《parse_request_line 函数》:解析HTTP请求行
《parse_headers 函数》:解析HTTP请求头
epoll
epoll_create函数
#include <sys/epoll.h>
int epoll_create(int size)创建一个指示epoll内核事件表的文件描述符,该描述符将用作其他epoll系统调用的第一个参数,size不起作用。
epoll_ctl函数
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)该函数用于操作内核事件表监控的文件描述符上的事件:注册、修改、删除
epfd:为epoll_creat的句柄
op:表示动作,用3个宏来表示:
EPOLL_CTL_ADD (注册新的fd到epfd),
EPOLL_CTL_MOD (修改已经注册的fd的监听事件),
EPOLL_CTL_DEL (从epfd删除一个fd);
event:告诉内核需要监听的事件
events
events描述事件类型,其中epoll事件类型有以下几种
EPOLLIN:表示对应的文件描述符可以读(包括对端SOCKET正常关闭)
EPOLLOUT:表示对应的文件描述符可以写
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来)
EPOLLERR:表示对应的文件描述符发生错误
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET:将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)而言的
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
epoll_wait函数
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout)该函数用于等待所监控文件描述符上有事件的产生,返回就绪的文件描述符个数
events:用来存内核得到事件的集合,
maxevents:告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,
timeout:是超时时间
-1:阻塞
0:立即返回,非阻塞
>0:指定毫秒
返回值:成功返回有多少文件描述符就绪,时间到时返回0,出错返回-1
select/poll/epoll
调用函数
select和poll都是一个函数,epoll是一组函数
文件描述符数量
select通过线性表描述文件描述符集合,文件描述符有上限,一般是1024,但可以修改源码,重新编译内核,不推荐
poll是链表描述,突破了文件描述符上限,最大可以打开文件的数目
epoll通过红黑树描述,最大可以打开文件的数目,可以通过命令ulimit -n number修改,仅对当前终端有效
将文件描述符从用户传给内核
select和poll通过将所有文件描述符拷贝到内核态,每次调用都需要拷贝
epoll通过epoll_create建立一棵红黑树,通过epoll_ctl将要监听的文件描述符注册到红黑树上
内核判断就绪的文件描述符
select和poll通过遍历文件描述符集合,判断哪个文件描述符上有事件发生
epoll_create时,内核除了帮我们在epoll文件系统里建了个红黑树用于存储以后epoll_ctl传来的fd外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。
epoll是根据每个fd上面的回调函数(中断函数)判断,只有发生了事件的socket才会主动的去调用 callback函数,其他空闲状态socket则不会,若是就绪事件,插入list
应用程序索引就绪文件描述符
select/poll只返回发生了事件的文件描述符的个数,若知道是哪个发生了事件,同样需要遍历
epoll返回的发生了事件的个数和结构体数组,结构体包含socket的信息,因此直接处理返回的数组即可
工作模式
select和poll都只能工作在相对低效的LT模式下
epoll则可以工作在ET高效模式,并且epoll还支持EPOLLONESHOT事件,该事件能进一步减少可读、可写和异常事件被触发的次数。
应用场景
当所有的fd都是活跃连接,使用epoll,需要建立文件系统,红黑书和链表对于此来说,效率反而不高,不如selece和poll
当监测的fd数目较小,且各个fd都比较活跃,建议使用select或者poll
当监测的fd数目非常大,成千上万,且单位时间只有其中的一部分fd处于就绪状态,这个时候使用epoll能够明显提升性能
ET、LT、EPOLLONESHOT
LT水平触发模式
epoll_wait检测到文件描述符有事件发生,则将其通知给应用程序,应用程序可以不立即处理该事件。
当下一次调用epoll_wait时,epoll_wait还会再次向应用程序报告此事件,直至被处理
ET边缘触发模式
epoll_wait检测到文件描述符有事件发生,则将其通知给应用程序,应用程序必须立即处理该事件
必须要一次性将数据读取完,使用非阻塞I/O,读取到出现eagain
EPOLLONESHOT
一个线程读取某个socket上的数据后开始处理数据,在处理过程中该socket上又有新数据可读,此时另一个线程被唤醒读取,此时出现两个线程处理同一个socket
我们期望的是一个socket连接在任一时刻都只被一个线程处理,通过epoll_ctl对该文件描述符注册epolloneshot事件,一个线程处理socket时,其他线程将无法处理,当该线程处理完后,需要通过epoll_ctl重置epolloneshot事件
HTTP报文格式
HTTP报文分为请求报文和响应报文两种,每种报文必须按照特有格式生成,才能被浏览器端识别。
其中,浏览器端向服务器发送的为请求报文,服务器处理后返回给浏览器端的为响应报文。
请求报文
HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
其中,请求分为两种,GET和POST,具体的:
GET
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host:img.mukewang.com
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept:image/webp,image/*,*/*;q=0.8
Referer:http://www.imooc.com/
Accept-Encoding:gzip, deflate, sdch
Accept-Language:zh-CN,zh;q=0.8
请求数据为空- POST
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
空行
name=Professional%20Ajax&publisher=Wiley
请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本。
GET说明请求类型为GET,/562f25980001b1b106000338.jpg(URL)为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息。
HOST,给出请求资源所在服务器的域名。
User-Agent,HTTP客户端程序的信息,该信息由你发出请求使用的浏览器来定义,并且在每个请求中自动发送等。
Accept,说明用户代理可处理的媒体类型。
Accept-Encoding,说明用户代理支持的内容编码。
Accept-Language,说明用户代理能够处理的自然语言集。
Content-Type,说明实现主体的媒体类型。
Content-Length,说明实现主体的大小。
Connection,连接管理,可以是Keep-Alive或close。
空行,请求头部后面的空行是必须的即使第四部分的请求数据为空,也必须有空行。
请求数据也叫主体,可以添加任意的其他数据。
响应报文
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8
空行
<html>
<head></head>
<body>
<!--body goes here-->
</body>
</html>
状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为OK。消息报头,用来说明客户端要使用的一些附加信息。
第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8。空行,消息报头后面的空行是必须的。
响应正文,服务器返回给客户端的文本信息。空行后面的html部分为响应正文。
HTTP状态码
HTTP有5种类型的状态码,具体的:
1xx:指示信息--表示请求已接收,继续处理。
2xx:成功--表示请求正常处理完毕。
200 OK:客户端请求被正常处理。
206 Partial content:客户端进行了范围请求。
3xx:重定向--要完成请求必须进行更进一步的操作。
301 Moved Permanently:永久重定向,该资源已被永久移动到新位置,将来任何对该资源的访问都要使用本响应返回的若干个URI之一。
302 Found:临时重定向,请求的资源现在临时从不同的URI中获得。
4xx:客户端错误--请求有语法错误,服务器无法处理请求。
400 Bad Request:请求报文存在语法错误。
403 Forbidden:请求被服务器拒绝。
