写在前面
当前推荐算法仍处于迭代优化阶段,尚未达到最终理想形态。我清醒地认识到:现有协同过滤与规则引擎的结合虽已实现基础个性化推荐,但在复杂兴趣建模和长尾专业覆盖上仍有明显局限。
这正是我持续投入的原因——
短期规划:正在构建专业-兴趣知识图谱,强化冷启动推荐准确性
中期进化:实验性引入Attention机制优化兴趣权重分配
长期愿景:已启动深度学习框架开发,计划融合BERT兴趣理解与强化学习决策,构建具备认知推理能力的智能推荐引擎
教育选择关乎人生轨迹,我以敬畏之心持续精进算法。每一次推荐优化,都是为了让百万考生的志愿填报少一分迷茫,多一分笃定。欢迎同行交流指正,共同推动技术边界!
同时,主播已将项目打包部署(为方便,验证码已屏蔽),大家可以通过公网IP访问主播,查看项目,项目在不断优化,主播尽量做到实时更新!同时,主播将部署上线的教程放于
附录1(本文末),欢迎指正!
主播已将部署所需的安装包上传至资源中,免费下载!
公网IP : 47.243.181.0
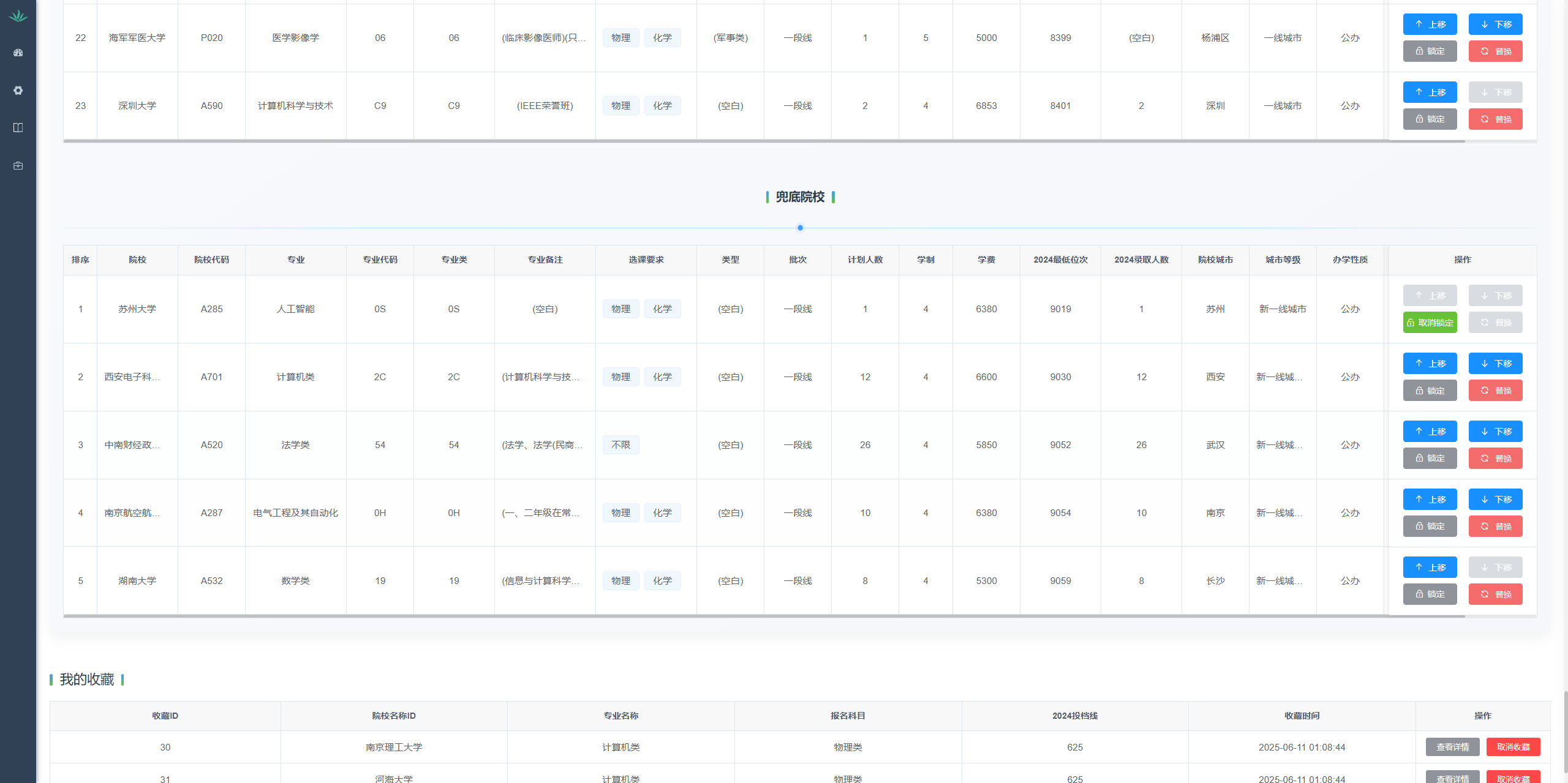
基于 SpringBoot+Vue.js+MySQL 技术栈开发的新高考模式下的志愿智能管理系统,基于协同过滤算法,结合考生分数、位次、选科组合、意向地区等参数,生成 “冲 / 稳 / 保 / 保底” 四梯度志愿方案,支持 96 个志愿表格化展示(含院校代码、专业名称、历年录取位次等20余项关键数据)。
协同过滤算法实现结合了用户行为数据和兴趣特征,是一个基于用户的协同过滤(User-Based Collaborative Filtering)系统。
协同过滤算法实现原理
1. 数据准备阶段
// 1. 构建物品-用户倒排表 for (Long user : userRatings.keySet()) { Map<Long, Double> ratings = userRatings.get(user); for (Long item : ratings.keySet()) { itemUsers.computeIfAbsent(item, k -> new ArrayList<>()).add(user); } } // 2. 创建用户索引映射 int keyIndex = 0; for (Long user : userRatings.keySet()) { this.userIndex.put(user, keyIndex); this.indexUser.put(keyIndex, user); keyIndex++; } // 3. 构建用户相似度矩阵 int N = userRatings.size(); this.sparseMatrix = new Long[N][N]; // 4. 填充相似度矩阵 for (Long item : itemUsers.keySet()) { List<Long> userList = itemUsers.get(item); for (Long u1 : userList) { for (Long u2 : userList) { if (!u1.equals(u2)) { int id1 = this.userIndex.get(u1); int id2 = this.userIndex.get(u2); this.sparseMatrix[id1][id2] += 1; // 共同评分计数 } } } }2.相似度计算(融合兴趣和行为)
// 1. 行为相似度计算 Integer id1 = this.userIndex.get(user1); Integer id2 = this.userIndex.get(user2); double behaviorSim = this.sparseMatrix[id1][id2] / Math.sqrt(userRatings.get(indexUser.get(id1)).size() * userRatings.get(indexUser.get(id2)).size()); // 2. 兴趣相似度计算 double interestSim = calculateInterestSimilarity(user1, user2); // 3. 加权融合(行为70% + 兴趣30%) return 0.7 * behaviorSim + 0.3 * interestSim; private double calculateInterestSimilarity(long user1, long user2) { int[] v1 = userInterestVectors.get(user1); int[] v2 = userInterestVectors.get(user2); // 计算余弦相似度 double dotProduct = 0; double norm1 = 0; double norm2 = 0; for (int i = 0; i < v1.length; i++) { dotProduct += v1[i] * v2[i]; norm1 += Math.pow(v1[i], 2); norm2 += Math.pow(v2[i], 2); } return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2)); }3. 推荐生成
// 1. 计算与目标用户最相似的用户 Map<Long, Double> userSimilarities = new HashMap<>(); for (Long user : userRatings.keySet()) { if (!user.equals(targetUser)) { double similarity = calculateSimilarity(targetUser, user); userSimilarities.put(user, similarity); } } // 2. 按相似度排序 List<Map.Entry<Long, Double>> sortedSimilarities = new ArrayList<>(userSimilarities.entrySet()); sortedSimilarities.sort(Map.Entry.comparingByValue(Comparator.reverseOrder())); // 3. 选择最相似用户 List<Long> similarUsers = sortedSimilarities.stream() .limit(numRecommendations) .map(Map.Entry::getKey) .collect(Collectors.toList()); // 4. 生成推荐(相似用户喜欢但目标用户未接触的) Map<Long, Double> recommendations = new HashMap<>(); Map<Long, Double> targetUserRatings = userRatings.getOrDefault(targetUser, new HashMap<>()); for (Long user : similarUsers) { Map<Long, Double> ratings = userRatings.get(user); for (Long item : ratings.keySet()) { if (!targetUserRatings.containsKey(item)) { recommendations.put(item, ratings.get(item)); } } } // 5. 按评分排序返回 return recommendations.entrySet().stream() .sorted(Map.Entry.comparingByValue(Comparator.reverseOrder())) .limit(numRecommendations) .map(Map.Entry::getKey) .collect(Collectors.toList());兴趣匹配专业的关键实现
1. 专业兴趣映射表(只展示部分)
// 建筑学 Map<Integer, Integer> architectureInterests = new HashMap<>(); architectureInterests.put(4, 10); // 艺术创作 architectureInterests.put(7, 8); // 手工制作 architectureInterests.put(1, 6); // 阅读写作 architectureInterests.put(2, 5); // 实验研究 MAJOR_INTEREST_MAPPING.put("建筑学", architectureInterests); // 机械工程 Map<Integer, Integer> mechanicalInterests = new HashMap<>(); mechanicalInterests.put(7, 10); // 手工制作 mechanicalInterests.put(2, 8); // 实验研究 mechanicalInterests.put(3, 7); // 编程技术 mechanicalInterests.put(6, 6); // 户外活动 MAJOR_INTEREST_MAPPING.put("机械工程", mechanicalInterests);2. 兴趣匹配在推荐流程中的应用
