背景:
上期文章主要讲了Flink项目搭建的一些方法,其中对于数据流的处理很大一部分是通过算子来进行计算和处理的,算子也是Flink中功能非常庞大,且很重要的一部分。
算子介绍:
算子在Flink的开发者文档中是这样介绍的:通过算子能将一个或多个 DataStream 转换成新的 DataStream,在应用程序中可以将多个数据转换算子合并成一个复杂的数据流拓扑。这简单总结就有点类似于Flink的一些API,来对数据流进行操作处理。
算子介绍目录:
主要介绍几个在日常开发中,比较常用的几个算子方法:
1.FlatMap
2.Filter
3.Window
4.join
5.coGroup
1.FlatMap
flatMap是输入一个元素同时产生零个、一个或多个元素。通常在日常开发中用于对于数据流的初步处理和合并,将数据流转换成我们希望输入的数据格式
方法举例:
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out)
throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});
日常使用举例:
/// 将binglog获取的dataChangInfo格式转换成OrderInfo业务格式
dataStream1.flatMap(new FlatMapFunction<DataChangeInfo, OrderInfo>() {
@Override
public void flatMap(DataChangeInfo dataChangeInfo, Collector<OrderInfo> collector) throws Exception {
OrderInfo orderInfo = JSONObject.parseObject(dataChangeInfo.getAfterData(), OrderInfo.class);
log.info("订单数据:{}", orderInfo);
collector.collect(orderInfo);
}
});
2.Filter
对数据流进行过滤操作,将一些脏数据或者我们不希望流入的数据进行排除处理
使用举例:
/// 筛选出订单状态小于等于40的订单数据
orderInfoSingleOutputStream.filter(new FilterFunction<OrderInfo>() {
@Override
public boolean filter(OrderInfo orderInfo) throws Exception {
if (orderInfo.getStatus() <= 40){
return true;
}
return false;
}
});
3.Window
Window 根据某些特征(例如,最近 5 秒内到达的数据)对每个 key Stream 中的数据进行分组。就类似于上期文章所讲述的窗口,具体介绍可以查看上期文章「Flink」Flink项目搭建方法介绍;
/// 先通过keyby设置主键
/// 然后设置一个以事件时间为标定,设一个5秒的窗口
dataStream
.keyBy(value -> value.f0)
.window(TumblingEventTimeWindows.of(Duration.ofSeconds(5)));
4.Join
根据指定的 key 和窗口 join 两个数据流。
这个方法通常用在两个数据流需要通过某个key值进行合并的时候,比如订单主表和订单副表需要通过orderId进行数据合并的时候,进行数据处理。
方法举例:
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Duration.ofSeconds(3)))
.apply (new JoinFunction () {...});
日常使用举例:
DataStream<OrderOutputInfo> outputInfoDataStream = orderInfoSingleOutputStream
.join(orderCodeInfoSingleOutputStream)
.where(OrderInfo::getId)
.equalTo(OrderCodeInfo::getId)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.apply(new JoinFunction<OrderInfo, OrderCodeInfo, OrderOutputInfo>() {
@Override
public OrderOutputInfo join(OrderInfo orderInfo, OrderCodeInfo orderCodeInfo) throws Exception {
OrderOutputInfo orderOutputInfo = new OrderOutputInfo();
orderOutputInfo.setId(orderInfo.getId());
orderOutputInfo.setStatus(orderInfo.getStatus());
