一、前言
Qdrant 是一个高性能的向量搜索引擎,广泛应用于相似性搜索、推荐系统和大规模数据检索等场景。虽然其原生 API 提供了强大的功能,但对于开发者和运维人员来说,缺乏直观的可视化界面常常增加了使用门槛。为了解决这一问题,Qdrant Web UI 应运而生——它提供了一个简洁友好的前端操作界面,帮助用户更高效地管理集合、查看数据、执行查询和监控服务状态。
本文将手把手带你搭建 Qdrant Web UI,从环境准备到部署运行,一步步实现对 Qdrant 服务的可视化管理,让向量数据库的操作变得更加简单直观。
二、术语
2.1、向量数据库
向量数据库是一种专门用于存储和处理高维向量数据的数据库系统。与传统的关系型数据库或文档数据库不同,向量数据库的设计目标是高效地支持向量数据的索引和相似性搜索。
在传统数据库中,数据通常是以结构化的表格形式存储,每个记录都有预定义的字段。但是,对于包含大量高维向量的数据,如图像、音频、文本等,传统的数据库模型往往无法有效地处理。向量数据库通过引入特定的数据结构和索引算法,允许高效地存储和查询向量数据。
向量数据库的核心概念是向量索引。它使用一种称为向量空间模型的方法,将向量映射到多维空间中的点,并利用这种映射关系构建索引结构。这样,当需要搜索相似向量时,可以通过计算向量之间的距离或相似度来快速定位相似的向量。
2.2、向量数据库的使用场景
向量数据库在许多领域中都有广泛的应用场景,特别是涉及到高维向量数据存储和相似性搜索的任务。以下是一些常见的使用场景:
- 目标识别和图像搜索:向量数据库可用于存储图像特征向量,以支持快速的相似图像搜索和目标识别。它在图像搜索引擎、人脸识别和视频监控等领域具有重要作用。
- 推荐系统:向量数据库可以存储用户和物品的特征向量,用于个性化推荐。基于相似性搜索,可以找到与用户兴趣相似的物品,提供个性化的推荐结果。
- 自然语言处理:在文本处理任务中,可以使用向量数据库存储文本向量,如词向量、句向量等。基于相似性搜索,可以进行文本匹配、语义相似度计算等操作。
- 数据聚类和分类:向量数据库可用于高维向量数据的聚类和分类分析。它可以帮助发现数据集中的聚类模式和类别,用于数据挖掘和机器学习任务。
- 检索与推荐系统:在电子商务和商品搜索中,向量数据库可以存储商品特征向量,以支持相似商品的搜索和推荐。它可以提供更准确和个性化的搜索结果。
- 医疗和生物信息学:向量数据库可用于存储基因表达向量、蛋白质特征向量等生物信息学数据。它可以在基因组学、药物研发等领域中帮助进行数据分析和研究。
- 视频内容分析:向量数据库可用于存储视频特征向量,如视频帧特征、视频片段特征等。它可以用于视频内容搜索、视频剪辑和视频推荐等应用。
2.3、Qdrant
Qdrant 是一个高性能、易用、功能丰富的开源向量搜索引擎,适用于需要处理大量向量数据并执行相似性搜索的各种 AI 应用。它结合了现代索引技术、灵活的数据模型以及强大的 API 接口,非常适合构建智能推荐、图像检索、语义搜索等系统。
三、前置条件
3.1、下载Qdrant
https://github.com/qdrant/qdrant/releases/tag/v1.14.1![]() https://github.com/qdrant/qdrant/releases/tag/v1.14.1 此次以Windows系统为例,下载文件:qdrant-x86_64-pc-windows-msvc.zip
https://github.com/qdrant/qdrant/releases/tag/v1.14.1 此次以Windows系统为例,下载文件:qdrant-x86_64-pc-windows-msvc.zip
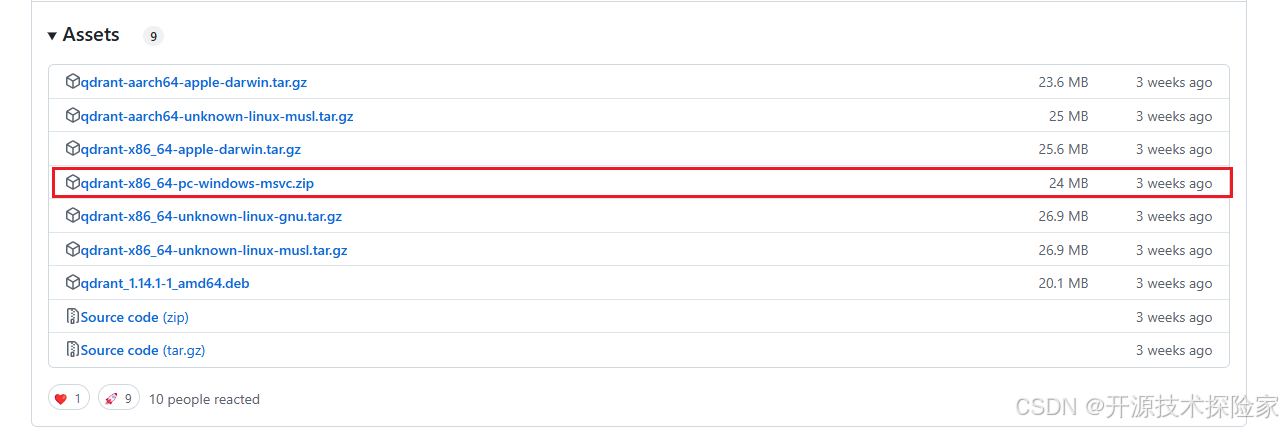
解压qdrant-x86_64-pc-windows-msvc.zip得到一个qdrant.exe文件
3.2、新建config配置文件
