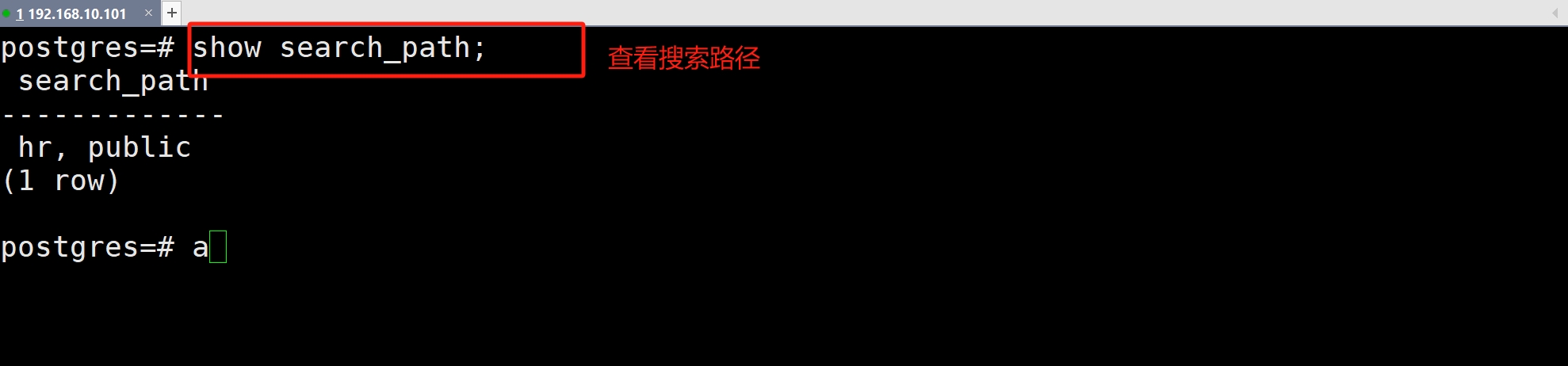
(9)PostgreSQL 的模式隔离性
PostgreSQl 的模式是数据库内的逻辑分组,不同模式可以存在同名表。这也是和 mysql 的不同之处
跨模式查询需显式指定模式名(如 schema1.users),或通过 search path 设置默认模式
无需切换数据库连接,所有操作在同一数据库内完成
步骤1:创建一个数据库
创建数据库 pg

切换到pg

步骤2:在数据库中创建两个模式
创建模式 sc1 和 s2

步骤3:在每个模式中创建同名表,并插入数据
在 sc1中创建 users 表


在 sc2 中创建同名 users 表

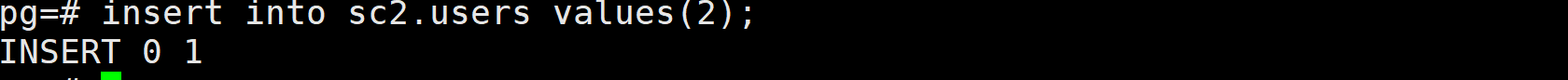
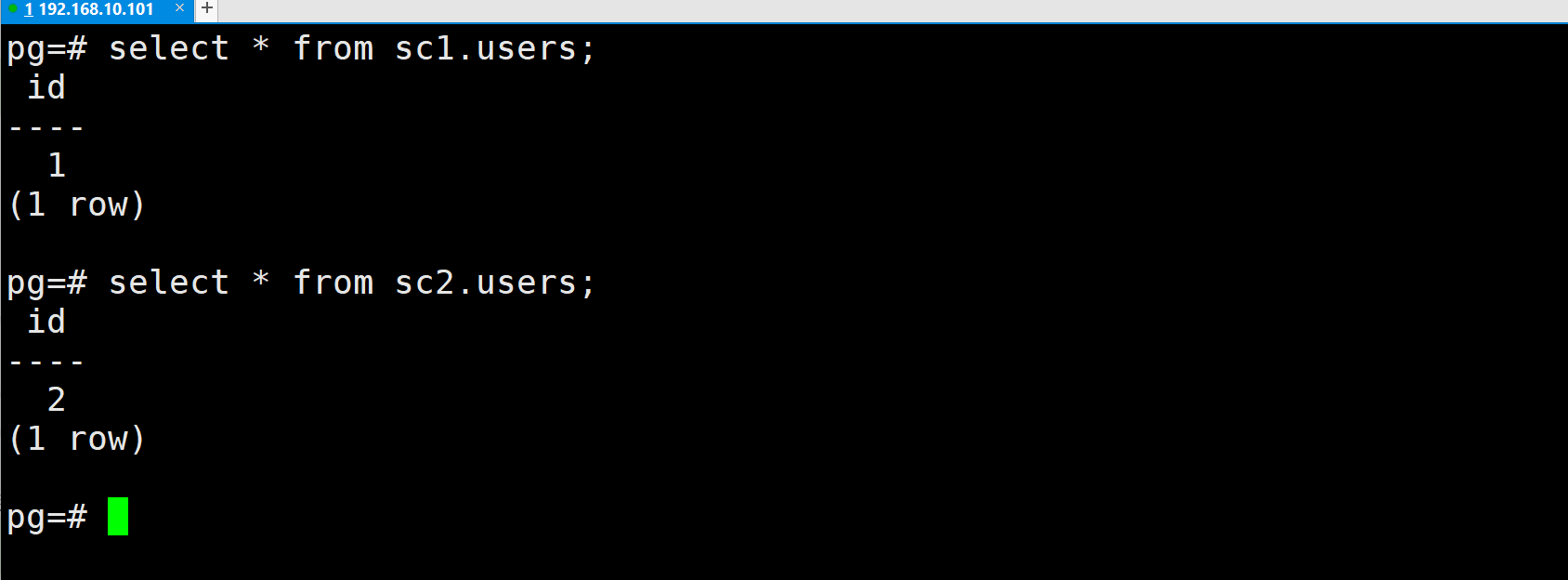
步骤 4:跨模式查询
查询 sc1.users 和 sc2.users(需显式指定模式名)
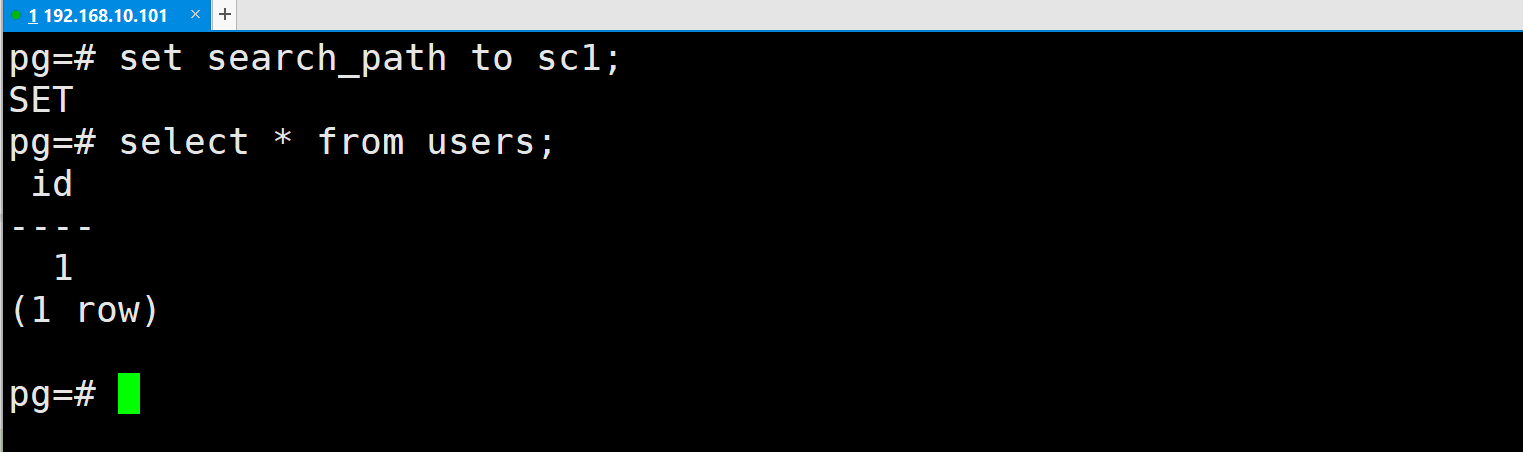
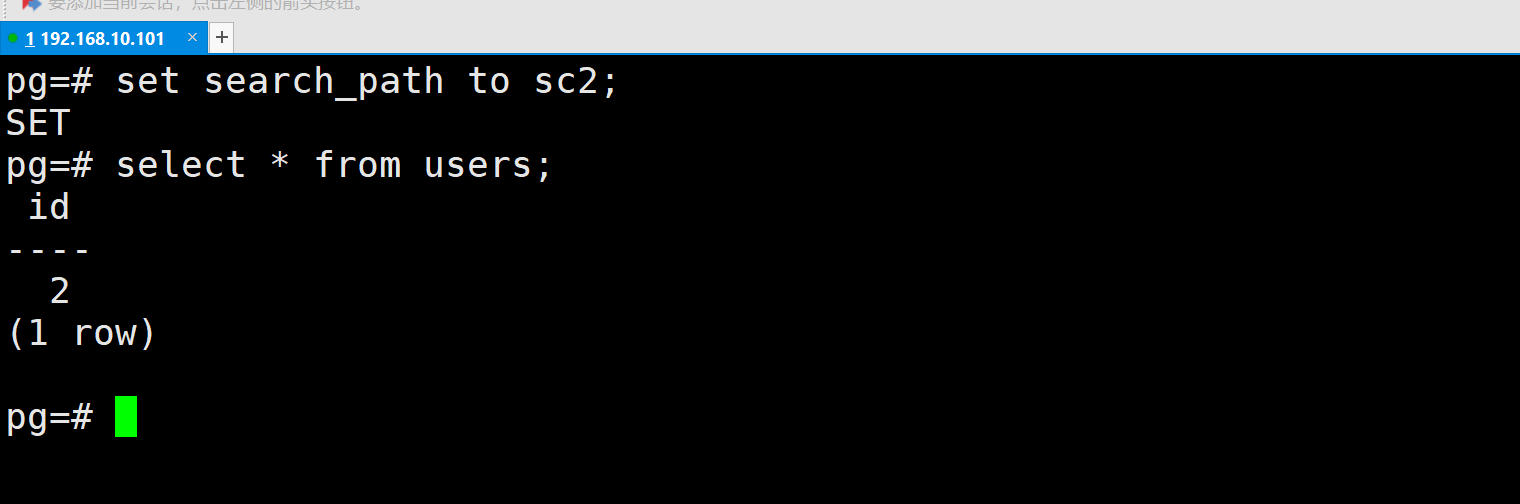
设置 search_path 切换默认模式(不需显式指定模式名)
5. 数据操作
(1)添加数据
