原文 https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
本文展现了自GPT-2(或者说Transformer)架构以来大模型结构的变化,以方便大家理解每一个步骤的细微变化所带来的影响。
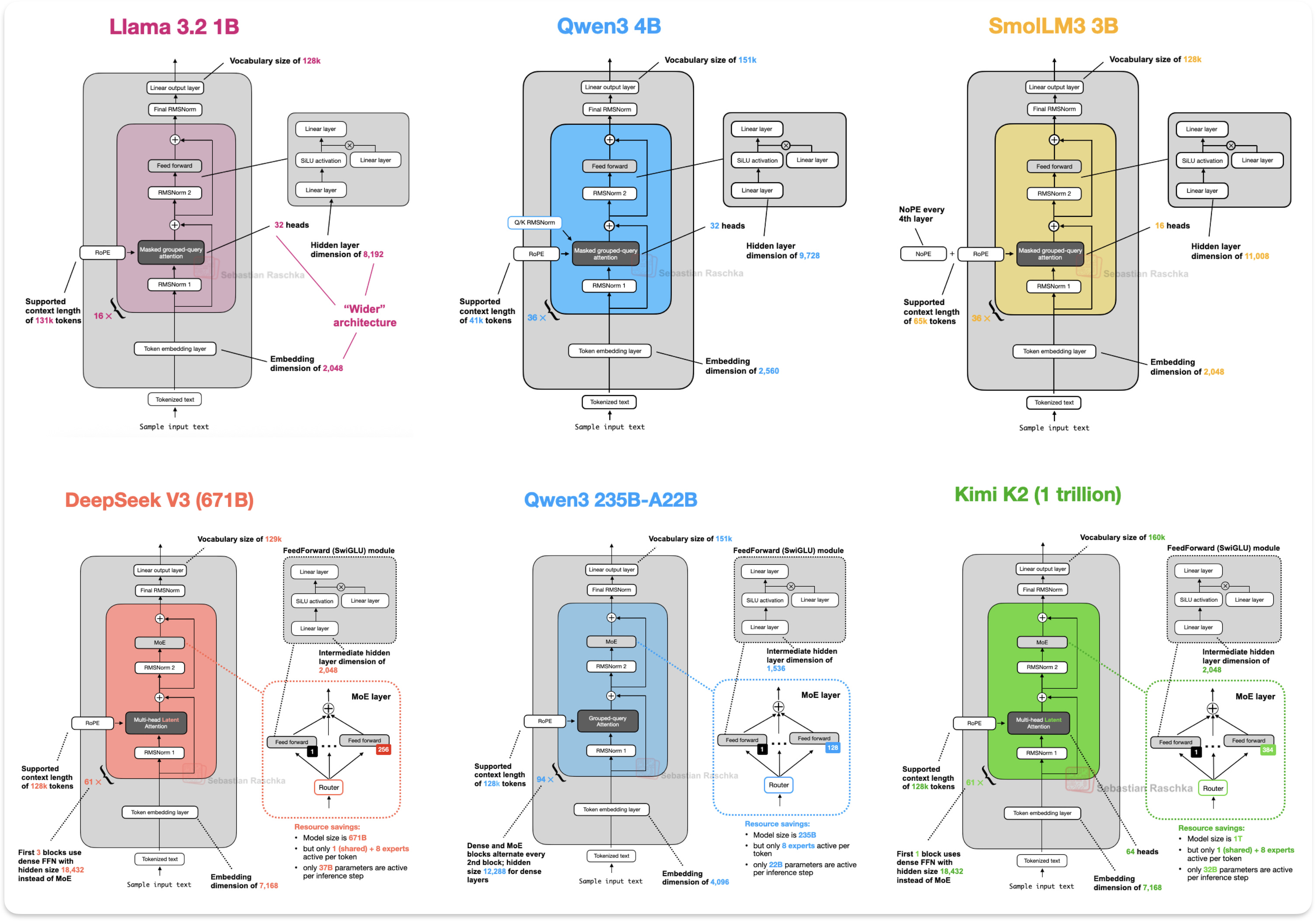
DeepSeek V3和R1所带来的影响
DeepSeek R1在2025年1月发布时产生了巨大的影响。DeepSeek R1是建立在DeepSeek V3架构之上的推理模型,该架构于2024年12月推出。
DeepSeek-V3是一个庞大的6710亿参数模型,在发布时表现优于其他开放式重量模型,包括405B Llama 3。尽管规模更大,但由于其混合专家(MoE)架构,它在推理时的效率要高得多,该架构每个令牌只激活一小部分(仅37B)参数。
DeepSeek V3中引入的两种关键架构技术,这些技术提高了其计算效率,并将其与许多其他LLM区分开来:
- 多头潜在注意力(MLA)
- 混合专家(MoE)
MLA
MLA是一个聪明的技巧,可以减少KV缓存内存的使用,同时在建模性能方面甚至略优于MHA。
