文末有全部图片资源
我在两年前更过如何用 MATLAB 爬取 《Nature》全部插图,最近又有人问我有没有下载好的24,25年插图的压缩包,于是又去拿代码运行了一下,发现两年前写的代码今天居然还能用,代码如下:
function getNaturePNGWhileTure(YEAR)
if nargin < 1
YEAR = 2024;
end
pbegin = 1; ibegin = 1; jbegin = 1;
forderName=['Year_',num2str(YEAR)];
if exist(['.\image_',forderName,'\pijbreak.mat'],'file')
load(['.\image_',forderName,'\pijbreak.mat']);
end
if ~exist(['.\image_',forderName],'dir')
mkdir(['.\image_',forderName]);
end
disp([pbegin,ibegin,jbegin])
url_full = 'https://www.nature.com/nature/research-articles?searchType=journalSearch&sort=PubDate&year=<Y/>&page=<P/>';
url_year = strrep(url_full,'<Y/>',num2str(YEAR));
options=weboptions('Timeout',inf);
html_year = webread(strrep(url_year,'<P/>','1'),options);fprintf('1->')
A_page_num = strfind(html_year,'u-visually-hidden');
Z_page_num = strfind(html_year,'data-page="next"');
page_num = html_year(A_page_num(find(A_page_num<Z_page_num,1,'last')):Z_page_num);
page_num = page_num(32:36);
page_num = str2double(page_num(abs(page_num)<=57&abs(page_num)>=48));
for p = pbegin:page_num
url_page = strrep(url_year,'<P/>',num2str(p));
html_page = webread(url_page,options);fprintf('2\n')
A_html_artical = strfind(html_page,'itemprop="name headline"');
Z_html_artical = strfind(html_page,'data-track-action="view article"');
for i = ibegin:length(Z_html_artical)