在qdrant.exe文件的同级目录创建一个config文件夹,并在config文件夹里面创建一个config.yaml,并写入以下内容
log_level: INFO
# Logging configuration
# Qdrant logs to stdout. You may configure to also write logs to a file on disk.
# Be aware that this file may grow indefinitely.
# logger:
# # Logging format, supports `text` and `json`
# format: text
# on_disk:
# enabled: true
# log_file: path/to/log/file.log
# log_level: INFO
# # Logging format, supports `text` and `json`
# format: text
storage:
# Where to store all the data
storage_path: E:/qdrant/storage
# Where to store snapshots
snapshots_path: E:/qdrant/snapshots
snapshots_config:
# "local" or "s3" - where to store snapshots
snapshots_storage: local
# s3_config:
# bucket: ""
# region: ""
# access_key: ""
# secret_key: ""
# Where to store temporary files
# If null, temporary snapshots are stored in: storage/snapshots_temp/
temp_path: null
# If true - point payloads will not be stored in memory.
# It will be read from the disk every time it is requested.
# This setting saves RAM by (slightly) increasing the response time.
# Note: those payload values that are involved in filtering and are indexed - remain in RAM.
#
# Default: true
on_disk_payload: true
# Maximum number of concurrent updates to shard replicas
# If `null` - maximum concurrency is used.
update_concurrency: null
# Write-ahead-log related configuration
wal:
# Size of a single WAL segment
wal_capacity_mb: 32
# Number of WAL segments to create ahead of actual data requirement
wal_segments_ahead: 0
# Normal node - receives all updates and answers all queries
node_type: "Normal"
# Listener node - receives all updates, but does not answer search/read queries
# Useful for setting up a dedicated backup node
# node_type: "Listener"
performance:
# Number of parallel threads used for search operations. If 0 - auto selection.
max_search_threads: 0
# Max number of threads (jobs) for running optimizations across all collections, each thread runs one job.
# If 0 - have no limit and choose dynamically to saturate CPU.
# Note: each optimization job will also use `max_indexing_threads` threads by itself for index building.
max_optimization_threads: 0
# CPU budget, how many CPUs (threads) to allocate for an optimization job.
# If 0 - auto selection, keep 1 or more CPUs unallocated depending on CPU size
# If negative - subtract this number of CPUs from the available CPUs.
# If positive - use this exact number of CPUs.
optimizer_cpu_budget: 0
# Prevent DDoS of too many concurrent updates in distributed mode.
# One external update usually triggers multiple internal updates, which breaks internal
# timings. For example, the health check timing and consensus timing.
# If null - auto selection.
update_rate_limit: null
# Limit for number of incoming automatic shard transfers per collection on this node, does not affect user-requested transfers.
# The same value should be used on all nodes in a cluster.
# Default is to allow 1 transfer.
# If null - allow unlimited transfers.
#incoming_shard_transfers_limit: 1
# Limit for number of outgoing automatic shard transfers per collection on this node, does not affect user-requested transfers.
# The same value should be used on all nodes in a cluster.
# Default is to allow 1 transfer.
# If null - allow unlimited transfers.
#outgoing_shard_transfers_limit: 1
# Enable async scorer which uses io_uring when rescoring.
# Only supported on Linux, must be enabled in your kernel.
# See: <https://qdrant.tech/articles/io_uring/#and-what-about-qdrant>
#async_scorer: false
optimizers:
# The minimal fraction of deleted vectors in a segment, required to perform segment optimization
deleted_threshold: 0.2
# The minimal number of vectors in a segment, required to perform segment optimization
vacuum_min_vector_number: 1000
# Target amount of segments optimizer will try to keep.
# Real amount of segments may vary depending on multiple parameters:
# - Amount of stored points
# - Current write RPS
#
# It is recommended to select default number of segments as a factor of the number of search threads,
# so that each segment would be handled evenly by one of the threads.
# If `default_segment_number = 0`, will be automatically selected by the number of available CPUs
default_segment_number: 0
# Do not create segments larger this size (in KiloBytes).
# Large segments might require disproportionately long indexation times,
# therefore it makes sense to limit the size of segments.
#
# If indexation speed have more priority for your - make this parameter lower.
# If search speed is more important - make this parameter higher.
# Note: 1Kb = 1 vector of size 256
# If not set, will be automatically selected considering the number of available CPUs.
max_segment_size_kb: null
# Maximum size (in KiloBytes) of vectors to store in-memory per segment.
# Segments larger than this threshold will be stored as read-only memmapped file.
# To enable memmap storage, lower the threshold
# Note: 1Kb = 1 vector of size 256
# To explicitly disable mmap optimization, set to `0`.
# If not set, will be disabled by default.
memmap_threshold_kb: null
# Maximum size (in KiloBytes) of vectors allowed for plain index.
# Default value based on https://github.com/google-research/google-research/blob/master/scann/docs/algorithms.md
# Note: 1Kb = 1 vector of size 256
# To explicitly disable vector indexing, set to `0`.
# If not set, the default value will be used.
indexing_threshold_kb: 20000
# Interval between forced flushes.
flush_interval_sec: 5
# Max number of threads (jobs) for running optimizations per shard.
# Note: each optimization job will also use `max_indexing_threads` threads by itself for index building.
# If null - have no limit and choose dynamically to saturate CPU.
# If 0 - no optimization threads, optimizations will be disabled.
max_optimization_threads: null
# This section has the same options as 'optimizers' above. All values specified here will overwrite the collections
# optimizers configs regardless of the config above and the options specified at collection creation.
#optimizers_overwrite:
# deleted_threshold: 0.2
# vacuum_min_vector_number: 1000
# default_segment_number: 0
# max_segment_size_kb: null
# memmap_threshold_kb: null
# indexing_threshold_kb: 20000
# flush_interval_sec: 5
# max_optimization_threads: null
# Default parameters of HNSW Index. Could be overridden for each collection or named vector individually
hnsw_index:
# Number of edges per node in the index graph. Larger the value - more accurate the search, more space required.
m: 16
# Number of neighbours to consider during the index building. Larger the value - more accurate the search, more time required to build index.