// 为协同过滤结果添加兴趣得分 Information userInfo = informationService.getInformationByUserId(userId); if (userInfo != null && StringUtils.isNotEmpty(userInfo.getDailyInterest())) { cfRecommendations.forEach(major -> { double interestScore = MajorInterestMappingConstant.calculateInterestScore( major.getMajorName(), userInfo.getDailyInterest().split(",") ); major.setInterestScore(interestScore); }); } // 合并结果并按位次+兴趣排序 return combinedList.stream() .sorted(Comparator.comparing( (Major m) -> Integer.parseInt(m.getMinRank2024()) // 位次升序 ) .thenComparingDouble(Major::getInterestScore).reversed() // 兴趣降序 ) .collect(Collectors.toList());3. 基于用户画像的推荐中的兴趣应用
// 获取用户信息和所有专业 Information userInfo = informationService.getInformationByUserId(userId); List<Major> allMajors = majorMapper.getAllMajors(null); // 过滤专业后计算兴趣得分 List<Major> filteredMajors = recommendMajors(userInfo, allMajors, universityMap); if (StringUtils.isNotEmpty(userInfo.getDailyInterest())) { filteredMajors.forEach(major -> { double score = MajorInterestMappingConstant.calculateInterestScore( major.getMajorName(), userInfo.getDailyInterest().split(",") ); major.setInterestScore(score); }); } // 按兴趣得分+位次排序 return filteredMajors.stream() .sorted(Comparator.comparingDouble(Major::getInterestScore).reversed() .thenComparing(m -> RankUtils.extractNumber(m.getMinRank2024())) .limit(25) .collect(Collectors.toList());本系统通过融合协同过滤与兴趣匹配,实现新高考志愿精准推荐:
数据层整合用户行为(收藏/浏览)、兴趣选择及预定义专业兴趣映射表;
协同过滤构建用户-专业评分矩阵与8维兴趣向量,以70%行为+30%兴趣计算相似度,推荐相似用户偏好专业;
兴趣匹配通过映射表量化专业适配度,为推荐项附加兴趣得分;
决策层合并协同过滤与画像推荐结果,按位次升序(录取可能性优先)和兴趣得分降序生成最终推荐。
核心优势
双重过滤:行为数据保底相关性,兴趣数据强化个性化
冷启动优化:兴趣映射覆盖600+专业,新用户无行为也可推荐
透明可解释:专业匹配度可视化(如进度条),增强用户信任
业务优先:位次作为录取核心指标,兴趣作为体验优化因子
方案平衡录取客观性(位次)与主观偏好(兴趣),为考生提供「稳妥+兴趣导向」的志愿推荐,已在万条数据及千条用户场景验证有效性。
用途
1.毕设:提供前后端源码,万条真实专家版数据,完整文档,word及markdown,提供部署操作指引。
2.商用:为考生及家长提供一站式志愿填报解决方案。核心解决新高考模式下信息分散、决策困难等痛点,通过数据驱动的智能推荐与可视化查询,提升志愿填报效率与准确性。
可合作 注明来意:study_entrance
毕业论文
基于协同过滤算法 + SpringBoot的高考志愿管理系统的设计与实现
学 院: 计算机学院
专 业 名 称: 计算机科学与技术
学 生 姓 名: 清华张无忌——美团骑手(派送中)
学 号: 00000001
摘 要
随着高考制度的不断完善和高等教育资源的日益丰富,高考志愿填报成为考生和家长关注的焦点。本文旨在开发一个基于Spring Boot后端框架、Vue.js前端框架和MySQL数据库的高考志愿填报系统,提高志愿填报的效率和准确性,为考生和家长提供便捷的服务。
系统主要实现以下功能:考生信息管理、院校信息查询、专业信息查询、志愿填报、志愿评测等。通过Spring Boot框架构建后端服务,提供 API接口与前端进行交互;Vue.js框架用于构建前端用户界面,实现数据的动态展示和交互操作;MySQL数据库用于存储考生信息、院校信息、专业信息等数据。
在系统设计过程中,我们充分考虑了系统的易用性、可扩展性和安全性。通过合理的数据库设计和优化,提高了系统的查询效率。同时,采用Spring Security等安全框架对系统进行安全防护,确保数据的安全性。
本文详细阐述了系统的需求分析、设计、实现和测试过程,并对关键技术和实现难点进行了深入探讨。通过实验验证,本系统能够满足高考志愿填报的基本需求,为考生和家长提供了高效、便捷的服务。此外,本文还对系统未来的发展方向和改进空间进行了展望,以期进一步完善系统功能,提高用户体验。
关键词:Spring Boot、Vue.js、MySQL、协同过滤、高考志愿填报系统
With the continuous improvement of the college entrance examination system and the increasingly rich resources of higher education, the process of filling out college entrance examination applications has become a focal point for candidates and their parents. This paper aims to develop a college entrance examination application system based on the Spring Boot backend framework, Vue.js frontend framework, and MySQL database, aiming to enhance the efficiency and accuracy of the volunteer filling process and provide convenient services for candidates and their parents.
The system primarily implements the following functions: candidate information management, university information inquiry, major information inquiry, volunteer filling, volunteer adjustment, and statistics of volunteer filling results. The backend services are constructed using the Spring Boot framework, providing RESTful API interfaces for interaction with the frontend. The Vue.js framework is used to build the frontend user interface, enabling dynamic data display and interactive operations. The MySQL database is utilized to store data such as candidate information, university information, and major information.
During the system design process, we have fully considered the usability, scalability, and security of the system. By designing and optimizing the database reasonably, we have improved the query efficiency of the system. Additionally, we have adopted security frameworks such as Spring Security to protect the system, ensuring data security.