在 postgres 库,新建表 tt1

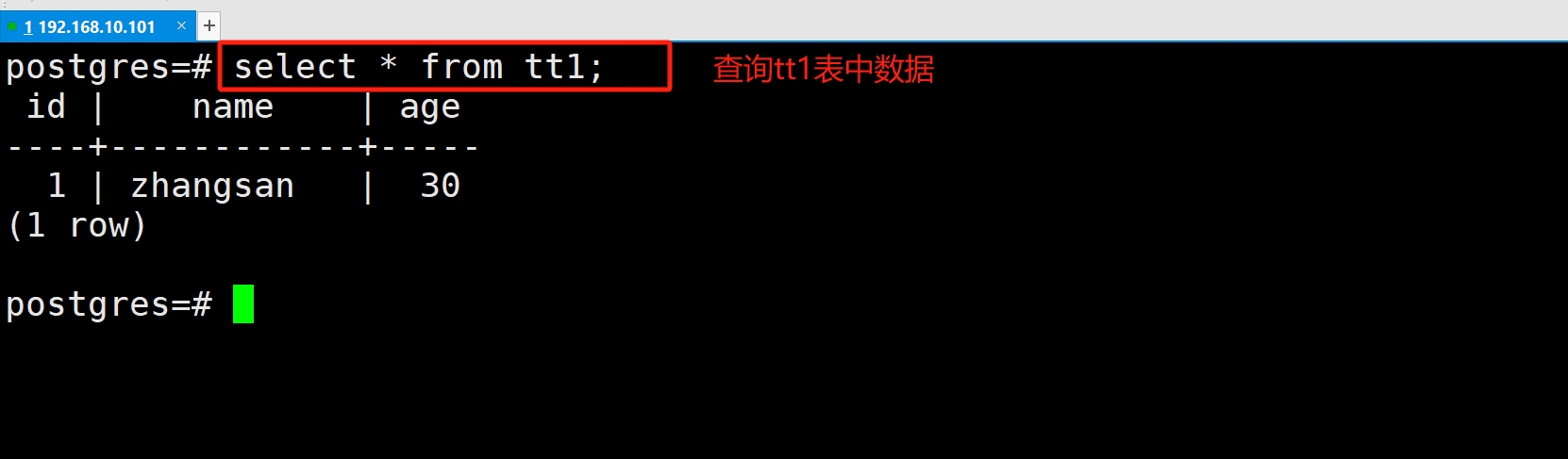
(2)查询数据
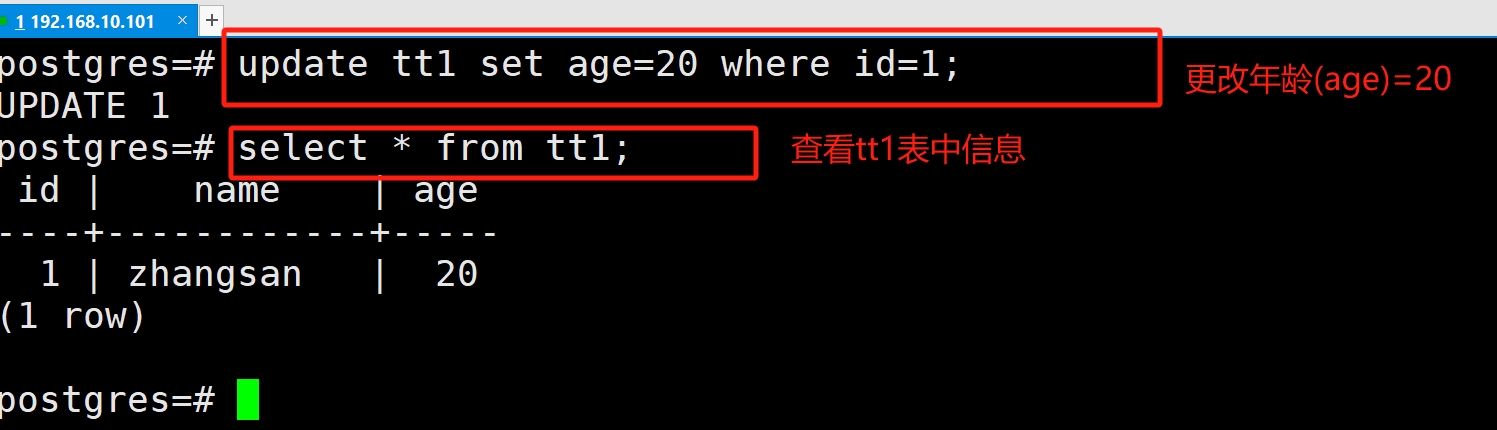
(3)修改数据
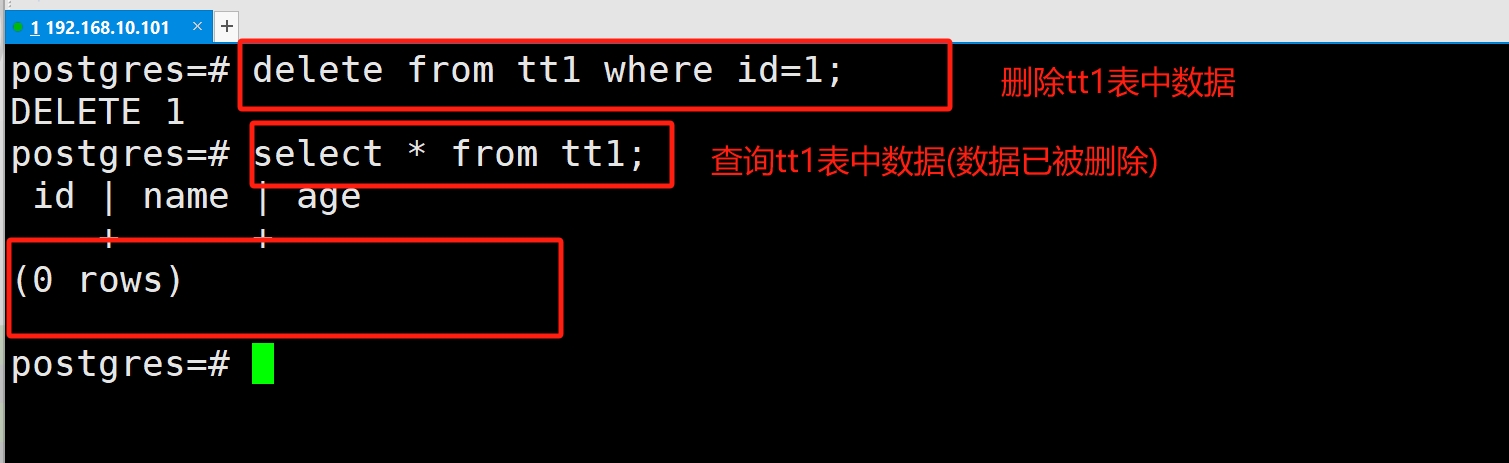
(4)删除数据
6. 备份与恢复
PostgreSQL 数据库应当被定期地备份。虽然过程相当简单,但清晰地理解其底层技术和假设是非常重要的。
有三种不同的基本方法来备份 PostgreSQL 数据:
- SQL 转储
- 文件系统级备份
- 连续归档
(1)SQL 转储
SQL转储方法的思想是创建一个由 SQL,命令组成的文件,当把这个文件回馈给服务器时,服务器将利用其中的SQL命令重建与转储时状态-样的数据库。PostgreSQl为此提供了工具pg dump。这个工具的基本用法是:
| pg dump dbname >dumpfile |
|---|

正如你所见,pg_dump 把结果输出到标准输出。我们后面将看到这样做有什么用处。 尽管上述命令会创建一个文本文件,pg_dump 可以用其他格式创建文件以支持并行 和细粒度的对象恢复控制
