Word文档合并工具解析
一 应用场景

Word文档合并适用于以下典型场景:
- 批量报告生成:将多个部门/人员的报告合并成一份完整文档
- 文档归档:将分散的文档章节合并为完整手册
- 合同管理:合并多个合同附件或条款文档
- 教学资料整合:将分散的课件合并为完整教材
二 实现思路
该工具采用"分块插入"技术实现文档合并,核心思路是:
- 将每个输入文档作为独立块(Chunk)处理
- 使用docx4j的CTAltChunk机制将这些块插入主文档
- 保持原始文档格式不变,避免格式冲突
三 实现分析
环境搭建
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j</artifactId>
<version>6.1.0</version>
</dependency>
docx4j介绍
docx4j 库是一款功能强大且极具灵活性的开源 Java 库,专为处理 Microsoft Office Word 文档而设计,其核心优势在于无需安装 Microsoft Office,即可实现对 Word 文档的高效操作。本章将为您介绍 docx4j 库的基本信息,以及它所能实现的核心功能。docx4j 的显著特点如下:
纯 Java实现:完全基于 Java 开发,可轻松部署于服务器或无界面环境,适配多种运行场景。
丰富 API支持:提供了一系列完备的 API,让开发者能够便捷地完成 Word 文档的创建、编辑、转换及内容提取等操作。
遵循 OpenXML标准:严格支持 Open XML 标准,不仅保障了文档在不同平台和软件间的兼容性,还为功能扩展提供了坚实基础。
1. 核心类结构
public class MergeWordDocuments {
// 主入口方法
public static void main(String[] args) {...}
// 文件处理流程控制
public static void saveMergeDoc(String path, String savePath, String fileName) {...}
// 文档合并核心逻辑
public static void mergeDoc(List<String> wordList, OutputStream out) {...}
private static void mergeDocStream(...) {...}
private static void insertDoc(...) {...}
// 输出处理
private static void saveTemplate(...) {...}
}
2. 关键技术点
docx4j库:专业处理Office Open XML格式文档
AlternativeFormatInputPart:表示要插入的文档部分
CTAltChunk:Word文档中的"外部内容引用"机制
临时文件处理:使用临时文件作为中间存储
3. 实现逻辑
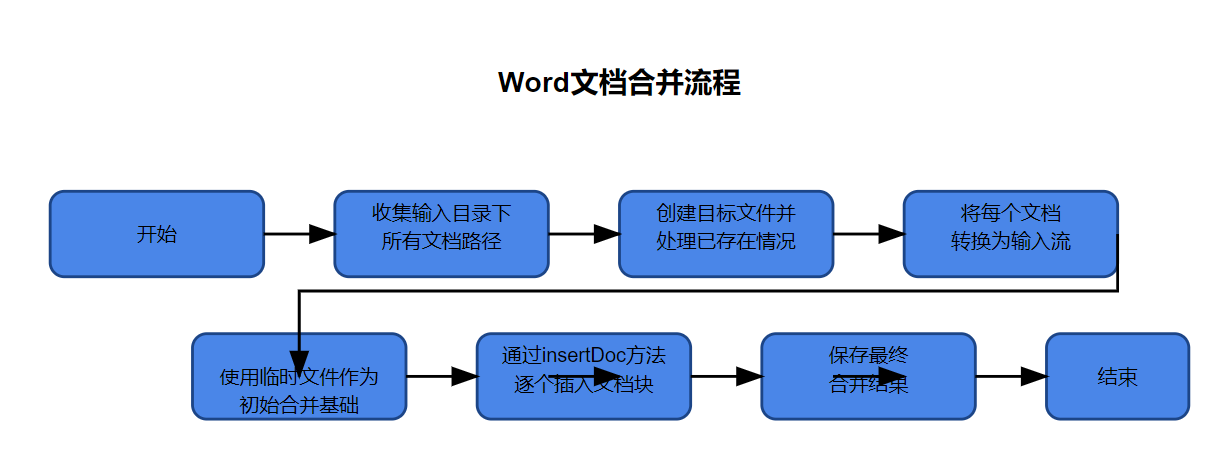
