【跟我学YOLO】(1)YOLOv13:基于超图增强的自适应视觉感知的实时物体检测
0. YOLOv13 简介
0.1 YOLOv13 的核心技术
YOLOv13 来了!
清华大学、太原理工大学、北京理工大学、深圳大学、香港科技大学(广州)、西安交通大学联合研究团队提出了 YOLOv13,其核心技术包括:
- HyperACE: 基于超图的自适应相关性增强 (Hypergraph-based Adaptive Correlation Enhancement)
- 将多尺度特征图中的像素视为超图顶点。
- 采用可学习的超边构建模块,自适应地探索顶点之间的高阶相关性。
- 利用一个线性复杂度的消息传递模块,在高阶相关性的指导下有效聚合多尺度特征,从而实现对复杂场景的有效视觉感知。
- FullPAD: 全流程聚合与分发范式 (Full-Pipeline Aggregation-and-Distribution Paradigm)
- 使用 HyperACE 聚合主干网络的多尺度特征,并在超图空间中提取高阶相关性。
- 利用三个独立通道,将这些相关性增强的特征分别转发到主干网络与颈部 (neck) 的连接处、颈部内部各层之间,以及颈部与头部 (head) 的连接层,实现全流程的细粒度信息流与表征协同。
- FullPAD 显著改善了梯度传播,并提升了检测性能。
- 轻量级基于深度可分离卷积的系列模块
- 将大核卷积替换为基于深度可分离卷积(DSConv, DS-Bottleneck, DS-C3k, DS-C3k2)构建的模块,在保持感受野的同时,极大地减少了参数量和计算量。
- 实现了推理速度的提升,且不牺牲精度。
0.2 YOLO13 论文下载
2025年6月21日,Lei MQ, Li SQ, Wu YH 等在 arxiv 发表论文 “YOLOv13:基于超图增强的自适应视觉感知的实时物体检测(YOLOv13: Attention-Centric Real-Time Object Detectors)”。
论文下载:ARIXV-YOLOv13
官方文档:iMoonLab-YOLOv13
Github下载:Github-YOLOv13
引用格式: Lei MQ, Li SQ, Wu YH, et al., YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception, 2025, arXiv preprint arXiv:2506.17733
0.3 论文摘要
YOLO系列模型因其卓越的准确性和计算效率,在实时目标检测领域占据主导地位。然而,无论是YOLO11及其早期版本的卷积架构,还是YOLOv12中引入的基于区域的自注意力机制,都仅限于局部信息聚合和成对相关性建模,无法捕捉全局多到多的高阶关联,这限制了模型在复杂场景中的检测性能。
本文提出YOLOv13,旨在提供一个既准确又轻量级的目标检测器。
为了解决上述问题,我们设计了一种基于超图的自适应相关性增强机制(HyperACE),通过超图计算自适应挖掘潜在高阶相关性,克服了现有方法局限于成对相关性建模的缺陷,实现了高效的全局跨位置与跨尺度特征融合增强。
随后,我们基于HyperACE 提出了全流程聚合与分发(FullPAD)范式,有效实现了细粒度信息的处理。
最后,我们提出利用深度可分离卷积替代常规大核卷积,设计了一系列能在不牺牲性能前提下显著减少参数量和计算复杂度的模块。
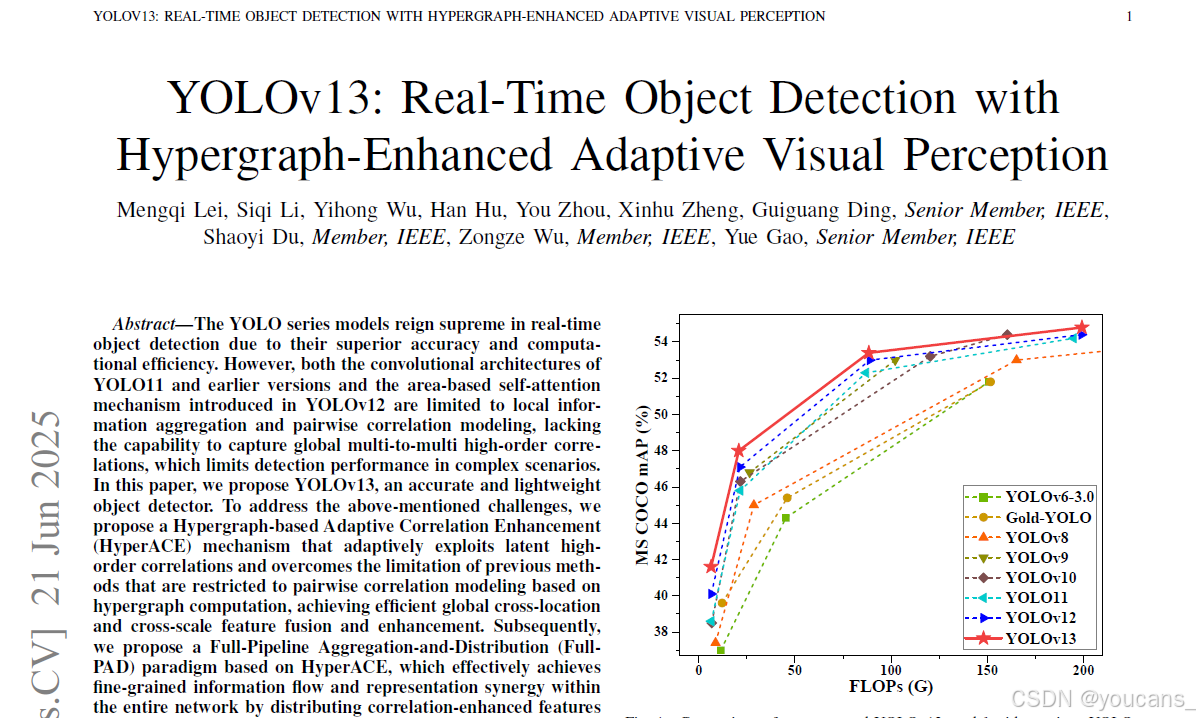
我们在广泛使用的MS COCO基准上进行了大量实验,结果表明本方法以更少的参数量和FLOPs实现了最先进性能。具体而言,YOLOv13-N相较YOLOv11-N提升mAP 3.0%,较YOLOv12-N提升1.5%。
代码与模型发布于:https://github.com/iMoonLab/yolov13。
索引词:YOLO,目标检测,自适应超图计算,视觉相关性建模。
1. 背景介绍
实时目标检测长期处于计算机视觉研究的前沿[1][2],其目标是以最小延迟对图像中的物体进行定位与分类,这对工业异常检测、自动驾驶和视频监控等广泛应用至关重要[3]。
近年来,单阶段CNN检测器通过将区域提议、分类和回归集成到统一的端到端框架,在该领域占据主导地位[4]-[7]。YOLO(You Only Look Once)系列[6][8]-[18]凭借推理速度与准确性的卓越平衡成为主流。
从早期YOLO版本到最近的YOLOv11模型,均采用以卷积为核心的架构,旨在通过不同设计的卷积层提取图像特征并实现目标检测。
最新的YOLOv12模型[18]进一步利用基于区域的自注意力机制增强模型表征能力。一方面,卷积运算固有地在固定感受野内执行局部信息聚合,因此建模能力受限于卷积核尺寸与网络深度;另一方面,尽管自注意力机制扩展了感受野,但其高计算成本迫使采用局部区域计算作为折衷方案,从而阻碍了充分的全局感知与建模。
此外,自注意力机制可视为在全连接语义图上对像素间成对相关性的建模,这本质上限制了其仅能捕获二元相关性,无法表征和聚合多对多高阶相关性。因此,现有YOLO模型的架构限制了其建模全局高阶语义相关性的能力,导致复杂场景下的性能瓶颈。