在讨论MLA之前,我们看到GQA,近年来,它已成为多头注意力(MHA)的计算和参数效率更高的替代品的新标准替代品。
如图,Llama,Qwen3以及SmoILM3都是用了GQA但是我们看到DeepSeek和Kimi是用了MLA。但我们看到Transformer论文中使用的是MHA。
简单来说GQA,与MHA不同,每个头也有自己的一组键和值,为了减少内存使用,GQA将多个头分组以共享相同的键和值投影。GQA背后的核心思想是通过在多个查询头之间共享键和值头来减少它们的数量。这(1)降低了模型的参数计数,(2)减少了推理过程中键和值张量的内存带宽使用,因为需要从KV缓存中存储和检索的键和值更少。
例如,如下图2所示,如果有2个键值组和4个注意力头,那么头1和2可能共享一组键值,而头3和4共享另一组键值。这减少了键值计算的总数,从而降低了内存使用率并提高了效率(根据消融研究,不会明显影响建模性能)。
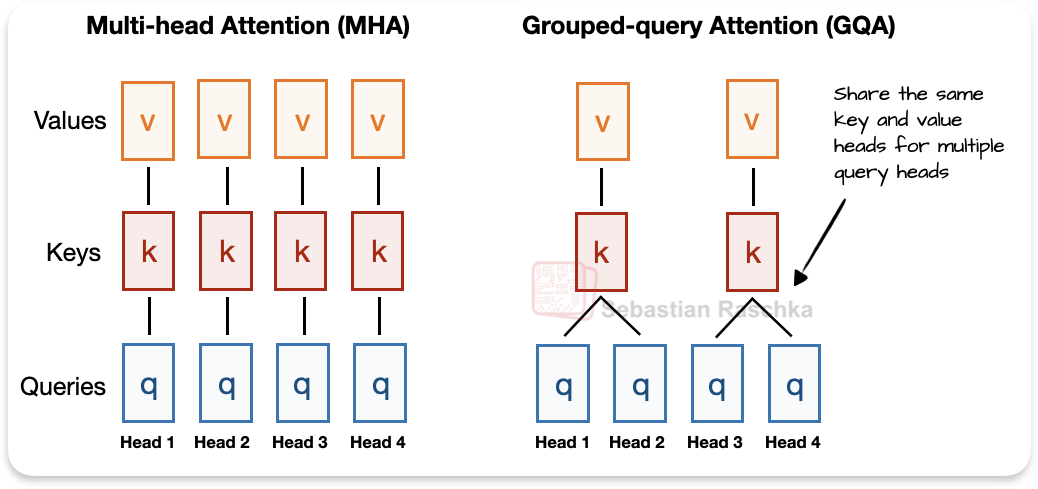