pg dump 是一个普通的 PostgreSQL,客户端应用(尽管是个 相当聪明的东西)这就意味着你可以在任何可以访问该数据库的远端主机上进行条份工作。但是请记住pg dump不会以任何特殊权限运行。具体说来,就是它必须要有你想备份的表的读 权眼,因此为了备份整个数据库你几平总是必须以一个数据库超级用户来运行它(如果你没有足够的特权 来备份整个数据库,你仍然可以使用诸如或-ttable 选项来备份该数据库中你能够 访问的部分)。
要声明pg_dump连接哪个数据库服务器,使用命令行选项-hhost和 -ppor。默认主机是本地主机或你的 PGHOST 环境变量指定的主机。 类似地,.默认端口是环境变量 PGPORT 或(如果 PGPORT不存在)内建的默认值。(服务器通常有相同的默认值,所以还算方便。
和任何其他 PostgreSQL 客户端应用一样, pg dump 默认使用与当前操作系统用户名同名的数据库用户名进行连接。要使用其他名字,要么声明-U选项,要么设置环境变量 PGUSER。请注意 pg dump 的连接也要通过客户认证机制
pg dump 对于其他备份方法的一个重要优势是,pg dump 的输出可以很容易地在新版本的 PostgreSQL 中载入,而文件级备份和连续归档都是极度的服务器版本限定的。pg dump 也是唯一可以将一个数据库传送到一个不同机器架构上的方法,例如从一个 32 位服务器到一个 64 位服务器