ef_construct: 100
# Minimal size (in KiloBytes) of vectors for additional payload-based indexing.
# If payload chunk is smaller than `full_scan_threshold_kb` additional indexing won't be used -
# in this case full-scan search should be preferred by query planner and additional indexing is not required.
# Note: 1Kb = 1 vector of size 256
full_scan_threshold_kb: 10000
# Number of parallel threads used for background index building.
# If 0 - automatically select.
# Best to keep between 8 and 16 to prevent likelihood of building broken/inefficient HNSW graphs.
# On small CPUs, less threads are used.
max_indexing_threads: 0
# Store HNSW index on disk. If set to false, index will be stored in RAM. Default: false
on_disk: false
# Custom M param for hnsw graph built for payload index. If not set, default M will be used.
payload_m: null
# Default shard transfer method to use if none is defined.
# If null - don't have a shard transfer preference, choose automatically.
# If stream_records, snapshot or wal_delta - prefer this specific method.
# More info: https://qdrant.tech/documentation/guides/distributed_deployment/#shard-transfer-method
shard_transfer_method: null
# Default parameters for collections
collection:
# Number of replicas of each shard that network tries to maintain
replication_factor: 1
# How many replicas should apply the operation for us to consider it successful
write_consistency_factor: 1
# Default parameters for vectors.
vectors:
# Whether vectors should be stored in memory or on disk.
on_disk: null
# shard_number_per_node: 1
# Default quantization configuration.
# More info: https://qdrant.tech/documentation/guides/quantization
quantization: null
# Default strict mode parameters for newly created collections.
strict_mode:
# Whether strict mode is enabled for a collection or not.
enabled: false
# Max allowed `limit` parameter for all APIs that don't have their own max limit.
max_query_limit: null
# Max allowed `timeout` parameter.
max_timeout: null
# Allow usage of unindexed fields in retrieval based (eg. search) filters.
unindexed_filtering_retrieve: null
# Allow usage of unindexed fields in filtered updates (eg. delete by payload).
unindexed_filtering_update: null
# Max HNSW value allowed in search parameters.
search_max_hnsw_ef: null
# Whether exact search is allowed or not.
search_allow_exact: null
# Max oversampling value allowed in search.
search_max_oversampling: null
service:
# Maximum size of POST data in a single request in megabytes
max_request_size_mb: 32
# Number of parallel workers used for serving the api. If 0 - equal to the number of available cores.
# If missing - Same as storage.max_search_threads
max_workers: 0
# Host to bind the service on
host: 0.0.0.0
# HTTP(S) port to bind the service on
http_port: 6333
# gRPC port to bind the service on.
# If `null` - gRPC is disabled. Default: null
# Comment to disable gRPC:
grpc_port: 6334
# Enable CORS headers in REST API.
# If enabled, browsers would be allowed to query REST endpoints regardless of query origin.
# More info: https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS
# Default: true
enable_cors: true
# Enable HTTPS for the REST and gRPC API
enable_tls: false
# Check user HTTPS client certificate against CA file specified in tls config
verify_https_client_certificate: false
# Set an api-key.
# If set, all requests must include a header with the api-key.
# example header: `api-key: <API-KEY>`
#
# If you enable this you should also enable TLS.
# (Either above or via an external service like nginx.)
# Sending an api-key over an unencrypted channel is insecure.
#
# Uncomment to enable.
# api_key: your_secret_api_key_here
# Set an api-key for read-only operations.
# If set, all requests must include a header with the api-key.
# example header: `api-key: <API-KEY>`
#
# If you enable this you should also enable TLS.
# (Either above or via an external service like nginx.)
# Sending an api-key over an unencrypted channel is insecure.
#
# Uncomment to enable.