超图能够建模多对多高阶相关性。与传统图不同,超图中的每条超边可连接多个顶点,从而实现对多顶点间相关性的建模。部分研究[19]-[21]已证明使用超图建模多像素高阶相关性对于目标检测等视觉任务的必要性与有效性。然而,现有方法仅通过手动设置阈值参数值,根据像素特征距离判定相关性——即特征距离低于特定阈值的像素被视为相关。这种人工建模范式难以应对复杂场景,并导致额外冗余建模,造成检测精度与鲁棒性受限。
为应对上述挑战,我们提出YOLOv13——一种创新的实时突破性端到端目标检测器。该模型将传统的基于区域的成对交互建模扩展至全局高阶相关性建模,使网络能感知跨空间位置与尺度的深层语义相关性,显著提升复杂场景下的检测性能。具体而言:
为克服现有方法中人工构建超边导致的鲁棒性与泛化性局限,我们提出基于超图的自适应相关性增强机制(HyperACE)。该机制以多尺度特征图中的像素为顶点,采用可学习的超边构建模块自适应探索顶点间高阶相关性,继而利用线性复杂度的消息传递模块,在高阶相关性指导下有效聚合多尺度特征,实现复杂场景的有效视觉感知。低阶相关性建模亦被整合至HyperACE以完成完整视觉感知。
基于HyperACE,我们提出包含全流程聚合-分发范式(FullPAD)的新型YOLO架构。该范式通过HyperACE机制聚合骨干网络提取的多层次特征,随后将相关性增强特征分发至骨干网络、颈部网络和检测头,实现全流程细粒度信息流与表征协同,显著改善梯度传播并提升检测性能。
为在不牺牲性能的前提下降低模型规模与计算成本,我们提出基于深度可分离卷积的轻量级特征提取模块系列,通过用其替代常规大核卷积模块,实现更快推理速度与更小模型体积,达成效率与性能的更好平衡。
为验证模型有效性,我们在广泛使用的MS COCO基准[22]上开展大量实验。定量与定性结果表明,所提方法在保持轻量化的同时性能超越所有先前YOLO模型及变体。具体而言,YOLOv13-N/S相较YOLOv12-N/S和YOLO11-N/S分别实现1.5%/0.9%和3.0%/2.2%的mAP提升。消融实验进一步验证了各模块的有效性。
YOLOv13 的主要贡献如下:
提出YOLOv13——一种卓越的实时端到端目标检测器,通过自适应超图挖掘潜在高阶相关性,并基于相关性指导的有效信息聚合与分发实现精准鲁棒的检测。
提出 HyperACE机制,基于自适应超图计算捕获复杂场景中的潜在高阶相关性,实现相关性指导的特征增强;提出FullPAD范式实现全流程内的多尺度特征聚合与分发,增强信息流与表征协同;提出基于深度可分离卷积的轻量级模块系列替代常规大核卷积模块,显著降低参数量与计算复杂度。
在MS COCO基准上开展大量实验,结果表明YOLOv13在保持轻量化的同时达到最先进检测性能。
2. 相关的工作
2.1. YOLO 检测器的演进
简要回顾了从初代 YOLO 到 YOLOv12 的发展历程,包括 DarkNet 骨干网、CSP 结构、SPP、PANet、无锚点(anchor-free)头部等关键技术的引入。指出现有所有 YOLO 系列模型的局限性:它们仅限于建模局部的成对相关性。
自深度卷积神经网络问世以来[2],实时目标检测技术经历了从R-CNN系列[4][5][23][24]为代表的多阶段流程,到以YOLO模型[25]为典范的高度优化单阶段框架的快速演进。
- 初代YOLO(You Only Look Once)模型[6]首次将检测任务重构为单次回归问题,消除了候选框生成开销,实现了速度与精度的卓越平衡。
后续YOLO迭代版本持续优化架构与训练策略[3][25]: - YOLOv2[8]通过引入基于锚点的预测机制和DarkNet-19骨干网络提升精度;
- YOLOv3[9]采用DarkNet-53骨干网络和三尺度预测机制强化小目标检测能力;
- YOLOv4至YOLOv8[10]-[14]逐步集成CSP模块、SPP模块、PANet网络、多模态支持和无锚检测头等组件,进一步平衡吞吐率与准确率;
- YOLOv9[15]与YOLOv10[16]则聚焦轻量化骨干网络和端到端部署流程精简。
- YOLOv11[17]保留"骨干-颈部-检测头"模块化设计,但将原始C2f模块替换为更高效的C3k2单元,并新增具有局部空间注意力的卷积块(C2PSA)以增强小目标和遮挡目标检测能力。
- 最新发布的YOLOv12[18]标志着注意力机制的完整融合,通过引入残差高效层聚合网络(R-ELAN)结合轻量化区域注意力(A2)和闪存注意力机制,优化内存访问效率,在保持实时性能的同时实现高效的全局与局部语义建模,并提升鲁棒性与精确度。
与此同时,衍生出若干基于YOLO的变体模型[25]:
- YOLOR[26]通过显隐特征融合获得更丰富的表征能力和更强的泛化性;
- YOLOX[27]采用动态标签分配的无锚检测头简化流程并提升小目标检测性能;
- YOLO-NAS[28]利用AutoNAC神经架构搜索技术,结合Quant-Aware RepVGG和混合精度量化来优化吞吐率与小目标性能;
- Gold-YOLO[29]提出GD机制以增强多尺度特征融合能力;
- YOLO-MS[30]设计集成全局查询学习的MS模块实现动态多分支特征融合,并采用渐进式异构核尺寸选择策略以最小开销丰富多尺度表征。
然而如前所述,当前YOLO系列模型的架构仍局限于局部成对相关性建模,无法构建全局多对多高阶相关性模型,这制约了现有方法在复杂场景下的检测性能。
2.2. 高阶相关性建模