This paper elaborates on the process of system requirements analysis, design, implementation, and testing, and delves into the key technologies and implementation difficulties. Through experimental verification, our system is able to meet the basic needs of filling out college entrance examination applications, providing candidates and their parents with efficient and convenient services. Furthermore, this paper also forecasts the future development direction and room for improvement of the system, aiming to further enhance the system's functionalities and improve user experience.
Keywords: Spring Boot、 Vue.js; MySQL、College Entrance Examination
目 录
第1章 绪论
本系统旨在为高考学生和家长提供一站式的志愿填报参考平台,支持交互式地图可视化、智能个性化推荐、院校与专业查询等功能,解决新高考填报志愿过程中的信息分散、决策困难等痛点。基于 SpringBoot + Vue 的高考志愿智能推荐系统,为全国考生提供个性化、数据驱动的志愿填报辅助工具。结合高校录取线、985/211 分布、院校排名和专业前景等多维数据,帮助你做出更明智的选择!
(1)系统管理员基于RBAC权限模型继承若依框架的全功能体系,具有管理高校、专业、分数线、普通用户信息等数据的维护权限,通过集成若依的代码生成器模块,可实现数据库表结构的动态建模与维护,同时拥有系统所有业务模块的CRUD权限。
(2)普通用户的权限相对较少,仅开放与高校志愿填报相关的查询类操作。核心功能涵盖地理信息系统(GIS)可视化、多维院校检索、专业分数线分析、智能推荐引擎。
个性化高考志愿智能推荐系统的网站功能结构图 如图1所示。
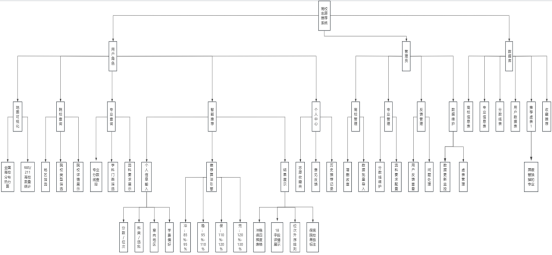
图1个性化高考志愿智能推荐系统功能结构图
1.2 任务分解
本课题根据前期的问卷调查以及实地考察,作出了适合实际的需求分析,采用了前后端分离的思想,后端使用了SpringBoot和SpringMVC框架,前端使用了Vue.js和若依框架进行页面的搭建,并且使用了MySQL数据库进行数据交互。整个系统的使用者有两种角色,分别是学生、系统管理员。
以下是三种不同的角色所分别拥有的功能:
1.2.1普通用户功能模块
(1) 注册:新用户可通过注册界面创建账号,已注册用户通过登录界面访问系统。
(2) 地图可视化:展示全国各省高校分布热力图、单独标注985/211高校数量统计、支持省份鼠标浮动查看详情。
(3) 院校查询:按省份、院校类型(综合/理工/师范等)、层次(本科/专科/提前批)筛选;查看院校详情。
(4) 专业查询:按专业名称、学科门类查询;查看专业详情;历年录取位次区间范围查询;选科要求说明;学费区间范围查询。
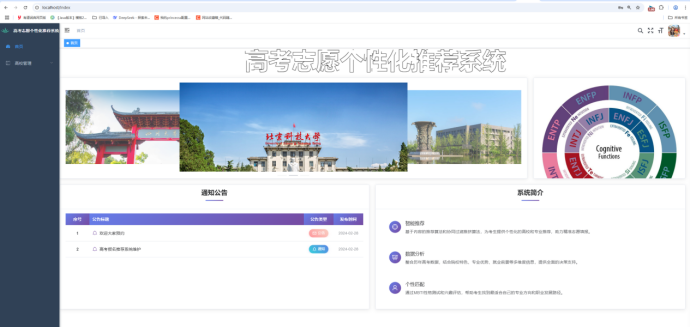
(5) 智能推荐:个人信息输入(分数/位次、选科组合、意向地区、学费范围);四梯度志愿推荐(冲/稳/保/保底);结果按位次升序排列(低在前);96个志愿表格展示(含18个关键字段)。
(6) 志愿收藏夹:收藏意向院校专业;管理收藏列表(添加/删除);收藏项对比分析。
(7) 意见反馈:此模块主要是针对用户意见反馈。提交系统使用建议、查看反馈处理状态、常见问题解答。
(8) 个人中心:查看/修改个人信息、密码修改、收藏夹管理。
1.2.2管理员功能模块
(1) 高校管理:高校信息增删改查、批量导入高校数据、高校属性配置(985/211标签等)。
(2) 专业管理:专业信息维护、选科要求配置、专业-院校关联管理。
(3) 分数线管理:历年分数线录入、位次数据更新、数据校验与修正。
(4) 推荐系统管理:推荐算法参数配置(梯度比例)、虚表维护(双虚表防刷新)、推荐结果抽样验证。
(5) 用户管理:用户信息查询、账户状态管理(启用/禁用)、用户行为分析。
(6) 意见反馈处理:查看所有用户反馈、反馈状态标记(已处理/待处理)、反馈回复功能。
(7) 数据监控:数据库更新状态监控、推荐系统性能监测、数据一致性检查。
(8) 系统维护:数据备份与恢复、系统参数配置、操作手册维护。
1.3 设计报告章节分布
本文主要设计和实现一个基于JavaEE+协同过滤的高考志愿填报管理系统。
以下罗列出了本论文的章节安排:
第1章 绪论:简明扼要地介绍了本课题的研究背景和意义,阐明了课题的主要任务,最后陈列出了本论文的章节安排。
第2章 相关技术和开发环境:本章介绍了系统用到的相关技术和开发环境。
第3章 系统分析:从经济、技术、运行三个方面介绍了系统可行性,从业务、功能、数据以及数据操作四个方面介绍了系统需求分析。
第4章 概要设计:介绍了本系统的设计,包括架构、功能、数据库以及接口的设计。
第5章 详细设计:对系统的主要功能以及数据库的设计进行了详细介绍。
第6章 系统实现:展示了系统的主要功能界面,并对其操作进行说明。
第7章 系统测试:简要介绍了系统的测试方法和测试环境,编写了主要测试用例,并分析记录了测试结果。
第8章 总结与展望:对本次的课题设计进行了总结,展望该系统仍需完善的功能。
第2章 相关技术和开发环境
2.1 相关技术
本课题在Windows系统下使用了JavaEE开发技术、Spring Boot技术、Vue.js技术、Redis无关系型数据库、MySQL关系型数据库以及若依框架前端框架技术进行开发。以下是关键技术及开发工具介绍。
Java是一种面向对象的编程语言,由Sun Microsystems(现在是Oracle公司)于1995年首次发布。它具有可移植性、安全性和跨平台等特性,因此被广泛应用于各个领域的软件开发中。
Java的平台无关性是其最重要的特性之一。通过Java虚拟机(JVM),Java程序可以在不同的操作系统和硬件上运行,而不需要针对特定平台进行修改。这意味着一次编写的Java代码可以在Windows、Linux、Mac等多个平台上运行。
Java是一种面向对象的语言,它支持封装、继承和多态等面向对象的编程概念。这使得Java程序更易于理解、扩展和维护。它还提供了强大的异常处理机制,使开发者能够更好地应对错误和异常情况。
Java还具有丰富的标准库和第三方库,以及一个庞大的开发者社区。这些库提供了许多常用的功能和工具,使得Java的开发变得更加高效和便捷。
总之,Java是一种功能强大、可靠性高、安全性好的编程语言,非常适合开发各种类型的应用程序,包括桌面应用程序、Web应用程序、移动应用程序等。它的广泛应用和稳定性使得Java成为了当今世界上最流行的编程语言之一。
HTML(超文本标记语言)是一种用于创建和组织网页内容的标记语言。它由一系列标签组成,标签用于标记和描述文档中的不同部分,如标题、段落、链接和图像等。HTML提供了结构化的标记方式,使得浏览器能够正确地解析并显示网页内容。
CSS(层叠样式表)是一种用于描述网页外观和布局的样式语言。通过CSS,可以对HTML文档中的元素进行样式设置,包括字体、颜色、大小、间距、边框和背景等。CSS的设计目标是将样式与内容分离,使得网页的样式可以独立于内容进行修改和调整,从而提高网页的可维护性和灵活性。
JavaScript是一种动态的、基于对象和事件驱动的脚本语言。它广泛用于前端开发,用于为网页增加交互性和动态性。通过JavaScript,可以操作网页的元素、处理用户的输入、响应事件、进行表单验证和数据处理等。它还可以通过AJAX技术与服务器进行数据交互,实现动态加载内容和实时更新。
HTML、CSS和JavaScript三者通常一起使用,被称为前端开发技术。HTML负责网页的内容和结构,CSS负责网页的样式和布局,JavaScript负责网页的交互和动态效果。它们共同作用于网页的不同方面,使网页成为一个功能丰富、外观吸引人且易于使用的用户界面。
总结起来,HTML提供了网页内容的结构和标记,CSS负责网页的样式和布局,JavaScript为网页增加了交互性和动态功能。三者的协同工作使得构建现代化、交互式的网页成为可能。
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API[1]。Redis的主要优点如下:
- 支持多种数据类型,包括Set,Zset,List,Hash,String五种数据类型,操作方便,适用于众多业务场景。
- 持久化存储,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- 性能好,Redis是基于内存操作的,所以读写性能很好。Redis读的速度是110000次/s,写的速度是81000次/s。
- 丰富的特性,Redis支持Publish/Subscribe,通知,Key过期策略等特性。
MySQL是一种关系型数据库管理系统,是一个多用户,多线程的SQL数据库。MySQL的优点是体积小、速度快、总体拥有成本低,开放源代码等,使得它成为了目前中小企业的最爱[2]。
Vue.js是一套用于构建用户界面的渐进式框架[4]。与其它大型框架不同的是,Vue被设计为可以自底向上逐层应用。Vue的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。