# read_only_api_key: your_secret_read_only_api_key_here
# Uncomment to enable JWT Role Based Access Control (RBAC).
# If enabled, you can generate JWT tokens with fine-grained rules for access control.
# Use generated token instead of API key.
#
# jwt_rbac: true
# Hardware reporting adds information to the API responses with a
# hint on how many resources were used to execute the request.
#
# Uncomment to enable.
# hardware_reporting: true
cluster:
# Use `enabled: true` to run Qdrant in distributed deployment mode
enabled: false
# Configuration of the inter-cluster communication
p2p:
# Port for internal communication between peers
port: 6335
# Use TLS for communication between peers
enable_tls: false
# Configuration related to distributed consensus algorithm
consensus:
# How frequently peers should ping each other.
# Setting this parameter to lower value will allow consensus
# to detect disconnected nodes earlier, but too frequent
# tick period may create significant network and CPU overhead.
# We encourage you NOT to change this parameter unless you know what you are doing.
tick_period_ms: 100
# Set to true to prevent service from sending usage statistics to the developers.
# Read more: https://qdrant.tech/documentation/guides/telemetry
telemetry_disabled: false
# TLS configuration.
# Required if either service.enable_tls or cluster.p2p.enable_tls is true.
tls:
# Server certificate chain file
cert: ./tls/cert.pem
# Server private key file
key: ./tls/key.pem