404 Not Found:请求不存在,服务器上找不到请求的资源。
5xx:服务器端错误--服务器处理请求出错。
500 Internal Server Error:服务器在执行请求时出现错误。
有限状态机
有限状态机,是一种抽象的理论模型,它能够把有限个变量描述的状态变化过程,以可构造可验证的方式呈现出来。比如,封闭的有向图。
有限状态机可以通过if-else,switch-case和函数指针来实现,从软件工程的角度看,主要是为了封装逻辑。
带有状态转移的有限状态机示例代码。
STATE_MACHINE() {
State cur_State = type_A;
while (cur_State != type_C) {
Package _pack = getNewPackage();
switch (cur_State) {
case type_A:
process_pkg_state_A(_pack);
cur_State = type_B;
break;
case type_B:
process_pkg_state_B(_pack);
cur_State = type_C;
break;
}
}
}
该状态机包含三种状态:type_A,type_B和type_C。其中,type_A是初始状态,type_C是结束状态。
状态机的当前状态记录在cur_State变量中,逻辑处理时,状态机先通过getNewPackage获取数据包,然后根据当前状态对数据进行处理,处理完后,状态机通过改变cur_State完成状态转移。
有限状态机一种逻辑单元内部的一种高效编程方法,在服务器编程中,服务器可以根据不同状态或者消息类型进行相应的处理逻辑,使得程序逻辑清晰易懂。
http处理流程
首先对http报文处理的流程进行简要介绍,然后具体介绍http类的定义和服务器接收http请求的具体过程。
http报文处理流程
浏览器端发出http连接请求,主线程创建http对象接收请求并将所有数据读入对应buffer,将该对象插入任务队列,工作线程从任务队列中取出一个任务进行处理。
工作线程取出任务后,调用process_read函数,通过主、从状态机对请求报文进行解析。
解析完之后,跳转do_request函数生成响应报文,通过process_write写入buffer,返回给浏览器端。
http类
这一部分代码在TinyWebServer/http/http_conn.h中,主要是http类的定义。
class http_conn{
public:
//设置读取文件的名称m_real_file大小
static const int FILENAME_LEN=200;
//设置读缓冲区m_read_buf大小
static const int READ_BUFFER_SIZE=2048;
//设置写缓冲区m_write_buf大小
static const int WRITE_BUFFER_SIZE=1024;
//报文的请求方法,本项目只用到GET和POST
enum METHOD{GET=0,POST,HEAD,PUT,DELETE,TRACE,OPTIONS,CONNECT,PATH};
//主状态机的状态
enum CHECK_STATE{CHECK_STATE_REQUESTLINE=0,CHECK_STATE_HEADER,CHECK_STATE_CONTENT};
//报文解析的结果
enum HTTP_CODE{NO_REQUEST,GET_REQUEST,BAD_REQUEST,NO_RESOURCE,FORBIDDEN_REQUEST,FILE_REQUEST,INTERNAL_ERROR,CLOSED_CONNECTION};
//从状态机的状态
enum LINE_STATUS{LINE_OK=0,LINE_BAD,LINE_OPEN};
public:
http_conn(){}
~http_conn(){}
public:
//初始化套接字地址,函数内部会调用私有方法init
void init(int sockfd,const sockaddr_in &addr);
//关闭http连接
void close_conn(bool real_close=true);
void process();
//读取浏览器端发来的全部数据
bool read_once();
//响应报文写入函数
bool write();
sockaddr_in *get_address(){
return &m_address;
}
//同步线程初始化数据库读取表
void initmysql_result();
//CGI使用线程池初始化数据库表
void initresultFile(connection_pool *connPool);
private:
void init();
//从m_read_buf读取,并处理请求报文
HTTP_CODE process_read();
//向m_write_buf写入响应报文数据
bool process_write(HTTP_CODE ret);
//主状态机解析报文中的请求行数据
HTTP_CODE parse_request_line(char *text);
//主状态机解析报文中的请求头数据
HTTP_CODE parse_headers(char *text);
//主状态机解析报文中的请求内容
HTTP_CODE parse_content(char *text);
//生成响应报文
HTTP_CODE do_request();
//m_start_line是已经解析的字符
//get_line用于将指针向后偏移,指向未处理的字符
char* get_line(){return m_read_buf+m_start_line;};
//从状态机读取一行,分析是请求报文的哪一部分
LINE_STATUS parse_line();
void unmap();
//根据响应报文格式,生成对应8个部分,以下函数均由do_request调用
bool add_response(const char* format,...);
bool add_content(const char* content);
bool add_status_line(int status,const char* title);
bool add_headers(int content_length);
bool add_content_type();
bool add_content_length(int content_length);
bool add_linger();
bool add_blank_line();
public:
static int m_epollfd;
static int m_user_count;
MYSQL *mysql;
private:
int m_sockfd;
sockaddr_in m_address;
//存储读取的请求报文数据
char m_read_buf[READ_BUFFER_SIZE];
//缓冲区中m_read_buf中数据的最后一个字节的下一个位置
int m_read_idx;
//m_read_buf读取的位置m_checked_idx
int m_checked_idx;
//m_read_buf中已经解析的字符个数
int m_start_line;
//存储发出的响应报文数据
char m_write_buf[WRITE_BUFFER_SIZE];
//指示buffer中的长度
int m_write_idx;
//主状态机的状态
CHECK_STATE m_check_state;
//请求方法
METHOD m_method;
//以下为解析请求报文中对应的6个变量
//存储读取文件的名称
char m_real_file[FILENAME_LEN];
char *m_url;
char *m_version;
char *m_host;
int m_content_length;
bool m_linger;
char *m_file_address; //读取服务器上的文件地址
struct stat m_file_stat;
struct iovec m_iv[2]; //io向量机制iovec
int m_iv_count;
int cgi; //是否启用的POST
char *m_string; //存储请求头数据
int bytes_to_send; //剩余发送字节数
int bytes_have_send; //已发送字节数
};在http请求接收部分,会涉及到init和read_once函数,但init仅仅是对私有成员变量进行初始化,不用过多讲解。
这里,对read_once进行介绍。read_once读取浏览器端发送来的请求报文,直到无数据可读或对方关闭连接,读取到m_read_buffer中,并更新m_read_idx。
bool http_conn::read_once()
{
if(m_read_idx>=READ_BUFFER_SIZE)
{
return false;
}
int bytes_read=0;
while(true)
{
//从套接字接收数据,存储在m_read_buf缓冲区
bytes_read=recv(m_sockfd,m_read_buf+m_read_idx,READ_BUFFER_SIZE-m_read_idx,0);
if(bytes_read==-1)
{
//非阻塞ET模式下,需要一次性将数据读完
if(errno==EAGAIN||errno==EWOULDBLOCK)
break;
return false;
