作者:来自 Elastic Jeffrey Rengifo

了解如何从 LlamaIndex RankGPT reranker 迁移到 Elastic 内置的 semantic reranker。
Elasticsearch 拥有与行业领先的 Gen AI 工具和服务商的原生集成。查看我们的网络研讨会,了解如何突破 RAG 基础,或使用 Elastic Vector Database 构建可投入生产的应用。
为了为你的使用场景构建最佳搜索方案,可以立即开始免费云试用,或在本地机器上尝试 Elastic。
在本文中,我们将探讨如何使用 Llamaindex RankGPT Reranker 和 Elasticsearch 内置的 semantic reranker。Elastic 提供开箱即用的体验,在 retrievers pipeline 中部署和使用 reranker,无需额外操作,且具备可扩展性。
最初,在 Elasticsearch 中进行 rerank 需要多个步骤,但现在它已经直接集成进 retrievers pipeline:第一阶段运行搜索查询,第二阶段对结果进行 rerank,如下图所示:
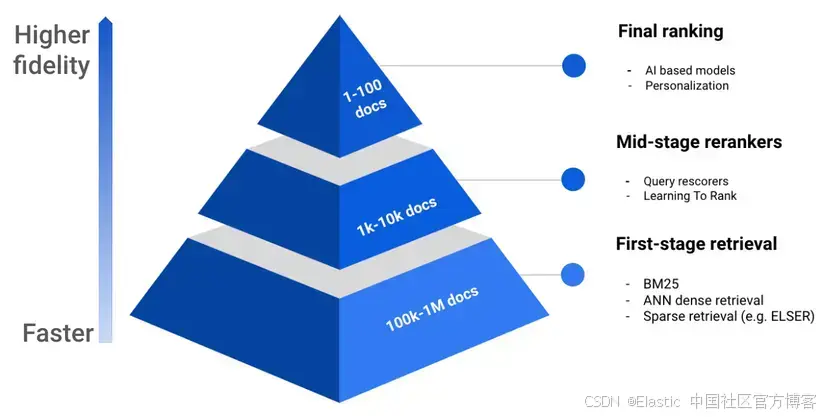
什么是 rerank?
Rerank 是一种在检索出一组与用户查询相关的文档后,使用较昂贵的机制将最相关的文档推到结果顶部的过程。
有许多策略可以使用专门的 cross-encoder 模型对文档进行 rerank,比如 Elastic Rerank 模型,或 MS Marco 的 Cross encoder( cross-encoder/ms-marco-MiniLM-L6-v2)。另一种方法是使用 LLM 进行 rerank。Elastic Rerank 模型的一个优点是,它既可以作为 semantic search pipeline 的一部分使用,也可以作为独立工具改进现有的 BM25 打分系统。
一个 reranker 需要一组候选文档和用户查询,根据用户查询重新排序这些候选文档,从最相关到最不相关。
在本文中,我们将探索 Llamaindex RankGPT Reranker(即 RankGPT reranker 实现)和 Elastic Semantic Reranker,后者使用 Elastic Rerank 模型。
完整示例可在此 notebook 中查看。
步骤
- Products 索引
- 用户问题
- LlamaIndex rerank
- Elasticsearch semantic rerank
Products 索引
让我们基于用户的问题为笔记本电脑创建一个 reranker。如果用户是重度玩家,他们应该获得性能最强的机器。如果他们是学生,轻便的机器可能就可以了。
让我们从在 Notebook 中创建一些文档开始:
products = [
{
"name": "ASUS ROG Strix G16",
"description": "Powerful gaming laptop with Intel Core i9 and RTX 4070.",
"price": 1899.99,
"reviews": 4.7,
"sales": 320,
"features": [
"Intel Core i9",
"RTX 4070",
"16GB RAM",
"512GB SSD",
"165Hz Display",
],
},
{
"name": "Razer Blade 15",
"description": "Premium gaming laptop with an ultra-slim design and high refresh rate." ,
"price": 2499.99,
"reviews": 4.6,
"sales": 290,
"features": [
"Intel Core i7",
"RTX 4060",
"16GB RAM",
"1TB SSD",
"240Hz Display",
],
},
{
"name": "Acer Predator Helios 300",
"description": "Affordable yet powerful gaming laptop with RTX graphics.",
"price": 1399.99,
"reviews": 4.5,
"sales": 500,
"features": [
"Intel Core i7",
"RTX 3060",
"16GB RAM",
"512GB SSD",
"144Hz Display",
],
},
{
"name": "MSI Stealth 17",
"description": "High-performance gaming laptop with a 17-inch display.",
"price": 2799.99,
"reviews": 4.8,
"sales": 200,
"features": ["Intel Core i9", "RTX 4080", "32GB RAM", "1TB SSD", "4K Display"],
},
{
"name": "Dell XPS 15",
"description": "Sleek and powerful ultrabook with a high-resolution display.",
"price": 2199.99,
"reviews": 4.7,
"sales": 350,
"features": [
"Intel Core i7",
"RTX 3050 Ti",
"16GB RAM",
"1TB SSD",
"OLED Display",
],
},
{
"name": "HP Omen 16",
"description": "Gaming laptop with a balanced price-to-performance ratio.",
"price": 1599.99,
"reviews": 4.4,
"sales": 280,
"features": [
"AMD Ryzen 7",
"RTX 3060",
"16GB RAM",
"512GB SSD",
"165Hz Display",