# Certificate authority certificate file.
# This certificate will be used to validate the certificates
# presented by other nodes during inter-cluster communication.
#
# If verify_https_client_certificate is true, it will verify
# HTTPS client certificate
#
# Required if cluster.p2p.enable_tls is true.
ca_cert: ./tls/cacert.pem
# TTL in seconds to reload certificate from disk, useful for certificate rotations.
# Only works for HTTPS endpoints. Does not support gRPC (and intra-cluster communication).
# If `null` - TTL is disabled.
cert_ttl: 3600主要修改以下参数:
- storage_path: E:/qdrant/storage
- snapshots_path: E:/qdrant/snapshots
- host: 0.0.0.0
- http_port: 6333
3.3、生成WebUI资源文件
执行以下sh文件,生成static目录
#!/usr/bin/env bash
set -euo pipefail
STATIC_DIR=${STATIC_DIR:-"./static"}
OPENAPI_FILE=${OPENAPI_DIR:-"./docs/redoc/master/openapi.json"}
# Download `dist.zip` from the latest release of https://github.com/qdrant/qdrant-web-ui and unzip given folder
# Get latest dist.zip, assume jq is installed
DOWNLOAD_LINK=$(curl --silent "https://api.github.com/repos/qdrant/qdrant-web-ui/releases/latest" | jq -r '.assets[] | select(.name=="dist-qdrant.zip") | .browser_download_url')
if command -v wget &> /dev/null
then
wget -O dist-qdrant.zip $DOWNLOAD_LINK
else
curl -L -o dist-qdrant.zip $DOWNLOAD_LINK
fi
rm -rf "${STATIC_DIR}/"*
unzip -o dist-qdrant.zip -d "${STATIC_DIR}"
rm dist-qdrant.zip
cp -r "${STATIC_DIR}/dist/"* "${STATIC_DIR}"
rm -rf "${STATIC_DIR}/dist"
cp "${OPENAPI_FILE}" "${STATIC_DIR}/openapi.json"资源文件明细:

注意: 把生成的static文件夹,复制到qdrant.exe文件的同级目录
四、运行Qdrant Web UI
4.1、启动Qdrant
在命令行执行以下命令
qdrant.exe --config-path E:/qdrant/config/config.yaml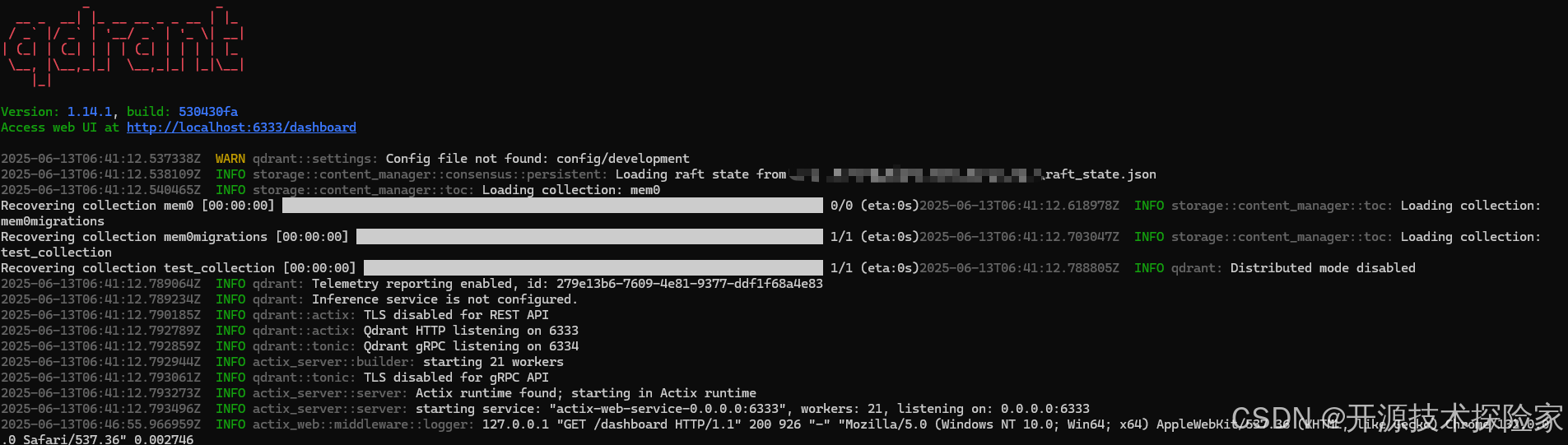