}
else if(bytes_read==0)
{
return false;
}
//修改m_read_idx的读取字节数
m_read_idx+=bytes_read;
}
return true;
}epoll相关代码
项目中epoll相关代码部分包括非阻塞模式、内核事件表注册事件、删除事件、重置EPOLLONESHOT事件四种。
非阻塞模式
//对文件描述符设置非阻塞
int setnonblocking(int fd)
{
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}- 内核事件表注册新事件,开启EPOLLONESHOT,针对客户端连接的描述符,listenfd不用开启
void addfd(int epollfd, int fd, bool one_shot)
{
epoll_event event;
event.data.fd = fd;
#ifdef ET
event.events = EPOLLIN | EPOLLET | EPOLLRDHUP;
#endif
#ifdef LT
event.events = EPOLLIN | EPOLLRDHUP;
#endif
if (one_shot)
event.events |= EPOLLONESHOT;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}内核事件表删除事件
void removefd(int epollfd, int fd)
{
epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, 0);
close(fd);
}- 重置EPOLLONESHOT事件
void modfd(int epollfd, int fd, int ev)
{
epoll_event event;
event.data.fd = fd;
#ifdef ET
event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;
#endif
#ifdef LT
event.events = ev | EPOLLONESHOT | EPOLLRDHUP;
#endif
epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event);
}服务器接收http请求
步骤1:定义连接对象(http_conn类)
目的:封装单个客户端连接的状态(如套接字、缓冲区、请求解析状态等),提供初始化、读写、关闭等接口。
关键成员:
int m_fd:客户端套接字描述符。char m_read_buf[MAX_BUFFER]:读缓冲区(存储客户端发送的数据)。int m_read_idx:读缓冲区当前有效数据的末尾索引。static int m_epollfd:全局epoll文件描述符(所有连接共享)。static int m_user_count:当前活跃连接数(用于限制最大并发)。
关键方法:
init(int fd, sockaddr_in& addr):初始化连接对象(绑定套接字、地址,重置缓冲区等)。read_once():从套接字读取数据到缓冲区(返回是否读取成功,如EOF或错误则返回false)。close_conn():关闭连接并释放资源。
步骤2:初始化全局资源
目的:创建epoll实例、监听套接字,并将监听套接字注册到epoll中。
编码逻辑:
// 1. 创建连接对象池(预分配MAX_FD个连接)
http_conn* users = new http_conn[MAX_FD];
// 2. 初始化全局变量(epollfd、连接计数)
http_conn::m_epollfd = -1;
http_conn::m_user_count = 0;
// 3. 创建监听套接字(TCP)
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
assert(listenfd != -1);
// 4. 设置监听套接字选项(可选:重用端口、非阻塞)
int opt = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
fcntl(listenfd, F_SETFL, fcntl(listenfd, F_GETFD, 0) | O_NONBLOCK); // 非阻塞(ET模式需要)
// 5. 绑定地址并监听
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT);
server_addr.sin_addr.s_addr = INADDR_ANY;
bind(listenfd, (struct sockaddr*)&server_addr, sizeof(server_addr));
listen(listenfd, 5); // 监听队列长度
// 6. 创建epoll实例(内核事件表)
int epollfd = epoll_create(5); // 参数为内核事件表的大小(实际可动态扩展)
assert(epollfd != -1);
http_conn::m_epollfd = epollfd; // 关联到连接对象的静态成员
// 7. 将监听套接字添加到epoll事件表(LT默认触发)
struct epoll_event ev;
ev.data.fd = listenfd;
ev.events = EPOLLIN | EPOLLRDHUP; // 监听可读事件和对端关闭事件
epoll_ctl(epollfd, EPOLL_CTL_ADD, listenfd, &ev); // 注册事件步骤3:主事件循环(epoll_wait)
目的:阻塞等待epoll事件就绪,循环处理所有触发的事件。
编码逻辑:
bool stop_server = false; // 服务器停止标志(可通过信号触发)
while (!stop_server) {
// 等待事件就绪(超时-1表示永久阻塞)
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if (number < 0 && errno != EINTR) { // 错误处理(EINTR为信号中断)
perror("epoll_wait error");
break;
}
// 遍历所有就绪事件
for (int i = 0; i < number; ++i) {
int sockfd = events[i].data.fd; // 当前事件的套接字
// 根据套接字类型分发处理
if (sockfd == listenfd) {
handle_new_connection(); // 处理新连接
} else if (events[i].events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR)) {
handle_error_connection(sockfd); // 处理异常连接
} else if (events[i].events & EPOLLIN) {
handle_read_event(sockfd); // 处理读事件(客户端发送数据)
}
// 其他事件(如EPOLLOUT写事件,可选)
}
}步骤4:处理新连接(监听套接字触发)
目的:接受客户端连接,初始化http_conn对象,并根据LT/ET模式调整监听方式。
关键逻辑(LT模式):
void handle_new_connection() {
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
// 循环接受新连接(LT模式可能一次触发多个,但默认只处理一个)
while (true) {
int connfd = accept(listenfd, (struct sockaddr*)&client_addr, &client_len);
if (connfd < 0) {
if (errno == EAGAIN || errno == EWOULDBLOCK) { // LT模式下无更多连接可accept
break;
}
perror("accept error");
continue;
}
// 检查连接数是否超限
if (http_conn::m_user_count >= MAX_FD) {
show_error(connfd, "Internal server busy"); // 返回错误响应
close(connfd); // 关闭多余连接
continue;
}
// 初始化连接对象(绑定套接字、地址,重置缓冲区)
users[connfd].init(connfd, client_addr);
http_conn::m_user_count++; // 连接数+1
}
}关键逻辑(ET模式):
ET模式需循环accept直到无新连接(否则可能丢失事件):
void handle_new_connection_ET() {
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
while (true) {
int connfd = accept(listenfd, (struct sockaddr*)&client_addr, &client_len);
if (connfd < 0) break; // ET模式下无更多连接则退出循环
// 同样检查连接数超限...