视觉数据中存在复杂的、超越成对关系的高阶(群组)相关性。超图(Hypergraph)是表示这种多对多高阶关系的有效工具,而超图神经网络(HGNNs)是主要的建模方法。指出现有的视觉超图方法大多采用手工制作(handcrafted)的超边构建方式,缺乏鲁棒性。本文提出的自适应机制旨在解决此问题。
复杂多对多高阶相关性广泛存在于自然界(如神经连接与蛋白质相互作用)及信息科学领域(如社交网络)[31][32]。在视觉数据中,不同对象通过空间、时间和语义交互形成复杂相关性,这些相关性既可能是成对的(低阶),也可能是更复杂的群体性关联(高阶)。作为传统图的扩展形式,超图不仅能表示成对相关性,还可表征多对多高阶相关性[33][34]。
近年来,超图神经网络(HGNN)已成为建模此类高阶相关性的主要工具[35]-[38]:Feng等人[39]提出谱域超图神经网络,在视觉检索任务中验证了其优势;Gao等人[40]进一步提出具有空间超图卷积算子的HGNN+,增强了超图神经网络的适用性;近期Feng等人[38]率先将HGNN集成至检测模型,证明了高阶相关性建模对检测任务的必要性。然而,该方法仅采用人工设定的固定参数作为阈值,将特征距离小于阈值的像素判定为相关,导致相关性建模的精度与鲁棒性不足。
为解决上述挑战,我们提出基于超图的自适应相关性增强机制,通过自适应挖掘潜在相关性,有效建模跨位置与跨尺度的语义交互。该机制既克服了现有超图计算范式因人工超参数导致的鲁棒性缺陷,又弥补了现有YOLO系列模型缺乏全局高阶相关性建模的不足。
3. 方法
本节详细阐述我们提出的 YOLOv13 方法。首先将介绍模型的整体网络架构;随后分别介绍基于超图的自适应相关性增强机制(HyperACE)与全流程聚合-分发范式(FullPAD)的核心思想与具体结构;最后介绍轻量化特征提取模块的架构设计。
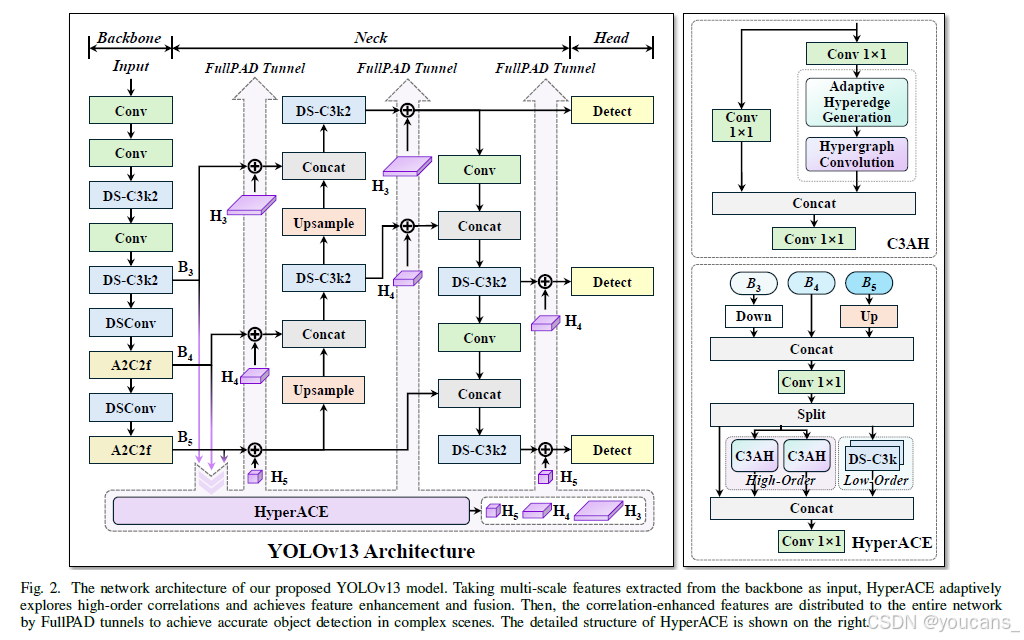
3.1. 整体架构
打破了传统的“骨干→颈部→头部”单向计算范式。
传统YOLO系列遵循"骨干网络→颈部网络→检测头"的计算范式,这种架构本质上限制了信息流的充分传递。相比之下,我们的模型通过基于超图的自适应相关性增强机制(HyperACE)实现了全流程特征聚合-分发(FullPAD),从而增强了传统YOLO架构。因此,我们提出的方法能够在整个网络中实现细粒度的信息流与表征协同,这有助于改善梯度传播并显著提升检测性能。
具体而言,如图2所示,我们的YOLOv13 模型:
- 首先采用与先前工作相似的骨干网络提取多尺度特征图 B1-B5,但其中大核卷积被替换为我们提出的轻量化DS-C3k2模块。
- 与传统YOLO方法直接将B3、B4和B5输入颈部网络不同,我们的方法将这些特征汇集并输入HyperACE模块,实现跨尺度、跨位置特征的高阶相关性自适应建模与特征增强。
- 随后,FullPAD范式通过三个独立通道将相关性增强特征分别分发至:骨干网络与颈部网络的连接处、颈部网络的内部层间、以及颈部网络与检测头的连接处,以实现更优的信息流。
- 最终,颈部网络的输出特征图被送入检测头实现多尺度目标检测。
3.2. 基于超图的自适应相关性增强
核心思想: HyperACE 包含一个全局高阶感知分支和一个局部低阶感知分支。
为实现高效且鲁棒的跨尺度、跨位置相关性建模与特征增强,我们提出基于超图的自适应相关性增强机制。
如图2所示,HyperACE包含两个核心组件:基于C3AH模块的全局高阶感知分支(通过自适应超图计算以线性复杂度建模高阶视觉相关性)和基于DS-C3k模块的局部低阶感知分支。以下小节将分别介绍自适应超图计算、C3AH模块以及HyperACE的整体设计。
3.2.1 自适应超图计算
为有效且高效地建模视觉特征中的高阶相关性并实现相关性指导的特征聚合与增强,我们提出一种新颖的自适应超图计算范式。与传统超图建模方法使用人工预定义参数基于特征相似度构建超边不同,我们提出的方法自适应学习每个顶点对每条超边的参与程度,使得该计算范式更具鲁棒性和高效性。传统超图计算范式更适用于非欧几里得数据(如社交网络),因其包含显式连接关系;而我们的自适应超图计算范式更适用于计算机视觉任务。
具体而言,我们定义的自适应超图为G = {V, A},其中V为顶点集,A为自适应超边集。在自适应超图中,每条超边连接所有顶点,其中每个顶点以连续可微的贡献度参与超边。因此,不同于传统超图使用关联矩阵H ∈ {0,1}N×M表示,我们的自适应超图采用连续参与矩阵A ∈ [0,1]N×M表示(N和M分别为顶点数和超边数),其中Ai,m表示顶点i对超边m的参与度。相应地,我们的自适应超图计算范式包含两个阶段:自适应超边生成和超图卷积,如图3所示。
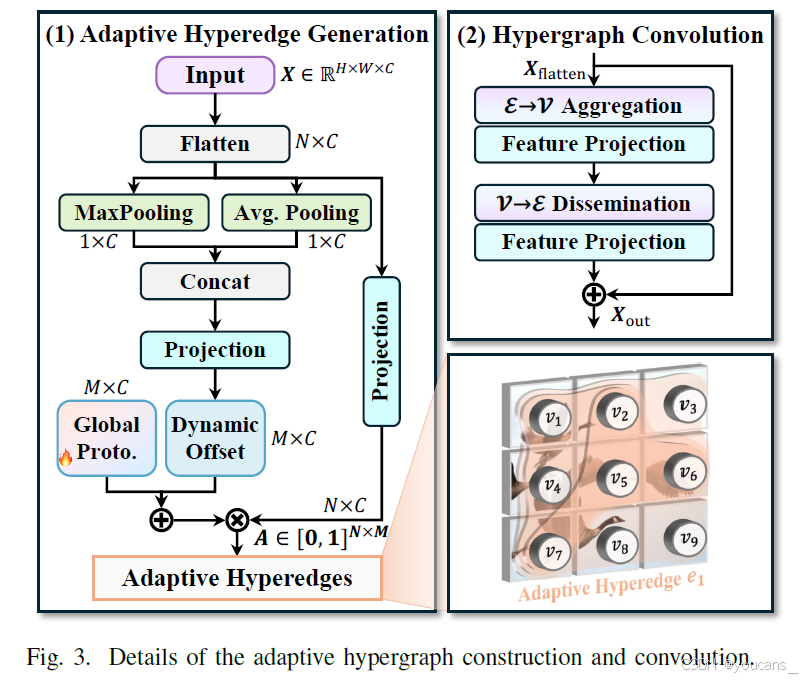
1. 自适应超边生成
自适应超边生成阶段着重于从输入视觉特征中动态建模相关性以生成超边,并估计每个顶点对每条超边的参与度。具体而言,令X = {x_i ∈ R^C | i = 1,…,N}表示顶点特征集(C为特征通道数),本方法首先生成全局平均池化向量f_avg与最大池化向量f_max,通过拼接操作获得全局顶点上下文特征:
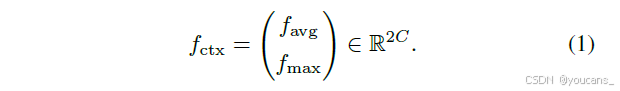