由 pg dump 创建的备份在内部是一致的,也就是说,转储表现了 pg dump开始运行时刻的数据库快照,且在 pg dump 运行过程中发生的更新将不会被转储pq dump 工作的时候并不阻塞其他的对数据库的操作(但是会阳塞那些需要排它锁的操作,比如大部分形式的ALTER TABLE)
(2)从转储中恢复
pg_dump 生成的文本文件可以由 psql 程序读取。 从转储中恢复的常用命令是:
| psql dbname< dumpfile |
|---|
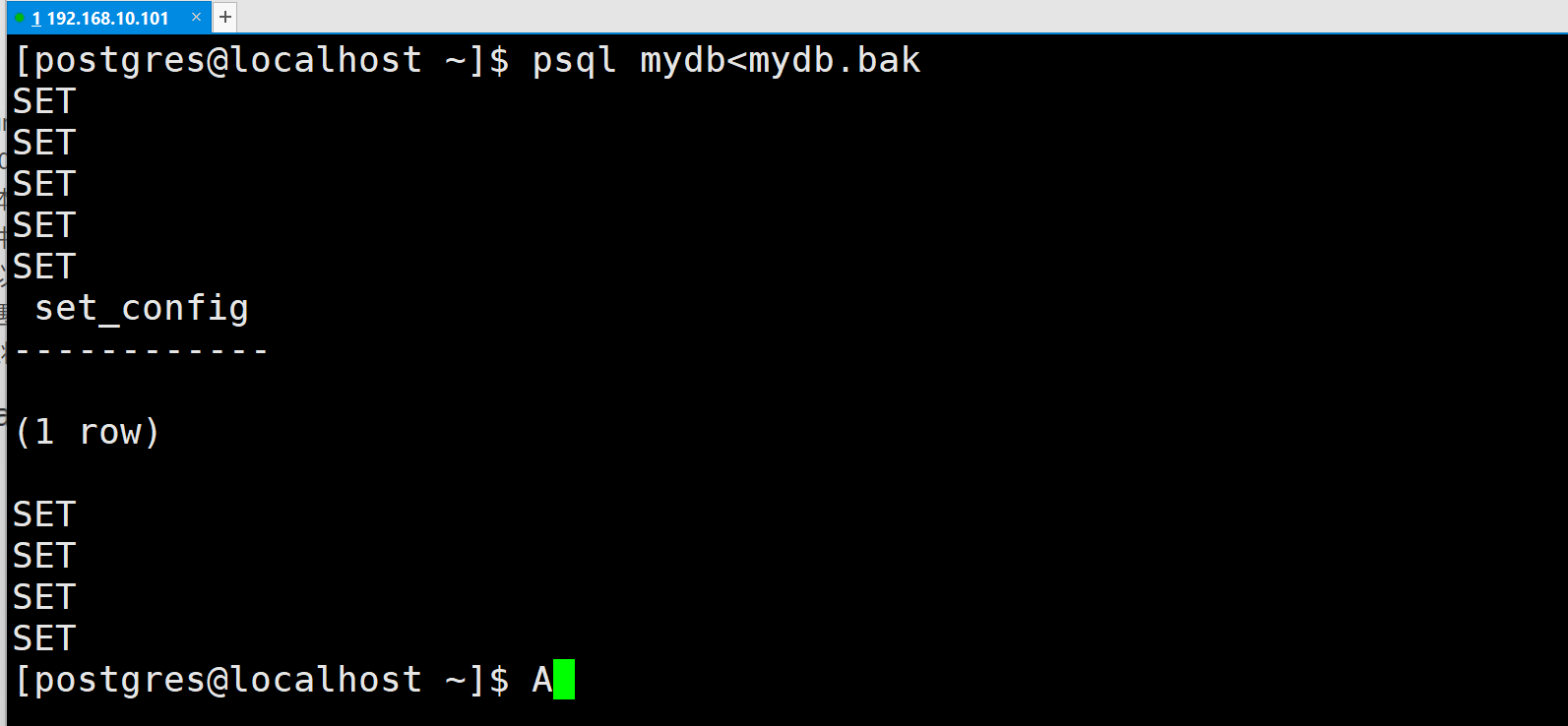
其中 dumpfile 就是 pg dump 命令的输出文件。这条命令不会创建数据库dbname,你必须在执行 psql 前自己从 template0 创建(例如,用命令 createdb-Ttemplate0 dbname)。psql 支持类似pg dump 的选项用以指定要连接的数据库服务器和要使用的用户名。参阅 psql的手册获取更多信息.非文本文件转储可以使用 pg restore 工具来恢复
在开始恢复之前,转储库中对象的拥有者以及在其上被授予了权限的用户必须已经存在。如果它们不存在,那么恢复过程将无法将对象创建成具有原来的所属关系以及权限(有时候这就是你所需要的,但通常不是)