SpringBoot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。使用SpringBoot的最大好处就是简化配置,它实现了自动化配置。
表2-1展示了系统所需的开发环境。
表2-1系统所需开发环境表
操作系统 |
Windows 10 |
开发工具 |
IntelliJ IDEA 2021.02 |
Java环境 |
JDK1.8,Maven 3.8.1,MyBatis plus |
数据库 |
MySQL 8.0、Redis 3.0.10 |
3.1 可行性分析
本系统为考生个性化定制,可真正投入到实际生活中,所需要的硬件设备目前只需用到一部电脑,后期部署上线到阿里云服务器即可。软件方面大部分为官方提高免费使用的,所需资料也可在网上或者查询相关书籍即可找到。因此,本系统开发在经济方面是可行的。
本系统的主要开发语言为Java,基于目前较为流行的SpringBoot以及Vue.js框架进行编写。本系统采用了MySQL数据库作为数据存储基础阵地,保证了一个安全、稳定的数据使用环境。本系统使用的技术,基本上都是目前较为流行的并且是开源的技术,文档和资料在互联网上都非常健全,且有许多开发成功的项目。因此,本系统开发在技术方面是可行的。
本系统基于SpringBoot框架,需要搭建Java,Maven,Redis,MySQL等软件环境。在搭建的过程中,有遇到过种种的问题,但通过查询资料和请教导师,都能一一解决,并能熟练掌握。因此,本系统开发在运行方面是可行的。
3.2 业务流程分析
本系统的使用者一共有学生、系统管理员这两种角色:
1、学生:可查阅高校排名,专业分数等,进行志愿填报测评,个性化志愿推荐,收藏。
2、系统管理员:录入各大高校信息,专业排名。对学生信息进行管理登记,角色管理,菜单管理。系统总体配置修改
主要业务需求表3-1:
表3-1 业务需求表
编号 |
业务名称 |
操作者 |
1 |
学生信息管理 |
学生 |
2 |
院校信息查询 |
学生 |
3 |
专业信息查询 |
学生 |
4 |
志愿评测分析 |
学生 |
5 |
志愿填报 |
学生 |
6 |
院校信息管理 |
系统管理员 |
7 |
专业信息管理 |
系统管理员 |
8 |
志愿管理 |
系统管理员 |
9 |
用户管理 |
系统管理员 |
10 |
角色管理 |
系统管理员 |
11 |
菜单管理 |
系统管理员 |
总体业务流程图如下:
根据本系统的使用者将用户划分为两种角色,分别是管理员,系统管理员和学生。进入系统前需要通过账号以及密码进行登录,患者若无账号可先注册,由管理员统一分配角色,登录成功后则根据他们的各自的角色进入相应的页面。
图3-2 用户关系用例图
管理员进入网站的页面后,可以进行的功能用例如图3-3所示:
图3-3 管理员用例图
- 用户管理:可以通过关键字搜索,分页展示用户信息,同时可以增加、删除、修改用户信息。
- 角色管理:可以通过关键字搜索,分页展示角色信息,同时也可以删除角色信息。
- 菜单管理:可以通过关键字搜索,分页展示菜单信息,也可以删除菜单信息。
- 高中管理:可以通过关键字搜索,分页展示高中信息,同时可以增加、删除、修改高中信息。
系统管理员进入网站的页面后,可以进行的功能用例如图3-4所示:
图3-4 系统管理员用例图
- 院校信息管理:可以通过关键字搜索,分页展示院校信息,同时可以增加、删除、修改院校信息。
- 专业信息管理:可以通过关键字搜索,分页展示专业信息,同时可以增加、删除、修改专业信息。
- 志愿管理:可以通过关键字搜索,分页展示用户信息,同时可以增加、删除、修改用户信息。
学生进入网站的页面后,可以进行的功能用例如图3-5所示:
图3-5 学生用例图
实体集是具有相同类型及相同属性的实体的集合[5]。本系统主要的实体集主要有:
根据系统的需求分析和功能模块的划分规则,本系统的数据库将包括以下6张核心数据表:用户表、高校表、专业表、志愿表、用户-推荐志愿关系表以及用户-推荐志愿屏蔽关系表等若依自带的辅助表。
用户表(sys_user):用于记录平台用户的详细信息,包括账户、权限、联系方式、登录状态等;
高校表(cers_university):用于存储全国各大高校的基本信息,如高校名称、所在省份、排名、类型等;
专业表(cers_major):用于记录各高校所开设的专业及其招生录取信息,如投档线、学费、学制等;
志愿表(ce_aspiration):用于记录学生填报志愿的相关信息,包括学生学号、填报年份等;
用户-推荐志愿关系表(cers_user_recommend_rel):用于记录用户的ID与专业的ID来建立用户与推荐志愿之间的关系,并且通过belong字段来区分推荐志愿的不同梯度策略,帮助用户更好地理解和选择适合自己的志愿填报方案。
用户-推荐志愿屏蔽关系表(cers_user_recommend_rel_exclude):用于记录用户的ID和他们不想接收推荐的专业的ID来实现对特定推荐志愿的屏蔽功能。
此外,还涉及其他辅助表:
第4章 概要设计
本系统使用SpringBoot、Vue.js等主流开发框架进行开发,遵守MVC模式,同时使用到了Element-UI进行页面的设计。为方便前后端进行整合和日后系统的维护,本系统分为视图层、控制层、业务层和持久层。各层之间相互独立,通过之间的接口进行通信,高内聚,低耦合[6]。
图4-1 系统架构图
图4-2 系统功能模块图
学生实体:用来存储学生的基本信息。数据来源:系统管理员的录入,修改。
图4-3 学生实体信息属性图
志愿表单实体:存储学生志愿的基本信息,ID为主键。
数据来源:学生填报。
图4-4志愿表单实体信息属性图
院校实体:存储院校的基本信息,ID为主键。
数据来源:管理员录入,修改。
图4-5 院校实体信息属性图
专业实体:存储专业的基本信息,ID为主键。
数据来源:管理员的录入,修改。
图4-6 专业实体信息属性图
第5章 详细设计
系统功能模块如表5-1所示:
表5-1 系统功能模块
用户输入帐号和密码后,传至系统后台进行校验。如果帐号密码不匹配,跳回登录页面。账号密码都匹配的话,后端生成Token,返回给前端,前端存储到本地localStorage中,如图5-1所示。
图5-1 登录时序图
在上一章中,已对本系统的实体集进行了概要设计,并设计了实体集之间的E-R模型图。在本章节中,从数据库关系的角度出发,设计关系模型以及数据表的逻辑结构。
表5-2:ce_aspiration(志愿表)
表5-3:ce_college(院校表)
表5-4:ce_profession(专业表)
表5-5:ce_student(学生表)
第6章 系统实现
登录页面,用户在浏览器中输入网址后进入到系统的登录页面,如图6-1所示。
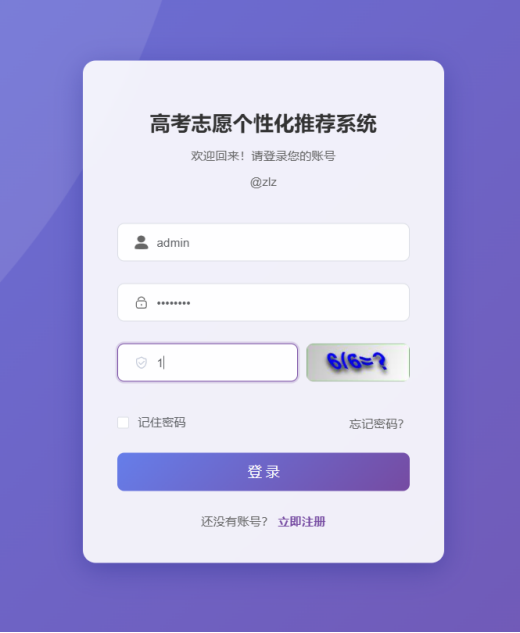
图6-1 登录页面
注册模块,用户填写表单可以注册成用户,如图6-2所示。
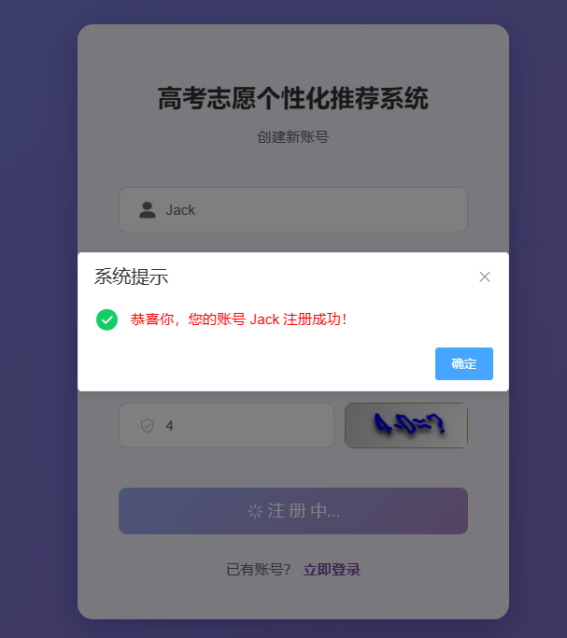
图6-2 注册界面
用户信息列表,管理员可对用户信息进行增删改查,如图6-3所示。
图6-3 用户信息管理
角色信息列表,管理员可以对角色信息进行增删改查,如图6-5所示。
图6-4 角色信息列表
图6-5 菜单信息列表
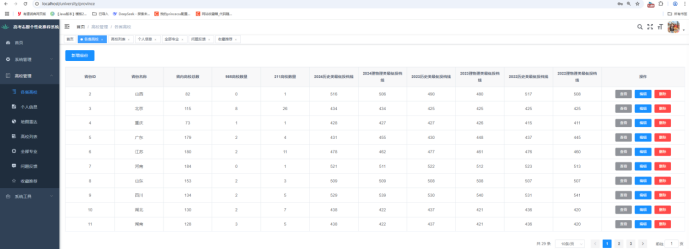
图6-6 学生信息
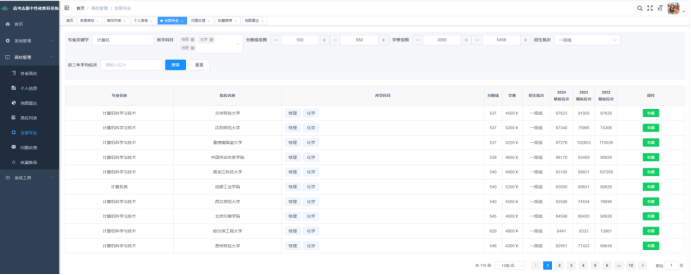
图6-7 院校管理
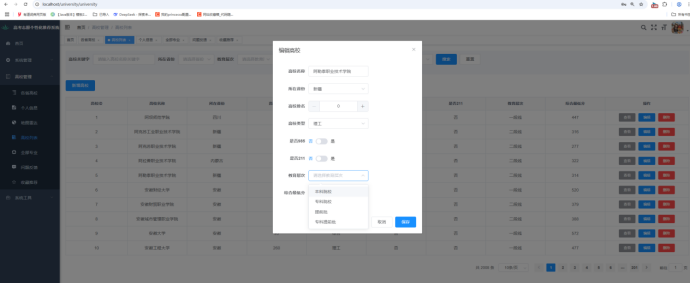
图6-8 专业管理
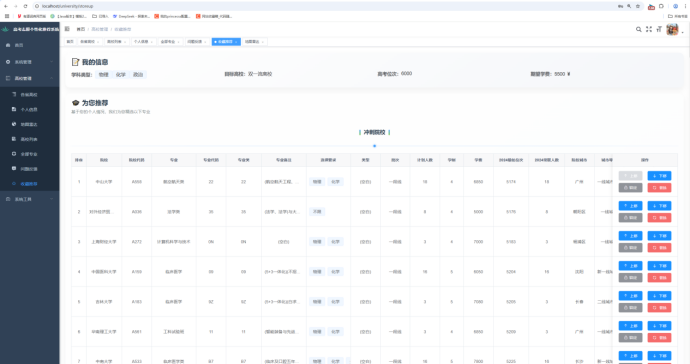
图6-9 志愿填报
第7章 系统测试
操作系统:Windows 10
数据库:MySQL 8.0.19、Redis 3.0.10
应用软件:Idea 2021.03
软硬件测试环境:10台电脑
系统测试是指在完成项目编码后,系统正式上线前,根据系统前期的需求分析以及规格说明进行最终审查。系统测试可以验证系统是否达到需求,每个功能模块是否存在着一些缺陷或错误引发系统不正常的运行[8],从而保证了系统的准确性与可靠性。
本系统在完成每一个小功能之后,都会进行单元测试,以此来找到存在的BUG并解决,同时可以检验功能实现是否达到了预期的效果。在系统完成后使用黑盒方法对本系统进行测试。
用户登录测试用例如表7-1所示:
表7-1 用户登录测试用例
编号 |
用例名 |
预期结果 |
实际结果 |
CS0101 |
输入正确的账号和密码 |
登录成功,进入用户角色首页 |
登录成功,进入用户角色首页 |
CS0102 |
输入错误的账号和正确的密码 |
提示账号或者密码错误,不做跳转 |
提示账号或者密码错误,不做跳转 |
CS0103 |
输入正确的账号和错误密码 |
提示账号或者密码错误,不做跳转 |
提示账号或者密码错误,不做跳转 |
CS0104 |
账号和密码均为空 |
提示账号或密码不能为空,不做跳转 |
提示账号或密码不能为空,不做跳转 |
用户注册测试用例如表7-2所示:
表7-2 用户注册测试用例
编号 |
用例名 |
预期结果 |
实际结果 |
CS0201 |
进入用户注册页面 |
显示用户注册页面 |
显示用户注册页面 |
CS0202 |
使用不正确的账号或者已存在的账号 |
提示该账号不合法或者已被占用 |
提示该账号不合法或者已被占用 |
CS0203 |
使用已存在的邮箱 |
提示该邮箱已被注册,请重新输入 |
提示该邮箱已被注册,请重新输入 |
7.4 结果及分析
...