随后利用映射层φ: R{2C}→R{M×C}从顶点上下文生成全局偏移量ΔP = φ(f_ctx)(M为超边数量)。该偏移量与可学习的全局原型P_0 ∈ R^{M×C}相加后,得到M个动态超边原型P = P_0 + ΔP,这些原型表征场景中潜在的视觉相关性。为计算顶点参与度,通过投影层将顶点特征x_i转换为查询向量:
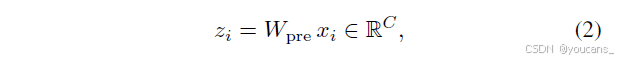
其中W_{pre}为权重矩阵。为增强特征多样性,引入多头机制将z_i沿特征维度划分为h个子空间{ẑ^τ_i ∈ R{d_h}}h_{τ=1}(d_h = C/h),超边原型同步划分为{ṕ^τ_m ∈ R{d_h}}h_{τ=1}。在第τ子空间中,计算顶点查询向量与超边原型的相似度:
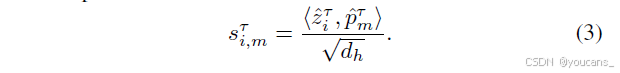
整体相似度定义为各子空间相似度均值:ŝ_{i,m} = (1/h)∑h_{τ=1}sτ_{i,m}。最终基于softmax函数对顶点间相似度归一化,得到连续参与矩阵:
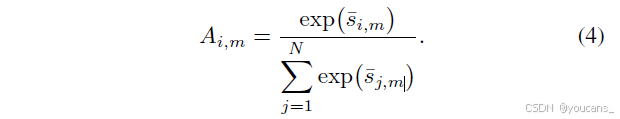
2. 超图卷积
在生成自适应超边后,执行超图卷积以实现特征聚合与增强。具体而言,在超图卷积中,每条超边首先收集所有顶点的特征并通过线性投影形成超边特征,随后将超边特征传播回顶点以更新其表征。该过程可形式化定义为:
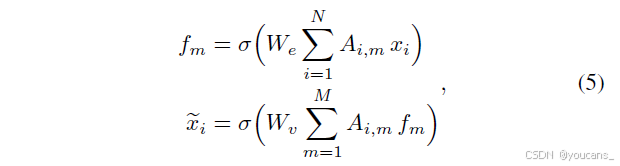
其中i = 1,…,N为顶点索引,m = 1,…,M为超边索引,W_e与W_v分别表示超边和顶点投影权重,σ为激活函数。
3.2.2 自适应高阶相关性建模的 C3AH 模块
将自适应超图计算模块(AHC)嵌入到一个 CSP 瓶颈结构中,实现了高效的全局高阶语义聚合。
基于提出的自适应超图计算范式,我们进一步设计C3AH模块以高效捕获高阶语义交互。如图2所示,C3AH模块保留CSP瓶颈分支拆分机制,同时集成自适应超图计算模块,实现跨空间位置的全局高阶语义聚合。
设C3AH模块输入特征图为X_in ∈ R^{C_in×H×W},首先通过两个1×1卷积层投影至相同隐藏维度:
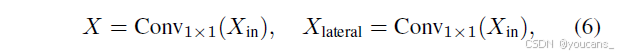
其中X, X_{lateral} ∈ R^{C×H×W},C = ⌊eC_in⌋,e为瓶颈压缩率。X与X_{lateral}分别用于自适应超图计算和横向连接。
随后将X展平为顶点特征并输入自适应超图计算模块(AHC)获取相关性增强特征:
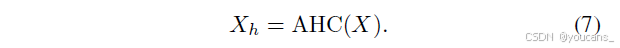
最终将X_h与X_{lateral}沿通道维度拼接,并通过1×1卷积层融合得到C3AH模块输出。
#### 3.2.3 HyperACE 的结构 *将融合后的多尺度特征图分为三路:一路通过并行的 C3AH 模块进行高阶建模,一路通过堆叠的 DS-C3k 模块进行低阶建模,还有一路作为直连(shortcut)。最后将三路输出拼接融合。*
HyperACE以多尺度特征作为输入,实现高效的视觉相关性建模与特征增强。具体流程如下:
- 特征预处理
将骨干网络最后三阶段的特征图B3/B4/B5调整至B4的空间尺寸,通过1×1卷积聚合获得融合特征X_b。
特征分组
将X_b沿通道维度拆分为三组特征:
(1)X_b^h ∈ R^{C_h×H×W}(高阶建模)
(2)X_b^l ∈ R^{C_l×H×W}(低阶建模)
(3)X_b^s ∈ R^{C_s×H×W}(快捷连接)高阶相关性建模分支
通过K个并行C3AH模块挖掘潜在高阶相关性:
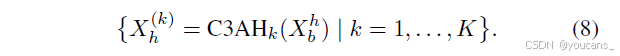
将K个增强特征沿通道维度拼接:
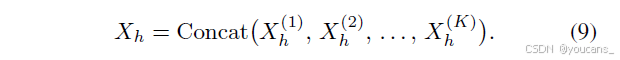
- 低阶相关性建模分支
采用L个堆叠的DS-C3k模块捕获局部细粒度信息:
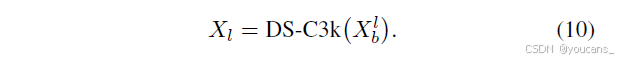
快捷分支
保留原始视觉信息:X_s = X_b^s特征融合
将三支路输出拼接并通过1×1卷积融合:
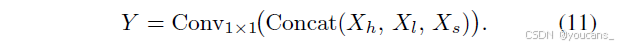
所提出的HyperACE通过并行全局高阶建模分支与局部低阶建模分支的协同工作,在保留快捷信息的同时,实现了跨全局-局部、高阶-低阶的多层次视觉相关性互补感知。
3.3. 全流程聚合与分发范式 (FullPAD)
将 HyperACE 输出的增强特征,通过可学习的门控融合机制,注入到主干网络、颈部和头部的多个关键节点。
这种设计实现了全网络范围内的精细化信息流动和表征协同。
为充分利用HyperACE获取的相关性增强特征,我们进一步提出FullPAD范式。如图2所示,该范式首先从骨干网络收集多尺度特征图并输入HyperACE,随后通过不同的FullPAD通道将增强特征重新分发至整个流程的各个位置。这种设计实现了细粒度信息流与表征协同,显著改善了梯度传播并提升了检测性能。
具体实现流程如下:
- 特征适配
当从B3/B4/B5通过HyperACE获得相关性增强特征Y后,FullPAD将其调整至各阶段的空间分辨率并通过1×1卷积调整通道维度:
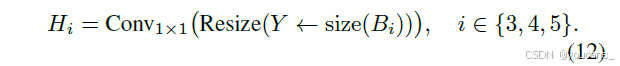