users[connfd].init(connfd, client_addr);
http_conn::m_user_count++;
}
}步骤5:处理客户端读事件(EPOLLIN触发)
目的:读取客户端发送的数据,解析HTTP请求,完成后提交到线程池异步处理。
编码逻辑:
void handle_read_event(int sockfd) {
// 获取对应的连接对象(假设sockfd是数组索引)
http_conn* conn = &users[sockfd];
// 读取数据(返回false表示读取失败或EOF)
if (!conn->read_once()) {
// 读取失败(如连接断开),关闭连接
conn->close_conn();
http_conn::m_user_count--;
return;
}
// 解析HTTP请求(简化示例,实际需处理完整协议)
if (conn->parse_request()) {
// 请求解析完成,提交到线程池处理
pool->append(conn); // 假设线程池支持任务队列
} else {
// 数据未读取完,LT模式下epoll会再次通知;ET模式需继续读取(但此处已用read_once)
}
}步骤6:处理异常事件(EPOLLRDHUP/EPOLLHUP/EPOLLERR)
目的:客户端主动关闭连接、网络错误等场景下的资源释放。
编码逻辑:
void handle_error_connection(int sockfd) {
// 查找对应的连接对象(需确保sockfd在数组范围内)
if (sockfd < 0 || sockfd >= MAX_FD) return;
http_conn* conn = &users[sockfd];
// 关闭连接并清理资源
conn->close_conn();
http_conn::m_user_count--;
}步骤7:线程池集成(异步处理请求)
目的:将客户端请求的处理(如解析HTTP、生成响应)放到线程池,避免阻塞epoll主线程。
关键设计:
- 线程池维护一组工作线程,从任务队列中取出
http_conn*对象处理。 - 处理完成后,若需要返回响应,调用
send发送数据;若连接保持(长连接),则重新监听读事件。
流程图与状态机
从状态机负责读取报文的一行,主状态机负责对该行数据进行解析,主状态机内部调用从状态机,从状态机驱动主状态机。
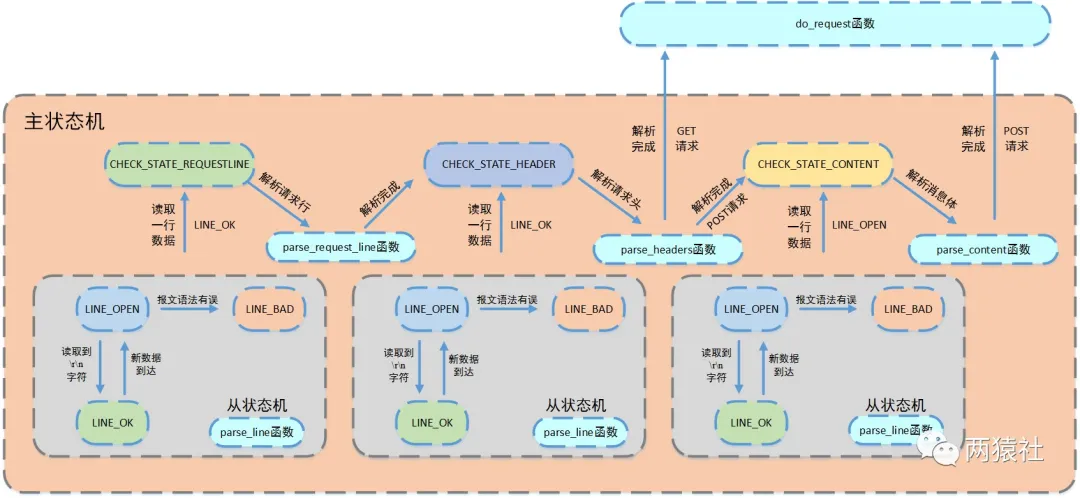
主状态机
三种状态,标识解析位置。
CHECK_STATE_REQUESTLINE,解析请求行
CHECK_STATE_HEADER,解析请求头
CHECK_STATE_CONTENT,解析消息体,仅用于解析POST请求
从状态机
三种状态,标识解析一行的读取状态。
LINE_OK,完整读取一行
LINE_BAD,报文语法有误
LINE_OPEN,读取的行不完整
代码分析-http报文解析
上面中介绍了服务器接收http请求的流程与细节,简单来讲,浏览器端发出http连接请求,服务器端主线程创建http对象接收请求并将所有数据读入对应buffer,将该对象插入任务队列后,工作线程从任务队列中取出一个任务进行处理。
各子线程通过process函数对任务进行处理,调用process_read函数和process_write函数分别完成报文解析与报文响应两个任务。
void http_conn::process()
{
HTTP_CODE read_ret = process_read();
// NO_REQUEST,表示请求不完整,需要继续接收请求数据
if (read_ret == NO_REQUEST)
{
// 注册并监听读事件(等待客户端继续发送数据)
modfd(m_epollfd, m_sockfd, EPOLLIN);
return;
}
// 调用process_write完成报文响应(根据读取结果生成响应并发送)
bool write_ret = process_write(read_ret);
if (!write_ret)
{
close_conn(); // 响应发送失败,关闭连接
}
// 注册并监听写事件(可能用于后续持续发送数据,如分块传输)
modfd(m_epollfd, m_sockfd, EPOLLOUT);
}HTTP_CODE含义
表示HTTP请求的处理结果,在头文件中初始化了八种情形,在报文解析与响应中只用到了七种。
NO_REQUEST
请求不完整,需要继续读取请求报文数据
跳转主线程继续监测读事件
GET_REQUEST
获得了完整的HTTP请求
调用do_request完成请求资源映射
NO_RESOURCE
请求资源不存在
跳转process_write完成响应报文
BAD_REQUEST
HTTP请求报文有语法错误或请求资源为目录
跳转process_write完成响应报文
FORBIDDEN_REQUEST
请求资源禁止访问,没有读取权限
跳转process_write完成响应报文
FILE_REQUEST
请求资源可以正常访问
跳转process_write完成响应报文
INTERNAL_ERROR
服务器内部错误,该结果在主状态机逻辑switch的default下,一般不会触发
解析报文整体流程
process_read通过while循环,将主从状态机进行封装,对报文的每一行进行循环处理。
判断条件
主状态机转移到CHECK_STATE_CONTENT,该条件涉及解析消息体
从状态机转移到LINE_OK,该条件涉及解析请求行和请求头部
两者为或关系,当条件为真则继续循环,否则退出
循环体
从状态机读取数据
调用get_line函数,通过m_start_line将从状态机读取数据间接赋给text
主状态机解析text
//_start_line是行在buffer中的起始位置,将该位置后面的数据赋给text
//此时从状态机已提前将一行的末尾字符\r\n变为\0\0,所以text可以直接取出完整的行进行解析
char* get_line(){
return m_read_buf+m_start_line;
}
http_conn::HTTP_CODE http_conn::process_read()
{
//初始化从状态机状态、HTTP请求解析结果
LINE_STATUS line_status=LINE_OK;
HTTP_CODE ret=NO_REQUEST;
char* text=0;
//这里为什么要写两个判断条件?第一个判断条件为什么这样写?
