前言:Paraformer-large长音频模型集成VAD、ASR、标点与时间戳功能,可直接对时长为数小时音频进行识别,并输出带标点文字与时间戳。ASR模型:Parformer-large模型结构为非自回归语音识别模型,多个中文公开数据集上取得SOTA效果,可快速地基于ModelScope对模型进行微调定制和推理。热词版本:Paraformer-large热词版模型支持热词定制功能,基于提供的热词列表进行激励增强,提升热词的召回率和准确率。
Paraformer语音识别-中文-通用-16k-离线-large-长音频版-魔搭社区
一、Paraformer模型
(1)Paraformer模型原理介绍
Paraformer是达摩院语音团队提出的一种高效的非自回归端到端语音识别框架。本项目为Paraformer中文通用语音识别模型,采用工业级数万小时的标注音频进行模型训练,保证了模型的通用识别效果。模型可以被应用于语音输入法、语音导航、智能会议纪要等场景。

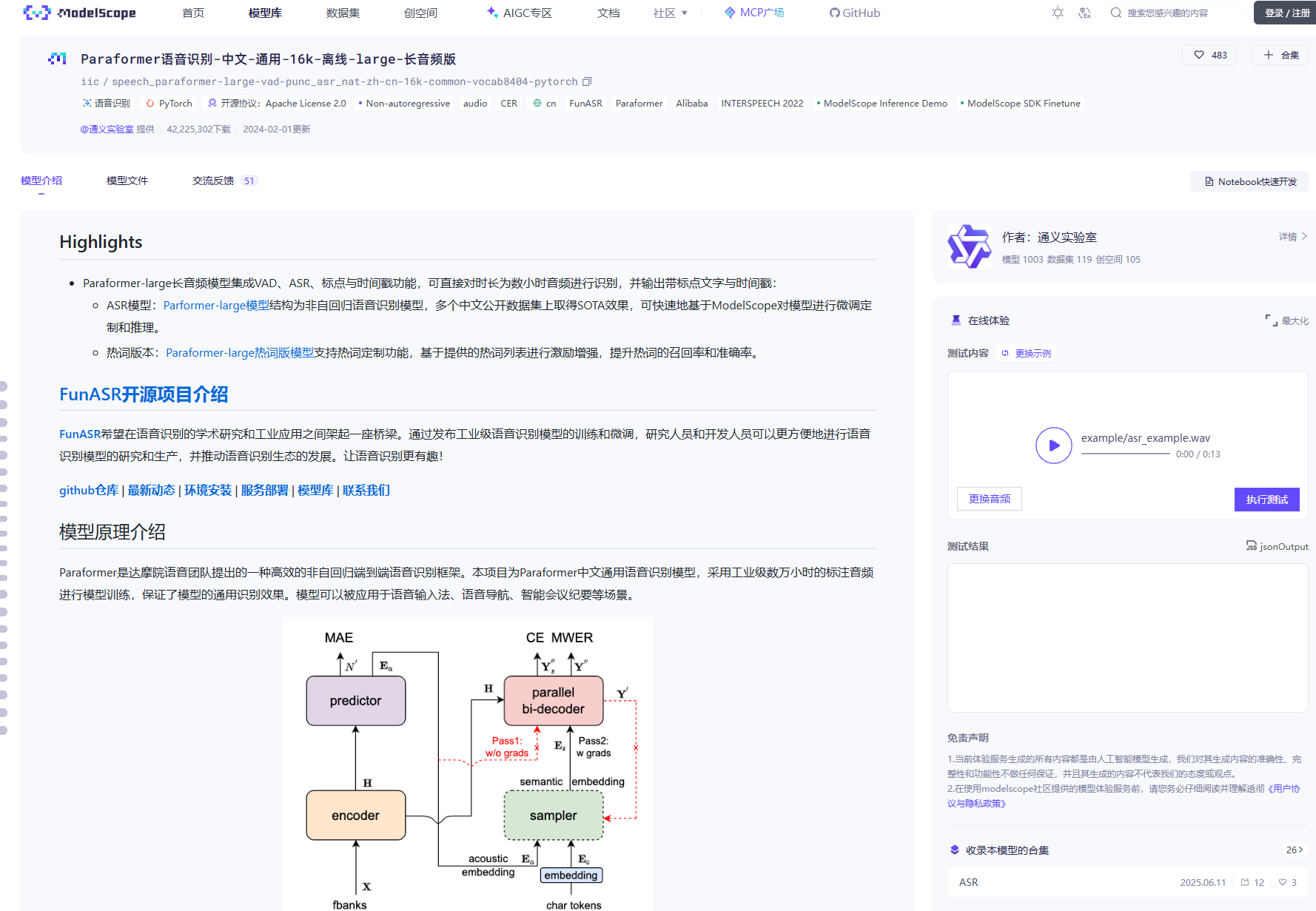
Paraformer模型结构如上图所示,由 Encoder、Predictor、Sampler、Decoder 与 Loss function 五部分组成。Encoder可以采用不同的网络结构,例如self-attention,conformer,SAN-M等。Predictor 为两层FFN,预测目标文字个数以及抽取目标文字对应的声学向量。Sampler 为无可学习参数模块,依据输入的声学向量和目标向量,生产含有语义的特征向量。Decoder 结构与自回归模型类似,为双向建模(自回归为单向建模)。Loss function 部分,除了交叉熵(CE)与 MWER 区分性优化目标,还包括了 Predictor 优化目标 MAE。
其核心点主要有:
Predictor 模块:基于 Continuous integrate-and-fire (CIF) 的 预测器 (Predictor) 来抽取目标文字对应的声学特征向量,可以更加准确的预测语音中目标文字个数。
Sampler:通过采样,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的 Decoder 来增强模型对于上下文的建模能力。
基于负样本采样的 MWER 训练准则。
更详细的细节见:
- 论文: Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition
- 论文解读:Paraformer: 高识别率、高计算效率的单轮非自回归端到端语音识别模型
(2)基于ModelScope进行推理
FunASR(1)
FunASR(1)
推理支持音频格式如下:
wav文件路径,例如:data/test/audios/asr_example.wav
pcm文件路径,例如:data/test/audios/asr_example.pcm
wav文件url,例如:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav
wav二进制数据,格式bytes,例如:用户直接从文件里读出bytes数据或者是麦克风录出bytes数据。
已解析的audio音频,例如:audio, rate = soundfile.read("asr_example_zh.wav"),类型为numpy.ndarray或者torch.Tensor。
wav.scp文件,需符合如下要求:
cat wav.scp
asr_example1 data/test/audios/asr_example1.wav
asr_example2 data/test/audios/asr_example2.wav
...- 若输入格式wav文件url,api调用方式可参考如下范例:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch',
model_revision="v2.0.4")
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_vad_punc_example.wav')
print(rec_result)- 输入音频为pcm格式,调用api时需要传入音频采样率参数audio_fs,例如:
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_vad_punc_example.pcm', fs=16000)- 输入音频为wav格式,api调用方式可参考如下范例:
rec_result = inference_pipeline('asr_vad_punc_example.wav')- 若输入格式为文件wav.scp(注:文件名需要以.scp结尾),可添加 output_dir 参数将识别结果写入文件中,api调用方式可参考如下范例:
inference_pipeline("wav.scp", output_dir='./output_dir')识别结果输出路径结构如下:

score:识别路径得分
text:语音识别结果文件
- 若输入音频为已解析的audio音频,api调用方式可参考如下范例:
import soundfile
waveform, sample_rate = soundfile.read("asr_vad_punc_example.wav")
rec_result = inference_pipeline(waveform)- ASR、VAD、PUNC模型自由组合
可根据使用需求对VAD和PUNC标点模型进行自由组合,使用方式如下:
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch', model_revision="v2.0.4",
vad_model='iic/speech_fsmn_vad_zh-cn-16k-common-pytorch', vad_model_revision="v2.0.4",
punc_model='iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch', punc_model_revision="v2.0.3",
# spk_model="iic/speech_campplus_sv_zh-cn_16k-common",
# spk_model_revision="v2.0.2",
)若不使用PUNC模型,可配置punc_model="",或不传入punc_model参数,如需加入LM模型,可增加配置lm_model='damo/speech_transformer_lm_zh-cn-common-vocab8404-pytorch',并设置lm_weight和beam_size参数。
二、Paraformer和FunAudioLLM区别
Paraformer和FunAudioLLM都是由阿里巴巴集团研发的语音技术模型,但它们的设计目标和技术特点有所不同。
(1)Paraformer
作者/开发团队:Paraformer是由阿里巴巴达摩院开发的新一代语音识别模型。
技术特点:
它是一个非自回归端到端(non-autoregressive end-to-end)的语音识别模型,旨在提高推理效率,相比传统模型在某些情况下可以提升10倍的速度。
支持多种语言,包括中文普通话及方言、英文、日语、韩语等,并提供诸如定制热词、时间戳、情感和事件识别等功能。
主要应用于实时音频流的语音识别以及录音文件的语音识别,适用于各种场景如智能问答、语音指令、音视频字幕等。
(2)FunAudioLLM
作者/开发团队:FunAudioLLM是由阿里巴巴通义实验室发布的AI语音大模型。
技术特点:
结合了多模态技术,不仅支持超过50种语言的语音识别,还特别强调了情感识别能力,能够理解和生成带有情感色彩的语音内容。
包含两个主要模块:SenseVoice用于处理多语言语音识别与情感辨识,CosyVoice专注于语音合成,可以快速生成模拟音色并保持情感和韵律的一致性。
应用范围涵盖了语音翻译、情感语音对话、互动播客等多个领域,强调人机交互中的情感温度和自然流畅度。
(3)总结
区别:Paraformer更注重于高效的语音转文字功能,而FunAudioLLM则在语音识别的基础上增加了对情感的理解和表达,更加关注人机交互的情感层面。此外,Paraformer在开源后提供了详细的API接入方式和应用场景,而FunAudioLLM则通过基石智算CoresHub平台为开发者提供服务,并且也已开源。
作者:两者均出自阿里巴巴的不同研究部门,Paraformer来自达摩院,而FunAudioLLM则是通义实验室的作品。