4.2、访问WebUI
http://localhost:6333/dashboard
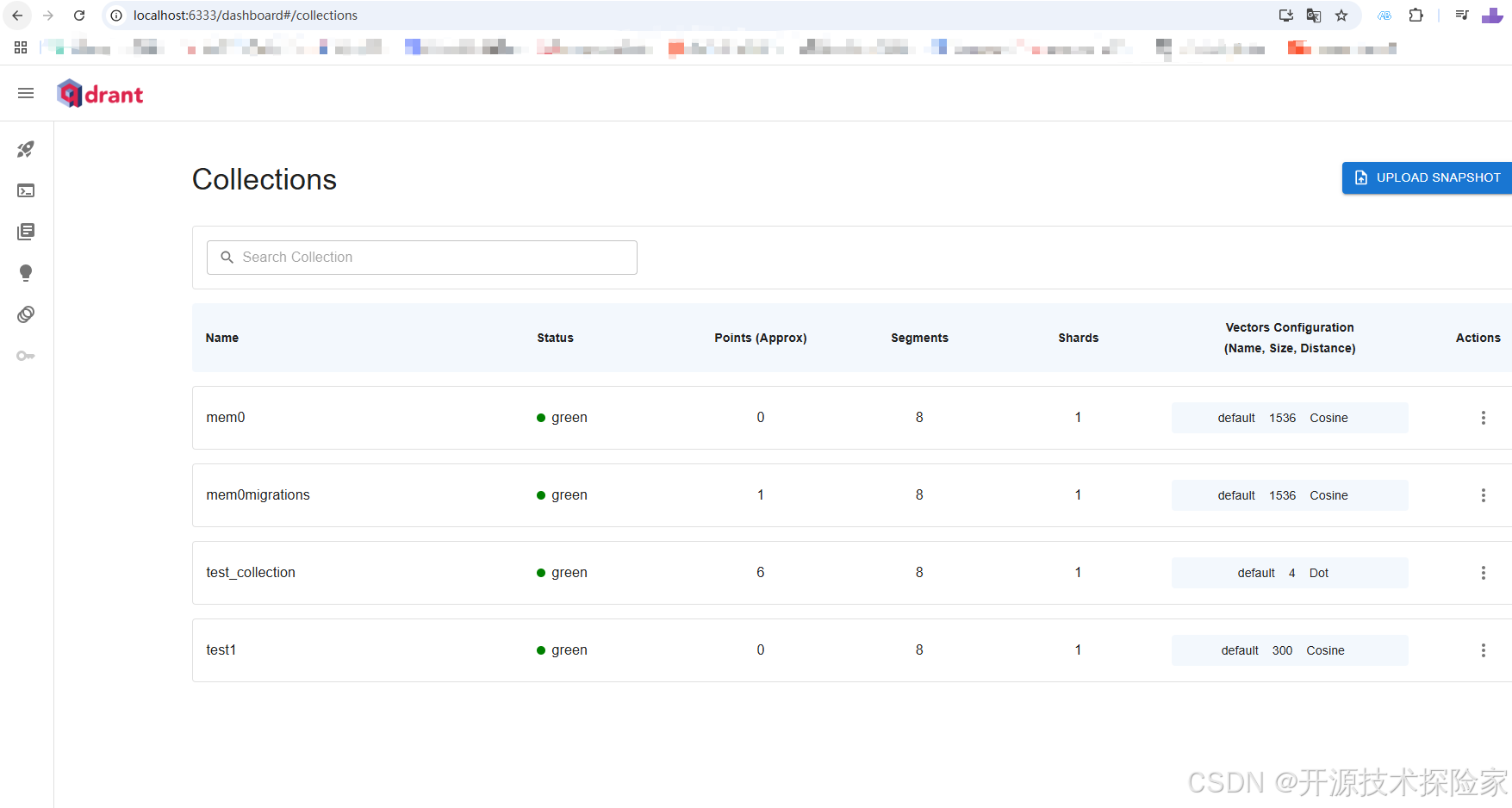
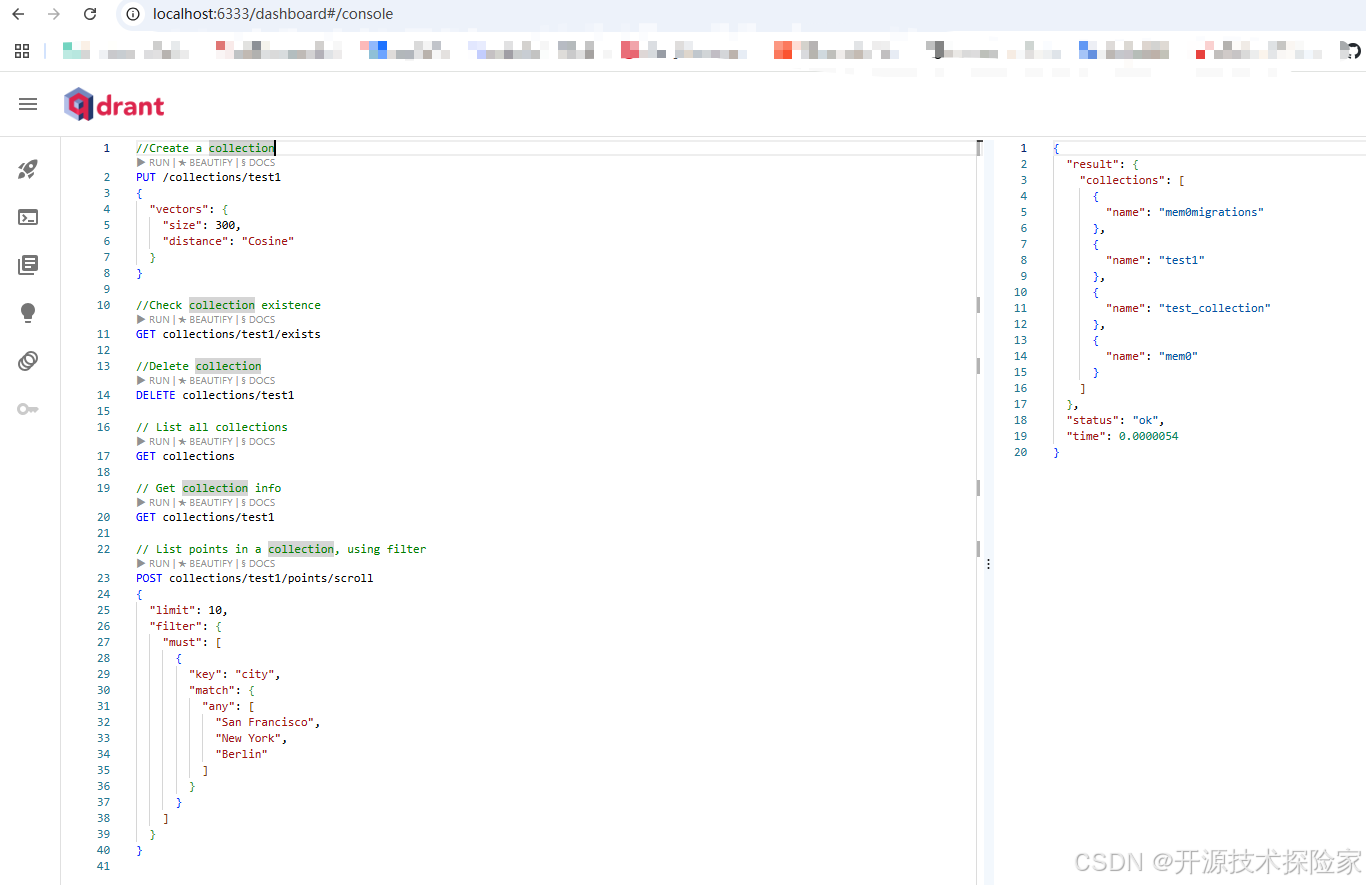
五、附带说明
5.1、直接使用qdrant-web-ui
以上web-ui是集成到qdrant的使用方式,也可以直接使用qdrant-web-ui的方式
https://github.com/qdrant/qdrant-web-ui![]() https://github.com/qdrant/qdrant-web-ui 1. 下载qdrant-web-ui源码
https://github.com/qdrant/qdrant-web-ui 1. 下载qdrant-web-ui源码
2. 安装依赖
npm install
3. 启动开发服务器
npm start
4. 访问qdrant-web-ui(端口为5173)
打开浏览器访问 http://localhost:5173/
5. 修改默认端口为3000
修改vite.config.js文件
import { defineConfig } from 'vite';
import reactRefresh from '@vitejs/plugin-react';
import svgrPlugin from 'vite-plugin-svgr';
import eslintPlugin from 'vite-plugin-eslint';
import {rehypeMetaAsAttributes} from "./src/lib/rehype-meta-as-attributes";
// https://vitejs.dev/config/
export default defineConfig(async () => {
const mdx = await import('@mdx-js/rollup');
return {
base: './',
// This changes the output dir from dist to build
// comment this out if that isn't relevant for your project
build: {
outDir: 'dist',
},
server: {
port: 3000 // 修改为你希望使用的端口号
},
plugins: [
reactRefresh(),
svgrPlugin({
svgrOptions: {
icon: true,
// ...svgr options (https://react-svgr.com/docs/options/)
},
}),
eslintPlugin({
include: ['src/**/*.jsx', 'src/**/*.js', 'src/**/*.ts', 'src/**/*.tsx'],
exclude: [
'node_modules/**',
'dist/**, build/**',
'**/*.mdx',
'**/*.md'],
}),
mdx.default({
rehypePlugins: [
rehypeMetaAsAttributes,
],
}),
],
test: {
globals: true,
environment: 'jsdom',
setupFiles: ['./src/setupTests.js'],
},
}
});