附录1
0.购买服务器
主播购买的是阿里云的,学生认证之后优惠券直接减免,因为主播还在完善项目并未真正意义上的上线,所以只购买最轻量化的服务器。
1.宝塔配置
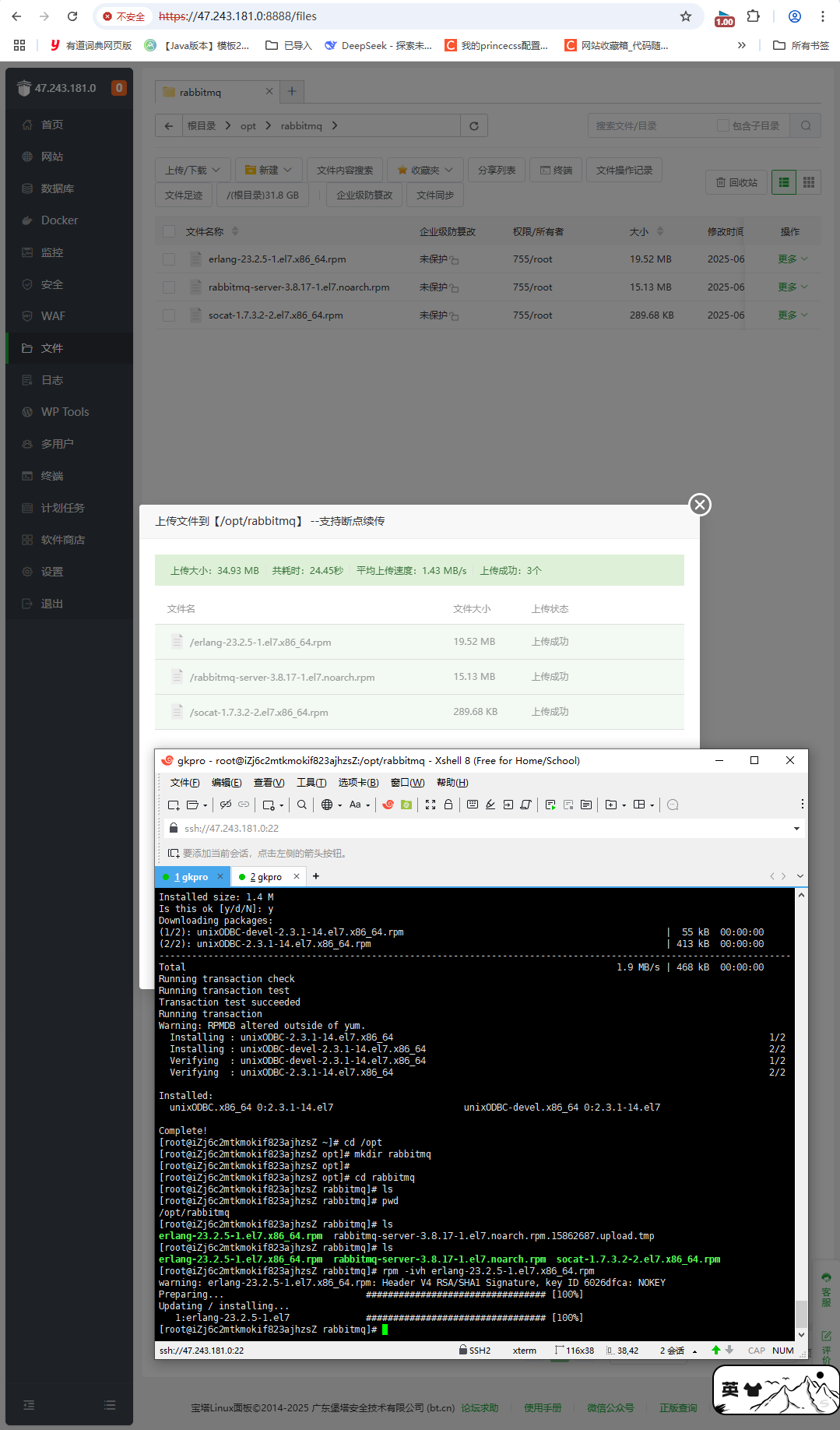
安装软件包(主播已经上传至资源中,免费下载)
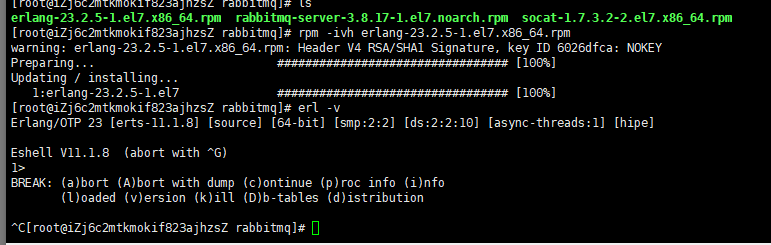
能看到版本号说明安装成功了

安装rabbitmq
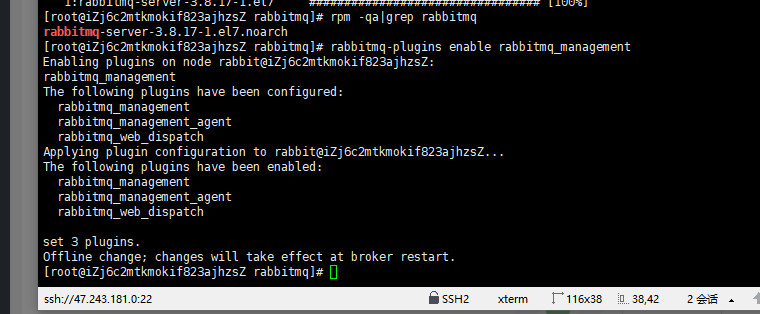
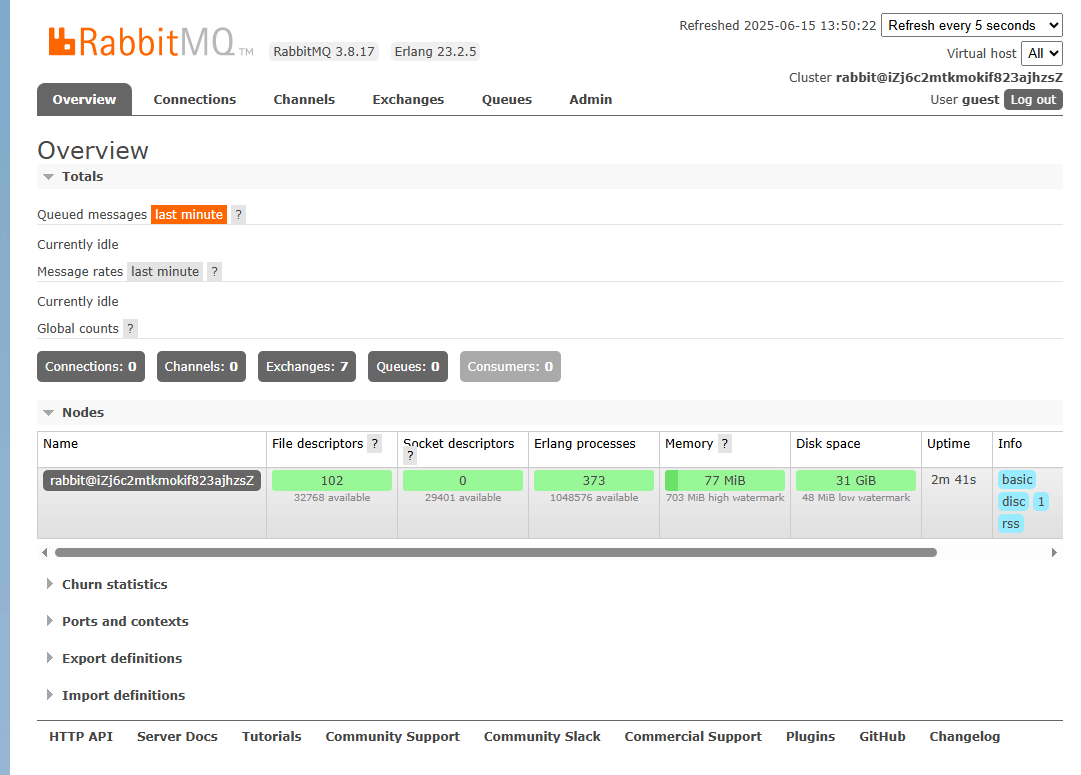
查看启动状态命令 并 访问15672端口
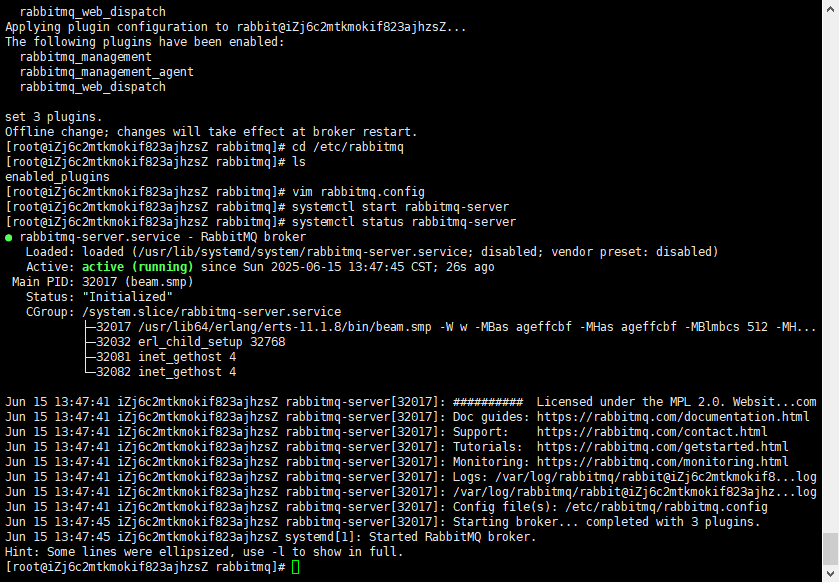

默认账号密码均为 guest
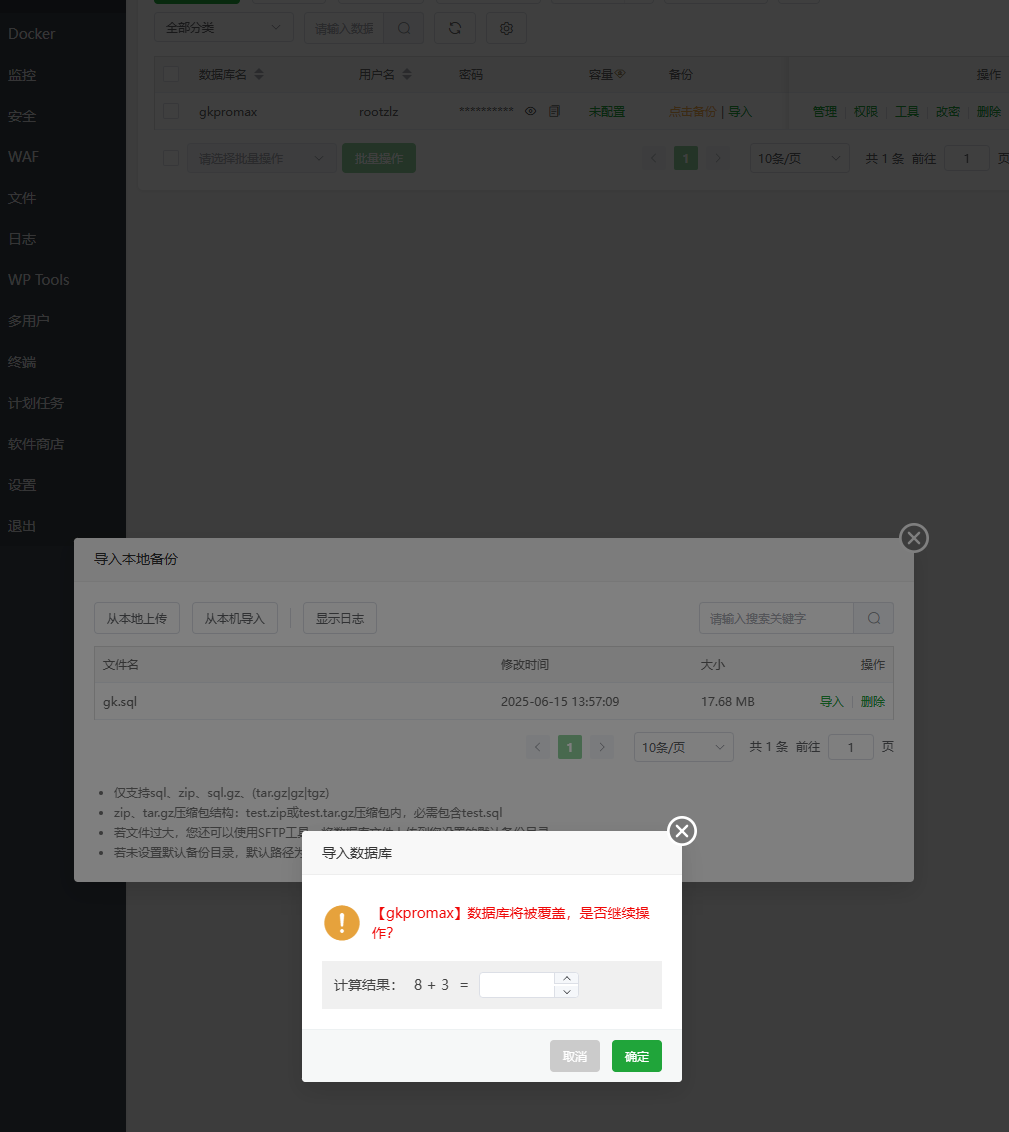
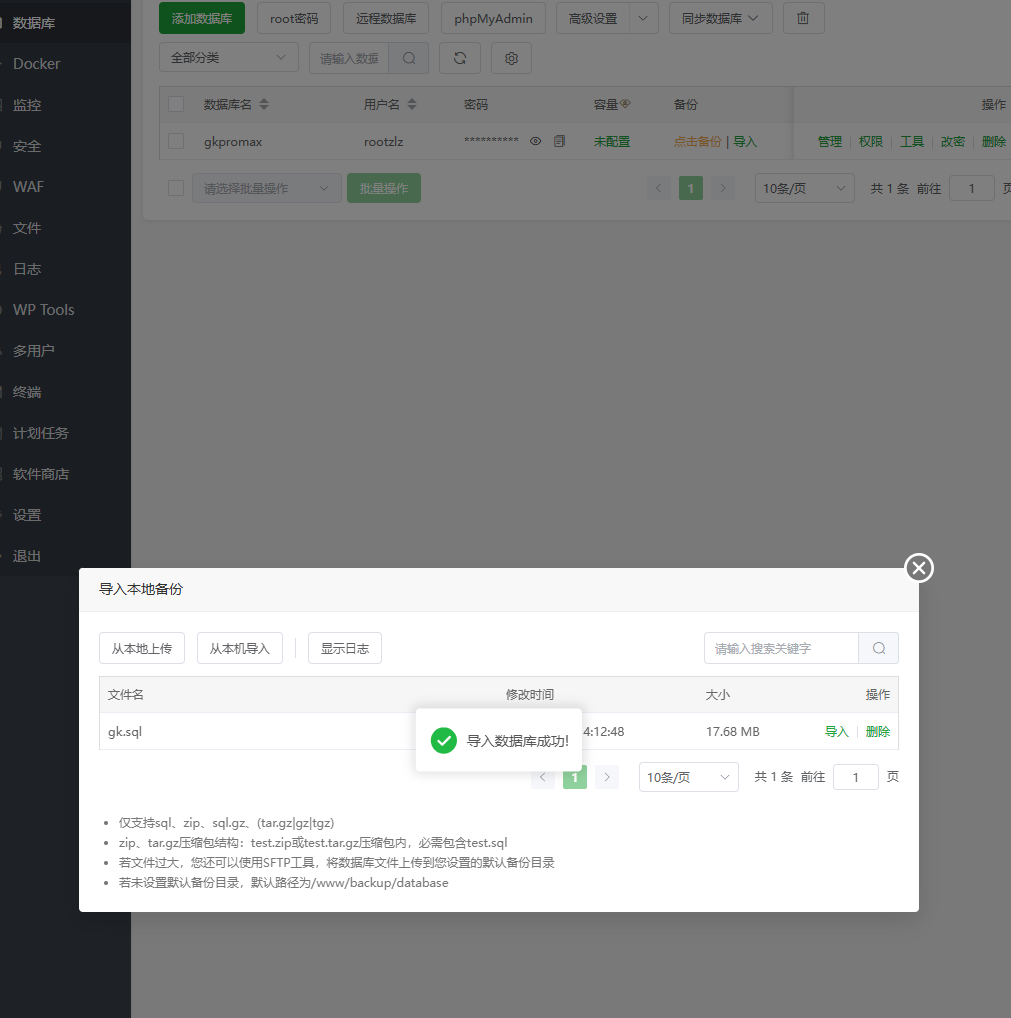
导入项目的数据库(这里有的兄弟会报错,看主播附录2的教程)
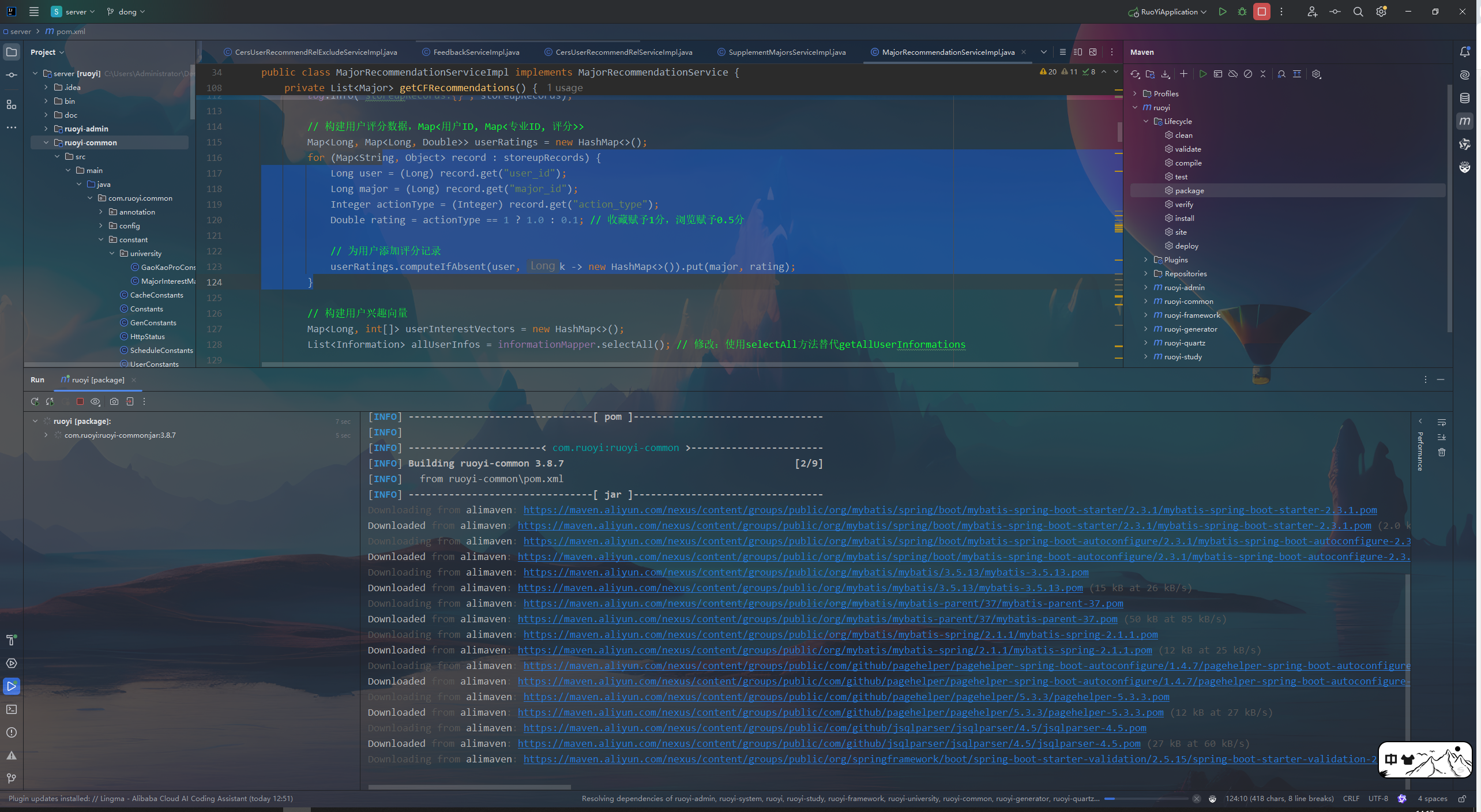
2.项目打包
先clean 再package