门控融合
对任意阶段i的特征图 F i F_i Fi,采用可学习门控参数γ进行特征融合:
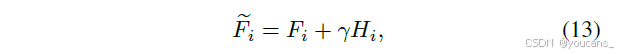
多路分发
如图2所示,FullPAD通过三条独立通道将增强特征分发至 7 个不同目标位置:
(1)骨干网络与颈部网络的连接层
(2)颈部网络的内部层级
(3)颈部网络与检测头的连接层
该范式通过将相关性增强特征有效整合至全流程各阶段,使模型能充分利用视觉相关性信息来感知复杂场景。
3.4. 基于深度可分离卷积的轻量化模型
DSConv: 基础的深度可分离卷积块。
DS-Bottleneck: 由两个 DSConv 块串联构成的瓶颈结构。
DS-C3k/DS-C3k2: 将 DS-Bottleneck 嵌入 CSP 结构中,形成新的轻量化特征提取模块,并被广泛用于骨干和颈部网络。
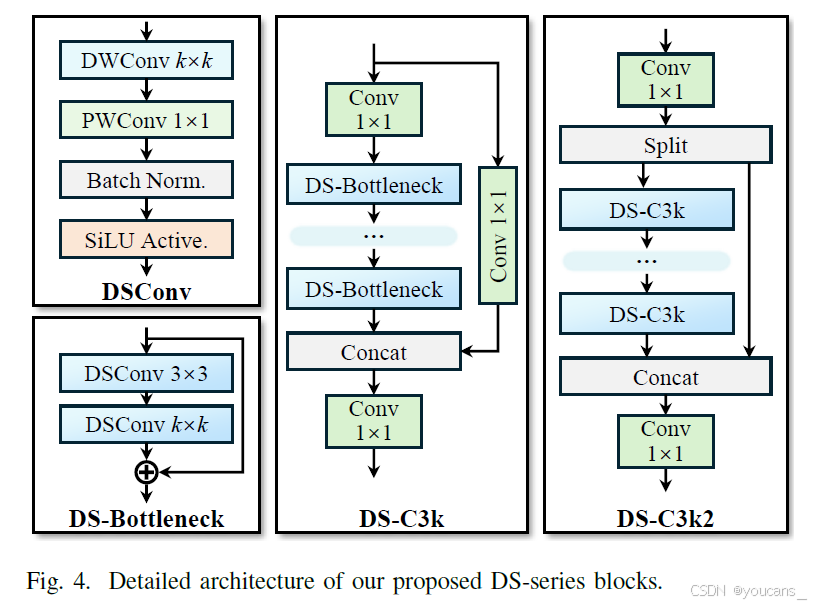
如图4所示,我们采用大核深度可分离卷积(DSConv)作为基础单元,设计了一系列轻量级特征提取模块,在保证模型性能的同时显著降低参数量与计算复杂度。
DSConv模块
由标准深度可分离卷积层、批归一化和SiLU激活函数构成:
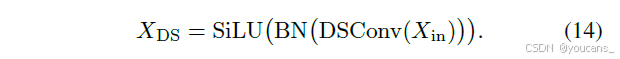
DS-Bottleneck模块
级联两个DSConv模块:首个为固定3×3深度可分离卷积,次个为可配置k×k大核深度可分离卷积:
当输入输出通道数相同时,添加残差连接以保留低频信息。
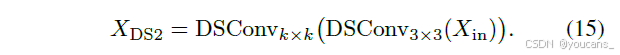
DS-C3k模块
继承标准CSP-C3结构:- 通过1×1卷积降维后输入n个级联DS-Bottleneck
- 并行1×1卷积旁路分支
- 通道维度拼接后通过1×1卷积恢复维度
DS-C3k2模块
基于C3k2结构改进:- 1×1卷积统一通道后特征二分
- 分支1通过多个DS-C3k模块处理
- 分支2保持快捷连接
最终拼接融合
如图2所示,YOLOv13在骨干网络和颈部网络中广泛采用DS-C3k2作为基础特征提取模块,在HyperACE中使用DS-C3k作为低阶特征提取器。该设计使所有YOLOv13模型尺寸实现最高30%的参数量减少和28%的GFLOPs降低。通过所提出的YOLOv13模型,视觉特征中的潜在相关性得以自适应建模,通过全流程传播相关性增强特征,最终实现复杂场景下精准高效的目标检测。
4. 实验
为验证所提YOLOv13模型的有效性与效率,我们开展系统性实验研究。第4.1节详细说明实验设置;第4.2节将本方法与现有实时目标检测方法进行对比以验证有效性;第4.3节通过消融实验证明各模块的贡献。
4.1 实验设置
数据集: 主要使用 MS COCO 2017,并使用 Pascal VOC 2007 测试泛化能力。
实现细节: 包含 N/S/L/X 四种尺寸的模型,训练 600 个 epoch,使用与 YOLOv11/v12 一致的优化器和数据增强策略。
数据集:
采用目标检测领域最广泛使用的基准数据集MS COCO[22]进行评估。其训练集(Train2017)包含约118,000张图像,验证集(Val2017)包含约5,000张图像,涵盖自然场景中80类常见目标。所有方法均在Train2017上训练,在Val2017上测试。
为评估模型泛化能力,额外选用Pascal VOC 2007数据集[42]作为跨域测试基准。该数据集训练验证集共5,011张图像,测试集4,952张图像,包含20类常见目标。跨域评估时,所有方法直接使用MS COCO训练的模型在Pascal VOC 2007测试集上进行测试。实施细节:
YOLOv13系列包含四个变体:Nano(N)、Small(S)、Large(L)和Extra-Large(X)。各变体超边数M分别设置为4/8/8/12。所有模型训练600个epoch,批次大小256,初始学习率0.01,采用SGD优化器(与YOLO11/v12保持一致)。学习率采用线性衰减策略,前3个epoch进行线性预热。训练输入尺寸为640×640,数据增强采用Mosaic和Mixup技术。使用4/8块RTX 4090 GPU分别训练YOLOv13-N/S,4/8块A800 GPU训练YOLOv13-L/X。延迟测试在Tesla T4 GPU上采用TensorRT FP16进行。为保证公平性,我们在相同硬件平台上使用官方配置复现了YOLO11和YOLOv12(v1.0版本)的所有变体模型。
4.2 对比实验
- 定量结果 (表 I): YOLOv13 在所有尺寸上均超越了先前的 YOLO 版本(v6-v12)和 RT-DETR 等模型,在 mAP 上取得了SOTA性能,同时保持了较低的参数量和计算量。
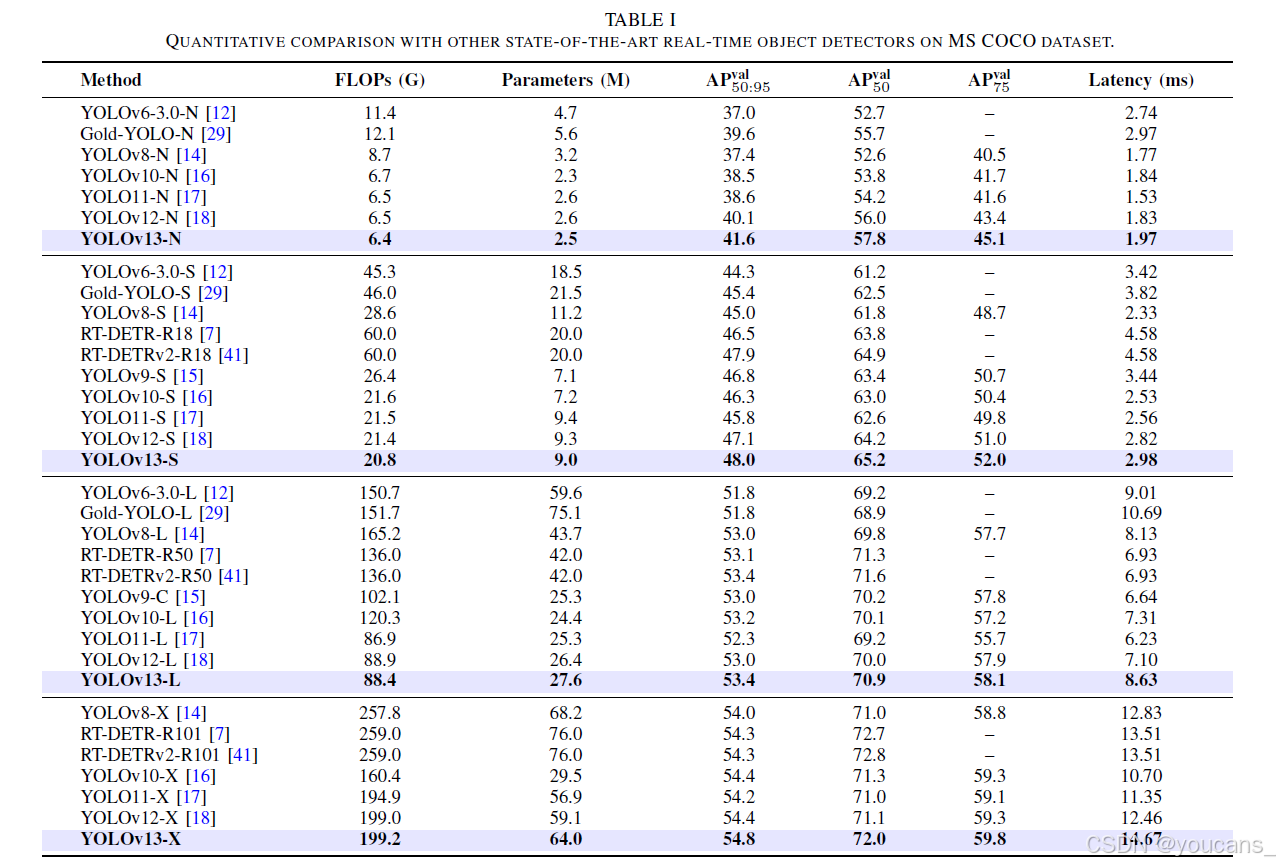
表I展示了MS COCO数据集上的定量对比结果。与最新YOLO11/v12相比,YOLOv13所有变体均实现最先进性能:在N/S/L/X模型上,APval50:95分别提升1.5%/0.9%/0.4%/0.4%,APval50分别提升1.8%/1.0%/0.9%/0.9%。相较于基于ViT的方法,YOLOv13在更少参数量和更低计算复杂度下获得更高检测精度。例如YOLOv13-S相比RT-DETRv2-R18,APval50:95提升0.1%的同时参数量减少55.0%,FLOPs降低65.3%。值得注意的是,本方法在轻量级变体(如Nano模型)上优势更为显著,这源于HyperACE机制能更充分挖掘复杂场景中的多对多相关性。作为传统自注意力机制的高阶扩展,HyperACE以低参数量/计算复杂度实现了精准的特征增强。