//具体的在主状态机逻辑中会讲解。
//parse_line为从状态机的具体实现
while((m_check_state==CHECK_STATE_CONTENT && line_status==LINE_OK)||((line_status=parse_line())==LINE_OK))
{
text=get_line();
//_start_line是每一个数据行在m_read_buf中的起始位置
//m_checked_idx表示从状态机在m_read_buf中读取的位置
m_start_line=m_checked_idx;
//主状态机的三种状态转移逻辑
switch(m_check_state)
{
case CHECK_STATE_REQUESTLINE:
{
//解析请求行
ret=parse_request_line(text);
if(ret==BAD_REQUEST)
return BAD_REQUEST;
break;
}
case CHECK_STATE_HEADER:
{
//解析请求头
ret=parse_headers(text);
if(ret==BAD_REQUEST)
return BAD_REQUEST;
//完整解析GET请求后,跳转到报文响应函数
else if(ret==GET_REQUEST)
{
return do_request();
}
break;
}
case CHECK_STATE_CONTENT:
{
//解析消息体
ret=parse_content(text);
//完整解析POST请求后,跳转到报文响应函数
if(ret==GET_REQUEST)
return do_request();
//解析完消息体即完成报文解析,避免再次进入循环,更新line_status
line_status=LINE_OPEN;
break;
}
default:
return INTERNAL_ERROR;
}
}
return NO_REQUEST;
}《process_read 方法》:读取数据后的状态机解析
功能
驱动状态机逐行解析读取缓冲区中的HTTP请求数据(请求行→请求头→消息体),根据解析结果更新状态或生成响应。
核心流程与关键逻辑
1. 初始化状态变量
LINE_STATUS line_status = LINE_OK; // 从状态机状态(行解析状态)
HTTP_CODE ret = NO_REQUEST; // 主状态机返回值(请求解析结果)
char* text = 0; // 当前行的文本指针LINE_STATUS:从状态机状态,标识当前行的解析状态(如LINE_OK表示行完整,LINE_OPEN表示行未闭合)。HTTP_CODE:主状态机状态,标识HTTP请求的整体解析进度(如NO_REQUEST表示未完成,GET_REQUEST表示请求完成)。
2. 循环解析行数据
while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) ||
((line_status = parse_line()) == LINE_OK))循环条件解析:
第一部分:
m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK
当主状态机处于CHECK_STATE_CONTENT(消息体解析状态)时,只要从状态机还能提取完整行(LINE_OK),就继续解析消息体(适用于POST请求的长消息体)。第二部分:
((line_status = parse_line()) == LINE_OK)
其他状态(请求行/请求头解析)下,每次循环先调用parse_line提取新的一行(更新line_status),若提取成功(LINE_OK)则继续解析。
设计意图:
- 请求行/请求头是固定格式的短数据(每行一个字段),需逐行解析;
- 消息体(如POST的表单数据)可能很长,需持续解析直到无更多数据(
LINE_OPEN表示未闭合)。
3. 提取当前行文本
text = get_line(); // 获取当前行的起始地址(已替换\r\n为\0\0)通过get_line获取当前行的文本指针,由于\r\n已被替换为\0\0,text可直接作为字符串使用(如strncasecmp)。
4. 更新状态机位置
m_start_line = m_checked_idx; // 记录当前行的起始位置(供下一次循环使用)m_checked_idx是从状态机已处理到的缓冲区位置,将其赋值给m_start_line,确保下一次循环时get_line能正确定位到下一行的起始位置。
5. 主状态机状态转移(核心解析逻辑)
根据m_check_state(主状态机当前状态),调用对应的解析函数处理当前行:
(1) CHECK_STATE_REQUESTLINE:解析请求行
case CHECK_STATE_REQUESTLINE:
{
ret = parse_request_line(text); // 解析请求行(提取方法、URL、版本)
if (ret == BAD_REQUEST) return BAD_REQUEST; // 解析失败,返回错误
break;
}- 调用
parse_request_line解析请求行(如GET /index.html HTTP/1.1\r\n); - 若解析失败(如格式错误),直接返回
BAD_REQUEST; - 解析成功后,主状态机自动进入下一步(由
parse_request_line设置m_check_state = CHECK_STATE_HEADER)。
(2) CHECK_STATE_HEADER:解析请求头
case CHECK_STATE_HEADER:
{
ret = parse_headers(text); // 解析请求头(提取Connection、Content-length等)
if (ret == BAD_REQUEST) return BAD_REQUEST; // 解析失败,返回错误
else if (ret == GET_REQUEST) return do_request(); // GET请求解析完成,生成响应
break;
}- 调用
parse_headers解析请求头(如Host: www.example.com\r\nContent-length: 1024\r\n); - 若解析失败(如未知头部),返回
BAD_REQUEST; - 若为GET请求且解析完成(
ret == GET_REQUEST),调用do_request生成响应(无需处理消息体); - 若为POST请求,继续等待消息体(
m_check_state仍为CHECK_STATE_HEADER,直到Content-length指定长度的数据读取完成)。
(3) CHECK_STATE_CONTENT:解析消息体
case CHECK_STATE_CONTENT:
{
ret = parse_content(text); // 解析消息体(提取POST表单数据等)
if (ret == GET_REQUEST) return do_request(); // POST消息体解析完成,生成响应
line_status = LINE_OPEN; // 标记消息体未闭合,继续解析
break;
}- 调用
parse_content解析消息体(根据Content-length读取指定长度的数据); - 若消息体解析完成(
ret == GET_REQUEST),调用do_request生成响应; - 若消息体未完全读取(如长数据分多次到达),设置
line_status = LINE_OPEN,保持循环继续解析。
(4) 默认情况
default:
return INTERNAL_ERROR; // 未知状态,返回内部错误从状态机逻辑
上一篇的基础知识讲解中,对于HTTP报文的讲解遗漏了一点细节,在这里作为补充。
在HTTP报文中,每一行的数据由\r\n作为结束字符,空行则是仅仅是字符\r\n。因此,可以通过查找\r\n将报文拆解成单独的行进行解析,项目中便是利用了这一点。
从状态机负责读取buffer中的数据,将每行数据末尾的\r\n置为\0\0,并更新从状态机在buffer中读取的位置m_checked_idx,以此来驱动主状态机解析。
从状态机从m_read_buf中逐字节读取,判断当前字节是否为\r
接下来的字符是\n,将\r\n修改成\0\0,将m_checked_idx指向下一行的开头,则返回LINE_OK