将admin下的jar包(只需这一个,若依框架的其他jar包不用管)上传至文件中,主播上传到自定义目录下,/www/wwwroot/ (如图)
上传完成之后点击网站添加站点
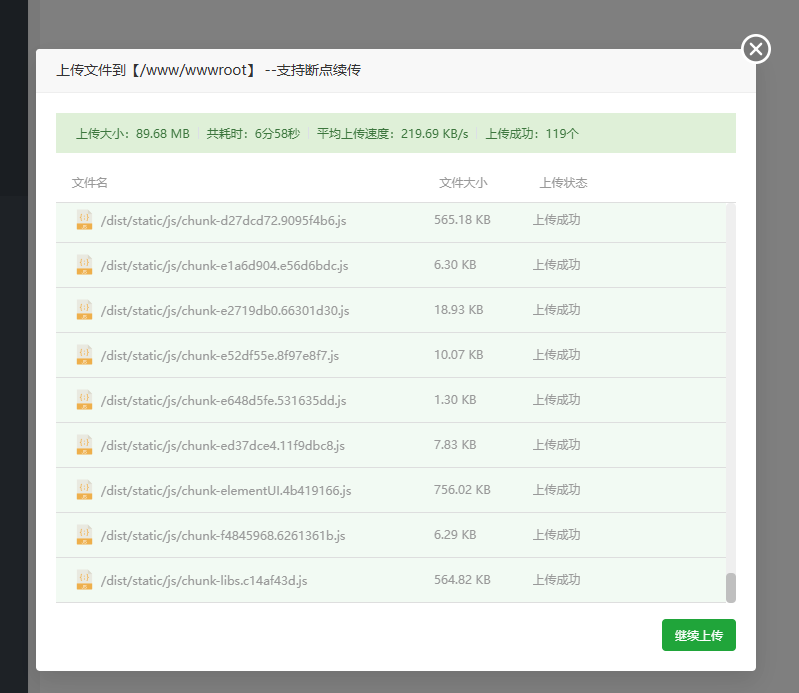
这里如果大家购买并ICP备案了域名,可以输入自己的域名,主播只演示最小白的方法,因为主播也是小白,用自己服务器的公网IP
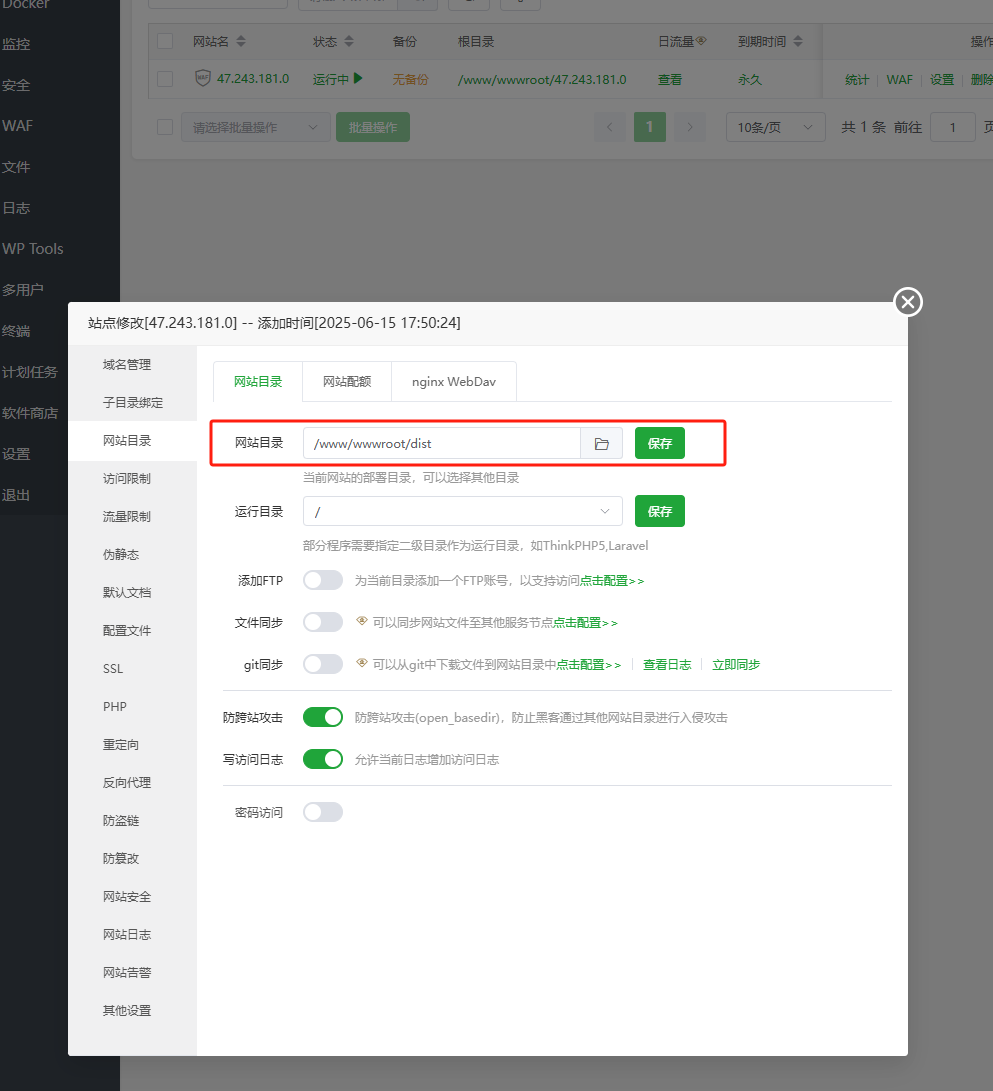
目录改为刚才上传的dist目录,并保存(两个保存都要点)
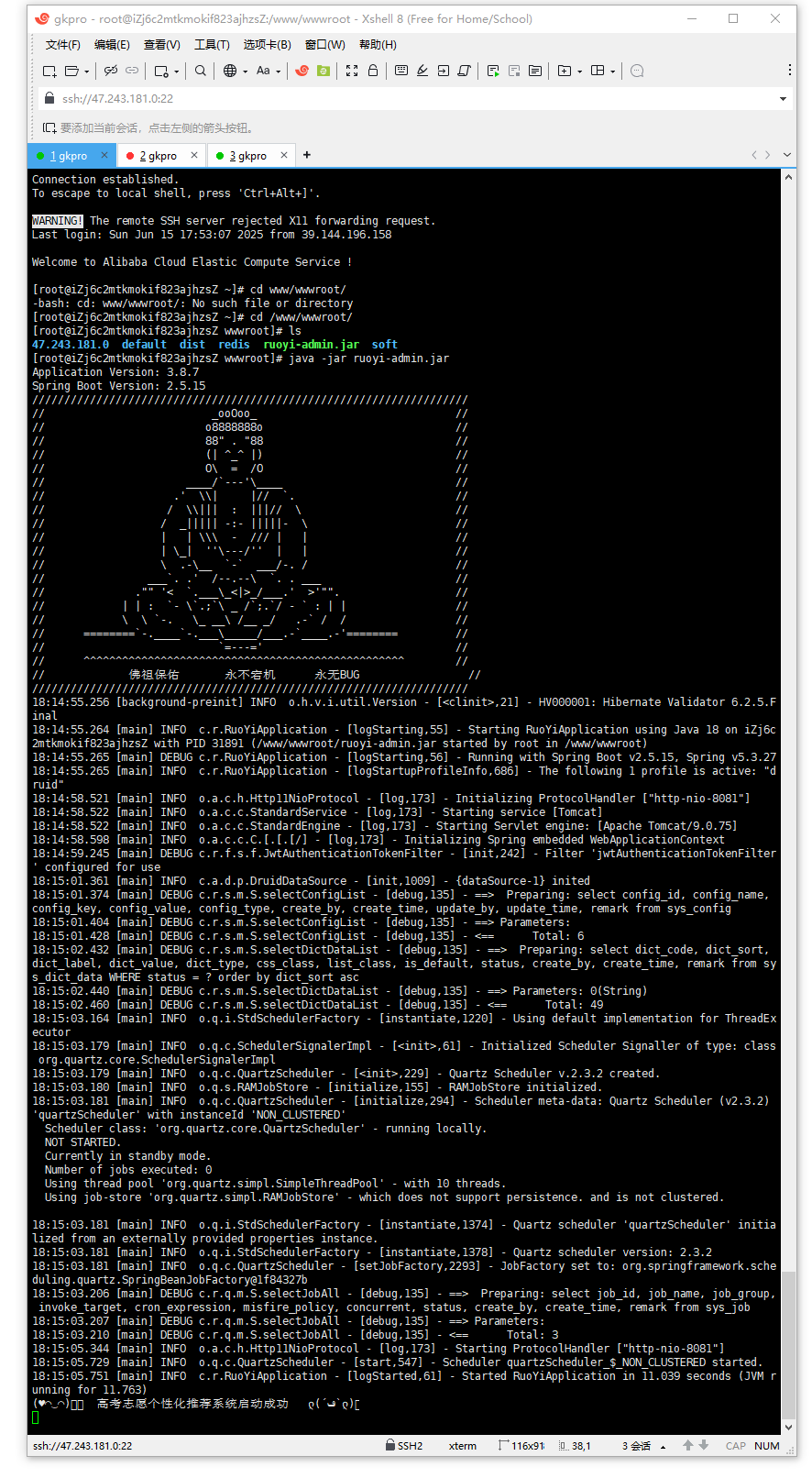
启动redis:
使用配置文件启动
/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
YS启动!启动成功
3.管理数据库
宝塔面板可通过phpMyAdmin管理数据库,根据提示下载依赖之后安装phpMyAdmin即可,初始账号为root 密码为空,如果你添加了数据库就按你的来。
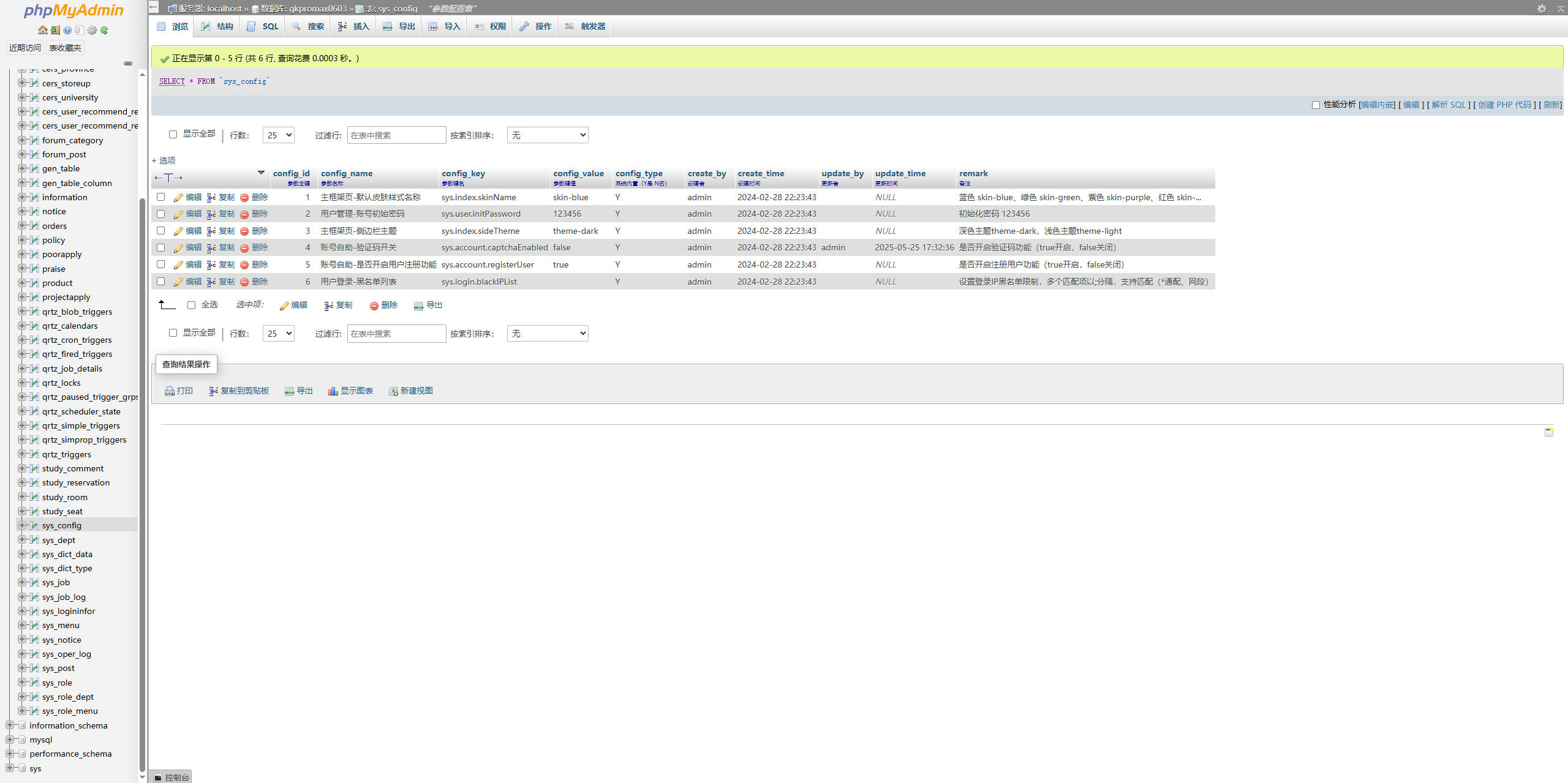
至此,访问成功

附录2
宝塔数据库导入错误排错指南
key:mysql版本兼容问题。
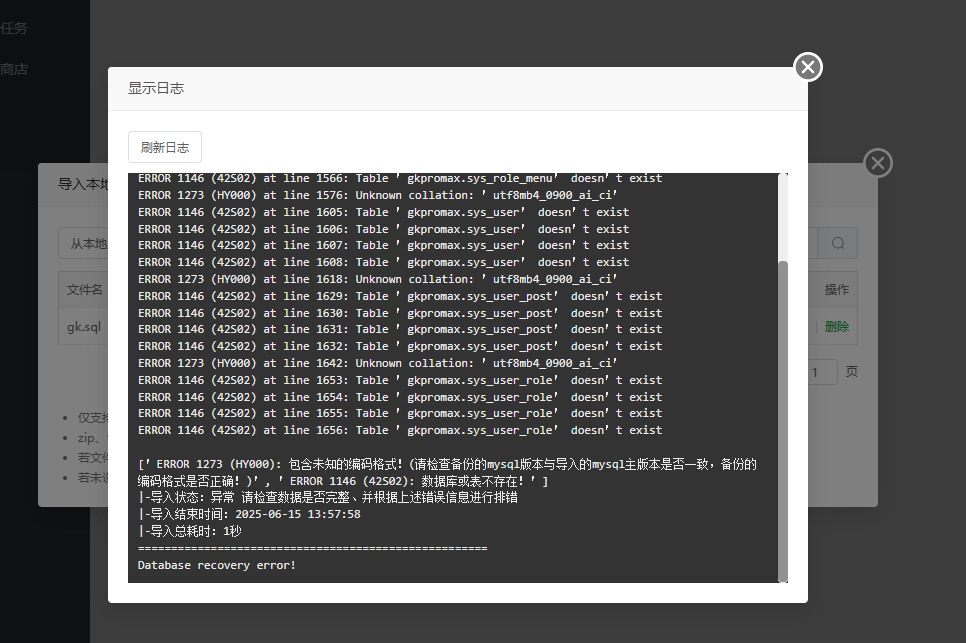