],
},
{
"name": "Lenovo Legion 5 Pro",
"description": "Powerful Ryzen-powered gaming laptop with high refresh rate.",
"price": 1799.99,
"reviews": 4.6,
"sales": 400,
"features": [
"AMD Ryzen 9",
"RTX 3070 Ti",
"16GB RAM",
"1TB SSD",
"165Hz Display",
],
},
{
"name": "MacBook Pro 16",
"description": "Apple's most powerful laptop with M3 Max chip.",
"price": 3499.99,
"reviews": 4.9,
"sales": 500,
"features": [
"Apple M3 Max",
"32GB RAM",
"1TB SSD",
"Liquid Retina XDR Display",
],
},
{
"name": "Alienware m18",
"description": "High-end gaming laptop with extreme performance.",
"price": 2999.99,
"reviews": 4.8,
"sales": 150,
"features": [
"Intel Core i9",
"RTX 4090",
"32GB RAM",
"2TB SSD",
"480Hz Display",
],
},
{
"name": "Samsung Galaxy Book3 Ultra",
"description": "Ultra-lightweight yet powerful laptop with AMOLED display.",
"price": 2099.99,
"reviews": 4.5,
"sales": 180,
"features": [
"Intel Core i7",
"RTX 4070",
"16GB RAM",
"512GB SSD",
"AMOLED Display",
],
},
{
"name": "Microsoft Surface Laptop 5",
"description": "Sleek productivity laptop with great battery life.",
"price": 1699.99,
"reviews": 4.3,
"sales": 220,
"features": ["Intel Core i7", "16GB RAM", "512GB SSD", "Touchscreen"],
},
{
"name": "Gigabyte AORUS 17",
"description": "Performance-focused gaming laptop with powerful cooling.",
"price": 1999.99,
"reviews": 4.6,
"sales": 250,
"features": [
"Intel Core i9",
"RTX 4070",
"16GB RAM",
"1TB SSD",
"360Hz Display",
],
},
]用户问题
让我们定义一个将用于 rerank 结果的问题。
user_query = "Best laptops for gaming"LlamaIndex rerank
安装依赖并导入包
我们安装执行 LlamaIndex 的 RankGPT reranker 和 Elasticsearch 文档检索所需的所有依赖。然后,我们将笔记本电脑数据加载到 ElasticsearchStore 中,ElasticsearchStore 是 LlamaIndex 对 Elasticsearch 向量数据库的抽象,并使用 VectorStoreIndex 类进行检索。
pip install llama-index-core llama-index-llms-openai rank-llm llama-index-postprocessor-rankgpt-rerank llama-index-vector-stores-elasticsearch elasticsearch -q
import os
import nest_asyncio
from getpass import getpass
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
from llama_index.core import (
Document,
VectorStoreIndex,
QueryBundle,
Settings,
StorageContext,
)
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.postprocessor.rankgpt_rerank import RankGPTRerank
from llama_index.llms.openai import OpenAI
from elasticsearch import Elasticsearch
nest_asyncio.apply()设置密钥:
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
os.environ["ELASTICSEARCH_ENDPOINT"] = "ELASTIC_ENDPOINT"
os.environ["ELASTICSEARCH_API_KEY"] = "ELASTIC_API_KEY"
INDEX_NAME = "products-laptops"Elasticsearch 客户端
我们实例化 Elasticsearch 客户端,用于索引文档并针对我们的集群运行查询。
_client = Elasticsearch(
os.environ["ELASTICSEARCH_ENDPOINT"],
api_key=os.environ["ELASTICSEARCH_API_KEY"],
)Mappings