html_artical = html_page(A_html_artical(find(A_html_artical<Z_html_artical(i),1,'last')):Z_html_artical(i));
A_artical = strfind(html_artical,'<a href=');
Z_artical = strfind(html_artical,'class="c-card__link u-link-inherit"');
html_artical = html_artical(A_artical(1)+10:Z_artical);
html_artical = html_artical(1:find(html_artical=='"')-1);
for j = jbegin:50
pbegin = p; ibegin = i ; jbegin = j;
save(['.\image_',forderName,'\pijbreak.mat'],'pbegin','ibegin','jbegin')
html_png=webread(['https://www.nature.com/',html_artical,'/figures/',num2str(j)]);
A_png = strfind(html_png,'aria-describedby');
Z_png = strfind(html_png,'alt="Fig.');
if isempty(Z_png)
break;
else
url_png = html_png(A_png:Z_png(find(Z_png>A_png,1)));
url_png = ['https:',url_png(strfind(url_png,'src="')+5:end-3)];
url_png = strrep(url_png,'lw685','full');
name_png = ['.\image_',forderName,'\',html_artical(10:end),' Fig-',num2str(j)];
websave(name_png,url_png,options);
disp(['Downloading Year-',num2str(YEAR),...
' Page-',num2str(p),' Artical-',num2str(i),...
' Fig-',num2str(j),':',html_artical])
end
end
jbegin = 1;
end
ibegin = 1;
end
end
使用方法很简单,例如下载2024年图片,就命令行窗口运行getNaturePNGWhileTure(2024):
代码做了断点设置,可以下载到一半暂停有空继续下,保存的文件名称即为论文编号,例如我想看看下面这张有意思图片的原文:

可以看到文章编号为s41586-023-06728-8,我们只需要搜索:
- https://www.nature.com/articles/s41586-023-06728-8