虽然GQA主要是MHA的计算效率解决方法,但消融研究(如原始GQA论文和Llama 2论文中的研究)表明,在LLM建模性能方面,它的表现与标准MHA相当。
现在,多头潜在注意力(MLA)提供了一种不同的内存节省策略,该策略也与KV缓存特别匹配。MLA没有像GQA那样共享键值头,而是将键值张量压缩到较低维的空间中,然后存储在KV缓存中。在推理时,这些压缩张量在使用前被投影回其原始大小,如下图3所示。这增加了额外的矩阵乘法,但减少了内存使用。
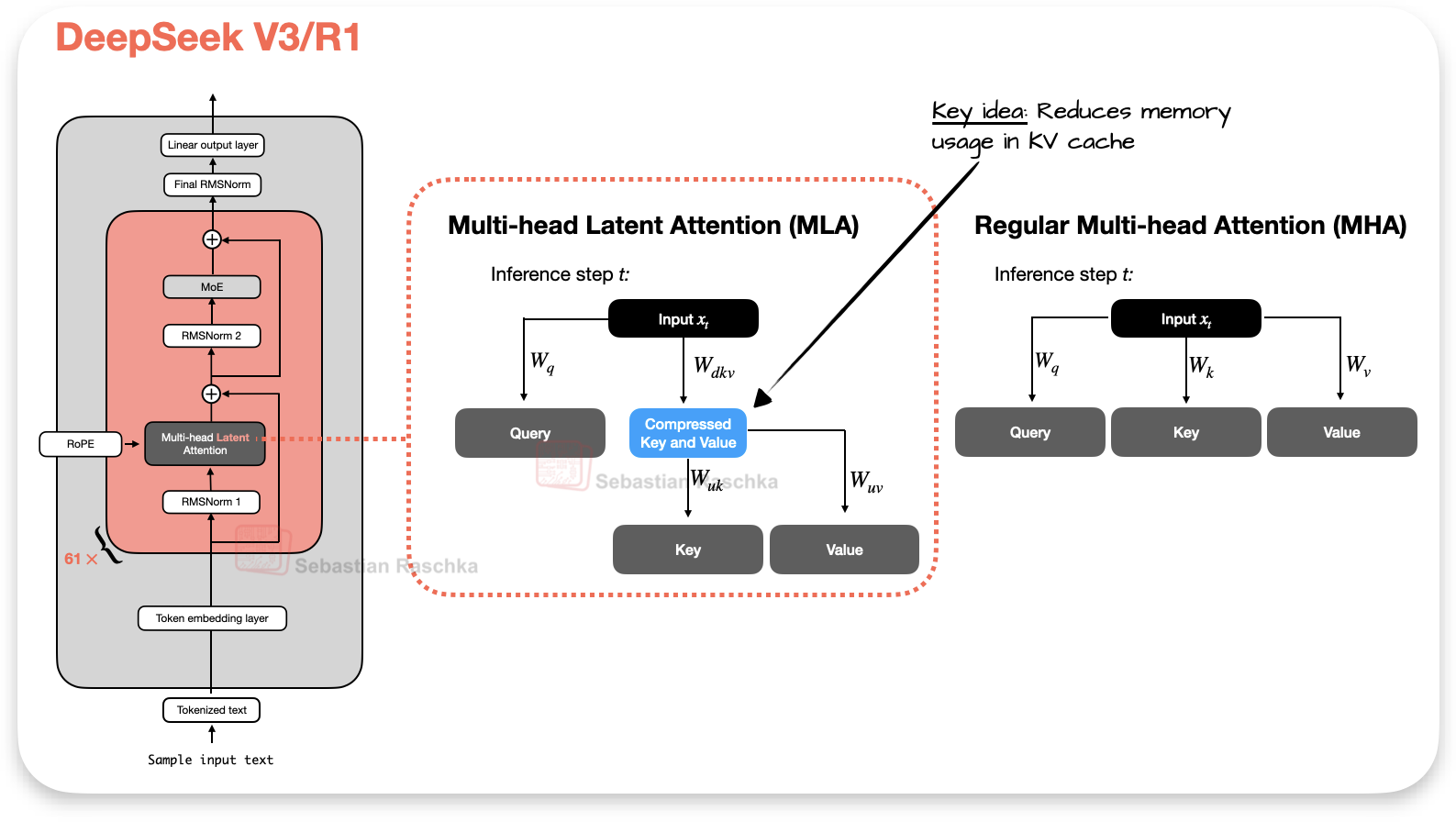
但MLA不是DeepSeek V3的创新,实际上在DeepSeek V2中就已经被使用了。在V2的论文中展示了消融研究的内容,也就解释了为什么使用MLA而不是GQA。
MOE
DeepSeek中另一个值得强调的主要架构组件是它对混合专家(MoE)层的使用。虽然DeepSeek并没有发明MoE,但它在今年已经复苏,我们稍后将介绍的许多架构也采用了它。
MoE的核心思想是用多个专家层替换变压器块中的每个前馈模块,其中每个专家层也是一个前馈模块。这意味着我们将单个FeedForward块替换为多个FeedForward模块,如下图5所示。内的前