接下来达到了buffer末尾,表示buffer还需要继续接收,返回LINE_OPEN
否则,表示语法错误,返回LINE_BAD
当前字节不是\r,判断是否是\n(一般是上次读取到\r就到了buffer末尾,没有接收完整,再次接收时会出现这种情况)
如果前一个字符是\r,则将\r\n修改成\0\0,将m_checked_idx指向下一行的开头,则返回LINE_OK
当前字节既不是\r,也不是\n
表示接收不完整,需要继续接收,返回LINE_OPEN
主状态机逻辑
主状态机初始状态是CHECK_STATE_REQUESTLINE,通过调用从状态机来驱动主状态机,在主状态机进行解析前,从状态机已经将每一行的末尾\r\n符号改为\0\0,以便于主状态机直接取出对应字符串进行处理。
CHECK_STATE_REQUESTLINE
主状态机的初始状态,调用parse_request_line函数解析请求行
解析函数从m_read_buf中解析HTTP请求行,获得请求方法、目标URL及HTTP版本号
解析完成后主状态机的状态变为CHECK_STATE_HEADER
// 解析HTTP请求行,获得请求方法、目标URL及HTTP版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{
// 在HTTP报文中,请求行格式为:方法 URL 版本\r\n,各部分由空格或制表符分隔
// 使用strpbrk查找第一个空格或制表符的位置,用于分割方法和URL
m_url = strpbrk(text, " \t");
// 若未找到分隔符(m_url为NULL),说明请求行格式错误(缺少方法与URL的分隔)
if (!m_url)
{
return BAD_REQUEST;
}
// 将分隔符位置替换为'\0',使text到m_url(不包含)形成独立的请求方法字符串
*m_url++ = '\0';
// 提取请求方法(text指向方法的起始位置)
char *method = text;
if (strcasecmp(method, "GET") == 0)
m_method = GET; // 方法为GET
else if (strcasecmp(method, "POST") == 0)
{
m_method = POST; // 方法为POST
cgi = 1; // 标记需要CGI处理(POST通常用于表单或动态内容)
}
else
return BAD_REQUEST; // 不支持的方法,返回错误
// 跳过URL前的空格和制表符(HTTP请求行中URL与方法间可能有多个空白)
m_url += strspn(m_url, " \t");
// 提取HTTP版本号:查找URL与版本间的分隔符(空格或制表符)
m_version = strpbrk(m_url, " \t");
if (!m_version)
return BAD_REQUEST; // 未找到版本分隔符,格式错误
// 将分隔符位置替换为'\0',使m_url到m_version(不包含)形成独立的URL字符串
*m_version++ = '\0';
// 跳过版本号前的空格和制表符(版本与URL间可能有多个空白)
m_version += strspn(m_version, " \t");
// 仅支持HTTP/1.1协议,其他版本返回错误
if (strcasecmp(m_version, "HTTP/1.1") != 0)
return BAD_REQUEST;
// 处理URL中的协议前缀(如http://或https://)
// 若URL以"http://"开头(前7字符匹配),跳过该前缀
if (strncasecmp(m_url, "http://", 7) == 0)
{
m_url += 7; // 移动指针到协议前缀之后
m_url = strchr(m_url, '/'); // 查找第一个'/',定位资源路径起点
}
// 若URL以"https://"开头(前8字符匹配),跳过该前缀
else if (strncasecmp(m_url, "https://", 8) == 0)
{
m_url += 8; // 移动指针到协议前缀之后
m_url = strchr(m_url, '/'); // 查找第一个'/',定位资源路径起点
}
// 若URL处理后为空或不以'/'开头(如无资源路径),格式错误
if (!m_url || m_url[0] != '/')
return BAD_REQUEST;
// 当URL为根路径"/"时,默认映射到欢迎页面"judge.html"
if (strlen(m_url) == 1)
strcat(m_url, "judge.html");
// 请求行解析完成,主状态机转移到请求头解析状态
m_check_state = CHECK_STATE_HEADER;
return NO_REQUEST; // 返回"请求未完成"(需继续解析请求头)
}《parse_request_line 函数》:解析HTTP请求行
功能
解析HTTP请求的第一行(请求行),提取请求方法(GET/POST)、目标URL和HTTP版本号,并根据解析结果设置状态机状态(转移到请求头解析)。
关键逻辑步骤
分割方法与URL:
使用strpbrk(text, " \t")找到请求行中第一个空格或制表符的位置(m_url),将其替换为\0,使text指向请求方法(如GET)。识别请求方法:
- 若方法为
GET,设置m_method=GET; - 若为
POST,设置m_method=POST并标记cgi=1(需CGI处理动态内容); - 否则返回
BAD_REQUEST(不支持的方法)。
- 若方法为
提取并清洗URL:
- 跳过URL前的空格/制表符(
strspn(m_url, " \t")); - 处理URL中的协议前缀(如
http://或https://),跳过前缀后定位到资源路径(以/开头); - 若URL格式错误(无
/或为空),返回BAD_REQUEST。
- 跳过URL前的空格/制表符(
验证HTTP版本:
仅支持HTTP/1.1,否则返回BAD_REQUEST。状态转移:
解析完成后,状态机转移到CHECK_STATE_HEADER(开始解析请求头)。
解析完请求行后,主状态机继续分析请求头。在报文中,请求头和空行的处理使用的同一个函数,这里通过判断当前的text首位是不是\0字符,若是,则表示当前处理的是空行,若不是,则表示当前处理的是请求头。
CHECK_STATE_HEADER
调用parse_headers函数解析请求头部信息
判断是空行还是请求头,若是空行,进而判断content-length是否为0,如果不是0,表明是POST请求,则状态转移到CHECK_STATE_CONTENT,否则说明是GET请求,则报文解析结束。
若解析的是请求头部字段,则主要分析connection字段,content-length字段,其他字段可以直接跳过,各位也可以根据需求继续分析。
connection字段判断是keep-alive还是close,决定是长连接还是短连接
content-length字段,这里用于读取post请求的消息体长度
// 解析HTTP请求的一个头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char *text)
{
// 判断当前行是否为空行(HTTP请求头以空行\r\n结束)
if (text[0] == '\0')
{
// 空行出现,说明请求头解析完成
// 如果是POST请求(m_content_length不为0),需要跳转到消息体处理状态
if (m_content_length != 0)
{
m_check_state = CHECK_STATE_CONTENT; // 状态转移到消息体解析
return NO_REQUEST; // 返回"请求未完成"(需继续读取消息体)
}
// 如果是GET请求(无消息体),直接返回请求完成标志
return GET_REQUEST;
}
// 解析请求头部字段(格式为:字段名: 值\r\n)
// 处理Connection字段(控制连接是否保持)
else if (strncasecmp(text, "Connection:", 11) == 0)
{