下面展示一下比较有趣或者好看新颖的图片,然后会在文章最后给出这仨年全部图片的资源,大概一万多张图片。
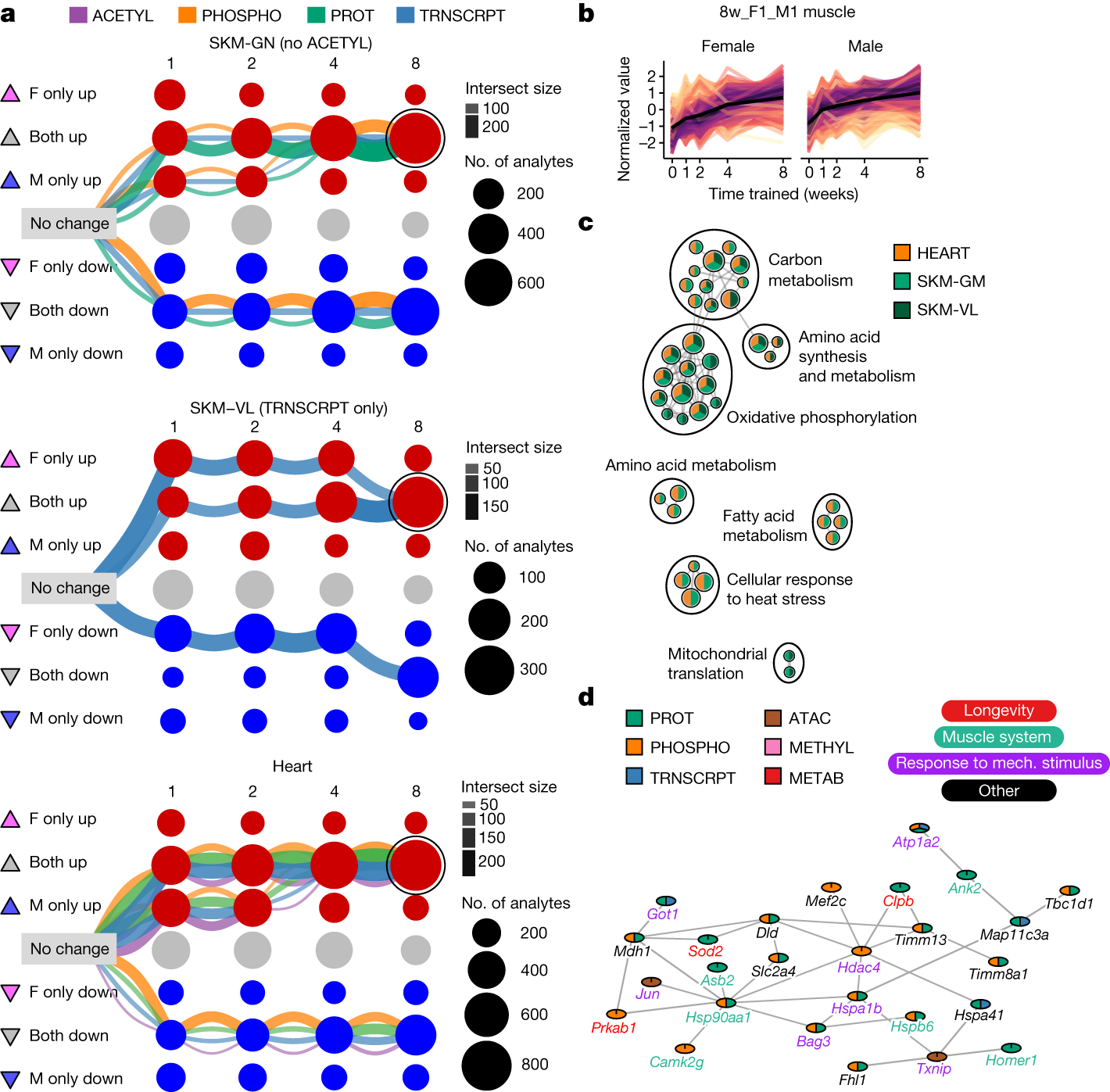
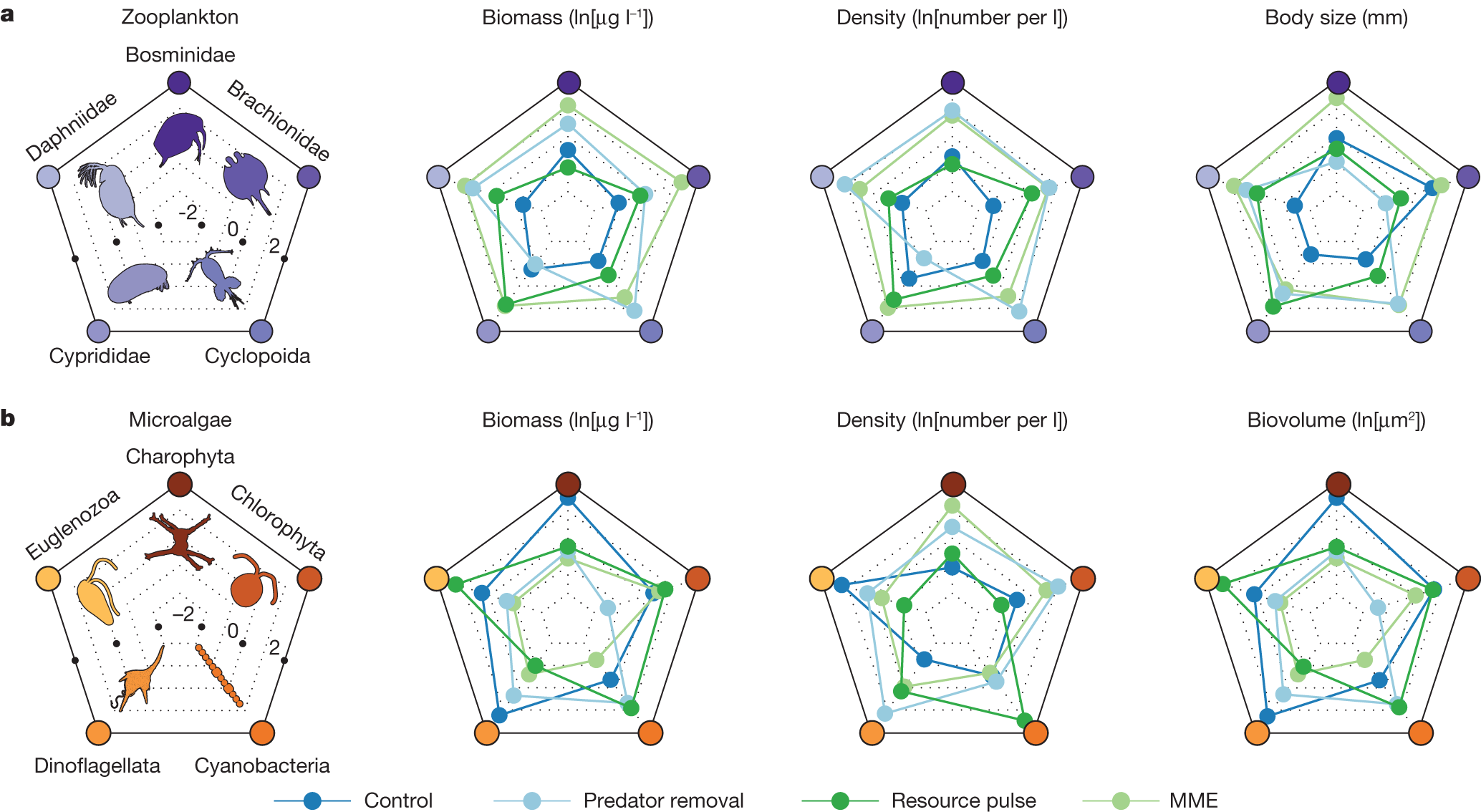
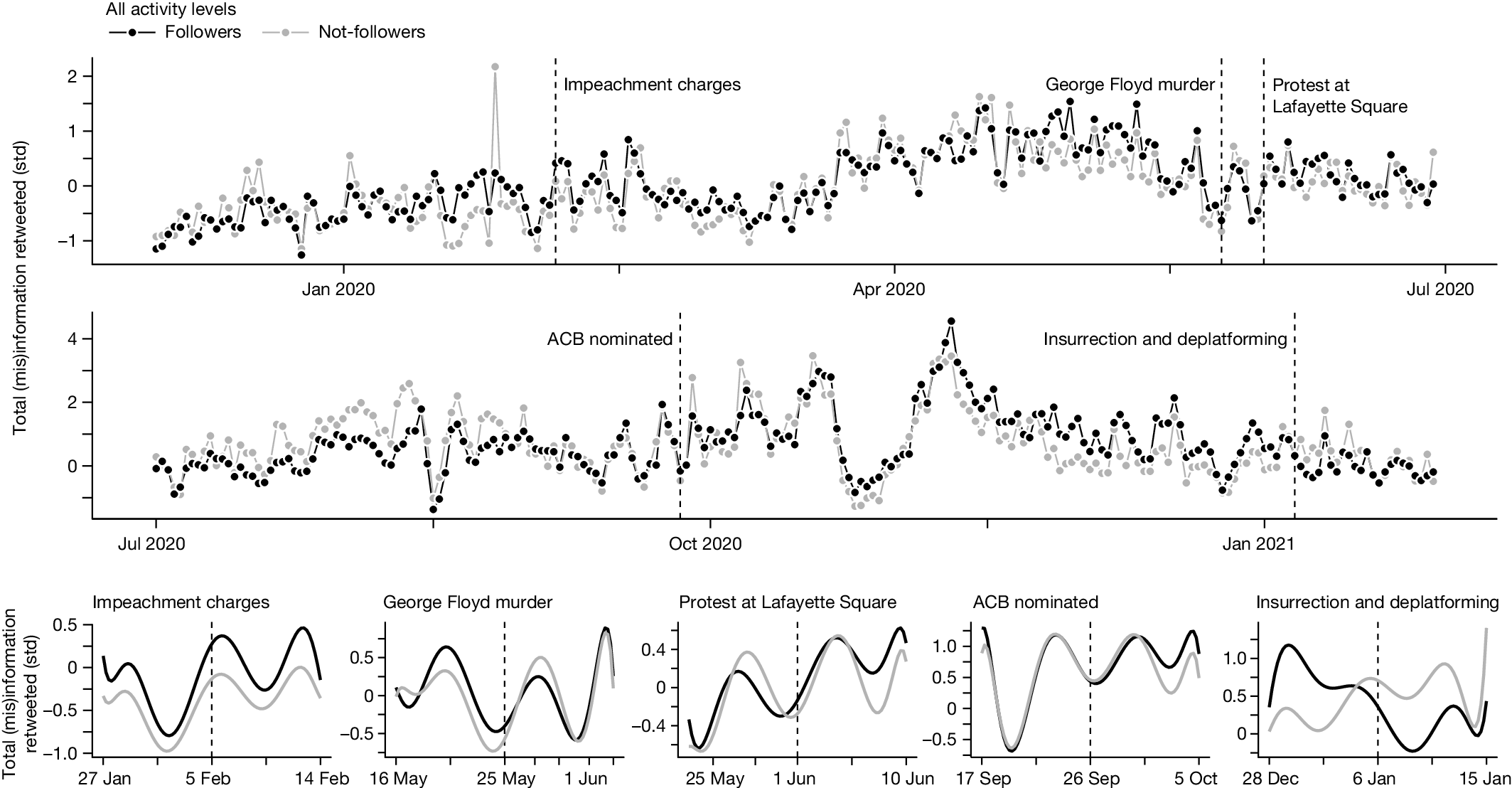
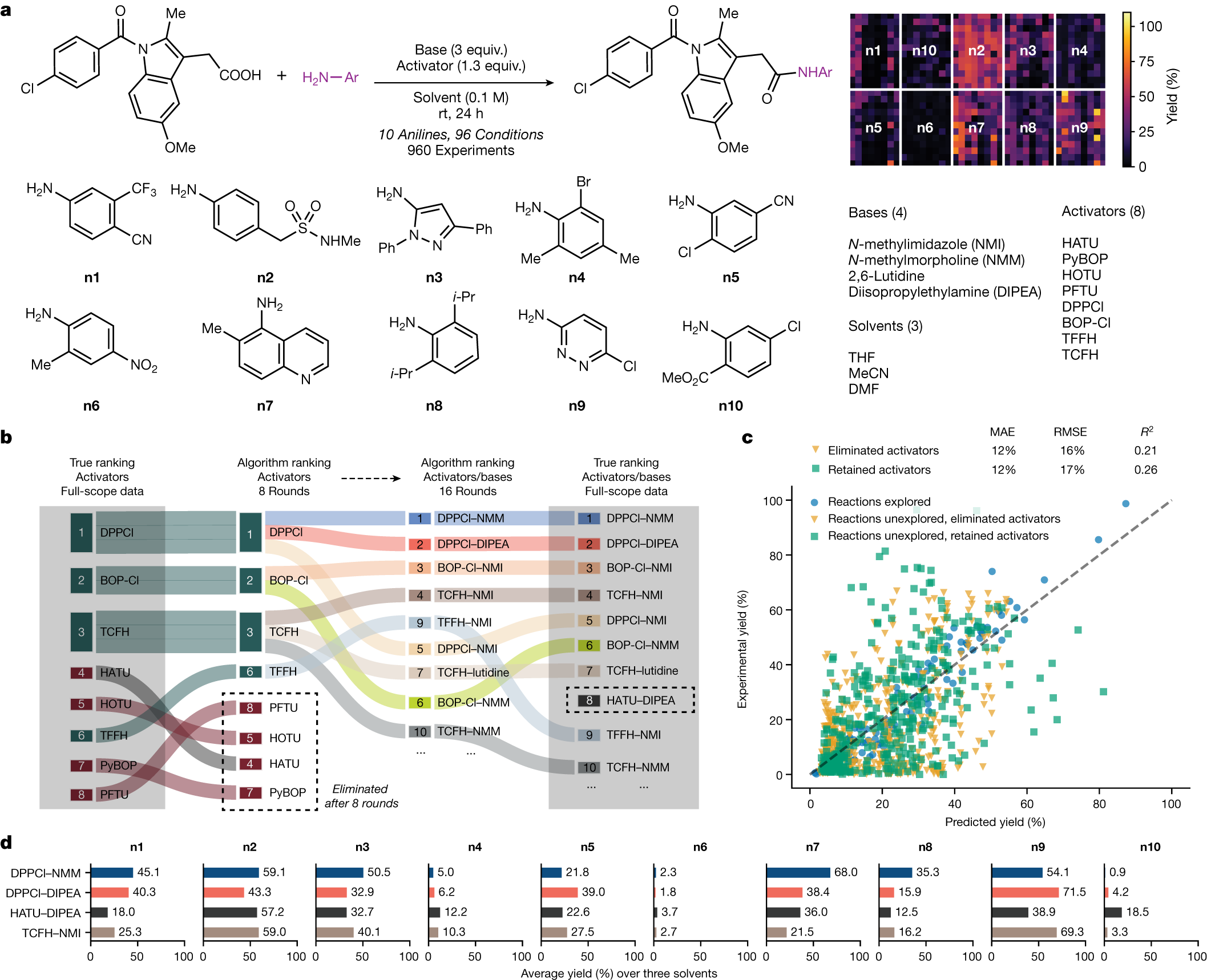
部分图像展示
2023


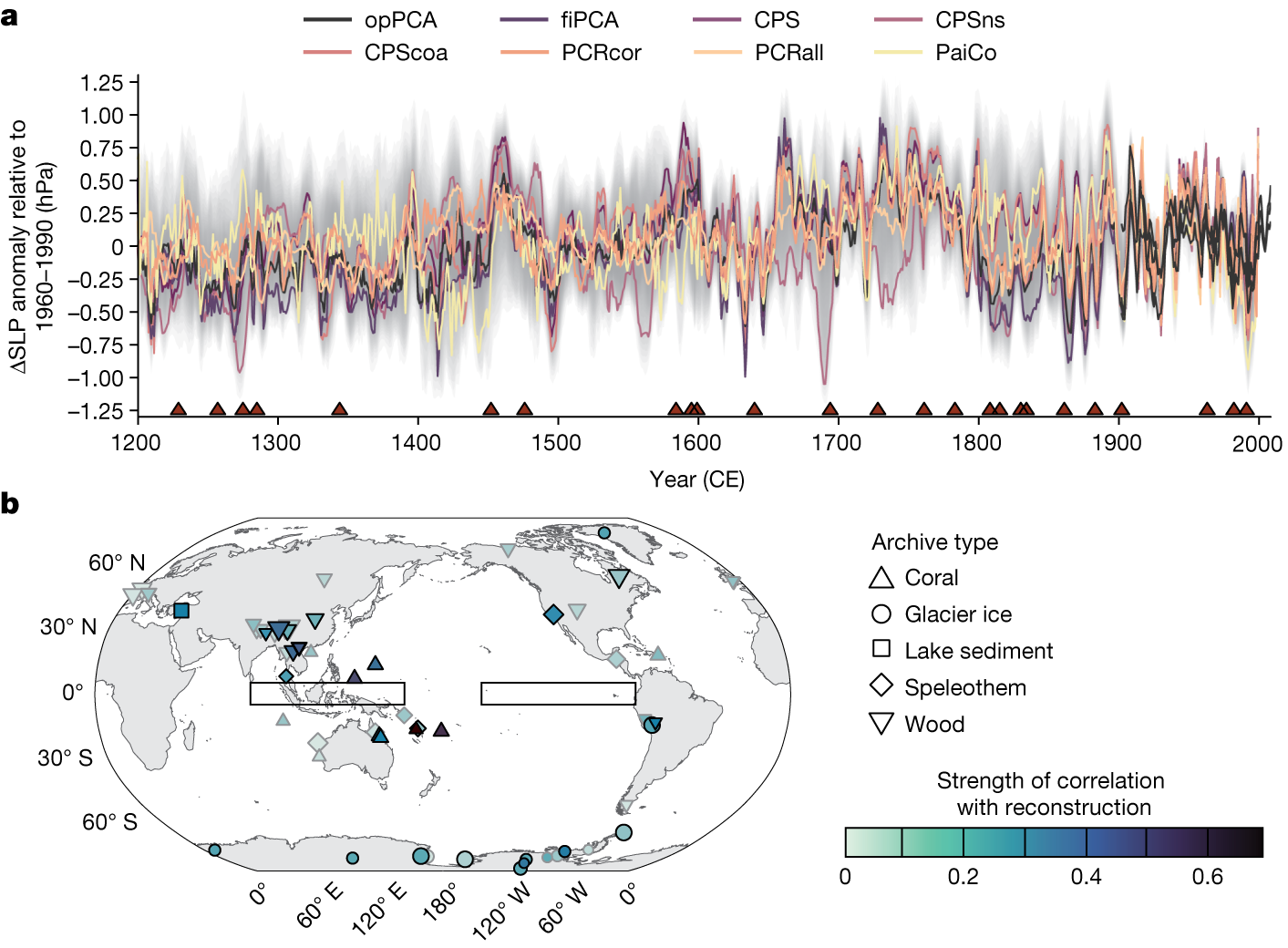
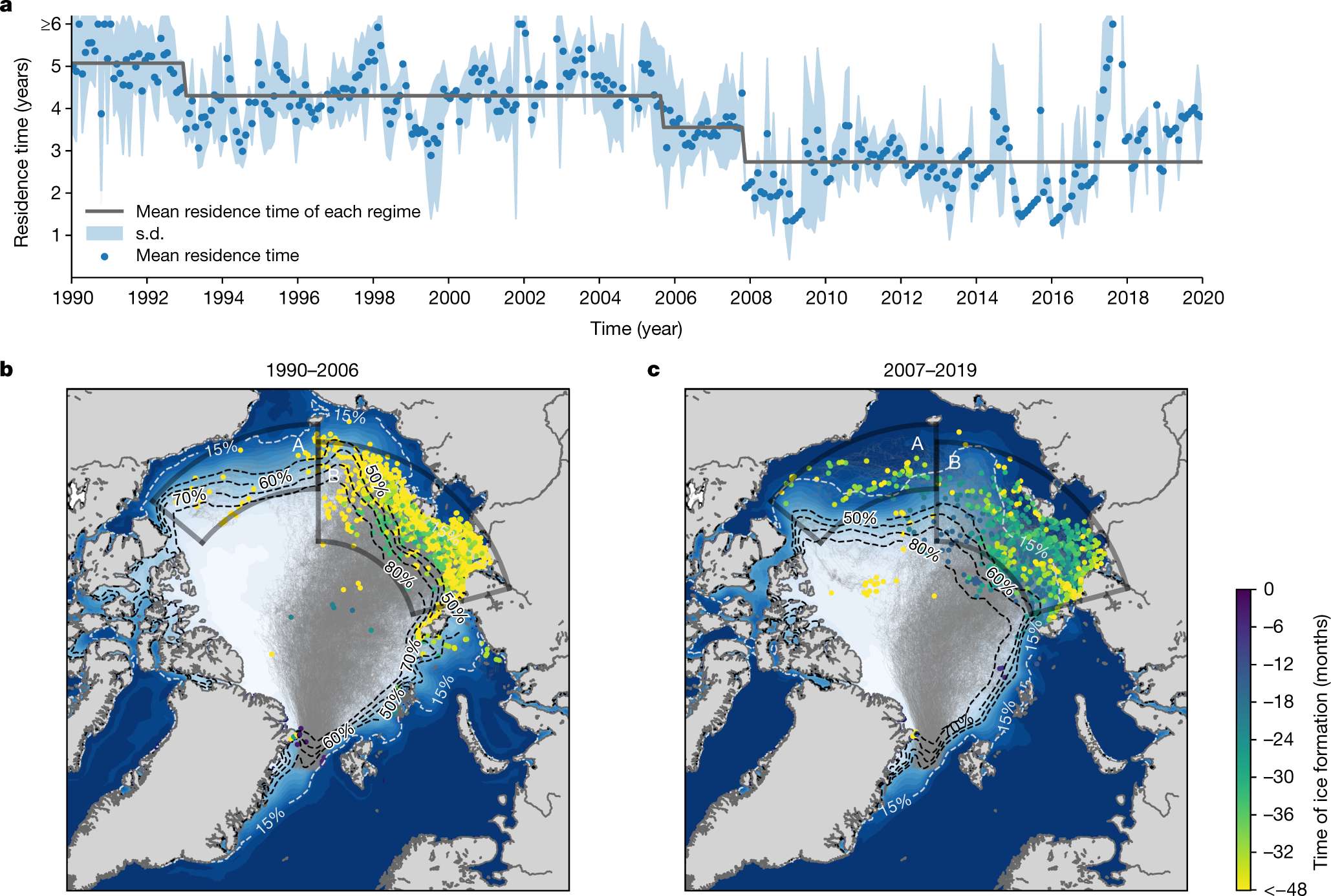
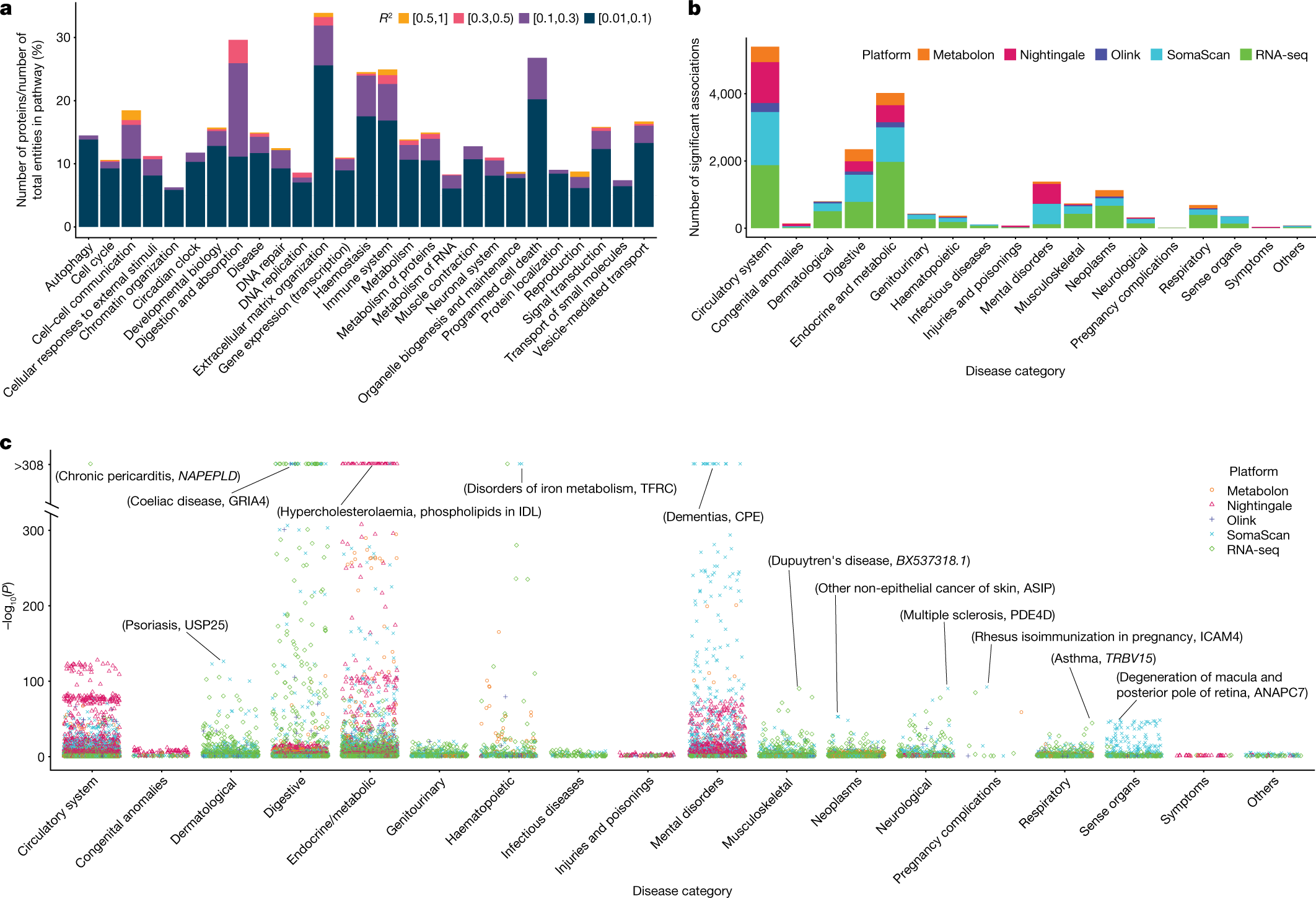
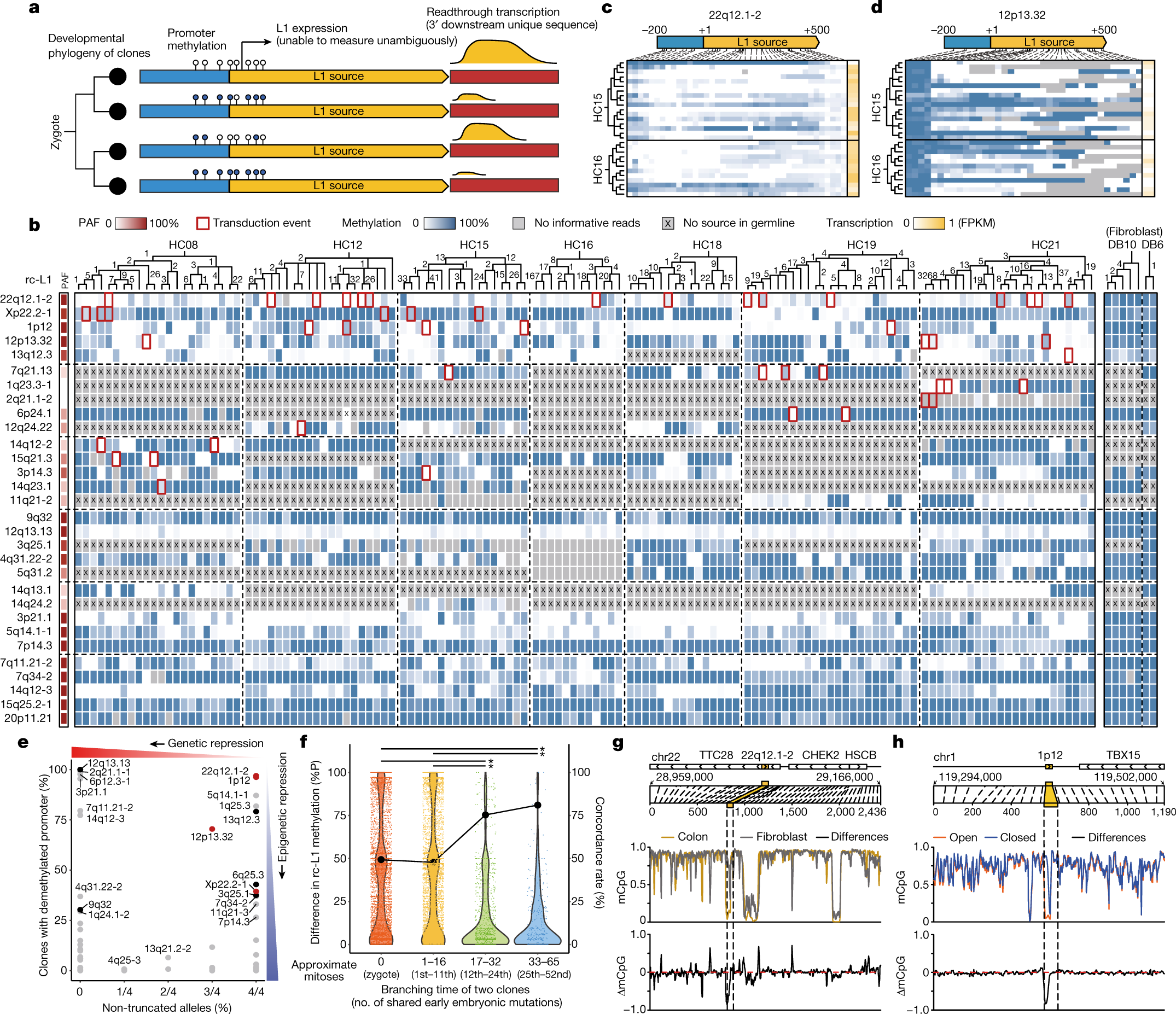


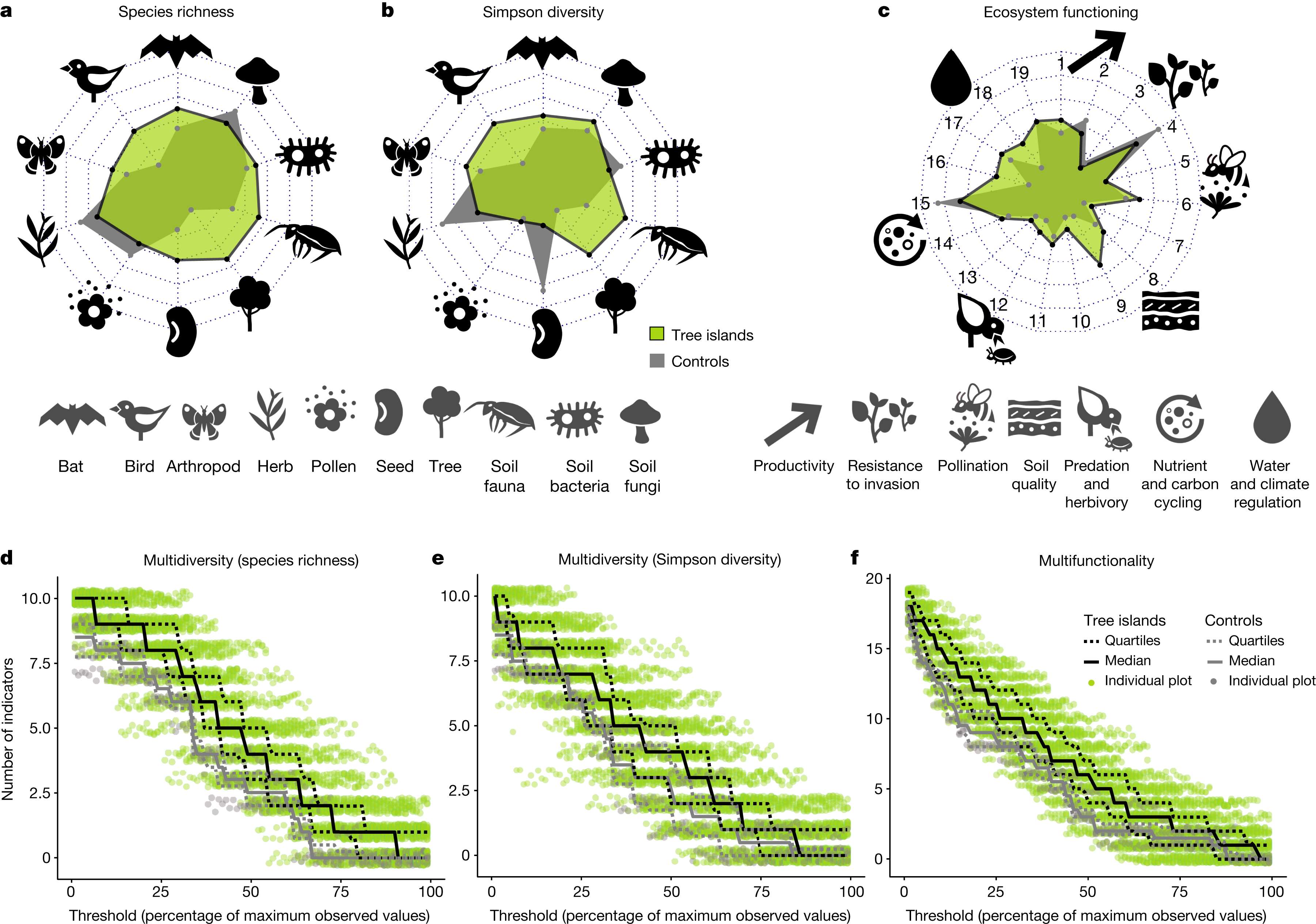
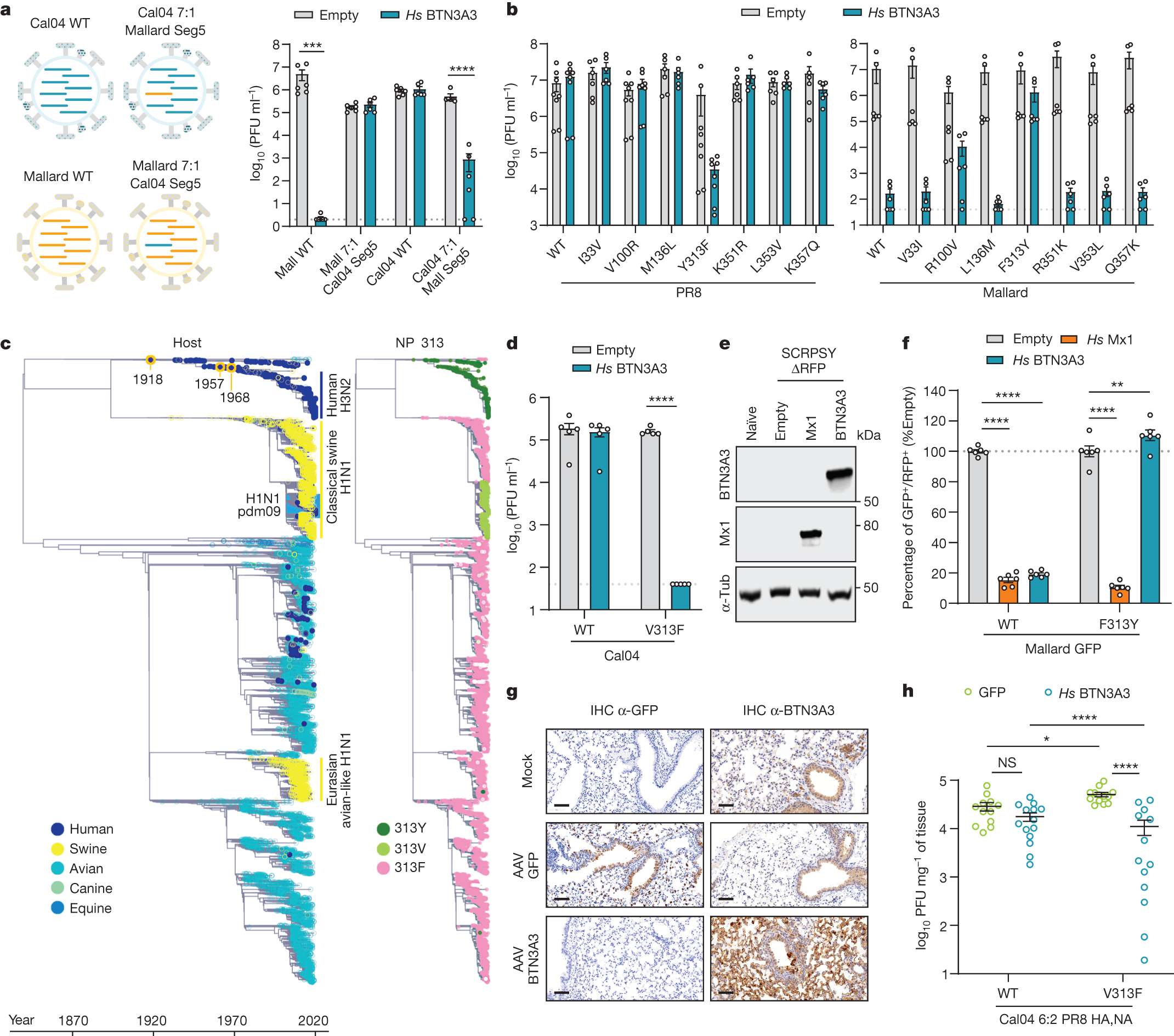
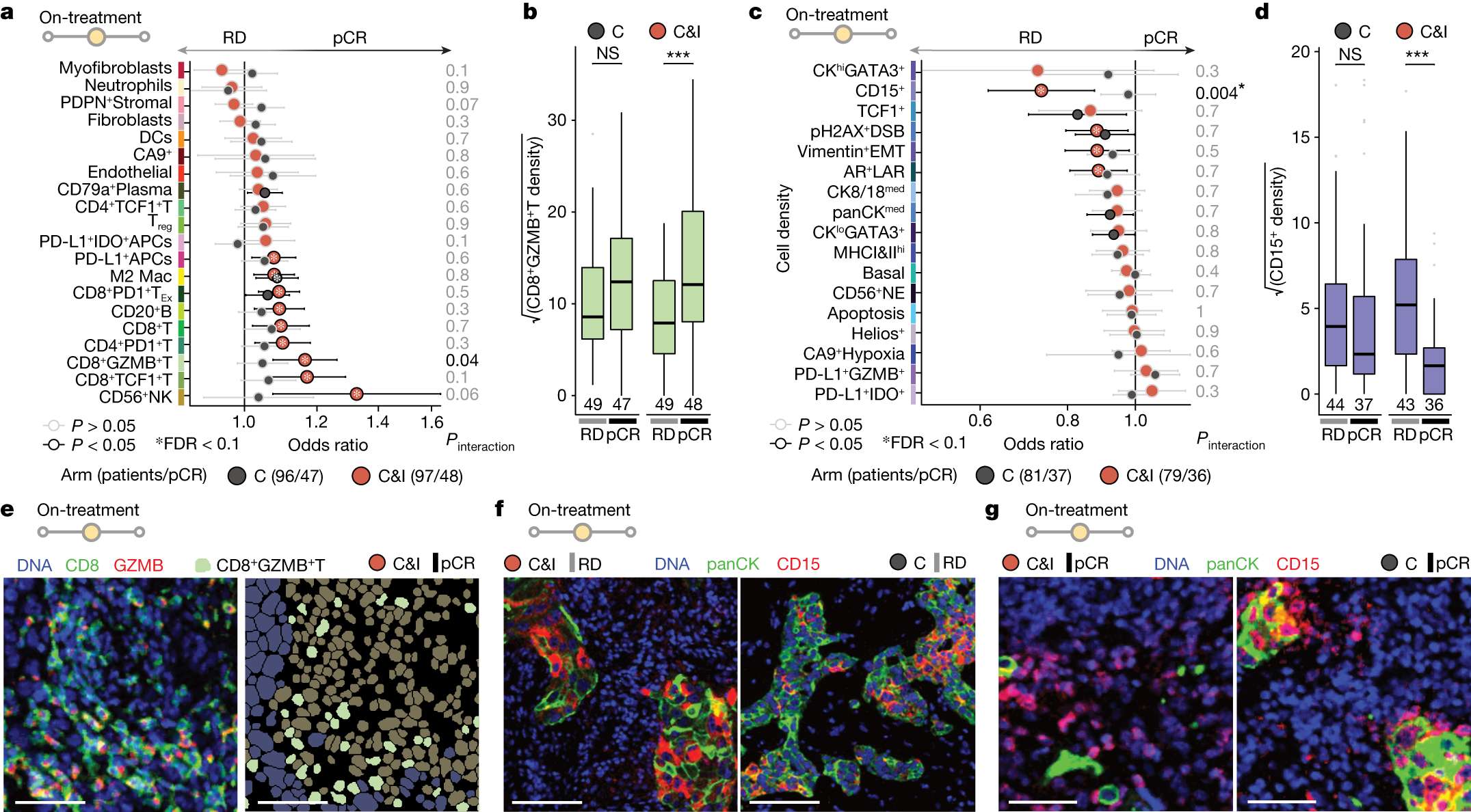
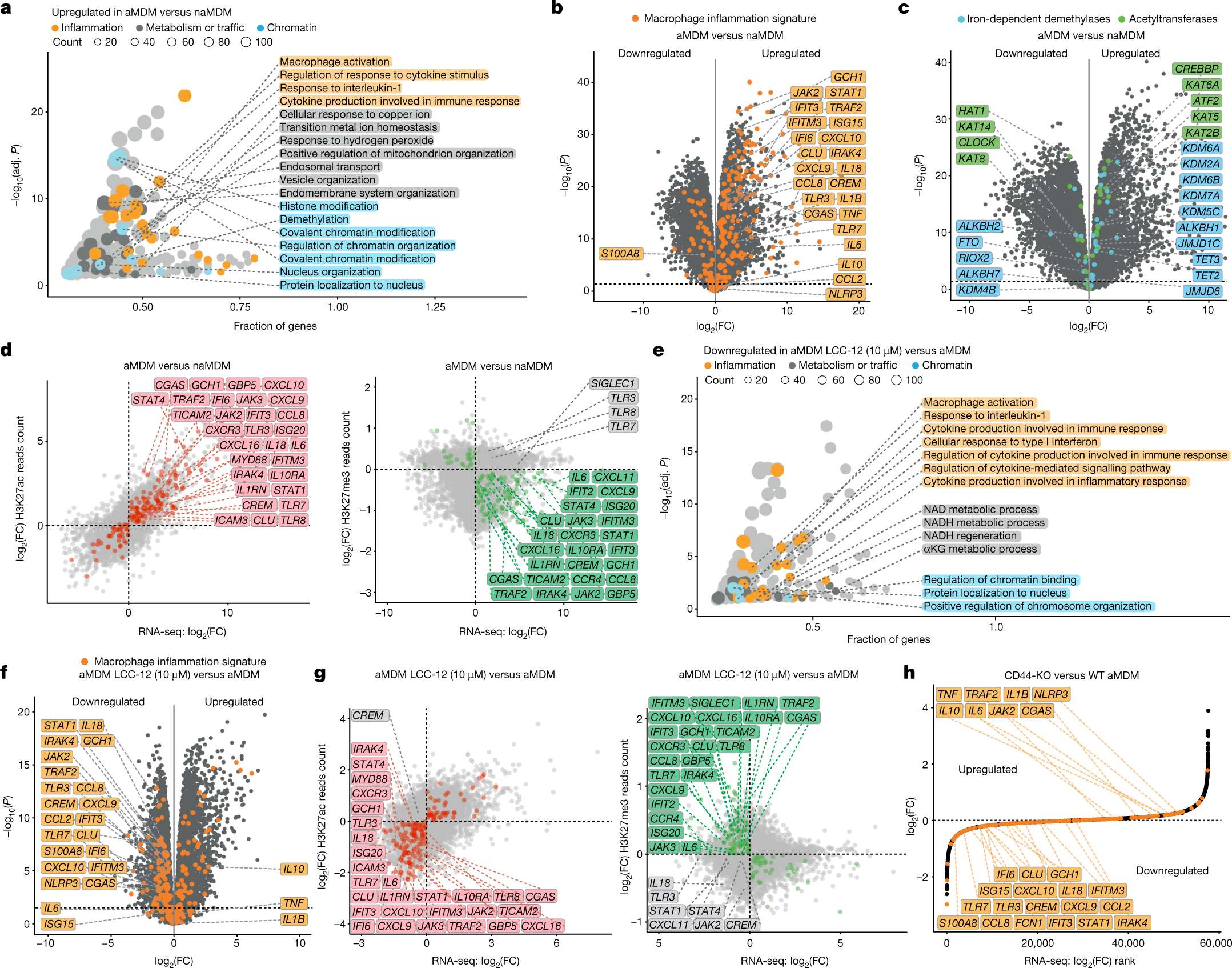
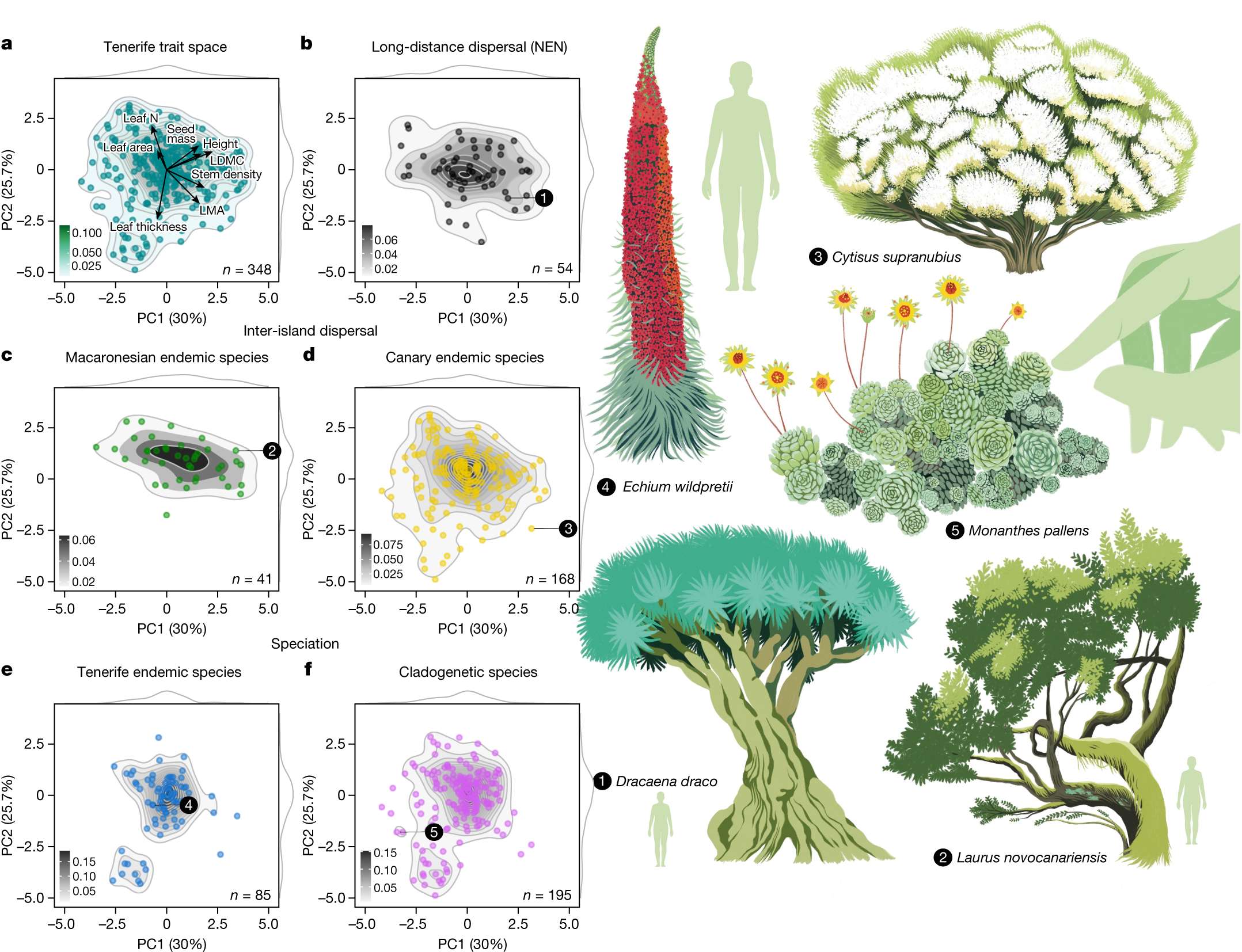
2024
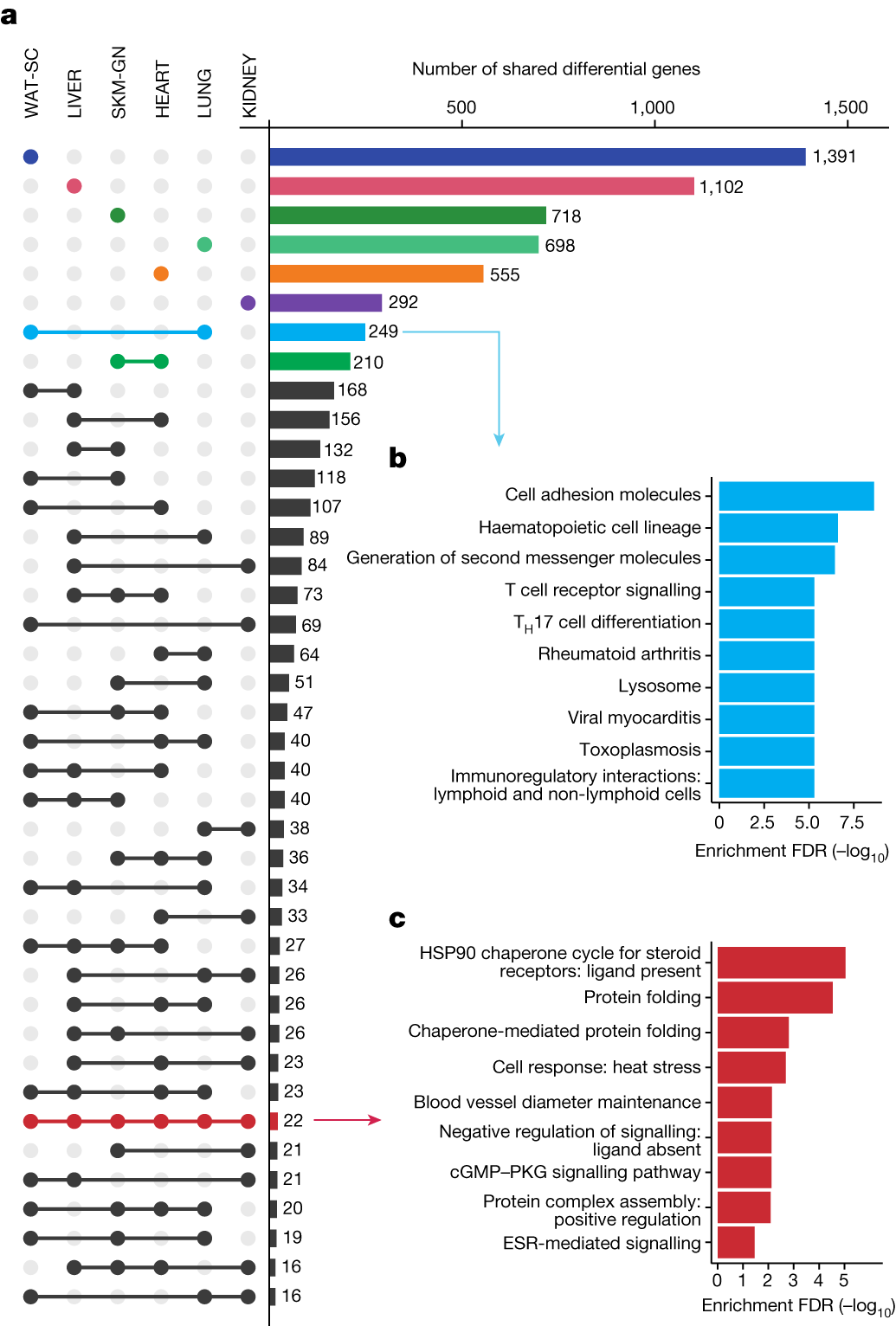
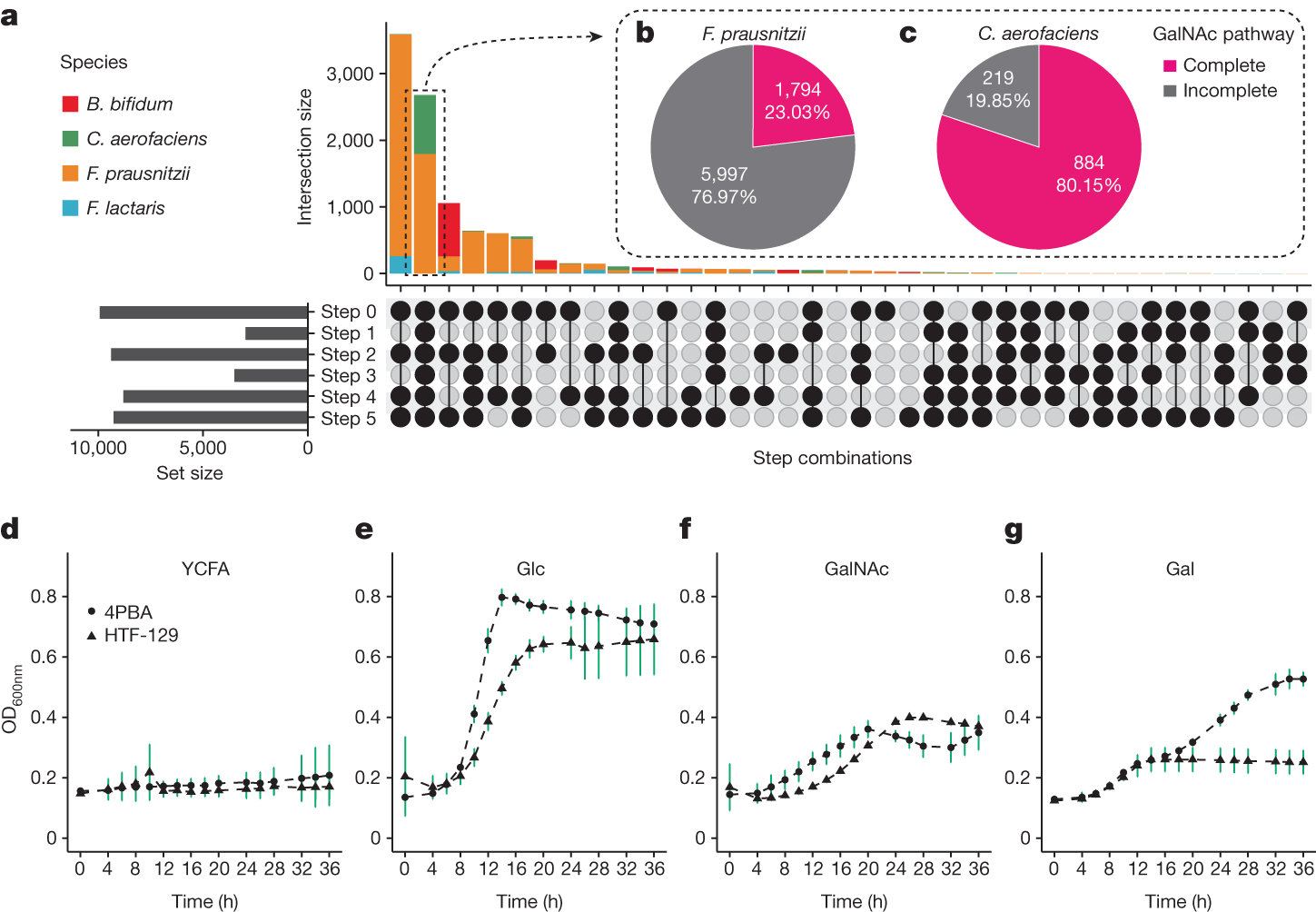
