参考资料
一 Agentic RAG理解
- **Agentic RAG(Agent-based Retrieval-Augmented Generation)**是指在传统的 RAG(Retrieval-Augmented Generation)框架中引入了 Agent(智能体)作为核心组件的变体。在标准的 RAG 系统中,主要是通过检索相关文档或信息来增强生成模型的能力,而 Agentic RAG 则通过集成一个智能体,帮助系统在搜索和生成过程中进行更智能的决策和交互。
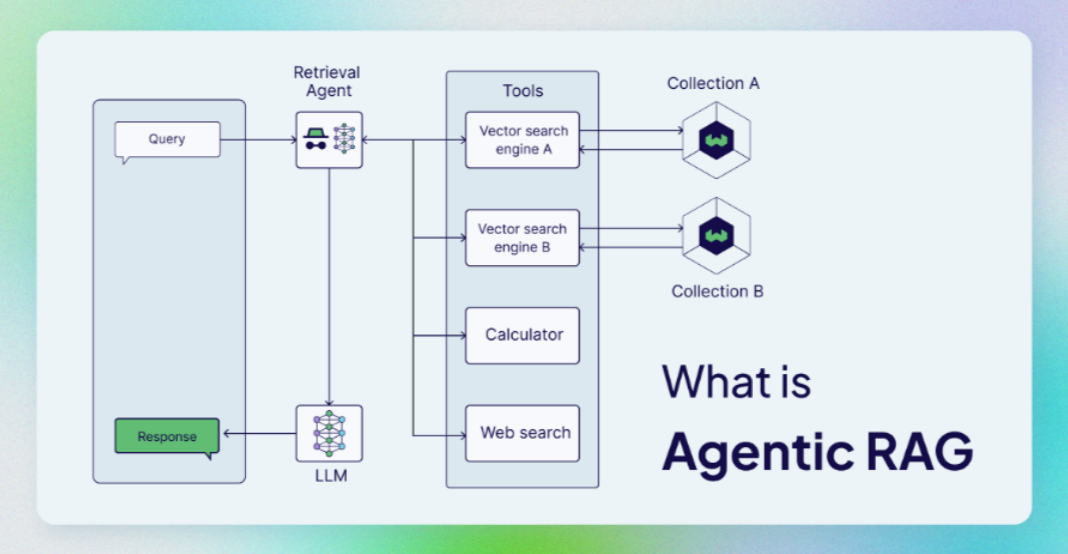
- 它将 AI 代理合并到 RAG 管道中,以编排其组件并执行简单信息检索和生成之外的其他操作,以克服非代理管道的限制。代理 RAG 最常见的是指在检索组件中使用代理。通过使用可访问不同检索器工具的检索代理而变得代理。例如:- 矢量搜索引擎(也称为查询引擎),通过矢量索引执行矢量搜索(如典型的 RAG 管道)、Web search 网页搜索、任何以编程方式访问软件的 API,例如电子邮件或聊天程序。
二 Agentic RAG简易实现
2.1 环境准备
2.2 完整代码
import os
from langchain_openai import ChatOpenAI
from typing import (Annotated,Sequence,TypedDict)
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
from langchain_core.tools import tool
from typing import Union, Optional
from pydantic import BaseModel, Field
import json
import http.client
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
os.environ["USER_AGENT"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
api_key="hk-xxx"
base_url="https://api.openai-hk.com/v1"
os.environ["OPENAI_API_KEY"] = api_key
os.environ["OPENAI_BASE_URL"] = base_url
llm = ChatOpenAI(
api_key=api_key,
base_url=base_url,
model="gpt-4o-mini"
)
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_milvus import Milvus
from PyPDF2 import PdfReader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
def pdf_read(pdf_doc):
text = ""
for pdf in pdf_doc:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
content = pdf_read(['./data/凡人修仙传第一章.pdf'])
chunk_size = 600
chunk_overlap = 200
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
documents = [Document(page_content=content)]
splits = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
)
vectorstore = Milvus.from_documents(
documents=splits,
collection_name="rag_milvus",
embedding=embeddings,
connection_args={
"uri": "https://xxx.serverless.gcp-us-west1.cloud.zilliz.com",
"user": "db_xxx",
"password": "xxx",
}
)
class AgentState(TypedDict):
"""代理状态"""
messages: Annotated[Sequence[BaseMessage], add_messages]
class SearchQuery(BaseModel):
query: str = Field(description="Questions for networking queries")
@tool(args_schema = SearchQuery)
def fetch_real_time_info(query):
"""获取互联网实时信息"""
conn = http.client.HTTPSConnection("google.serper.dev")
payload = json.dumps({
"q": query,
"gl": "cn",
"hl": "ny"
})
headers = {
'X-API-KEY': 'xxx',
'Content-Type': 'application/json'
}
conn.request("POST", "/search", payload, headers)
res = conn.getresponse()
data = res.read()
data=json.loads(data.decode("utf-8"))
if 'organic' in data:
return json.dumps(data['organic'], ensure_ascii=False)
else:
return json.dumps({"error": "No organic results found"}, ensure_ascii=False)
@tool
def vec_kg(question:str):
"""
Personal knowledge base, which stores the interpretation of AI Agent project concepts
"""
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Context: {context}
Answer:
""",
input_variables=["question", "document"],
)
'''