我们将使用普通文本字段进行全文搜索,并创建一个 semantic_field,复制所有内容,以便运行 semantic 和 hybrid 查询。在 Elasticsearch 8.18+ 中,推理端点将自动部署。
# Creating mapping for the index
try:
_client.indices.create(
index=INDEX_NAME,
body={
"mappings": {
"properties": {
"metadata": {
"properties": {
"name": {"type": "text", "copy_to": "semantic_field"},
"description": {
"type": "text",
"copy_to": "semantic_field",
},
"price": {
"type": "float",
},
"reviews": {
"type": "float",
},
"sales": {"type": "integer"},
"features": {
"type": "keyword",
"copy_to": "semantic_field",
},
}
},
"semantic_field": {"type": "semantic_text"},
"text": {
"type": "text"
}, # Field to store the text content for LlamaIndex
"embeddings": {"type": "dense_vector", "dims": 512},
}
}
},
)
print("index created successfully")
except Exception as e:
print(
f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }"
)向 LlamaIndex 索引数据
从我们定义的产品数组创建 ElasticsearchStore。这将创建一个 Elasticsearch 向量存储,后续可以使用 VectorStoreIndex 进行访问。
document_objects = []
es_store = ElasticsearchStore(
es_url=os.environ["ELASTICSEARCH_ENDPOINT"],
es_api_key=os.environ["ELASTICSEARCH_API_KEY"],
index_name=INDEX_NAME,
embedding_field="embeddings",
text_field="text",
)
storage_context = StorageContext.from_defaults(vector_store=es_store)
for doc in products:
text_content = f"""
Product Name: {doc["name"]}
Description: {doc["description"]}
Price: ${doc["price"]}
Reviews: {doc["reviews"]} stars
Sales: {doc["sales"]} units sold
Features: {', '.join(doc["features"])}
"""
metadata = {
"name": doc["name"],
"description": doc["description"],
"price": doc["price"],
"reviews": doc["reviews"],
"sales": doc["sales"],
"features": doc["features"],
}
document_objects.append(Document(text=text_content, metadata=metadata))
index = VectorStoreIndex([], storage_context=storage_context)
for doc in document_objects:
index.insert(doc)LLM 设置
定义将作为 reranker 的 LLM:
Settings.llm = OpenAI(temperature=0, model="gpt-4.1-mini")
Settings.chunk_size = 512Rerank 功能
我们现在创建一个函数,该函数先执行 retriever 从向量索引中获取与用户问题最相似的文档,然后在此基础上应用 RankGPTRerank 进行 rerank,最后返回重新排序后的文档。
def get_retrieved_nodes(
query_str, vector_top_k=10, reranker_top_n=5, with_reranker=False
):
query_bundle = QueryBundle(query_str)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=vector_top_k,
)
retrieved_nodes = retriever.retrieve(query_bundle)
if with_reranker:
# configure reranker
reranker = RankGPTRerank(
llm=OpenAI(
model="gpt-4.1-mini",
temperature=0.0,
api_key=os.environ["OPENAI_API_KEY"],
),
top_n=reranker_top_n,
verbose=True,
)
retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)
return retrieved_nodes我们还创建了一个函数来格式化结果文档。
def visualize_retrieved_nodes(nodes):
formatted_results = []
for node in nodes:
text = node.node.get_text()