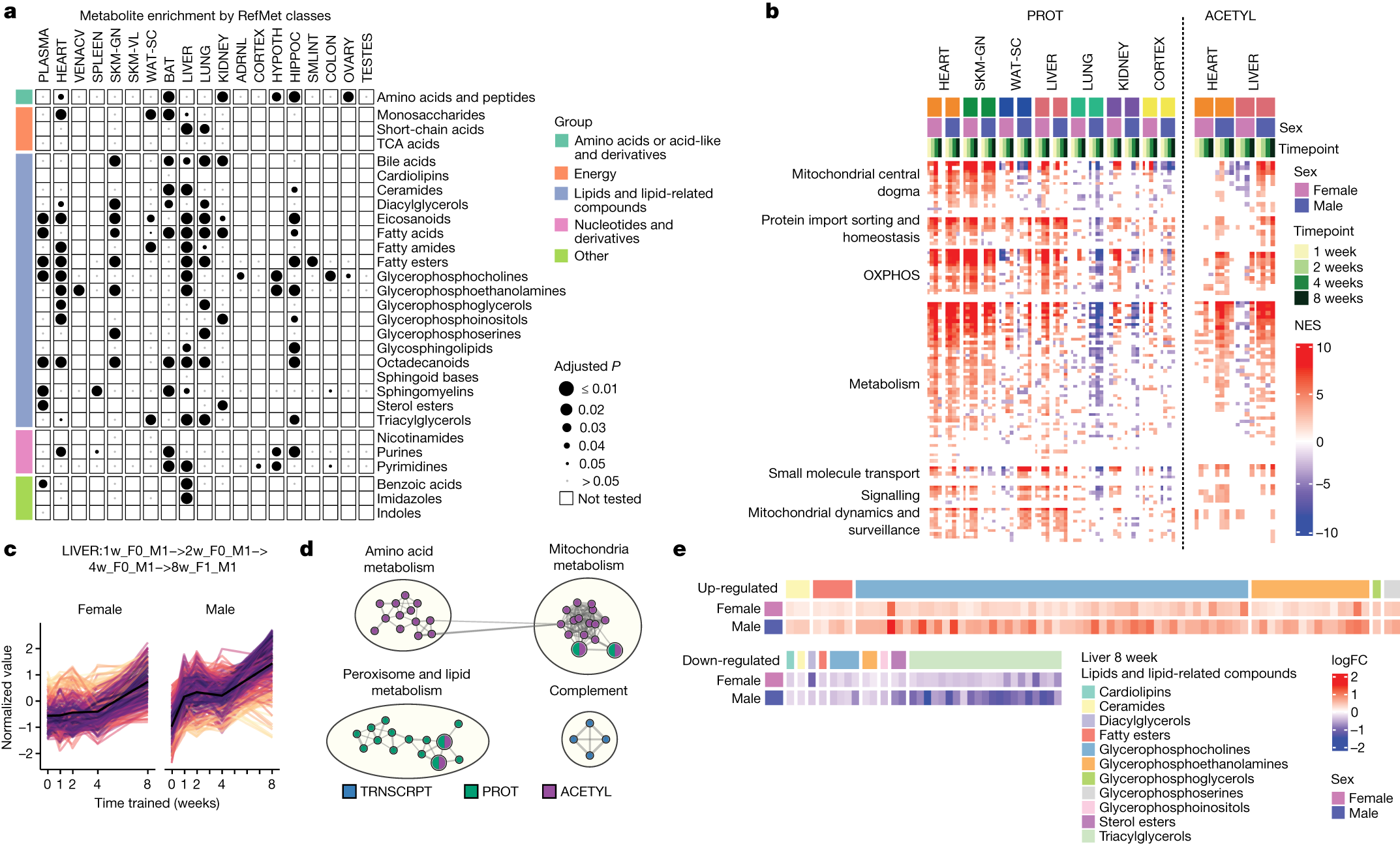
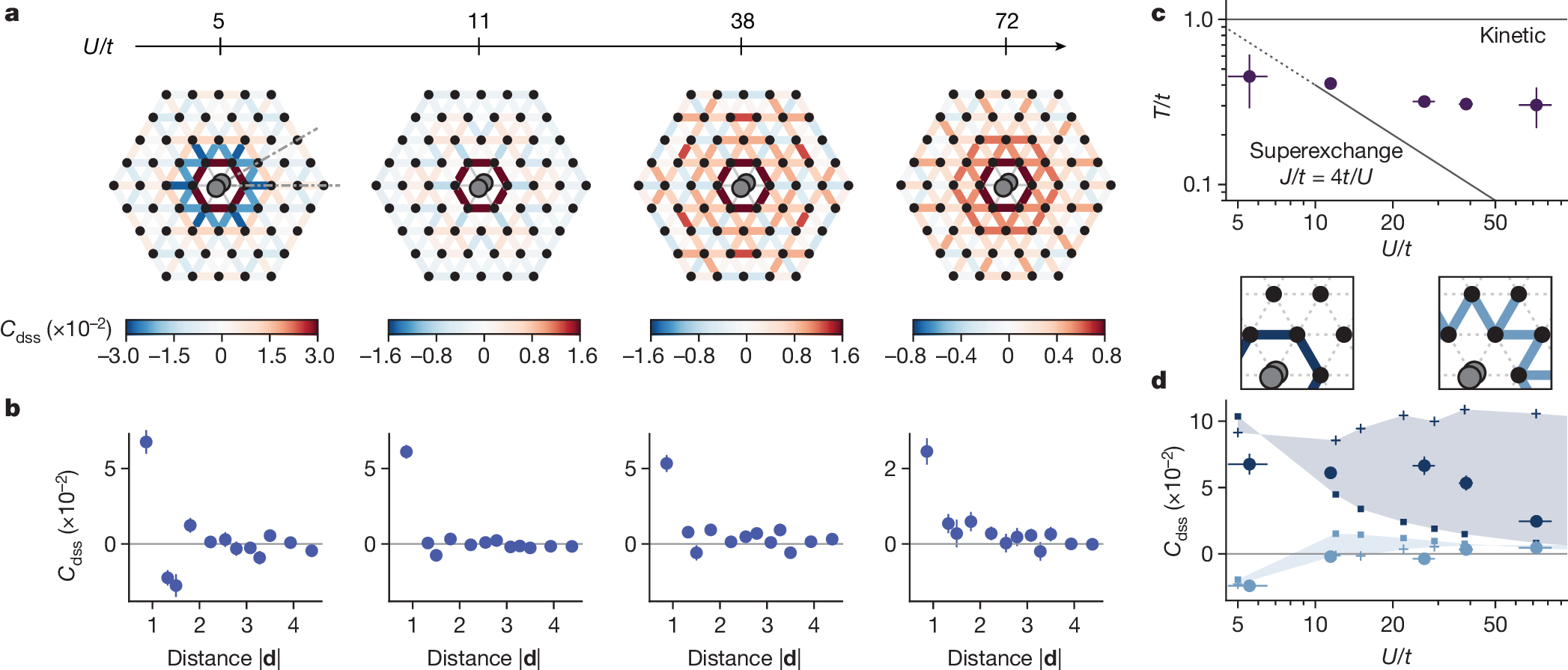
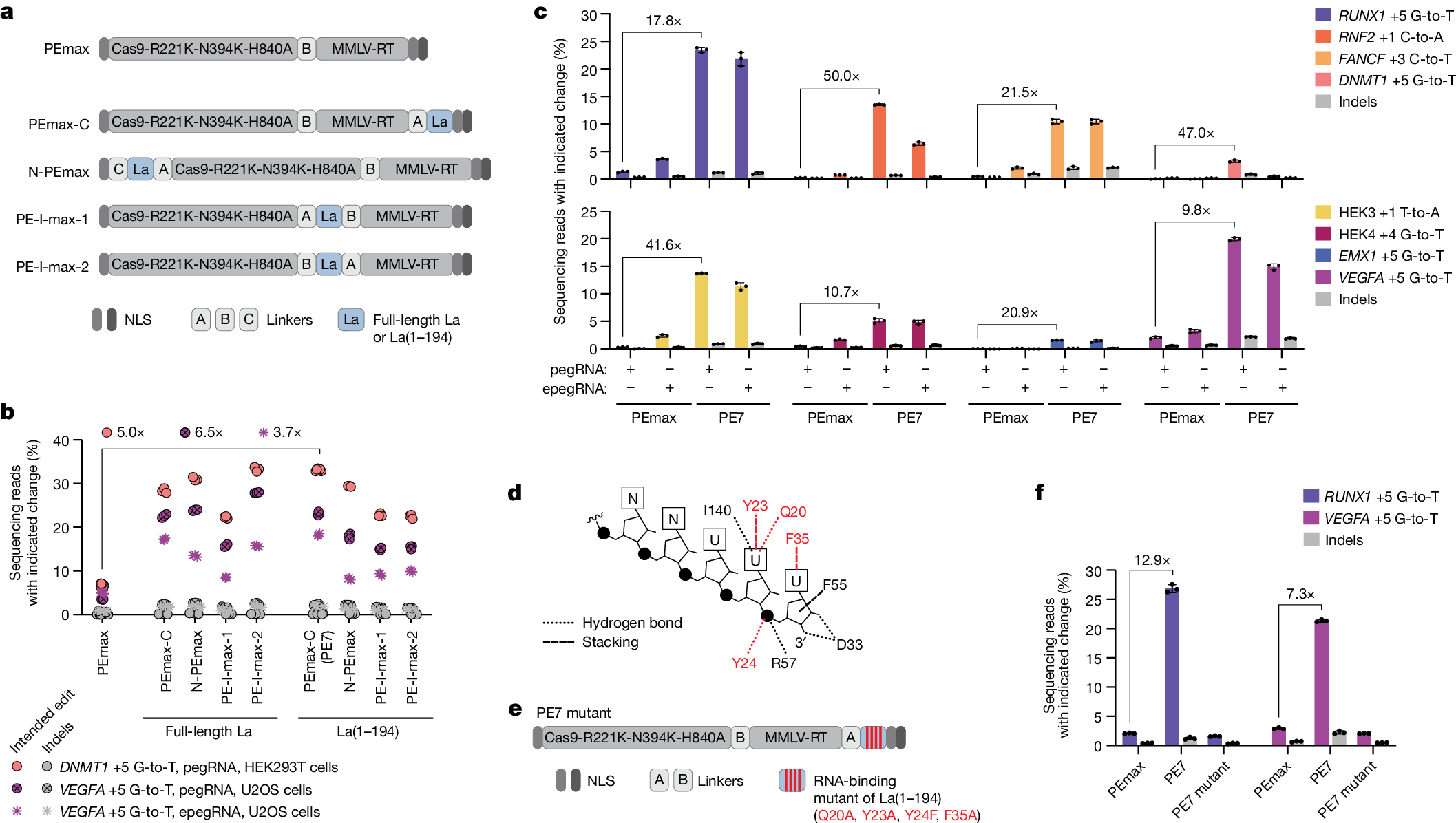
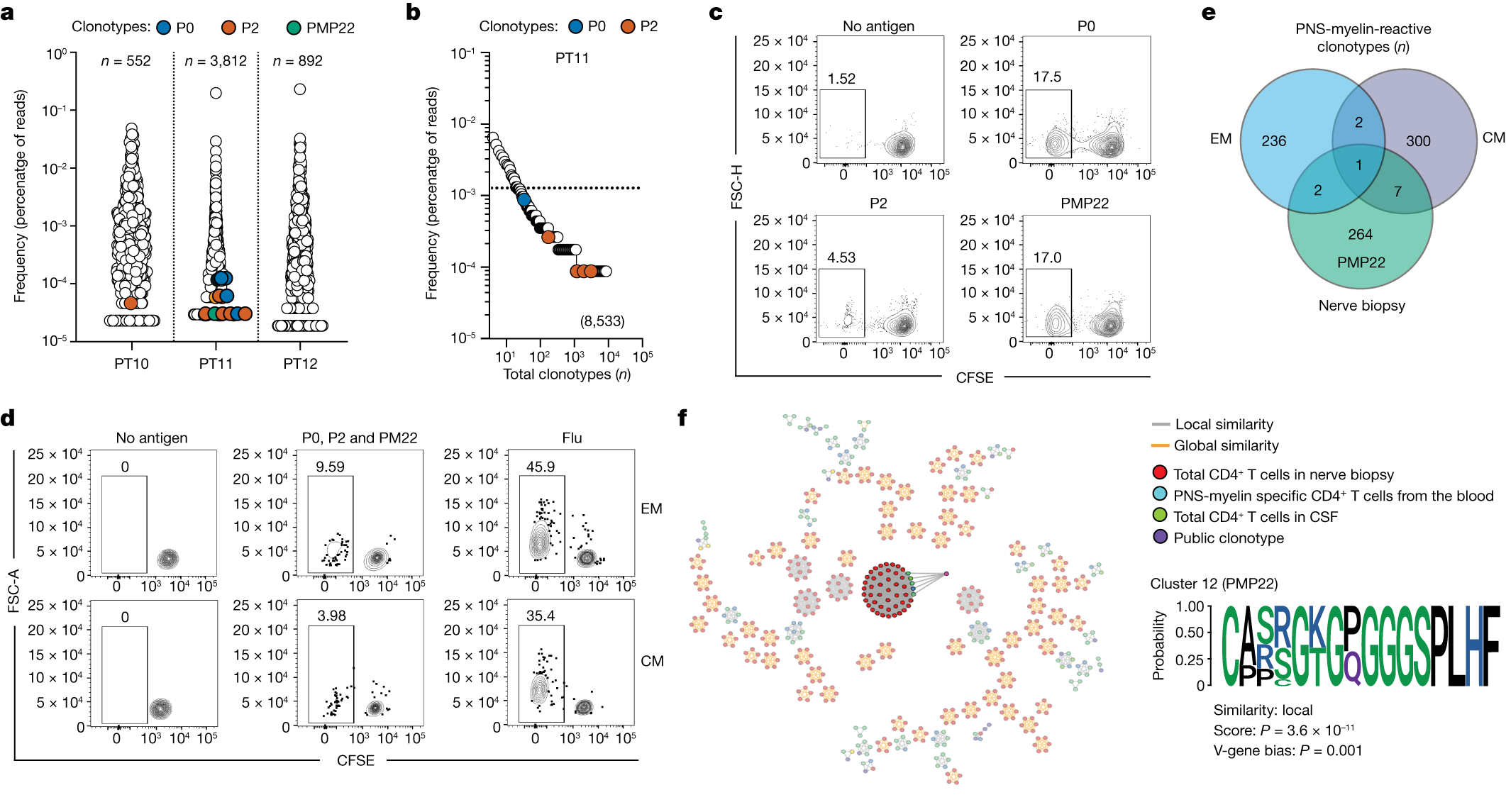
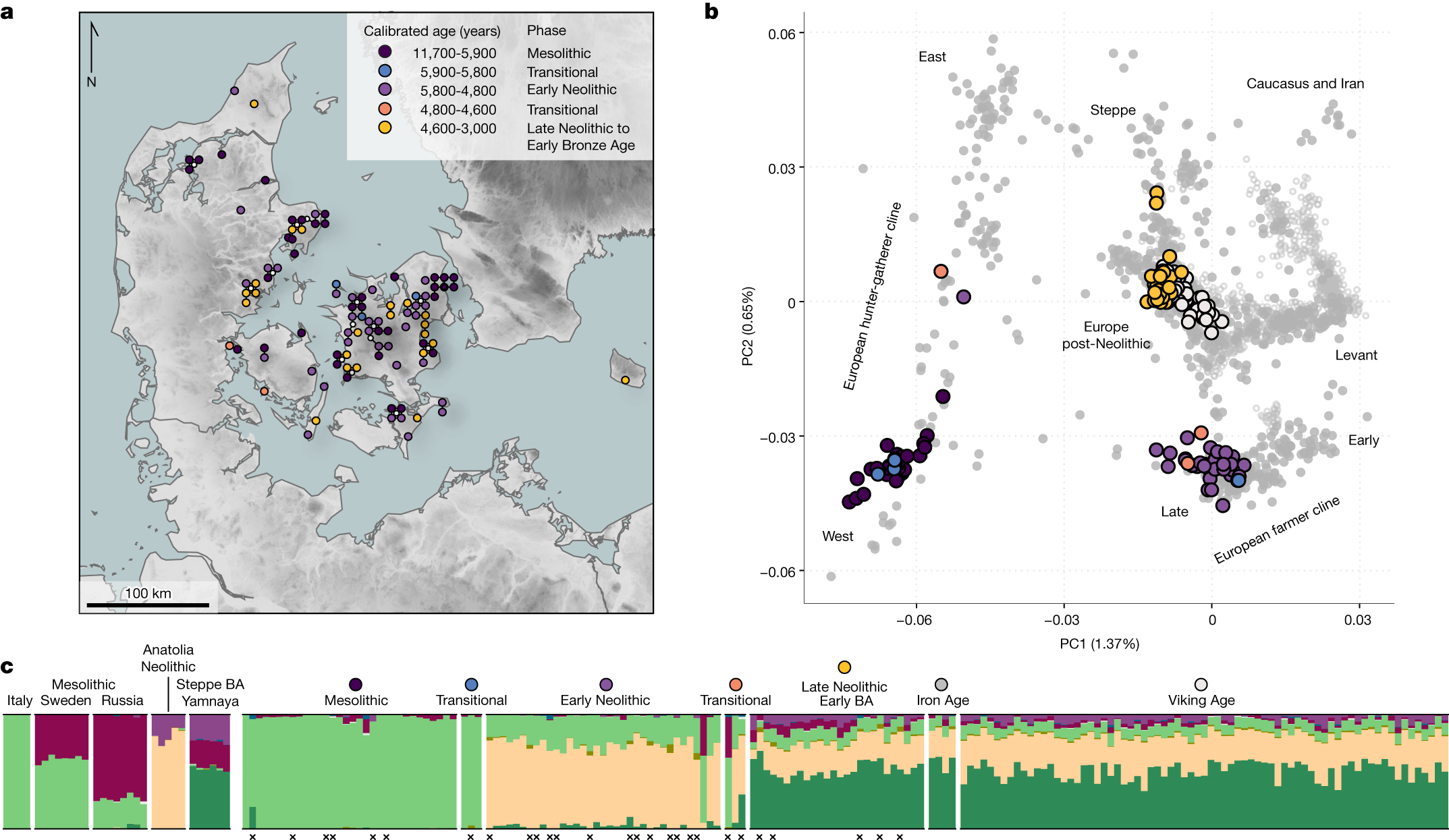
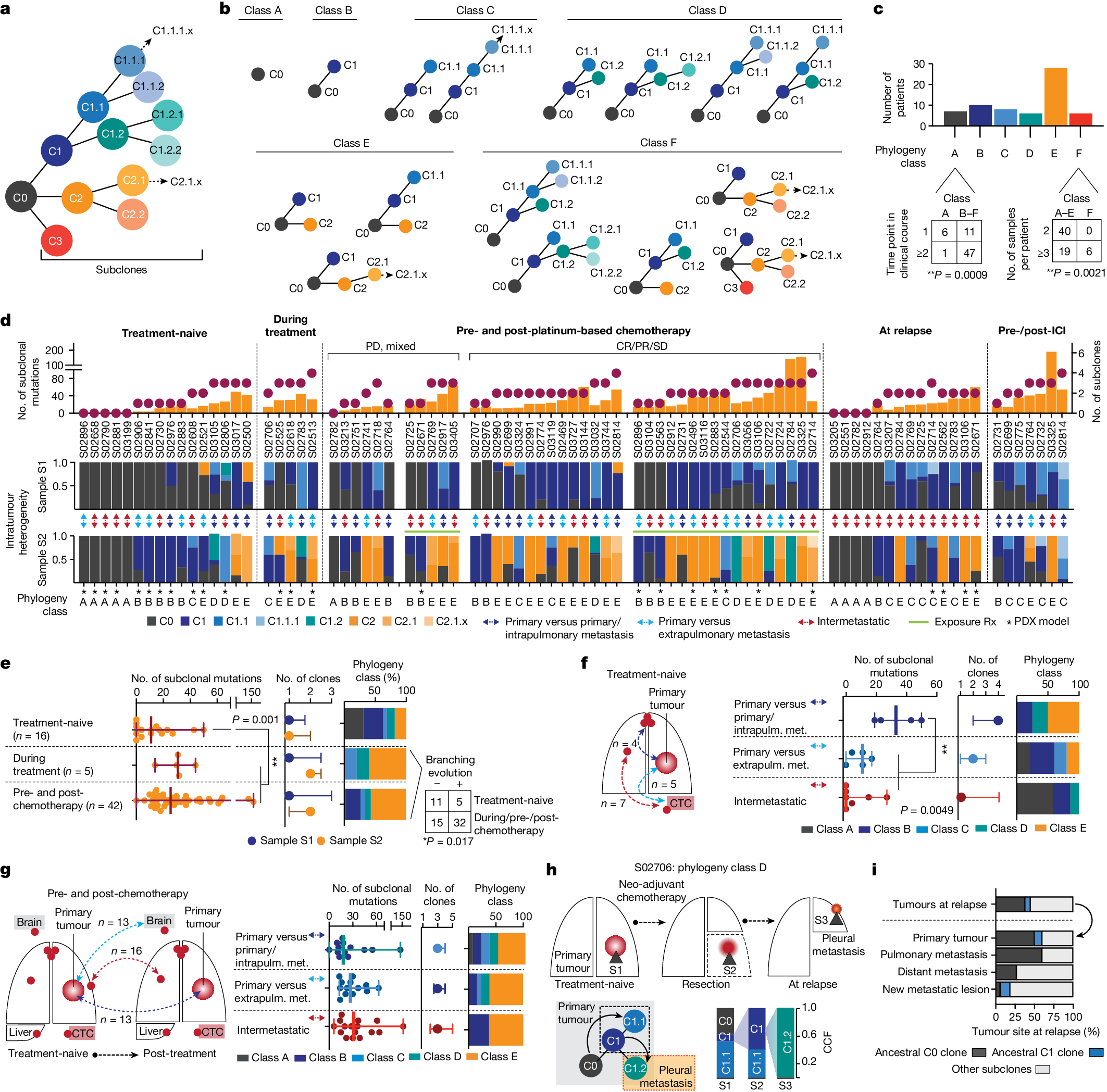
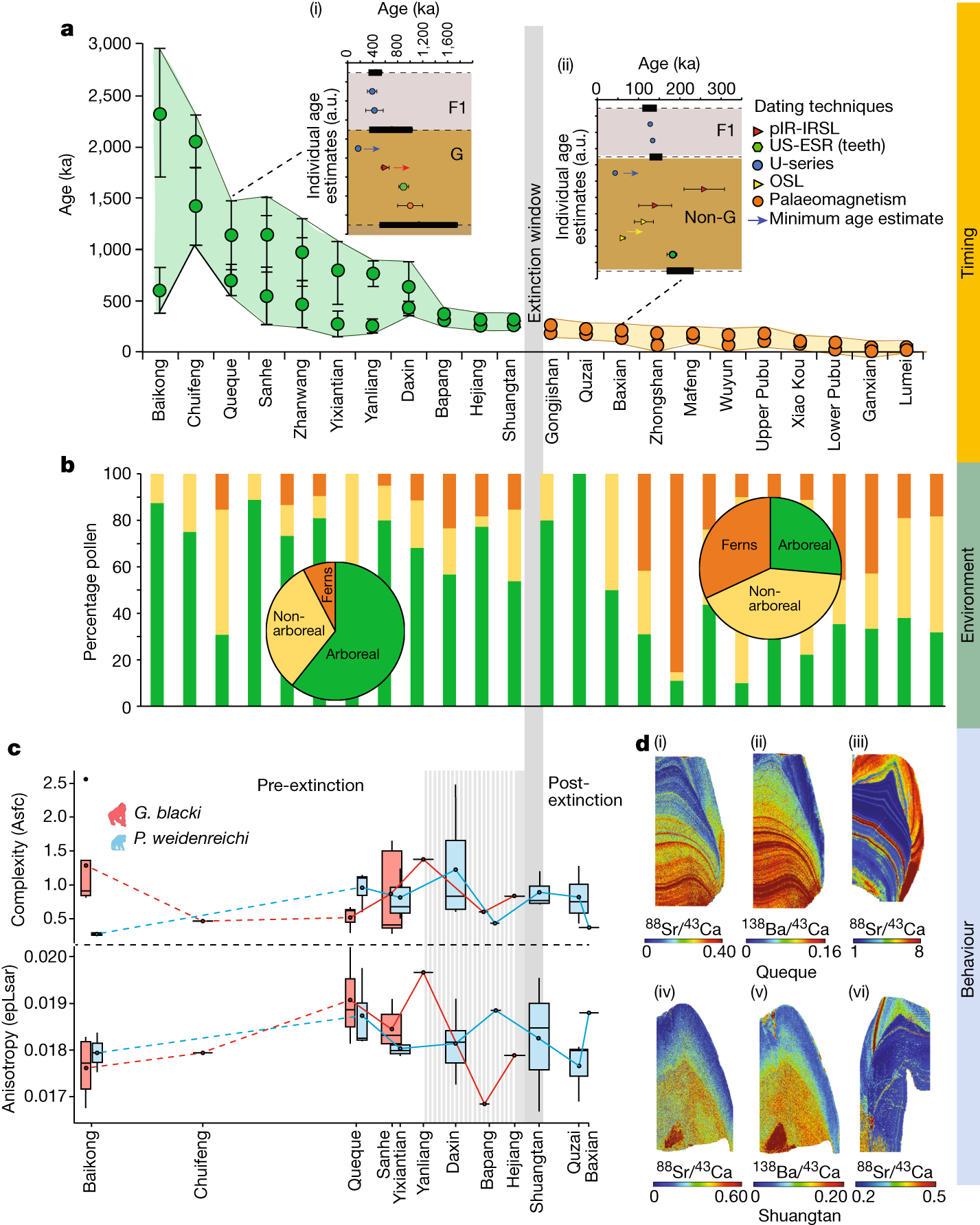
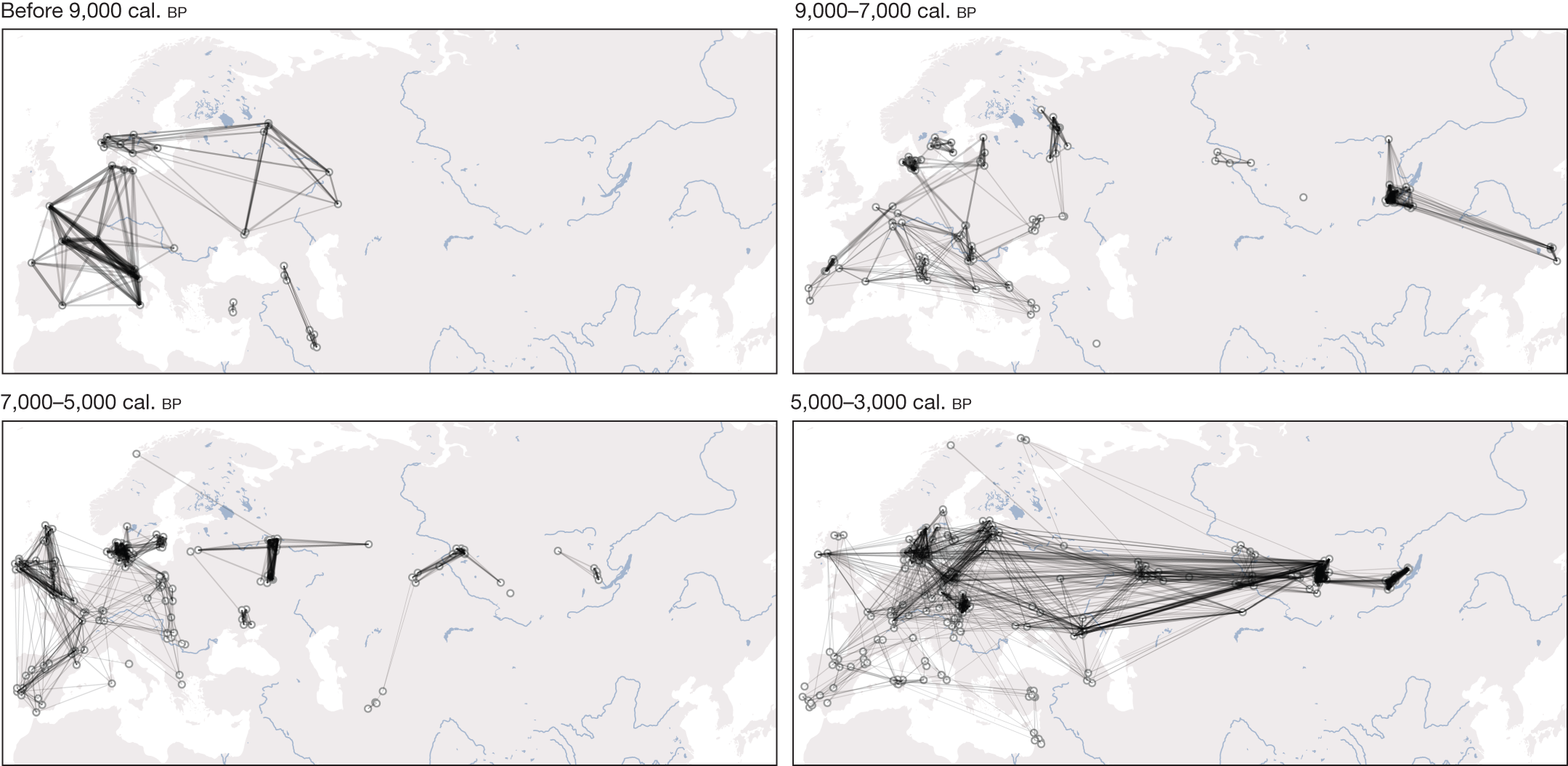
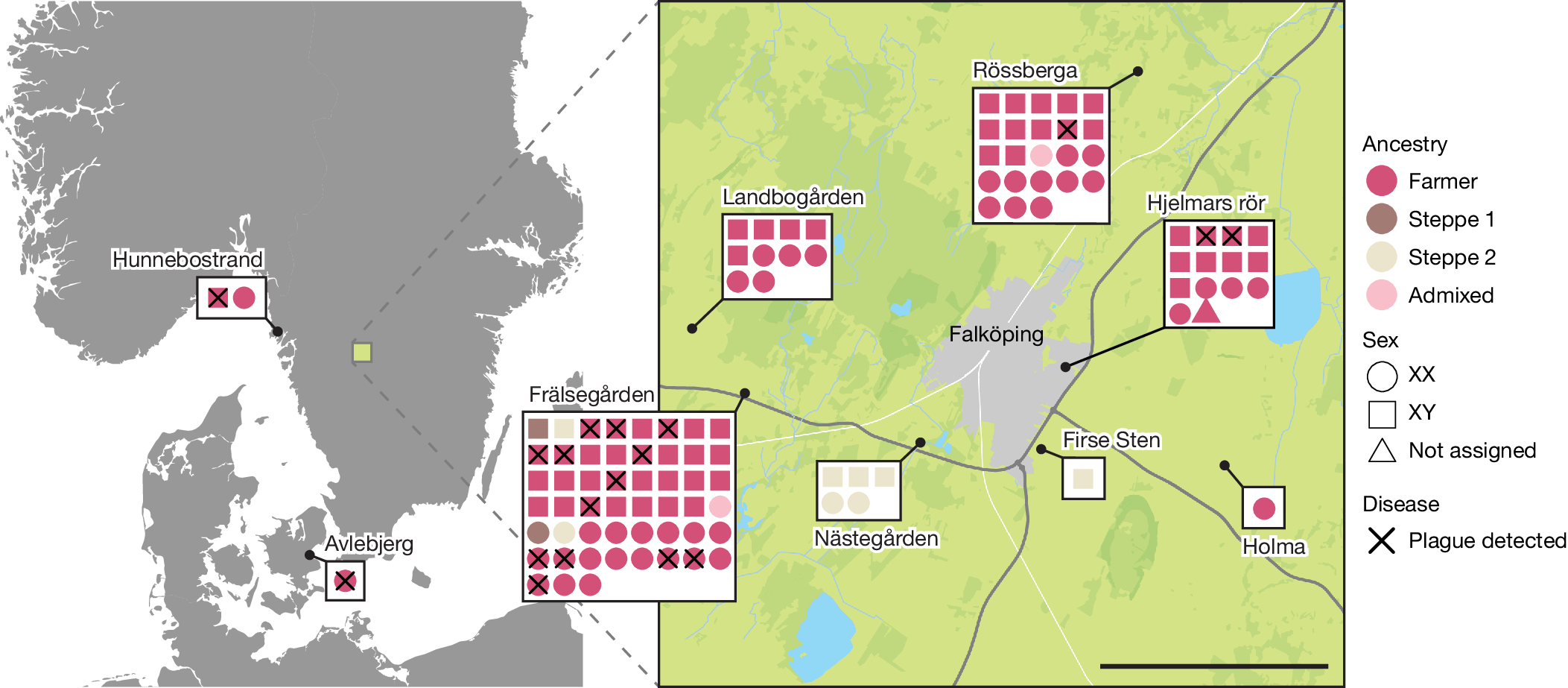
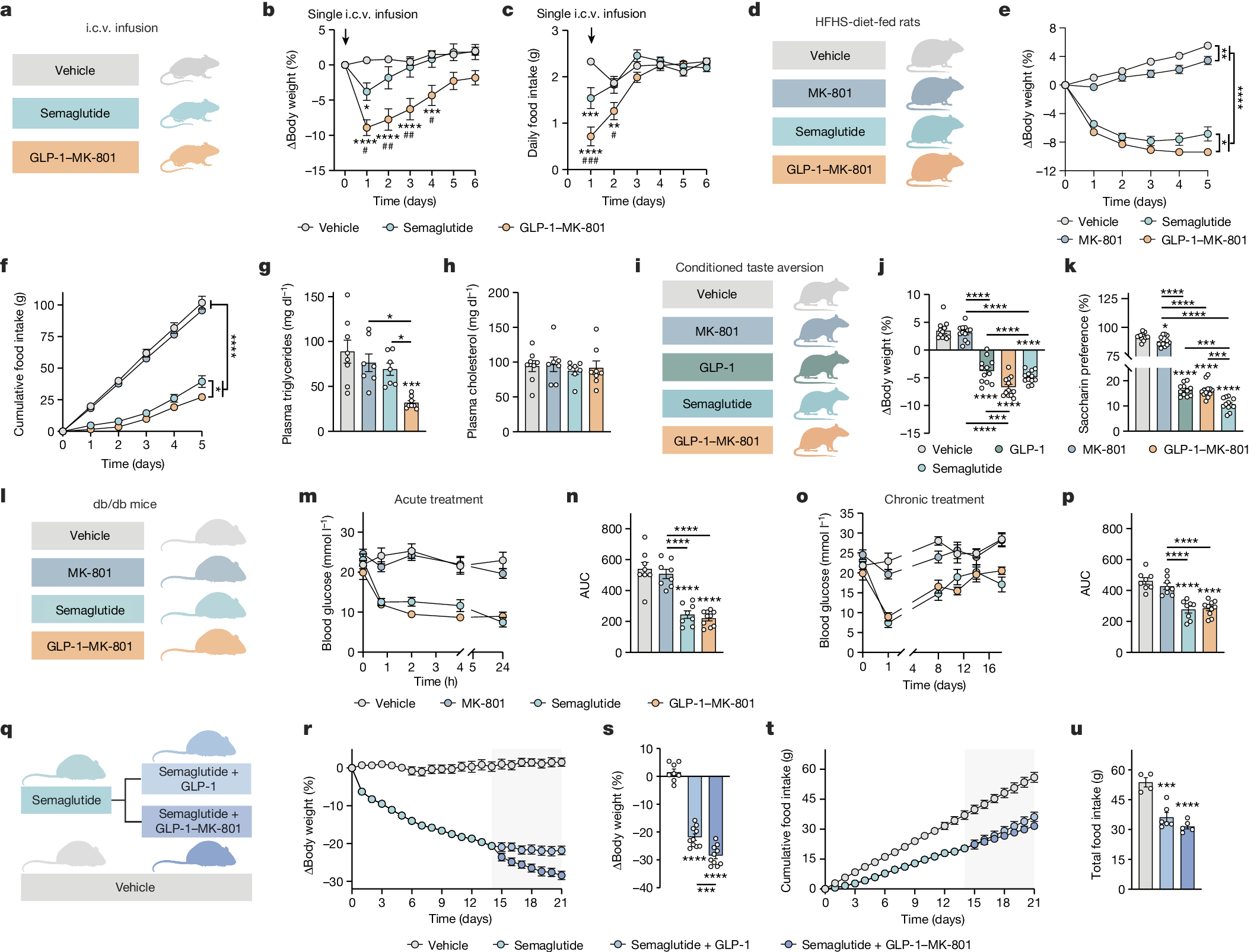
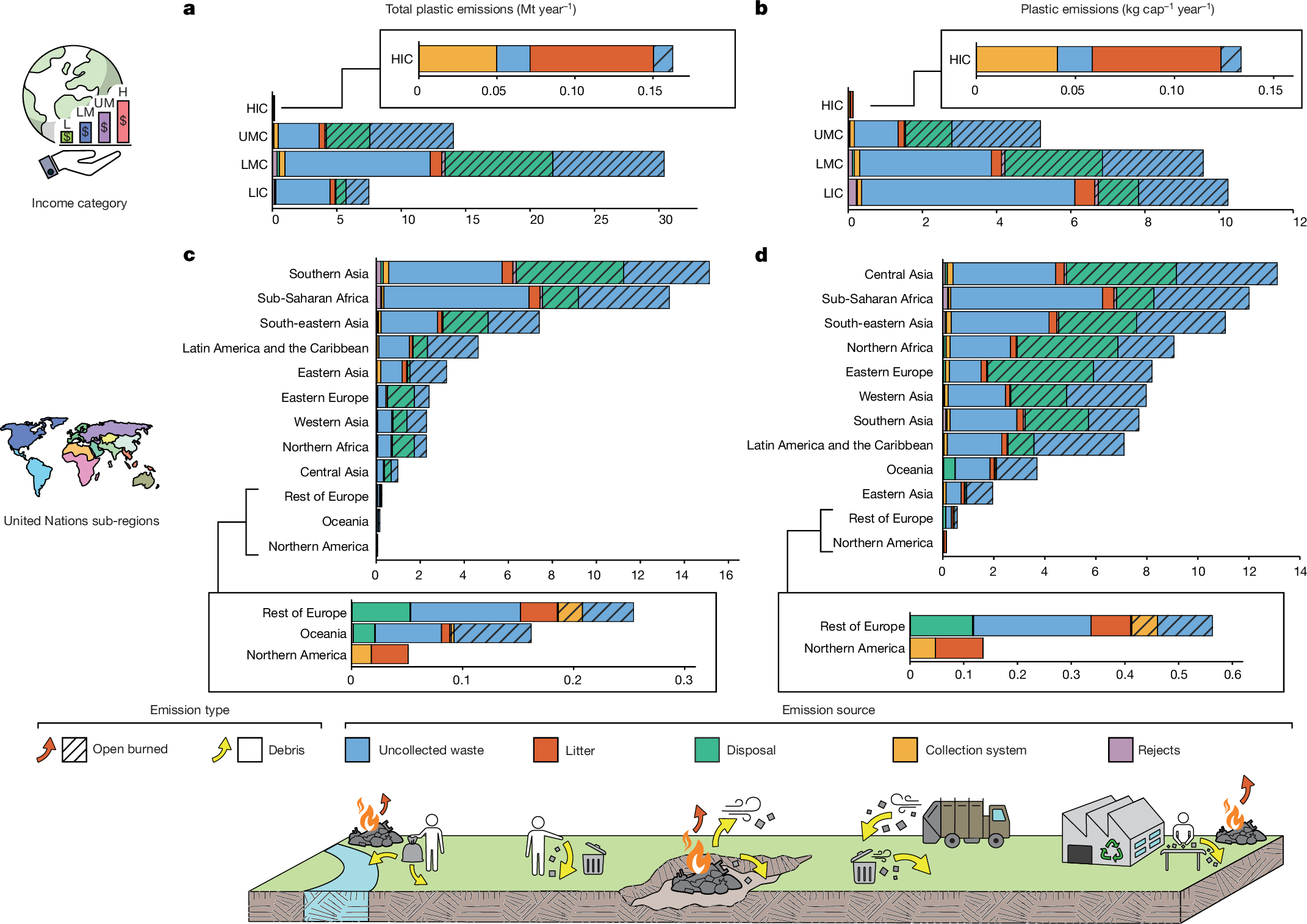
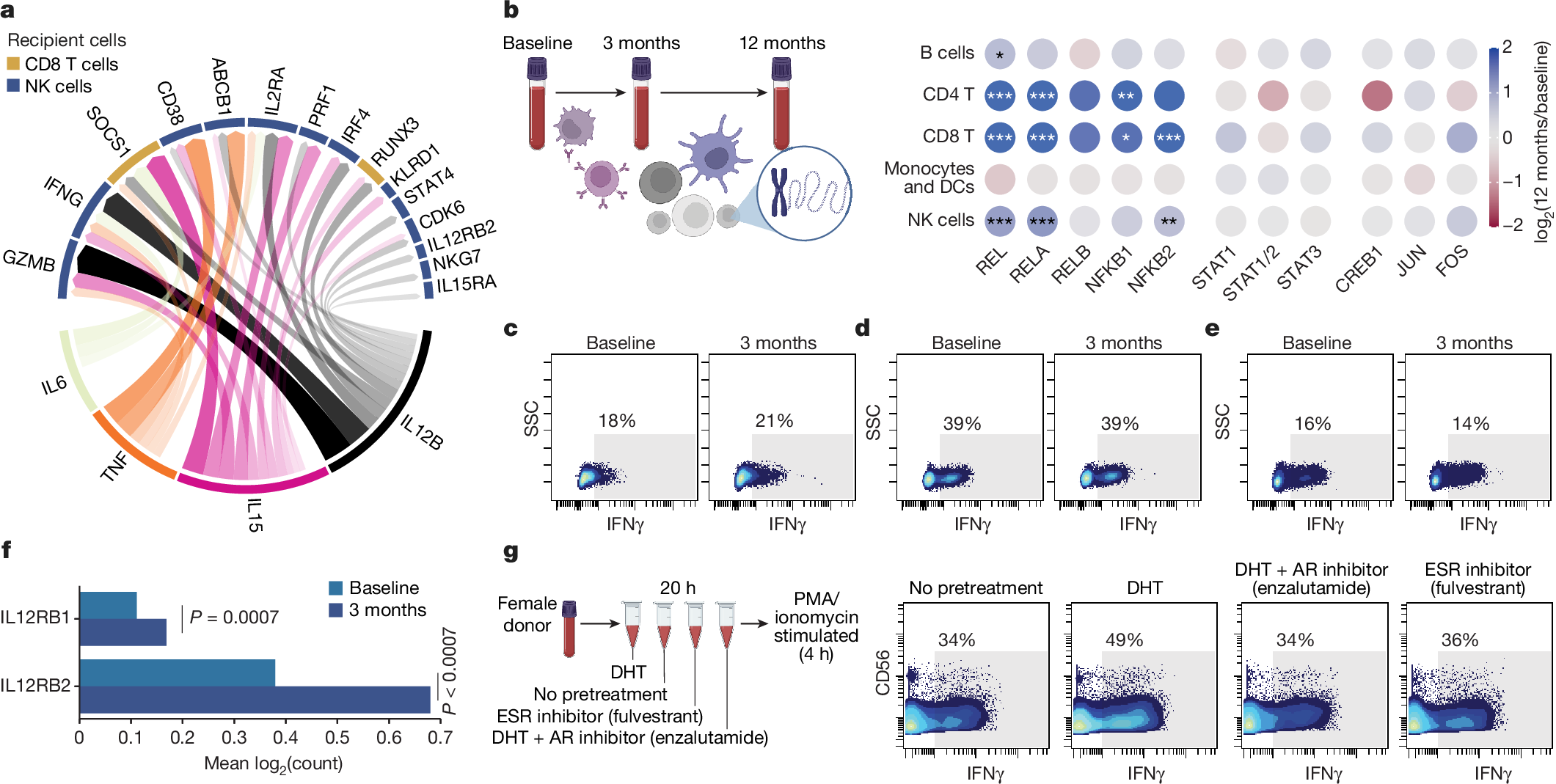
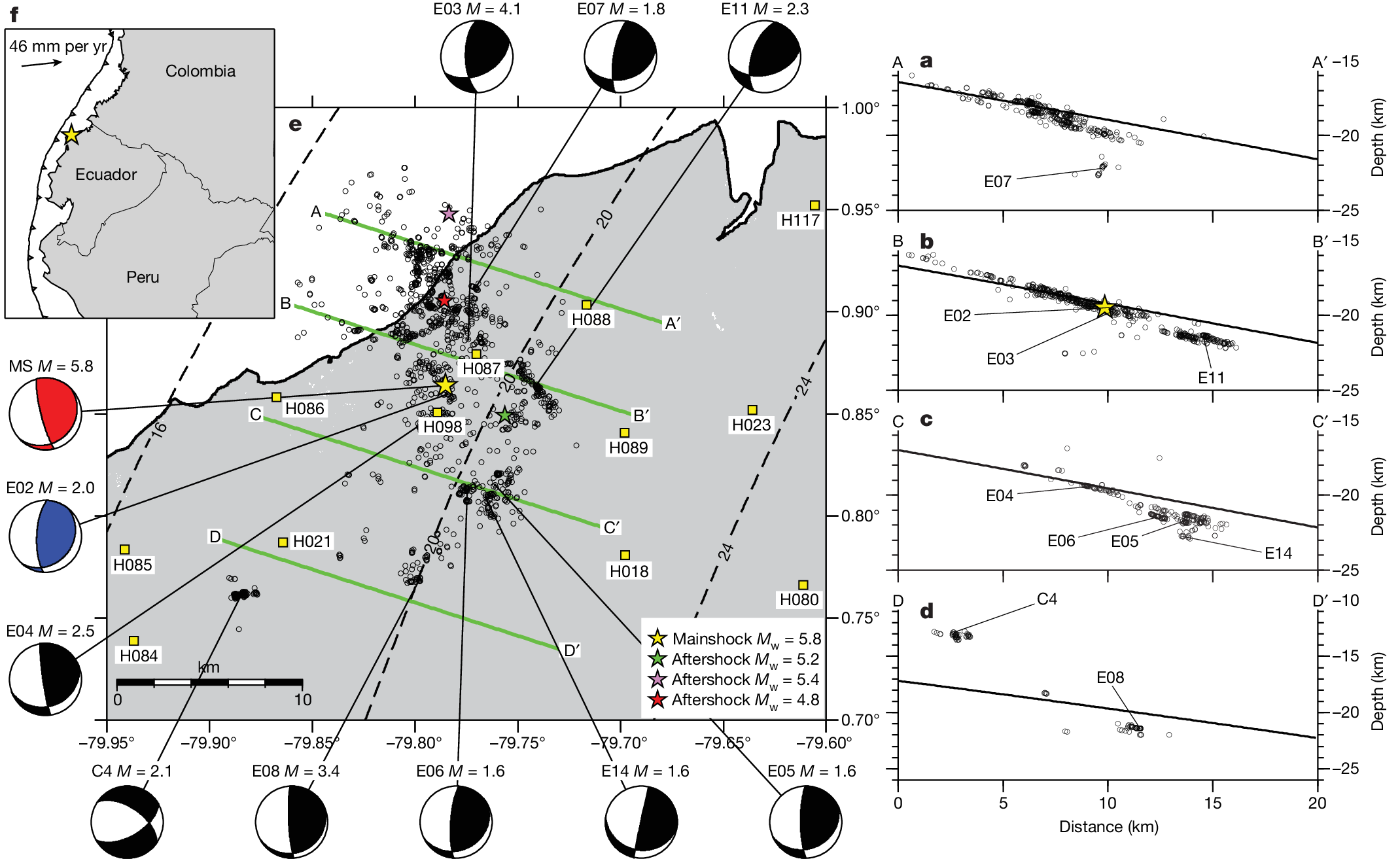
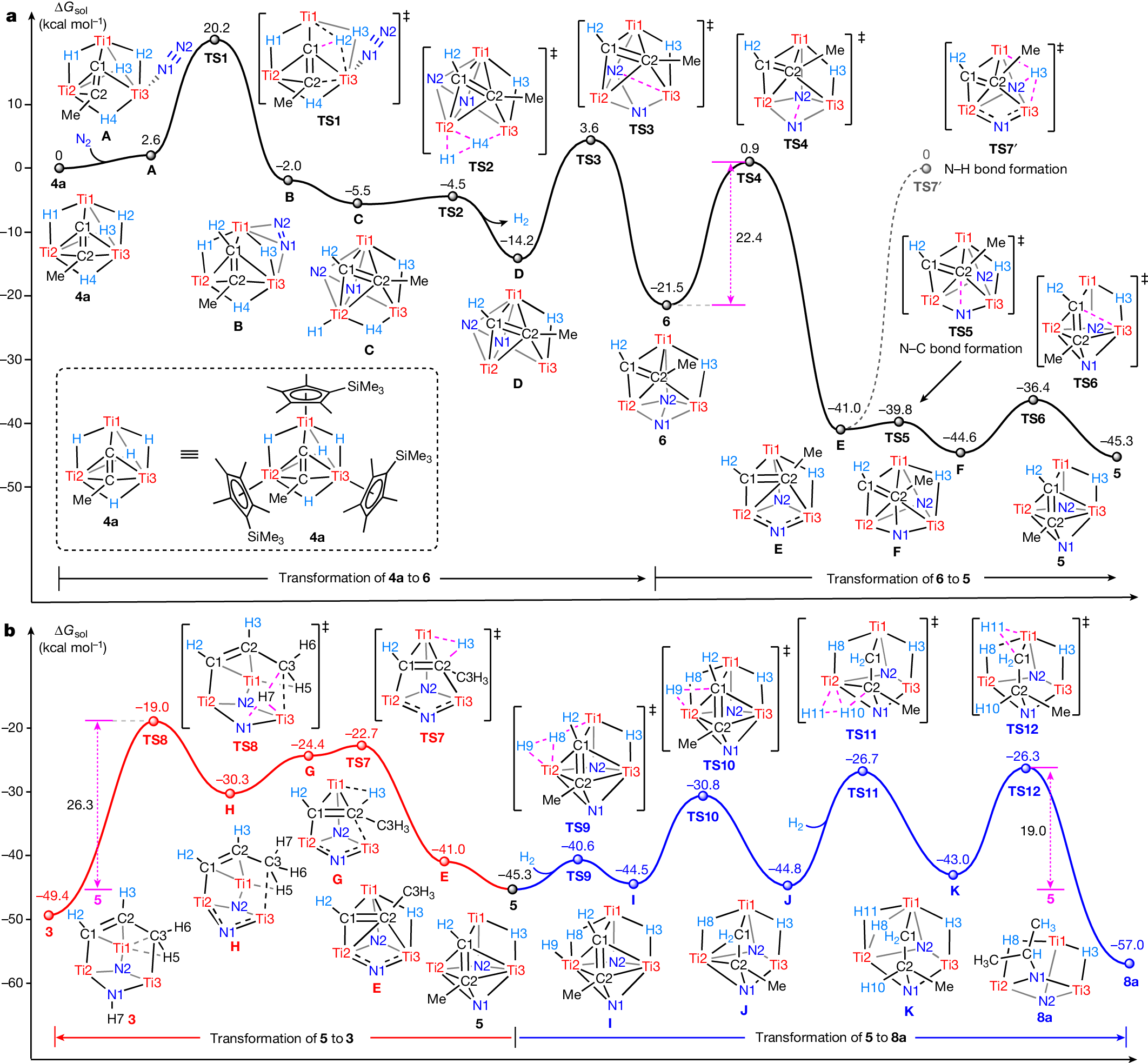
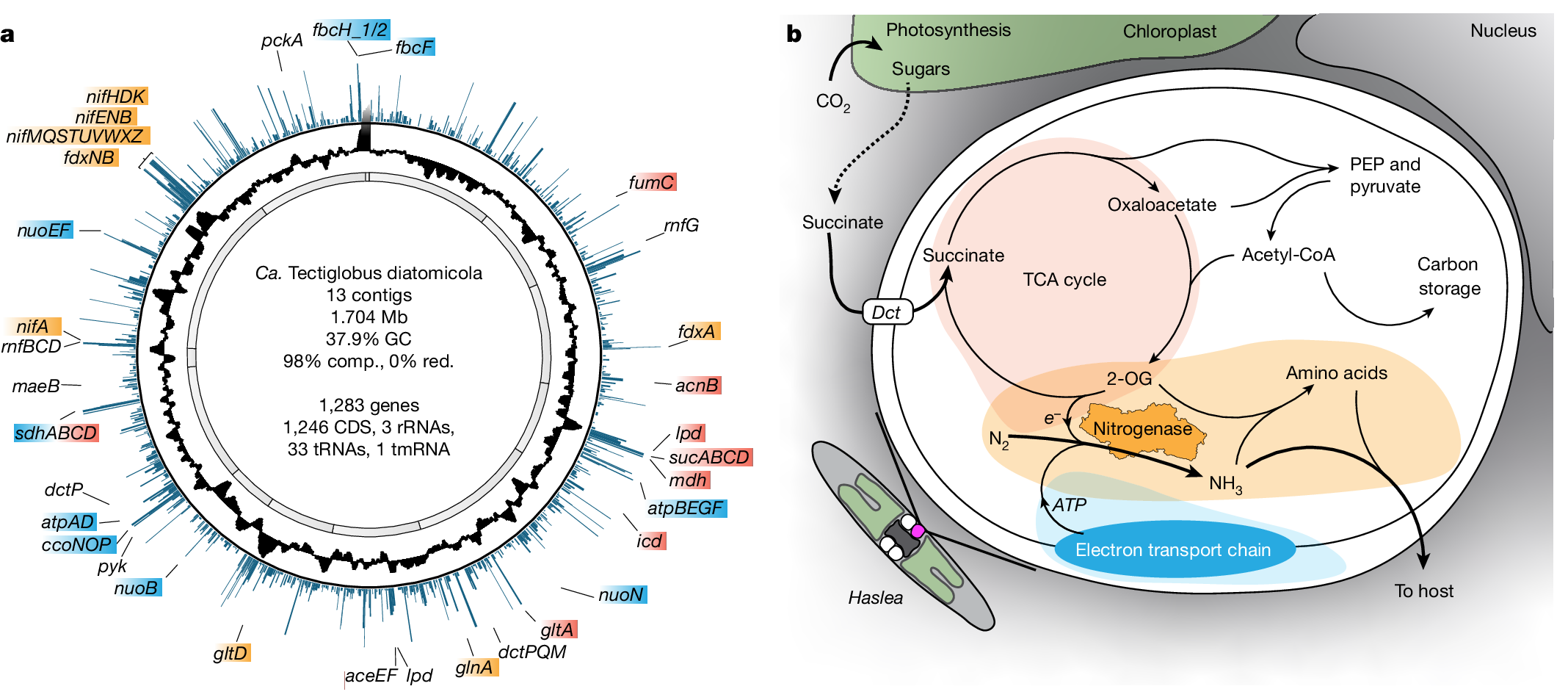
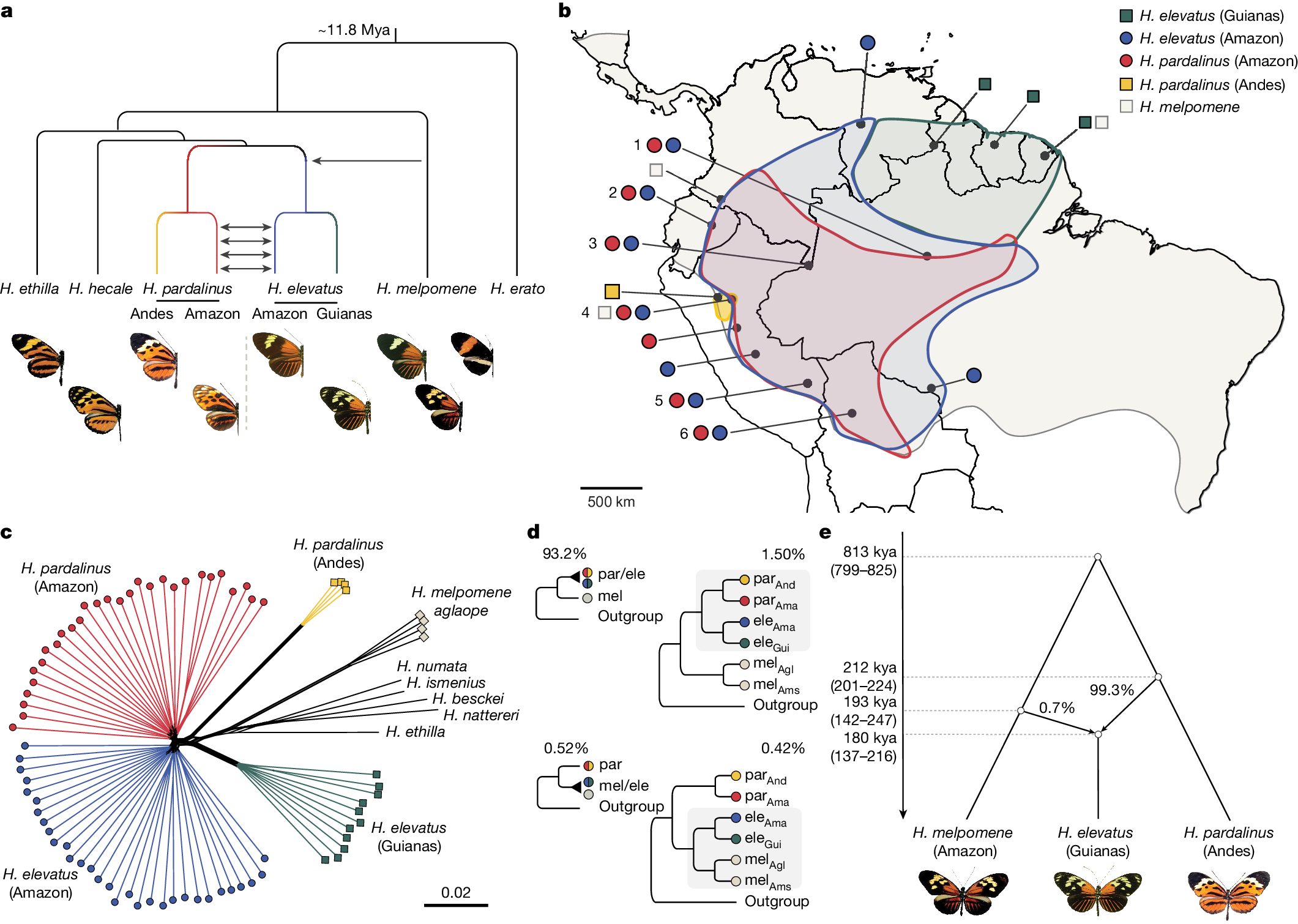