默认情况下,psq1 脚本在遇到一个 SQL 错误后会继续执行。你也许希望在遇到一个 SQL, 错误后让 psql 退出,那么可以设置 ON ERROR STOP 变量来运行 psql,这将使 psq1 在遇到 SQL 错误后退出并返回状态 3:
| psql --set ON ERROR STOP=on dbname< infile |
|---|
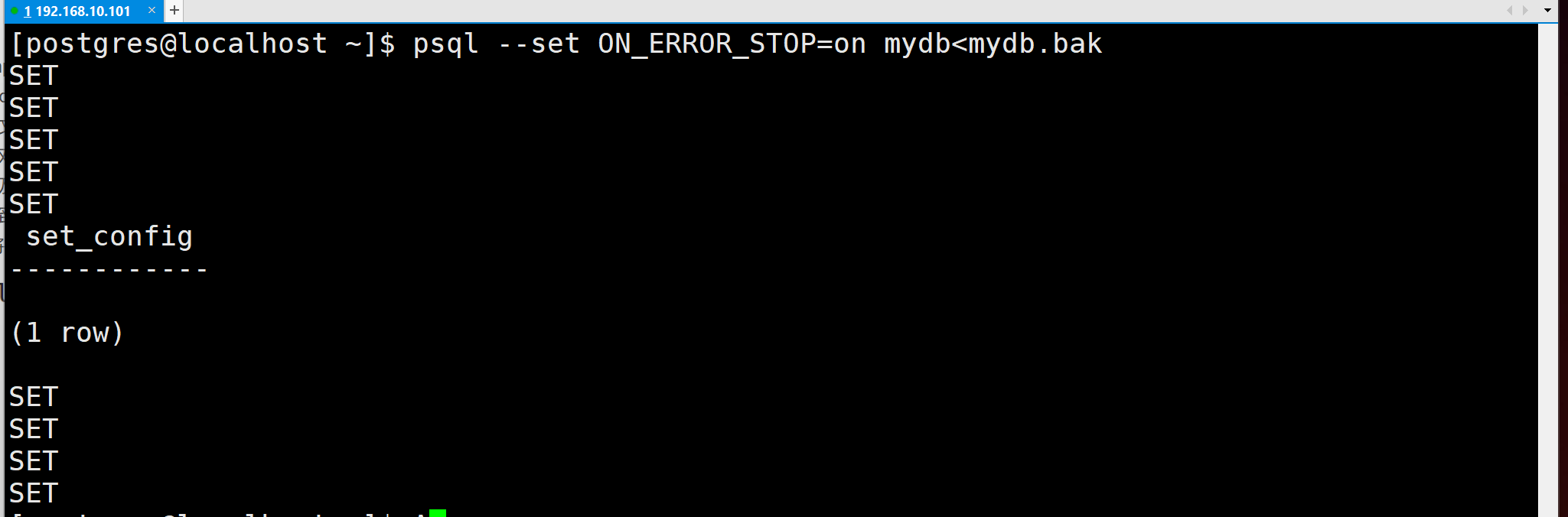
不管怎样,你将只能得到一个部分恢复的数据库。作为另一种选择,你可以指定让整个恢复作为一个单独的事务运行,这样恢复要么完全完成要么完全回滚这种模式可以通过向 psql 传递-1 或–single-transaction 命令行选项来指定。在使用这种模式时,注意即使是很小的一个错误也会导致运行了数小时的恢复被回滚。但是,这仍然比在一个部分恢复后手工清理复杂的数据要更好
pg dump和 psql 读写管道的能力使得直接从一个服务器转储一个数据库到另一个服务器成为可能,例如:
| pg dump -h hostl dbnamepsgl -h host2 dbname |
|---|
注意:
pg_dump 产生的转储是相对于 template0。这意味着在 templatel 中加入的任何语言、过程等都会被 pg dump 转储。结果是,如果在恢复时使用的是一个自定义的 template1,你必须从 template0 创建一个空的数据库,正如上面的例子所示
一旦完成恢复,在每个数据库上运行ANALYZE是明智的举动,这样优化器就有有用的统计数据了
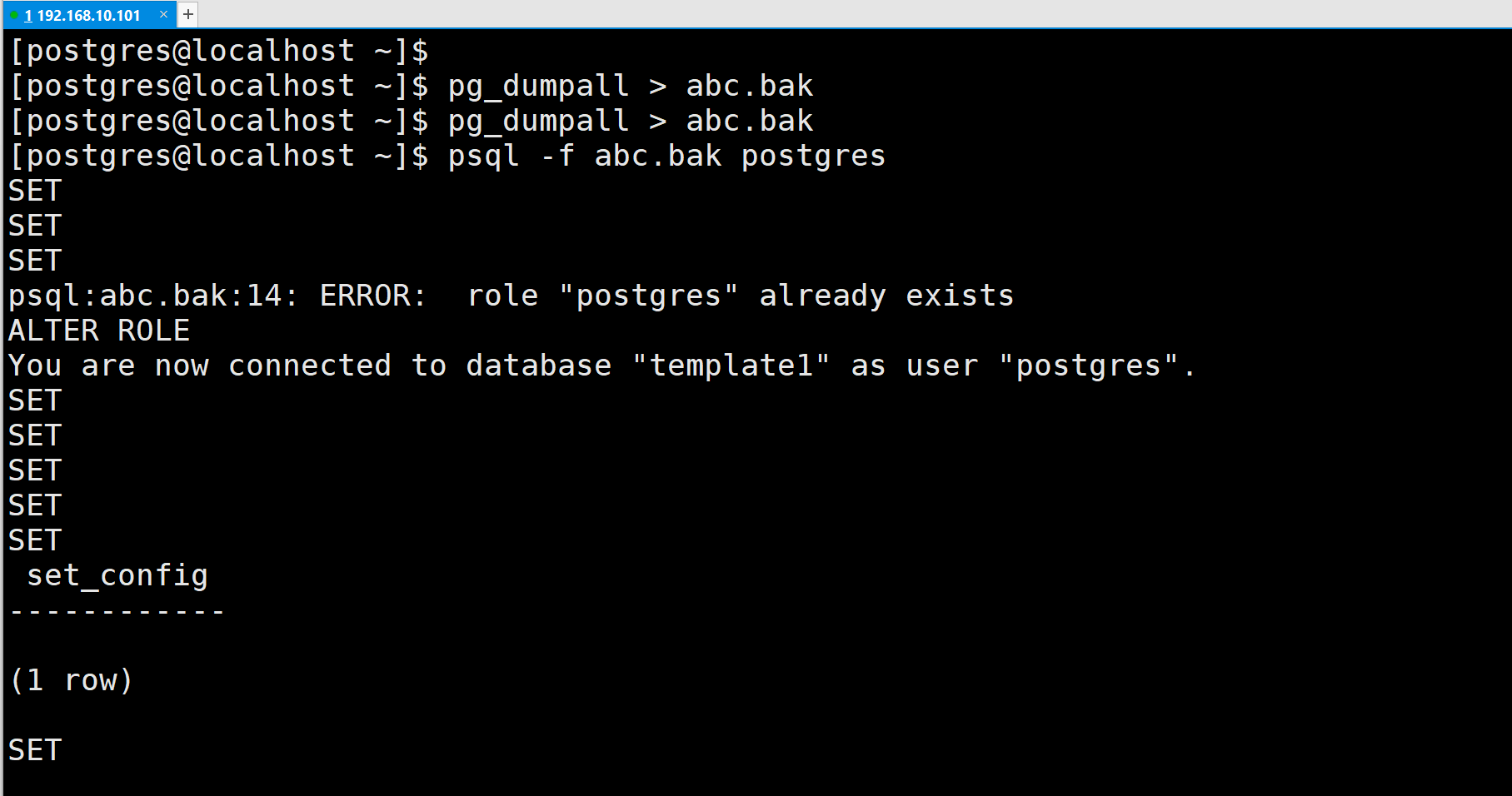
(3)使用pg_dumpall
pg dump 每次只转储一个数据库,而且它不会转储关于角色或表空间(因为它们是集簇范围的)的信息。为了支持方便地转储一个数据库集族的全部内容,提供了pg_dumpal1 程序。pg_dumpal1 备份一个给定集簇中的每一个数据库,并且也保留了集簇范围的数据,如角色和表空间定义,该命令的基本用法是:
| pg dumpall > dumpfile |
|---|
转储的结果可以使用 psql 恢复:
| psql -f dumpfile postgres |
|---|
实际上,你可以指定恢复到任何已有数据库名,但是如果你正在将转储载入到一个空集簇中则通常要用(postgres)。在恢复一个pg dumpa 转储时常常需要具有数据库超级用户访问权限,因为它需要恢复角色和表空间信息。如果你在使用表空间,请确保转储中的表空间路径适合于新的安装