图5展示了MS COCO数据集上的定性对比结果。如图所示:(1)在左图最后行,YOLOv13-N能准确检测复杂多目标场景中的碗、花瓶等小目标,而先前模型存在漏检;(2)右图第二行中,仅本方法成功检测花瓶后的植物,这是通过建模花瓶与植物间的高阶相关性实现的;(3)右图第三行中,本方法准确检测运动员手持的网球拍,而对比方法存在漏检或误检阴影的情况。
- 泛化能力 (表 II): 在 COCO 上训练、在 VOC 上测试的结果表明,YOLOv13 具有更强的泛化性能。
表II展示了Pascal VOC 2007上的跨域泛化结果。在MS COCO训练后直接测试,YOLOv13-N/S相比YOLOv12分别提升APval50:95达1.0%/0.4%,较早期模型提升更为显著,验证了方法的泛化能力。
- 定性结果 (图 5): 可视化结果显示,YOLOv13 在复杂场景中对小物体的检测更准确,能更好地处理遮挡(花瓶后的植物),并能有效区分目标与阴影(网球拍),检测性能优于其他模型。
### 4.3 消融研究 FullPAD 和 HyperACE 的有效性 (表 III, 图 6): 移除 HyperACE 和 FullPAD 会导致性能显著下降,证明了自适应相关性增强的必要性。 只将特征分发到部分位置的效果不如完整的 FullPAD 范式,证明了全流程分发的重要性。 可视化的超边表明,模型能学习到有意义的高阶关系,如“滑雪板和雪杖”、“网球拍和球场”。 超边数量的影响 (表 IV): 实验确定了不同尺寸模型(N/S/L/X)的最佳超边数量(分别为4/8/8/12),以平衡性能和计算开销。 DS 轻量化模块的有效性 (表 V): 与使用标准卷积相比,DS 模块在性能几乎无损的情况下,显著降低了 FLOPs 和参数量,证明了其高效性。 训练轮数和硬件延迟 (表 VI, VII): 确定了最佳训练轮数为 600,并展示了模型在不同硬件(GPU/CPU)上的低延迟,证明了其作为实时检测器的效率。
5. 结论
本文提出当前最先进的端到端实时目标检测器YOLOv13。我们设计了一种基于超图的自适应相关性增强机制(HyperACE),能够自适应挖掘潜在的全局高阶相关性,并基于相关性指导实现多尺度特征融合与增强。通过提出的全流程聚合-分发范式(FullPAD),将相关性增强特征分发至整个网络,有效促进信息流动并实现精准目标检测。此外,我们提出一系列基于深度可分离卷积的轻量化模块,在保持精度的同时显著降低参数量和浮点运算量。在广泛使用的MS COCO数据集上进行的大量实验表明,所提方法以更低计算复杂度实现了最先进的检测性能。
核心创新在于:
- 一个基于超图的自适应相关性增强机制 (HyperACE),用于探索全局高阶相关性。
- 一个全流程聚合与分发范式 (FullPAD),用于促进全网络信息流。
- 一系列基于深度可分离卷积的轻量化模块。
- 实验结果表明,YOLOv13 以更低的计算复杂度实现了SOTA的检测性能。
6. 快速上手
6.1 安装依赖
YOLOv13 需要依赖 FlashAttention,目前其支持的GPU包括Turing、Ampere、Ada Lovelace或Hopper架构(例如T4、Quadro RTX系列、RTX20系列、RTX30系列、RTX40系列、RTX A5000/6000、A30/40、A100、H100等)。
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov13 python=3.11
conda activate yolov13
pip install -r requirements.txt
pip install -e .
6.2 模型验证
使用以下代码在 COCO 数据集上验证 YOLOv13 模型。请确保将 {n/s/l/x} 替换为所需的模型规模。
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # 替换为所需的模型规模
6.3 模型训练
使用以下代码训练 YOLOv13 模型。请确保将 yolov13n.yaml 替换为您想要的模型配置文件路径,并将 coco.yaml 替换为您的 COCO 数据集配置文件。
from ultralytics import YOLO
model = YOLO('yolov13n.yaml')
# 训练模型
results = model.train(
data='coco.yaml',
epochs=600,
batch=256,
imgsz=640,
scale=0.5, # S:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; L:0.5; X:0.6
device="0,1,2,3",
)
# 在验证集上评估模型性能
metrics = model.val('coco.yaml')