问题1:未知排序规则 utf8mb4_0900_ai_ci
原因: 导出的SQL文件使用了MySQL 8.0特有的排序规则(utf8mb4_0900_ai_ci),但当前MySQL服务器版本低于8.0(可能是5.7或更低版本),无法识别该规则。
解决方案: 替换SQL文件中的排序规则
用文本编辑器(如VS Code、Notepad++)打开SQL备份文件。
全局替换所有
utf8mb4_0900_ai_ci为低版本兼容的排序规则(例如utf8mb4_general_ci)。替换目标:
utf8mb4_general_ci(兼容MySQL 5.x)。
保存文件后重新导入。
问题2:表不存在(如 sys_role_dept 等)
原因:
主问题:排序规则错误导致建表语句执行失败(
ERROR 1273),后续插入数据时表尚未创建。次要可能:SQL文件逻辑顺序错误(插入数据前未创建表)。
解决方案:
优先解决排序规则问题(完成上述替换后,建表语句即可正常执行)。
若替换后仍报错,检查SQL文件结构:
确认
CREATE TABLE语句位于插入数据(INSERT)之前。搜索
sys_role_dept等表名,检查建表语句是否存在。
操作步骤总结
修改SQL文件:
# Linux/Mac 终端命令 sed -i 's/utf8mb4_0900_ai_ci/utf8mb4_general_ci/g' /path/to/your_database.sql # Windows 用文本编辑器手动替换重新导入数据库:
在宝塔面板中选择修改后的SQL文件重新导入。
或通过命令行导入:
mysql -u用户名 -p密码 数据库名 < /path/to/修改后的.sql
预防措施
统一MySQL版本:
导出和导入的MySQL主版本尽量一致(例如均使用5.7或均使用8.0)。
导出时指定兼容选项:
mysqldump --compatible=mysql4 --skip-set-charset --default-character-set=utf8mb4 -u用户 -p 数据库名 > backup.sql
关键提示:错误中的
ERROR 1273是根源,它导致建表失败,进而引发后续表不存在的连锁错误。修复排序规则后,问题通常可彻底解决。
至此,导入成功
写在最后
主播正努力融入AI并优化算法,同时主播再次声明论文仅供参考!
主播已将项目打包部署(为方便,验证码已屏蔽),大家可以通过公网IP访问主播,查看项目,项目在不断优化,主播尽量做到实时更新!主播会不断优化此项目!
公网IP : 47.243.181.0
Thanks for your attention !