线程池
在 Python 中,线程池是一种用于管理多个线程资源、提高并发效率的重要工具,尤其适用于 I/O 密集型任务 (如网络请求、文件读写等)。
什么是线程池?
线程池是一组预先创建并处于等待状态的线程,它们等待任务被分配给它们执行。使用线程池可以:
- 减少线程创建和销毁的开销
- 控制并发数量,避免资源耗尽
- 提高程序响应速度
为什么需要线程池?
在没有线程池的情况下,每次执行一个任务都需要手动创建线程,任务完成后销毁线程,这会带来较大的开销。而线程池可以复用线程,提高效率。
基本使用
Python 提供了多种实现线程池的方式,其中最推荐的是:concurrent.futures.ThreadPoolExecutor这是 Python 3.2+ 内置的高级线程池接口,简洁易用,功能强大。
concurrent包中仅有futures一个模块用于启动并行任务。
from concurrent.futures import ThreadPoolExecutor,as_ompleted
# 创建一个最大线程数为5的线程池
executor = ThreadPoolExecutor(max_workers=5)
# 提交任务
future = executor.submit(task_function,arg1,arg2)case:
from concurrent.futures import ThreadPoolExecutor,as_completed
import time
def func(time_,num):
time.sleep(1)
print(f"\033[32m{num}:{time_}\033[0m")
return time_
executor = ThreadPoolExecutor(max_workers=20)
future = [executor.submit(func,time_,100) for time_ in range(100)]
print([f.result() for f in as_completed(future)])- future = [executor.submit(func, time_, 100) for time_ in range(100)] 这行代码会向线程池提交100个任务,每个任务会调用 func 函数。 executor.submit 返回的是 Future 对象。在这个代码中future代表的就是Future列表,即future:list[Future]
- Future 对象代表一个异步执行的任务。它包含了任务的执行状态(如是否完成)、返回结果(如果已完成)、异常信息(如果有异常)等内容。你可以通过 future.result() 获取任务的返回值,如果任务还没完成,这个方法会阻塞直到任务完成。
- as_completed(future) 是一个生成器,会在每个 Future 对象完成时依次产出它。这样你可以按任务完成的顺序处理结果,而不是提交的顺序。这对于并发任务来说很有用,因为有些任务可能先完成,有些后完成。
如果不使用as_completed,直接遍历future,获取的future.result是按任务submit顺序输出的,反之是按照任务完成顺序输出的,效率更高(如果先提交了但是未完成会有一定时间的阻塞)。
# 按完成顺序获取结果
for f in as_completed(future):
print(f.result())
# 按提交顺序获取结果
for f in future:
print(f.result())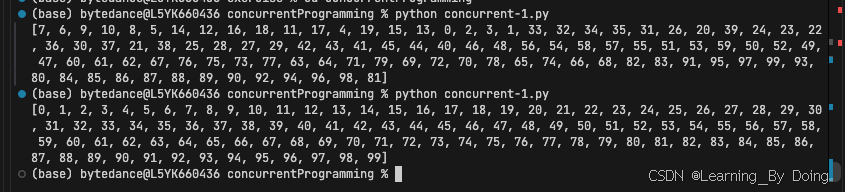
future.result()返回的值与函数返回值对应。future.result返回的是返回值object信息,加上括号()才是函数返回值。
case2:
线程池结合with语句
import time
from concurrent.futures import ThreadPoolExecutor,as_completed
import random
import json
def func(args:list[dict]):
num = random.randint(1,3)
time.sleep(num*2)
print(f"\033[3{num}m:{args}\033[0m")
return args
if __name__ == "__main__":
with open('./education_self.json','r',encoding="utf-8") as f:
data = json.load(f)
with ThreadPoolExecutor(max_workers=5) as executor:
future = [executor.submit(func,arg) for arg in data]
for f in as_completed(future):
print(f.result)case3:
线程池结合map方法,map方法会将参数逐一传递,返回的不再是future对象而是future.result(),也就是这一步被省略了,直接返回函数结果。
import time
from concurrent.futures import ThreadPoolExecutor,as_completed
import random
import json
def func(args:dict):
num = random.randint(1,3)
# time.sleep(num*2)
print(f"\033[3{num}m:{args}\033[0m")
return args
if __name__ == "__main__":
with open('./education_self.json','r',encoding="utf-8") as f:
data = json.load(f)
with ThreadPoolExecutor(max_workers=5) as executor:
for res in executor.map(func,data):
print(res)case4
import concurrent.futures
def test_function(arguments: tuple):
test_value, function = arguments
"""Print the test value 1000 times"""
for i in range(0, 1000):
print(f"Function {function}, {test_value}, iteration {i}")
return test_value
def main():
"""Main function"""
# Context manager for parallel tasks
with concurrent.futures.ThreadPoolExecutor() as executor:
# Submit example. Executes the function calls asynchronously
result = [executor.submit(test_function, (i, "submit")) for i in range(1, 21)]
# Map example.
# Takes an iterable as argument that will execute the function once for each item
result_2 = executor.map(test_function, [(i, "map") for i in range(1, 21)])
for future in concurrent.futures.as_completed(result):
print(f"Submit: Process {future.result()} completed")
for future in result_2:
print(f"Map: Process {future} completed")
if __name__ == '__main__':
main()