# 在单张图片上执行目标检测
results = model("path/to/your/image.jpg")
results[0].show()
6.4 模型推理
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # 替换为所需的模型规模
model.predict()
6.5 模型导出
使用以下代码将 YOLOv13 模型导出为 ONNX 或 TensorRT 格式。请确保将 {n/s/l/x} 替换为所需的模型规模。
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # 替换为所需的模型规模
model.export(format="engine", half=True) # 或 format="onnx"
7. 参考文献
[1] G. Cheng, X. Yuan, X. Yao, K. Yan, Q. Zeng, X. Xie, and J. Han,“Towards large-scale small object detection: Survey and benchmarks,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 11, pp. 13 467–13 488, 2023.
[2] Z. Zou, K. Chen, Z. Shi, Y. Guo, and J. Ye, “Object detection in 20years: A survey,” Proceed. of the IEEE, vol. 111, no. 3, pp. 257–276,2023.
[3] A. Vijayakumar and S. Vairavasundaram, “YOLO-based object detectionmodels: A review and its applications,” Multimedia Tools and Applicat.,vol. 83, no. 35, pp. 83 535–83 574, 2024.
[4] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich featurehierarchies for accurate object detection and semantic segmentation,”in IEEE Conf. Comput. Vis. Pattern Recog., 2014, pp. 580–587.
[5] K. He, G. Gkioxari, P. Dollar, and R. Girshick, “Mask R-CNN,” IEEETrans. Pattern Anal. Mach. Intell., vol. 42, no. 2, pp. 386–397, 2020.
[6] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only lookonce: Unified, real-time object detection,” in IEEE Conf. Comput. Vis.Pattern Recog., 2016, pp. 779–788.
[7] Y. Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y. Liu, and J. Chen,“DETRs beat YOLOs on real-time object detection,” in IEEE Conf.Comput. Vis. Pattern Recog., 2024, pp. 16 965–16 974.
[8] J. Redmon and A. Farhadi, “YOLO9000: Better, faster, stronger,” inIEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 7263–7271.
[9] ——, “YOLOv3: An incremental improvement,” arXiv preprintarXiv:1804.02767, 2018.
[10] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “YOLOv4: Optimalspeed and accuracy of object detection,” arXiv preprintarXiv:2004.10934, 2020.
[11] G. Jocher, “Ultralytics YOLOv5,” 2020.
[Online]. Available: https://github.com/ultralytics/yolov5
[12] C. Li, L. Li, Y. Geng, H. Jiang, M. Cheng, B. Zhang, Z. Ke, X. Xu,and X. Chu, “YOLOv6 v3.0: A full-scale reloading,” arXiv preprintarXiv:2301.05586, 2023.