product_name = text.split("Product Name:")[1].split("\n")[0].strip()
price = text.split("Price:")[1].split("\n")[0].strip()
reviews = text.split("Reviews:")[1].split("\n")[0].strip()
features = text.split("Features:")[1].strip()
formatted_result = f"{price} - {product_name} ({reviews}) {features}"
formatted_results.append(formatted_result)
return formatted_results不使用 rerank
我们先运行不带 rerank 的请求。
new_nodes = get_retrieved_nodes(
query_str=user_query,
vector_top_k=5,
with_reranker=False,
)
results = visualize_retrieved_nodes(new_nodes)
print("\nTop 5 results without rerank:")
for idx, result in enumerate(results, start=1):
print(f"{idx}. {result}")答案:
Top 5 results without rerank:
1. $2499.99 - Razer Blade 15 (4.6 stars) Intel Core i7, RTX 4060, 16GB RAM, 1TB SSD, 240Hz Display
2. $1899.99 - ASUS ROG Strix G16 (4.7 stars) Intel Core i9, RTX 4070, 16GB RAM, 512GB SSD, 165Hz Display
3. $1999.99 - Gigabyte AORUS 17 (4.6 stars) Intel Core i9, RTX 4070, 16GB RAM, 1TB SSD, 360Hz Display
4. $2799.99 - MSI Stealth 17 (4.8 stars) Intel Core i9, RTX 4080, 32GB RAM, 1TB SSD, 4K Display
5. $2999.99 - Alienware m18 (4.8 stars) Intel Core i9, RTX 4090, 32GB RAM, 2TB SSD, 480Hz Display使用 rerank
现在我们启用 rerank,它将执行相同的向量搜索,然后使用 LLM 对结果进行 rerank,应用 “Best laptops for gaming” 标准对前 5 个结果进行排序。我们可以看到细微差别,比如 Intel Core i7 处理器被排到最后,而 Alienware m18 升到了第 2 位。
new_nodes = get_retrieved_nodes(
user_query,
vector_top_k=5,
reranker_top_n=5,
with_reranker=True,
)
results = visualize_retrieved_nodes(new_nodes)
print("\nTop 5 results with reranking:")
for idx, result in enumerate(results, start=1):
print(f"{idx}. {result}")答案:
Top 5 results with reranking:
1. $1899.99 - ASUS ROG Strix G16 (4.7 stars) Intel Core i9, RTX 4070, 16GB RAM, 512GB SSD, 165Hz Display
2. $2999.99 - Alienware m18 (4.8 stars) Intel Core i9, RTX 4090, 32GB RAM, 2TB SSD, 480Hz Display
3. $2799.99 - MSI Stealth 17 (4.8 stars) Intel Core i9, RTX 4080, 32GB RAM, 1TB SSD, 4K Display
4. $1999.99 - Gigabyte AORUS 17 (4.6 stars) Intel Core i9, RTX 4070, 16GB RAM, 1TB SSD, 360Hz Display
5. $2499.99 - Razer Blade 15 (4.6 stars) Intel Core i7, RTX 4060, 16GB RAM, 1TB SSD, 240Hz DisplayElasticsearch 语义 rerank
推理 rerank 端点
创建一个推理端点,可以独立调用它来根据查询对候选列表进行 rerank,或作为 retriever 的一部分使用:
INFERENCE_RERANK_NAME = "my-elastic-rerank"
try:
_client.options(
request_timeout=60, max_retries=3, retry_on_timeout=True
).inference.put(
task_type="rerank",
inference_id=INFERENCE_RERANK_NAME,
body={
"service": "elasticsearch",
"service_settings": {
"model_id": ".rerank-v1",
"num_threads": 1,
"adaptive_allocations": {
"enabled": True,
"min_number_of_allocations": 1,
"max_number_of_allocations": 4,
},
},
},
)
print("Inference endpoint created successfully.")