pg dumpa1 工作时会发出命令重新创建角色、表空间和空数据库,接着为每一个数据库 pgump,这意味着每个数据库自身是一致的,但是不同数据库的快照并不同步
集簇范围的数据可以使用 pg dumpal的-globals-ony 选项来单独转储。如果在单个数据库上运行 pg dump 命令,上述做法对于完全备份整个集族是必需的
7. 远程连接
(1)修改PostgreSQL 监听地址
默认 PostgreSQl 监听的地址是 127.0.0.1,别的机器无法远程连接上,所以需要调整,修改 postgresql.conf 文件
通过源码编译安装的 pgsq1配置文件在/usr/local/pgsql/data/postgresql.conf

(2)配置访问权限
默认是只能本地访问 PostgreSQL 的,我们需要在 pg_hba.conf 里面配置
[postgres@localhost ~]$ vim /usr/local/pgsql/data/pg_hba.conf
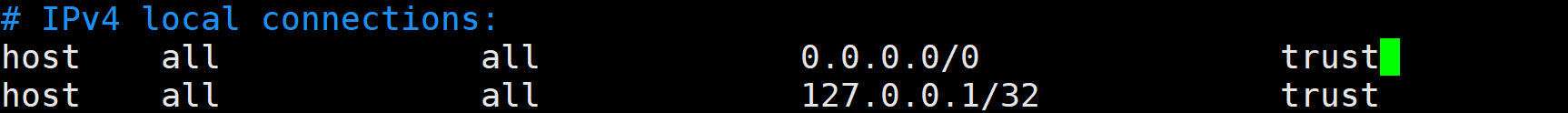
host:这指定了连接类型。host 表示该规则适用于通过 TCP/IP 进行的远程连接。如果是本地连接,通常会使用 local。
all:这定义了哪些数据库可以接受这个规则。a11表示这个规则适用于所有数据库。你也可以指定特定的数据库名,例如mydatabase。
all:这定义了哪些用户可以接受这个规则。all 表示这个规则适用于所有用户。你也可以指定特定的用户名,例如 myuser。
0.0.0.0/0:这定义了哪些客户端IP地址或 IP 地址范围可以接受这个规则。0.0.0.0/0 是一个特殊的 CIDR 表示法,它表示任何 IP 地址(即没有 IP 地址限制)。你也可以指定具体的IP地址,如192.168.1.100,或者 IP 地址范围,如 192.168.1.0/24。
trust:这定义了认证方法。trust 表示不需要密码或其他任何形式的认证,客户端可以直接连接。这通常只在本地或受信任的网络环境中使用,因为它允许任何人无需认证即可访问数据库。请注意,使用 trust 认证方法允许任何 IP地址连接到你的数据库,而不需要任何认证,这是非常不安全的。这通常只在开发或测试环境中使用,并且应该始终确保数据库服务器不暴露在不受信任的网络中在生产环境中,你应该使用更安全的认证方法,如md5或password(对于较新版本的 PostgreSQL,建议使用 scram-sha-256)
如果不是设置的 trust,而是选择了md5或password之类的,需要有密码才行,配置 PostgreSQL密码流程如下

(3)重启服务

(4)验证远程连接