构建传统的RAG (Retrieval-Augmented Generation) Chain
使用LangChain的管道操作符(|)将prompt、语言模型(llm)和输出解析器(StrOutputParser)串联起来
流程: 用户输入 -> prompt模板处理 -> 语言模型生成 -> 字符串输出解析
'''
rag_chain = prompt | llm | StrOutputParser()
'''
构建检索器
将向量数据库(vectorstore)转换为检索器
search_kwargs={"k":1} 表示每次检索只返回最相关的1个文档片段
'''
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
'''
执行检索
用检索器获取与问题相关的文档片段
注意: 代码中直接使用了字符串"question",实际应该使用变量question
'''
docs = retriever.invoke(question)
'''
生成最终答案
将检索到的文档(context)和原始问题(question)作为输入传递给RAG链
RAG链会结合上下文信息生成答案
'''
generation = rag_chain.invoke({"context": docs, "question": question})
return generation
tools = [fetch_real_time_info, vec_kg]
model = llm.bind_tools(tools)
import json
from langchain_core.messages import ToolMessage, SystemMessage, HumanMessage
from langchain_core.runnables import RunnableConfig
tools_by_name = {tool.name: tool for tool in tools}
def tool_node(state: AgentState):
outputs = []
for tool_call in state["messages"][-1].tool_calls:
tool_result = tools_by_name[tool_call["name"]].invoke(tool_call["args"])
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
def call_model(
state: AgentState,
):
system_prompt = SystemMessage(
"你是一个智能助手,请尽全力回答用户的问题!"
)
response = model.invoke([system_prompt] + state["messages"])
return {"messages": [response]}
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return "end"
else:
return "continue"
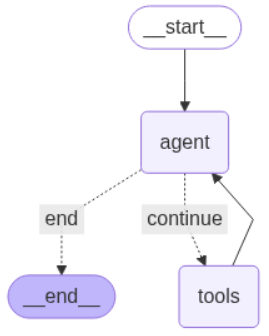
from langgraph.graph import StateGraph, END
from IPython.display import Image, display
workflow = StateGraph(AgentState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"end": END,
},
)
workflow.add_edge("tools", "agent")
graph = workflow.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
def print_stream(stream):
for s in stream:
message = s["messages"][-1]
if isinstance(message, tuple):
print(message)
else:
message.pretty_print()
inputs = {"messages": [("user", "请检索知识库,并实时联网检索,韩立的名字是谁起的?韩立的结局是什么?")]}
print_stream(graph.stream(inputs, stream_mode="values"))
2.3 运行结果
================================ Human Message =================================
请检索知识库,并实时联网检索,韩立的名字是谁起的?韩立的结局是什么?
================================== Ai Message ==================================
Tool Calls:
vec_kg (call_00r9KttjnIyBIpXsIhgWZbiS)
Call ID: call_00r9KttjnIyBIpXsIhgWZbiS
Args:
question: 韩立的名字是谁起的?
fetch_real_time_info (call_QzXlMFBxoxiMpd7cnxtHppsg)
Call ID: call_QzXlMFBxoxiMpd7cnxtHppsg
Args:
query: 韩立的结局
vec_kg (call_gi3ghV9O2TqPg3KFS9KSZm4d)
Call ID: call_gi3ghV9O2TqPg3KFS9KSZm4d
Args:
question: 韩立的结局是什么?
================================= Tool Message =================================
Name: vec_kg
"xxx"
================================== Ai Message ==================================
根据知识库的检索,韩立的名字是由村里人所起的,外号是“二愣子”。这个名字的来源与村里已经有一个叫“愣子”的孩子有关。尽管韩立并不喜欢这个名字,但他只能默默接受。
关于韩立的结局,来自实时联网信息的描述表明,韩立的结局是走上了一条与其他修士不同的修仙之路。起初,他出远门是为了赚取大量财富,但最后却实现了自己的修炼梦想,最终达到了一种自我修炼的境地。在经历诸多磨难之后,韩立在世俗利益面前选择了自己的信仰与道路,这与他最初的追求有了较大变化。