text += 11; // 移动指针到字段值的起始位置(跳过"Connection:")
// 跳过字段值前的空格和制表符(如" keep-alive"中的空格)
text += strspn(text, " \t");
// 检查是否为长连接(keep-alive)
if (strcasecmp(text, "keep-alive") == 0)
{
m_linger = true; // 标记为长连接(后续读取数据时不立即关闭套接字)
}
}
// 处理Content-length字段(指定消息体长度,仅POST请求可能有)
else if (strncasecmp(text, "Content-length:", 15) == 0)
{
text += 15; // 移动指针到字段值的起始位置(跳过"Content-length:")
// 跳过字段值前的空格和制表符(如" 1024"中的空格)
text += strspn(text, " \t");
// 将字段值转换为长整型,记录消息体长度(用于后续读取消息体)
m_content_length = atol(text);
}
// 处理Host字段(指定请求的目标主机,HTTP/1.1必须包含)
else if (strncasecmp(text, "Host:", 5) == 0)
{
text += 5; // 移动指针到字段值的起始位置(跳过"Host:")
// 跳过字段值前的空格和制表符(如" www.example.com"中的空格)
text += strspn(text, " \t");
// 记录目标主机名(用于后续日志、路由或虚拟主机处理)
m_host = text;
}
// 未知的请求头字段(实际应用中可扩展处理,如忽略或记录警告)
else
{
printf("Oops unknown header: %s\n", text); // 打印未知头信息(调试用)
}
// 请求头解析未完成(继续解析下一行)
return NO_REQUEST;
}
```《parse_headers 函数》:解析HTTP请求头
功能
解析HTTP请求头(多行键值对,以空行\r\n结束),提取关键头部字段(如连接类型、内容长度、主机名),并根据解析结果更新连接状态或准备消息体处理。
关键逻辑步骤
空行判断(请求头结束):
若当前行为空(text[0]='\0'),说明请求头解析完成:- 若
m_content_length>0(POST请求有消息体),状态机转移到CHECK_STATE_CONTENT(准备解析消息体); - 否则(GET请求无消息体),返回
GET_REQUEST(请求解析完成,可生成响应)。
- 若
解析关键头部字段:
- Connection字段:若值为
keep-alive,设置m_linger=true(长连接,不立即关闭套接字); - Content-length字段:提取消息体长度(
m_content_length=atol(text)),用于后续读取消息体; - Host字段:记录目标主机名(
m_host=text),HTTP/1.1强制要求; - 未知头部字段:打印日志(调试用途)。
- Connection字段:若值为
状态保持:
若仍有未解析的头部字段,返回NO_REQUEST(继续解析下一行)。
如果仅仅是GET请求,如项目中的欢迎界面,那么主状态机只设置之前的两个状态足矣。
GET和POST请求报文的区别之一是有无消息体部分,GET请求没有消息体,当解析完空行之后,便完成了报文的解析。
但后续的登录和注册功能,为了避免将用户名和密码直接暴露在URL中,我们在项目中改用了POST请求,将用户名和密码添加在报文中作为消息体进行了封装。
为此,我们需要在解析报文的部分添加解析消息体的模块。
代码分析
do_request
process_read函数的返回值是对请求的文件分析后的结果,一部分是语法错误导致的BAD_REQUEST,一部分是do_request的返回结果.该函数将网站根目录和url文件拼接,然后通过stat判断该文件属性。另外,为了提高访问速度,通过mmap进行映射,将普通文件映射到内存逻辑地址。
为了更好的理解请求资源的访问流程,这里对各种各页面跳转机制进行简要介绍。其中,浏览器网址栏中的字符,即url,可以将其抽象成ip:port/xxx,xxx通过html文件的action属性进行设置。
m_url为请求报文中解析出的请求资源,以/开头,也就是/xxx,项目中解析后的m_url有8种情况。
/
GET请求,跳转到judge.html,即欢迎访问页面
/0
POST请求,跳转到register.html,即注册页面
/1
POST请求,跳转到log.html,即登录页面
/2CGISQL.cgi
POST请求,进行登录校验
验证成功跳转到welcome.html,即资源请求成功页面
验证失败跳转到logError.html,即登录失败页面
/3CGISQL.cgi
POST请求,进行注册校验
注册成功跳转到log.html,即登录页面
注册失败跳转到registerError.html,即注册失败页面
/5
POST请求,跳转到picture.html,即图片请求页面
/6
POST请求,跳转到video.html,即视频请求页面
/7
POST请求,跳转到fans.html,即关注页面
const char* doc_root="/home/qgy/github/ini_tinywebserver/root";
http_conn::HTTP_CODE http_conn::do_request()
{
strcpy(m_real_file,doc_root);
int len=strlen(doc_root);
const char *p = strrchr(m_url, '/');
if(cgi==1 && (*(p+1) == '2' || *(p+1) == '3'))
{
}
if(*(p+1) == '0'){
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real,"/register.html");
strncpy(m_real_file+len,m_url_real,strlen(m_url_real));
free(m_url_real);
}
else if( *(p+1) == '1'){
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real,"/log.html");
strncpy(m_real_file+len,m_url_real,strlen(m_url_real));
free(m_url_real);
}
else
strncpy(m_real_file+len,m_url,FILENAME_LEN-len-1);
if(stat(m_real_file,&m_file_stat)<0)
return NO_RESOURCE;
if(!(m_file_stat.st_mode&S_IROTH))
return FORBIDDEN_REQUEST;
if(S_ISDIR(m_file_stat.st_mode))
return BAD_REQUEST;
int fd=open(m_real_file,O_RDONLY);
m_file_address=(char*)mmap(0,m_file_stat.st_size,PROT_READ,MAP_PRIVATE,fd,0);
close(fd);
return FILE_REQUEST;
}
process_write
根据do_request的返回状态,服务器子线程调用process_write向m_write_buf中写入响应报文。
add_status_line函数,添加状态行:http/1.1 状态码 状态消息
add_headers函数添加消息报头,内部调用add_content_length和add_linger函数
content-length记录响应报文长度,用于浏览器端判断服务器是否发送完数据
connection记录连接状态,用于告诉浏览器端保持长连接
add_blank_line添加空行
上述涉及的5个函数,均是内部调用add_response函数更新m_write_idx指针和缓冲区m_write_buf中的内容。
bool http_conn::add_response(const char* format,...)