[13] C.-Y. Wang, A. Bochkovskiy, and H.-Y. M. Liao, “YOLOv7: Trainablebag-of-freebies sets new state-of-the-art for real-time object detectors,”arXiv preprint arXiv:2207.02696, 2022.
[14] G. Jocher, A. Chaurasia, and J. Qiu, “Ultralytics YOLOv8,” 2023.
[Online]. Available: https://github.com/ultralytics/ultralytics
[15] C.-Y. Wang and H.-Y. M. Liao, “YOLOv9: Learning what you wantto learn using programmable gradient information,” arXiv preprintarXiv:2402.13616, 2024.
[16] A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han et al., “YOLOv10:Real-time end-to-end object detection,” in Adv. Neural Inform. Process.Syst., 2024, pp. 107 984–108 011.
[17] G. Jocher and J. Qiu, “Ultralytics YOLO11,” 2024.
[Online]. Available:https://github.com/ultralytics/ultralytics
[18] Y. Tian, Q. Ye, and D. Doermann, “YOLOv12: Attention-centric realtimeobject detectors,” arXiv preprint arXiv:2502.12524, 2025.
[19] Y. Han, P. Wang, S. Kundu, Y. Ding, and Z. Wang, “Vision HGNN: Animage is more than a graph of nodes,” in Int. Conf. Comput. Vis., 2023,pp. 19 878–19 888.
[20] J. Fixelle, “Hypergraph vision transformers: Images are more than nodes,more than edges,” in IEEE Conf. Comput. Vis. Pattern Recog., 2025, pp.9751–9761.
[21] H. Wang, S. Zhang, and B. Leng, “HGFormer: Topology-aware visiontransformer with hypergraph learning,” IEEE Trans. Multimedia, 2025.
[22] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan,P. Doll´ar, and C. L. Zitnick, “Microsoft COCO: Common objects incontext,” in Eur. Conf. Comput. Vis., 2014, pp. 740–755.
[23] R. Girshick, “Fast R-CNN,” in Int. Conf. Comput. Vis., 2015, pp. 1440–1448.
[24] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towardsreal-time object detection with region proposal networks,” Adv. NeuralInform. Process. Syst., 2015.
[25] L. T. Ramos and A. D. Sappa, “A decade of you only look once (YOLO)for object detection,” arXiv preprint arXiv:2504.18586, 2025.
[26] C.-Y. Wang, I.-H. Yeh, and H.-Y. M. Liao, “You only learn onerepresentation: Unified network for multiple tasks,” arXiv preprintarXiv:2105.04206, 2021.
[27] Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “YOLOX: Exceeding yoloseries in 2021,” arXiv preprint arXiv:2107.08430, 2021.
[28] S. Aharon, Louis-Dupont, Ofri Masad, K. Yurkova, Lotem Fridman,Lkdci, E. Khvedchenya, R. Rubin, N. Bagrov, B. Tymchenko, T. Keren,A. Zhilko, and Eran-Deci, “Super-gradients,” 2021.
[Online]. Available:https://zenodo.org/records/7789328
[29] C. Wang, W. He, Y. Nie, J. Guo, C. Liu, Y. Wang, and K. Han, “Gold-YOLO: Efficient object detector via gather-and-distribute mechanism,”Adv. Neural Inform. Process. Syst., pp. 51 094–51 112, 2023.
[30] Y. Chen, X. Yuan, J. Wang, R. Wu, X. Li, Q. Hou, and M.-M. Cheng,“YOLO-MS: Rethinking multi-scale representation learning for realtimeobject detection,” IEEE Trans. Pattern Anal. Mach. Intell., 2025.
[31] Y. Gao, S. Ji, X. Han, and Q. Dai, “Hypergraph computation,” Engineering,2024.
[32] Y. Gao, Z. Zhang, H. Lin, X. Zhao, S. Du, and C. Zou, “Hypergraphlearning: Methods and practices,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 44, no. 5, pp. 2548–2566, 2020.
[33] A. Antelmi, G. Cordasco, M. Polato, V. Scarano, C. Spagnuolo, andD. Yang, “A survey on hypergraph representation learning,” ACM Comp.Surv., vol. 56, no. 1, pp. 1–38, 2023.
[34] G. Lee, F. Bu, T. Eliassi-Rad, and K. Shin, “A survey on hypergraphmining: Patterns, tools, and generators,” ACM Comp. Surv., 2024.
[35] X. Fu, J. Xiao, Y. Zhu, A. Liu, F. Wu, and Z.-J. Zha, “Continual imagederaining with hypergraph convolutional networks,” IEEE Trans. PatternAnal. Mach. Intell., vol. 45, no. 8, pp. 9534–9551, 2023.
[36] D. Di, C. Zou, Y. Feng, H. Zhou, R. Ji, Q. Dai, and Y. Gao, “Generatinghypergraph-based high-order representations of whole-slide histopathologicalimages for survival prediction,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 45, no. 5, pp. 5800–5815, 2023.
[37] H. Fan, F. Zhang, Y. Wei, Z. Li, C. Zou, Y. Gao, and Q. Dai,“Heterogeneous hypergraph variational autoencoder for link prediction,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 8, pp. 4125–4138,2022.
[38] Y. Feng, J. Huang, S. Du, S. Ying, J.-H. Yong, Y. Li, G. Ding, R. Ji,and Y. Gao, “Hyper-YOLO: When Visual Object Detection MeetsHypergraph Computation,” IEEE Trans. Pattern Anal. Mach. Intell.,vol. 47, no. 4, pp. 2388–2401, 2025.
[39] Y. Feng, H. You, Z. Zhang, R. Ji, and Y. Gao, “Hypergraph neuralnetworks,” in AAAI, 2019, pp. 3558–3565.
[40] Y. Gao, Y. Feng, S. Ji, and R. Ji, “HGNN+: General hypergraph neuralnetworks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 3, pp.3181–3199, 2022.
[41] W. Lv, Y. Zhao, Q. Chang, K. Huang, G. Wang, and Y. Liu, “RTDETRv2:Improved baseline with bag-of-freebies for real-time detectiontransformer,” arXiv preprint arXiv:2407.17140, 2024.
[42] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman,“The pascal visual object classes (VOC) challenge,” Int. J. Comput.Vis., vol. 88, pp. 303–338, 2010.
引用说明:
@article{yolov13,
title={YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception},
author={Lei, Mengqi and Li, Siqi and Wu, Yihong and et al.},
journal={arXiv preprint arXiv:2506.17733},
year={2025}
}
【本节完】
本文由 youcans@xidian 对论文 YOLOv13: Attention-Centric Real-Time Object Detectors 进行摘编和翻译。该论文版权属于原文期刊和作者,译文只供研究学习使用。
版权声明:
欢迎关注『跟我学YOLO』系列
转发必须注明原文链接:
【跟我学YOLO】(1)YOLOv13:基于超图增强的自适应视觉感知的实时物体检测
Copyright 2025 by youcans@qq.com
Crated:2025-07