- 收集输入目录下所有文档路径
- 创建目标文件并处理已存在情况
- 将每个文档转换为输入流
- 使用临时文件作为初始合并基础
- 通过insertDoc方法逐个插入文档块
- 保存最终合并结果
4.代码实现
核心合并方法
private static void insertDoc(MainDocumentPart mainDocumentPart, byte[] bytes, int chunkId) {
try {
PartName partName = new PartName("/part" + chunkId + ".docx");
AlternativeFormatInputPart afiPart = new AlternativeFormatInputPart(partName);
afiPart.setBinaryData(bytes);
Relationship relationship = mainDocumentPart.addTargetPart(afiPart);
CTAltChunk chunk = Context.getWmlObjectFactory().createCTAltChunk();
chunk.setId(relationship.getId());
mainDocumentPart.addObject(chunk);
} catch (Exception e) {
e.printStackTrace();
}
}
文档块插入的核心逻辑:
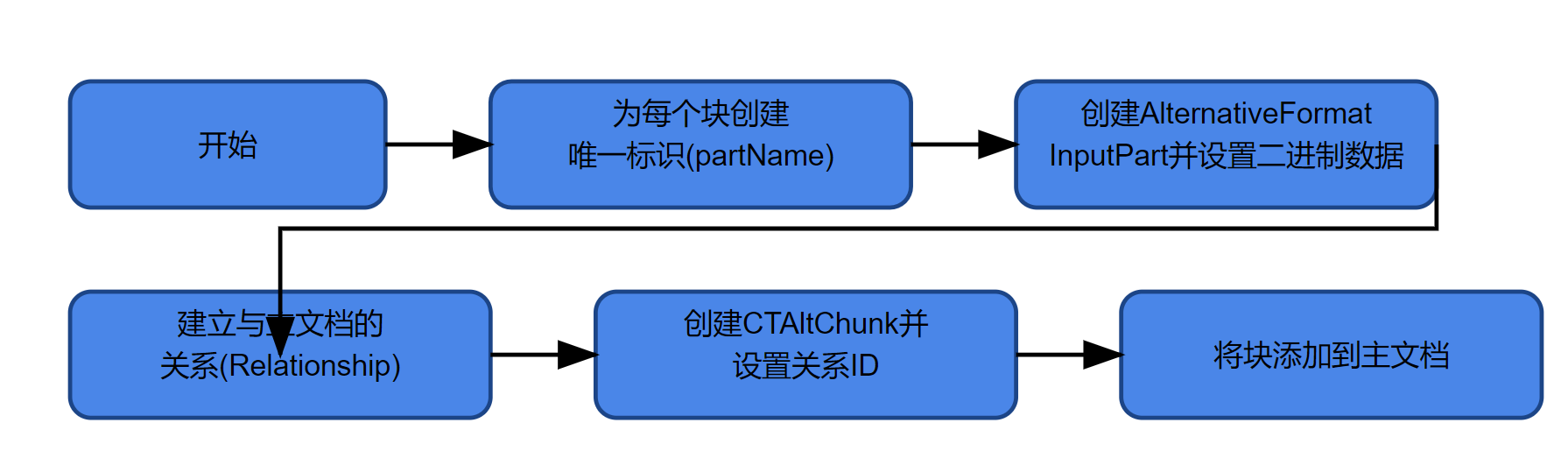
- 为每个块创建唯一标识(partName)
- 创建AlternativeFormatInputPart并设置二进制数据
- 建立与主文档的关系(Relationship)
- 创建CTAltChunk并设置关系ID
- 将块添加到主文档
文件处理逻辑
public static void saveMergeDoc(String path, String savePath, String fileName) {
// 处理目标文件路径
String savePathFile = savePath + "\\" + fileName;
// 处理已存在文件
if (Files.exists(savePathFilePath)) {
Files.delete(savePathFilePath);
}
// 收集输入文件
File[] files = currentDir.listFiles();
List<String> inputFileStr = new ArrayList<>();
// ...收集文件路径...
// 执行合并
try (FileOutputStream out = new FileOutputStream(savePathFile)) {
mergeDoc(inputFileStr, out);
}
}
四 说明
这个工具通过docx4j的专业能力,实现了稳定可靠的Word文档合并功能,适合需要批量处理Word文档的各种业务场景。