{
//如果写入内容超出m_write_buf大小则报错
if(m_write_idx>=WRITE_BUFFER_SIZE)
return false;
//定义可变参数列表
va_list arg_list;
//将变量arg_list初始化为传入参数
va_start(arg_list,format);
//将数据format从可变参数列表写入缓冲区写,返回写入数据的长度
int len=vsnprintf(m_write_buf+m_write_idx,WRITE_BUFFER_SIZE-1-m_write_idx,format,arg_list);
//如果写入的数据长度超过缓冲区剩余空间,则报错
if(len>=(WRITE_BUFFER_SIZE-1-m_write_idx)){
va_end(arg_list);
return false;
}
//更新m_write_idx位置
m_write_idx+=len;
//清空可变参列表
va_end(arg_list);
return true;
}
//添加状态行
bool http_conn::add_status_line(int status,const char* title)
{
return add_response("%s %d %s\r\n","HTTP/1.1",status,title);
}
//添加消息报头,具体的添加文本长度、连接状态和空行
bool http_conn::add_headers(int content_len)
{
add_content_length(content_len);
add_linger();
add_blank_line();
}
//添加Content-Length,表示响应报文的长度
bool http_conn::add_content_length(int content_len)
{
return add_response("Content-Length:%d\r\n",content_len);
}
//添加文本类型,这里是html
bool http_conn::add_content_type()
{
return add_response("Content-Type:%s\r\n","text/html");
}
//添加连接状态,通知浏览器端是保持连接还是关闭
bool http_conn::add_linger()
{
return add_response("Connection:%s\r\n",(m_linger==true)?"keep-alive":"close");
}
//添加空行
bool http_conn::add_blank_line()
{
return add_response("%s","\r\n");
}
//添加文本content
bool http_conn::add_content(const char* content)
{
return add_response("%s",content);
}
响应报文分为两种,一种是请求文件的存在,通过io向量机制iovec,声明两个iovec,第一个指向m_write_buf,第二个指向mmap的地址m_file_address;一种是请求出错,这时候只申请一个iovec,指向m_write_buf。
iovec是一个结构体,里面有两个元素,指针成员iov_base指向一个缓冲区,这个缓冲区是存放的是writev将要发送的数据。
成员iov_len表示实际写入的长度
bool http_conn::process_write(HTTP_CODE ret)
{
switch(ret)
{
case INTERNAL_ERROR:
{
add_status_line(500,error_500_title);
add_headers(strlen(error_500_form));
if(!add_content(error_500_form))
return false;
break;
}
case BAD_REQUEST:
{
add_status_line(404,error_404_title);
add_headers(strlen(error_404_form));
if(!add_content(error_404_form))
return false;
break;
}
case FORBIDDEN_REQUEST:
{
add_status_line(403,error_403_title);
add_headers(strlen(error_403_form));
if(!add_content(error_403_form))
return false;
break;
}
case FILE_REQUEST:
{
add_status_line(200,ok_200_title);
if(m_file_stat.st_size!=0)
{
add_headers(m_file_stat.st_size);
m_iv[0].iov_base=m_write_buf;
m_iv[0].iov_len=m_write_idx;
m_iv[1].iov_base=m_file_address;
m_iv[1].iov_len=m_file_stat.st_size;
m_iv_count=2;
bytes_to_send = m_write_idx + m_file_stat.st_size;
return true;
}
else
{
const char* ok_string="<html><body></body></html>";
add_headers(strlen(ok_string));
if(!add_content(ok_string))
return false;
}
}
default:
return false;
}
m_iv[0].iov_base=m_write_buf;
m_iv[0].iov_len=m_write_idx;
m_iv_count=1;
return true;
}
http_conn::write
服务器子线程调用process_write完成响应报文,随后注册epollout事件。服务器主线程检测写事件,并调用http_conn::write函数将响应报文发送给浏览器端。
该函数具体逻辑如下:
在生成响应报文时初始化byte_to_send,包括头部信息和文件数据大小。通过writev函数循环发送响应报文数据,根据返回值更新byte_have_send和iovec结构体的指针和长度,并判断响应报文整体是否发送成功。
若writev单次发送成功,更新byte_to_send和byte_have_send的大小,若响应报文整体发送成功,则取消mmap映射,并判断是否是长连接.
长连接重置http类实例,注册读事件,不关闭连接,
短连接直接关闭连接
若writev单次发送不成功,判断是否是写缓冲区满了。
若不是因为缓冲区满了而失败,取消mmap映射,关闭连接
若eagain则满了,更新iovec结构体的指针和长度,并注册写事件,等待下一次写事件触发(当写缓冲区从不可写变为可写,触发epollout),因此在此期间无法立即接收到同一用户的下一请求,但可以保证连接的完整性。
bool http_conn::write()
{
int temp = 0;
int newadd = 0;
//若要发送的数据长度为0
//表示响应报文为空,一般不会出现这种情况
if(bytes_to_send==0)
{
modfd(m_epollfd,m_sockfd,EPOLLIN);
init();
return true;
}
while (1)
{
//将响应报文的状态行、消息头、空行和响应正文发送给浏览器端
temp=writev(m_sockfd,m_iv,m_iv_count);
//正常发送,temp为发送的字节数
if (temp > 0)
{
//更新已发送字节
bytes_have_send += temp;
//偏移文件iovec的指针
newadd = bytes_have_send - m_write_idx;
}
if (temp <= -1)
{
//判断缓冲区是否满了
if (errno == EAGAIN)
{
//第一个iovec头部信息的数据已发送完,发送第二个iovec数据
if (bytes_have_send >= m_iv[0].iov_len)
{
//不再继续发送头部信息
m_iv[0].iov_len = 0;
m_iv[1].iov_base = m_file_address + newadd;
m_iv[1].iov_len = bytes_to_send;
}
//继续发送第一个iovec头部信息的数据
else
{
m_iv[0].iov_base = m_write_buf + bytes_to_send;
m_iv[0].iov_len = m_iv[0].iov_len - bytes_have_send;
}
//重新注册写事件
modfd(m_epollfd, m_sockfd, EPOLLOUT);
return true;
}
//如果发送失败,但不是缓冲区问题,取消映射
unmap();
return false;
}
//更新已发送字节数
bytes_to_send -= temp;
//判断条件,数据已全部发送完
if (bytes_to_send <= 0)
{
unmap();
//在epoll树上重置EPOLLONESHOT事件
modfd(m_epollfd,m_sockfd,EPOLLIN);
//浏览器的请求为长连接
if(m_linger)
{
//重新初始化HTTP对象
init();
return true;
}
else
{
return false;
}
}
}
}