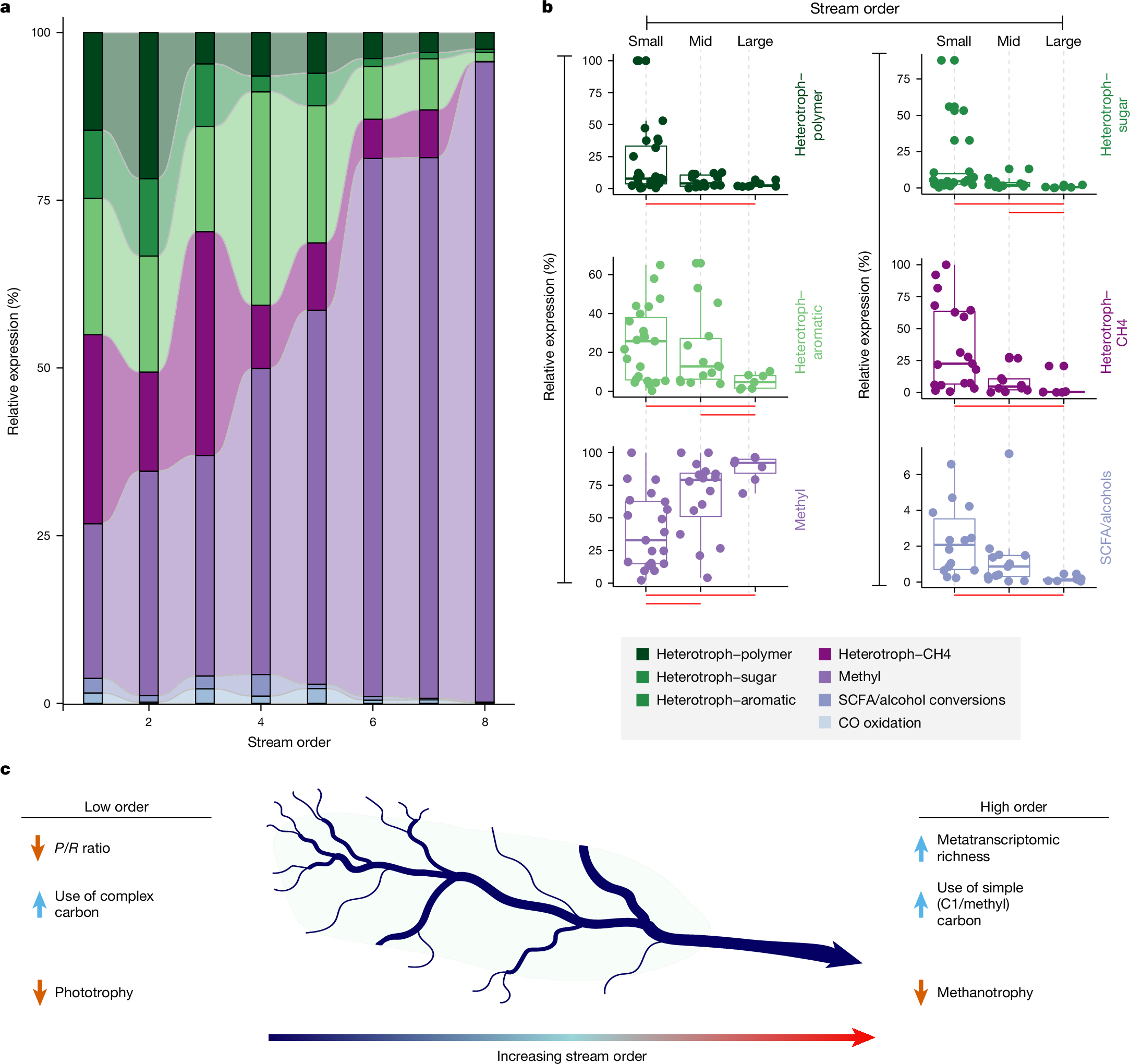
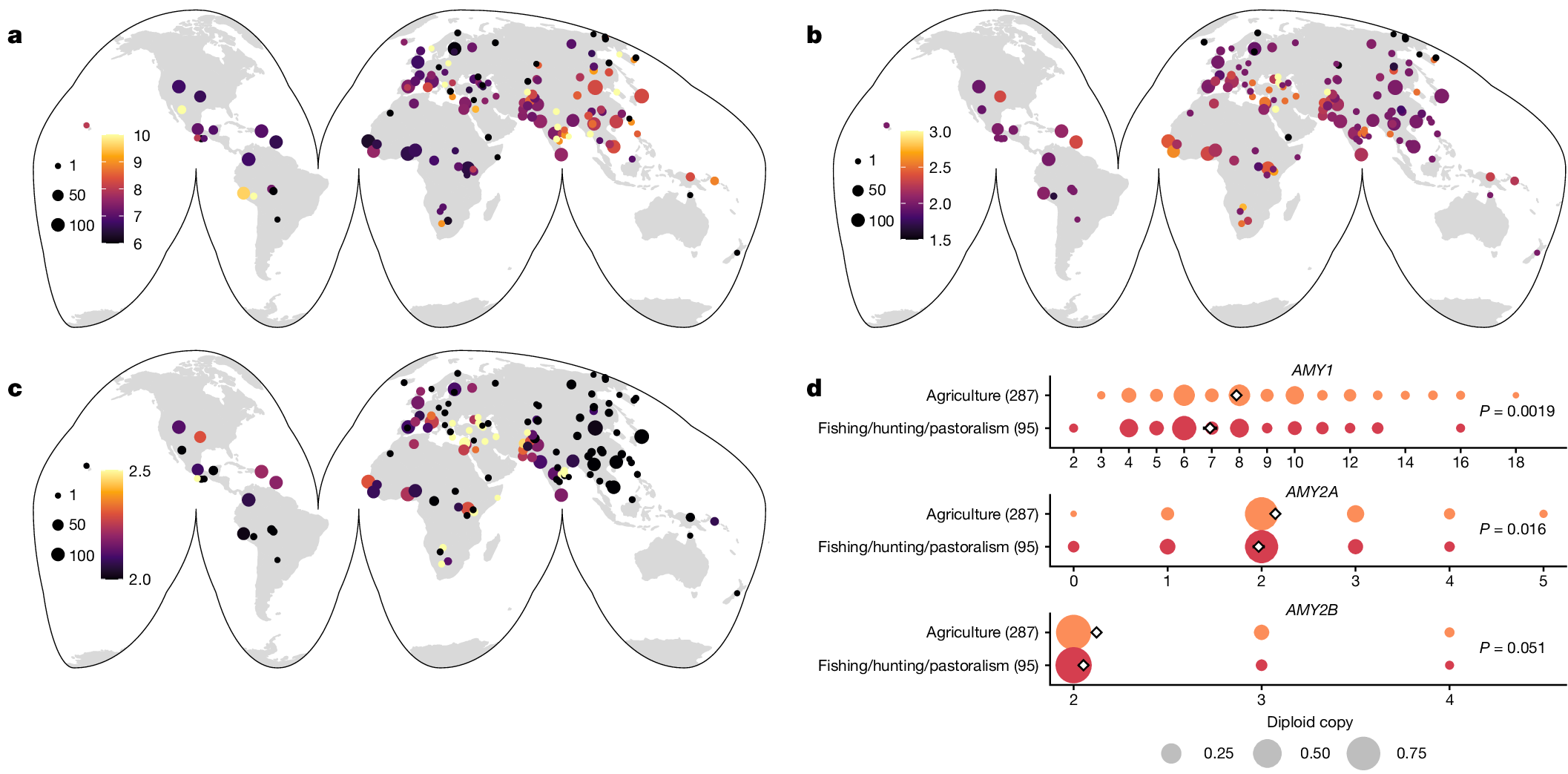
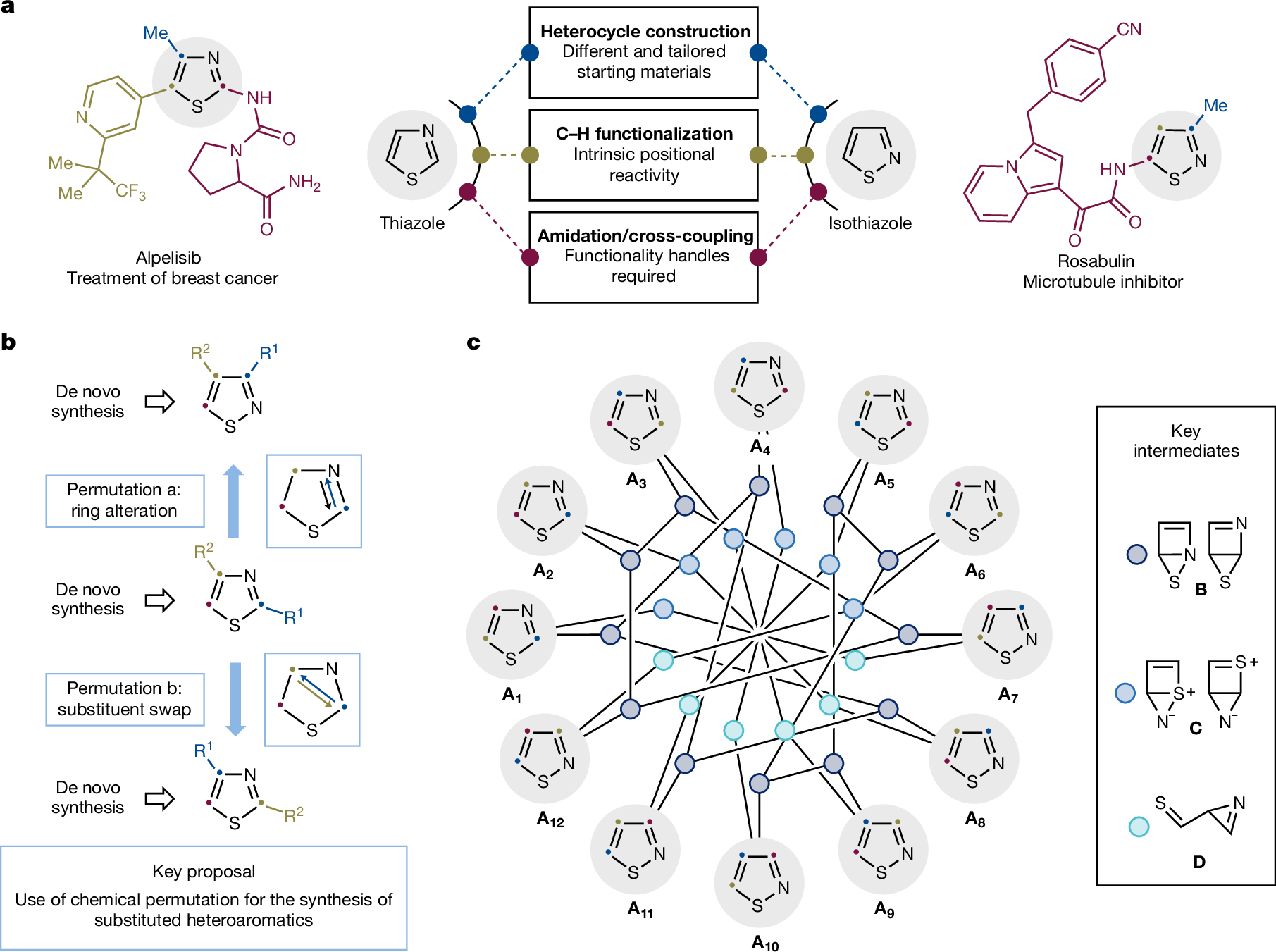
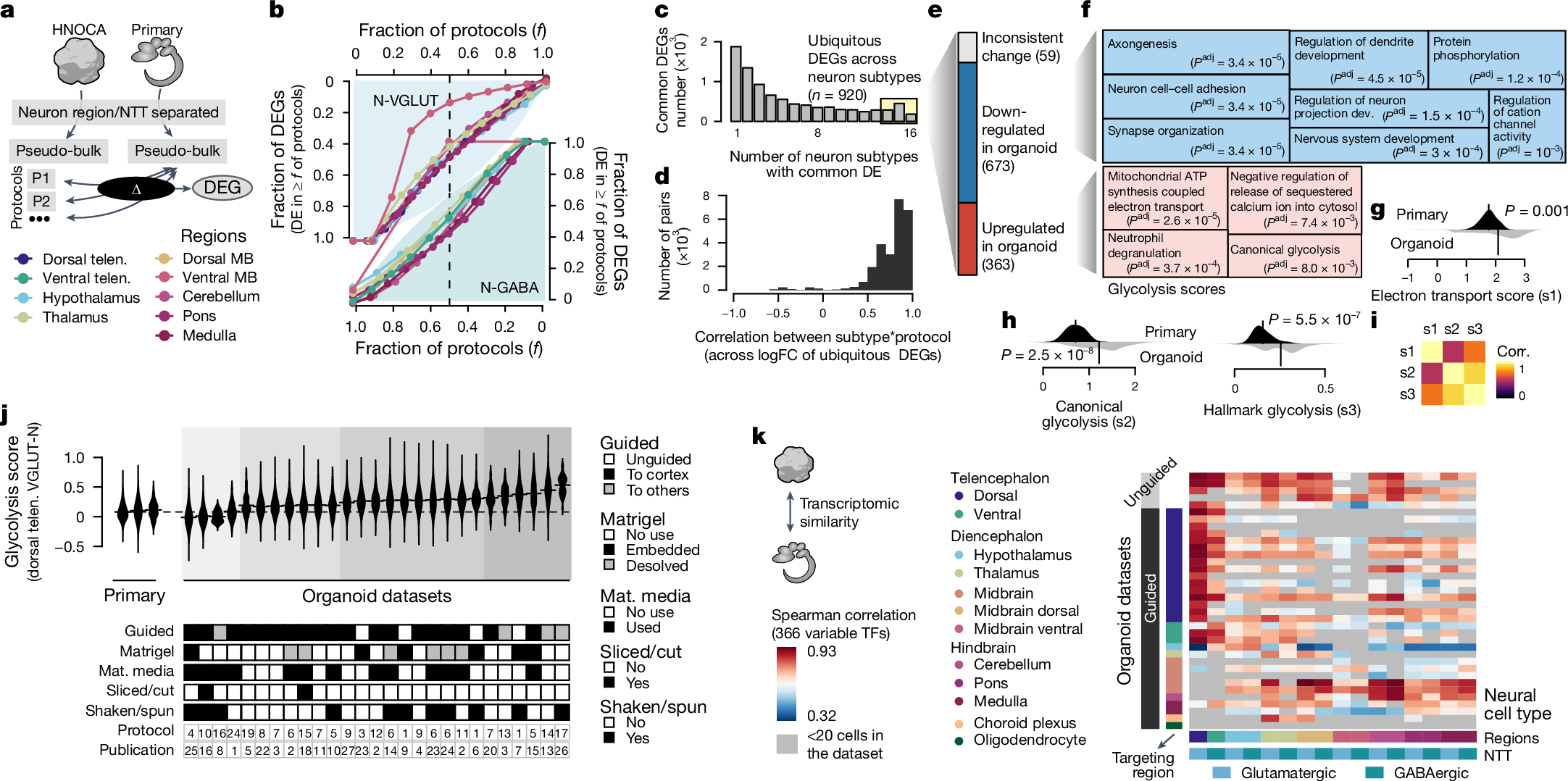
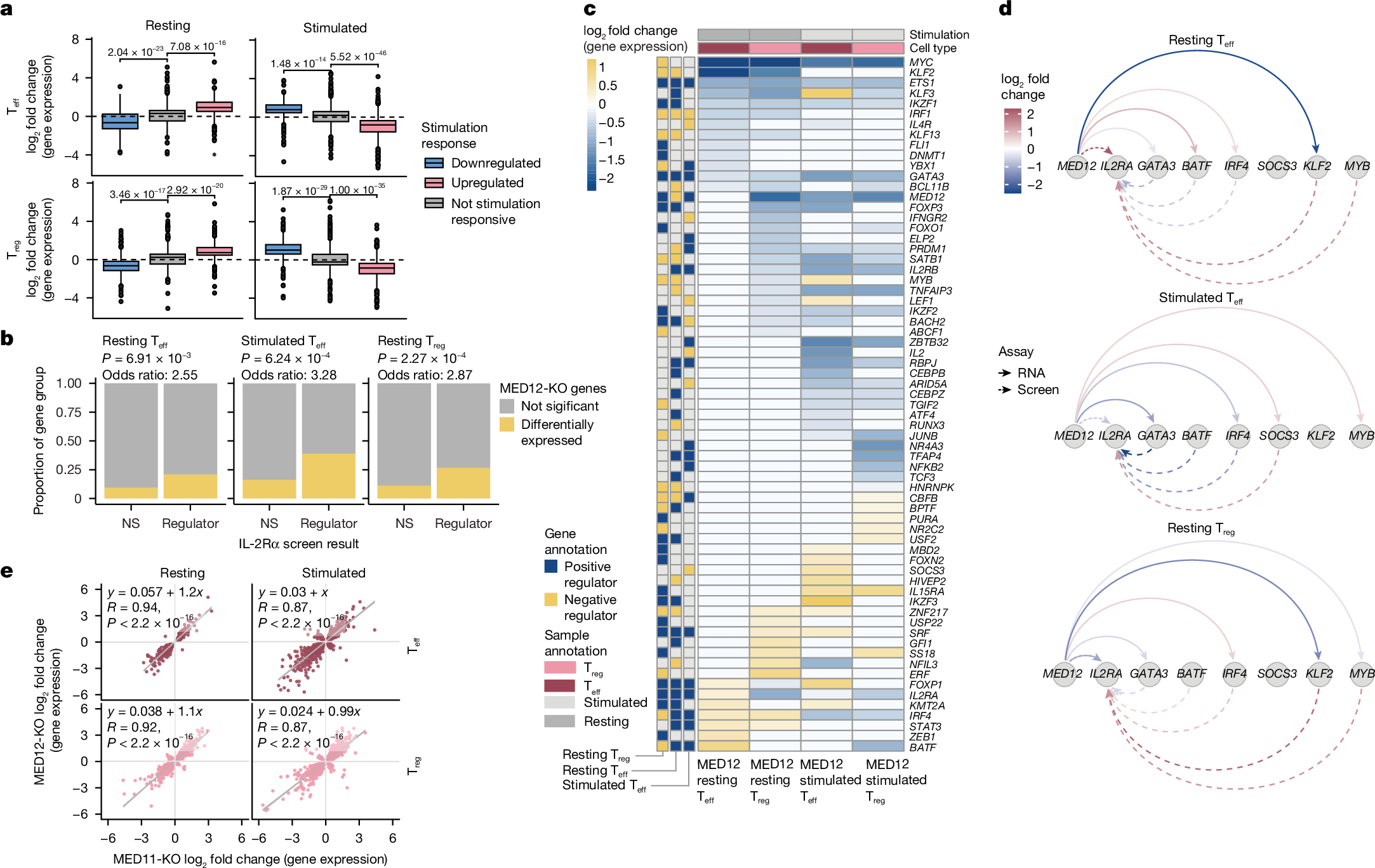
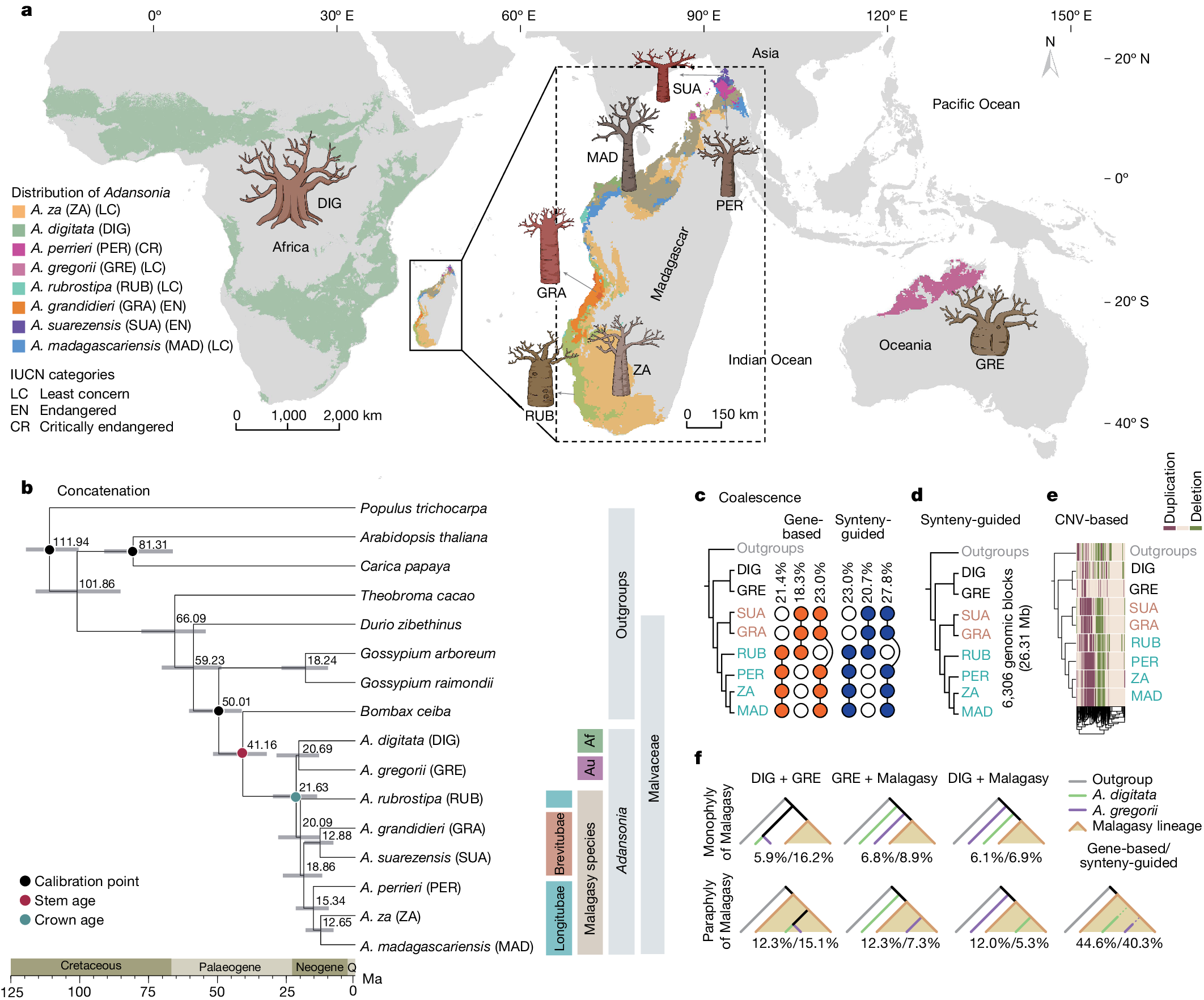
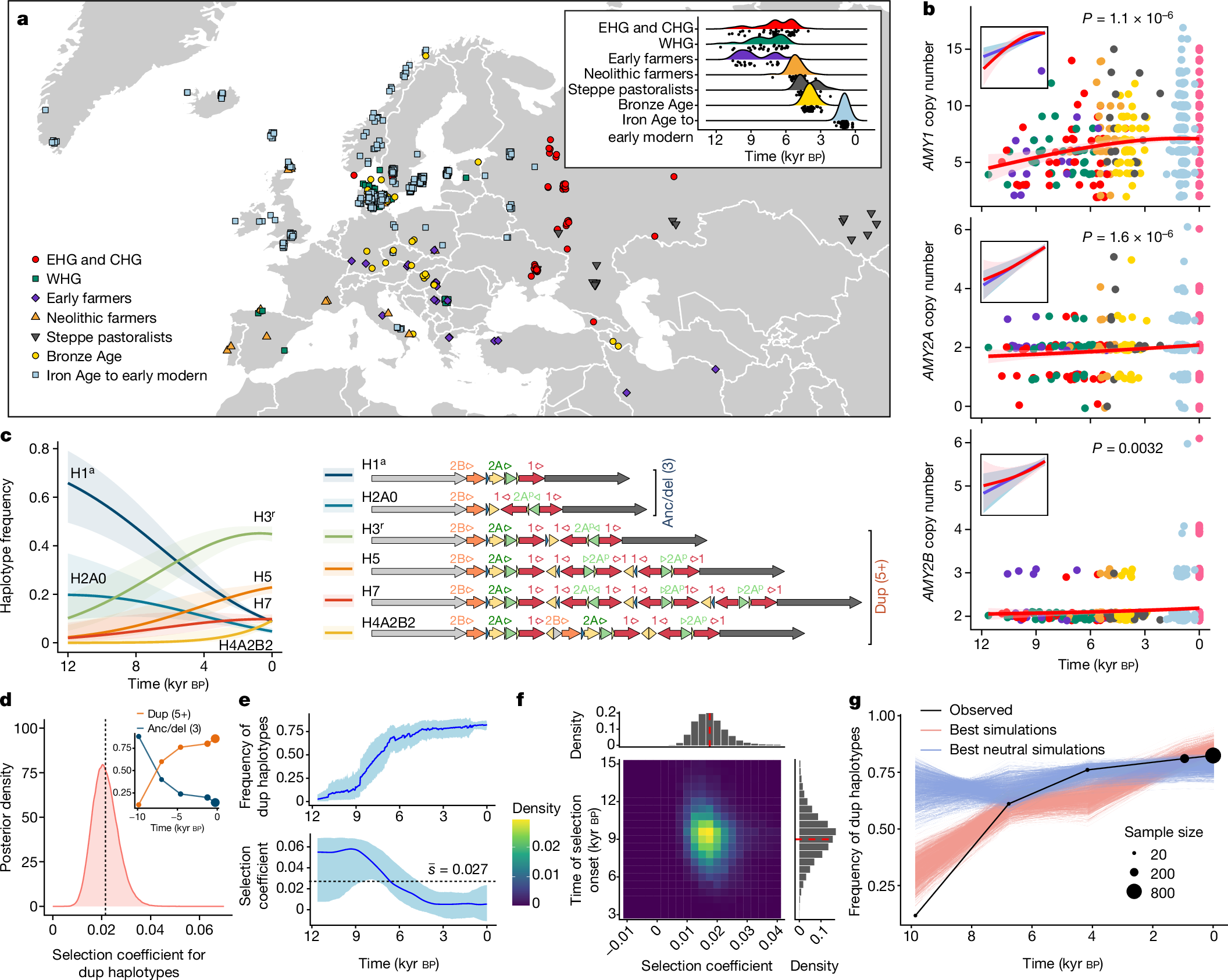
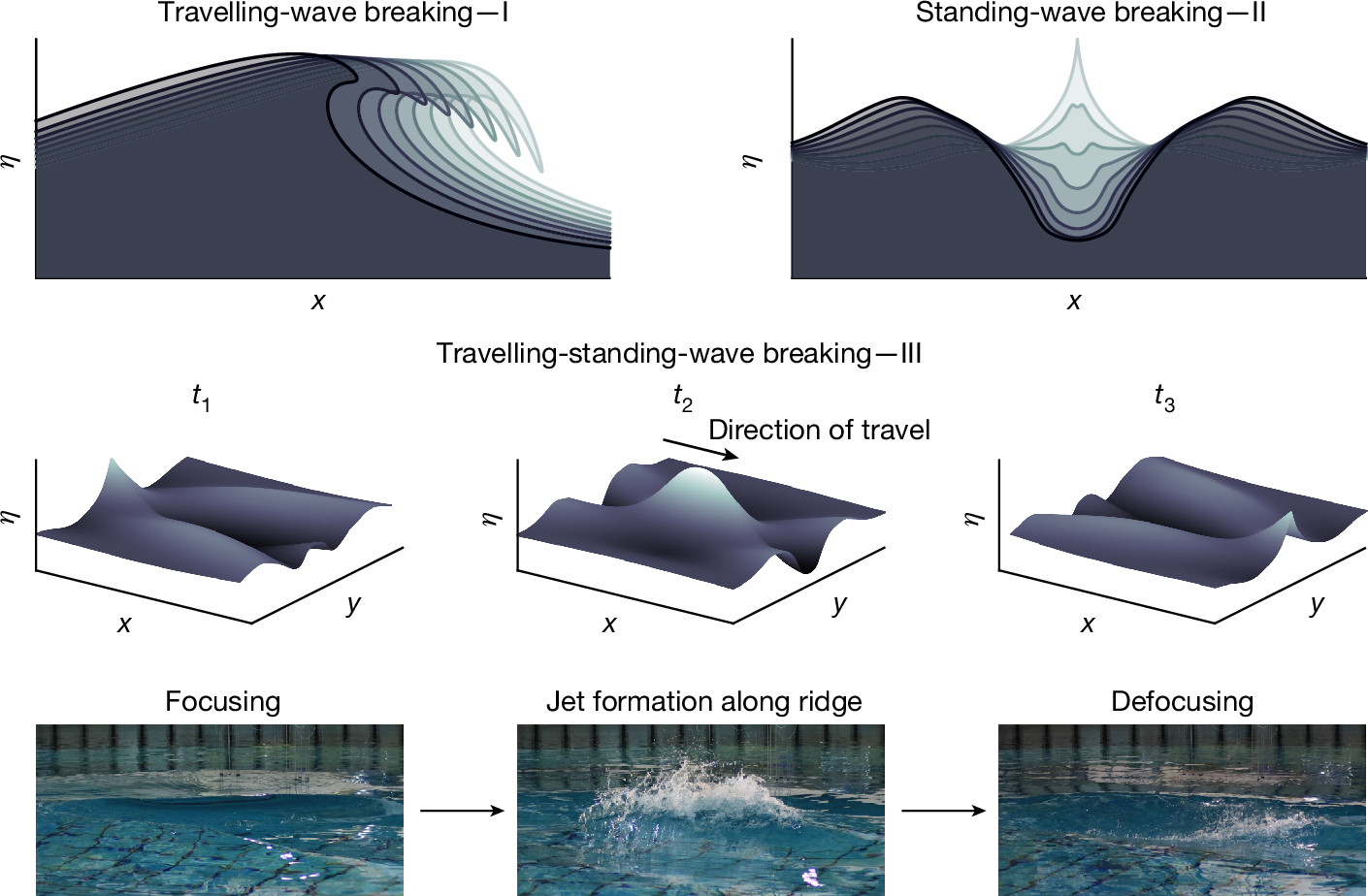
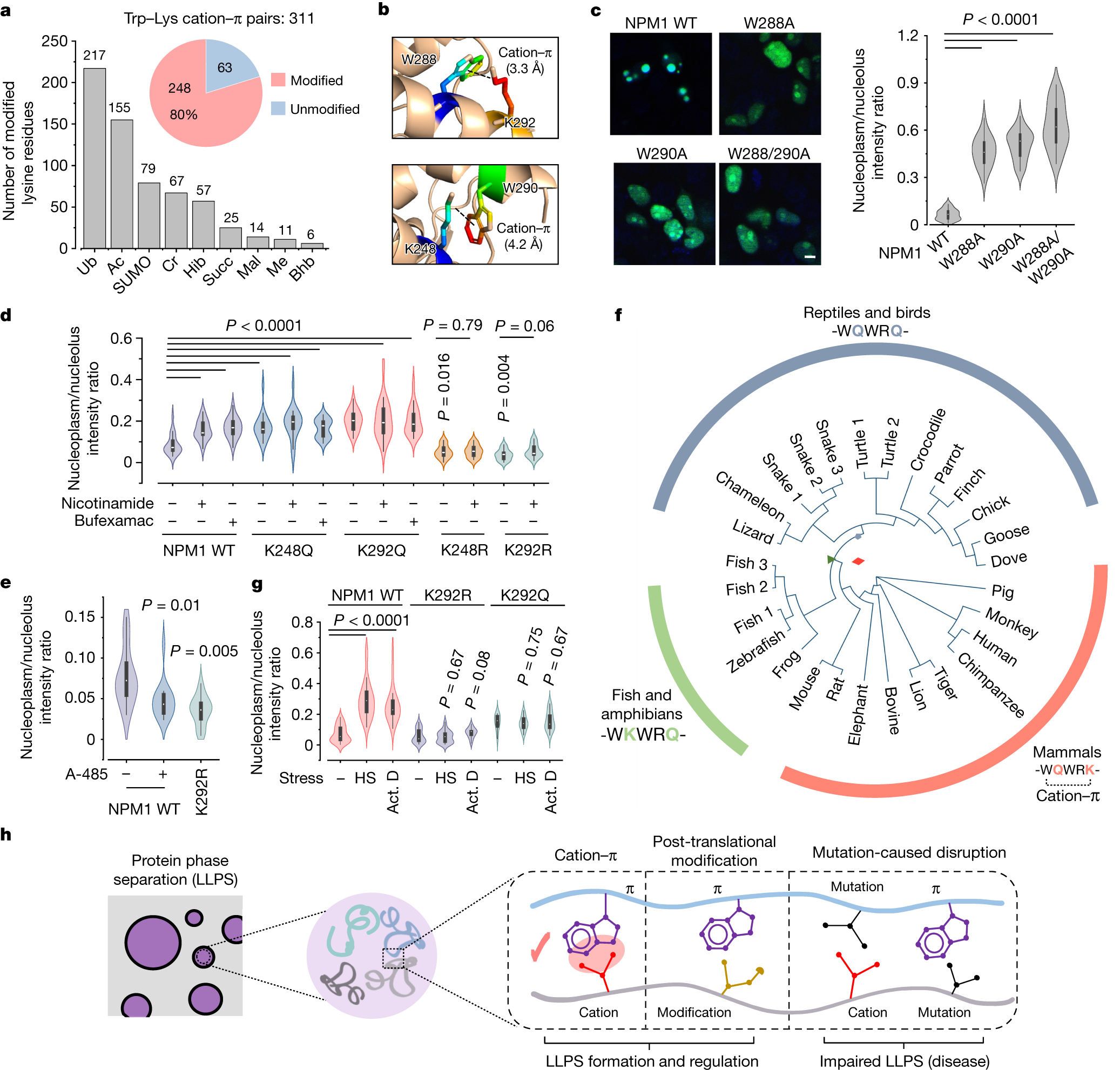
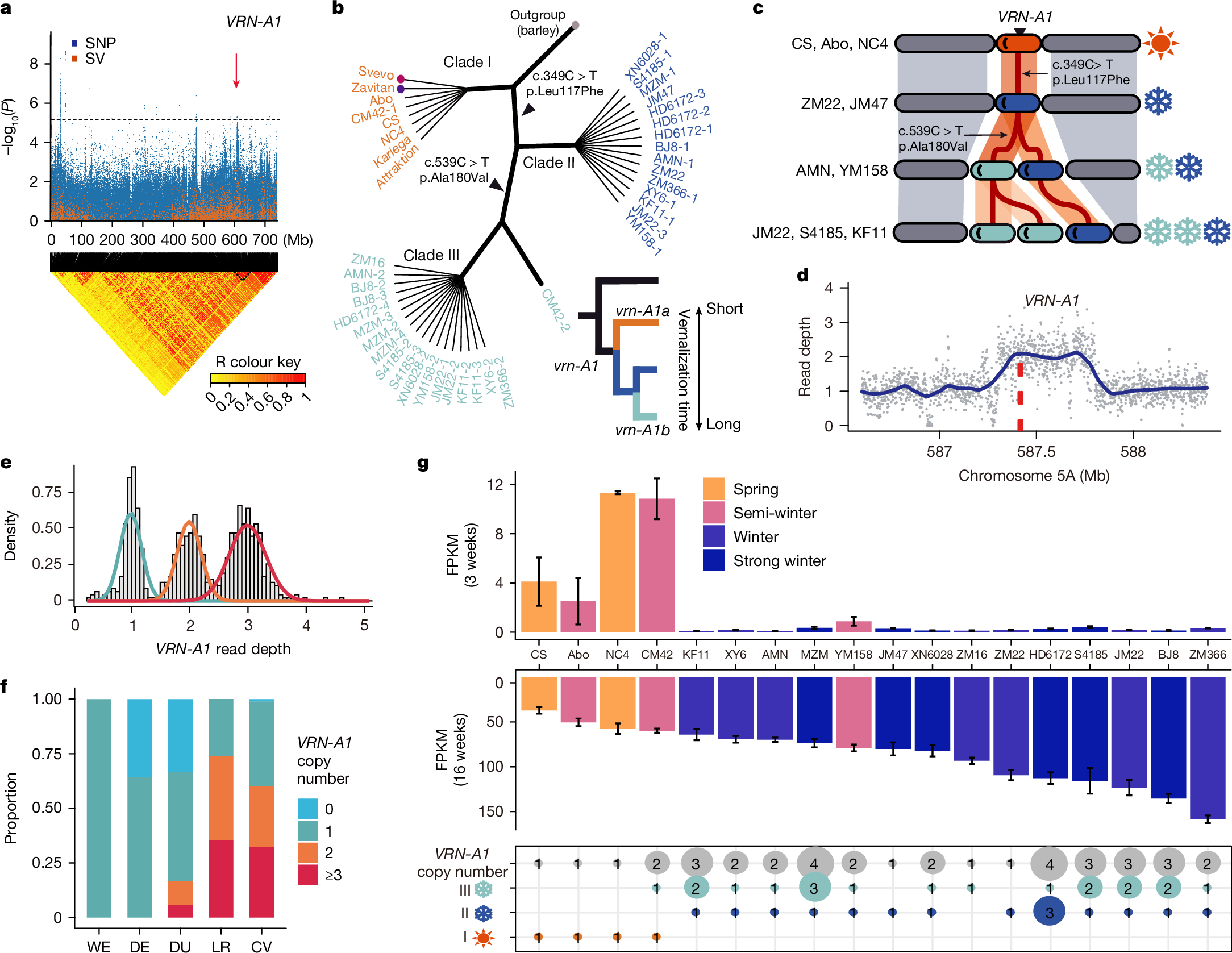
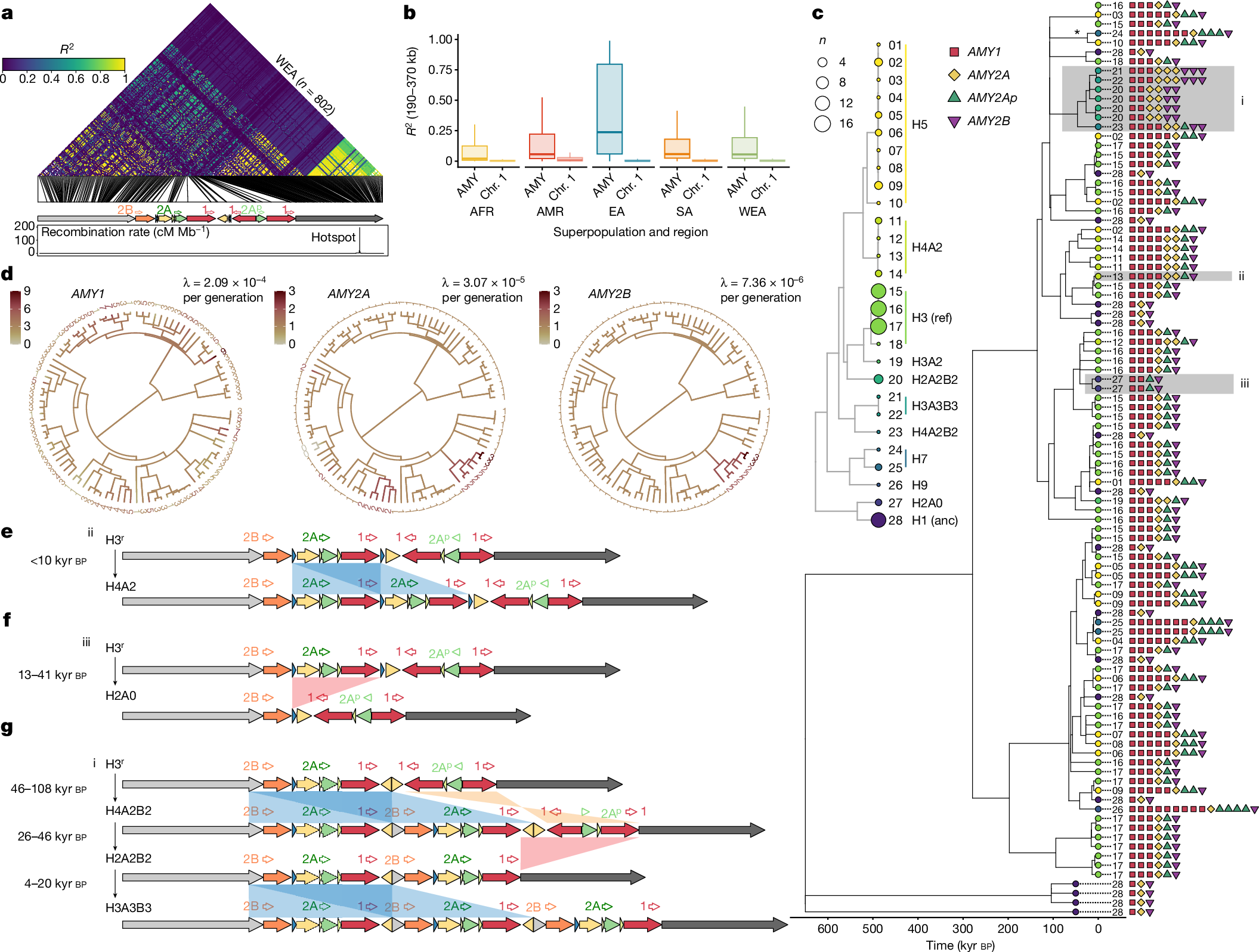
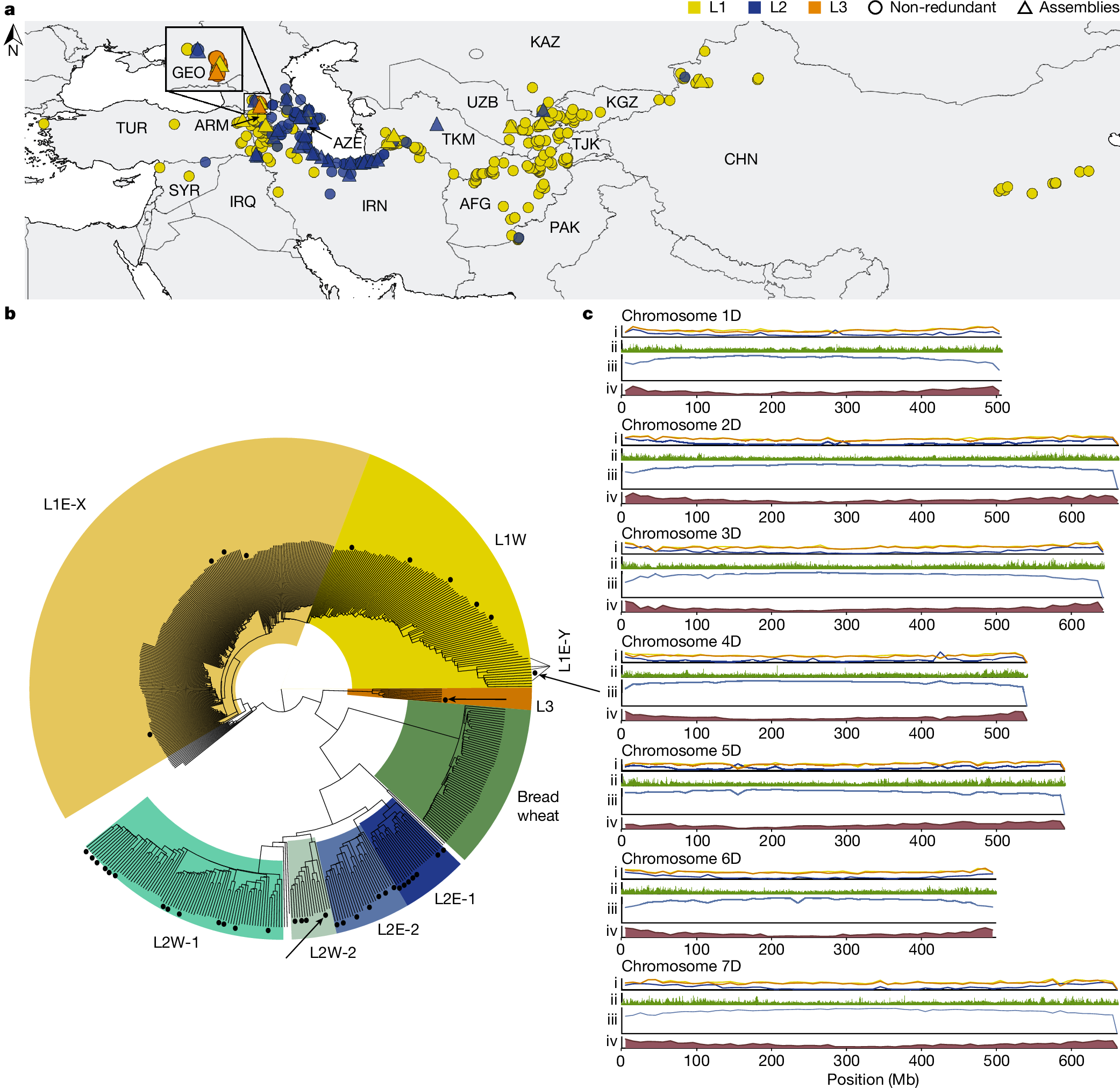
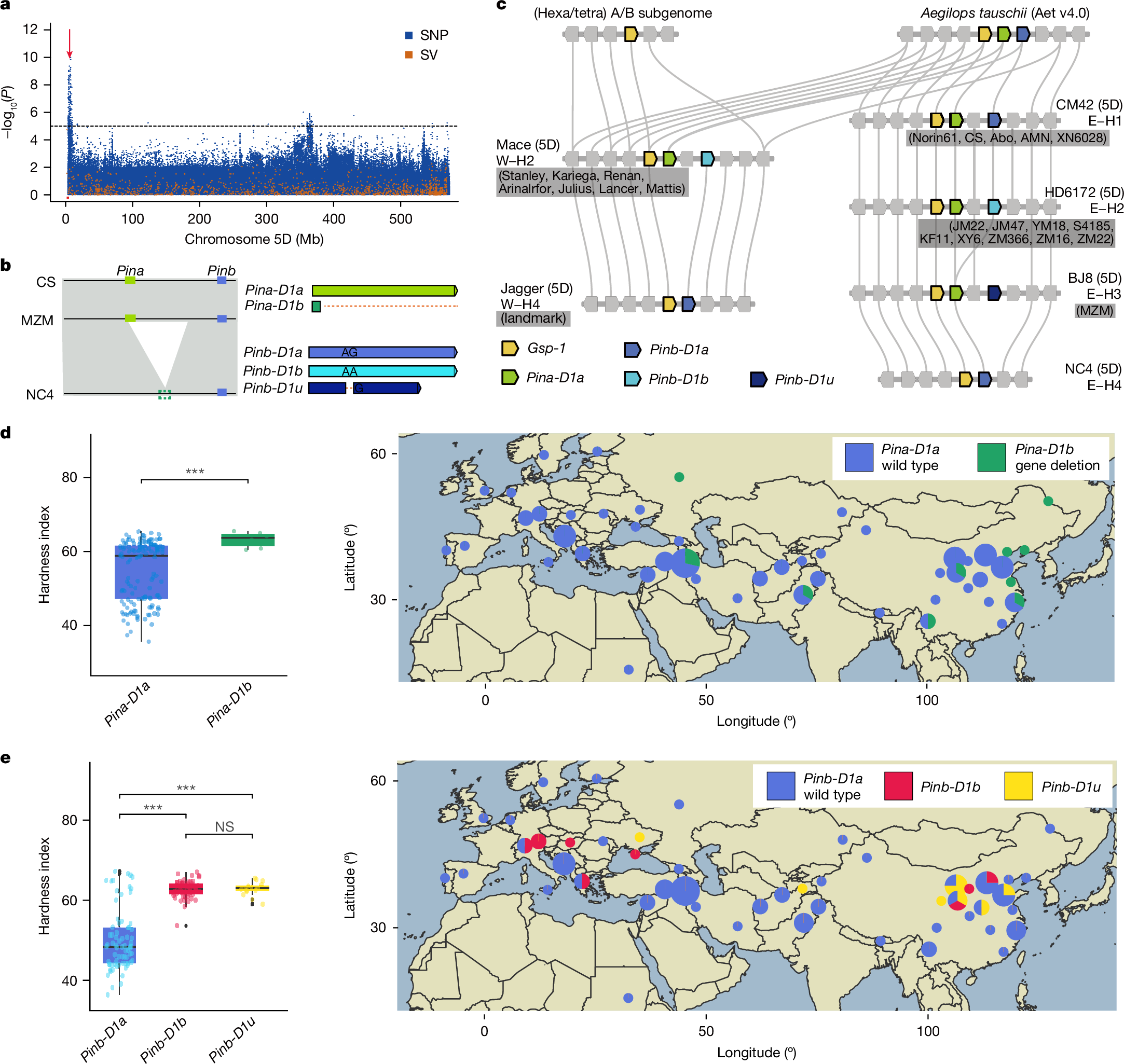
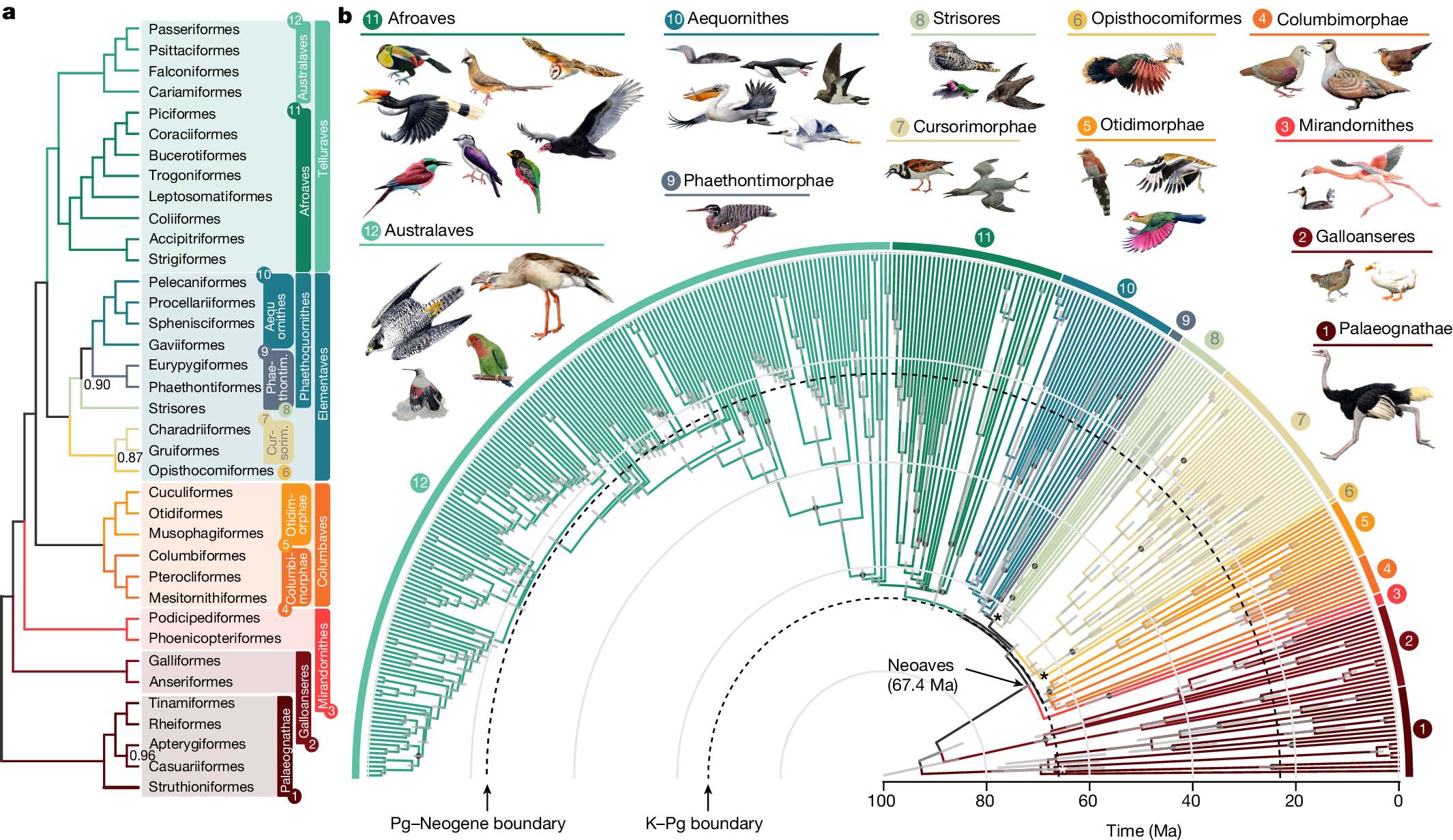
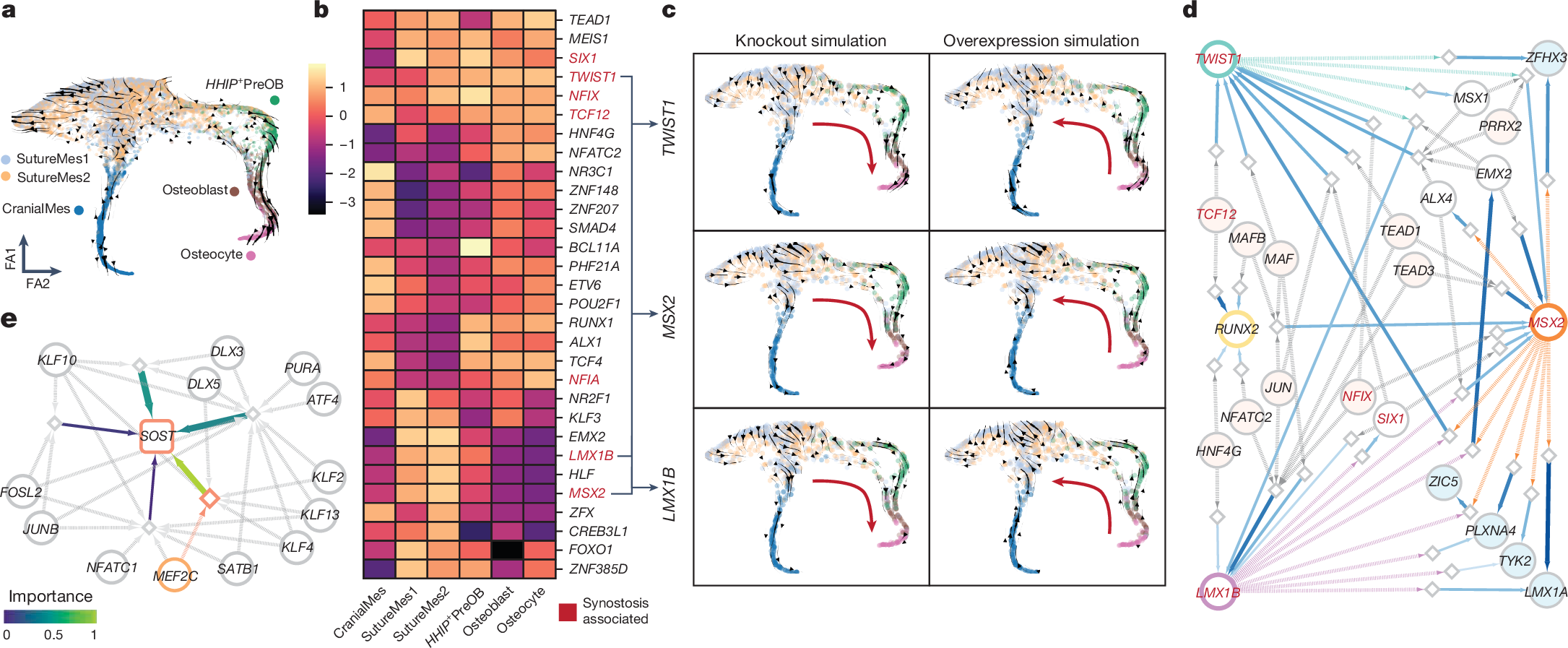
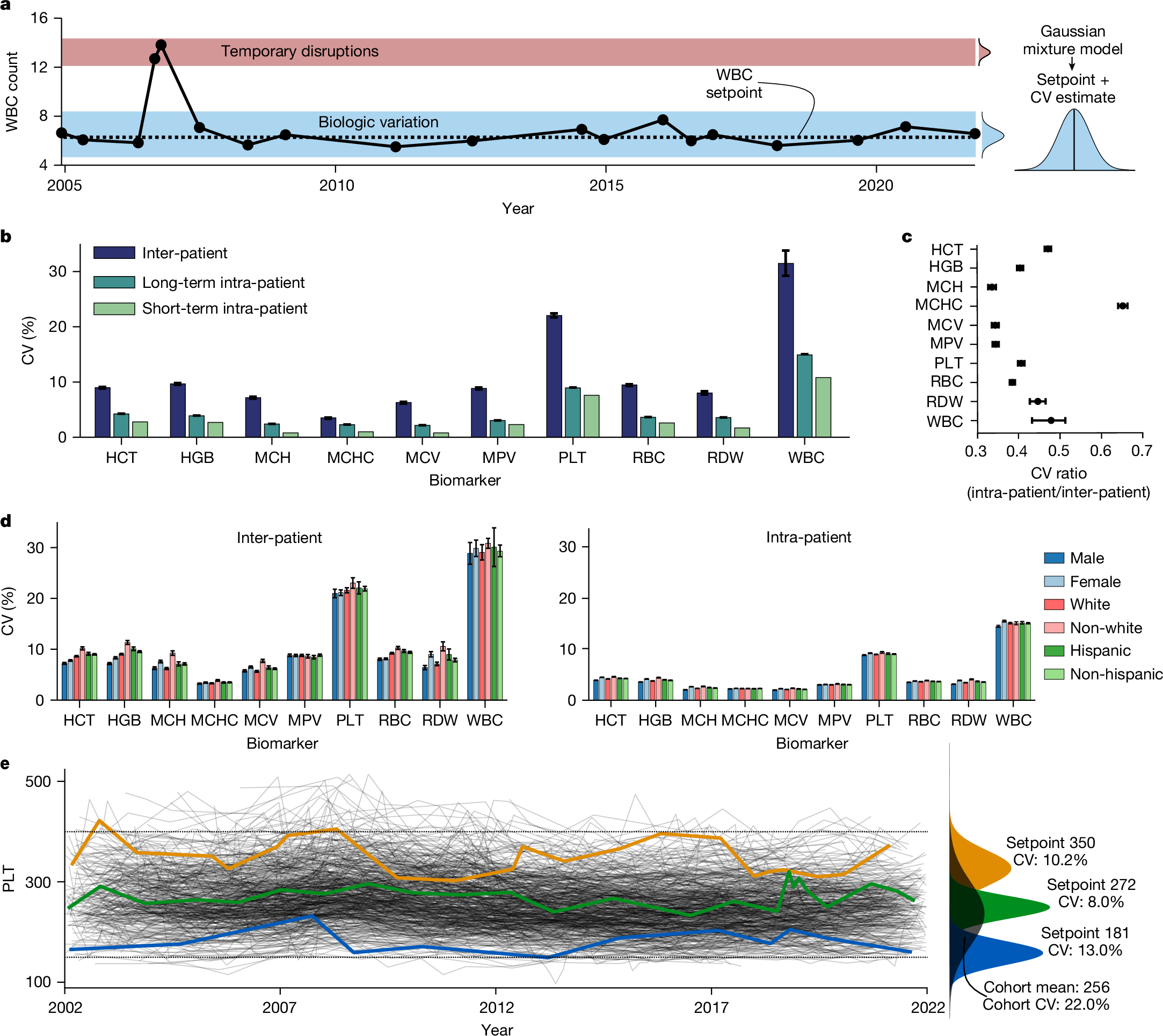