orderOutputInfo.setCode(orderCodeInfo.getCode());
orderOutputInfo.setCreate_time(orderInfo.getCreate_time());
log.info("输出数据:{}", orderOutputInfo);
return orderOutputInfo;
}
});

通过断点,其实可以发现,数据并不是按照一批一批进行输出的,而是根据key,进行一条一条的输出的,这个需要注意写入库的方法,以免对数据库写入产生较大的压力。
然后该方法会发现一个弊端,那就是如果不在事件窗口期输入的,那么无法匹配到对应的数据行,那么就会出现数据无法输出,数据丢失的情况,使用outside,官方推荐的侧输出,也无法有效输出,这时候比较推荐下面这个方法Cogroup,可以通过自定义的方法进行对未匹配的数据进行输出报错;
5.CoGroup
根据指定的 key 和窗口将两个数据流组合在一起。
CoGroup和Join是个类似的方法,但是CoGroup的数据处理方法里面可以有迭代器,然后在实际数据处理过程中可以通过判断迭代器,从而实现对于未匹配成功的订单进行打印输出。
方法举例:
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Duration.ofSeconds(3)))
.apply (new CoGroupFunction () {...});
日常使用举例:
orderInfoSingleOutputStream.coGroup(orderCodeInfoSingleOutputStream)
.where(OrderInfo::getId)
.equalTo(OrderCodeInfo::getId)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.apply(new CoGroupFunction<OrderInfo, OrderCodeInfo, OrderOutputInfo>() {
@Override
public void coGroup(Iterable<OrderInfo> iterable, Iterable<OrderCodeInfo> iterable1, Collector<OrderOutputInfo> collector) throws Exception {
if(iterable.iterator().hasNext() && iterable1.iterator().hasNext()){
OrderInfo orderInfo = iterable.iterator().next();
OrderCodeInfo orderCodeInfo = iterable1.iterator().next();
System.out.println("匹配成功的订单ID:" + orderInfo.getId() + " 订单创建时间:" + orderInfo.getCreate_time() + " status " + orderInfo.getStatus());
System.out.println("=============================");
OrderOutputInfo orderOutputInfo = new OrderOutputInfo();
orderOutputInfo.setId(orderInfo.getId());
orderOutputInfo.setStatus(orderInfo.getStatus());
orderOutputInfo.setCode(orderCodeInfo.getCode());
orderOutputInfo.setCreate_time(orderInfo.getCreate_time());
collector.collect(orderOutputInfo);
}else if(iterable.iterator().hasNext() && !iterable1.iterator().hasNext()){
OrderInfo order = iterable.iterator().next();
System.out.println("订单未找到匹配的订单-----------Code:"+ order.getId());
} else if(!iterable.iterator().hasNext() && iterable1.iterator().hasNext()){
OrderCodeInfo orderCodeInfo = iterable1.iterator().next();
System.out.println("未找到匹配的Code订单-----------Code:" + orderCodeInfo.getId() );
}
}
});
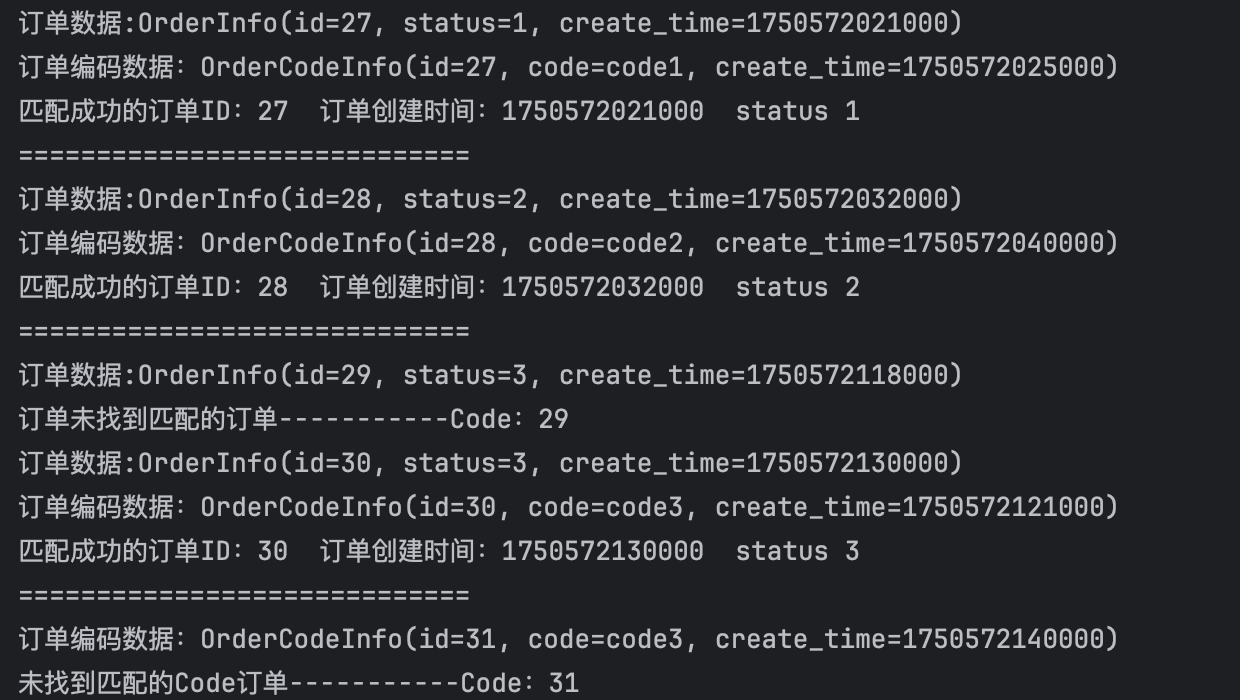
数据输出日志:
可以看到数据也是一条条匹配后输出,无法匹配的数据也会在窗口结束后进行输出展示或告警。
总结:
以上几个算子方法就是平时日常开发中比较常用且好用的方法,大家可以结合各自的业务场景,进行挑选使用。