except Exception as e:
print(
f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }"
)我们定义一个函数来执行搜索查询,然后解析返回的命中结果。
async def es_search(query):
response = _client.search(index=INDEX_NAME, body=query)
hits = response["hits"]["hits"]
if not hits:
return ""
return hits与 LlamaIndex 一样,我们创建一个函数来格式化结果文档。
def format_es_results(hits):
formatted_results = []
for hit in hits:
metadata = hit["_source"]["metadata"]
name = metadata.get("name")
price = metadata.get("price")
reviews = metadata.get("reviews")
features = metadata.get("features")
formatted_result = f"{price} - {name} ({reviews}) {features}"
formatted_results.append(formatted_result)
return formatted_results语义查询
我们将从语义查询开始,返回与用户问题最相似的结果。
semantic_results = await es_search(
{
"size": 5,
"query": {
"semantic": {
"field": "semantic_field",
"query": user_query,
}
},
"_source": {
"includes": [
"metadata",
]
},
}
)
semantic_formatted_results = format_es_results(semantic_results)
print("Query results:")
for idx, result in enumerate(semantic_formatted_results, start=1):
print(f"{idx}. {result}")查询结果:
1. 2999.99 - Alienware m18 (4.8) ['Intel Core i9', 'RTX 4090', '32GB RAM', '2TB SSD', '480Hz Display']
2. 2799.99 - MSI Stealth 17 (4.8) ['Intel Core i9', 'RTX 4080', '32GB RAM', '1TB SSD', '4K Display']
3. 1599.99 - HP Omen 16 (4.4) ['AMD Ryzen 7', 'RTX 3060', '16GB RAM', '512GB SSD', '165Hz Display']
4. 1399.99 - Acer Predator Helios 300 (4.5) ['Intel Core i7', 'RTX 3060', '16GB RAM', '512GB SSD', '144Hz Display']
5. 1999.99 - Gigabyte AORUS 17 (4.6) ['Intel Core i9', 'RTX 4070', '16GB RAM', '1TB SSD', '360Hz Display']rerank_results = await es_search(
{
"size": 5,
"_source": {
"includes": [
"metadata",
]
},
"retriever": {
"text_similarity_reranker": {
"retriever": {
"standard": {
"query": {
"semantic": {
"field": "semantic_field",
"query": user_query,
}
}
}
},
"field": "semantic_field",
"inference_id": INFERENCE_RERANK_NAME,
"inference_text": "reorder by quality-price ratio",
"rank_window_size": 5,
}
},
}
)
rerank_formatted_results = format_es_results(rerank_results)
print("Query results:")
for idx, result in enumerate(rerank_formatted_results, start=1):
print(f"{idx}. {result}")查询结果:
1. 1399.99 - Acer Predator Helios 300 (4.5) ['Intel Core i7', 'RTX 3060', '16GB RAM', '512GB SSD', '144Hz Display']
2. 2999.99 - Alienware m18 (4.8) ['Intel Core i9', 'RTX 4090', '32GB RAM', '2TB SSD', '480Hz Display']
3. 2799.99 - MSI Stealth 17 (4.8) ['Intel Core i9', 'RTX 4080', '32GB RAM', '1TB SSD', '4K Display']
4. 1999.99 - Gigabyte AORUS 17 (4.6) ['Intel Core i9', 'RTX 4070', '16GB RAM', '1TB SSD', '360Hz Display']
5. 1599.99 - HP Omen 16 (4.4) ['AMD Ryzen 7', 'RTX 3060', '16GB RAM', '512GB SSD', '165Hz Display']在下表中,我们可以看到不同测试中的排名对比:
| Laptop model | Llama (no rerank) | Llama (with rerank) | Elastic (no rerank) | Elastic (with rerank) |
|---|---|---|---|---|
| Razer Blade 15 | 1 | 5 | - | - |
| ASUS ROG Strix G16 | 2 | 1 | - | - |
| Gigabyte AORUS 17 | 3 | 4 | 5 | 4 |
| MSI Stealth 17 | 4 | 3 | 2 | 3 |
| Alienware m18 | 5 | 2 | 1 | 2 |
| HP Omen 16 | - | - | 3 | 5 |
| Acer Predator Helios 300 | - | - | 4 | 1 |
图例:破折号(-)表示该方法的前五名中未出现该项。
它保持了一致性,将高端笔记本如 Alienware m18 和 MSI Stealth 17 保持在前列 —— 就像 LlamaIndex rerank 一样 —— 同时实现了更好的性价比。
结论
Reranker 是提升搜索系统质量的强大工具,确保我们总能检索到每个用户问题中最重要的信息。
LlamaIndex 提供多种 reranker 策略,使用专门模型或 LLM。在最简单的实现中,你可以创建内存中的向量存储并本地保存文档,然后进行检索和 rerank,或者使用 Elasticsearch 作为持久化的向量存储。
另一方面,Elasticsearch 提供开箱即用的推理端点框架,可以将 reranker 作为检索管道的一部分或独立端点使用。你还可以选择 Elastic 自身、Cohere、Jina 或阿里巴巴等多种服务商,或部署任何兼容的第三方模型。在 Elasticsearch 的最简单实现中,你的文档和 rerank 模型都存储在 Elasticsearch 集群中,便于扩展。
原文:LlamaIndex and Elasticsearch Rerankers: Unbeatable simplicity - Elasticsearch Labs