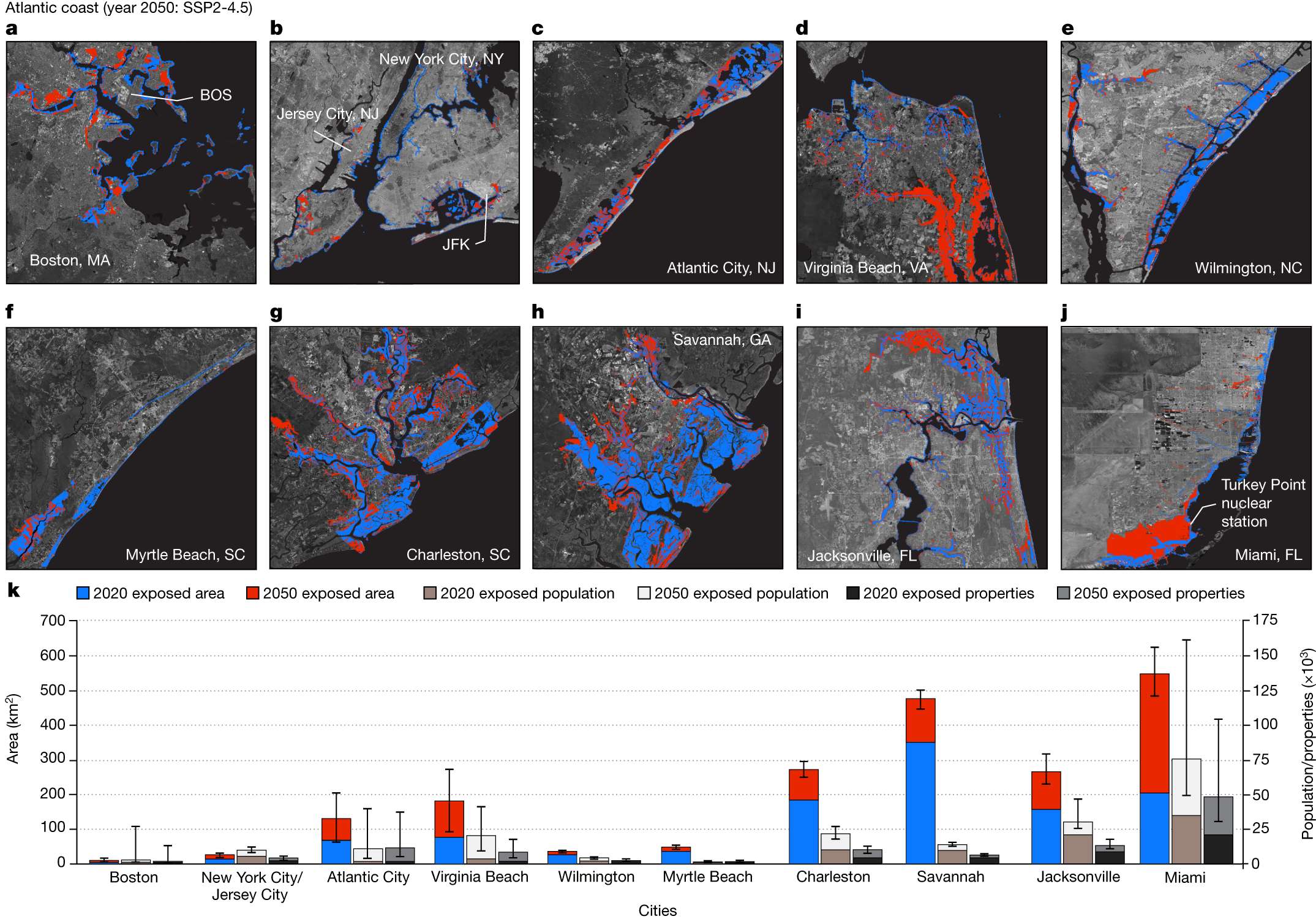
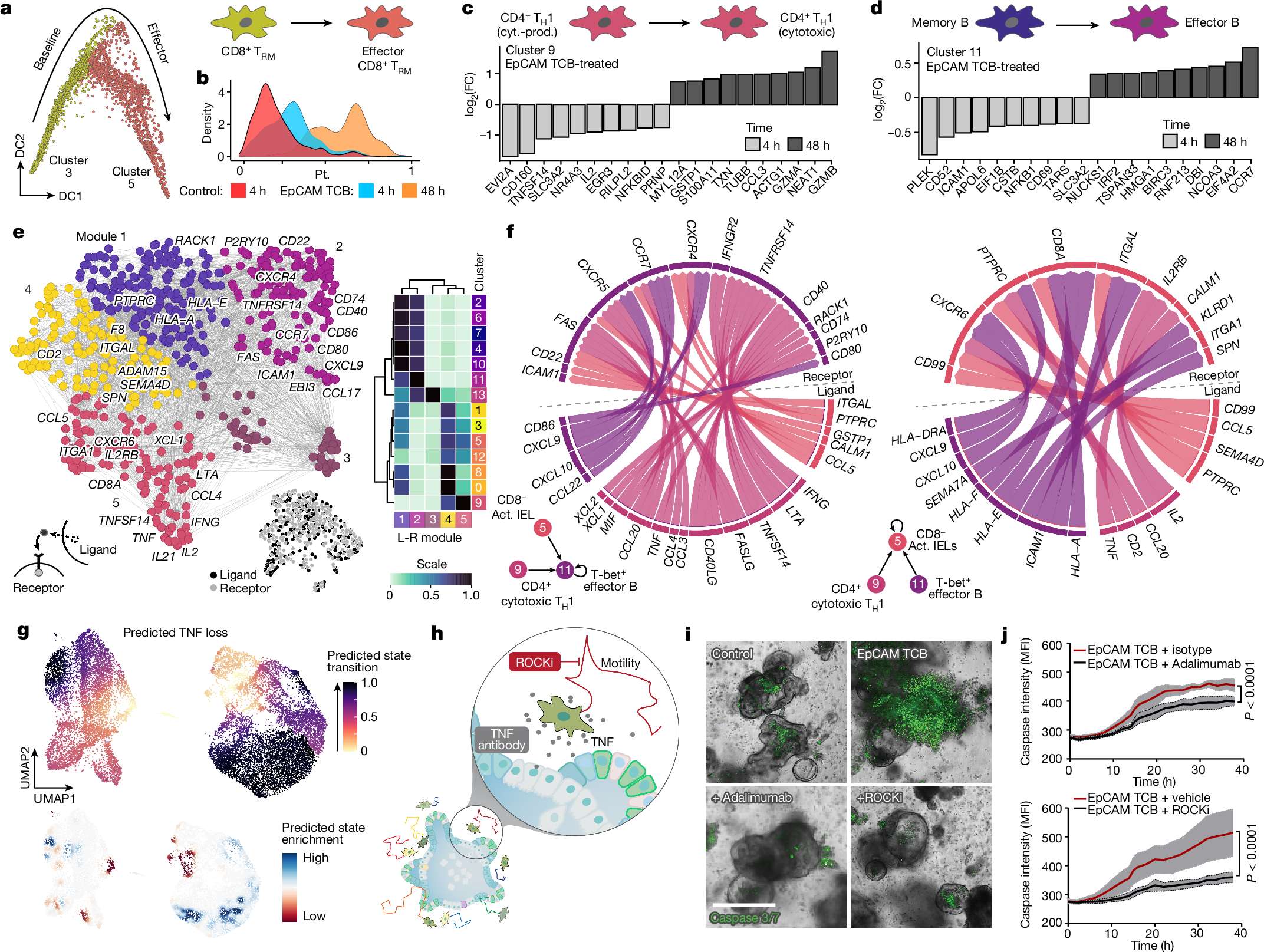
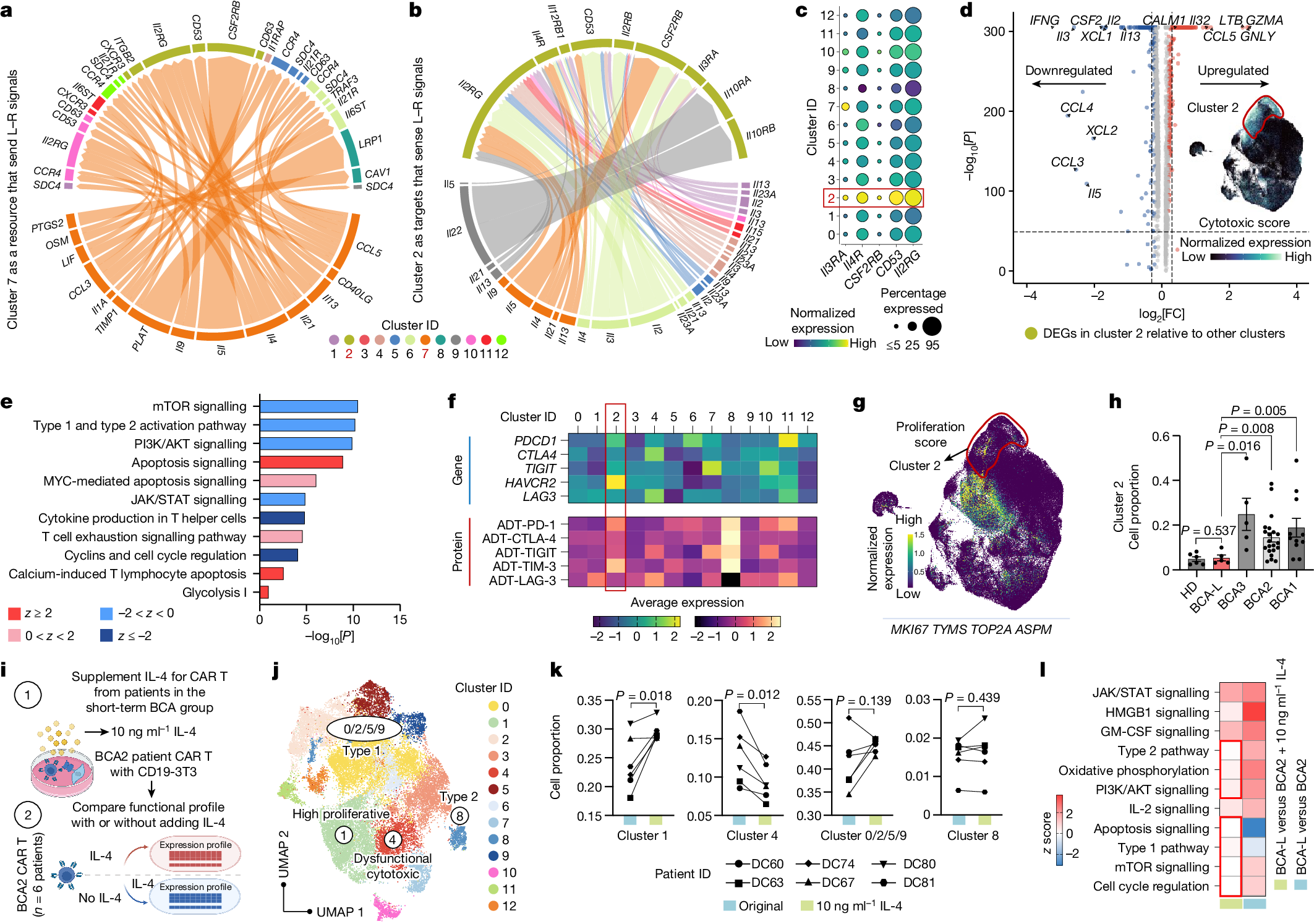

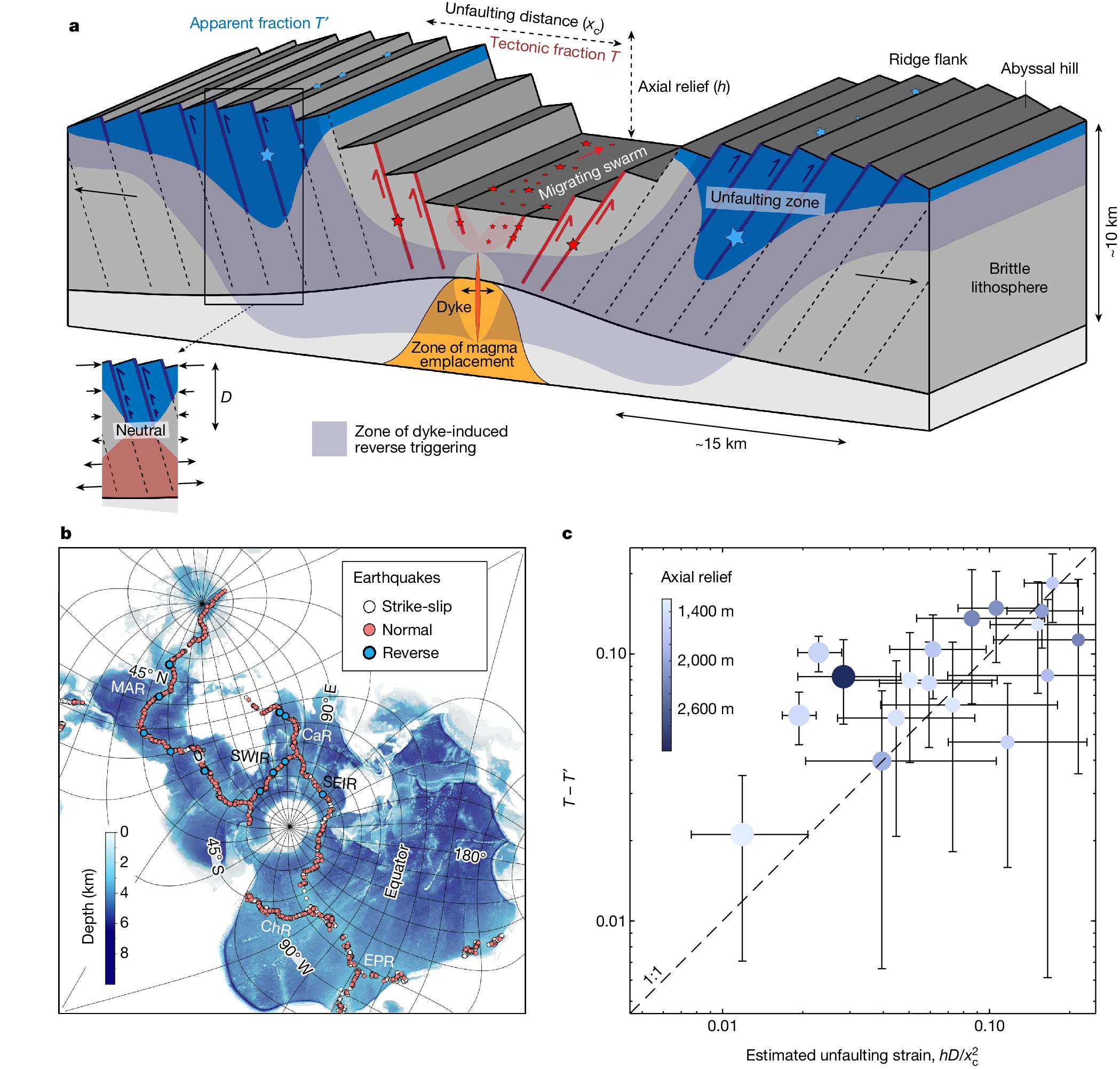
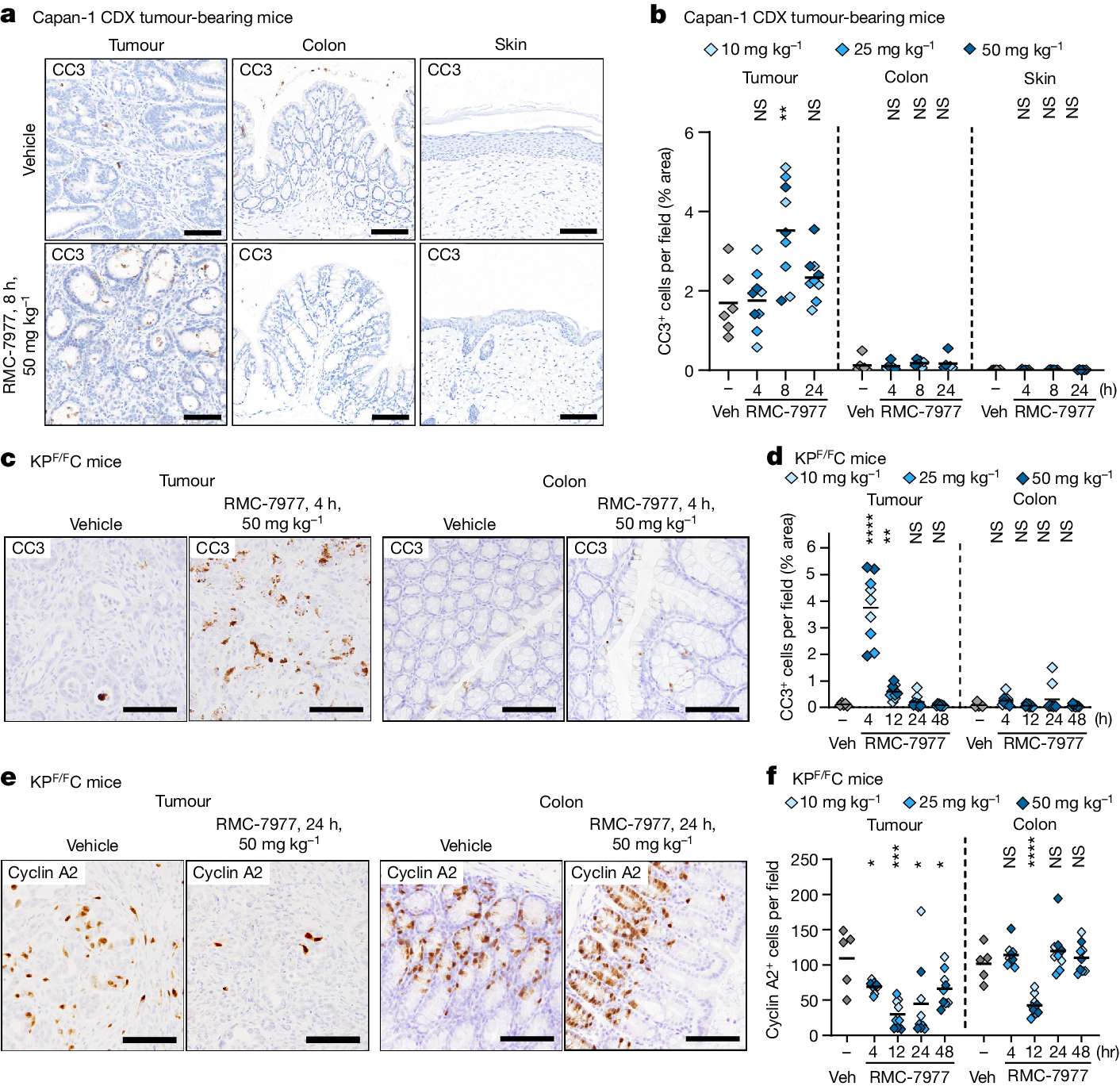

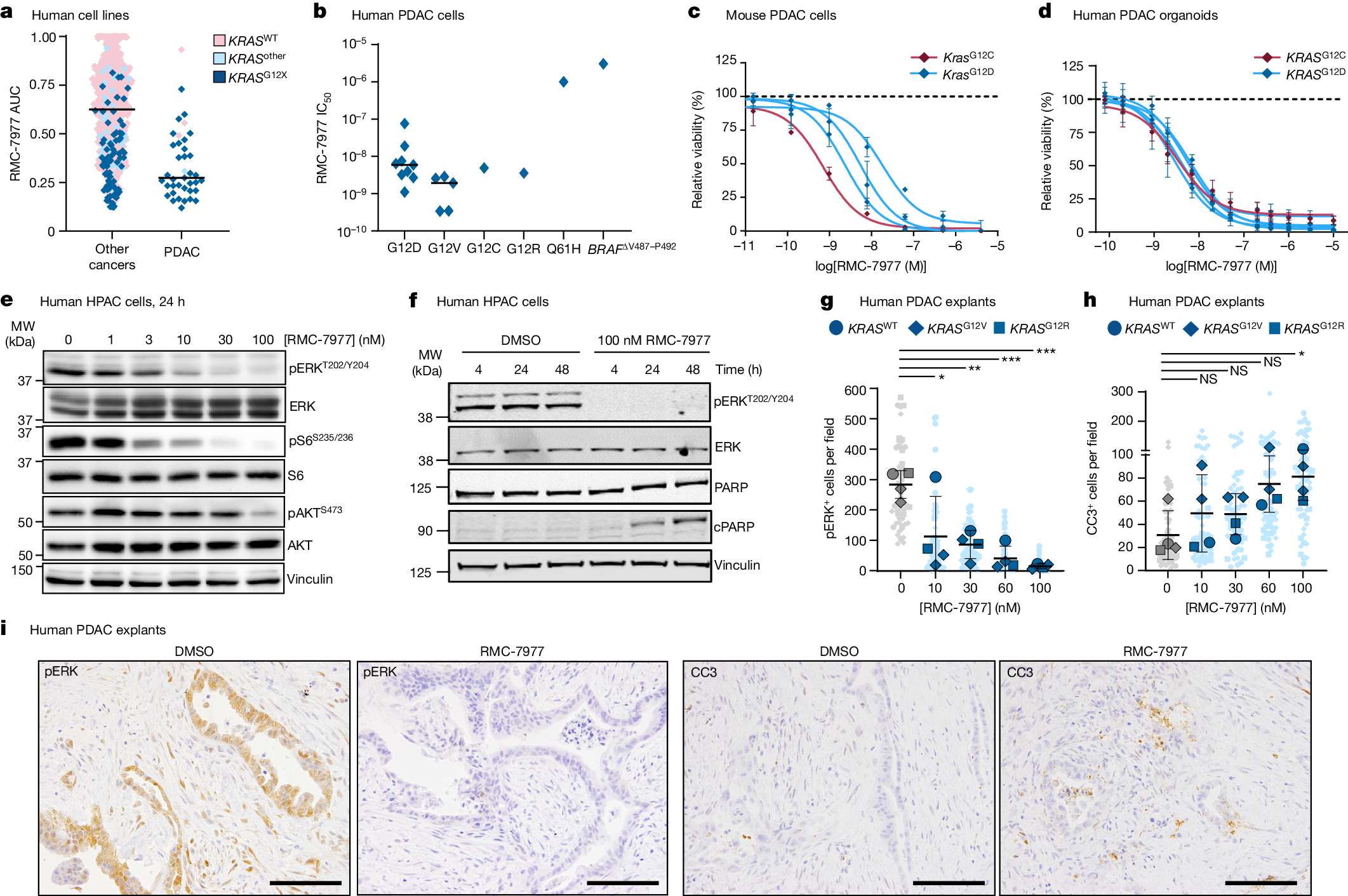
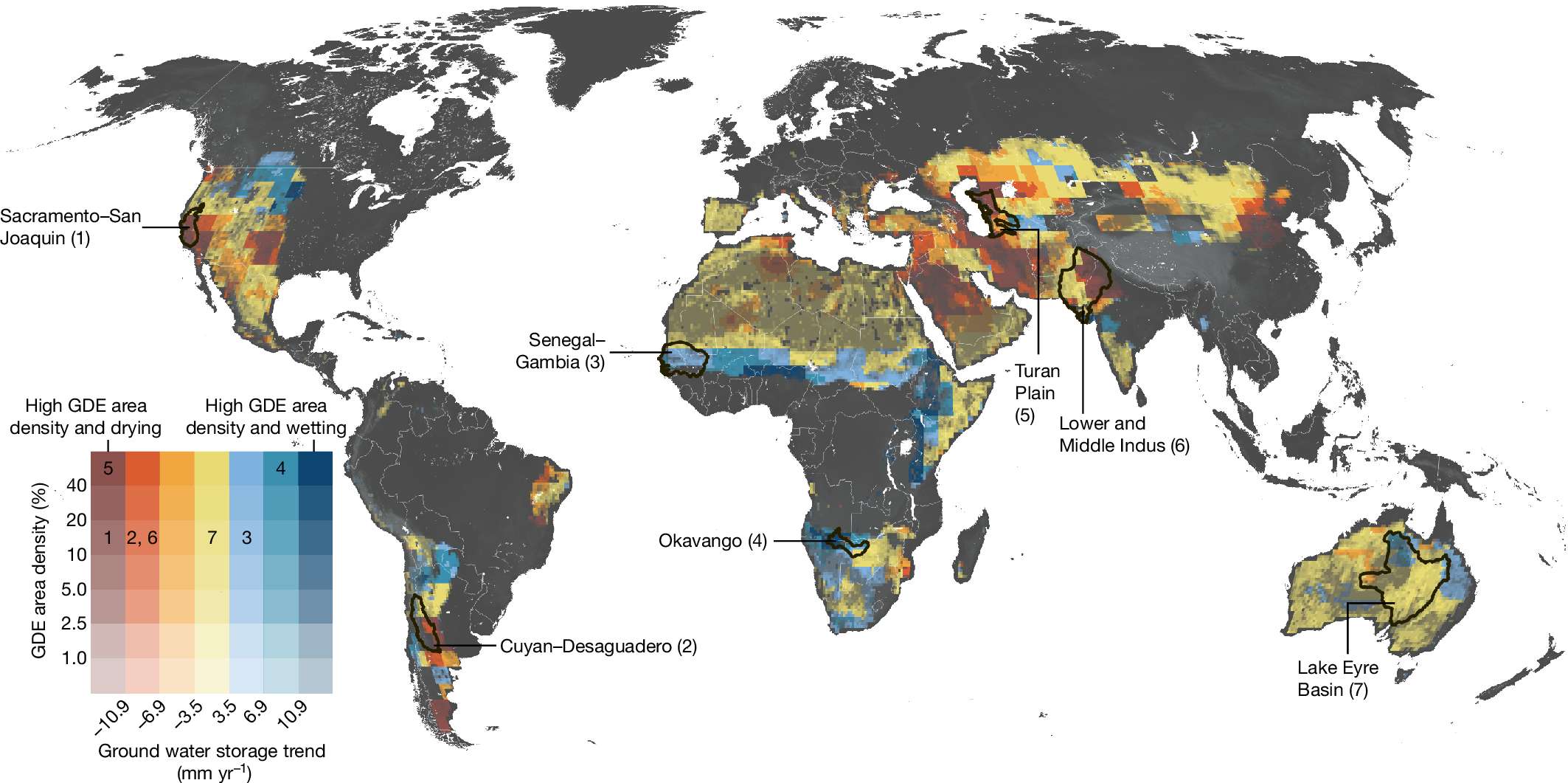
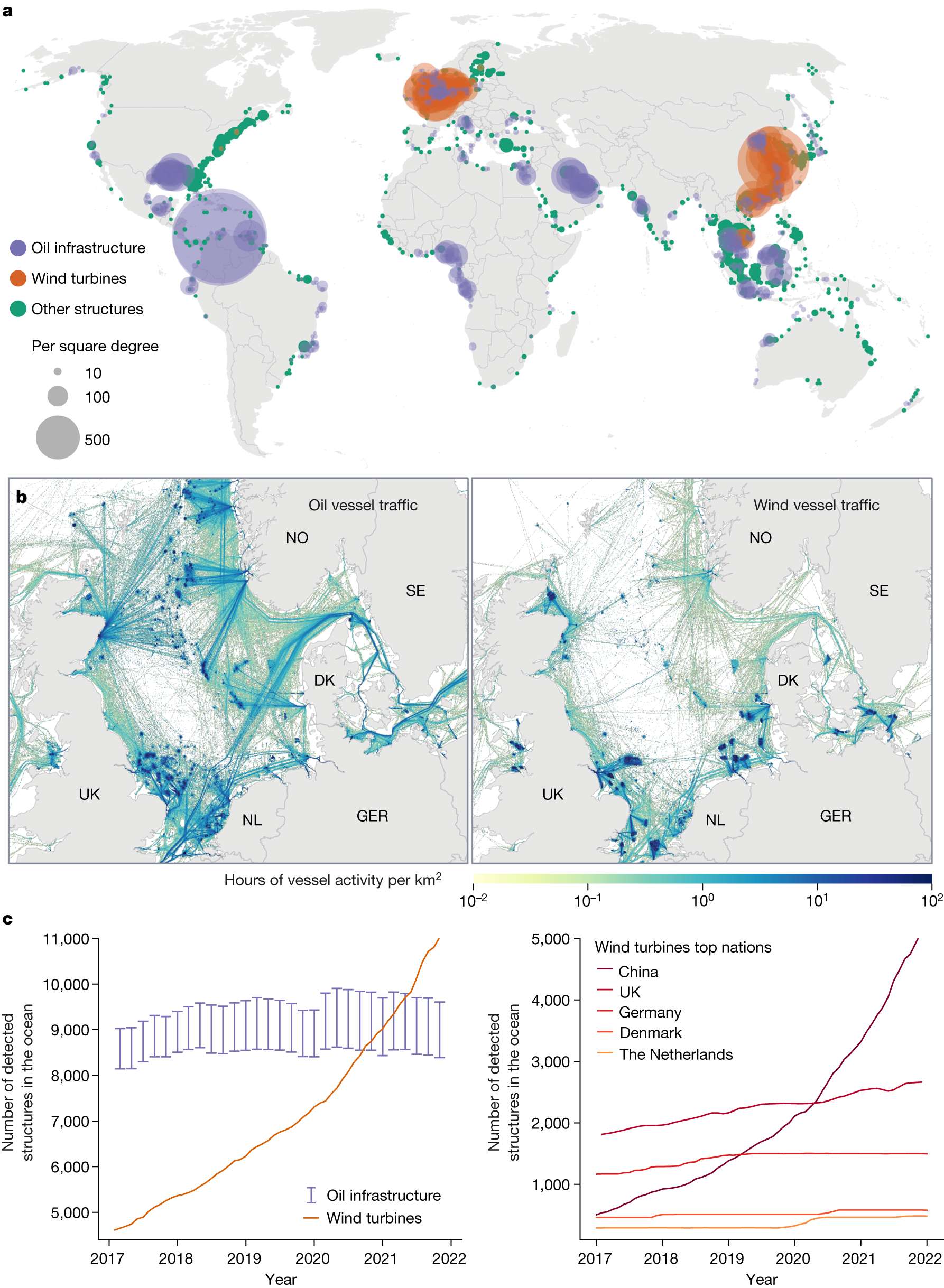
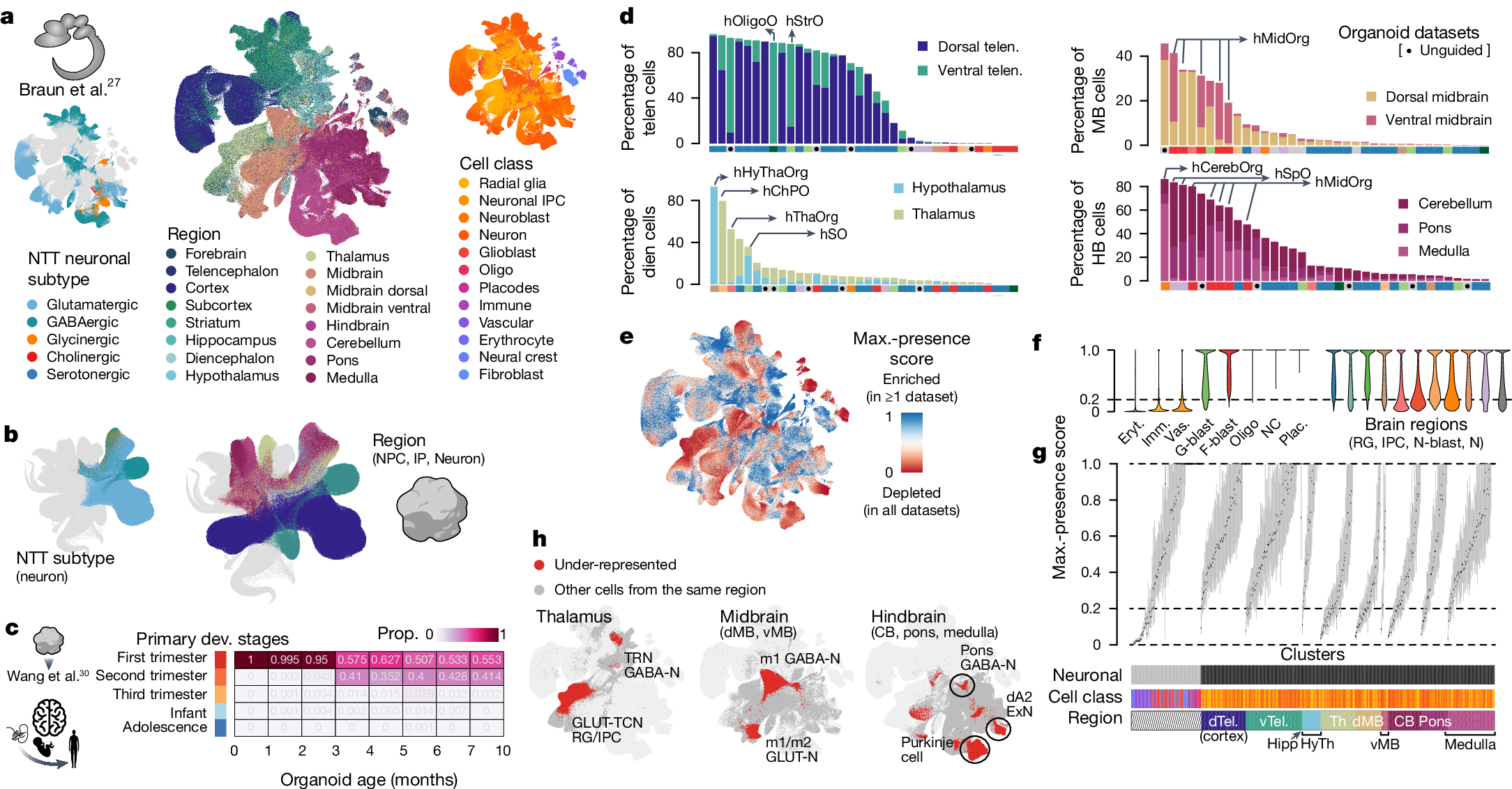
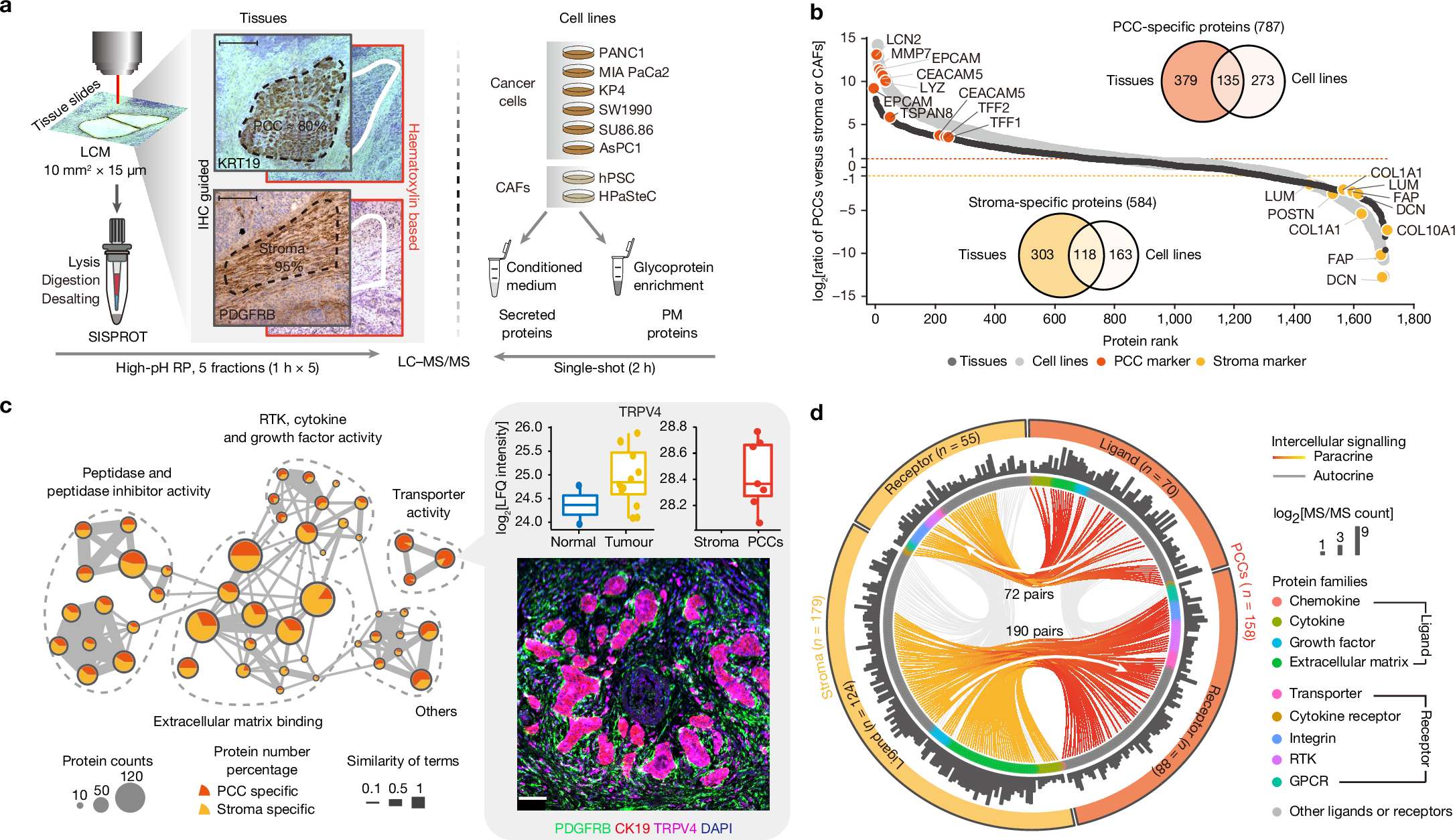
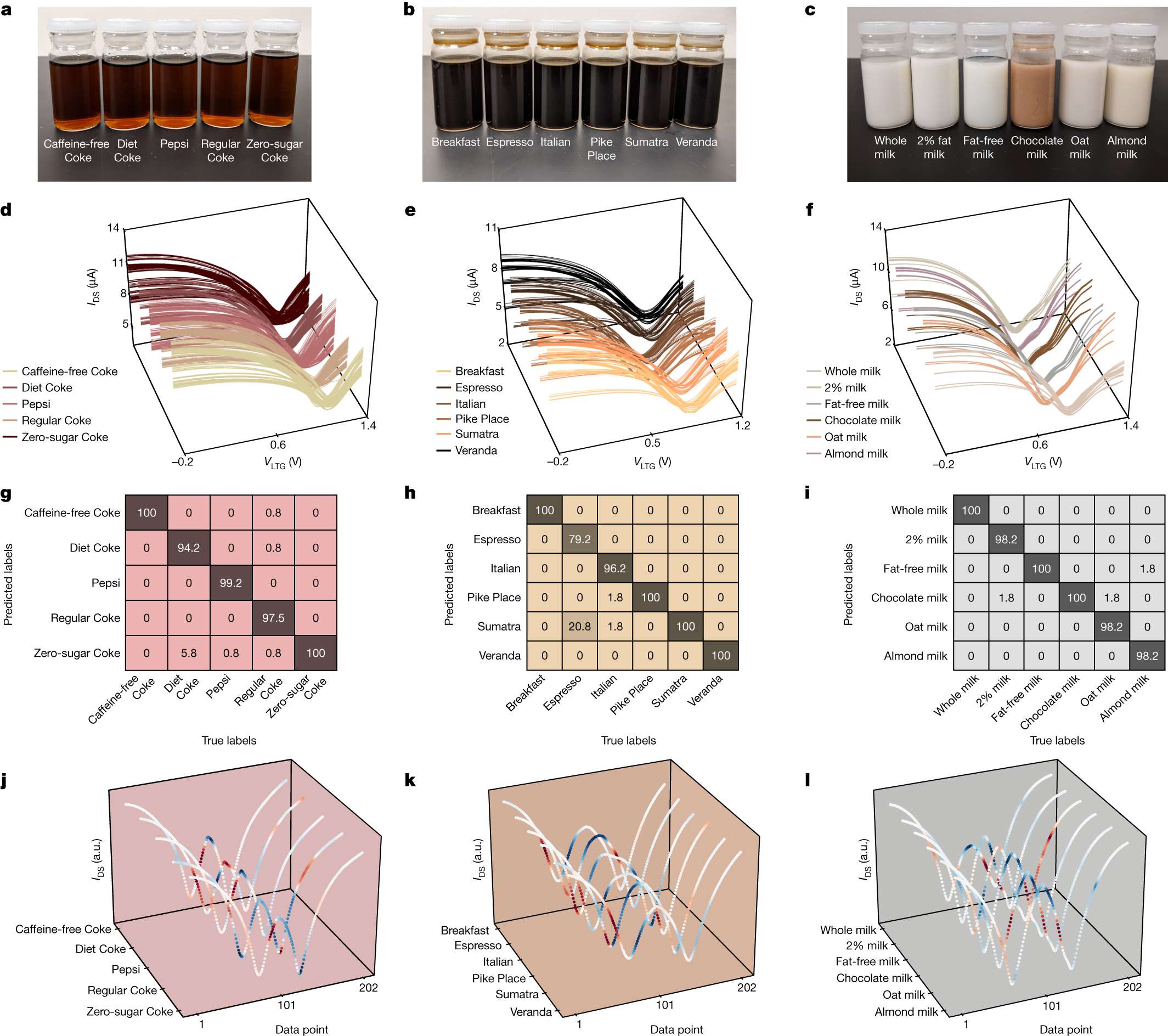
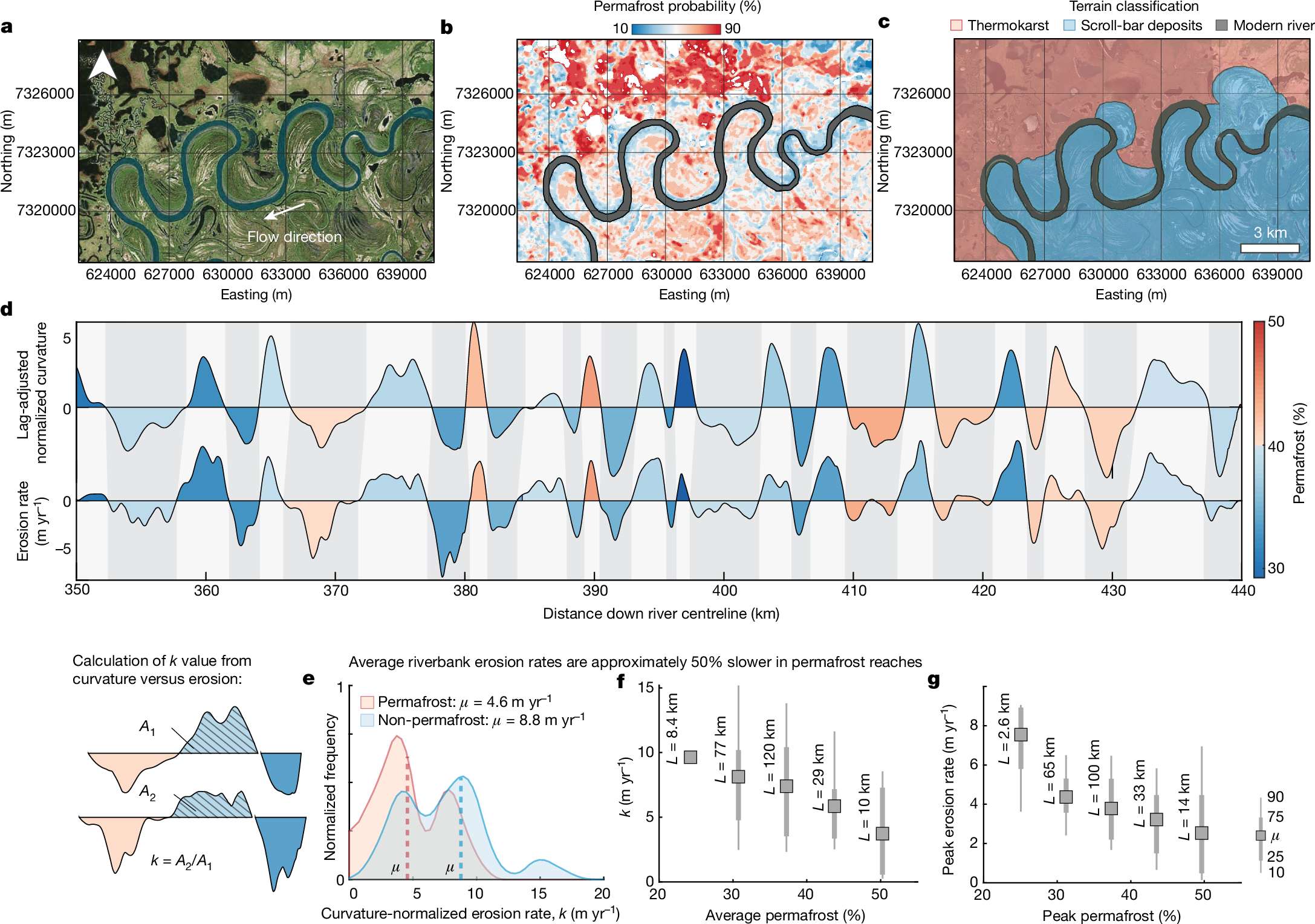
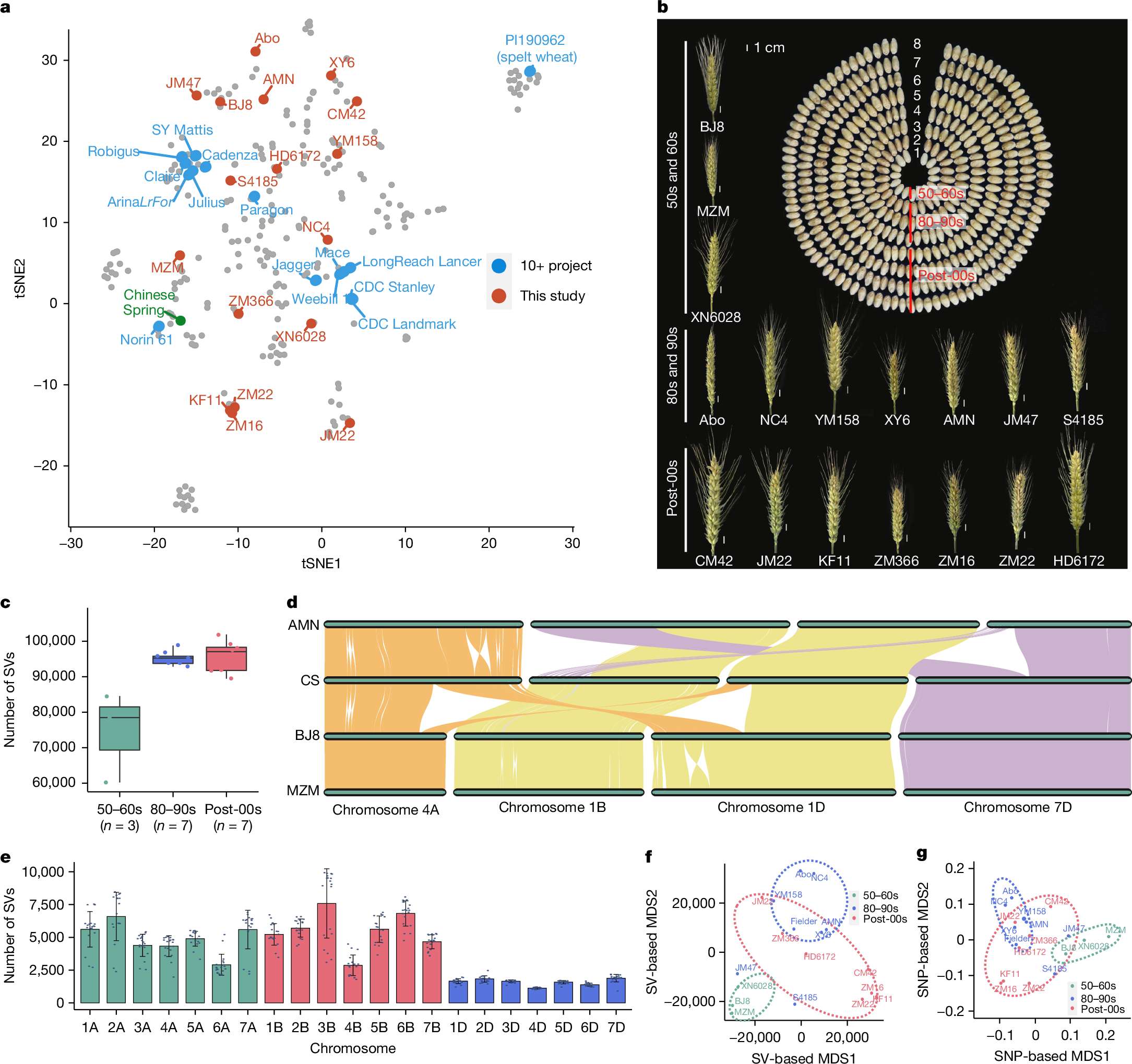
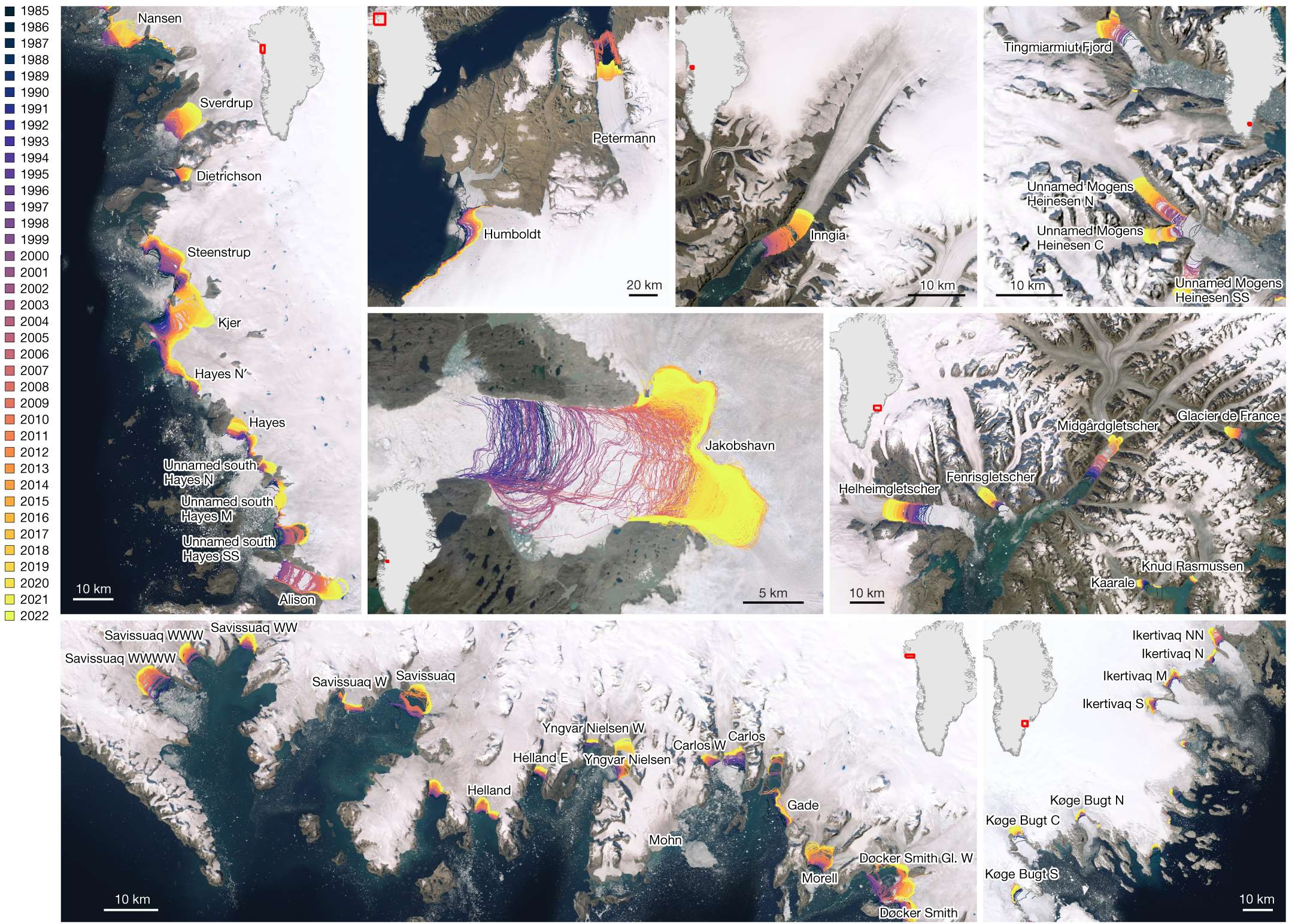
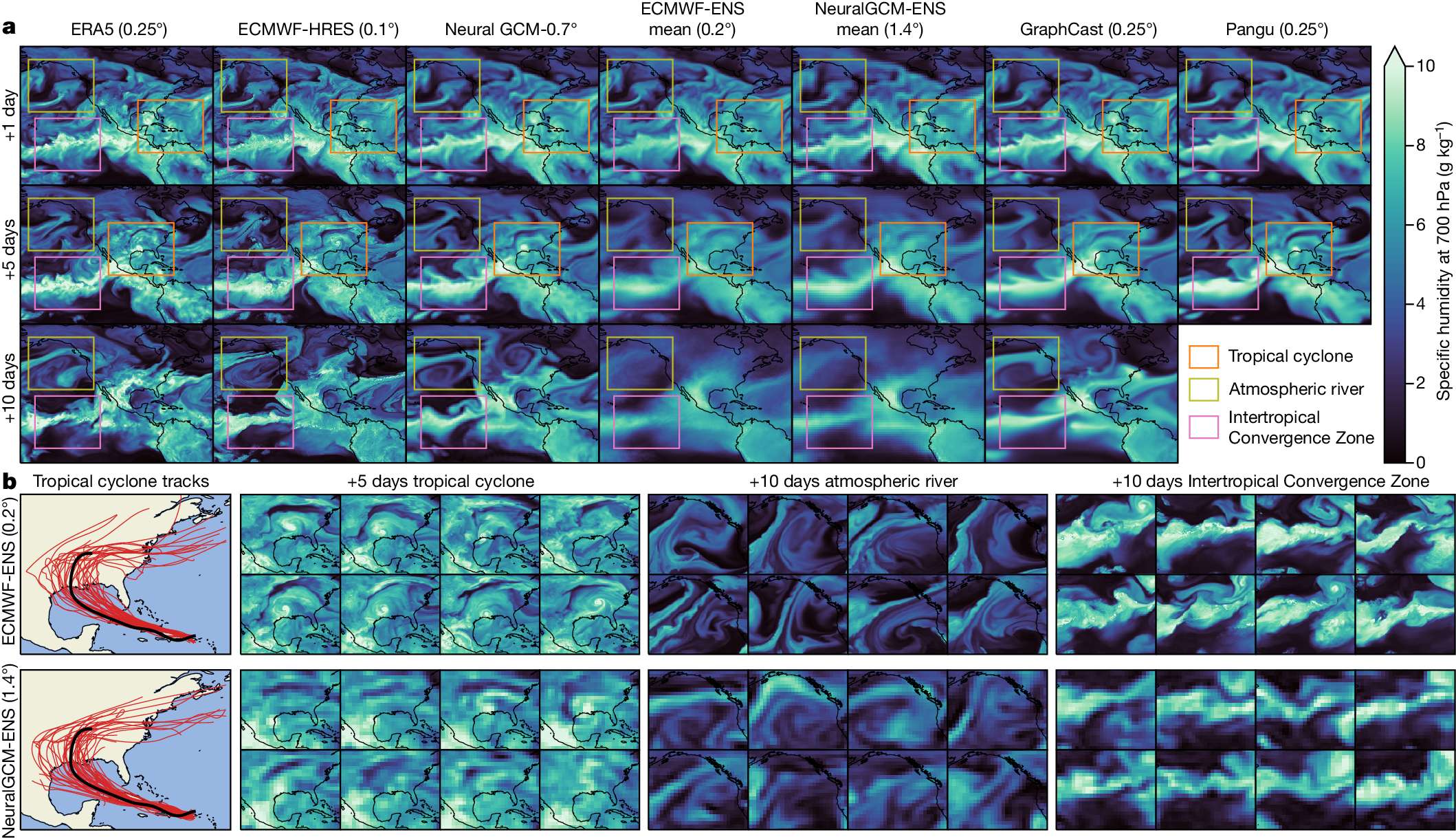
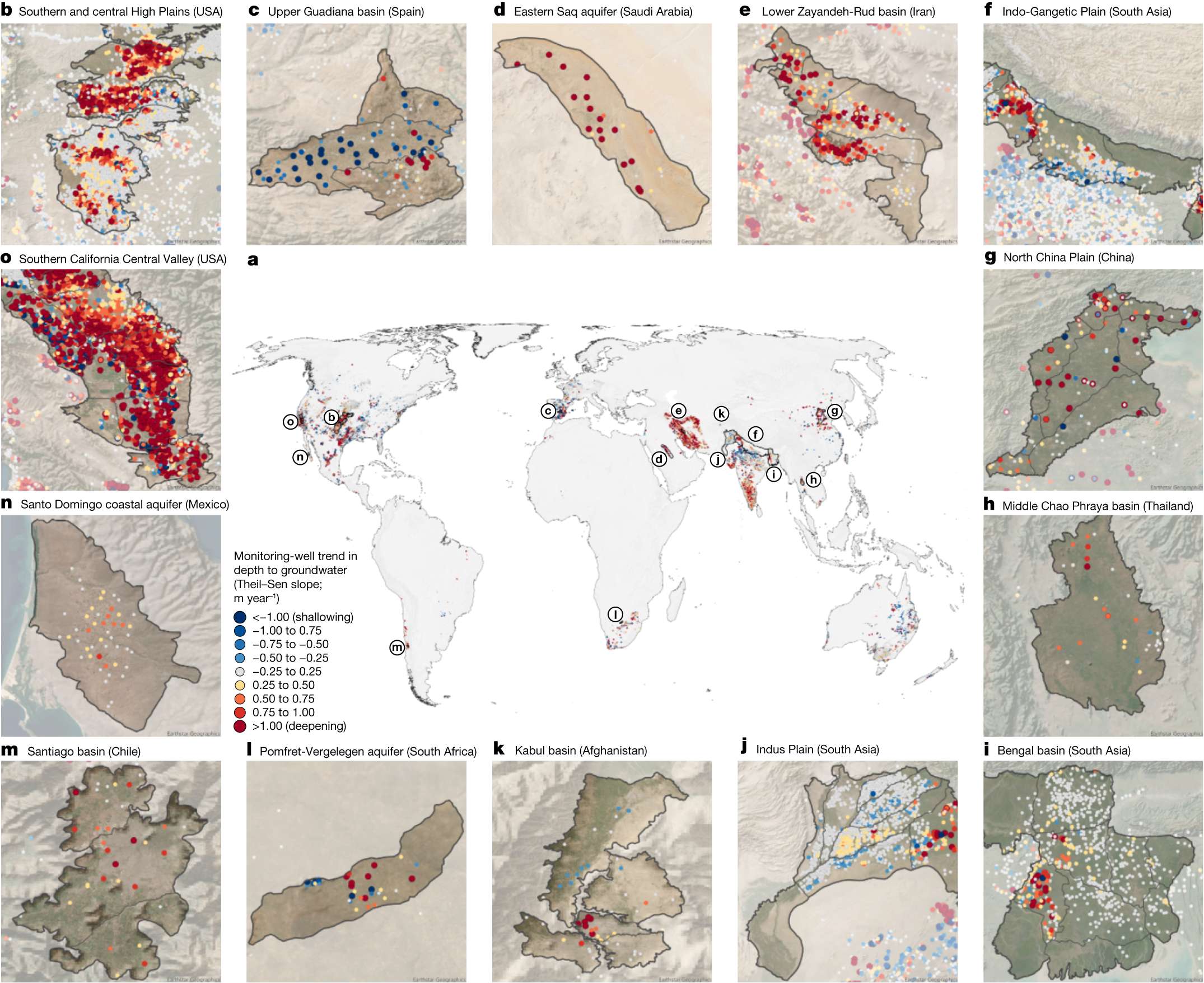

2025